




ANNベンチマーク総合ガイド:Approximate Nearest Neighbor Search(ANNS)性能の評価
ANNベンチマーク総合ガイド:Approximate Nearest Neighbor Search(ANNS)性能の評価
数十億もの画像、テキスト文書、その他の非構造化データを含むデータベースから、最も類似したアイテムを素早く見つける必要がある検索エンジンを構築していると想像してみてください。検索アルゴリズムが正確な結果を返すだけでなく、それを超高速で実行するにはどうすればよいでしょうか?ここで Approximate Nearest Neighbor(ANN)検索が重要になります。ANN検索は、レコメンデーションシステムから大規模な画像検索まで、多くの実世界のアプリケーションにおいて不可欠です。
市場には非常に多くのANN検索ソリューションがありますが、特に大規模環境において、異なるANNアルゴリズムの有効性をどのように評価すればよいのでしょうか?そこで登場するのがANN Benchmarksです。これは、大規模データセット上でANN検索手法の性能をテストするためのゴールドスタンダードとなっています。
このブログでは、ANNベンチマークとは何か、なぜ重要なのか、そして開発者やアルゴリズムエンジニアが目的に合ったベクトル検索ソリューションを選ぶうえでどのように役立つのかを解説します。また、現在使用されている最も人気のあるベンチマークの一部と、それらがベクトル検索において不可欠である理由についても見ていきます。
ANN検索とは何か、どのように機能するのか?
ベンチマークに入る前に、Approximate Nearest Neighbor(ANN)Search、つまりANNSとは何か、そしてそれがどのように動作するのかを理解することが重要です。ANN Searchは、機械学習(ML)における強力な手法であり、Zilliz Cloudのようなベクトルデータベースによく見られる大規模データセット内で、効率的なセマンティック類似性検索を可能にします。データセット内で、与えられたクエリアイテムに最も近いアイテムを素早く見つけることができます。100%の精度を保証する厳密検索手法とは異なり、ANNSは速度とスケーラビリティを大幅に向上させる代わりに、わずかな精度をトレードオフします。
ANN検索の仕組み:
データ表現: データセット内の各アイテムは、多次元空間内のベクトルとして表現されます。ベクトルは通常、OpenAI text embedding models、Cohere multilingual models、OpenAI multimodal modelsなどの埋め込みモデルによってエンコードされます。たとえば、画像は色や形状などの特徴を持つベクトルとして、128次元空間で表現される場合があります。
クエリ処理: クエリが行われると、ANN Searchアルゴリズムは、処理を高速化するために近似を用いながら、クエリベクトルに近いベクトルをデータセットから取得します。
結果ランキング: アルゴリズムは、高次元空間におけるクエリからの距離に基づいて最近傍をランク付けします。多くの場合、ユークリッド距離やコサイン類似度のような指標が使用されます。ベクトル同士が近くに位置しているほど、それらはより類似しており、関連性が高いとみなされます。
効率性: ANN Searchの主な利点は、厳密検索にかかる時間のごく一部で結果を提供できる点であり、大規模データセットに最適です。
ANNS手法は、最近傍を迅速に近似するためにさまざまな戦略を使用します。
木ベースの手法: KD-TreeやBall Treeなどの手法は、検索プロセスを簡素化するためにデータを階層的に整理します。低次元では効果的ですが、次元数が増えるにつれて性能は低下します。
ハッシング手法: Locality-sensitive hashing (LSH)は、類似したデータポイントを同じハッシュバケットにグループ化し、検索時に必要な比較回数を削減します。
グラフベースの手法: Navigable Small World (NSW) グラフやHierarchical Navigable Small World (HNSW) グラフのようなアルゴリズムは、データポイントのネットワークを作成して近傍探索を高速化します。
量子化手法: Product Quantization (PQ) などの手法は、データをより扱いやすい形式に圧縮し、検索効率を高めます。
これらの手法を活用することで、ANNSアルゴリズムは検索精度と性能のバランスを取ることができ、大規模データセットに適したものになります。
ANN検索とKNN検索の比較
厳密なK近傍法検索(KNN)と近似最近傍探索(ANNS)は、ベクトル検索で使用される2つの基本的なアプローチであり、それぞれに利点とトレードオフがあります。
厳密なKNNは、クエリポイントとデータセット内のすべてのデータポイントとの距離を評価することで正確な結果を提供し、特定された近傍が可能な限り最も近いことを保証します。しかし、この手法は総当たり的な性質により、特に大規模データセットや高次元空間を扱う場合、計算負荷が高く遅くなる可能性があります。そのため、厳密なKNNは、小規模データセットや、精度が最重要で計算リソースがそれほど問題にならないシナリオに適しています。
これに対して、ANNSは、ある程度の精度を犠牲にして高速な性能を得ることで、大規模データを扱うための実用的なソリューションを提供します。ANNSは、木ベースの構造、ハッシング手法、グラフベースのアプローチなど、さまざまなアルゴリズムや手法を用いて、最近傍を効率的に近似します。このアプローチは計算コストを大幅に削減し、巨大なデータセットにも適切にスケールするため、検索エンジンや推薦システムのように速度が重要なリアルタイムアプリケーションに最適です。ANNSは常に厳密な最近傍を提供するとは限りませんが、ほぼ正確な結果を迅速に提供できる能力により、現代のデータ検索および分析タスクにおいて価値あるツールとなっています。
詳細については、ANNS用語集ページをご覧ください。
ANN Benchmarkとは?
ANN Benchmarkは、さまざまなANNSアルゴリズムの性能を測定・比較するために設計された包括的な評価ツールです。 ann-benchmarks.comでホストされており、ANNS手法のさまざまな側面を評価するための標準化されたテストと指標を提供しています。これには以下が含まれます。
検索速度: アルゴリズムが最近傍をどれだけ迅速に見つけられるか。
精度: アルゴリズムの結果が真の最近傍にどの程度近似しているか。
スケーラビリティ: データセットのサイズや次元数が増加したときに、アルゴリズムがどれだけ適切に機能するか。
このベンチマークは、さまざまなデータセットと評価基準を提供し、開発者が公平な条件下でさまざまな状況における異なるアルゴリズムの有効性を評価できるようにします。
ANNベンチマークにおける主要な指標:
Recall: アルゴリズムによって正常に取得された真の最近傍の割合。高いRecallは、より高い精度を示します。
検索時間: アルゴリズムが結果を返すまでにかかる時間。リアルタイム応答を必要とするアプリケーションでは、より速い検索時間が極めて重要です。
メモリ使用量: アルゴリズムがデータセットを保存および検索するために必要とするメモリ量。効率的なメモリ使用は、スケーラビリティにとって重要です。
スケーラビリティ: データセットのサイズが増加してもアルゴリズムが性能を維持できる能力。データセットが急速に増加する可能性がある実世界のアプリケーションでは、スケーラビリティは重要な要因です。
ANN Benchmarks で使用される主要なデータセット
ANN Benchmark は、多様なデータセットを使用してアルゴリズムをテストします。これらのデータセットは、画像特徴量、テキスト埋め込み、合成データなど、さまざまな領域をカバーしています。ベンチマークで使用される主要なデータセットには、次のものがあります。
| データセット | 次元数 | 訓練サイズ | テストサイズ | 近傍数 | 距離 | ダウンロード |
|---|---|---|---|---|---|---|
| DEEP1B | 96 | 9,990,000 | 10,000 | 100 | 角距離 | HDF5 (3.6GB) |
| Fashion-MNIST | 784 | 60,000 | 10,000 | 100 | ユークリッド | HDF5 (217MB) |
| GIST | 960 | 1,000,000 | 1,000 | 100 | ユークリッド | HDF5 (3.6GB) |
| GloVe | 25 | 1,183,514 | 10,000 | 100 | 角距離 | HDF5 (121MB) |
| GloVe | 50 | 1,183,514 | 10,000 | 100 | 角距離 | HDF5 (235MB) |
| GloVe | 100 | 1,183,514 | 10,000 | 100 | 角距離 | HDF5 (463MB) |
| GloVe | 200 | 1,183,514 | 10,000 | 100 | 角距離 | HDF5 (918MB) |
| Kosarak | 27,983 | 74,962 | 500 | 100 | ジャッカード | HDF5 (33MB) |
| MNIST | 784 | 60,000 | 10,000 | 100 | ユークリッド | HDF5 (217MB) |
| MovieLens-10M | 65,134 | 69,363 | 500 | 100 | ジャッカード | HDF5 (63MB) |
| NYTimes | 256 | 290,000 | 10,000 | 100 | 角距離 | HDF5 (301MB) |
| SIFT | 128 | 1,000,000 | 10,000 | 100 | ユークリッド | HDF5 (501MB) |
| Last.fm | 65 | 292,385 | 50,000 | 100 | 角距離 | HDF5 (135MB) |
テスト済みのANNアルゴリズムまたはベクトル検索エンジン
ANN Benchmarksは、Annoy、Faiss、Knowhere(Milvusの検索エンジン)、Glass(Zilliz Cloudのレガシー検索エンジン)など、幅広いANNアルゴリズムとベクトル検索エンジンを評価してきました。テスト済みアルゴリズムの数は増え続けています。以下は、2024年9月時点でテスト済みのアルゴリズムと検索エンジンの一覧です。
scikit-learn: LSHForest, KDTree, BallTree
NMSLIB (Non-Metric Space Library) : SWGraph, HNSW, BallTree, MPLSH
NGT : ONNG, PANNG, QG
Elasticsearch : HNSW
DiskANN : Vamana, Vamana-PQ
scipy: cKDTree
注: Zilliz CloudはCardinalという新しい検索エンジンをリリースしました。これは従来のGlassエンジンの3倍のパフォーマンスを提供し、Milvusの最大10倍の検索スループット(QPS)を実現します。しかし、時間的制約やその他の要因により、CardinalのパフォーマンスはANNベンチマーク結果には含まれていません。次のセクションでは、VectorDBBenchを使用してそのパフォーマンスを確認できます。
ベンチマーク結果
以下のグラフは、GIST1Mデータセット(960次元の100万ベクトル)に基づくさまざまなアルゴリズムの再現率/秒間クエリ数のテスト結果を示しています。x軸に再現率、y軸にQPSをプロットし、検索精度の異なるレベルにおける各アルゴリズムのパフォーマンスを示しています。
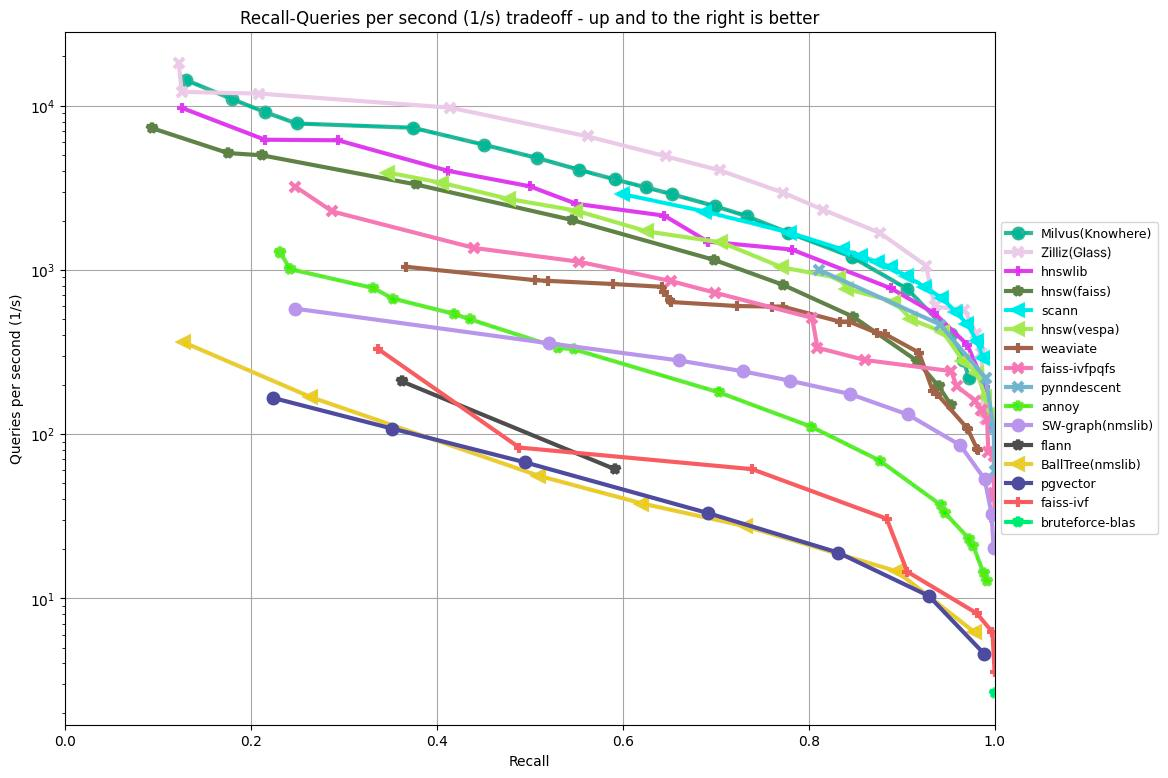 図1: GIST1MデータセットにおけるANNベンチマーク結果
図1: GIST1MデータセットにおけるANNベンチマーク結果
図1: GIST1MデータセットにおけるANNベンチマーク結果
上のグラフに示された結果によると、960次元の1,000,000ベクトルを処理した際、Knowhere(Milvusの検索エンジン)、Glass(Zilliz Cloudの従来の検索エンジン)、およびHNSWライブラリが上位3つの最良の結果を達成しました。
さらなるベンチマーク結果については、ANN-Benchmarkのウェブサイトをご覧ください。
VectorDBBench: ベクトルデータベース向けオープンソースベンチマークツール
ベクトル検索、またはベクトル類似検索は、データセット内で類似するベクトルを見つけるプロセスを指す、より広い概念です。ANNS は、ベクトル検索を支える一連のアルゴリズムを表します。ベクトルデータベースは、効率的なベクトル類似検索のために専用設計されたソリューションです。
ANN-Benchmark は、さまざまなベクトル検索アルゴリズムを選択・比較するうえで非常に有用ですが、ベクトルデータベースの包括的な概要を提供するものではありません。リソース消費、データ読み込み容量、システムの安定性といった要素も考慮する必要があります。さらに、ANN Benchmark は、フィルタリング付きベクトル検索など、多くの一般的なシナリオを見落としています。
このような課題に対処するため、Zilliz の開発者は VectorDBBench を提案しました。これは、Milvus and Weaviate のようなオープンソースのベクトルデータベースや、Zilliz Cloud and Pinecone のようなフルマネージドサービス向けに設計されたオープンソースのベンチマークツールです。多くのフルマネージド型ベクトル検索サービスは、ユーザーによるチューニングのためのパラメータを公開していないため、VectorDBBench は QPS と再現率を別々に表示します。
以下のグラフは、768 次元の 1,000,000 個のベクトルを処理する際の、さまざまな主流ベクトルデータベースにおける QPS と再現率のテスト結果を示しています。
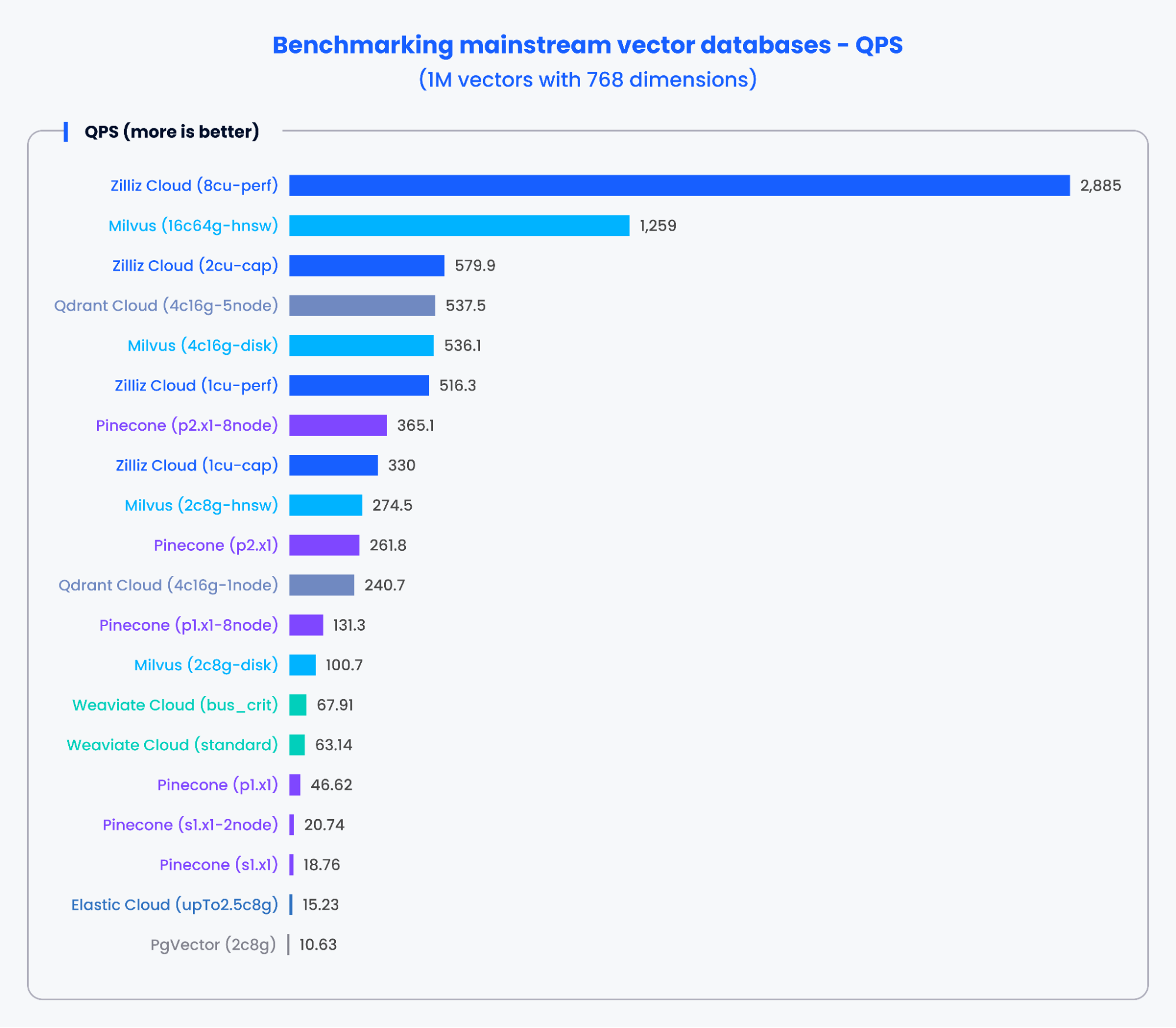 図 2: QPS のベンチマーク結果
図 2: QPS のベンチマーク結果
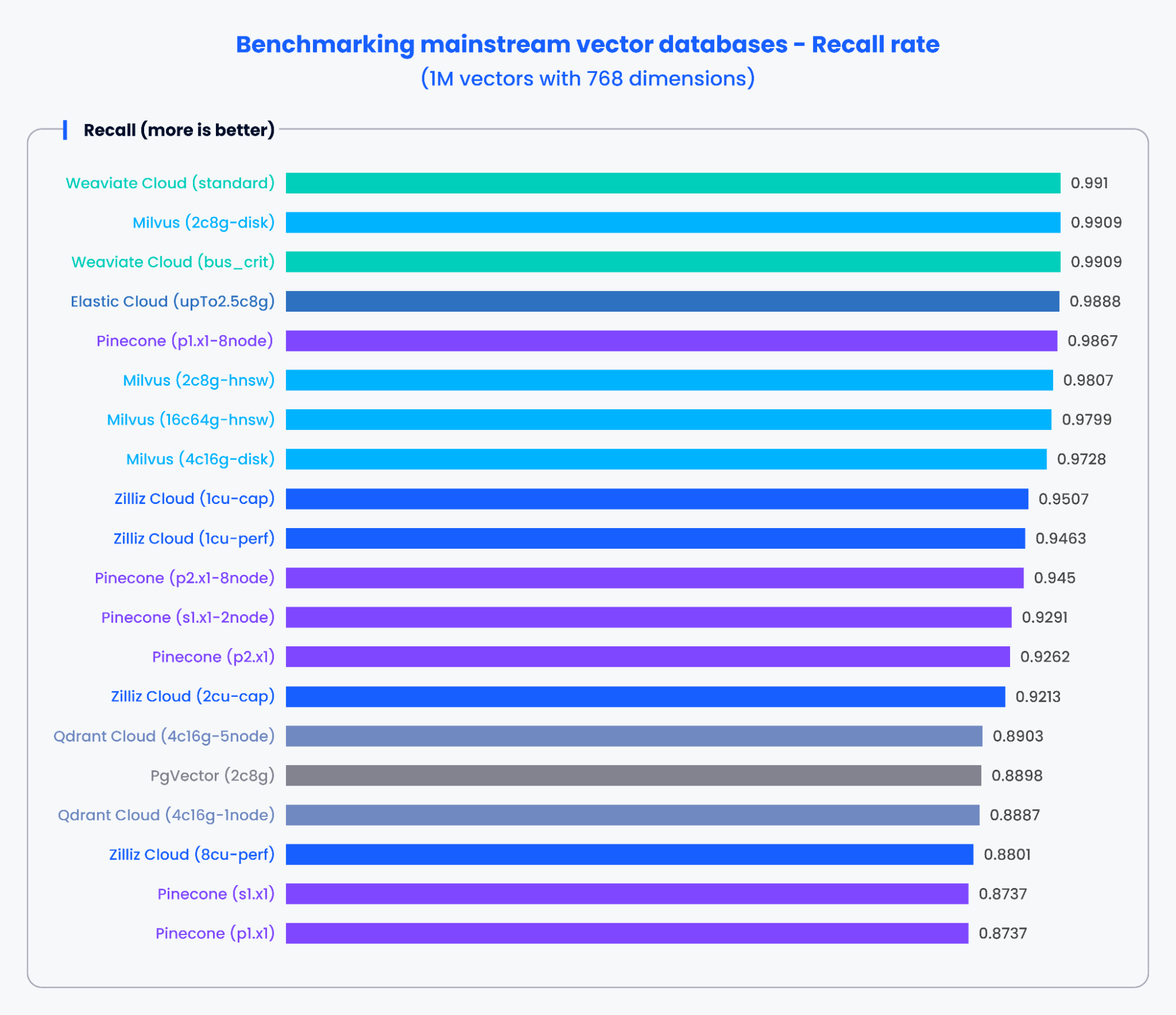 図 3: 再現率のベンチマーク結果
図 3: 再現率のベンチマーク結果
上記のグラフの結果に基づくと、Milvus や Zilliz のような専用設計のベクトルデータベースは、QPS と再現率の両方で優れた性能を示しました。これらの結果は、専用設計のベクトルデータベースが膨大な量のデータを迅速に処理し、より正確な結果を取得できることを示しています。対照的に、従来型データベースをベースにしたベクトル検索アドオンは、より低い性能を示しました。
ベンチマーク結果を再現したり、自身のデータセットで性能結果を取得したりするには、GitHub repository から VectorDBBench をダウンロードしてください。
VectorDBBench Leaderboard
VectorDBBench は、テスト結果の提示を効率化し、詳細な性能分析レポートを提供するために設計された専用の leaderboard page も提供しています。このリーダーボードでは、包括的な性能評価のために、Queries Per Second (QPS)、クエリ価格 ($) メトリクス、レイテンシなどの主要な指標を選択できます。
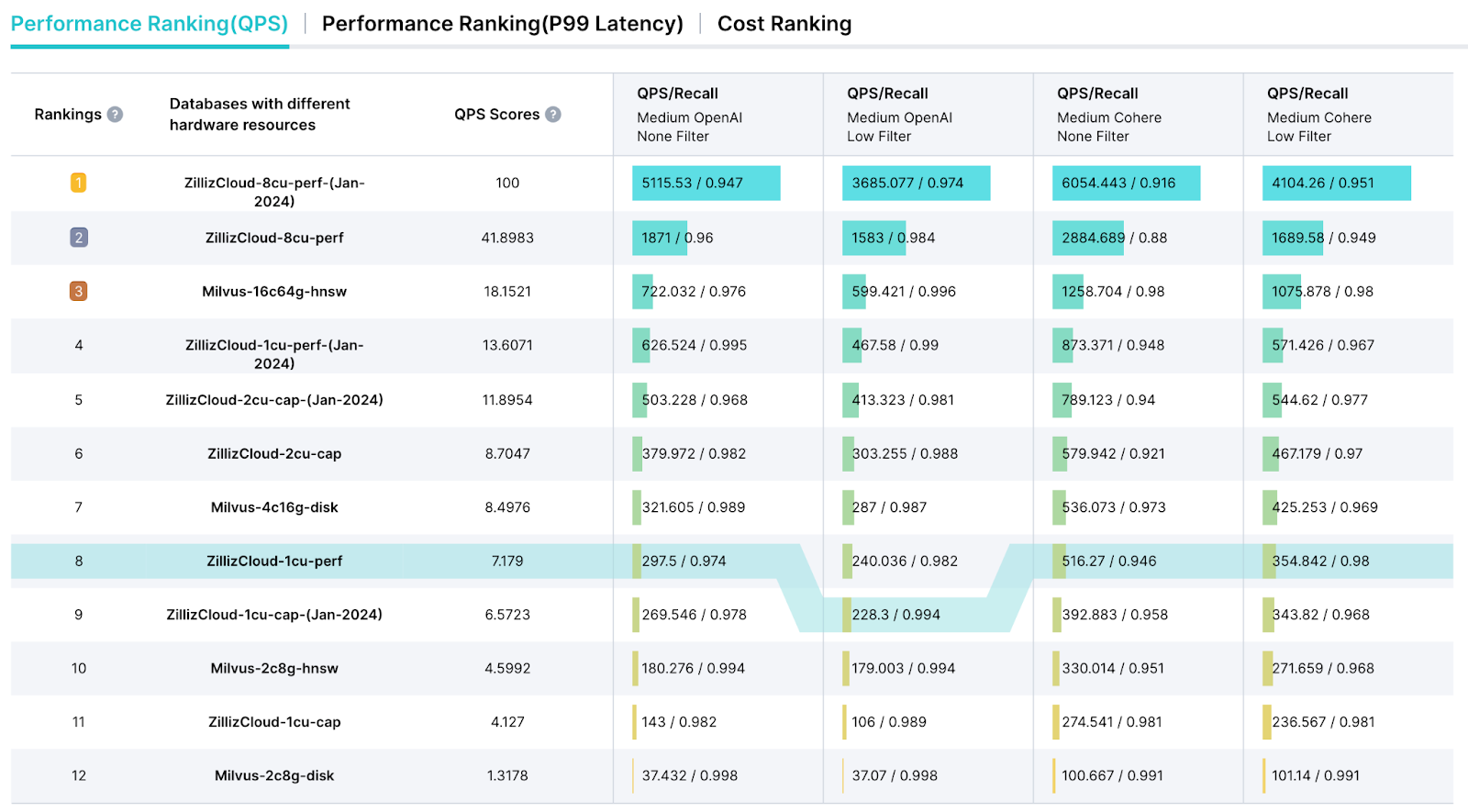 vectordbbench リーダーボードのスクリーンショット
vectordbbench リーダーボードのスクリーンショット
図 4: VectorDBBench Leaderboard のスクリーンショット
ANN Benchmarks vs. VectorDBBench
ANN Benchmarks はベクトルインデックスアルゴリズムを評価し、さまざまなベクトル検索ライブラリの選択と比較に役立ちます。しかし、複雑で成熟したベクトルデータベースの評価には適しておらず、フィルタリング付きベクトル検索のような状況を見落としています。
Zilliz のエンジニアは、包括的なベクトルデータベース評価に特化するよう VectorDB Bench を作成しました。これは、リソース消費、データ読み込み容量、システムの安定性といった重要な要素を考慮します。テストクライアントとベクトルデータベースを分離し、独立したデプロイを確保することで、VectorDB Bench は実際の本番環境に近い形でのテストを可能にします。
パフォーマンス評価に影響を与える要因
ベクトルデータベースまたはANNアルゴリズムのパフォーマンスには、データセット、ネットワーク条件、データベース設定など、いくつかの要因が影響します。
ネットワーク
ネットワーク条件は重要です。レイテンシはクエリ応答を遅くする可能性があり、限られた帯域幅はデータ転送速度に影響します。ネットワークの安定性も重要であり、変動によってパフォーマンスが不安定になる可能性があります。
データセット
データセットサイズはメモリとディスク使用量に影響します—より大きなデータセットにはより多くのリソースが必要です。ベクトル次元数は操作の複雑さとクエリ時間に影響します。データ分布とインデックス構造(例:階層型、フラット型)も検索効率と精度に影響します。
データベース設定
インデックスパラメータ(例:ツリー数)と検索設定(例:最近傍)は、取得効率と速度に直接影響します。キャッシュは、頻繁にアクセスされるデータの応答時間を改善できます。
環境要因
オペレーティングシステムとバックグラウンドプロセスは、リソースの可用性とシステムの応答性に影響し、全体的なパフォーマンスに影響を与える可能性があります。
これらの要因を考慮することで、ベクトルデータベースのパフォーマンスを理解し、最適化するのに役立ちます。