




От векторной базы данных к векторному Lakebase
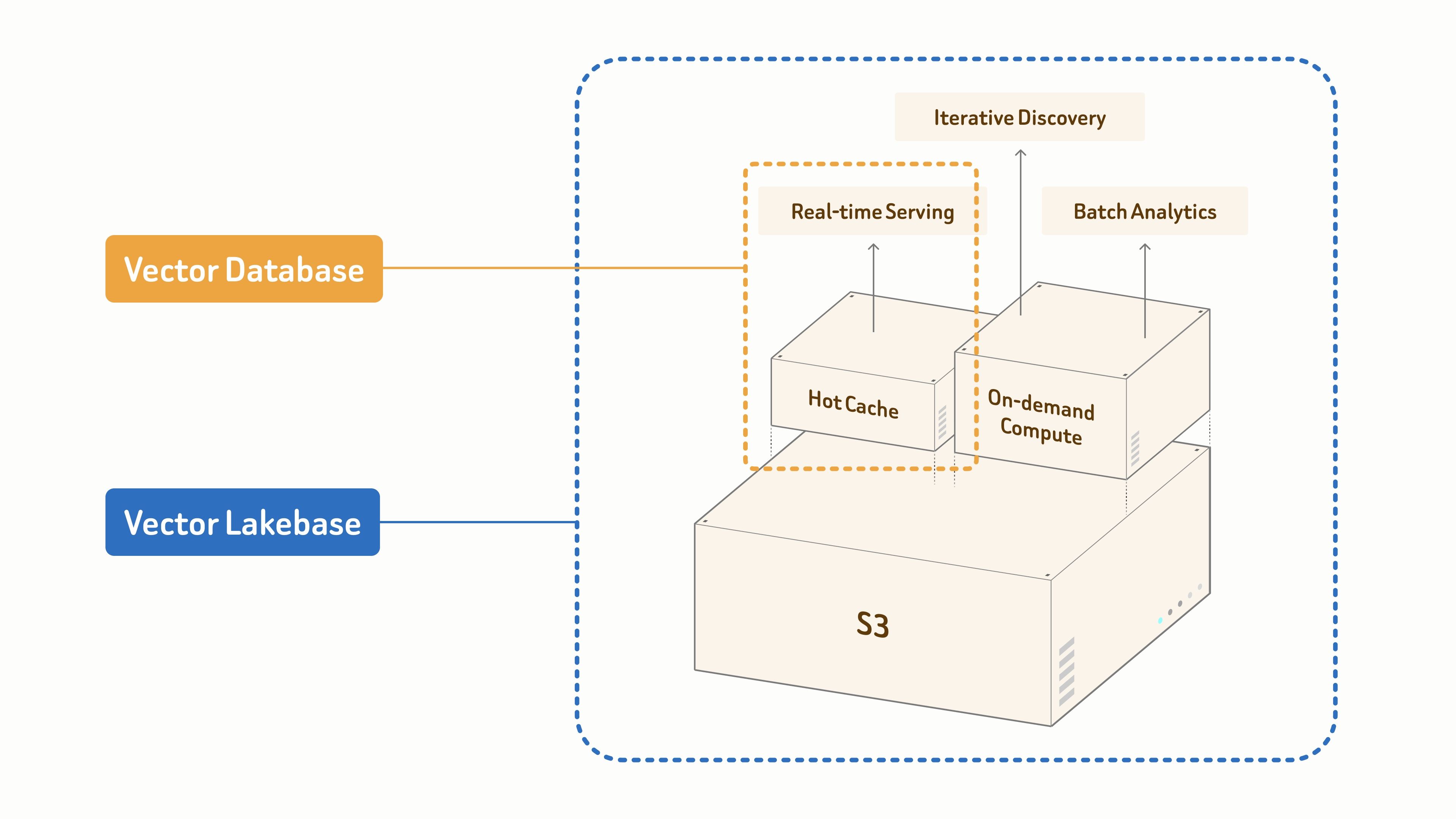
Сегодня мы запускаем публичную предварительную версию Zilliz Vector Lakebase — следующую главу для Zilliz Cloud. Vector Lakebase — это следующий шаг за пределы векторных баз данных. Это семантико-центричная платформа данных, где открытое хранилище и эластичные вычисления объединяются для AI-нагрузок.
- Векторные базы данных специально созданы для обслуживания в реальном времени.
- Vector Lakebase строится на унифицированной основе данных на базе S3, чтобы поддерживать AI и агентов в трех режимах нагрузки:
- извлечение в реальном времени для критически важного к задержкам production-обслуживания,
- итеративное исследование для интерактивного и многошагового изучения,
- пакетная аналитика для офлайн-майнинга и оптимизации наборов данных.
Все это масштабируется от гигабайтов до петабайтов.
Почему унифицированная основа данных и три режима нагрузки действительно важны?
Кратко: потому что AI-системы больше не являются просто задачей извлечения по одному запросу. Они работают как непрерывный цикл обслуживания, обучения и улучшения.
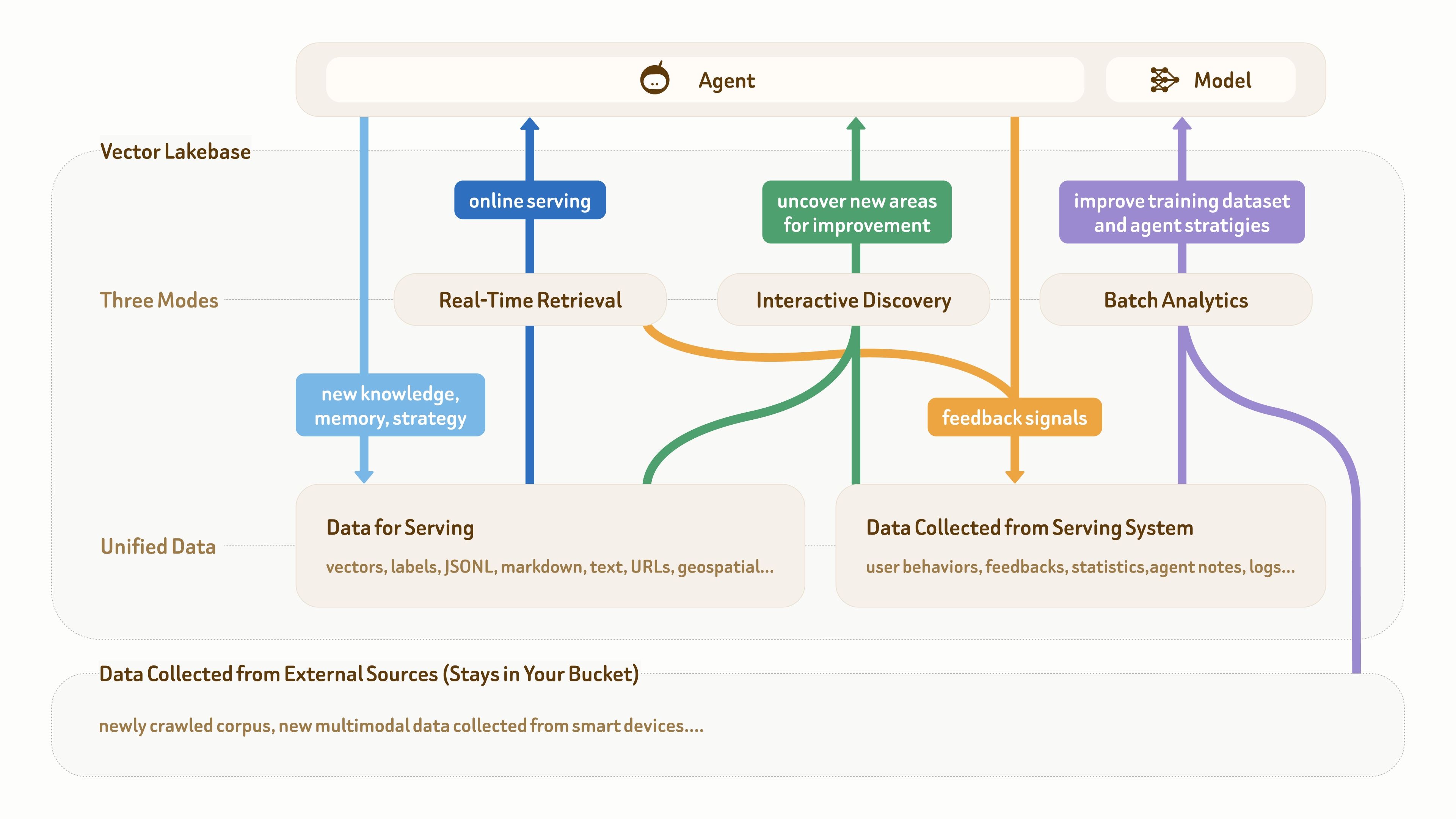
Как показано на этом рисунке, основа данных для AI- и агентских приложений обычно состоит из трех частей: сырые мультимодальные данные внизу, семантические данные для онлайн-обслуживания (такие как текст, векторы и метки) и данные обратной связи, собираемые из production-систем (такие как поведение пользователей, логи, заметки агентов и статистика).
У многих зрелых агентских приложений уже есть такая основа данных. Настоящая болевая точка заключается в том, что эти разные типы данных часто разбросаны по множеству пайплайнов и систем, без унифицированной и структурированной плоскости данных для поддержки циклического рабочего процесса:
онлайн-обслуживание (темно-синий) → накопление знаний и обратной связи (светло-синий и оранжевый) → обнаружение инсайтов (зеленый) → улучшение наборов данных и стратегий (фиолетовый) → лучшее онлайн-обслуживание.
Как также показывает изображение, одной только векторной базы данных уже недостаточно, потому что она в основном поддерживает извлечение в реальном времени и ориентированные на обслуживание записи данных (два синих пути). В этом цикле два других режима доступа — интерактивное исследование и пакетная аналитика — не менее важны.
Например, AI-разработчикам (вручную или через агентские системы) часто нужно исследовать данные обратной связи и базовый корпус, чтобы понять, почему качество обслуживания низкое. Они также могут выполнять крупномасштабную семантическую дедупликацию и кластеризацию на недавно собранных данных, а затем анализировать пограничные кластеры, чтобы обнаружить новых кандидатов для обучающих данных.
Эти нагрузки сильно отличаются от традиционной обработки больших данных. Основные вычисления являются семантическими, а не числовыми. Данные в основном состоят из векторов, текста, меток и семантических метаданных, тогда как основные операции включают векторный поиск, полнотекстовый поиск, reranking, семантическую кластеризацию и связанные задачи семантического извлечения.
Из-за этого интерактивное исследование и пакетная аналитика естественным образом согласуются с векторными базами данных как на уровне данных, так и на уровне вычислений. Во многих случаях онлайн-обслуживание и офлайн-обработка даже используют одну и ту же базовую основу данных.
Например, команды могут кластеризовать и анализировать высокоценные пользовательские задачи офлайн, одновременно проверяя, не проявляют ли поддерживающие знания или стратегии в системе обслуживания признаков разреженности или проблем качества.
В целом любая фрагментированная архитектура данных или изолированные инфраструктурные острова замедляют этот цикл — что может быть фатальным в быстро развивающейся гонке за AI-возможностями. Vector Lakebase ускоряет этот цикл с помощью простого, но эффективного подхода: предоставляя семантическую плоскость данных с нулевым копированием, к которой могут эффективно обращаться все три режима нагрузки — извлечение в реальном времени, интерактивное исследование и пакетная аналитика.
Ключевые возможности Vector Lakebase
Zilliz Vector Lakebase поддерживает этот циклический рабочий процесс с помощью пяти основных возможностей:
- Многоуровневые решения для обслуживания
Гибкие уровни обслуживания, оптимизированные для различных рабочих нагрузок в реальном времени, — обеспечивают сверхвысокую производительность, сбалансированную эффективность и экономически эффективное масштабирование для массивных наборов данных. - Поиск по требованию
Разработан для крупномасштабных рабочих нагрузок, где задержка менее критична, а вычислительные ресурсы большую часть времени простаивают, — включая нерегулярный поиск, исследование данных и пакетную аналитику. - Поиск во внешнем озере данных
Добавьте современные возможности индексирования и крупномасштабного поиска непосредственно к вашим существующим данным в озере. - Полноспектральный поиск От векторов и текста до JSON и геопространственных данных — в сочетании с гибридным извлечением, фильтрацией и переранжированием для выразительных мультимодальных запросов.
- Унифицированное lake-native хранилище
Унифицированное хранилище как для обслуживания, так и для аналитики, построенное на Vortex — открытом формате следующего поколения, обеспечивающем более быстрые и дешевые случайные чтения, чем Lance и Parquet, а также гибкость формата на уровне столбцов и более широкие возможности моделирования данных.
Многоуровневые решения для обслуживания в реальном времени
Многоуровневые решения для обслуживания Zilliz Cloud предоставляют три уровня обслуживания: Performance-Optimized, Capacity-Optimized и Tiered-Storage. Каждый уровень построен на специализированных алгоритмах индексирования и стратегиях размещения данных в иерархии хранилища, предлагая широкий диапазон компромиссов между производительностью и стоимостью.
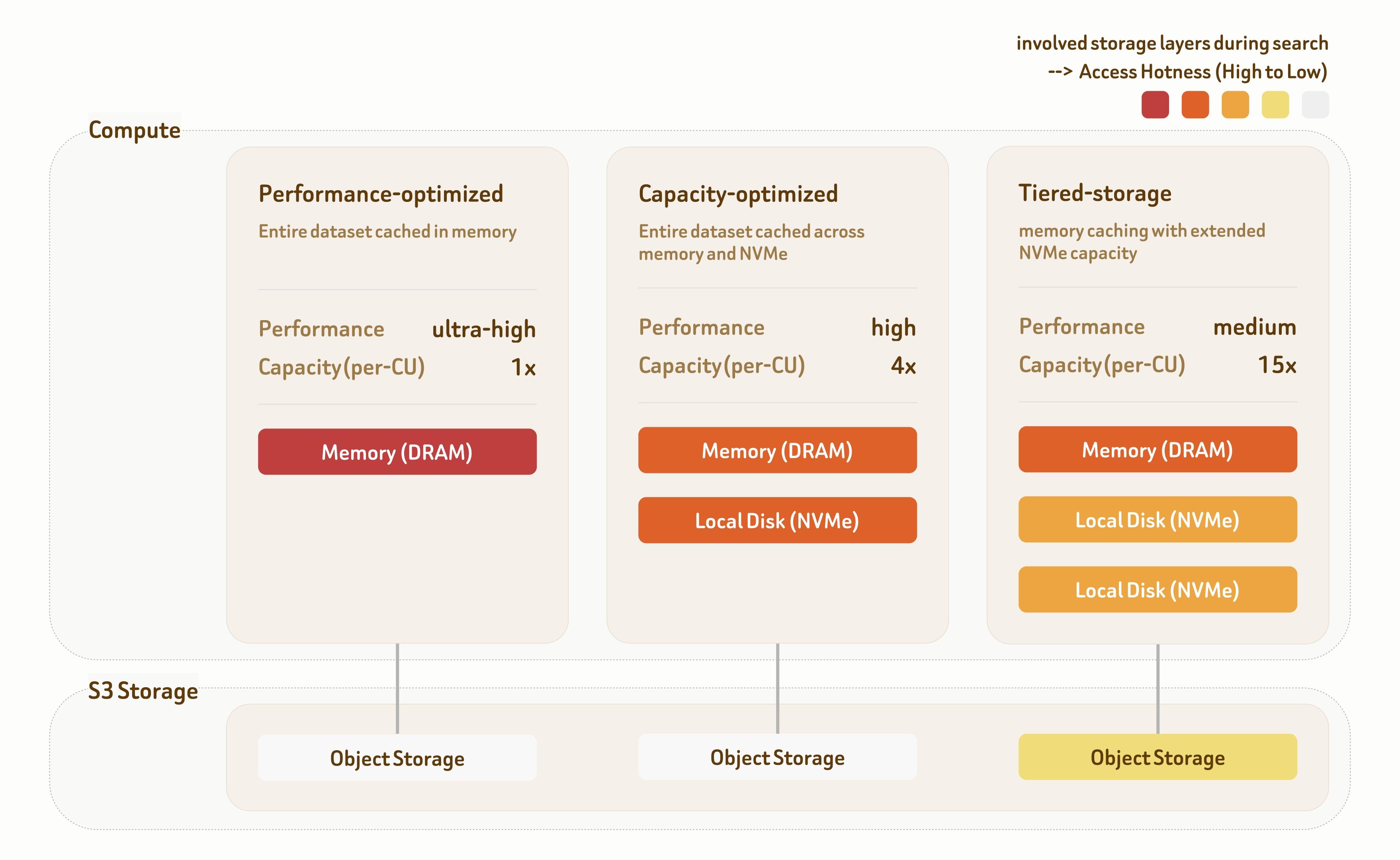
Уровень Performance-Optimized предназначен для сценариев со сверхвысокой производительностью. Все данные обслуживаются напрямую из памяти, обеспечивая 1000+ QPS с задержкой в единицы миллисекунд. Пропускная способность дополнительно масштабируется линейно при развертывании с несколькими репликами.
Уровень Capacity-Optimized сочетает память и локальное хранилище NVMe для баланса производительности и емкости. Он обеспечивает 100~500 QPS с задержкой менее 100 мс, что делает его подходящим для большинства рабочих нагрузок извлечения.
Уровень Tiered-Storage охватывает память, локальный NVMe и объектное хранилище. Благодаря высоко оптимизированным стратегиям предварительной выборки и кэширования более 95% обращений к данным по-прежнему попадает в память или на локальный диск, обеспечивая 10~50 QPS с задержкой около 100 мс при значительно более низкой стоимости инфраструктуры.
Все три уровня по умолчанию обеспечивают 95%–98% полноты, с гибкой настройкой индексирования и поиска — поддерживая полноту от 90% до 99%+ в зависимости от требований рабочей нагрузки.
Эти архитектуры обслуживания проверены в боевых условиях в некоторых из самых требовательных крупномасштабных AI- и интернет-нагрузок в мире, включая:
- интернет-масштабные мультитенантные AI-платформы,
- дифференцированные уровни сервиса как для премиальных корпоративных пользователей, так и для крупных пулов бесплатных пользователей,
- высокопроизводительные базы знаний агентов,
- рекомендательные системы со сверхвысокой пропускной способностью,
- AI-поисковые системы веб-масштаба,
- динамическое планирование горячих/холодных данных на уровне секунд между уровнями хранилища,
- конвейеры интеллектуального анализа данных для автономного вождения масштаба 100B+ в условиях экстремальных ограничений по стоимости.
Для онлайн-обслуживания Zilliz Cloud также предоставляет возможности Global Cluster для высокой доступности между регионами и аварийного восстановления, подкрепленные SLA доступности 99,99%.
Поиск по требованию
Интерактивное обнаружение и пакетная аналитика часто работают с объемами данных на один–три порядка больше, чем онлайн-обслуживание, особенно с учетом данных обратной связи, заметок, сгенерированных агентами, журналов и просканированных корпусов. Такие наборы данных легко могут достигать масштаба ТБ или даже ПБ. Но использование сотен или даже тысяч узлов векторной базы данных для их обслуживания часто трудно обосновать с точки зрения соотношения затрат и выгод.

Что еще важнее, эти рабочие нагрузки обычно ориентированы на задачи. В отличие от уровня онлайн-обслуживания агентских приложений, они не требуют активной инфраструктуры 24/7. Вычислительные ресурсы интенсивно используются только во время активных задач обработки, оставаясь простаивающими большую часть времени, часто с более чем 97% времени простоя.
Бессерверные решения для обслуживания могут казаться привлекательными, но для таких рабочих нагрузок они часто становятся значительно дороже.
На вычислительном уровне и бессерверные системы, и On-Demand Search используют модель оплаты по мере использования. Несмотря на различия в детальных моделях ценообразования, базовая стоимость вычислений часто схожа. Однако в бессерверной архитектуре накладные расходы на пул ресурсов, индексацию и постоянное хранение данных включаются в дополнительные наценки на запись и хранение, а не напрямую отражают реальную стоимость базовых ресурсов.
В отличие от этого, Zilliz On-Demand Search взимает плату напрямую за объектное хранилище и вычисления по требованию — аналогично AWS Lambda, где ценообразование в основном основано на размере выделенных ресурсов и времени выполнения, а стоимость хранения остается близкой к базовой стоимости S3. Это позволяет избежать скрытых инфраструктурных накладных расходов и непрозрачных моделей ценообразования.
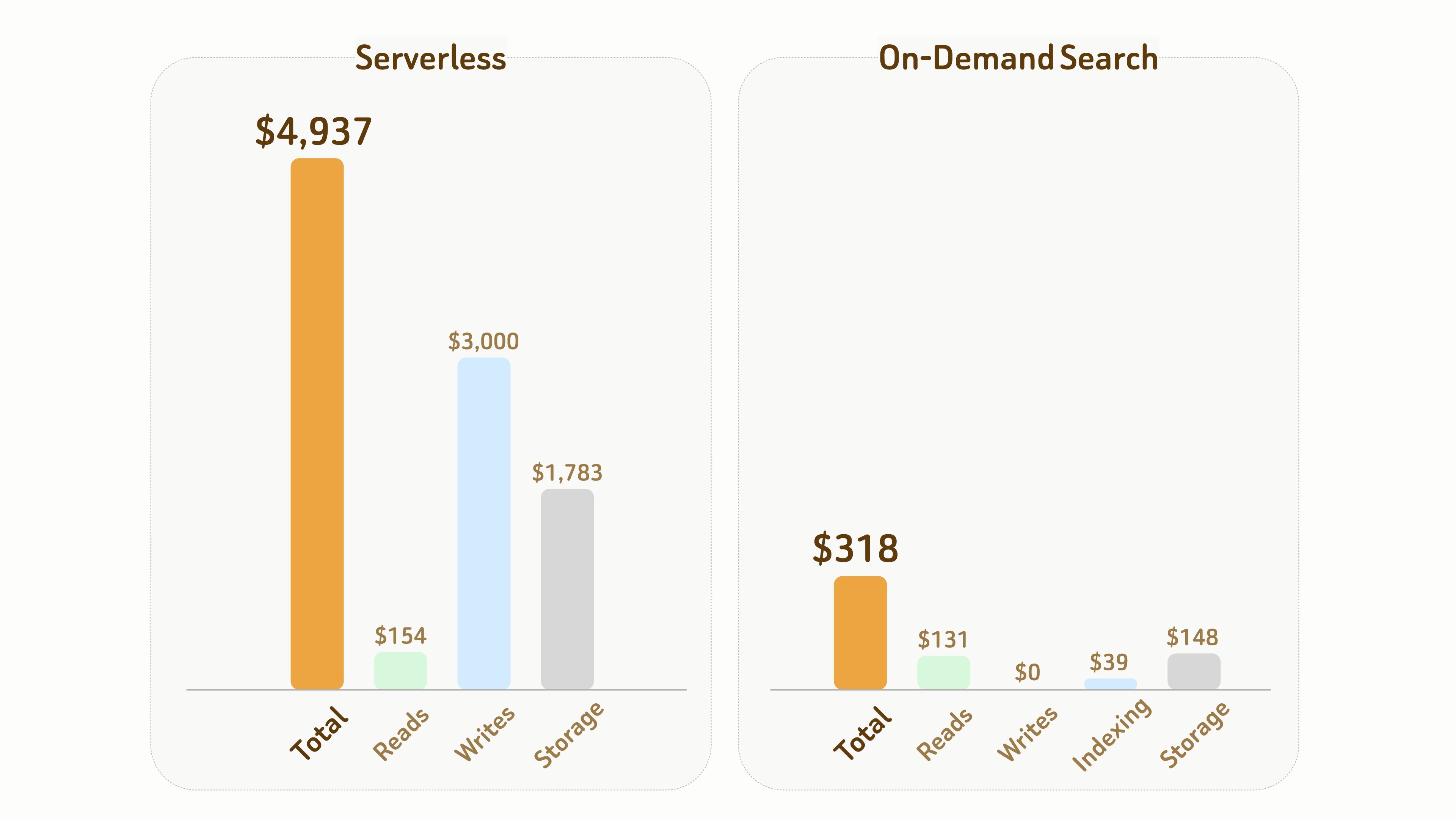
Следующее сравнение иллюстрирует разницу в стоимости между Serverless и On-Demand Search.
Настройка:
- 1 млрд векторов с 768 измерениями, требующих примерно 6 ТБ хранилища, включая файлы данных и индексов,
- Продолжительность 1 месяц с 10 часами суммарного активного времени вычислений.
В целом, в этом эксперименте общая стоимость On-Demand Search составляет всего около 1/15 ($318 против $4,937) от стоимости Serverless.
Поиск во внешнем озере данных
Zilliz Vector Lakebase предоставляет полностью управляемое хранилище и вычисления для запросов, позволяя пользователям хранить свои данные и работать с ними непосредственно в Zilliz Cloud. Однако у некоторых клиентов уже есть зрелая инфраструктура озера данных и конвейеры управления данными.
Для AI-приложений одной из ключевых задач является обеспечение эффективного извлечения и семантического исследования непосредственно поверх существующих данных в озере. Традиционные системы больших данных, такие как Spark и Ray, не оптимизированы для таких рабочих нагрузок, поскольку они в своей основе спроектированы вокруг полного сканирования данных и вычислений map-reduce, а не запросов с ускорением за счет индексов и семантического извлечения.
Чтобы решить эту задачу, Zilliz предоставляет режим External Collection. Он создает логическое сопоставление без копирования из плоскости данных Zilliz с таблицами озера, принадлежащими клиенту, одновременно обеспечивая высокопроизводительные индексы и полноспектральный поиск поверх этого сопоставления.
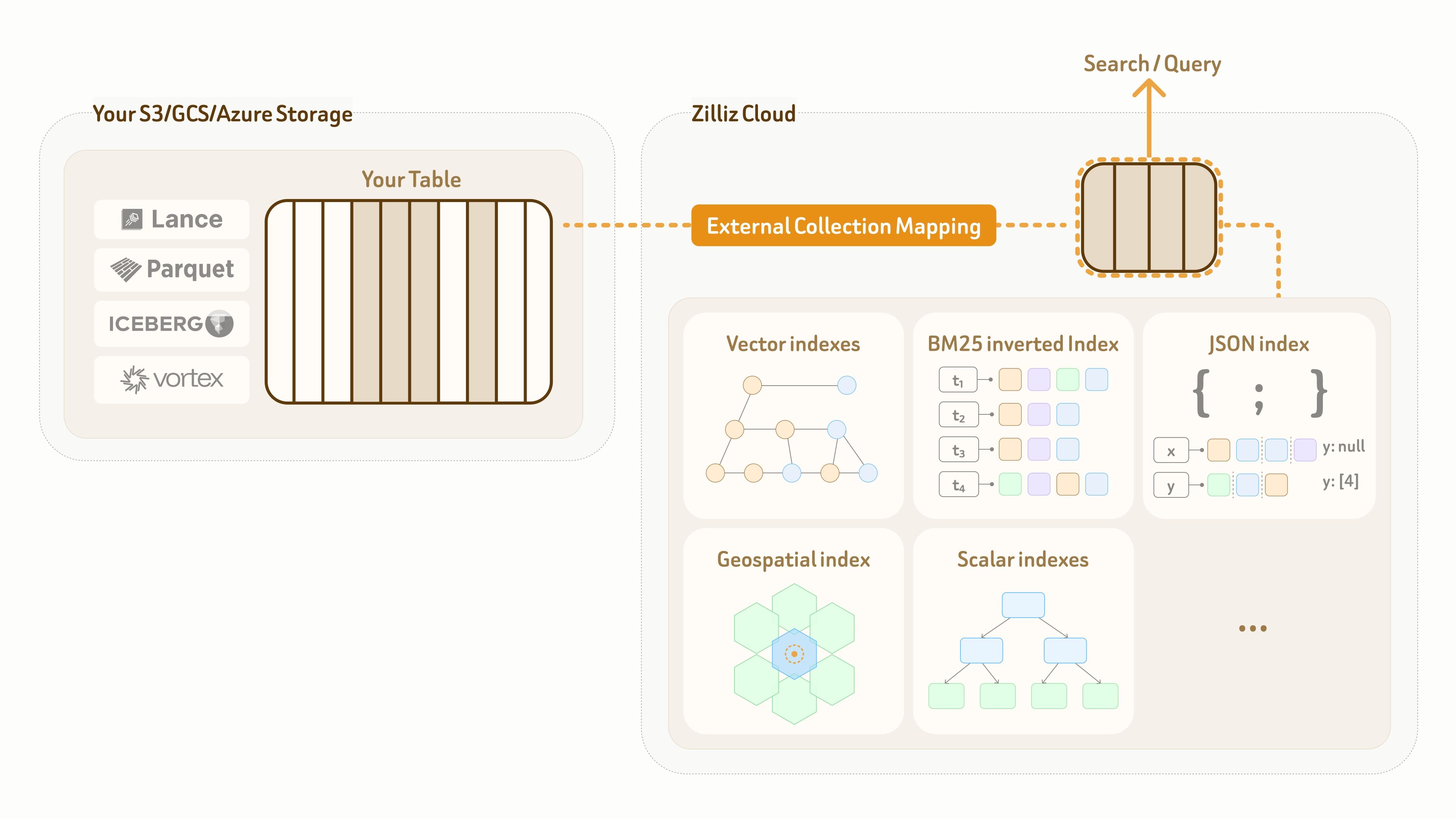
В настоящее время External Collection поддерживает два формата таблиц озера данных — Lance и Iceberg, а также два открытых формата данных — Parquet и Vortex.
Для обновлений озера данных Zilliz External Collection предоставляет возможности инкрементальной синхронизации. В зависимости от шаблона обновления озера данных и требований к видимости запросов пользователи могут синхронизировать данные в любое время с помощью вызова обновления.
Полноспектральный поиск
AI-приложениям все чаще требуется извлекать и анализировать данные из разных источников и модальностей — как для объединения взаимодополняющей информации, так и для извлечения нескольких перспектив из одного и того же исходного контента для повышения качества извлечения и анализа.
Zilliz Vector Lakebase поддерживает моделирование широких таблиц с богатыми типами данных, включая плотные и разреженные векторы, текст, JSON, геопространственные данные и примитивные типы, а также сложные структуры, такие как Struct и Array, — обеспечивая эффективное вложенное семантическое моделирование непосредственно в рамках единой табличной структуры.

Это обеспечивает унифицированное моделирование контекста путем сопоставления каждой сущности уровня приложения непосредственно с одной строкой. Например, вместо разбиения документа на сотни строк для текстовых фрагментов, изображений и таблиц Zilliz Vector Lakebase может моделировать весь документ как одну строку. Это улучшает мультимодальное извлечение и аналитику, одновременно избегая накладных расходов на производительность и эксплуатацию, связанных с JOIN и агрегациями.
Помимо моделирования данных, Vector Lakebase также предоставляет передовые возможности индексирования и поиска по всем поддерживаемым типам данных. Подробные возможности перечислены ниже:
| Векторный поиск | Передовые алгоритмы индексирования, превосходящие HNSW, IVF и RaBitQ, с 10 уровнями настройки полноты и задержки. |
|---|---|
| Полнотекстовый поиск | Полнотекстовый поиск с BM25, фразовым, префиксным и нечетким сопоставлением, а также широким набором анализаторов. |
| Grep | Встроенная поддержка regex, охватывающая большинство шаблонов сопоставления в стиле grep. |
| Гибридный поиск | Гибридный поиск по плотным и разреженным векторам для повышения полноты и релевантности. |
| Запросы к JSON | Встроенное разбиение и индексирование JSON для быстрой фильтрации и выполнения запросов по вложенным полям JSON. |
| Геопространственный поиск | Быстрый геопространственный поиск с фильтрацией по радиусу, ближайшим соседям и области. |
| Мультивекторный поиск | Поиск по нескольким эмбеддингам, созданным из одной или нескольких модальностей, с унифицированным переранжированием. |
| Векторный поиск с фильтрацией | Векторный поиск с фильтрацией по атрибутам, оптимизированный для фильтров с низкой и высокой селективностью. |
| Диапазонный поиск | Возвращает все векторы в пределах указанного порога расстояния от вектора запроса. |
| Итеративный поиск | Итеративный поиск с пошаговым уточнением запроса на основе промежуточных результатов. |
| Многопутевое извлечение | Многопутевое извлечение с несколькими стратегиями, где каждый путь может использовать любой из вышеуказанных методов поиска. |
а также возможности переранжирования, используемые вместе с многопутевым извлечением.
| Cohere Reranker | Модель переранжирования на основе cross-encoder, которая оценивает пары запрос–документ с высокой семантической точностью, чтобы переупорядочить результаты извлечения для максимальной релевантности. |
|---|---|
| Voyage AI Reranker | Легковесная модель переранжирования с высокой пропускной способностью, оптимизированная для быстрой и экономичной оценки релевантности в крупномасштабных конвейерах извлечения. |
| Boost Reranker | Применяет условные фильтры к совпавшим результатам и корректирует их оценки с заданным весом, чтобы повысить или понизить позиции в ранжировании. |
| Decay Reranker | Корректирует оценки результатов, применяя функцию затухания на основе таких факторов, как расстояние или время, постепенно снижая релевантность по мере отклонения значений от целевого. |
| RRF Reranker | Объединяет несколько списков результатов, комбинируя позиции ранга каждого элемента в разных списках в единый рейтинг. |
| Weighted Reranker | Объединяет оценки из нескольких списков результатов с использованием настраиваемых весов для формирования единого рейтинга. |
Унифицированное Lake-Native-хранилище
Zilliz Cloud построен на полностью разделенной архитектуре хранения и вычислений, где все данные сохраняются в облачном объектном хранилище.
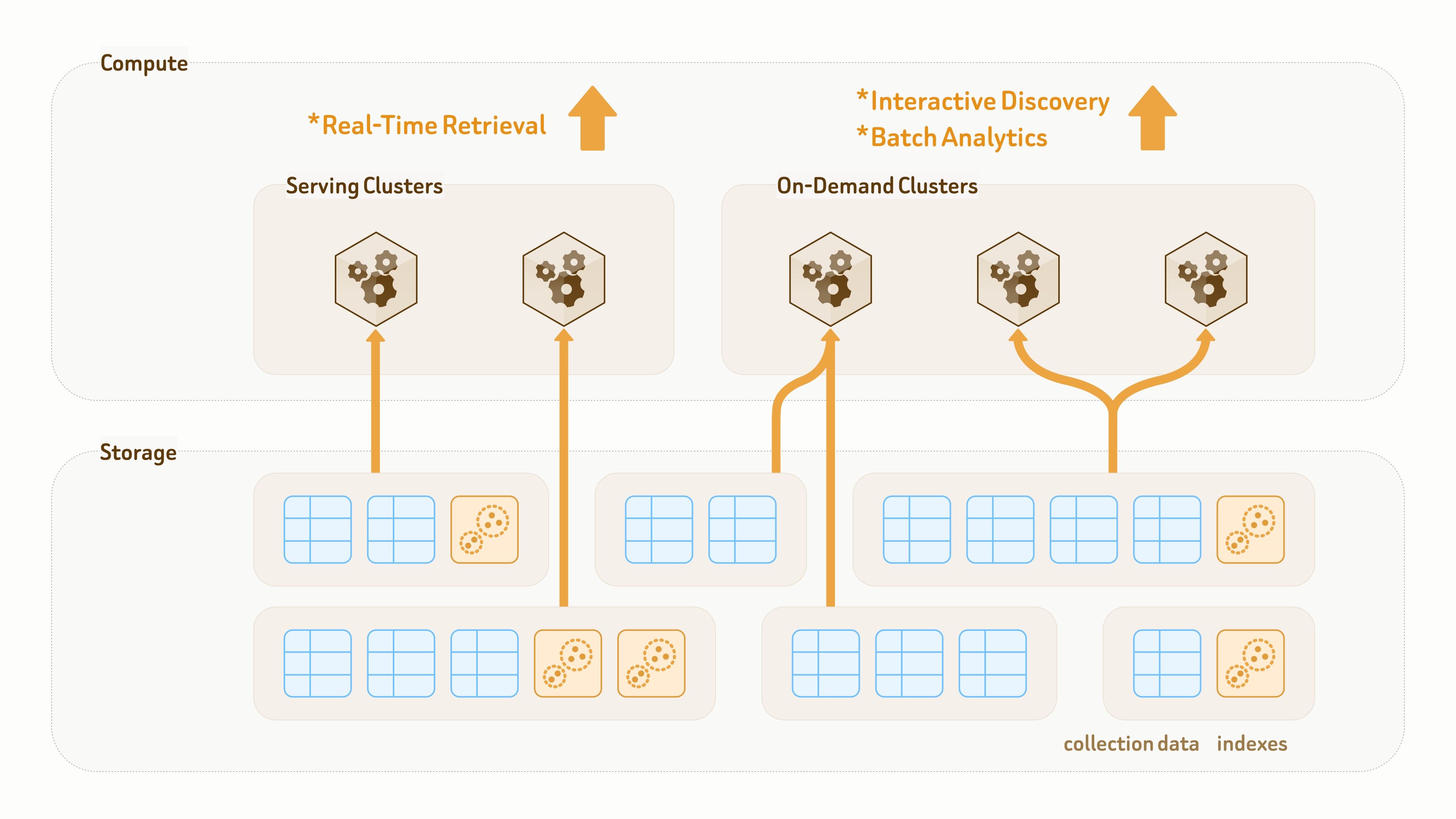
В отличие от традиционных озер данных, предназначенных главным образом для хранения, уровень данных Zilliz Vector Lakebase предназначен как для постоянного хранения, так и для выполнения запросов. Коллекции и индексы отделены от вычислительных кластеров, что позволяет одним и тем же данным и индексам монтироваться через доступ без копирования различными кластерами для разных рабочих нагрузок запросов и аналитики.
Для AI- и агентских приложений с постоянно развивающимися моделями данных — таких как частое добавление новых меток и признаков или переключение моделей эмбеддингов — Zilliz предоставляет бесшовный и высокоскоростной механизм эволюции схемы и обратного заполнения данных.
Новые поля заполняются и выравниваются объединенными вычислительными ресурсами платформы, а затем становятся доступными кластерам запросов через обновления метаданных. Обратное заполнение 100 млн строк обычно может быть завершено за считанные минуты.
Поскольку большая часть работы выполняется вычислительными ресурсами на стороне платформы, существующие пользовательские кластеры остаются незатронутыми и могут продолжать обслуживать трафик чтения и записи на протяжении всего процесса.
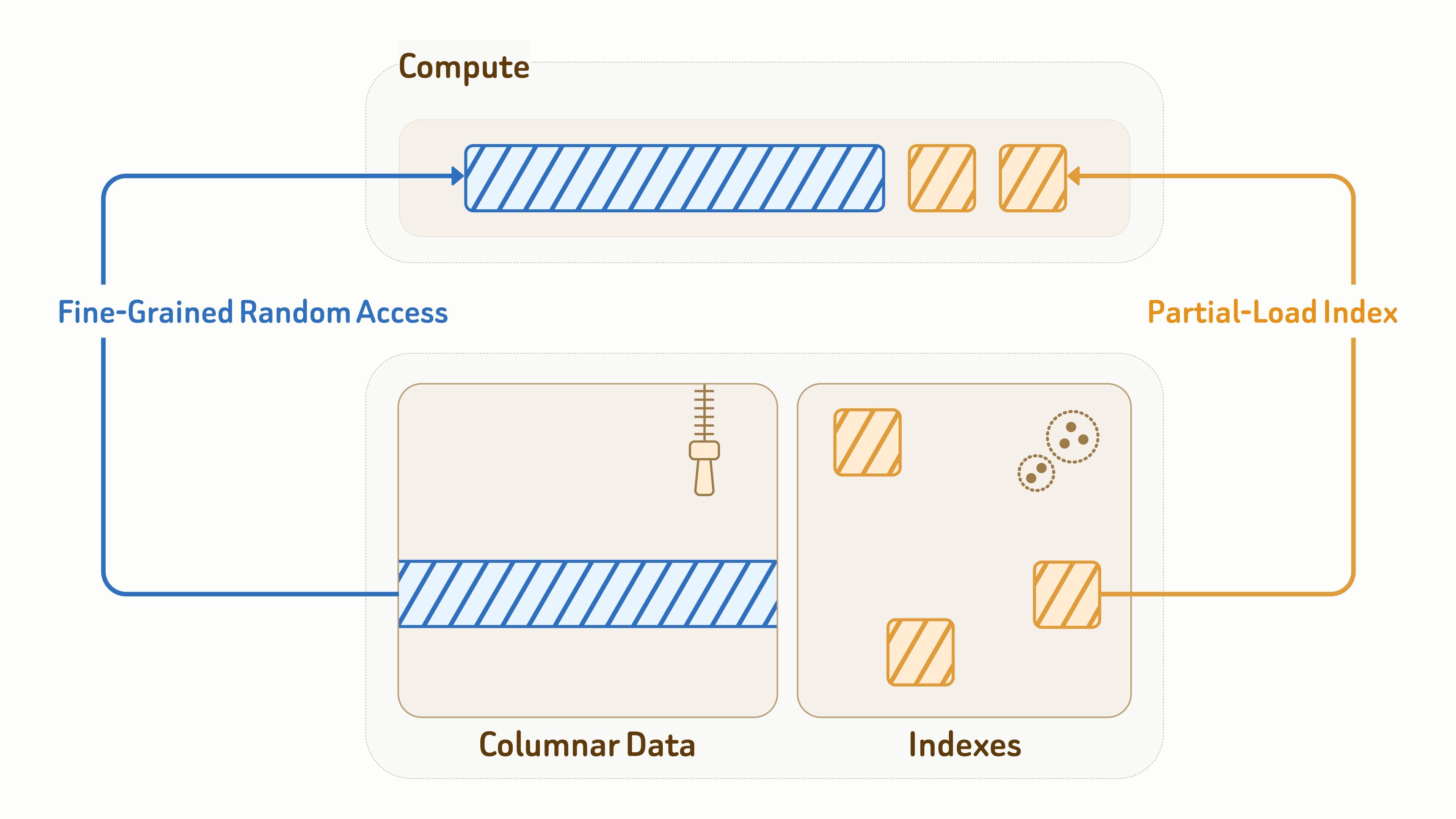
Поскольку уровень данных также напрямую обслуживает рабочие нагрузки запросов, эффективный I/O критически важен как для задержки, так и для пропускной способности.
Для данных коллекций Zilliz использует открытый формат Vortex для колоночной схемы хранения, сочетая эффективное кодирование с мелкозернистым произвольным доступом к фрагментам данных — значительно быстрее, чем Lance и Parquet при произвольном чтении.
Для индексов Zilliz предоставляет разработки алгоритмов индексации, учитывающие специфику объектного хранилища, с глубоко оптимизированными схемами размещения и шаблонами доступа для эффективного ввода-вывода, включая векторные индексы, инвертированные индексы BM25 и JSON-индексы.
Во время выполнения запросов вычислительные узлы лишь частично загружают страницы индекса и сущности данных, затронутые запросом. В сочетании с кэшированием и отсечением данных это значительно снижает усиление чтения более чем на 90%.
Основные сценарии использования Vector Lakebase
Типичные сценарии применения Vector Lakebase включают, помимо прочего:
Рабочие нагрузки обслуживания в реальном времени:
- Критичная к задержкам память агентов и извлечение стратегий.
- Отраслевые базы знаний для юридической сферы, здравоохранения, финансов и других специализированных отраслей.
- AI-поисковые системы веб-масштаба.
- Рекомендательные системы со сверхвысокой пропускной способностью.
- Динамическое планирование горячих/холодных данных между уровнями хранения на уровне секунд.
- Дифференцированные уровни обслуживания как для премиальных корпоративных пользователей, так и для крупных пулов бесплатных пользователей.
Рабочие нагрузки итеративного обнаружения:
- Анализ качества AI-сервисов и выявление проблем по данным обратной связи, заметкам, сгенерированным агентами, логам и другим данным из нескольких источников.
- Эффективное исследование крупномасштабных наборов данных.
- Многоэтапные итеративные глубокие исследования.
Рабочие нагрузки пакетной аналитики:
- Дедупликация и кластеризация корпусов сверхкрупного масштаба.
- Добавление полноспектральных поисковых возможностей в Spark и Ray для эффективной фильтрации, извлечения и двухэтапных конвейеров запросов с грубым отбором и повторным ранжированием.
- Подготовка наборов данных для обучения и дообучения.
Гибридные сценарии:
- Ускоренная индексация и извлечение по существующим таблицам озёр данных, таким как Lance и Iceberg.
- Непрерывно развивающиеся модели данных с частыми крупномасштабными обратными загрузками.
- Мультимодальное семантическое моделирование широких таблиц, объединяющее векторы, метаданные, сгенерированные LLM сводки и структурированные поля в ориентированные на сущности таблицы с согласованным версионированием и управлением происхождением данных.
Попробуйте Zilliz Vector Lakebase
Для получения дополнительной информации о Vector Lakebase и последних обновлениях посетите веб-сайт Zilliz или изучите документацию Zilliz Cloud. Если архитектура или сценарии использования, описанные в этой статье, актуальны для вашей работы, свяжитесь с командой Zilliz для более глубокого технического обсуждения.

Читать далее

A Few Notes from Databricks Data + AI Summit 2026: Why the Data Layer Matters Again
James Luan shares notes from Databricks Data + AI Summit 2026 on why production AI is pushing the data layer back to the center of infrastructure.

Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
Vector Lakebase: a unified, lake-native data foundation for AI workloads — and an answer to what happens after vector databases succeed.

Milvus WebUI: A Visual Management Tool for Your Vector Database
Explore Milvus WebUI to monitor, manage, and optimize your vector database with real-time insights, performance tracking, and system health monitoring.