




ベクトルデータベースからベクトルレイクベースへ
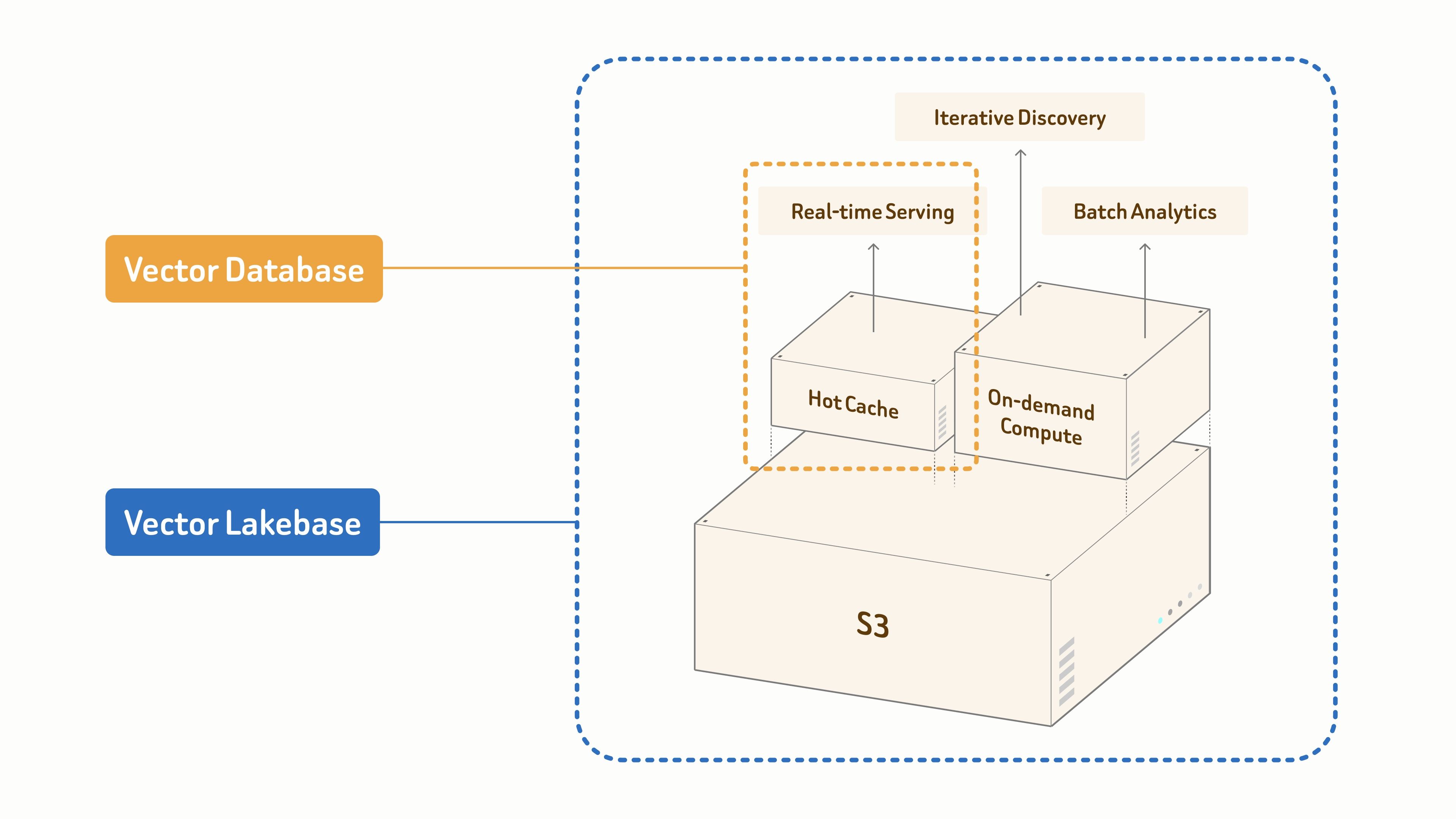
本日、Zilliz Cloud の次なる章となる Zilliz Vector Lakebase のパブリックプレビューを開始します。Vector Lakebase は、ベクトルデータベースを超える次のステップです。 これは、オープンストレージとエラスティックコンピュートが AI ワークロードのために融合する、セマンティック中心のデータプラットフォームです。
- ベクトルデータベースは、リアルタイムサービングに特化して設計されています。
- Vector Lakebaseは、S3 ベースの統合データ基盤の上に構築され、3 つのワークロードモードで AI とエージェントを強化します。
- レイテンシが重要な本番サービング向けのリアルタイム検索、
- インタラクティブかつ多段階の探索向けの反復的発見、
- オフラインマイニングとデータセット最適化向けのバッチ分析。
ギガバイトからペタバイトまで、あらゆる規模に対応します。
統合データ基盤と 3 つのワークロードモードが本当に重要な理由
要するに、AI システムはもはや単一クエリの検索問題ではないからです。AI システムは、サービング、学習、改善の継続的なループとして動作します。
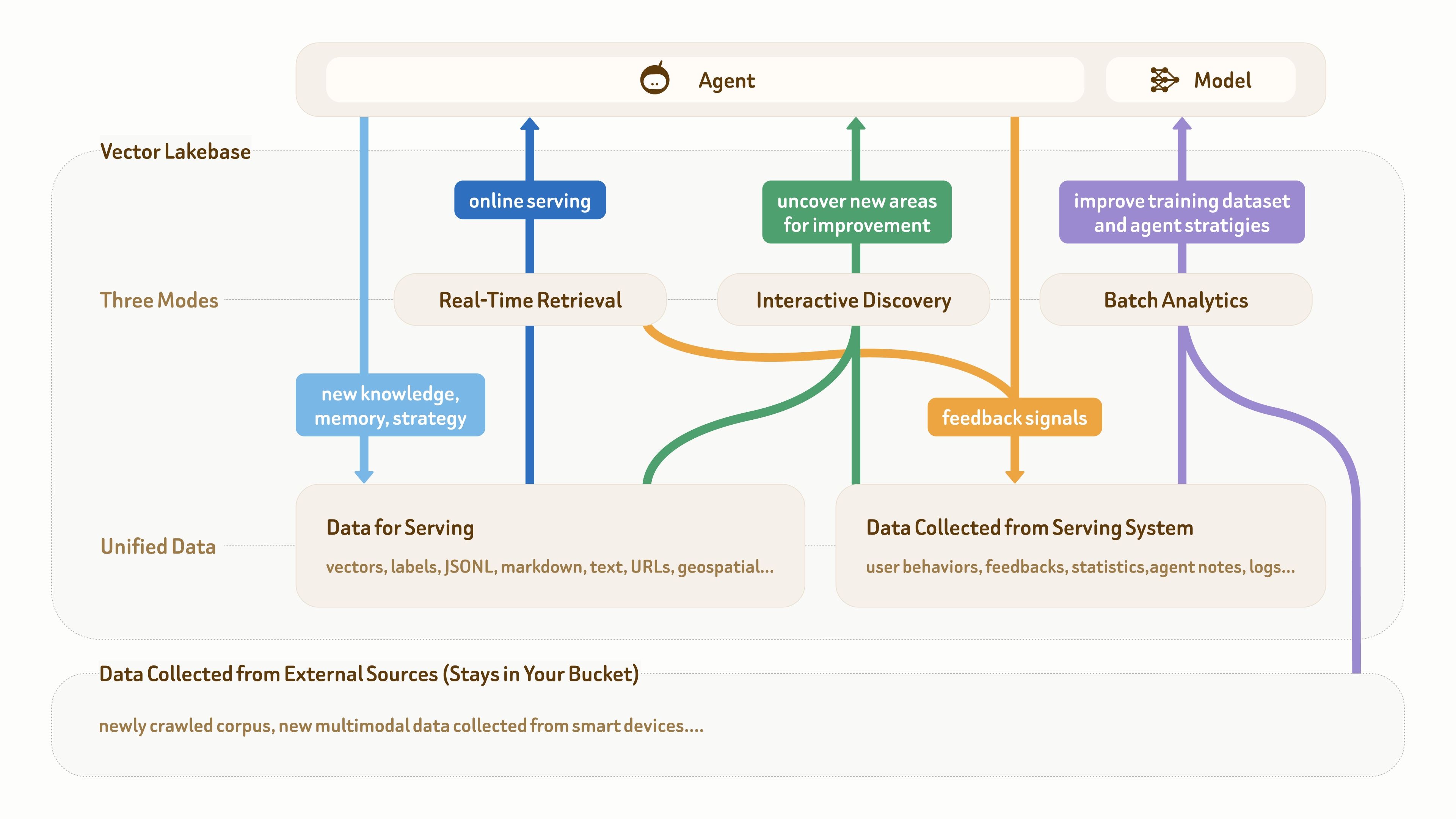
この図が示すように、AI およびエージェントアプリケーションのデータ基盤は通常、下層の生のマルチモーダルデータ、オンラインサービング向けのセマンティックデータ(テキスト、ベクトル、ラベルなど)、そして本番システムから収集されるフィードバックデータ(ユーザー行動、ログ、エージェントのメモ、統計など)の 3 つの部分で構成されます。
多くの成熟したエージェントアプリケーションは、すでにこのようなデータ基盤を備えています。本当の課題は、これらの異なる種類のデータがしばしば複数のパイプラインやシステムに分散しており、ワークフローループを支える統一された構造化データプレーンが存在しないことです。
オンラインサービング(濃い青) → 知識とフィードバックの蓄積(薄い青とオレンジ) → インサイト発見(緑) → データセットと戦略の改善(紫) → より優れたオンラインサービング。
この図がさらに示すように、ベクトルデータベースだけではもはや十分ではありません。なぜなら、ベクトルデータベースは主にリアルタイム検索とサービング指向のデータ書き込み(2 つの青い経路)をサポートするものだからです。このループでは、他の 2 つのアクセスモードであるインタラクティブな発見とバッチ分析も同じくらい重要です。
たとえば、AI 開発者は(手作業またはエージェント型システムを通じて)、サービング品質がなぜ低いのかを理解するために、フィードバックデータと基盤となるコーパスを探索する必要がよくあります。また、新たにクロールされたデータに対して大規模なセマンティック重複排除やクラスタリングを実行し、エッジクラスタをマイニングして新しいトレーニングデータ候補を発見することもあります。
これらのワークロードは、従来のビッグデータ処理とは大きく異なります。中核となる計算は数値的なものではなくセマンティックなものです。データは主にベクトル、テキスト、ラベル、セマンティックメタデータで構成され、中核となる操作にはベクトル検索、全文検索、リランキング、セマンティッククラスタリング、および関連するセマンティック検索タスクが含まれます。
このため、インタラクティブな発見とバッチ分析は、データ層とコンピュート層の両方において、ベクトルデータベースと自然に整合します。多くの場合、オンラインサービングとオフライン処理は、同じ基盤データを共有することさえあります。
たとえば、チームは高価値なユーザータスクをオフラインでクラスタリングおよび分析しながら、同時にサービングシステム内のそれを支える知識や戦略にスパース性や品質上の問題がないかを確認できます。
全体として、断片化されたデータアーキテクチャや孤立したインフラストラクチャの島は、このループを遅くします。これは、急速に進化する AI 能力の競争において致命的になり得ます。Vector Lakebase は、シンプルでありながら効率的なアプローチによってこのループを加速します。それは、リアルタイム検索、インタラクティブな発見、バッチ分析という 3 つのワークロードモードすべてから効率的にアクセスできる、ゼロコピーのセマンティックデータプレーンを提供することです。
Vector Lakebase の主要機能
Zilliz Vector Lakebase は、5 つのコア機能を通じてこのワークフローループをサポートします。
- 階層型サービングソリューション
さまざまなリアルタイムワークロード向けに最適化された柔軟なサービング階層 — 大規模データセット全体で、超高性能、バランスの取れた効率性、費用対効果の高いスケーリングを実現します。 - オンデマンド検索
レイテンシの重要度が低く、コンピュートがほとんどの時間アイドル状態にある大規模ワークロード向けに設計されています — 低頻度の検索、データ探索、バッチ分析などを含みます。 - 外部データレイク検索
最先端のインデックス作成機能と大規模検索機能を、既存のレイクデータに直接追加します。 - フルスペクトラム検索 ベクトルとテキストからJSON、地理空間まで—ハイブリッド検索、フィルタリング、リランキングと組み合わせることで、表現力豊かなマルチモーダルクエリを実現します。
- 統合レイクネイティブストレージ
サービングと分析の両方に対応する統合ストレージ。Vortexを基盤として構築されています — LanceやParquetよりも高速かつ低コストなランダム読み取りに加え、列ごとのフォーマット柔軟性と、より広範なデータモデリング機能を提供するオープンな次世代フォーマットです。
階層型リアルタイムサービングソリューション
Zilliz Cloudの階層型サービングソリューションは、Performance-Optimized、Capacity-Optimized、Tiered-Storageの3つのサービング階層を提供します。各階層は、専用のインデックスアルゴリズムと、ストレージ階層全体にわたるデータ配置戦略によって構築されており、幅広い性能–コストのトレードオフを提供します。
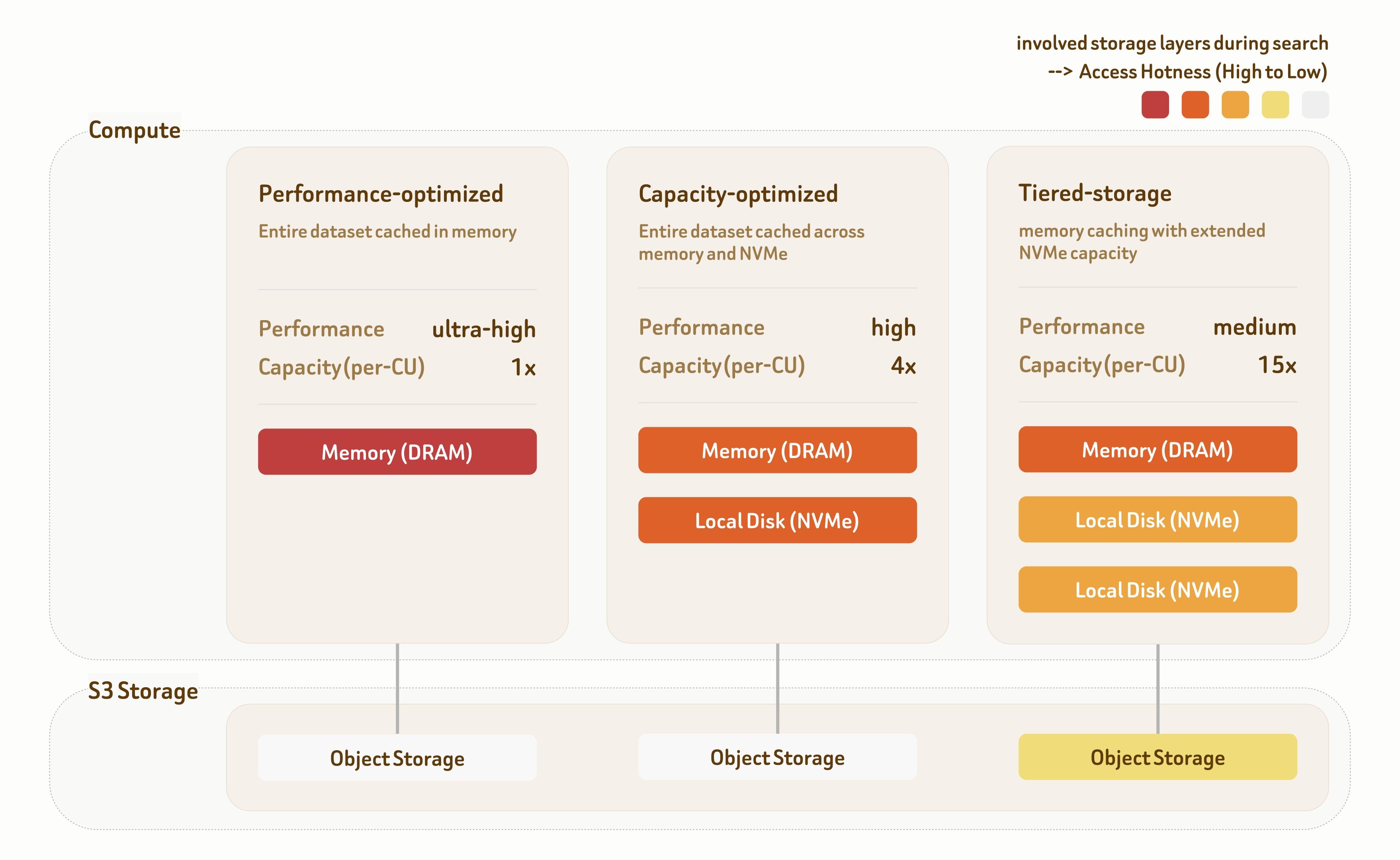
The Performance-Optimized tierは、超高性能シナリオを対象としています。すべてのデータがメモリから直接提供され、1桁ミリ秒のレイテンシで1000+ QPSを実現します。スループットは、マルチレプリカ展開によってさらに線形にスケールします。
The Capacity-Optimized tierは、メモリとローカルNVMeストレージを組み合わせ、性能と容量のバランスを取ります。100ミリ秒未満のレイテンシで100~500 QPSを実現し、ほとんどの検索ワークロードに適しています。
The Tiered-Storage tierは、メモリ、ローカルNVMe、オブジェクトストレージにまたがります。高度に最適化されたプリフェッチおよびキャッシュ戦略により、データアクセスの95%以上が依然としてメモリまたはローカルディスクにヒットし、大幅に低いインフラコストで約100ミリ秒のレイテンシと10~50 QPSを提供します。
3つの階層はいずれも、デフォルトで95%–98%のリコールを提供し、インデックス作成と検索全体で柔軟にチューニングできます—ワークロード要件に応じて90%から99%+のリコールをサポートします。
これらのサービングアーキテクチャは、以下を含む、世界でも最も要求の厳しい大規模AIおよびインターネットワークロードの一部で実戦実証されています。
- インターネット規模のマルチテナントAIプラットフォーム、
- プレミアムエンタープライズユーザーと大規模な無料ユーザープールの両方に対応する差別化されたサービス階層、
- 高性能エージェントナレッジベース、
- 超高スループット推薦システム、
- Web規模のAI検索エンジン、
- ストレージ階層全体にわたる秒単位の動的ホット/コールドデータスケジューリング、
- 極端なコスト制約下で100B+規模の自動運転データマイニングパイプライン。
オンラインサービング向けに、Zilliz Cloudはクロスリージョンの高可用性と災害復旧のためのGlobal Cluster機能も提供しており、99.99%の稼働時間SLAによって支えられています。
オンデマンド検索
インタラクティブな発見とバッチ分析は、特にフィードバックデータ、エージェント生成メモ、ログ、クロールされたコーパスを含む場合、オンラインサービングよりも1〜3桁大きいデータ量で運用されることがよくあります。これらのデータセットは、容易にTB、さらにはPB規模に達する可能性があります。しかし、それらを提供するために数百、さらには数千のベクトルデータベースノードを使用することは、費用対効果の観点から正当化が難しい場合が多いです。

さらに重要なのは、これらのワークロードが通常タスク駆動型であることです。エージェントアプリケーションのオンラインサービング層とは異なり、24時間365日稼働するアクティブなインフラを必要としません。コンピュートリソースは、アクティブな処理タスク中にのみ大量に使用され、それ以外のほとんどの時間はアイドル状態のままであり、多くの場合アイドル時間は97%を超えます。
サーバーレスのサービングソリューションは魅力的に見えるかもしれませんが、こうしたワークロードでは多くの場合、はるかに高額になります。
コンピュート層では、サーバーレスシステムと On-Demand Search のどちらも従量課金モデルに従います。詳細な料金モデルには違いがありますが、基盤となるコンピュートコストは多くの場合類似しています。しかし、サーバーレスアーキテクチャでは、プーリングのオーバーヘッド、インデックス作成、永続データのコストが、基盤リソースの真のコストを直接反映するのではなく、追加の書き込みおよびストレージのマークアップに組み込まれています。
これに対して、Zilliz On-Demand Search はオブジェクトストレージとオンデマンドコンピュートに対して直接課金します。これは AWS Lambda と同様で、料金は主に割り当てられたリソースサイズと実行時間に基づき、ストレージコストは基盤となる S3 のコストに近いままです。これにより、隠れたインフラオーバーヘッドやブラックボックス型の料金モデルを回避できます。
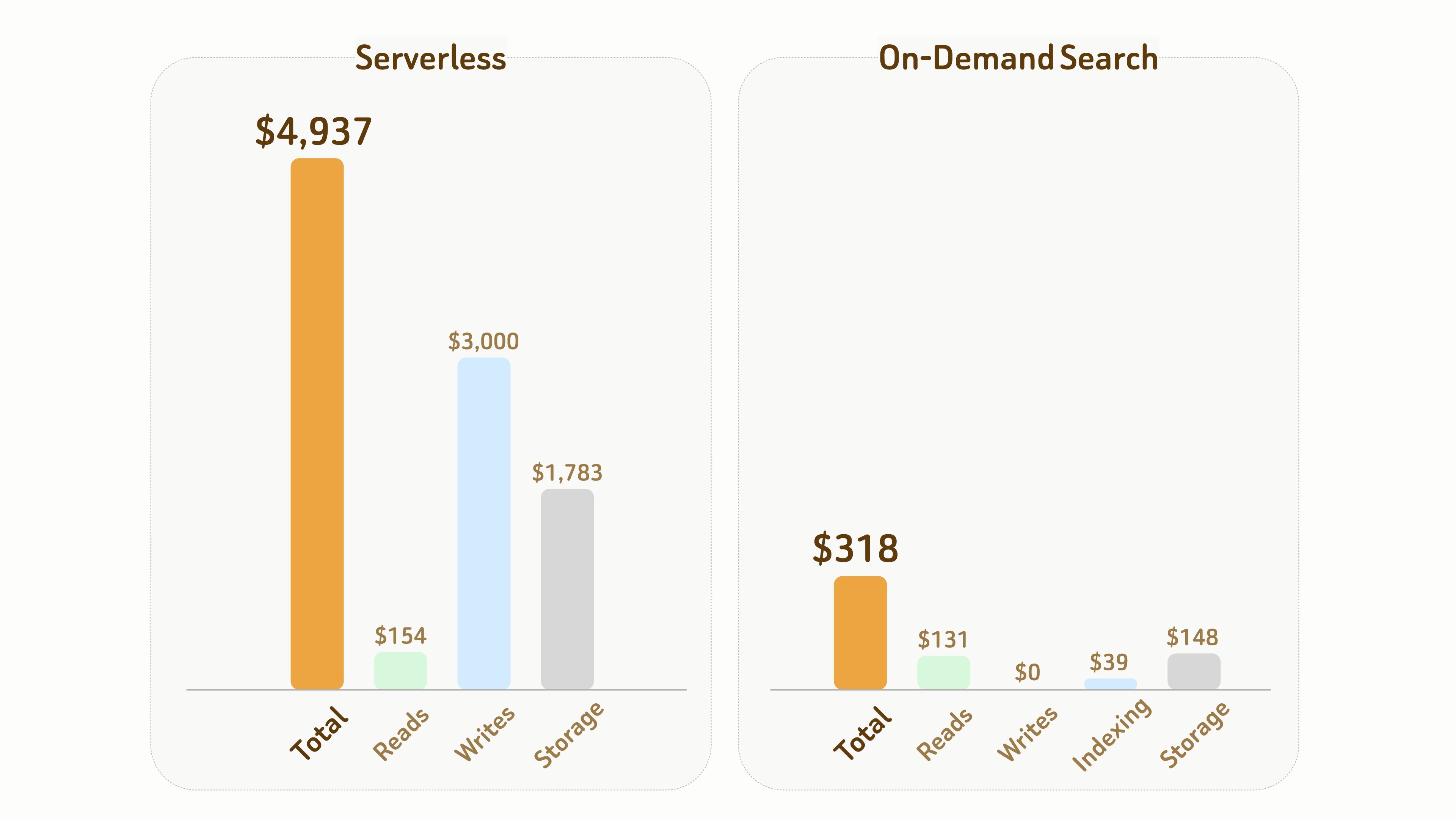
以下の比較は、Serverless と On-Demand Search のコスト差を示しています。
セットアップ:
- 768 次元の 10 億ベクトル。データとインデックスファイルを含めて約 6 TB のストレージが必要。
- 1 か月間で、累積アクティブコンピュート時間は 10 時間。
全体として、この実験では、On-Demand Search の総コストは Serverless の約 1/15($318 対 $4,937) にすぎません。
外部データレイク検索
Zilliz Vector Lakebase は、フルマネージドのストレージとクエリコンピュートを提供し、ユーザーが Zilliz Cloud 内で直接データを保存および操作できるようにします。しかし、一部の顧客はすでに成熟したデータレイクインフラストラクチャとガバナンスパイプラインを整備しています。
AI アプリケーションにとって重要な課題の 1 つは、既存のレイクデータ上で直接、効率的な検索とセマンティック探索を可能にすることです。Spark や Ray などの従来のビッグデータシステムは、これらのワークロードに最適化されていません。なぜなら、それらは基本的に、インデックスで高速化されたクエリやセマンティック検索ではなく、全データスキャンと map-reduce 計算を中心に設計されているためです。
これを解決するために、Zilliz は External Collection モードを提供しています。これは、Zilliz データプレーンから顧客所有のレイクテーブルへのゼロコピーの論理マッピングを作成し、そのマッピング上で高性能なインデックスとフルスペクトル検索を可能にします。
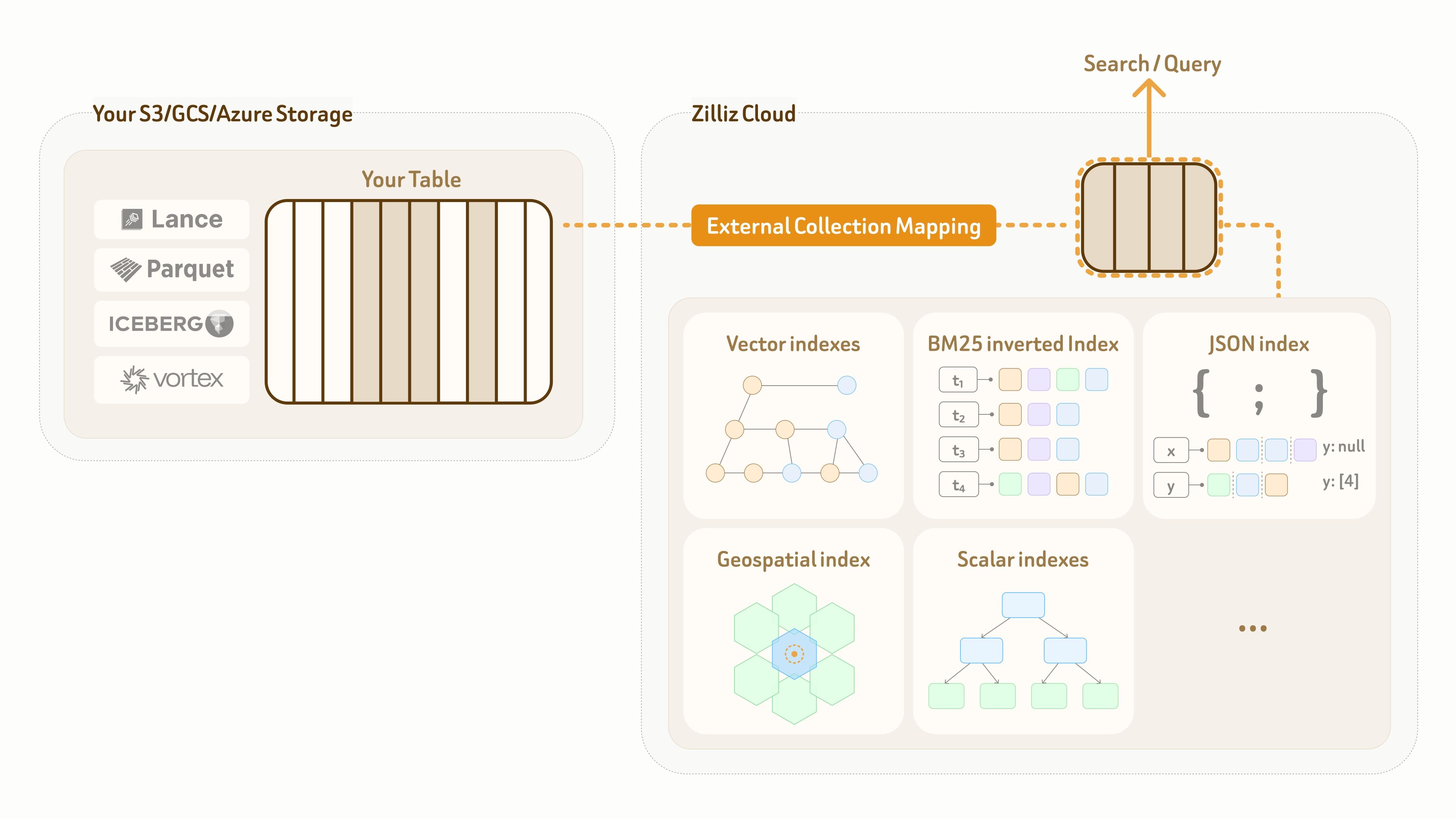
現在、External Collection は 2 つのデータレイクテーブル形式である Lance と Iceberg、および 2 つのオープンデータ形式である Parquet と Vortex をサポートしています。
データレイクの更新については、Zilliz External Collection が増分同期機能を提供します。データレイクの更新パターンとクエリの可視性要件に基づいて、ユーザーは refresh 呼び出しによりいつでもデータを同期できます。
フルスペクトル検索
AI アプリケーションでは、異なるソースやモダリティにまたがってデータを検索・分析する必要性が高まっています。これは、補完的な情報を組み合わせるためでもあり、また同じ生コンテンツから複数の視点を抽出して、検索と分析の品質を向上させるためでもあります。
Zilliz Vector Lakebase は、dense ベクトルおよび sparse ベクトル、テキスト、JSON、地理空間データ、プリミティブ型を含む豊富なデータ型に加え、Struct や Array などの複雑な構造を備えたワイドテーブルモデリングをサポートします。これにより、統一されたテーブルレイアウト内で直接、効率的なネストされたセマンティックモデリングが可能になります。

これにより、各アプリケーションレベルのエンティティを単一の行に直接マッピングすることで、統一されたコンテキストモデリングが可能になります。たとえば、ドキュメントをテキストチャンク、画像、表のために何百もの行に分割する代わりに、Zilliz Vector Lakebase はドキュメント全体を単一の行としてモデル化できます。これにより、JOIN や集約のパフォーマンスおよび運用上のオーバーヘッドを回避しながら、マルチモーダル検索と分析が向上します。
データモデリングに加えて、Vector Lakebase は、サポートされるすべてのデータ型にわたって最先端のインデックス作成および検索機能も提供します。詳細な機能は以下のとおりです。
| Vector Search | HNSW、IVF、RaBitQ を上回る高度なインデックス作成アルゴリズム。リコールとレイテンシを調整する 10 段階のチューニングに対応。 |
|---|---|
| Full-Text Search | BM25、フレーズ、プレフィックス、ファジーマッチング、および幅広いアナライザーに対応した全文検索。 |
| Grep | ほとんどの grep スタイルのマッチングパターンをカバーする組み込みの正規表現サポート。 |
| Hybrid Search | リコールと関連性を向上させるための、密ベクトルと疎ベクトルのハイブリッド検索。 |
| Query on JSON | ネストされた JSON フィールドに対する高速なフィルタリングとクエリのための、組み込み JSON シュレッディングとインデックス作成。 |
| Geospatial Search | 半径、最近傍、エリアフィルタリングに対応した高速な地理空間検索。 |
| Multi-Vector Search | 1 つ以上のモダリティから生成された複数の埋め込みに対する検索と、統合された再ランキング。 |
| Vector Search with Filtering | 低いフィルター選択性から高いフィルター選択性まで最適化された、属性フィルタリング付きベクトル検索。 |
| Range Search | クエリベクトルから指定された距離しきい値内にあるすべてのベクトルを返します。 |
| Iterative Search | 中間結果に基づいてクエリを段階的に改良する反復検索。 |
| Multi-Path Retrieval | 複数の戦略によるマルチパス検索。各パスでは上記のいずれの検索方法も使用可能。 |
さらに、マルチパス検索と併用される再ランキング機能も備えています。
| Cohere Reranker | クエリとドキュメントのペアを高い意味的精度でスコアリングし、検索結果を最大限の関連性に基づいて並べ替えるクロスエンコーダー再ランキングモデル。 |
|---|---|
| Voyage AI Reranker | 大規模な検索パイプラインにおいて、高速かつコスト効率の高い関連性スコアリングに最適化された、軽量で高スループットの再ランキングモデル。 |
| Boost Reranker | 一致した結果に条件付きフィルターを適用し、指定された重みによってスコアを調整してランキングを上げたり下げたりします。 |
| Decay Reranker | 距離や時間などの要因に基づく減衰関数を適用して結果スコアを調整し、値がターゲットから離れるにつれて関連性を徐々に低下させます。 |
| RRF Reranker | 複数の結果リストを統合し、各項目のリスト間での順位を組み合わせて単一のランキングにします。 |
| Weighted Reranker | 設定可能な重みを使用して複数の結果リストのスコアを組み合わせ、統一されたランキングを生成します。 |
統合されたレイクネイティブストレージ
Zilliz Cloud は、完全に分離されたストレージ–コンピュートアーキテクチャ上に構築されており、すべてがクラウドオブジェクトストレージに永続化されます。
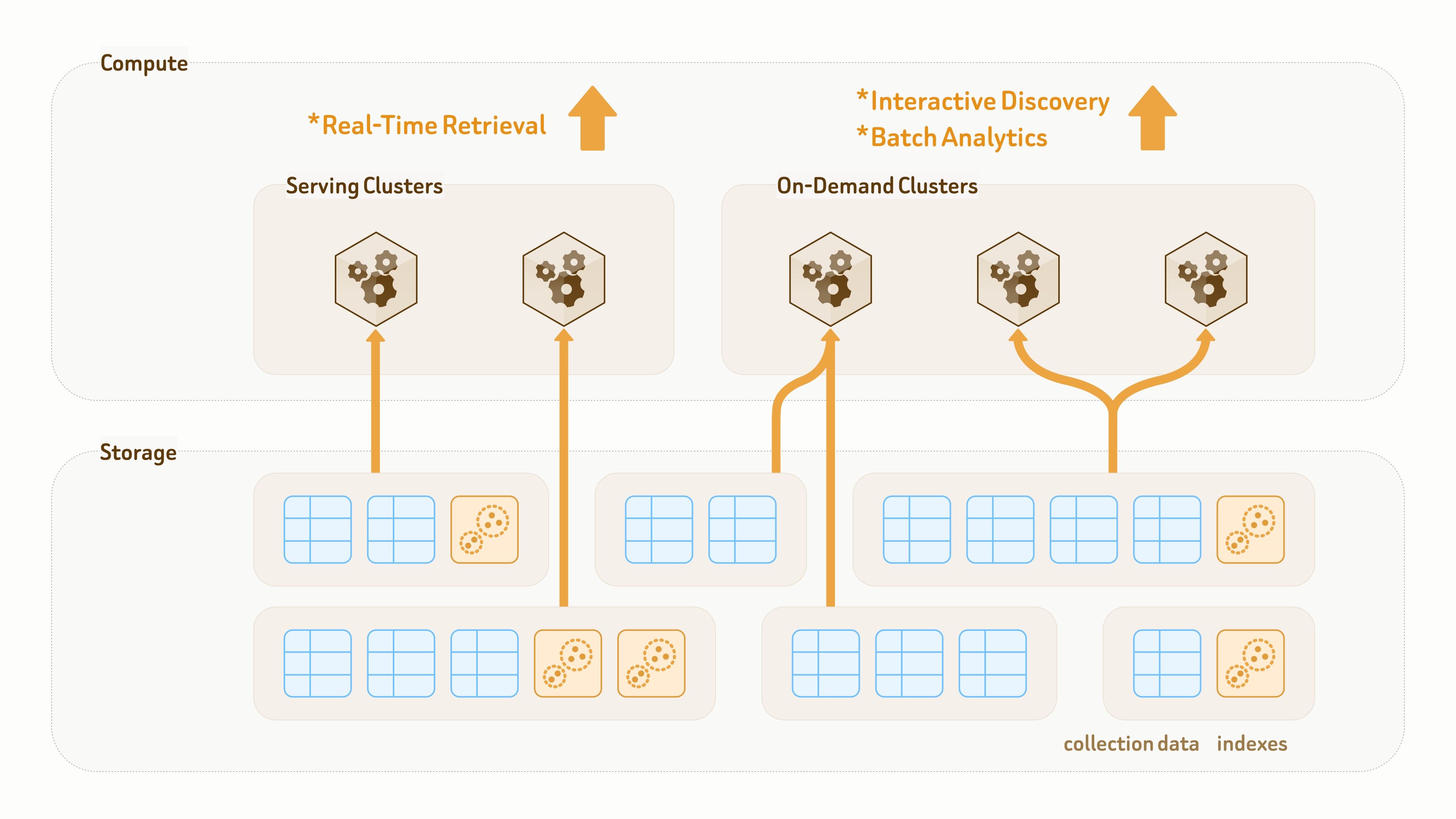
主にストレージ向けに設計された従来のデータレイクとは異なり、Zilliz Vector Lakebase のデータレイヤーは、永続化とクエリ実行の両方を目的として設計されています。コレクションとインデックスはコンピュートクラスターから分離されているため、同じデータとインデックスを、異なるクラスターからゼロコピーアクセスでマウントし、異なるクエリおよび分析ワークロードに利用できます。
新しいラベルや特徴量を頻繁に追加したり、埋め込みモデルを切り替えたりするなど、データモデルが継続的に進化する AI およびエージェントアプリケーション向けに、Zilliz はシームレスかつ高速なスキーマ進化とデータバックフィルのメカニズムを提供します。
新しいフィールドは、プールされたプラットフォームのコンピュートリソースによってバックフィルおよび整合化され、その後メタデータ更新を通じてクエリクラスターに公開されます。1 億行のバックフィルは、通常 10 分未満で完了できます。
作業の大部分はプラットフォーム側のコンピュートリソースによって処理されるため、既存のユーザークラスターは影響を受けず、プロセス全体を通じて読み取りおよび書き込みトラフィックの提供を継続できます。
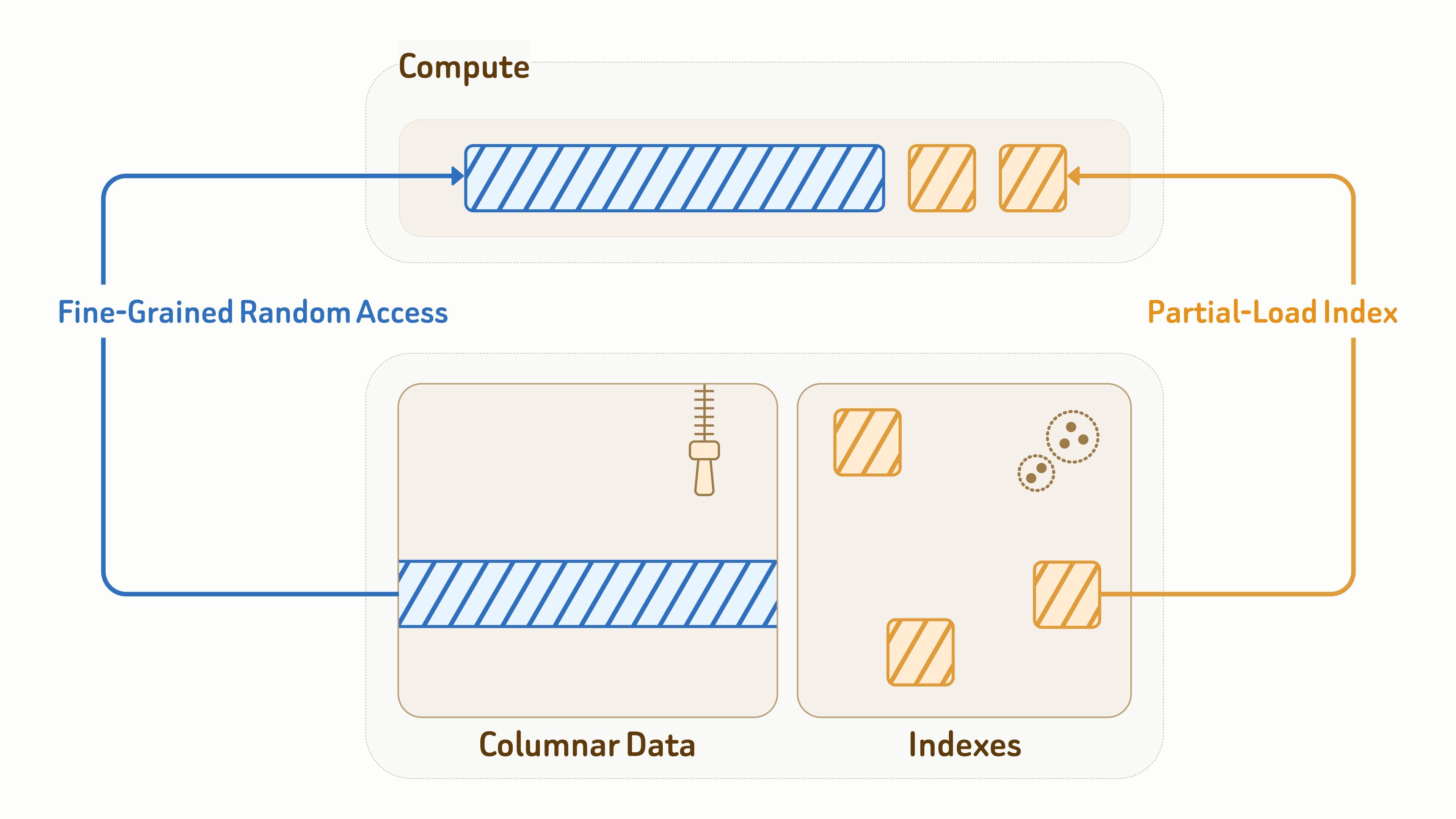
データレイヤーはクエリワークロードも直接処理するため、効率的な I/O はレイテンシとスループットの両方にとって重要です。
コレクションデータについて、Zilliz はカラムナストレージレイアウトに Vortex オープンフォーマットを使用し、効率的なエンコーディングとデータフラグメントへのきめ細かなランダムアクセスを組み合わせています。これにより、ランダム読み取りにおいて Lance や Parquet よりも大幅に高速です。
インデックスについて、Zilliz は、ベクトルインデックス、BM25 倒立インデックス、JSON インデックスを含む、効率的な I/O のためにレイアウトとアクセスパターンを深く最適化した、オブジェクトストレージ対応のインデックスアルゴリズム設計を提供します。
クエリ実行中、コンピュートノードは、クエリによってアクセスされるインデックスページとデータエンティティのみを部分的にロードします。キャッシュとデータプルーニングと組み合わせることで、これにより読み取り増幅が 90% 超、大幅に削減されます。
Vector Lakebase の主なユースケース
Vector Lakebase の典型的なアプリケーションシナリオには、以下が含まれますが、これらに限定されません。
リアルタイムサービングワークロード:
- レイテンシが重要なエージェントメモリと戦略検索。
- 法務、医療、金融、その他の専門産業向けの垂直ドメイン知識ベース。
- Web スケールの AI 検索エンジン。
- 超高スループットのレコメンデーションシステム。
- ストレージ階層間での秒単位の動的なホット/コールドデータスケジューリング。
- プレミアムエンタープライズユーザーと大規模な無料ユーザープールの両方に対応する差別化されたサービス階層。
反復的ディスカバリーワークロード:
- フィードバックデータ、エージェント生成ノート、ログ、その他のマルチソースデータ全体にわたる AI サービス品質分析と課題発見。
- 大規模データセットの効率的な探索。
- 複数ステップの反復的なディープリサーチ。
バッチ分析ワークロード:
- 超大規模コーパスの重複排除とクラスタリング。
- 効率的なフィルタリング、検索、および 2 段階の粗い検索から再ランキングまでのクエリパイプラインのために、Spark と Ray にフルスペクトラム検索機能を追加。
- トレーニングおよびファインチューニング用データセットの準備。
ハイブリッドケース:
- Lance や Iceberg などの既存のデータレイクテーブル上でのインデックス作成と検索の高速化。
- 頻繁な大規模バックフィルを伴う、継続的に進化するデータモデル。
- マルチモーダルなセマンティックワイドテーブルモデリング。ベクトル、メタデータ、LLM 生成サマリー、構造化フィールドを、整合性のあるバージョニングとリネージ管理を備えたエンティティ中心のテーブルに統合します。
Zilliz Vector Lakebase を試す
Vector Lakebase と最新アップデートの詳細については、Zilliz website にアクセスするか、Zilliz Cloud documentation をご覧ください。この記事のアーキテクチャやユースケースがあなたの業務に関連している場合は、より深い技術的な議論のために contact the Zilliz team してください。

読み続けて

Introducing Loon: A New Storage Engine for Vector Data That Never Stops Changing
Loon is a new storage engine for Milvus 3.0 and Zilliz Vector Lakebase, built to manage evolving vector datasets with ColumnGroups, row ID alignment, and Manifests.

3 Easiest Ways to Use Claude Code on Your Mobile Phone
Run Claude Code from your phone with Remote Control, Happy Coder, or SSH + Tailscale. Comparison table, setup steps, and tools for typing, memory, and parallel tasks.

Vector Databases vs. Document Databases
Use a vector database for similarity search and AI-powered applications; use a document database for flexible schema and JSON-like data storage.