




Лучшие практики внедрения приложений с расширенным поиском (RAG)
Retrieval-Augmented Generation (RAG) - это метод, который доказал свою эффективность в улучшении ответов ЛЛМ и решении проблемы галлюцинаций ЛЛМ. В двух словах, RAG предоставляет ЛЛМ контекст, который может помочь им генерировать более точные и контекстуализированные ответы. Контекст может быть получен откуда угодно: из ваших внутренних документов, векторных баз данных, CSV-файлов, JSON-файлов и т. д.
RAG - это новый подход, состоящий из множества компонентов, которые работают вместе. Эти компоненты включают в себя обработку запросов, context chunking, поиск контекста, context reranking, и сам LLM для генерации ответа. Каждый компонент влияет на качество конечного ответа, генерируемого приложением RAG. Проблема в том, что трудно найти наилучшую комбинацию методов в каждом компоненте, которая приведет к наиболее оптимальной производительности RAG.
В этой статье мы обсудим несколько методов, обычно используемых во всех компонентах RAG, оценим лучший подход для каждого компонента, а затем найдем наилучшую комбинацию, которая приведет к наиболее оптимальному ответу, сгенерированному RAG, согласно this paper. Итак, без лишних слов, давайте начнем с введения в компоненты RAG.
Компоненты RAG
Как уже говорилось, RAG - это мощный метод, позволяющий облегчить проблемы галлюцинаций у LLM, которые обычно возникают, когда мы задаем запросы, выходящие за рамки их обучающих данных, или когда они требуют специальных знаний. Например, если мы зададим LLM вопрос о наших внутренних данных, то, скорее всего, получим неточный ответ. RAG решает эту проблему, предоставляя LLM контекст, который может помочь ответить на наш запрос.
RAG состоит из цепочки компонентов, которые формируют рабочий процесс. Типичные компоненты RAG включают:
Классификация запроса: для определения того, нуждается ли наш запрос в поиске контекстов или может быть обработан непосредственно LLM.
Поиск контекстов: получение k лучших кандидатов в наиболее релевантных контекстах для нашего запроса.
Перегруппировка контекстов: сортировка k лучших кандидатов, полученных из компонента поиска, начиная с наиболее похожего.
Упаковка контекстов: упорядочивание наиболее релевантных контекстов в более структурированный формат для лучшего формирования ответа.
Суммирование контекста: извлечение ключевой информации из соответствующих контекстов для улучшения генерации ответов.
Генерирование ответа: генерирование ответа на основе запроса и релевантных контекстов.
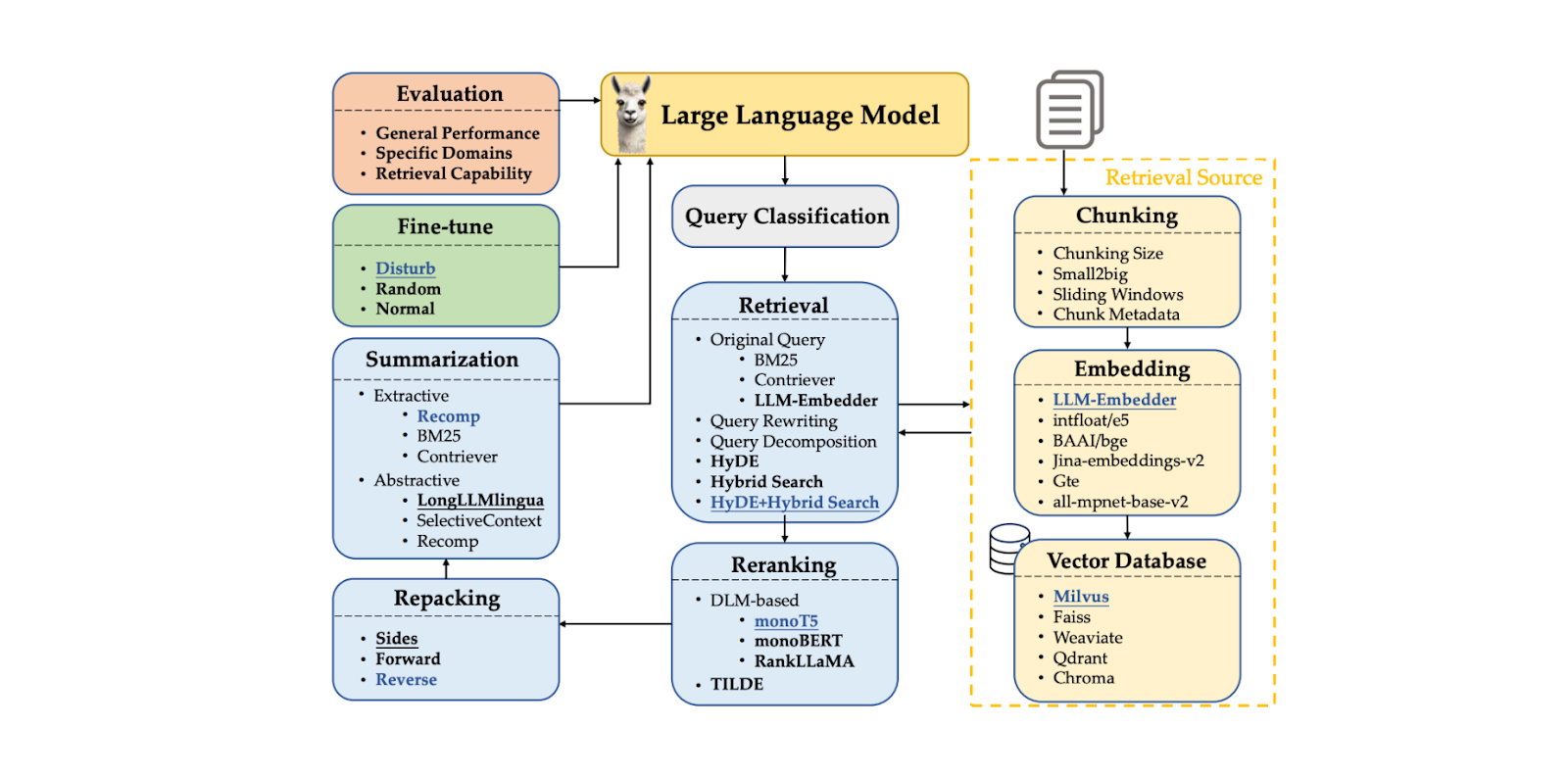 Рисунок - Компоненты RAG..png
Рисунок - Компоненты RAG..png
Фигура: RAG Components. Источник
Хотя эти компоненты RAG полезны в процессе генерации ответа (т. е. когда мы уже сохранили все контексты и они готовы к извлечению), перед реализацией метода RAG необходимо учесть еще несколько факторов.
Чтобы сделать наши контекстные документы полезными в RAG-подходе, нам необходимо преобразовать их в векторные вкрапления. Поэтому выбор [наиболее подходящей модели встраивания] (https://zilliz.com/blog/choosing-the-right-embedding-model-for-your-data) и стратегии представления наших входных документов в виде вкраплений имеет решающее значение.
Встраивание содержит семантически богатое представление нашего входного документа. Однако если документ, используемый в качестве контекста, слишком длинный, он может запутать LLM при генерации соответствующего ответа. Общий подход к решению этой проблемы заключается в применении метода chunking, при котором мы разбиваем входной документ на несколько фрагментов, а затем преобразуем каждый фрагмент во вкрапление. Очень важно выбрать оптимальный метод разбиения и размер фрагмента, поскольку слишком короткие фрагменты, скорее всего, будут содержать недостаточно информации.
 Рисунок - RAG workflow.png
Рисунок - RAG workflow.png
Рисунок: Рабочий процесс RAG
После того как мы преобразуем каждый чанк в эмбеддинг, мы должны подумать о подходящем хранилище для этих эмбеддингов. Если вы не имеете дело с большим количеством эмбеддингов, вы можете хранить их непосредственно в локальной памяти устройства. Однако на практике вы часто будете иметь дело с сотнями или даже миллионами вкраплений. В этом случае для их хранения вам понадобится векторная база данных, например Milvus или ее управляемый сервис Zilliz Cloud, и выбор правильной векторной базы данных имеет решающее значение для успеха нашего приложения RAG.
И последнее соображение - это сам LLM. Если это возможно, мы можем тонко настроить LLM для более точного удовлетворения наших конкретных потребностей. Однако в большинстве случаев тонкая настройка является дорогостоящей и ненужной, особенно если мы используем производительный LLM с большим количеством параметров.
В следующих разделах мы обсудим лучшие подходы для каждого компонента RAG. Далее мы рассмотрим комбинации этих лучших подходов и предложим несколько стратегий развертывания RAG, которые обеспечивают баланс между производительностью и эффективностью.
Классификация запросов
Как уже говорилось в предыдущем разделе, RAG полезен для обеспечения того, чтобы LLM генерировал точные и контекстуализированные ответы, особенно когда требуются специализированные знания из наших внутренних данных. Однако RAG также увеличивает время выполнения процесса генерации ответов. Дело в том, что не все запросы требуют процесса поиска, и многие из них могут быть обработаны LLM напрямую. Поэтому пропуск процесса поиска контекста будет более выгодным, если запрос в нем не нуждается.
Мы можем реализовать модель классификации запросов, чтобы определить, нуждается ли запрос в поиске контекста, до процесса генерации ответа. Такая модель классификации обычно состоит из контролируемой модели, такой как BERT, основной целью которой является предсказание того, нуждается ли запрос в извлечении или нет. Однако, как и другие контролируемые модели, мы должны обучить ее, прежде чем использовать для вывода. Чтобы обучить модель, нам нужно создать набор данных с примерами подсказок и соответствующими им бинарными метками, включая информацию о том, нуждается ли подсказка в поиске или нет.
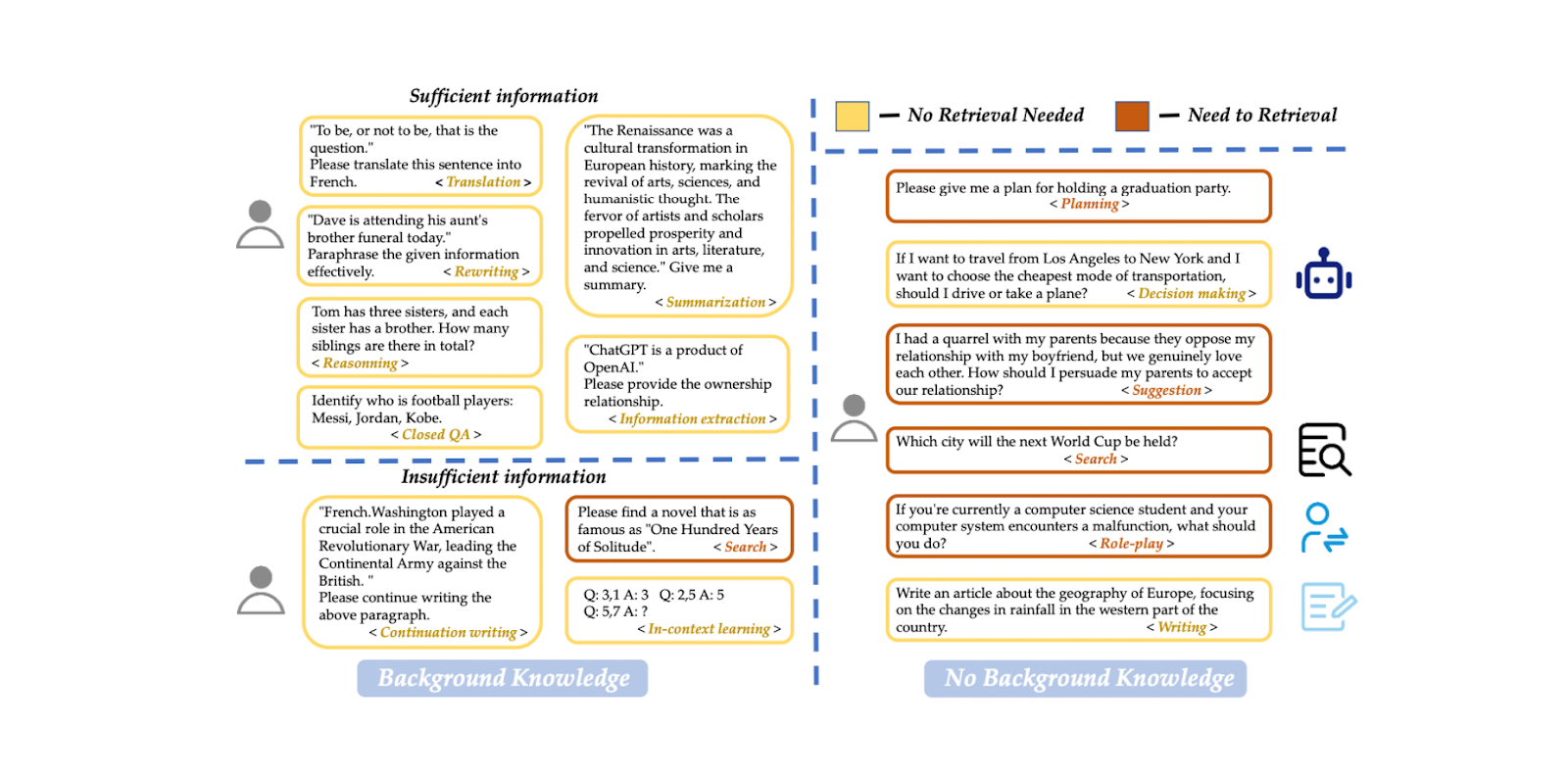 Рисунок - Пример набора данных для классификации запросов..png
Рисунок - Пример набора данных для классификации запросов..png
Рисунок: Query classification dataset example._ Источник
В статье для классификации запросов используется многоязычная модель на основе BERT. Обучающие данные включают в себя 15 типов подсказок, таких как перевод, обобщение, переписывание, обучение в контексте и т. д. Есть две разные метки: "достаточный", если подсказка полностью основана на информации, предоставленной пользователем, и не требует поиска, и "недостаточный", если информация в подсказке неполная, нуждается в специализированной информации и требует процесса поиска. Используя этот подход, модель достигла 95 % как по точности, так и по F1 score.
Этот шаг классификации запросов может значительно повысить эффективность процесса RAG, избегая ненужных поисков по запросам, которые могут быть обработаны непосредственно LLM. Он действует как фильтр, гарантируя, что только запросы, требующие дополнительного контекста, будут отправлены через более трудоемкий процесс поиска.
 Рисунок - Результат работы классификатора запросов..png
Рисунок - Результат работы классификатора запросов..png
_Рисунок: Результат классификатора запросов.png](https://arxiv.org/pdf/2407.01219)
Техника разбиения на части
Chunking относится к процессу разбиения длинных входных документов на более мелкие сегменты. Этот процесс очень полезен для обеспечения LLM более детальным контекстом. Существует несколько методов разбиения, включая подходы на уровне лексем и на уровне предложений. Кускование на уровне предложений часто приводит к хорошему балансу между простотой и сохранением семантического контекста. Выбирая метод фрагментации, мы должны быть осторожны с размером фрагмента, так как слишком короткие фрагменты могут не обеспечить полезный контекст для LLM.
 Рисунок - Разбиение длинного документа на более мелкие фрагменты.png
Рисунок - Разбиение длинного документа на более мелкие фрагменты.png
Рисунок: Разделение длинного документа на более мелкие фрагменты_
Чтобы найти оптимальный размер фрагмента, была проведена оценка на документе Lyft 2021. Первые 60 страниц документа были выбраны в качестве корпуса и разбиты на фрагменты нескольких размеров. Затем с помощью LLM было сгенерировано 170 запросов на основе этих 60 страниц. Модель text-embedding-ada-002 была использована для вкраплений, а модель Zephyr 7B - в качестве LLM для генерации ответов на основе выбранных запросов.
Для оценки производительности модели на различных размерах чанков использовался GPT-3.5 Turbo. Для оценки качества ответов использовались две метрики: верность и релевантность. Верность измеряет, является ли ответ галлюцинацией или соответствует найденным контекстам, в то время как релевантность измеряет, соответствуют ли найденные контексты и ответы запросам.
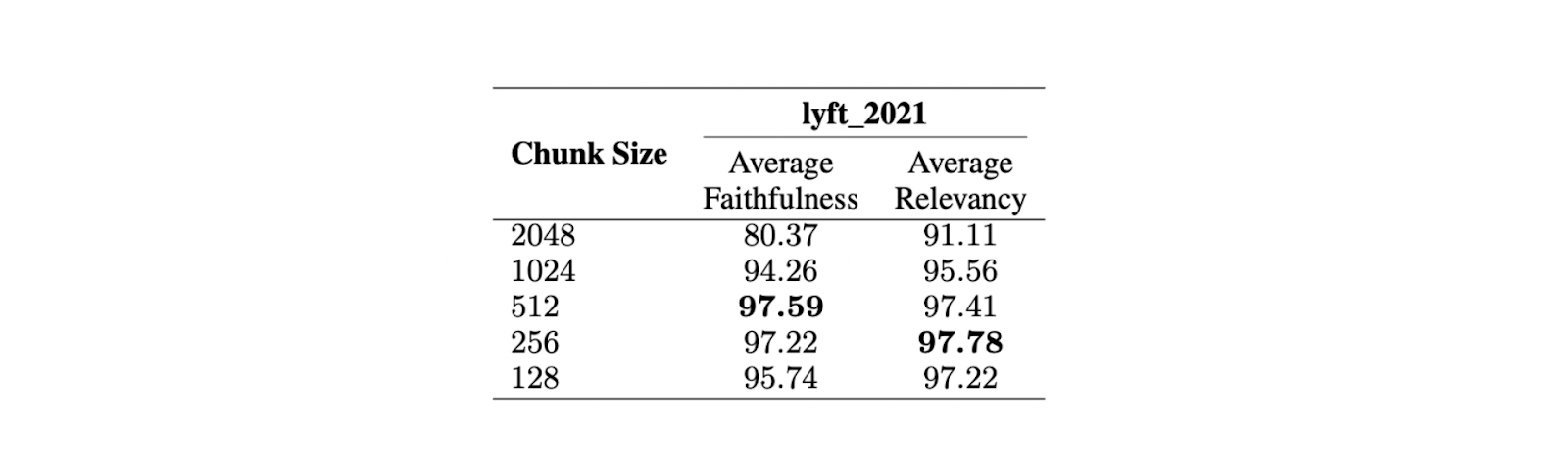 Рисунок - Сравнение различных размеров чанков. .png
Рисунок - Сравнение различных размеров чанков. .png
Рисунок: Сравнение различных размеров чанков. Источник
Результаты показывают, что максимальный размер чанка в 512 лексем предпочтительнее для генерации высоко релевантных ответов из LLM. Более короткие куски, например 256 лексем, также хорошо работают и могут улучшить общее время работы приложения RAG. Для сочетания преимуществ разных размеров кусков можно использовать расширенные техники разбиения, такие как small2big и скользящие окна.
Small2big - это подход к чанкингу, который организует отношения между блоками чанков. Чанки малого размера используются для сопоставления запросов, а большие чанки, содержащие информацию из меньших, используются в качестве конечного контекста для LLM. Скользящее окно - это метод разбиения на блоки, который обеспечивает перекрытие маркеров между блоками для сохранения информации о контексте.
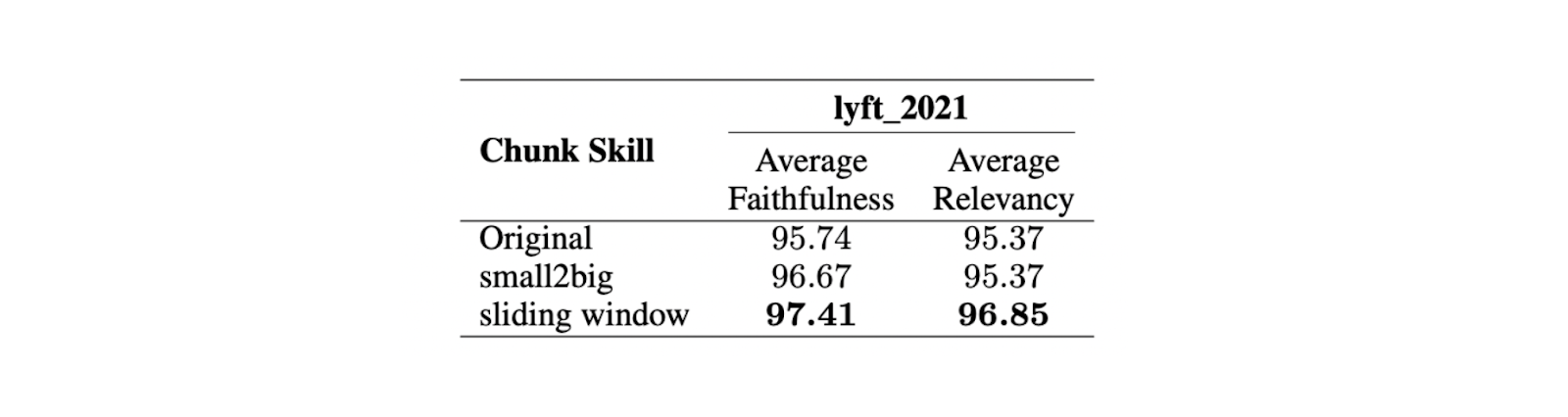 Рисунок - Сравнение различных техник разбиения на части..png
Рисунок - Сравнение различных техник разбиения на части..png
_Рисунок: Сравнение различных методов разбиения на части.png](https://arxiv.org/pdf/2407.01219)
Эксперименты показывают, что при меньшем размере фрагмента в 175 лексем, большем размере фрагмента в 512 лексем и перекрытии фрагментов в 20 лексем оба метода фрагментации улучшают показатели верности и релевантности ответов LLM.
Далее необходимо найти наилучшую модель встраивания для представления каждого чанка в виде векторного встраивания. Для этого был проведен тест на namespace-Pt/msmarco. Результаты показывают, что лучше всего работают модели LLM Embedder и bge-large-en. Однако, поскольку LLM Embedder в три раза меньше, чем bge-large-en, она была выбрана в качестве вставки по умолчанию для эксперимента.
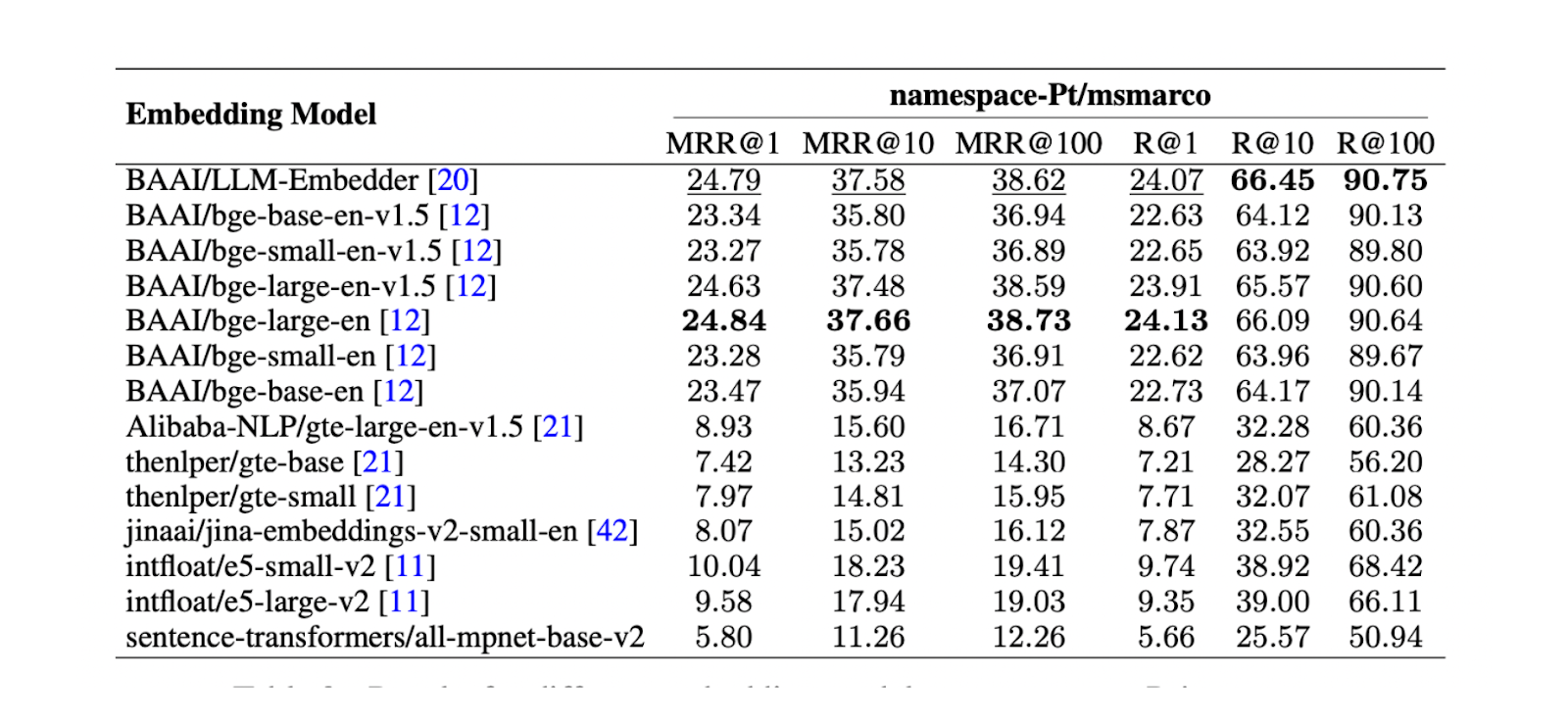 Рисунок - Результаты для различных моделей встраивания на namespace-Pt:msmarco. .png
Рисунок - Результаты для различных моделей встраивания на namespace-Pt:msmarco. .png
Рисунок: Результаты для различных моделей встраивания на namespace-Ptmsmarco. Источник
Векторные базы данных
Векторные базы данных играют важную роль в RAG-приложениях, особенно в хранении и извлечении релевантных контекстов. В обычных реальных приложениях RAG мы имеем дело с огромным количеством документов, что приводит к огромному количеству контекстных вкраплений, которые необходимо хранить. В таких случаях хранения этих вкраплений в локальной памяти недостаточно, а вычисления для поиска релевантных контекстов среди больших коллекций вкраплений занимают значительное время.
Векторные базы данных предназначены для решения этих проблем. Векторная база данных позволяет хранить миллионы и даже миллиарды векторных вкраплений и выполнять поиск контекста за доли секунды. При выборе лучшей векторной базы данных для вашего случая использования необходимо учитывать несколько факторов, таких как поддержка типов индексов, поддержка векторов миллиардного масштаба, поддержка гибридного поиска и возможности облачных вычислений.
Среди этих критериев Milvus выделяется как лучшая векторная база данных с открытым исходным кодом по сравнению с такими конкурентами, как Weaviate, Chroma, Faiss, Qdrant и т. д.
 Сравнение различных векторных баз данных..png
Сравнение различных векторных баз данных..png
Сравнение различных векторных баз данных. Источник.
Что касается поддержки типов индексов, Milvus предлагает несколько методов индексирования для удовлетворения различных потребностей, таких как наивный плоский индекс (FLAT) или другие типы индексирования, разработанные для ускорения процесса поиска, такие как инвертированный файловый индекс (IVF-FLAT) и иерархический навигационный малый мир (HNSW). Чтобы сжать память, необходимую для хранения контекстов, можно также реализовать квантование произведения (PQ) в процессе индексации вкраплений.
Milvus также поддерживает подход гибридного поиска. Этот подход позволяет нам комбинировать два различных метода в процессе поиска контекста. Например, мы можем сочетать плотное встраивание с разреженным встраиванием для получения релевантных контекстов, повышая релевантность найденного контекста по отношению к запросу. Это, в свою очередь, также улучшает ответ, генерируемый LLM. Кроме того, при желании мы можем сочетать плотное встраивание с фильтрацией метаданных.
Если вы хотите использовать Milvus в облаке, будь то GCP или AWS, для хранения миллиардов вкраплений, вы можете выбрать управляемый сервис: Zilliz Cloud.
В Zilliz Cloud вы можете создавать кластеры (CU), оптимизированные как по емкости, так и по производительности, для хранения крупных эмбеддингов. Например, можно создать 256 CU, оптимизированных по производительности и обслуживающих 1,3 миллиарда 128-мерных векторов, или 128 CU, оптимизированных по емкости и обслуживающих 3 миллиарда 128-мерных векторов.
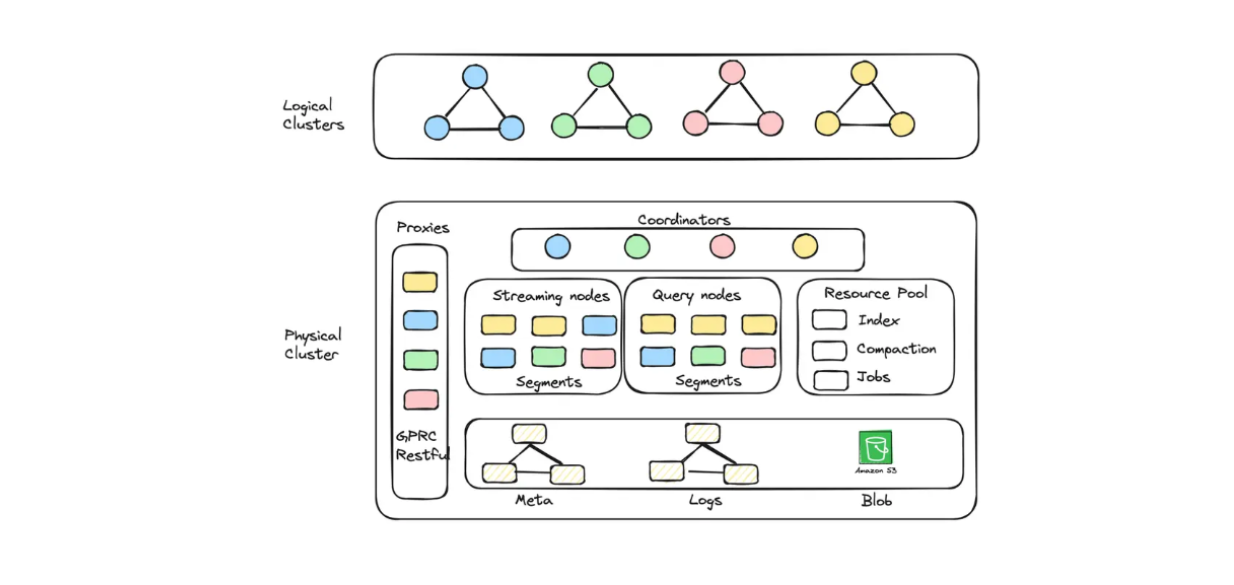 Диаграмма логического кластера и автомасштабирования, реализованная в Zilliz Cloud Serverless..png
Диаграмма логического кластера и автомасштабирования, реализованная в Zilliz Cloud Serverless..png
Диаграмма логического кластера и автомасштабирования, реализованная в Zilliz Cloud Serverless._
Если вы хотите создать RAG-приложение с помощью Milvus, но при этом сэкономить на эксплуатационных расходах, вы можете выбрать Zilliz Cloud Serverless. Эта услуга обеспечивает функцию автоматического масштабирования в Milvus, при этом затраты увеличиваются только по мере роста вашего бизнеса. Бессерверный вариант также идеально подходит для экономии средств, поскольку вы платите только тогда, когда пользуетесь услугой, а не когда она простаивает.
В последнее время Zilliz Cloud выпустила несколько интересных обновлений, включая новую службу миграции, несколько реплик, новую интеграцию с коннекторами Fivetran, возможность автоматического масштабирования и множество других функций, готовых к работе. Более подробную информацию вы найдете ниже:
Разблокируйте поиск на основе искусственного интеллекта с помощью Fivetran и Milvus
5 причин перейти с Milvus с открытым исходным кодом на Zilliz Cloud
Методы поиска
Основная цель компонента поиска - получить k наиболее релевантных контекстов по заданному запросу. Однако значительная проблема в этом компоненте, которая может повлиять на общее качество нашей RAG, исходит от самого запроса. Оригинальные запросы часто плохо написаны или плохо выражены, в них отсутствует семантическая информация, необходимая приложениям RAG для поиска релевантных контекстов.
Для решения этой проблемы обычно применяются следующие техники:
Переписывание запроса: Предлагает LLM переписать исходный запрос, чтобы улучшить его ясность и семантическую информацию.
Декомпозиция запроса:** Декомпозиция исходного запроса на подзапросы и выполнение поиска на основе этих подзапросов.
Генерация псевдодокументов: Генерирует гипотетические или синтетические документы на основе исходного запроса, а затем использует эти гипотетические документы для поиска похожих документов в базе данных. Наиболее известной реализацией этого подхода является HyDE (Hypothetical Document Embeddings).
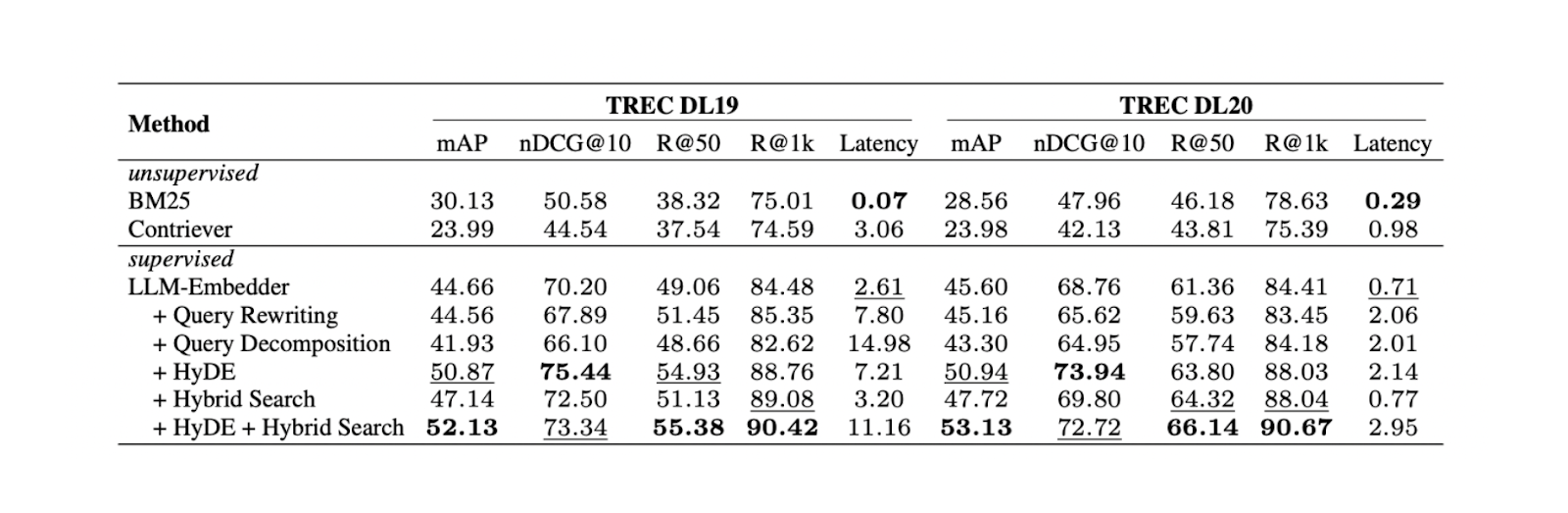
Эксперименты показали, что сочетание HyDE и гибридного поиска дает лучшие результаты в TREC DL19/20 по сравнению с переписыванием и декомпозицией запросов. Гибридный поиск, упомянутый в эксперименте, сочетает LLM Embedder для получения плотных вкраплений и BM25 для получения разреженных вкраплений.
Процесс работы HyDe + гибридного поиска выглядит следующим образом: сначала мы генерируем гипотетический документ, отвечающий на запрос с помощью HyDE. Затем этот гипотетический документ конкатенируется с исходным запросом и преобразуется в плотные и разреженные вкрапления с помощью LLM Embedder и BM25, соответственно.
 Результаты для различных методов поиска. .png
Результаты для различных методов поиска. .png
Результаты применения различных методов поиска. Источник
Хотя комбинация HyDE и гибридного поиска дает наилучшие результаты, она также связана с большими вычислительными затратами. По результатам дальнейших тестов на нескольких наборах данных NLP, гибридный поиск и использование только плотных вкраплений дают результаты, сравнимые с HyDE + гибридный поиск, но почти в 10 раз меньшую задержку. Поэтому рекомендуется использовать гибридный поиск.
Поскольку мы используем гибридный поиск, найденные контексты основаны на векторном поиске из плотных и разреженных вкраплений. Поэтому интересно также изучить влияние весового коэффициента между плотными и разреженными вкраплениями на общую оценку релевантности в соответствии с этим уравнением:
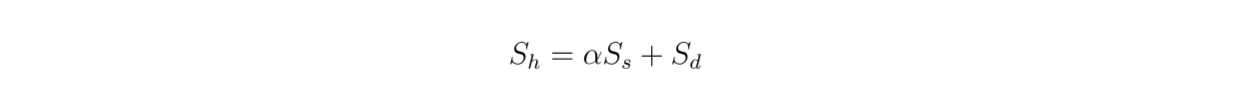 formula.png
formula.png
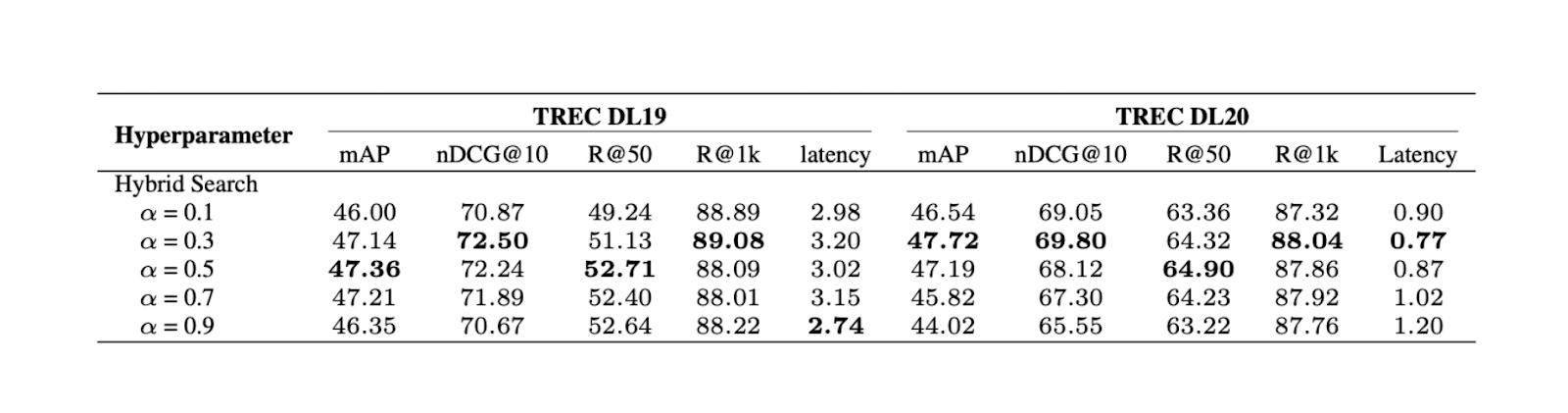 Рисунок - Результаты гибридного поиска с различными значениями альфа..png
Рисунок - Результаты гибридного поиска с различными значениями альфа..png
Рисунок: Результаты гибридного поиска с различными значениями альфа-спектра.png](https://arxiv.org/pdf/2407.01219)._
Эксперимент показывает, что значение весового коэффициента 0,3 дает наилучший общий балл релевантности в TREC DL19/20.
Техники реранжирования и переупаковки
Основная цель reranking techniques - переупорядочить k наиболее релевантных контекстов, полученных методом поиска, чтобы гарантировать, что наиболее похожий контекст будет возвращен в верхней части списка. Существует два общих подхода к упорядочиванию контекстов:
DLM Reranking: Этот метод использует модель глубокого обучения для реранжирования. Модель обучается, получая на вход пару, состоящую из исходного запроса и контекста, а на выходе - бинарную метку "true" (если пара релевантна друг другу) или "false". Затем контексты сортируются в зависимости от вероятности, с которой модель предсказывает пару запроса и контекста как "истинную".
Реранжирование по ТИЛДЕ: Этот подход использует вероятность каждого термина в исходном запросе для ранжирования. Во время вывода мы можем использовать либо только компонент вероятности запроса (TILDE-QL) для более быстрого ранжирования, либо комбинацию TILDE-QL с компонентом вероятности документа (TILDE-DL) для улучшения результата ранжирования при более высоких вычислительных затратах.
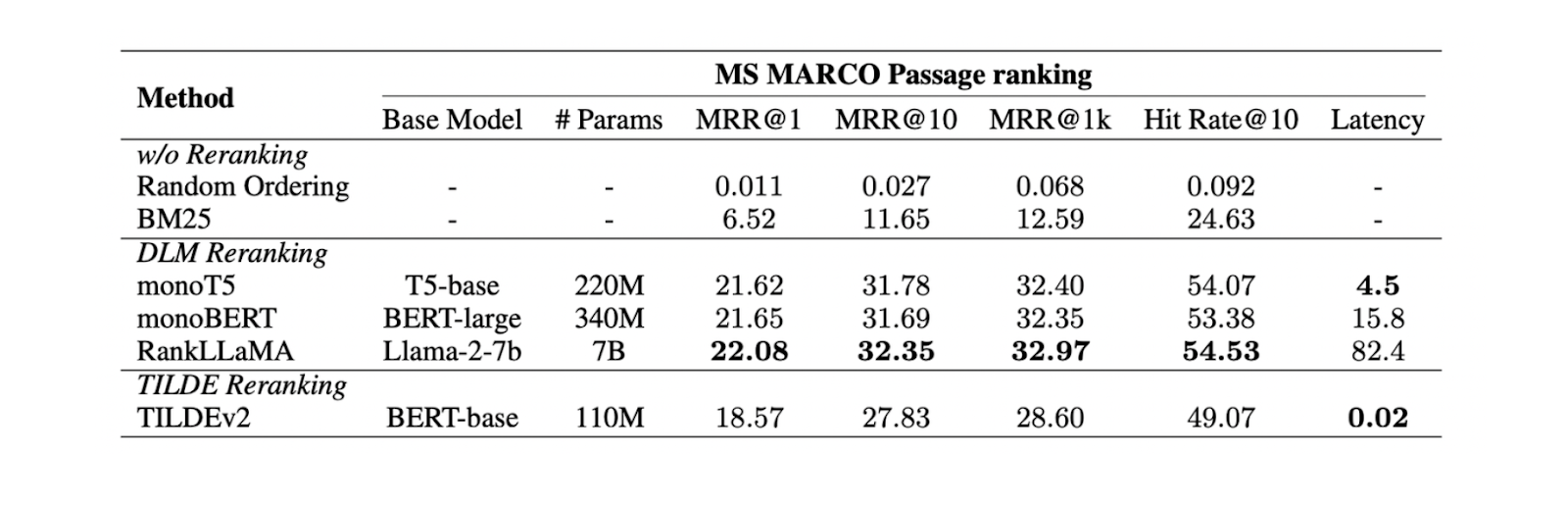 Рисунок - Результаты различных методов ранжирования..png
Рисунок - Результаты различных методов ранжирования..png
Рисунок: Результаты различных методов ранжирования. Источник
Эксперименты на наборе данных MS MARCO Passage показывают, что метод реранкинга DLM с моделью Llama 27B дает наилучшие результаты реранкинга. Однако, поскольку эта модель имеет большой размер, ее использование связано со значительными вычислительными затратами. Поэтому для DLM-рерайтинга рекомендуется использовать модель mono T5, так как она обеспечивает баланс между производительностью и вычислительной эффективностью.
После этапа ранжирования нам также необходимо подумать о том, как представлять ранжированные контексты нашему LLM: в нисходящем ("прямом") или восходящем ("обратном") порядке. На основе экспериментов, проведенных в данной статье, можно сделать вывод, что наилучшее качество ответа достигается при использовании "обратной" конфигурации. Гипотеза заключается в том, что расположение более релевантного контекста ближе к запросу приводит к оптимальному результату.
Методы суммирования
В случаях, когда у нас есть длинные контексты, извлеченные из предыдущих компонентов, мы можем захотеть сделать их более компактными и удалить избыточную информацию. Для достижения этой цели обычно применяются подходы к обобщению.
Существует две различные техники обобщения контекста: экстрактивный и абстрактивный.
Экстрактивное обобщение разбивает входной документ на более мелкие сегменты, которые затем ранжируются по степени важности. В то же время абстрактный метод генерирует новое контекстное резюме, содержащее только релевантную информацию.
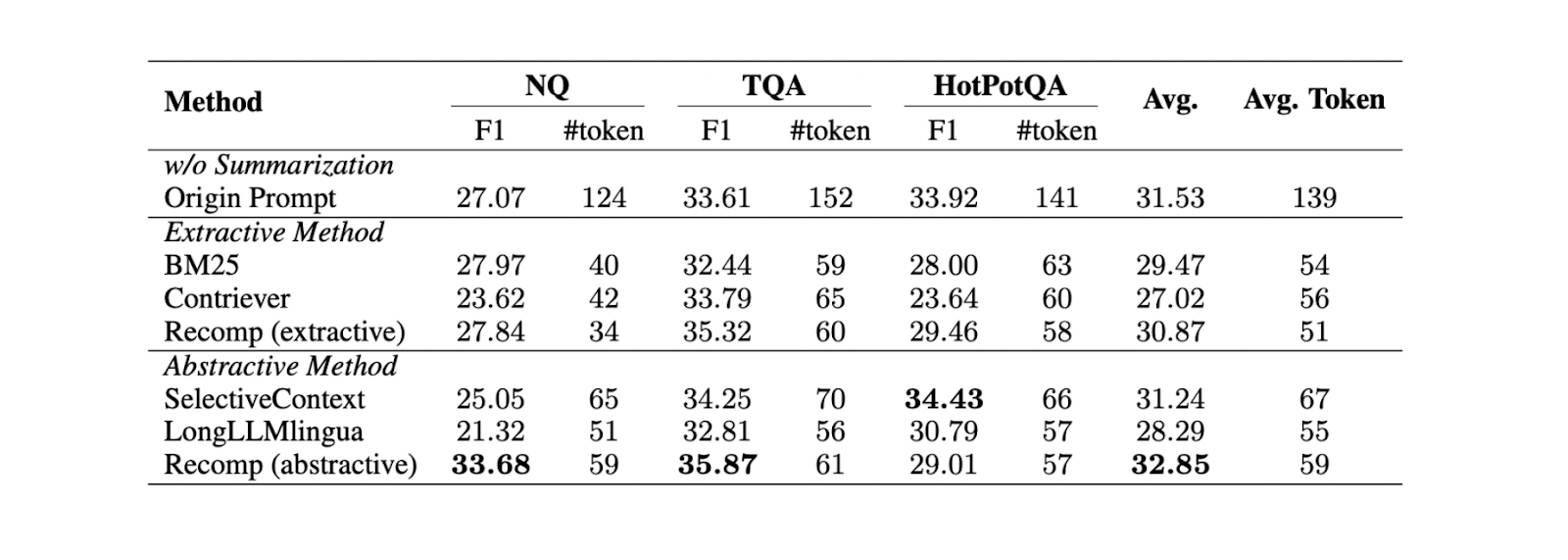 Рисунок - Сравнение различных методов обобщения..png
Рисунок - Сравнение различных методов обобщения..png
_Рисунок: Сравнение различных методов суммирования.png](https://arxiv.org/pdf/2407.01219)
По результатам экспериментов на трех различных наборах данных (NQ, TriviaQA и HotpotQA), абстрактное обобщение с помощью Recomp дает наилучшую производительность по сравнению с другими абстрактными и экстрактивными методами.
Резюме лучших методов RAG
Теперь, когда мы знаем лучший подход для каждого компонента RAG для конкретных эталонных наборов данных, мы можем продолжить тестирование всех подходов, упомянутых в предыдущих разделах, на большем количестве наборов данных. Результаты показывают, что каждый компонент вносит свой вклад в общую производительность нашего приложения RAG. Ниже приведены результаты для каждого подхода в каждом компоненте на основе пяти различных наборов данных:
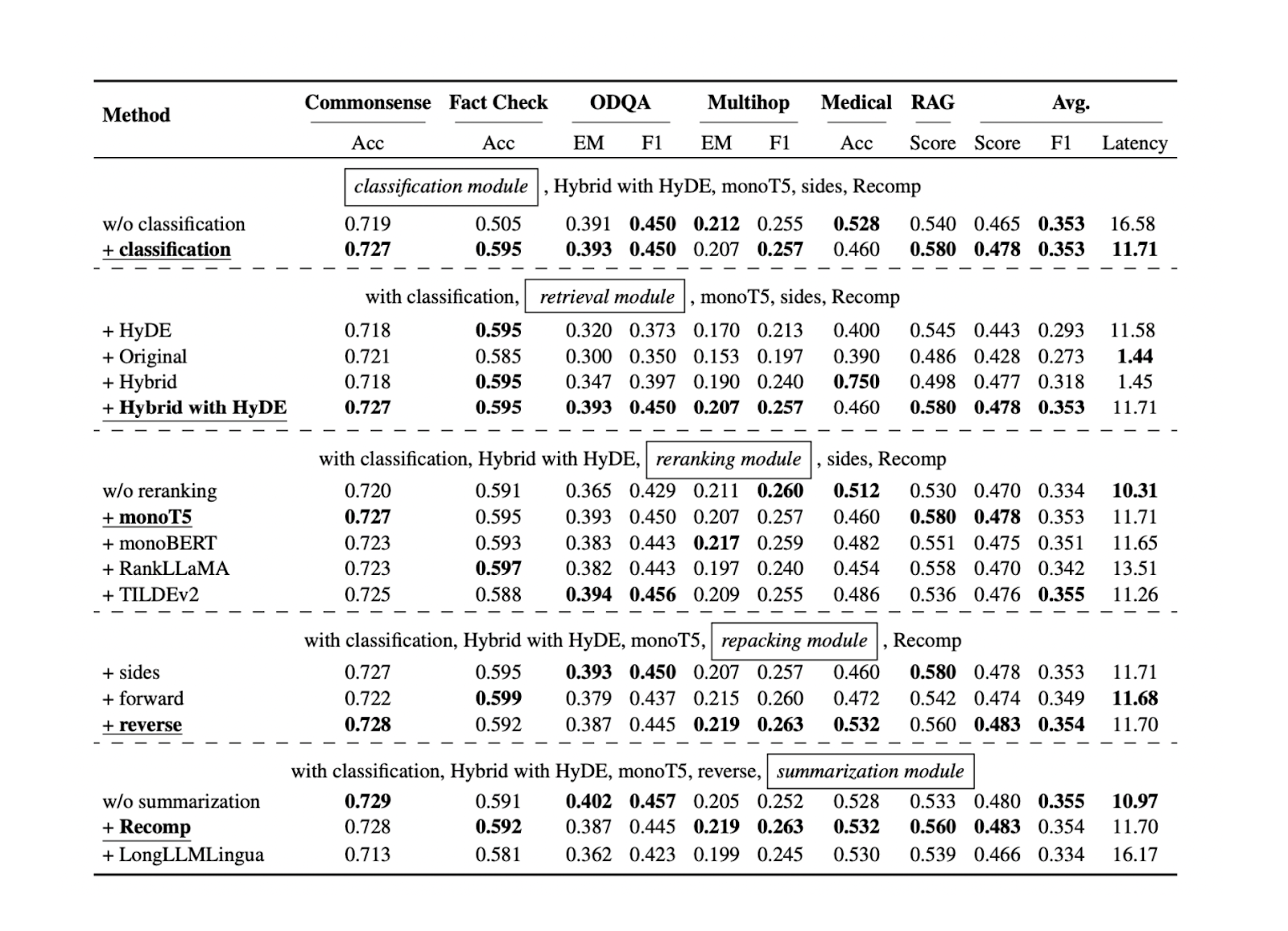 Рисунок - Результаты поиска оптимальных практик RAG..png
Рисунок - Результаты поиска оптимальных практик RAG..png
Рисунок: Результаты поиска оптимальных практик RAG. Источник
Компонент классификации запросов помогает повысить точность ответов и снизить общую задержку выполнения. Этот начальный шаг помогает определить, требует ли запрос контекстного поиска или может быть обработан непосредственно LLM, оптимизируя таким образом эффективность системы.
Компонент поиска имеет решающее значение для обеспечения получения релевантных контекстных кандидатов по отношению к запросу. Для этого компонента рекомендуется использовать более масштабируемую и производительную векторную базу данных, например Milvus или ее управляемый сервис Zilliz Cloud. Кроме того, рекомендуется использовать гибридный поиск или поиск с плотным вкраплением. Эти методы позволяют найти баланс между всесторонним подбором контекста и вычислительной эффективностью.
Компонент ранжирования обеспечивает получение наиболее релевантных контекстов путем переупорядочивания k лучших контекстов, полученных в результате работы компонента поиска. Модель monoT5 рекомендуется для ранжирования благодаря балансу производительности и вычислительных затрат. Этот шаг позволяет уточнить выбор контекстов, отдавая предпочтение наиболее релевантным контекстам для запроса.
Для переупаковки контекстов рекомендуется использовать обратный метод. Этот подход позволяет расположить наиболее релевантный контекст ближе всего к запросу, что потенциально приводит к более точным и согласованным ответам LLM.
Наконец, абстрактный метод с Recomp показал наилучшие результаты при обобщении контекста. Этот метод помогает сократить длинные контексты, сохраняя при этом ключевую информацию, что облегчает обработку и генерацию релевантных ответов для LLM.
Тонкая настройка LLM
В большинстве случаев тонкая настройка LLM не требуется, особенно если вы используете производительный LLM с большим количеством параметров. Однако если у вас есть аппаратные ограничения и вы можете использовать только небольшие LLM, вам может потребоваться их тонкая настройка, чтобы сделать их более надежными при генерации ответов, связанных с вашим сценарием использования. Прежде чем приступить к тонкой настройке LLM, необходимо продумать, какие данные вы будете использовать в качестве обучающих.
Во время подготовки данных вы можете собрать обучающие данные в виде подсказки и контекста в качестве пары входов, а в качестве выхода - пример сгенерированного текста. Эксперименты показывают, что добавление к данным смеси релевантных и случайно выбранных контекстов во время обучения приводит к наилучшей производительности. Интуиция подсказывает, что смешение релевантных и случайных контекстов в процессе тонкой настройки может повысить устойчивость нашего LLM.
Заключение
В этой статье мы рассмотрели различные компоненты RAG, от классификации запросов до обобщения контекста. Мы обсудили и выделили подходы с оптимальной производительностью в каждом компоненте.
Эти оптимизированные компоненты работают вместе, чтобы улучшить общую производительность системы RAG. Они повышают качество и релевантность генерируемых ответов, сохраняя при этом эффективность вычислений. Реализовав эти лучшие практики в каждом компоненте, мы сможем создать более надежную и эффективную систему RAG, способную обрабатывать широкий спектр запросов и задач.
Дальнейшее чтение
Читать далее

How to Install and Run OpenClaw (Previously Clawdbot/Moltbot) on Mac
Turn your Mac into an AI gateway for WhatsApp, Telegram, Discord, iMessage, and more — in under 5 minutes.

DeepSeek-OCR Explained: Optical Compression for Scalable Long-Context and RAG Systems
Discover how DeepSeek-OCR uses visual tokens and Contexts Optical Compression to boost long-context LLM efficiency and reshape RAG performance.

Demystifying the Milvus Sizing Tool
Explore how to use the Sizing Tool to select the optimal configuration for your Milvus deployment.