




Подробное руководство по бенчмаркам ANN: оценка производительности поиска приближенных ближайших соседей (ANNS)
Подробное руководство по бенчмаркам ANN: оценка производительности поиска приближенных ближайших соседей (ANNS)
Представьте, что вы создаете поисковую систему, которой нужно быстро находить наиболее похожие элементы в базе данных, содержащей миллиарды изображений, текстовых документов или других неструктурированных данных. Как убедиться, что ваш поисковый алгоритм не только возвращает точные результаты, но и делает это с молниеносной скоростью? Здесь на помощь приходит поиск приближенных ближайших соседей (ANN). Поиск ANN имеет решающее значение во многих реальных приложениях — от рекомендательных систем до крупномасштабного поиска изображений.
При таком количестве решений для поиска ANN, доступных на рынке, как нам оценить эффективность различных алгоритмов ANN, особенно в масштабе? Здесь появляются бенчмарки ANN, которые стали золотым стандартом для тестирования производительности методов поиска ANN на больших наборах данных.
В этом блоге мы рассмотрим бенчмарки ANN, почему они важны и как они помогают разработчикам и инженерам алгоритмов выбирать подходящие решения для векторного поиска под конкретную задачу. Мы также рассмотрим некоторые из самых популярных бенчмарков, используемых сегодня, и то, что делает их важными в векторном поиске.
Что такое поиск ANN и как он работает?
Прежде чем перейти к бенчмаркам, важно понять поиск Approximate Nearest Neighbor (ANN), или ANNS, и то, как он работает. Поиск ANN — это мощная техника в машинном обучении (ML), которая позволяет эффективно выполнять поиск по семантическому сходству в больших наборах данных, часто встречающихся в векторных базах данных, таких как Zilliz Cloud. Он может быстро находить элементы в наборе данных, наиболее близкие к заданному элементу запроса. В отличие от методов точного поиска, которые обеспечивают 100% точность, ANNS жертвует небольшой долей точности ради значительного повышения скорости и масштабируемости.
Как работает поиск ANN:
Представление данных: Каждый элемент в наборе данных представлен в виде вектора в многомерном пространстве. Векторы обычно кодируются моделью эмбеддингов, такой как модели текстовых эмбеддингов OpenAI, многоязычные модели Cohere и мультимодальные модели OpenAI. Например, изображение может быть представлено как вектор признаков, таких как цвет или форма, в 128-мерном пространстве.
Обработка запроса: Когда выполняется запрос, алгоритм поиска ANN извлекает из набора данных векторы, близкие к вектору запроса, используя аппроксимации для ускорения процесса.
Ранжирование результатов: Алгоритм ранжирует ближайших соседей на основе их расстояния от запроса в высокоразмерном пространстве, часто используя такие метрики, как евклидово расстояние или косинусное сходство. Чем ближе расположены векторы, тем более похожими и релевантными они являются.
Эффективность: Ключевое преимущество поиска ANN — его способность выдавать результаты за долю времени, которое потребовалось бы для точного поиска, что делает его идеальным для крупномасштабных наборов данных.
Методы ANNS используют различные стратегии для быстрой аппроксимации ближайших соседей:
Методы на основе деревьев: Такие техники, как KD-Trees и Ball Trees, организуют данные иерархически, чтобы упростить процесс поиска. Хотя они эффективны в пространствах низкой размерности, их производительность снижается по мере увеличения размерности.
Методы хеширования: Locality-sensitive hashing (LSH) группирует похожие точки данных в одни и те же хеш-бакеты, уменьшая количество сравнений, необходимых во время поиска.
Методы на основе графов: Алгоритмы, такие как графы Navigable Small World (NSW) и Hierarchical Navigable Small World (HNSW), создают сети точек данных для ускорения поиска соседей.
Методы квантования: Такие техники, как Product Quantization (PQ), сжимают данные в более управляемую форму, повышая эффективность поиска.
Используя эти методы, алгоритмы ANNS могут обеспечивать баланс между точностью поиска и производительностью, что делает их подходящими для крупномасштабных наборов данных.
Поиск ANN и поиск KNN
Точный поиск K-nearest neighbor (KNN) и Approximate Nearest Neighbor Search (ANNS) — это два фундаментальных подхода, используемых в векторном поиске, каждый со своими преимуществами и компромиссами.
Точный KNN предоставляет точные результаты, оценивая расстояние между точкой запроса и каждой точкой данных в наборе данных, гарантируя, что найденные соседи являются максимально близкими. Однако этот метод может быть вычислительно затратным и медленным из-за своей природы полного перебора, особенно при работе с большими наборами данных или пространствами высокой размерности. Это делает точный KNN подходящим для небольших наборов данных или сценариев, где точность имеет первостепенное значение, а вычислительные ресурсы вызывают меньшую озабоченность.
В отличие от него, ANNS предлагает практическое решение для обработки крупномасштабных данных, жертвуя некоторой степенью точности ради более высокой производительности. ANNS использует различные алгоритмы и техники, такие как древовидные структуры, методы хеширования и подходы на основе графов, чтобы эффективно приближенно находить ближайших соседей. Этот подход значительно снижает вычислительные затраты и хорошо масштабируется на массивные наборы данных, что делает его идеальным для приложений реального времени, таких как поисковые системы и рекомендательные системы, где скорость имеет решающее значение. Хотя ANNS не всегда может предоставлять точно самых близких соседей, его способность быстро выдавать почти точные результаты делает его ценным инструментом в современных задачах поиска и анализа данных.
Для получения дополнительной информации см. нашу страницу глоссария ANNS.
Что такое ANN Benchmark?
ANN Benchmark — это комплексный инструмент оценки, предназначенный для измерения и сравнения производительности различных алгоритмов ANNS. Размещенный на ann-benchmarks.com, он предоставляет стандартизированные тесты и метрики для оценки различных аспектов методов ANNS, включая:
Скорость поиска: Насколько быстро алгоритм может находить ближайших соседей.
Точность: Степень, в которой результаты алгоритма приближаются к истинным ближайшим соседям.
Масштабируемость: Насколько хорошо алгоритм работает по мере увеличения размера набора данных или размерности.
Этот бенчмарк предлагает набор различных датасетов и критериев оценки, позволяя разработчикам оценивать эффективность разных алгоритмов в различных условиях на равных основаниях.
Ключевые метрики в ANN Benchmarks:
Recall: Процент истинных ближайших соседей, успешно извлеченных алгоритмом. Высокий recall указывает на лучшую точность.
Время поиска: Время, необходимое алгоритму для возврата результата. Более быстрое время поиска критически важно для приложений, требующих ответов в реальном времени.
Использование памяти: Объем памяти, необходимый алгоритму для хранения и поиска в наборе данных. Эффективное использование памяти важно для масштабируемости.
Масштабируемость: Способность алгоритма сохранять производительность по мере увеличения размера набора данных. Масштабируемость является критически важным фактором в реальных приложениях, где наборы данных могут быстро расти.
Ключевые наборы данных, используемые в ANN Benchmarks
ANN Benchmark использует разнообразные наборы данных для тестирования алгоритмов. Эти наборы данных охватывают ряд областей, таких как признаки изображений, текстовые эмбеддинги и синтетические данные. Ключевые наборы данных, используемые в бенчмарках, включают:
| Набор данных | Размерности | Размер обучающей выборки | Размер тестовой выборки | Соседи | Расстояние | Скачать |
|---|---|---|---|---|---|---|
| DEEP1B | 96 | 9,990,000 | 10,000 | 100 | Угловое | HDF5 (3.6GB) |
| Fashion-MNIST | 784 | 60,000 | 10,000 | 100 | Евклидово | HDF5 (217MB) |
| GIST | 960 | 1,000,000 | 1,000 | 100 | Евклидово | HDF5 (3.6GB) |
| GloVe | 25 | 1,183,514 | 10,000 | 100 | Угловое | HDF5 (121MB) |
| GloVe | 50 | 1,183,514 | 10,000 | 100 | Угловое | HDF5 (235MB) |
| GloVe | 100 | 1,183,514 | 10,000 | 100 | Угловое | HDF5 (463MB) |
| GloVe | 200 | 1,183,514 | 10,000 | 100 | Угловое | HDF5 (918MB) |
| Kosarak | 27,983 | 74,962 | 500 | 100 | Жаккар | HDF5 (33MB) |
| MNIST | 784 | 60,000 | 10,000 | 100 | Евклидово | HDF5 (217MB) |
| MovieLens-10M | 65,134 | 69,363 | 500 | 100 | Жаккар | HDF5 (63MB) |
| NYTimes | 256 | 290,000 | 10,000 | 100 | Угловое | HDF5 (301MB) |
| SIFT | 128 | 1,000,000 | 10,000 | 100 | Евклидово | HDF5 (501MB) |
| Last.fm | 65 | 292,385 | 50,000 | 100 | Угловое | HDF5 (135MB) |
Протестированные ANN-алгоритмы или векторные поисковые системы
ANN Benchmarks оценили широкий спектр ANN-алгоритмов и векторных поисковых систем, включая Annoy, Faiss, Knowhere (поисковую систему Milvus) и Glass (устаревшую поисковую систему Zilliz Cloud). Количество протестированных алгоритмов продолжает расти. Ниже приведен список алгоритмов и поисковых систем, протестированных по состоянию на сентябрь 2024 года.
scikit-learn: LSHForest, KDTree, BallTree
NMSLIB (Non-Metric Space Library) : SWGraph, HNSW, BallTree, MPLSH
NGT : ONNG, PANNG, QG
Elasticsearch : HNSW
DiskANN : Vamana, Vamana-PQ
scipy: cKDTree
Примечание: Zilliz Cloud запустила новую поисковую систему под названием Cardinal, которая обеспечивает в три раза более высокую производительность по сравнению с устаревшим движком Glass и предлагает пропускную способность поиска (QPS) до десяти раз выше, чем у Milvus. Однако из-за ограничений по времени и других факторов производительность Cardinal не включена в результаты ANN-бенчмарка. В следующем разделе вы можете изучить ее производительность с помощью VectorDBBench.
Результаты бенчмарка
График ниже демонстрирует результаты тестирования полноты/количества запросов в секунду для различных алгоритмов на основе набора данных GIST1M (1 млн векторов с 960 измерениями). Он отображает уровень полноты по оси x и QPS по оси y, иллюстрируя производительность каждого алгоритма при разных уровнях точности поиска.
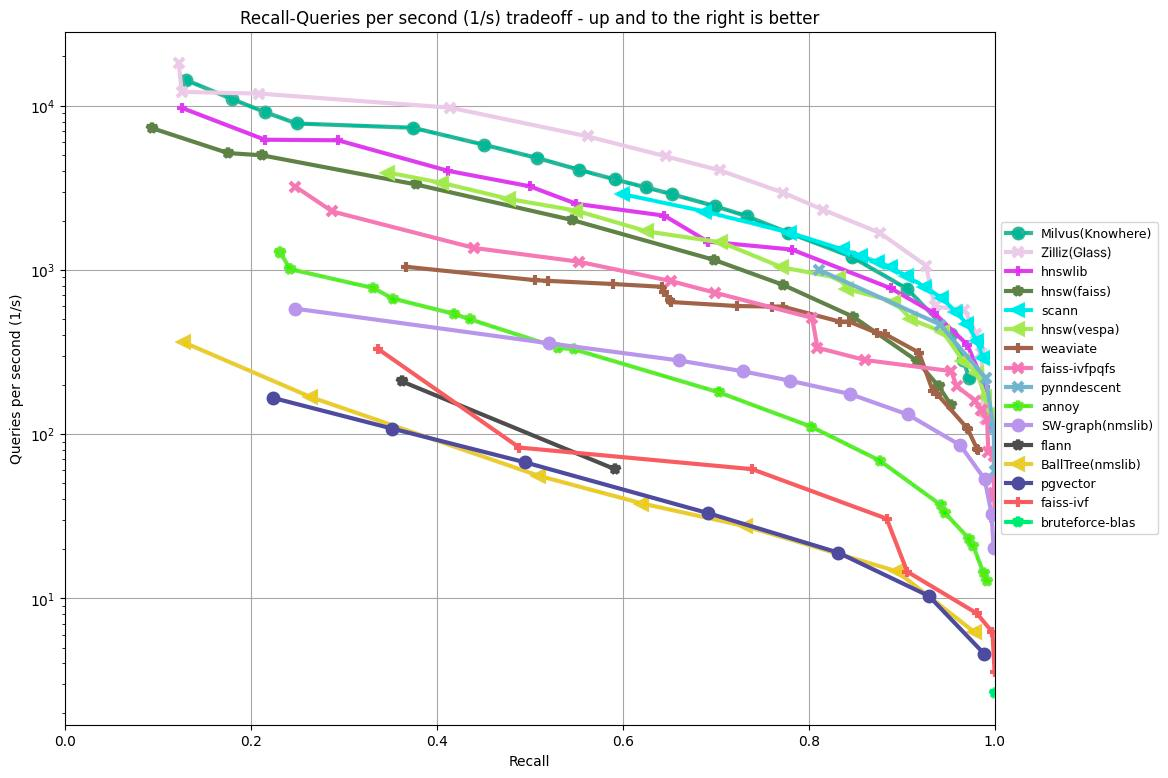 Рисунок 1: результаты ANN Benchmark на наборе данных GIST1M
Рисунок 1: результаты ANN Benchmark на наборе данных GIST1M
Рисунок 1: результаты ANN Benchmark на наборе данных GIST1M
Согласно результатам, показанным на графике выше, библиотеки Knowhere (поисковый движок Milvus), Glass (устаревший поисковый движок Zilliz Cloud) и HNSW показали три лучших результата при обработке 1 000 000 векторов с 960 измерениями.
Дополнительные результаты бенчмаркинга см. на сайте ANN-Benchmark.
VectorDBBench: инструмент бенчмаркинга с открытым исходным кодом для векторных баз данных
Векторный поиск, или поиск векторного сходства, — это более широкое понятие, которое относится к процессу нахождения похожих векторов в наборе данных. ANNS представляет собой набор алгоритмов, обеспечивающих векторный поиск. Векторные базы данных — это специализированные решения для эффективного поиска векторного сходства.
Хотя ANN-Benchmark чрезвычайно полезен для выбора и сравнения различных алгоритмов векторного поиска, он не предоставляет всестороннего обзора векторных баз данных. Мы также должны учитывать такие факторы, как потребление ресурсов, емкость загрузки данных и стабильность системы. Кроме того, ANN Benchmark упускает многие распространенные сценарии, такие какфильтрованный векторный поиск.
Для решения таких задач разработчики Zilliz предложили VectorDBBench, инструмент сравнительного тестирования с открытым исходным кодом, предназначенный для векторных баз данных с открытым исходным кодом, таких как Milvus и Weaviate, а также полностью управляемых сервисов, таких как Zilliz Cloud и Pinecone. Поскольку многие полностью управляемые сервисы векторного поиска не раскрывают свои параметры для пользовательской настройки, VectorDBBench отображает QPS и показатели recall отдельно.
Приведенные ниже диаграммы демонстрируют результаты тестирования QPS и показателя recall различных популярных векторных баз данных при обработке 1 000 000 векторов с 768 измерениями.
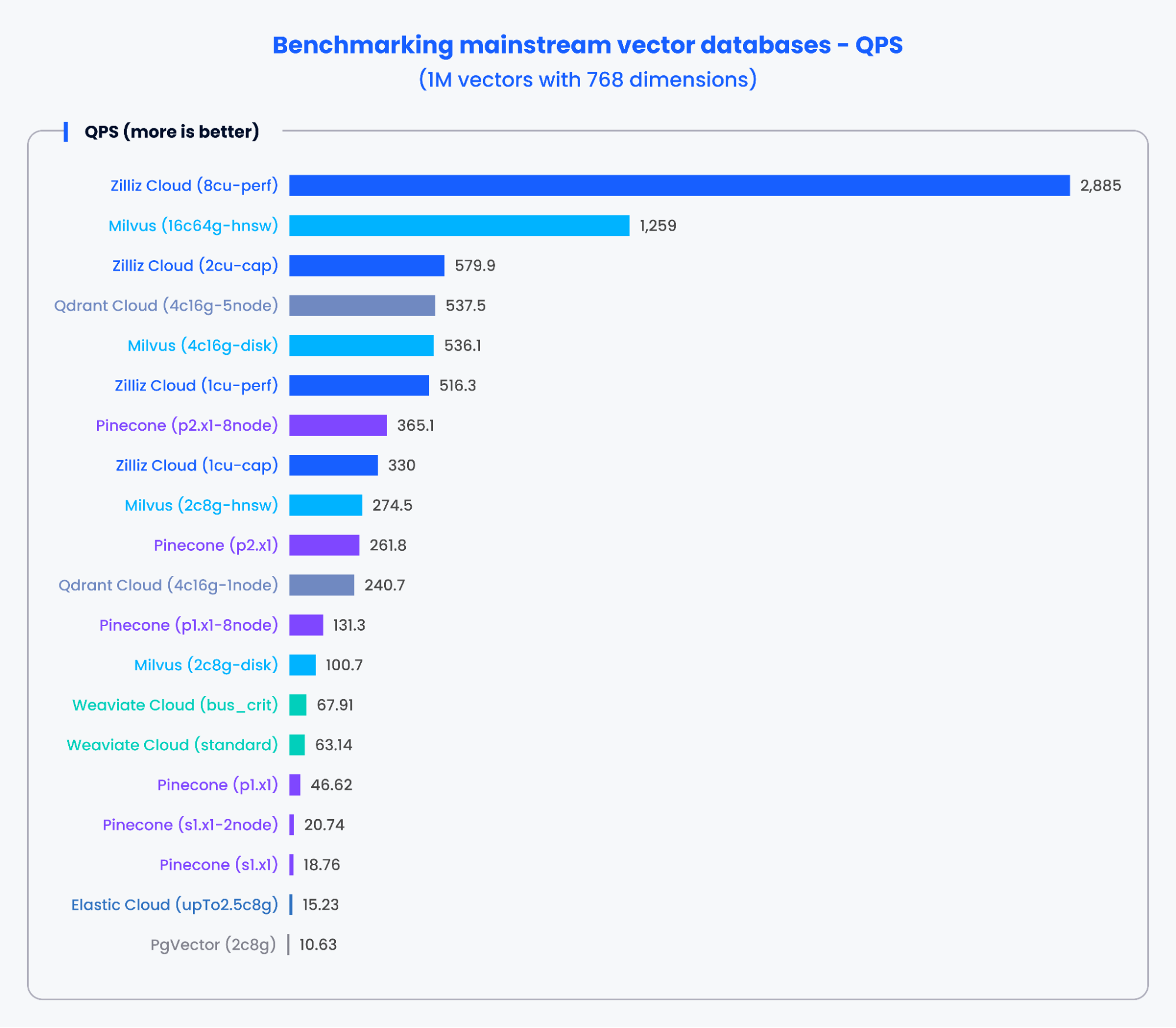 Рисунок 2: Результаты бенчмарка для QPS
Рисунок 2: Результаты бенчмарка для QPS
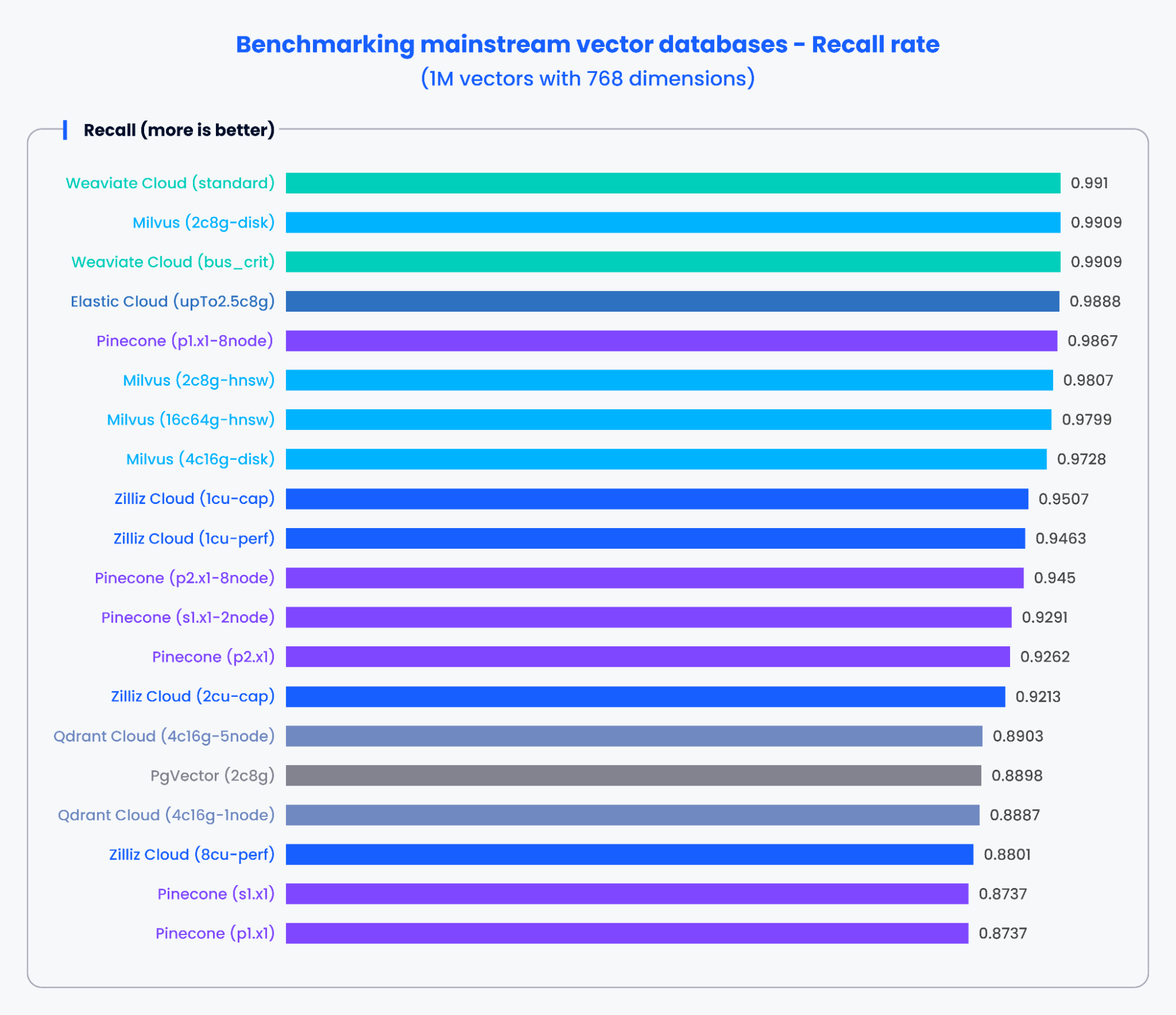 Рисунок 3: Результаты бенчмарка для показателя recall
Рисунок 3: Результаты бенчмарка для показателя recall
Судя по результатам на диаграммах выше, специализированные векторные базы данных, такие как Milvus и Zilliz, продемонстрировали выдающуюся производительность как по QPS, так и по показателям recall. Эти результаты показывают, что специализированные векторные базы данных могут быстро обрабатывать огромные объемы данных и извлекать более точные результаты. Напротив, надстройки векторного поиска на базе традиционных баз данных показали более низкую производительность.
Загрузите VectorDBBench из его репозитория GitHub, чтобы воспроизвести наши результаты бенчмарка или получить результаты производительности на собственных наборах данных.
Таблица лидеров VectorDBBench
VectorDBBench также предлагает специальную страницу таблицы лидеров, предназначенную для упрощения представления результатов тестирования и предоставления подробного отчета об анализе производительности. Эта таблица лидеров позволяет выбирать ключевые метрики, такие как Queries Per Second (QPS), метрики Query Price ($) и задержку, для комплексной оценки производительности.
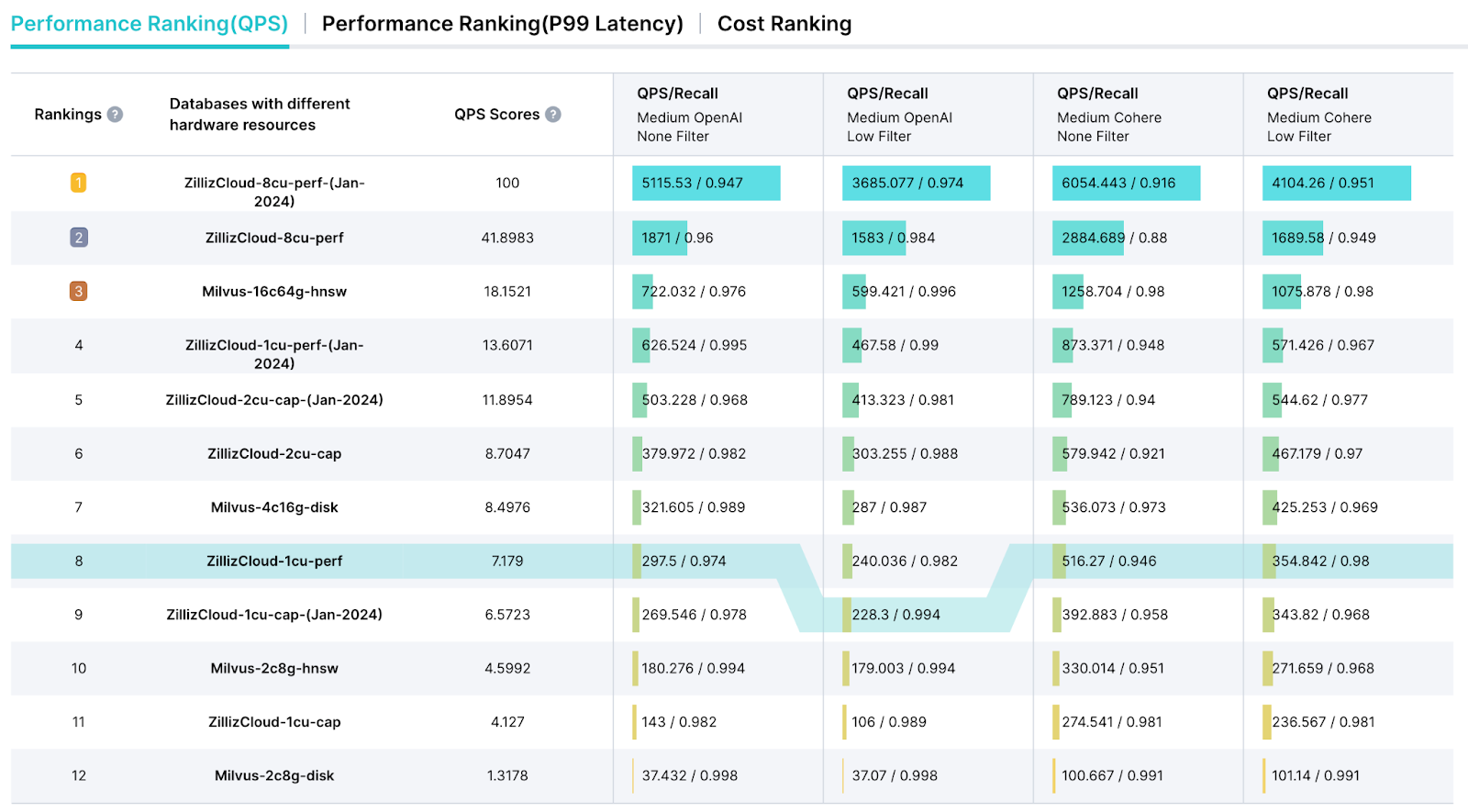 скриншот таблицы лидеров vectordbbench
скриншот таблицы лидеров vectordbbench
Рисунок 4: Скриншот таблицы лидеров VectorDBBench
ANN Benchmarks и VectorDBBench
ANN Benchmarks оценивают алгоритмы векторных индексов, помогая выбирать и сравнивать различные библиотеки векторного поиска. Однако они не подходят для оценки сложных и зрелых векторных баз данных и упускают такие ситуации, как фильтрованный векторный поиск.
Инженеры Zilliz создали VectorDB Bench, чтобы он был адаптирован для комплексной оценки векторных баз данных. Он учитывает важные факторы, такие как потребление ресурсов, емкость загрузки данных и стабильность системы. Разделяя тестовый клиент и векторную базу данных и обеспечивая независимое развертывание, VectorDB Bench позволяет проводить тестирование, которое максимально точно имитирует реальные производственные среды.
Факторы, влияющие на оценку производительности
На производительность векторной базы данных или алгоритма ANN влияет несколько факторов, включая набор данных, сетевые условия и конфигурацию базы данных.
Сеть
Сетевые условия имеют критическое значение. Задержка может замедлять ответы на запросы, тогда как ограниченная пропускная способность влияет на скорость передачи данных. Стабильность сети также важна, поскольку колебания могут вызывать нестабильную производительность.
Наборы данных
Размер набора данных влияет на использование памяти и диска — более крупные наборы данных требуют больше ресурсов. Размерность векторов влияет на сложность операций и время выполнения запросов. Распределение данных и структура индексирования (например, иерархическая, плоская) также влияют на эффективность и точность поиска.
Конфигурация базы данных
Параметры индекса (например, количество деревьев) и настройки поиска (например, ближайшие соседи) напрямую влияют на эффективность и скорость извлечения. Кэширование может улучшить время отклика для часто используемых данных.
Факторы среды
Операционная система и фоновые процессы могут влиять на доступность ресурсов и отзывчивость системы, сказываясь на общей производительности.
Учет этих факторов помогает понять и оптимизировать производительность вашей векторной базы данных.
Дополнительные ресурсы
- Что такое поиск ANN и как он работает?
- Что такое ANN Benchmark?
- VectorDBBench: инструмент бенчмаркинга с открытым исходным кодом для векторных баз данных
- ANN Benchmarks и VectorDBBench
- Факторы, влияющие на оценку производительности
- Дополнительные ресурсы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно