




Data Mining: От сырых данных к ценным сведениям

Data Mining: От сырых данных к ценным сведениям
Что такое добыча данных?
Добыча данных - это метод обнаружения закономерностей, тенденций и ценных идей в больших объемах данных. Она помогает компаниям и исследователям принимать более эффективные решения, обнаруживая скрытые связи, которые не очевидны на первый взгляд. С помощью таких методов, как классификация, кластеризация и поиск ассоциативных правил, методы поиска данных превращают необработанные данные в ценные сведения. Будь то прогнозирование поведения клиентов, выявление мошенничества или улучшение результатов поиска, добыча данных играет ключевую роль в формировании современных технологий.
Как работает добыча данных?
Добыча данных анализирует большие массивы данных, чтобы найти скрытые закономерности, взаимосвязи и тенденции, которые могут быть использованы для принятия решений. В нем используются статистические методы, алгоритмы машинного обучения и методы управления базами данных для обработки необработанных данных в полезные сведения. Процесс состоит из ряда шагов, направленных на очистку, организацию и извлечение полезной информации из данных. Чтобы лучше понять это, рассмотрим платформу электронной коммерции, которая хочет предсказать, какие клиенты, скорее всего, совершат покупку, основываясь на их поведении в браузере.
Шаги в процессе добычи данных
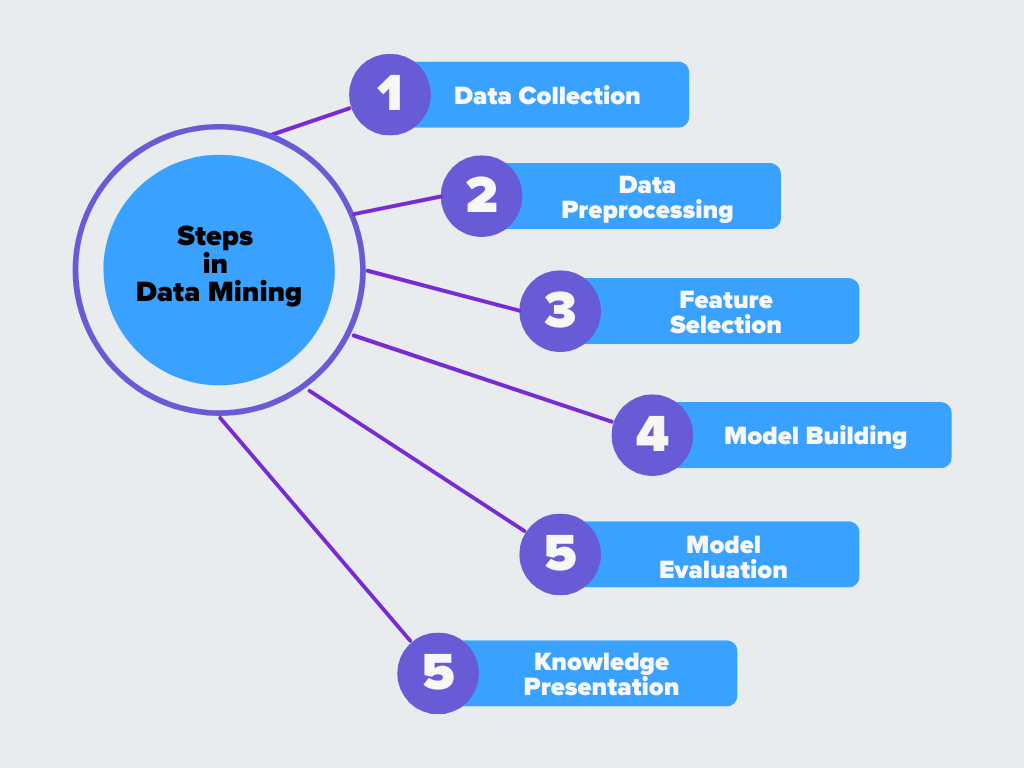 Рисунок - Шаги в процессе добычи данных
Рисунок - Шаги в процессе добычи данных
Иллюстрация: Шаги в добыче данных
1. Сбор данных
На первом этапе необходимо собрать данные из различных источников, таких как базы данных, электронные таблицы, IoT-устройства или облачные хранилища. Поскольку данные часто поступают в различных форматах и структурах, их необходимо интегрировать в единую систему. На этом этапе также обрабатываются дублирующиеся записи и объединяются наборы данных для создания единой картины.
**Например, платформа электронной коммерции собирает данные из журналов сайта, учетных записей пользователей и истории покупок, чтобы составить полное представление о поведении покупателей.
2. Предварительная обработка данных
Необработанные данные редко бывают идеальными. Они могут содержать недостающие значения, несоответствия или ошибки, которые могут повлиять на точность результатов. Предварительная обработка данных включает в себя очистку данных путем удаления дубликатов, восполнения недостающих значений и исправления ошибок. Такие методы предварительной обработки, как нормализация и преобразование, помогают структурировать данные, чтобы они были готовы к анализу.
Например, некоторые клиенты могут иметь неполный профиль, отсутствующую историю покупок или дублирующиеся записи, которые необходимо очистить перед анализом.
3. Выбор признаков
Не все данные полезны для добычи. На этапе feature selection данные преобразуются в более подходящий формат, выбираются важные признаки, а нерелевантные удаляются. Инжиниринг признаков создает новые переменные на основе существующих данных, что также является частью этого шага для повышения эффективности модели.
**Например, могут быть отобраны такие характеристики, как время, проведенное на страницах товаров, прошлые покупки и количество отказов от корзины, а менее полезные данные, например IP-адреса, могут быть удалены.
4. Построение модели
После очистки и подготовки данных применяются алгоритмы для поиска закономерностей и взаимосвязей. Такие методы, как кластеризация, классификация и поиск ассоциативных правил, помогают выявить значимые моменты. Модели машинного обучения могут быть обучены на этом этапе, чтобы распознавать тенденции, классифицировать данные или делать прогнозы на основе исторических закономерностей.
**Например, платформа может использовать модель классификации, чтобы предсказать, совершит ли пользователь покупку, основываясь на его поведении в браузере и прошлых покупках.
5. Оценка модели
Не все закономерности, обнаруженные в процессе поиска, являются полезными. На этом этапе проверяются результаты, чтобы убедиться в их точности и значимости. Аналитики сравнивают полученные результаты с известными данными, используют показатели эффективности, такие как точность и запоминание, и при необходимости дорабатывают модели. Цель - подтвердить, что найденные закономерности надежны и применимы к реальным сценариям.
**Платформа тестирует модель прогнозирования, сравнивая ее результаты с реальными покупками, чтобы проверить ее точность.
6. Представление знаний
Заключительный этап заключается в четком и понятном представлении полученных знаний. Это может включать в себя визуальные отчеты, информационные панели или сводки, которые могут использовать лица, принимающие решения. Извлеченные знания затем применяются для улучшения процессов, принятия бизнес-решений или усовершенствования систем, управляемых искусственным интеллектом.
**Например, платформа электронной коммерции использует эти знания для создания персонализированных рекомендаций по товарам, целевой рекламы и рекламных предложений для увеличения продаж.
Методы и алгоритмы добычи данных
Методы добычи данных делятся на категории в зависимости от того, как они анализируют данные и извлекают значимые закономерности. Эти методы включают подконтрольное обучение, неподконтрольное обучение, полуподконтрольное обучение и обнаружение аномалий. Каждый подход подходит для решения различных типов задач, начиная от классификации и прогнозирования и заканчивая выявлением скрытых структур в данных.
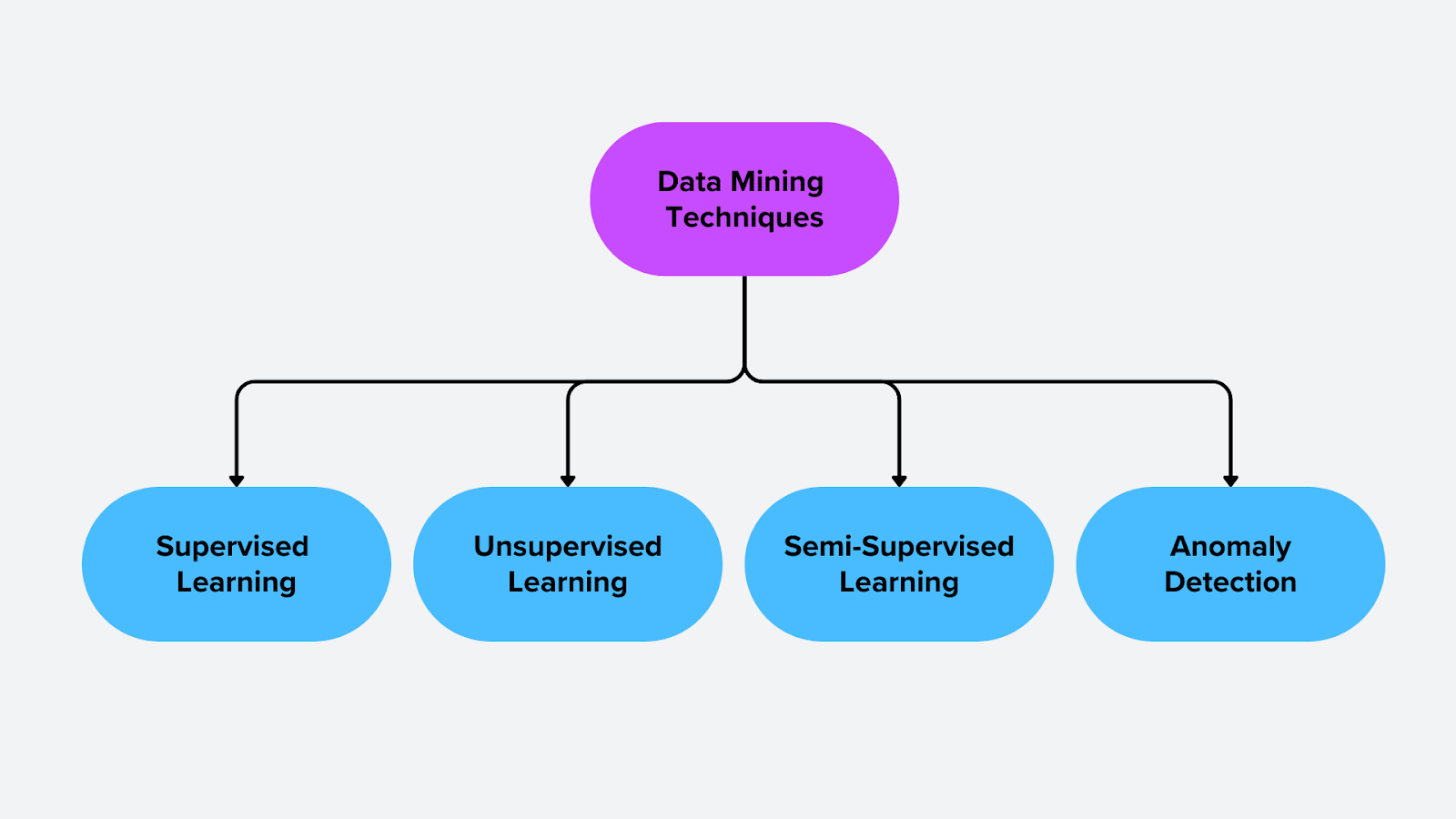 Рисунок - Методы добычи данных
Рисунок - Методы добычи данных
Иллюстрация: Методы добычи данных
1. Контролируемое обучение
Контролируемое обучение тренирует модель на маркированных данных, где каждому входу соответствует известный выход. Модель учится на этих примерах, чтобы предсказывать результаты для новых, еще не полученных данных. Этот подход широко используется в задачах классификации, регрессии и прогнозирования временных рядов.
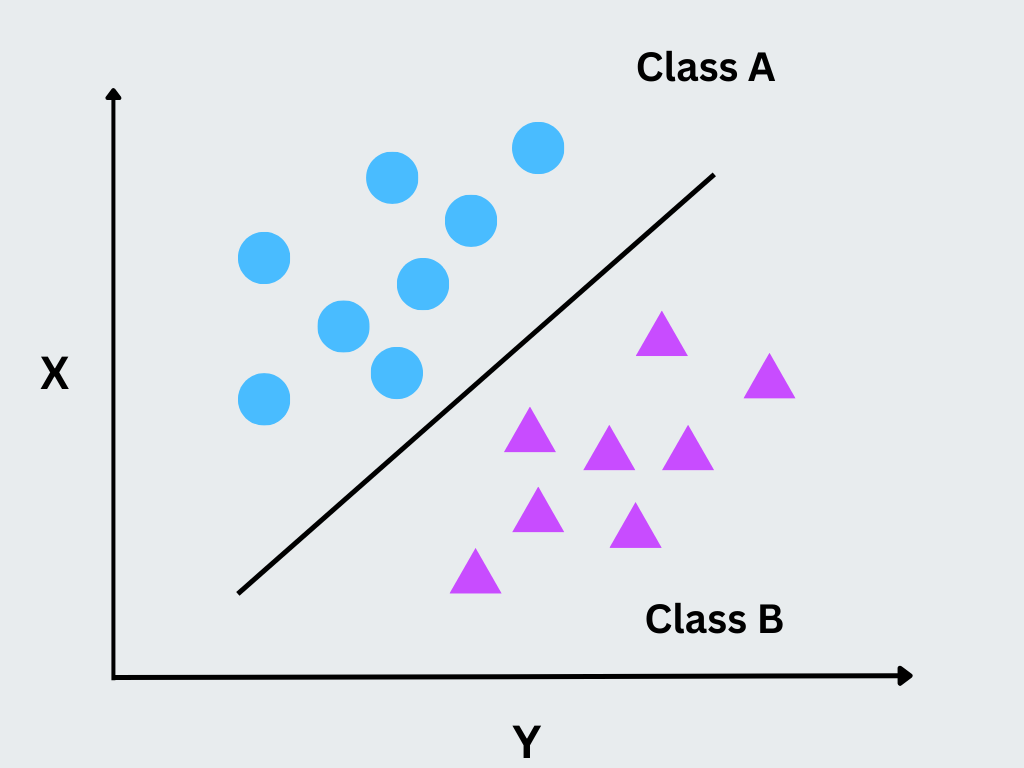 Рисунок - Методы контролируемого машинного обучения
Рисунок - Методы контролируемого машинного обучения
Иллюстрация: Методы машинного обучения с супервизией
Деревья решений: Модель, основанная на правилах, которая разбивает данные на более мелкие подмножества на основе значений признаков, формируя древовидную структуру для принятия решений.
Random Forests: Ансамбль из нескольких деревьев решений, который повышает точность и уменьшает избыточную подгонку путем усреднения прогнозов нескольких моделей.
Gradient Boosted Trees (GBTs): Последовательный подход к построению деревьев решений, который исправляет предыдущие ошибки на каждой итерации, что приводит к повышению эффективности прогнозирования.
Support Vector Machines (SVMs): Алгоритм классификации, который находит оптимальную границу (гиперплоскость) для разделения различных категорий данных.
K-Nearest Neighbors (K-NN): Алгоритм, основанный на расстоянии, который классифицирует новые точки данных на основе большинства классов их ближайших соседей.
Нейронные сети: Многослойные модели, созданные на основе человеческого мозга, которые учатся сложным взаимосвязям между входными и выходными данными.
Поддерживающая векторная регрессия (SVR): Разновидность SVM, используемая для предсказания непрерывных значений вместо категориальных меток.
2. Неконтролируемое обучение
Неподконтрольное обучение анализирует данные без помеченных выводов, выявляя скрытые структуры и взаимосвязи в наборе данных. Оно обычно используется для кластеризации, обнаружения аномалий и уменьшения размерности.
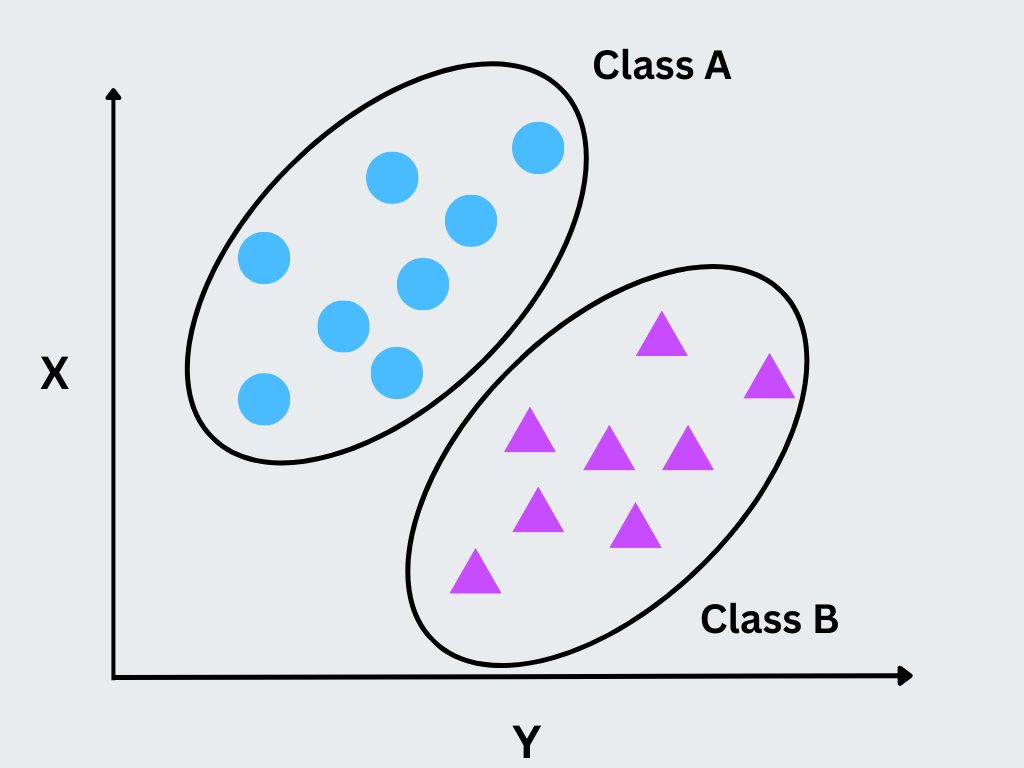 Рисунок - Методы машинного обучения без контроля
Рисунок - Методы машинного обучения без контроля
Иллюстрация: Методы машинного обучения без контроля
K-Means Clustering: Алгоритм разбиения, который делит данные на K кластеров путем отнесения каждой точки к ближайшему центру кластера.
Иерархическая кластеризация:** Построение иерархии кластеров с помощью методов "снизу вверх" (агломеративный) или "сверху вниз" (делительный).
DBSCAN (Density-Based Spatial Clustering): Группирует плотно упакованные точки данных, рассматривая промахи как шум, что делает его полезным для нерегулярных распределений данных.
Принципиальный компонентный анализ (PCA): Техника уменьшения размерности, которая преобразует данные в более низкоразмерное пространство с сохранением дисперсии.
Автоэнкодеры: Тип нейронной сети, которая обучается сжатым представлениям данных для обнаружения аномалий и извлечения признаков.
Association Rule Mining: Выявляет связи между элементами в наборе данных, обычно используется при анализе рыночной корзины.
Алгоритм Априори:** Метод поиска частых шаблонов, который находит взаимосвязи между элементами путем итеративного определения наборов частых элементов.
FP-Growth Algorithm: Более эффективная альтернатива Apriori, использующая древовидную структуру (FP-tree) для извлечения частых шаблонов с меньшими вычислениями.
3. Полуподконтрольное обучение
Полуподконтрольное обучение - это гибридный подход, при котором небольшое количество меченых данных сочетается с большим количеством немеченых данных для повышения точности обучения. Этот метод полезен, когда маркировка данных стоит дорого или требует много времени.
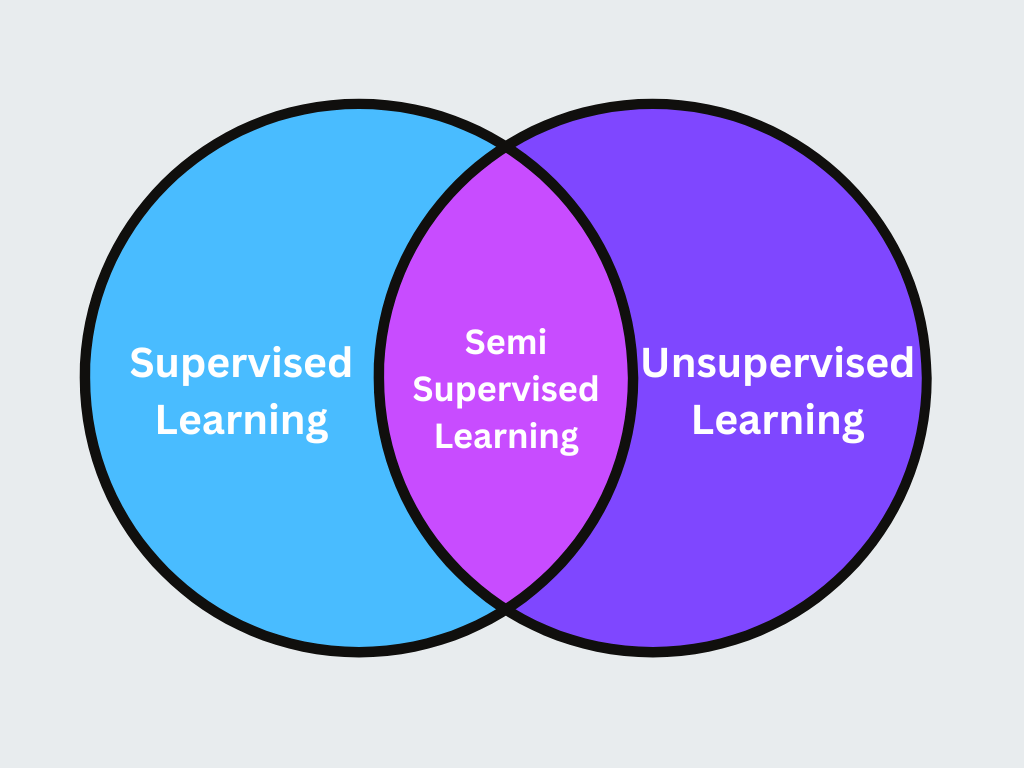 Рисунок - Полуподчиненное обучение.png
Рисунок - Полуподчиненное обучение.png
Иллюстрация: Полуподконтрольное обучение
Самообучение:** Модель первоначально обучается на помеченных данных, затем делает предсказания на немеченых данных, добавляя высокодостоверные предсказания в набор помеченных данных для дальнейшего обучения.
Полунаблюдаемое обучение на основе графов: Оно использует графовые структуры для распространения меток через сеть связанных точек данных, что широко используется в рекомендательных системах.
Генеративные адверсарные сети (GANs): GANs генерируют новые помеченные образцы для улучшения обучения в сценариях с низким количеством меток, что делает их полезными в распознавании изображений и речи.
Регуляризация согласованности:** Гарантирует, что предсказания модели остаются согласованными даже при незначительных изменениях входных данных, повышая устойчивость полуподконтрольного обучения.
4. Обнаружение аномалий и анализ выбросов
Обнаружение аномалий позволяет выявить точки данных, которые значительно отклоняются от нормальных закономерностей. Эти алгоритмы широко используются в обнаружении мошенничества, кибербезопасности и обнаружении промышленных неисправностей.
 Рисунок - Обнаружение аномалий
Рисунок - Обнаружение аномалий
** Рисунок:** Обнаружение аномалий
Метод Z-Score:** Обнаруживает промахи, измеряя, на сколько стандартных отклонений точка отклоняется от среднего значения.
Интерквартильный размах (IQR):** Выявляет промахи, анализируя диапазон между первым и третьим квартилями, отмечая экстремальные значения.
Isolation Forest: Модель на основе дерева, которая быстрее изолирует аномалии за счет случайного разбиения точек данных.
Локальный фактор выбросов (LOF): Измеряет относительную плотность точек данных для выявления аномалий в наборе данных.
Одноклассовая SVM: Разновидность SVM, предназначенная для обнаружения отклонений от класса большинства, обычно используется для выявления мошенничества.
Обнаружение аномалий на основе автоэнкодера: Использует глубокое обучение для реконструкции входных данных, отмечая аномалии при высокой ошибке реконструкции.
Применение Data Mining в различных отраслях
Добыча данных используется в различных отраслях для анализа больших массивов данных, выявления закономерностей и улучшения процесса принятия решений. Ниже приведены примеры использования в конкретных отраслях:
1. Финансы
Обнаружение мошенничества: Банки используют интеллектуальный анализ данных для анализа моделей транзакций и обнаружения подозрительных действий, таких как необычное поведение при расходовании средств или несколько неудачных попыток входа в систему.
Кредитный скоринг и оценка рисков: Финансовые учреждения оценивают степень риска заемщика, анализируя кредитную историю, уровень доходов и предыдущие выплаты по кредитам.
Алгоритмическая торговля: Инвестиционные компании используют предиктивную аналитику для анализа рыночных тенденций и автоматизации стратегий высокочастотной торговли.
2. Здравоохранение
Прогнозирование и диагностика заболеваний:** Больницы анализируют истории болезни и симптомы, чтобы предсказывать заболевания на ранних стадиях, улучшая планы лечения и сокращая количество госпитализаций.
Открытие и разработка лекарств: Фармацевтические компании используют интеллектуальный анализ данных для выявления потенциальных кандидатов на лекарства, анализируя генетические данные и данные клинических испытаний.
Прогнозирование повторной госпитализации:** Медицинские учреждения анализируют историю болезни пациентов, чтобы предсказать вероятность повторной госпитализации и принять профилактические меры.
3. Электронная коммерция и розничная торговля
Персонализированные рекомендации: Интернет-магазины анализируют историю посещений и покупок клиентов, чтобы предложить индивидуальные рекомендации по товарам.
Динамические стратегии ценообразования: Платформы электронной коммерции корректируют цены в зависимости от спроса, цен конкурентов и поведения покупателей.
Прогнозирование оттока покупателей:** Розничные компании используют анализ данных для выявления клиентов, которые могут уйти, и направляют им специальные предложения для повышения уровня удержания.
4. Кибербезопасность
Системы обнаружения вторжений (IDS):** Организации используют анализ данных для обнаружения необычной сетевой активности, например попыток несанкционированного доступа или заражения вредоносным ПО.
Анализ угроз и оценка рисков: Команды безопасности анализируют исторические данные об атаках, чтобы предсказать и предотвратить будущие киберугрозы.
Обнаружение фишинга и мошенничества: Модели машинного обучения выявляют попытки фишинга, анализируя шаблоны электронной почты, URL-адреса и поведение отправителей.
5. Производство и промышленный IoT
Предиктивное обслуживание: Фабрики анализируют данные датчиков машин, чтобы предсказывать поломки до их возникновения, сокращая время простоя и расходы на ремонт.
Оптимизация цепочки поставок: Производители используют интеллектуальный анализ данных для прогнозирования колебаний спроса, оптимизации запасов и сокращения отходов.
Контроль качества и обнаружение дефектов: Анализ данных помогает выявлять производственные дефекты на ранней стадии, обнаруживая аномалии в производственных процессах.
6. Телекоммуникации
Оптимизация сети: Телекоммуникационные компании анализируют схемы использования сети, чтобы оптимизировать распределение полосы пропускания и уменьшить перегрузку.
Сегментация и удержание клиентов: Операторы классифицируют клиентов на основе их поведения при использовании и предлагают индивидуальные планы для улучшения удержания.
Обнаружение спама и робозвонков: Методы интеллектуального анализа данных помогают отфильтровывать спам-звонки и сообщения на основе моделей звонков и сообщений пользователей.
7. Энергетика и коммунальные услуги
Прогнозирование энергопотребления:** Энергетические компании анализируют прошлые модели потребления, чтобы предсказать будущий спрос и оптимизировать работу сети.
Обнаружение неисправностей в электросетях: Датчики следят за линиями электропередачи и обнаруживают аномалии, чтобы предотвратить отключения и улучшить техническое обслуживание.
Аналитика умных счетчиков: Поставщики коммунальных услуг используют анализ данных для выявления необычных моделей энергопотребления и потенциального хищения энергии.
8. Образование
Прогнозирование успеваемости учащихся: Школы анализируют данные об учащихся, чтобы выявить учеников из группы риска и предоставить им индивидуальную поддержку в обучении.
Адаптивные системы обучения: Образовательные платформы используют анализ данных для персонализации учебных материалов на основе сильных и слабых сторон учащихся.
Системы рекомендации курсов: Университеты анализируют успеваемость студентов, чтобы рекомендовать им подходящие курсы с учетом интересов и карьерных целей.
Преимущества добычи данных
Обнаружение скрытых закономерностей: Помогает компаниям и исследователям обнаружить в необработанных данных не очевидные сразу выводы.
Улучшает процесс принятия решений: Предоставляет основанные на данных сведения, которые повышают точность стратегического планирования и прогнозирования.
Автоматизированный анализ тенденций: Этот инструмент выявляет тенденции и сдвиги в поведении потребителей, состоянии рынка и финансовых закономерностях без ручного вмешательства.
Увеличение персонализации клиентов: Обеспечивает высокоцелевой маркетинг за счет анализа предпочтений клиентов и их прошлых взаимодействий.
Оптимизация бизнес-операций: Повышает эффективность цепочки поставок, сокращает количество отходов и повышает производительность за счет прогнозирования спроса и потребностей в ресурсах.
Улучшение диагностики в здравоохранении: Помогает выявлять заболевания на ранних стадиях и составлять индивидуальные планы лечения, анализируя данные о пациентах.
Ускоряет научные исследования: Ускоряет открытие лекарств, генетический анализ и моделирование климата благодаря быстрому анализу огромных массивов данных.
Как Milvus помогает в добыче данных?
Добыча данных часто требует анализа огромных объемов структурированных и неструктурированных данных для обнаружения значимых закономерностей. Традиционные реляционные базы данных плохо справляются с высокоразмерными и неструктурированными данными, что делает их неэффективными для современных приложений, таких как рекомендательные системы, обнаружение аномалий и семантический поиск. Milvus, векторная база данных с открытым исходным кодом [https://zilliz.com/learn/what-is-vector-database], разработанная Zilliz **** инженерами, специально предназначена для работы с крупномасштабными, высокоразмерными данными, что делает ее мощным инструментом для задач интеллектуального анализа данных.
1. Работа с высокоразмерными данными
Современные приложения для добычи данных опираются на высокоразмерные данные, такие как изображения embeddings, текстовые представления и time-series data, для извлечения значимых выводов. Традиционные реляционные базы данных неэффективны при работе с такими типами данных, поскольку они предназначены для структурированных таблиц, а не для многомерных векторных представлений.
Milvus предоставляет специальную векторную базу данных для хранения и управления многомерными вкраплениями, что делает ее основным компонентом инфраструктуры для интеллектуального анализа данных.
Она поддерживает различные форматы данных, включая плотные и разреженные векторы, чтобы обеспечить гибкость для различных моделей машинного обучения и глубокого обучения.
Оптимизированные структуры векторного индексирования (такие как IVF, HNSW и PQ) повышают эффективность хранения данных, уменьшая избыточность и улучшая производительность запросов в больших наборах данных.
Возможности Batch processing и распараллеливания обеспечивают быструю вставку и извлечение миллионов векторов для приложений ИИ, требующих постоянного обновления.
**Например, компания, занимающаяся анализом видео, хранит в Milvus покадровые вкрапления, что обеспечивает эффективный поиск и извлечение информации на основе контента для автоматической маркировки и классификации видео.
2. Масштабируемость для приложений добычи больших данных
Для добычи больших данных требуются базы данных, которые могут масштабироваться с увеличением объемов информации. Milvus обеспечивает:
Cloud-native architecture для крупномасштабного развертывания в распределенных средах.
Эффективное использование ресурсов для экономичного выполнения запросов даже при работе с огромными массивами данных.
Легко интегрируется с конвейерами для добычи данных на основе ИИ, поскольку интегрирован с такими фреймворками машинного обучения, как TensorFlow, PyTorch и Hugging Face.
**Например, в геномике Milvus хранит и ищет вкрапления последовательностей ДНК, помогая исследователям быстро находить генетическое сходство в миллионах записей.
3. Эффективный поиск по семантике и сходству
Семантический и поиск по сходству необходимы для современных приложений интеллектуального анализа данных, в которых используются неструктурированные данные, такие как изображения, текст и мультимедиа. В отличие от традиционного поиска по ключевым словам, поиск по сходству опирается на векторные вложения для получения наиболее релевантных результатов, основанных на значении, а не на точном совпадении.
Milvus обеспечивает высокопроизводительный поиск по сходству за счет использования векторных вкраплений. Это позволяет пользователям находить результаты на основе контекста, а не точных слов.
Он поддерживает алгоритмы поиска Approximate Nearest Neighbor (ANN), такие как HNSW, IVF и PQ, для ускорения поиска в больших массивах данных.
Возможности мультимодального поиска позволяют осуществлять междоменный поиск по тексту, изображениям и видео, что делает его идеальным для рекомендательных систем, поиска контента и приложений NLP.
**Например, система поиска юридических документов может использовать Milvus для извлечения прецедентов на основе семантического значения, а не просто совпадения ключевых слов, что повышает точность юридических исследований.
Заключение
Добыча данных - это трансформационный процесс, который превращает огромные массивы данных в действенные идеи, стимулируя инновации в финансовой и медицинской отраслях. Организации могут выявлять скрытые закономерности, оптимизировать операции и принимать решения на основе данных, используя такие передовые методы, как контролируемое и неконтролируемое обучение, обнаружение аномалий и поиск частых шаблонов. Milvus расширяет эти возможности, предоставляя надежную платформу для хранения и поиска высокоразмерных данных, обеспечивая эффективный семантический поиск и поиск по сходству. Способность легко масштабироваться с приложениями для работы с большими данными делает его бесценным инструментом для решения современных задач интеллектуального анализа данных.
Часто задаваемые вопросы о добыче данных
**1. Какие основные методы используются в добыче данных?
При добыче данных используются различные методы, включая контролируемое обучение (деревья решений, SVM, нейронные сети), неконтролируемое обучение (кластеризация, поиск ассоциативных правил), обнаружение аномалий и поиск частых шаблонов (Apriori, FP-Growth). Каждая из этих методик помогает извлекать значимые сведения из больших массивов данных.
**2. Чем добыча данных отличается от традиционного анализа данных?
Традиционный анализ данных опирается на предопределенные запросы и человеческую интерпретацию, в то время как добыча данных использует автоматизированные алгоритмы для выявления скрытых закономерностей, тенденций и взаимосвязей в данных. Кроме того, анализ данных более масштабируем, что делает его пригодным для работы с большими данными и приложениями искусственного интеллекта.
**3. Каковы самые большие проблемы в области добычи данных?
К основным проблемам добычи данных относятся обработка зашумленных и неполных данных, обеспечение конфиденциальности и безопасности данных, управление вычислительной сложностью и масштабирование на огромные массивы данных. Эффективная предварительная обработка и использование передовых моделей искусственного интеллекта помогают решить эти проблемы.
4. Как добыча данных используется в реальных приложениях?
Анализ данных широко используется для выявления мошенничества в банковской сфере, рекомендательных систем в электронной коммерции, предиктивного обслуживания в производстве, диагностики заболеваний в здравоохранении и обнаружения угроз кибербезопасности. Он помогает организациям оптимизировать процесс принятия решений и автоматизировать процессы.
5. Какую роль в добыче данных играют векторные базы данных?
Векторные базы данных, такие как Milvus, помогают эффективно хранить и извлекать высокоразмерные данные, ускоряя поиск сходства, кластеризацию и обнаружение аномалий. Эти базы данных полезны для приложений, основанных на искусственном интеллекте, таких как распознавание изображений, обработка естественного языка и рекомендательные системы.
Связанные ресурсы
- Что такое добыча данных?
- Как работает добыча данных?
- Методы и алгоритмы добычи данных
- Применение Data Mining в различных отраслях
- Преимущества добычи данных
- Как Milvus помогает в добыче данных?
- Заключение
- Часто задаваемые вопросы о добыче данных
- Связанные ресурсы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно