




Introducing Cardinal: The Most Performant Engine For Vector Searches
This post is written by Alexandr Guzhva and Li Liu.
In databases, 'performance' is a critical metric, especially in vector databases. It is pivotal in efficiently processing a high volume of user requests within limited resources. While access latency might not be a concern in some situations, for a vector database, performance remains essential for various reasons.
Vector search, reliant on Approximate Nearest Neighbor Search (ANNS), may trade a slight degree of accuracy for enhanced performance. Improved performance, in turn, allows for greater precision.
Outstanding performance, maintained under a consistent query latency, facilitates higher throughput using the same resources, accommodating a larger user base.
Moreover, improved performance translates to the need for fewer computational resources to support identical usage scenarios.
Vector databases are inherently computation-intensive, with a significant portion of resource usage—often exceeding 80%—dedicated to vector distance calculations. As a result, the vector search engine, responsible for handling vector search tasks, becomes a critical factor in determining the overall performance of a vector database.
Zilliz consistently prioritizes the enhancement of vector database performance. The open-source Milvus and the fully managed Zilliz Cloud demonstrate superior performance compared to similar products. The Milvus vector search engine Knowhere, plays a significant role in achieving this success by laying a foundation for a new search engine.
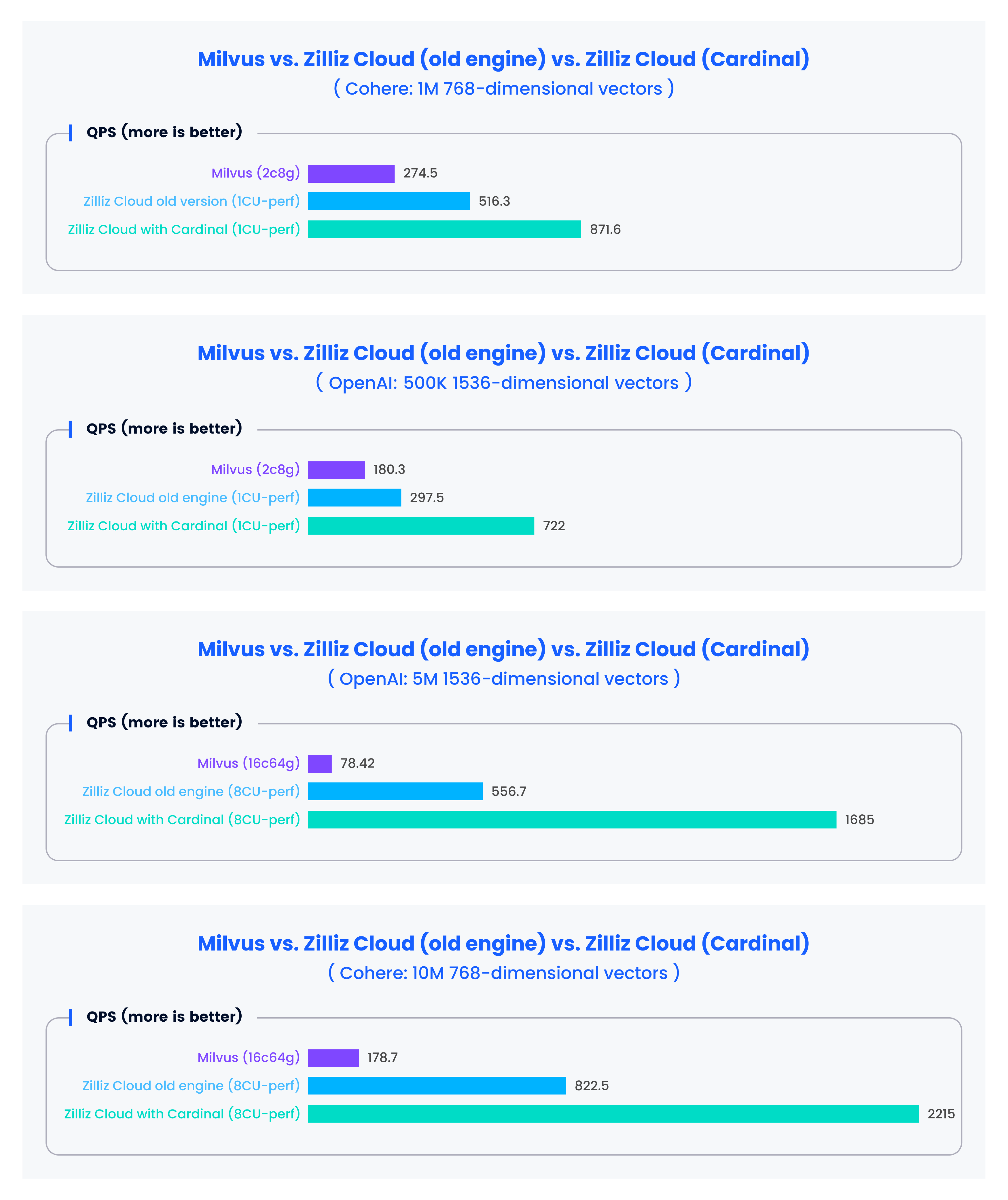
At the heart of the latest release of Zilliz Cloud is Cardinal, a new vector search engine we built. This search engine has already demonstrated a threefold increase in performance compared to the previous version, offering a search performance (QPS) that reaches tenfold that of Milvus.
We evaluated the latest Zilliz Cloud's performance through the open-source vector database benchmark tool and compared its performance with Milvus and Zilliz Cloud with an old engine. The evaluation results are shown in the charts below.
What is Cardinal?
Cardinal is a proprietary multi-threaded modern C++ template-based vector search engine that implements the most practical and widely used ANNS methods. Cardinal was designed and written from scratch to use available compute resources efficiently.
Cardinal is capable of:
performing brute-force search,
creating and modifying ANNS indices,
performing the index Top-K and index range search,
working with various input data formats, including FP32, FP16, and BF16,
working with in-memory data or with memory-mapped data,
filtering the results during the search based on user-provided criteria.
Cardinal includes:
An implementation of ANN methods that allow for easy configuration of various internal parameters. However, the default operating point is consistently tuned to maximize search speed (QPS, queries per second) while maintaining reasonable accuracy (recall rate).
Efficient implementation of various algorithms that support ANNS methods. For example, ones that provide sample filtering capabilities.
Low-level specialized optimized kernels for most compute-intensive operations used during the search or construction. Multiple hardware platforms are supported. Besides kernels that compute distances for various metrics, Cardinal also contains fused kernels and kernels for data preprocessing.
Supporting facilities, such as asynchronous operations, memory-mapped I/O capabilities, caching, memory allocators, logging, etc.
Knowhere vs Cardinal
The Knowhere library is an internal core of open-source Milvus, responsible for the vector search. Knowhere is based on patched versions of industry-standard open-sourced libraries, such as Faiss, DiskANN, and hnswlib.
Let us provide a comparison between Knowhere and Cardinal:
| Feature | Knowhere | Cardinal |
|---|---|---|
| Production-Readiness | Yes | Yes |
| Scalability Capabilities | Yes | Yes |
| Design Philosophy | Experimentation and Flexibility | Narrow in scope, prioritizing the enhancement of existing features for performance |
| Host Compatibility | All Host Types | Optimized for Zilliz Cloud Host Environment |
| Dependency | Relies on Well-known OSS Libraries and Implementations | Contains Non-trivial Modifications and Optimizations |
Both are production-ready and provide all the scalability capabilities that Milvus and Zilliz Cloud need.
Knowhere is designed with experimentation and flexibility in mind. Cardinal is narrower in scope, prioritizing the enhancement of existing features for improved speed and performance rather than introducing extensive new functionality.
Since Knowhere is open-source and may be deployed in many different environments, it runs on all host types. Cardinal is optimized for the Zilliz Cloud host environment.
Knowhere relies on well-known OSS libraries and implementations(such as Faiss, DiskANN, and hnswlib). Cardinal contains non-trivial modifications and optimizations.
What makes Cardinal so fast
Cardinal implements various algorithms-related, engineering, and low-level optimizations. Cardinal introduces the AUTOINDEX mechanism, which automatically selects the best search strategy and index for the dataset. This eliminates the need for manual tuning, saving developers’ time and effort.
Let’s dig into the details.
Algorithm optimizations
This form of optimization significantly enhances the accuracy and effectiveness of the search process, a multifaceted pipeline involving various algorithms working in tandem. Numerous algorithms within this pipeline can be refined to boost overall performance. Notable candidates for algorithm optimizations within Cardinal include:
Search algorithms, encompassing both IVF-based and graph-based approaches,
Algorithms designed to help the search maintain the required recall rate, irrespective of the percentage of filtered samples,
Advanced iterations of best-first search algorithms,
Customized algorithms for a priority queue data structure.
Parameterizable algorithms provide the flexibility for tradeoffs, such as balancing performance versus RAM usage. As a result, algorithm optimizations for Cardinal also involve selecting optimal operating points within the parameter space.
Engineering optimizations
While algorithms are initially designed with abstract Turing machines in mind, the real-world implementation faces challenges such as network latencies, cloud provider restrictions on IOPS, and limitations on machine RAM, a valuable yet finite resource.
Engineering optimizations ensure that Cardinal's vector search pipeline remains practical and aligns with compute, RAM, and other resource constraints. In Cardinal's development, we blend standard practices and innovative techniques. This approach enables the C++ compiler to generate computationally optimal compiled code while maintaining clean, benchmarkable, and easily extendable source code that facilitates the swift addition of new features.
Here are some examples of engineering practices implemented in Cardinal, showcasing specific optimizations:
Specialized memory allocators and memory pools,
Properly implemented multi-threaded code,
A hierarchical structure of components facilitating the combination of elements into various search pipelines,
Code customization for specific, critical use cases.
Low-level optimizations
Most of the search time is spent on relatively small pieces of code known as kernels. The simplest example is a kernel that computes L2 distance between two vectors.
Cardinal includes numerous compute kernels for different purposes, each written and optimized specifically for a specific hardware platform and use case.
Cardinal supports x86 and ARM hardware platforms, but other platforms can be easily added.
For the x86 platform, Cardinal kernels use AVX-512’s F, CD, VL, BW, DQ, VPOPCNTDQ, VBMI, VBMI2, VNNI, BF16 and FP16 extensions. Also, we are exploring the usage of a new AMX instruction set.
For the ARM platform, Cardinal kernels are available for both NEON and SVE instruction sets.
We ensure that Cardinal gets the most optimal code for the compute kernels. We do not just rely on a modern C++ compiler to do the job:
We use dedicated tools, such as Linux perf, to analyze hotspots and CPU metrics
We use machine code analysis tools, such as GodBolt Compiler Explorer and uiCA, to ensure the optimal use of hardware ‘resources’, such as the number of RAM/cache accesses, used CPU instructions, registers, compute ports.
We use an iterative approach that interleaves the design, the benchmarking, the profiling, and the assembler code analysis stages.
A properly optimized compute kernel may provide 2x or 3x times speedup compared to a naive but unoptimized kernel. This may further translate into a 2x higher QPS value or 20% lower memory requirements on a cloud host machine.
AutoIndex: search strategy selection
Vector search is a complex process involving many independent components, including quantization, index building, search algorithms, data structures, and more. Each component has a multitude of adjustable parameters. Together, they form a highly varied range of vector search strategies, and different datasets and scenarios require different search strategies.
To better tap into the potential for performance improvement, Cardinal, in addition to supporting multiple strategies in each component, has implemented a set of AI-based dynamic strategy selection mechanisms known as AUTOINDEX. It adaptively chooses the most suitable strategy based on the distribution of the given dataset, the provided query, and the hardware configuration. This helps us achieve optimal performance while meeting users' demands for search quality.
Cardinal benchmark
We have adopted the ANN-benchmarks to support Cardinal in our testing environment. ANN benchmarks is a standard benchmarking tool for evaluating ANNS implementations, and it is run on several standard datasets which use different distance metrics. Every performance evaluation is conducted inside a docker container restricted to a single thread usage. Metrics are based on several evaluation iterations, which utilize numerous single query requests. The results of every evaluated framework are aggregated into a recall-vs-QPS Pareto frontier.
All the tests were performed on the same kind of machine as the baseline ann-benchmarks (as of Jan 2024), which is Amazon EC2 r6i.16xlarge machine with the following configuration:
CPU: Intel(R) Xeon(R) Platinum 8375C CPU @ 2.90GHz
Number of CPU cores: 32
Hyperthreading is disabled
RAM: 512 GB
OS: Ubuntu 22.04.3 LTS with Linux kernel 6.2.0-1017-aws
Huge page support was not enabled.
Tests were run with the `--parallelism=31` option.
Cardinal was compiled using the clang 17.0.6 compiler.
The presented benchmark results below are for the Cardinal engine only and do not include additional non-index optimizations provided by Zilliz Cloud.
Note: Results that do include Zilliz Cloud-specific optimizations are provided above at the beginning of the article.
The following charts were produced by taking the images of charts with results presented on the ANN-benchmark GitHub page and precisely adding an extra Cardinal curve on top.
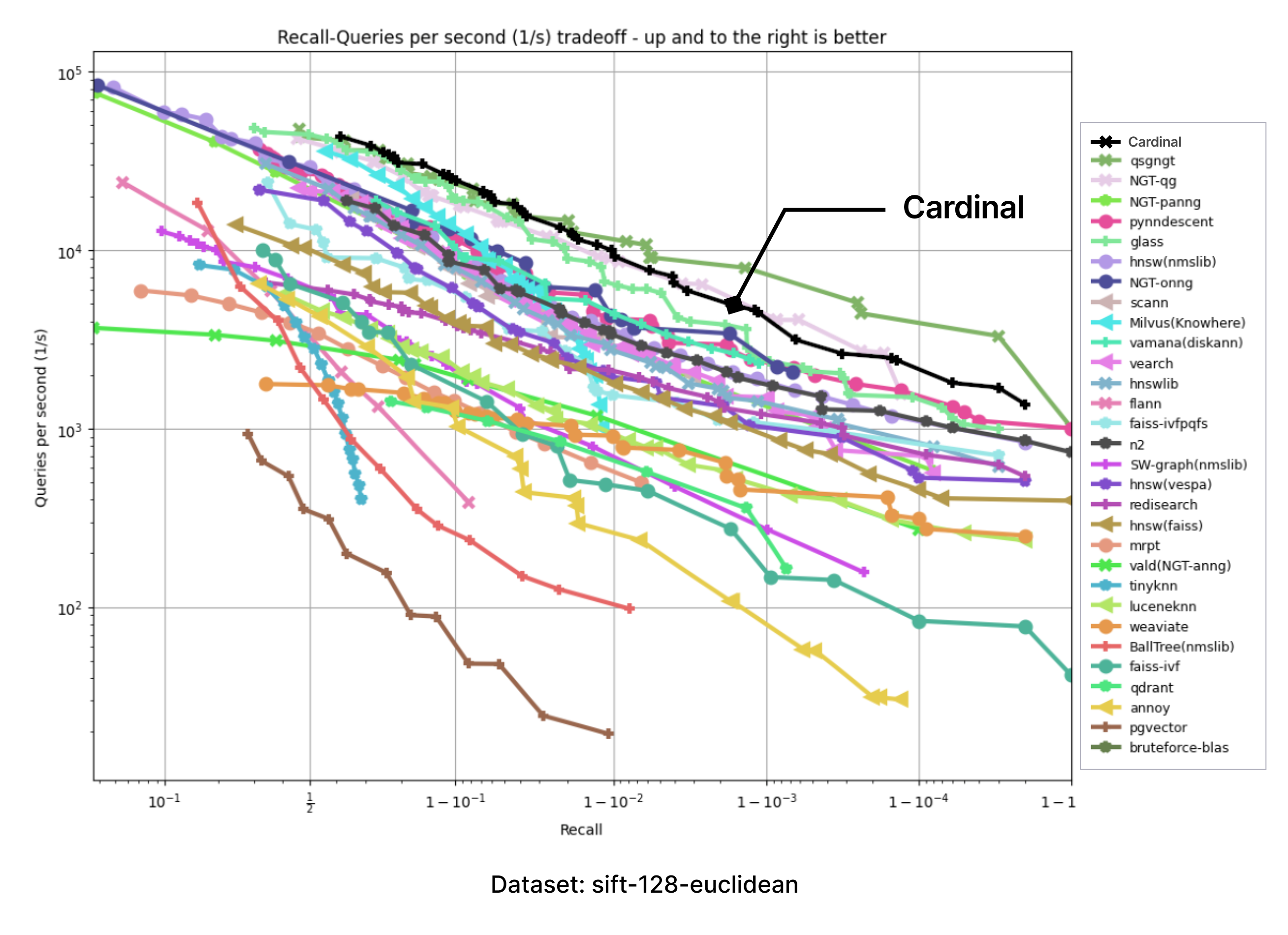
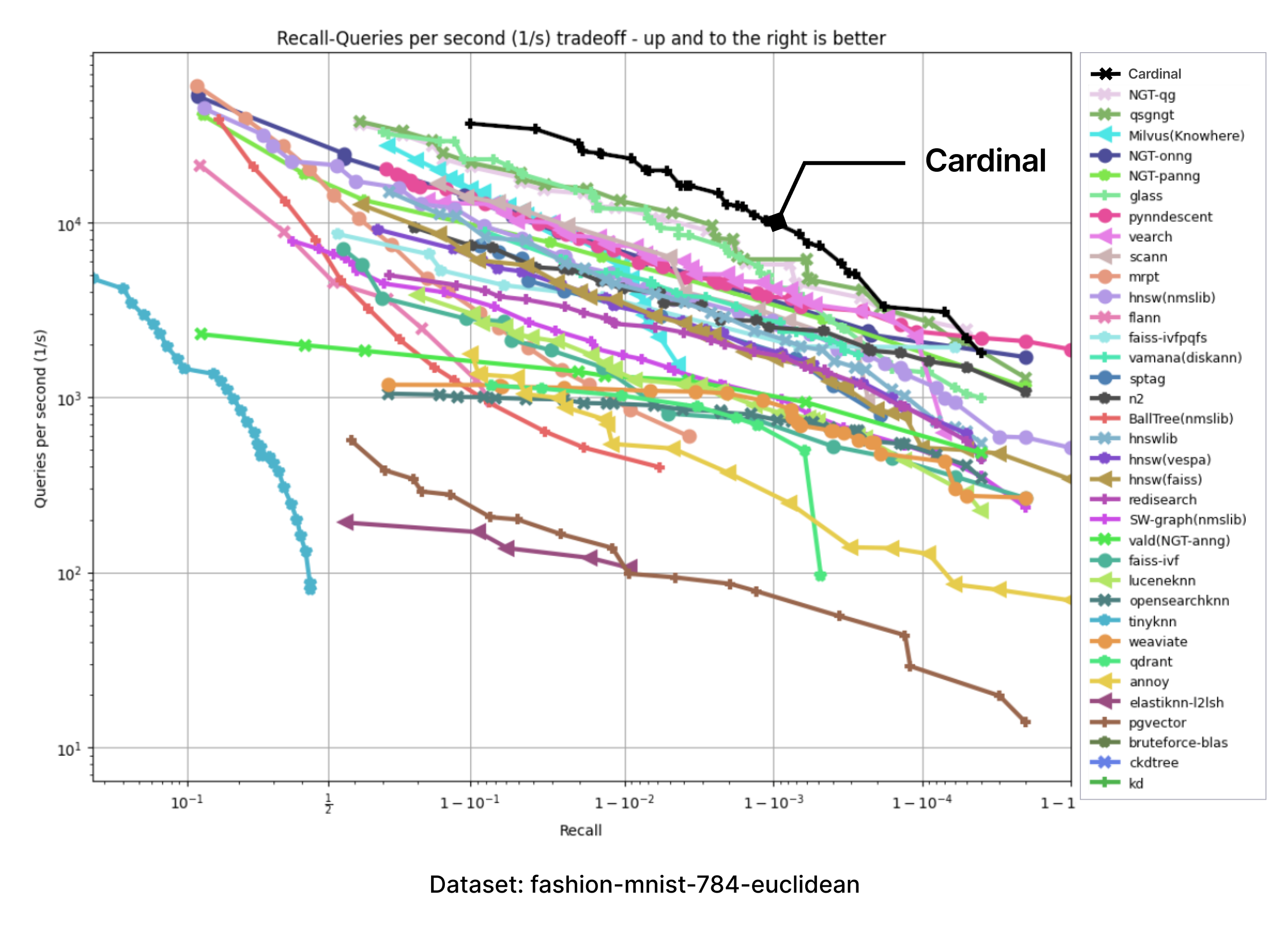
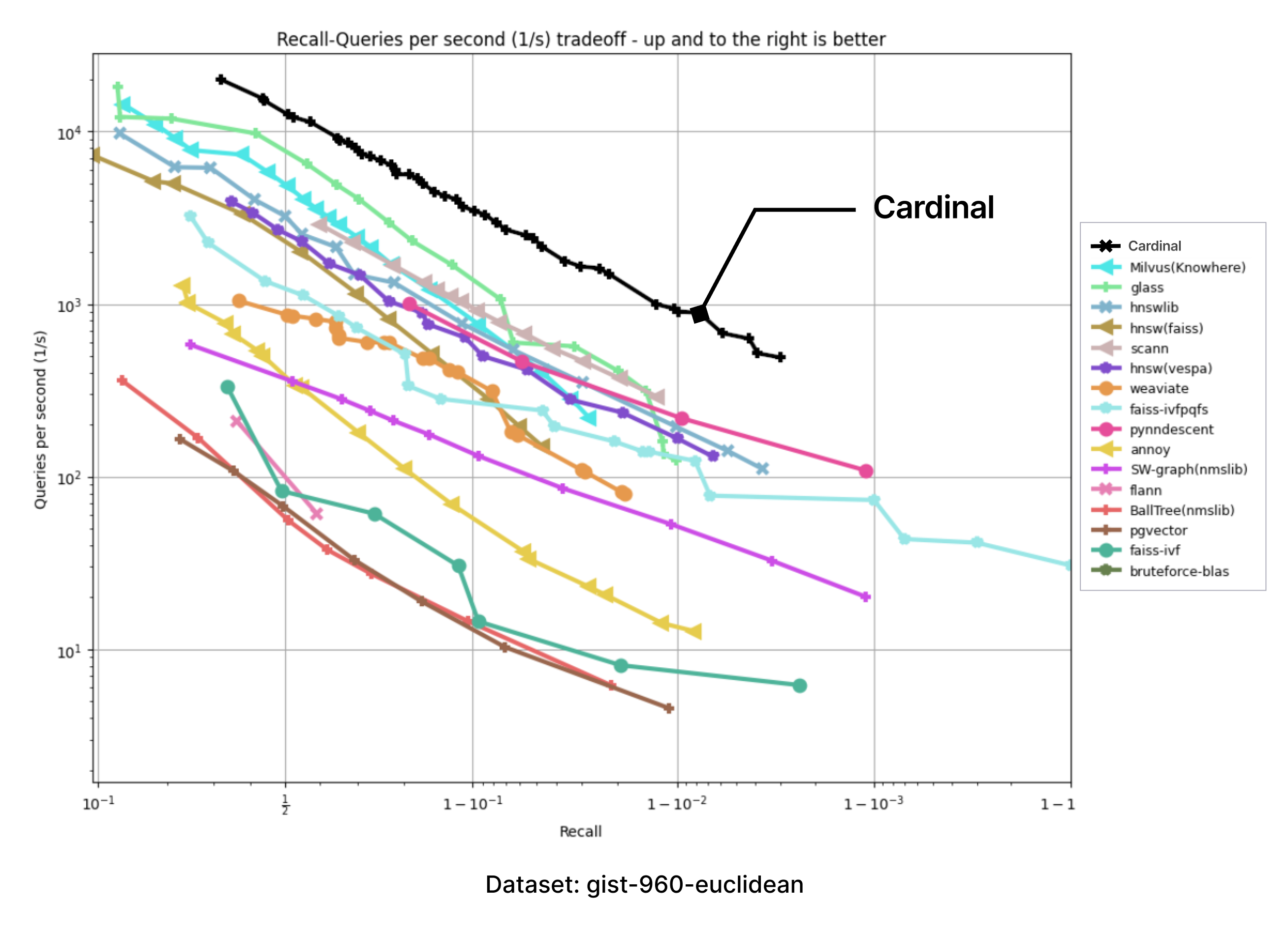
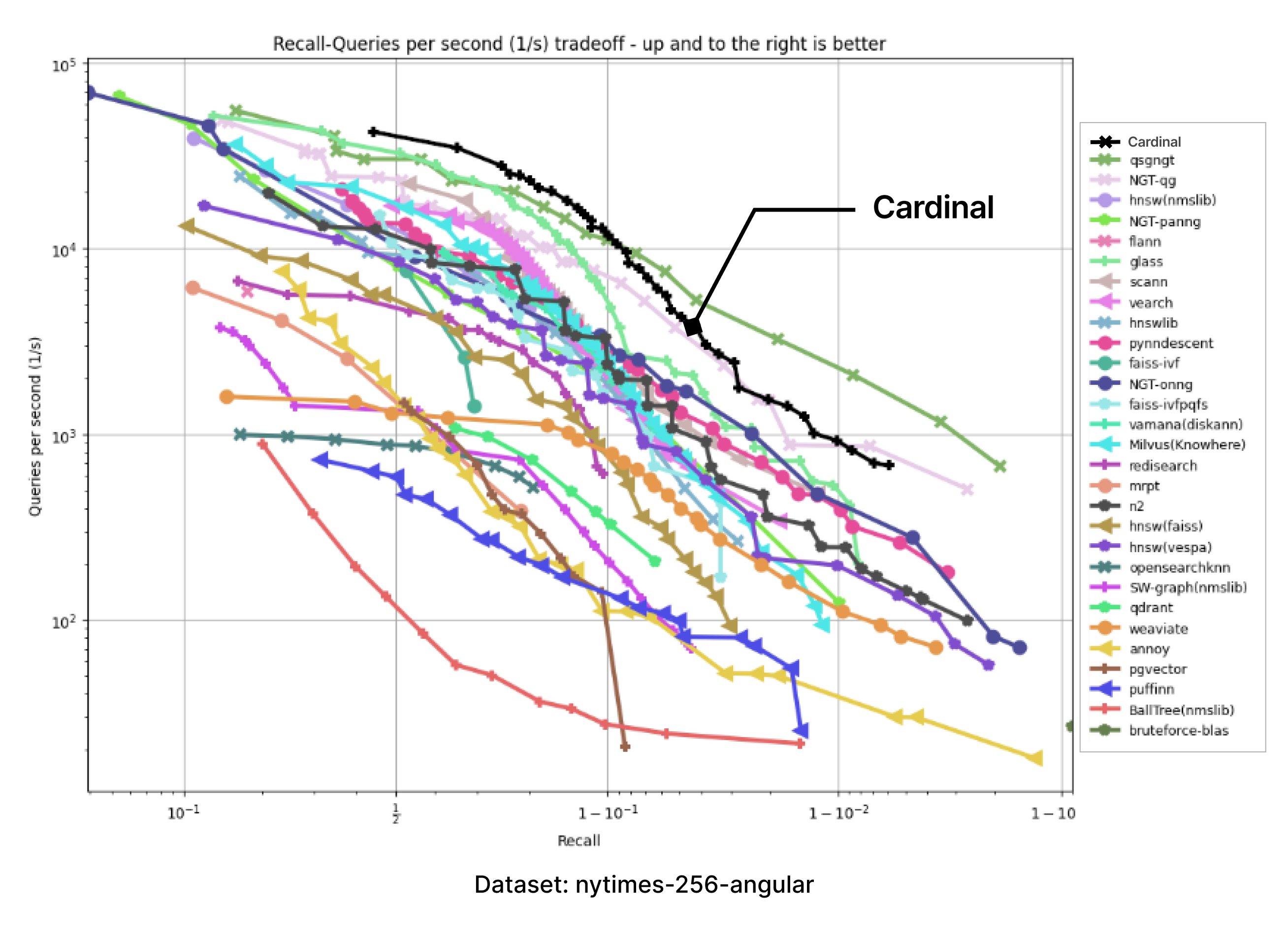
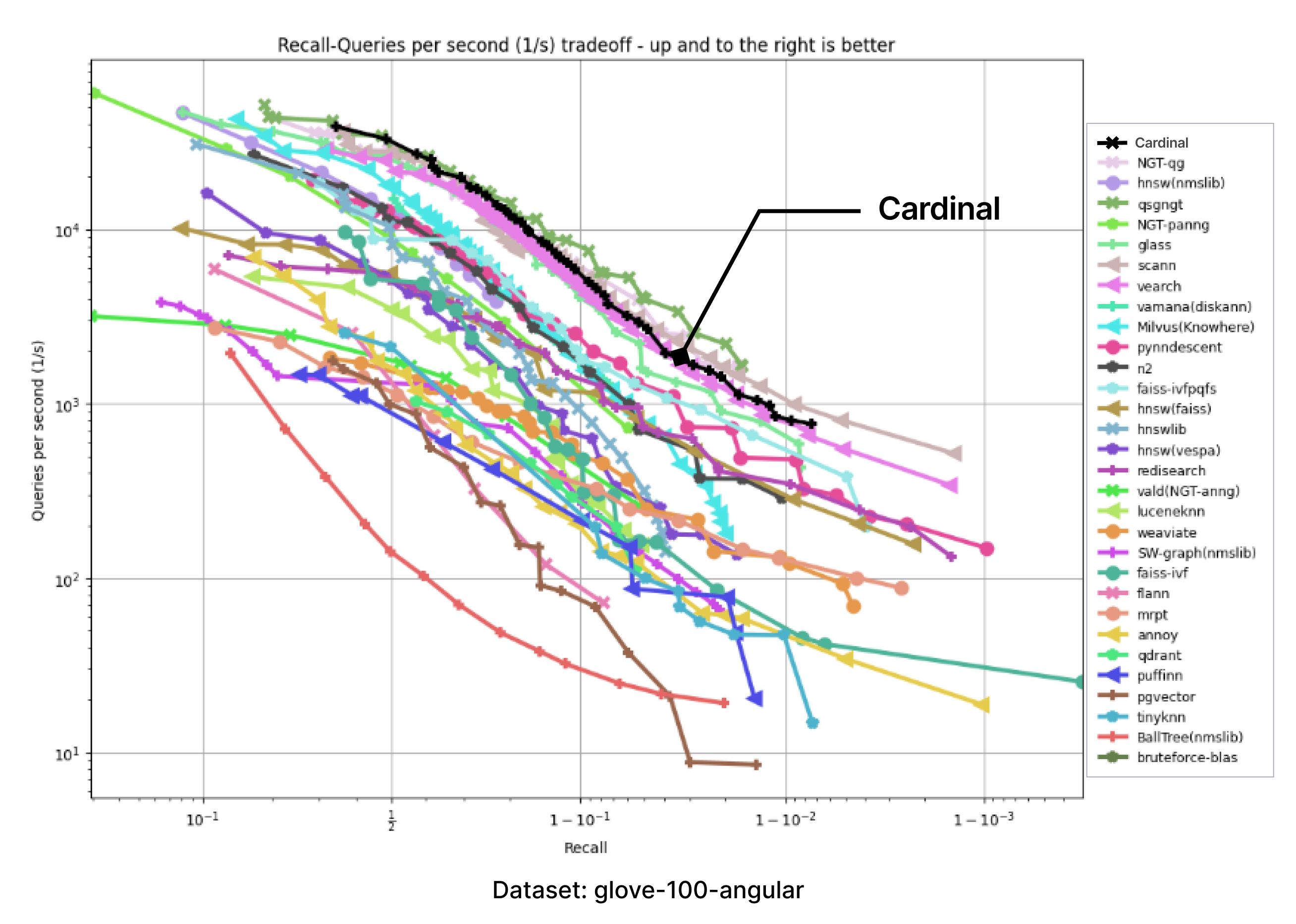
For all of the provided benchmarks, Cardinal shows very competitive results. And there is room for further improvement.
What’s next?
The future will bring us new challenges, no doubt. Different requirements, different bottlenecks, larger datasets. We keep on working to make Cardinal even better.
The way is lit. The path is clear. We require only the strength to follow it :)

Keep Reading

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

The Great AI Agent Protocol Race: Function Calling vs. MCP vs. A2A
Compare Function Calling, MCP, and A2A protocols for AI agents. Learn which standard best fits your development needs and future-proof your applications.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.