




AIはどのように情報検索を変えつつあるのか?
2024年は、AI、特にディープラーニングの目覚ましい進歩に後押しされ、 情報検索 (IR) にとって極めて重要な年となった。データ・スケール、計算能力、モデル・サイズの向上がパラダイム・シフトを促進し、IRは従来のキーワード・ベースのマッチングからディープ・ラーニング主導のアプローチへと移行した。大規模言語モデル](https://zilliz.com/glossary/large-language-models-(llms))(LLMs)の採用の増加は、検索、情報抽出、知識合成をさらに変革し、より高いインテリジェンスとイノベーションをもたらした。
検索拡張世代(RAG)の台頭から、知識工学技術をRAGに統合したより高度なグラフRAGに至るまで、情報検索は大きな変革を経験した。これらの進歩によりAIは民主化され、エンタープライズサーチ、コンテンツディスカバリー、ナレッジマネジメント、データ合成など、その応用範囲は拡大し、広範な採用が推進され、業界に新たなベンチマークを打ち立てた。
このブログでは、AIが2024年に情報検索(IR)にもたらした記念碑的な変化を要約し、ディープラーニング、LLM、ベクトルデータベースが検索、データ分析、知識合成をどのように再定義したかを探ります。また、RAG、マルチモーダル埋め込み、AIインフラストラクチャの進歩など、2025年に期待されるイノベーションを展望し、AI主導のアプリケーションの次の波の舞台を整えます。
スケーリングの法則:AIの進歩を支える原動力
スケーリングの法則は、2024年におけるAIの進歩の重要な原動力である。より大きなモデルサイズ、データセット、計算リソースは、OpenAIの text-embedding-3-largeやオープンソースのBGE-M3のようなより有能な埋め込みモデルと並んで、GPT-4oやClaude 3.5のようなますます強力なLLMを生み出しました。これらの進歩は、ドメイン間の汎化を大幅に改善し、理解と検索タスクの新しいベンチマークを設定した。
情報検索(IR)システムとLLMは深く統合され、 意味検索、全文検索、 知識グラフ(KG)のようなツールを統合システムに組み合わせることで、外部データソースを活用している。さらに、推論と自己反省の機能を持つ高度なLLMは、エージェントとして動作し、検索ツールを使用するタイミングを自律的に決定することができる。この統合により、より微妙な推論、正確な検索、人間のような回答生成が可能になり、検索エンジン、企業知識ベース、会話AIプラットフォームを変革している。
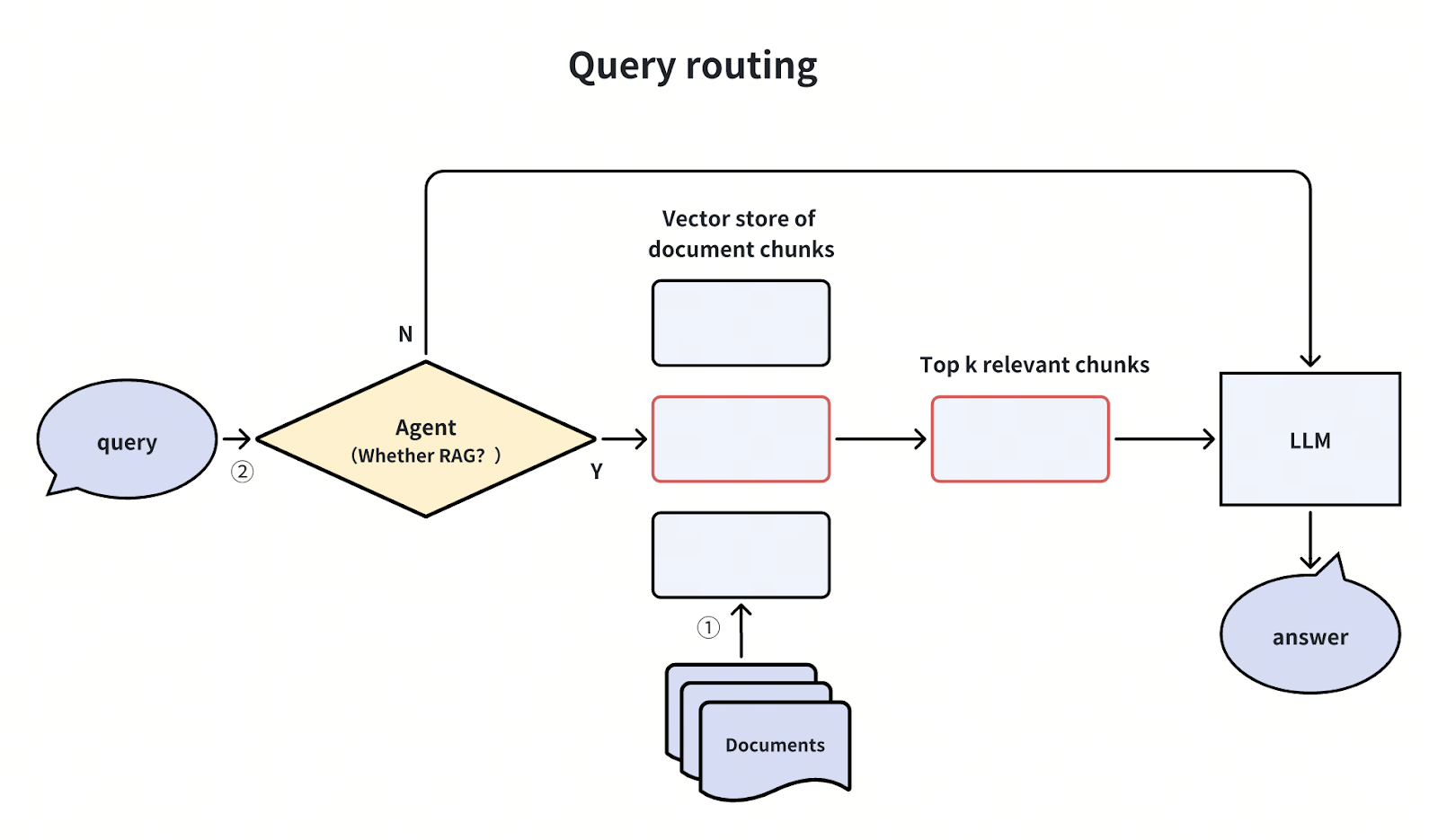
図:LLMの推論能力によるクエリ意図の理解は、従来のウェブ検索における複雑なアルゴリズムを置き換える。
RAGの進化:プロトタイプからプロダクションへ
外部の知識ベースでLLMを強化する実用的なアプローチとして導入されたRAG(Retrieval-Augmented Generation)は、2024年に大きく成熟した。Twitterのデモから本番環境に対応したシステムへと移行し、企業の知識ベースから消費者向けのチャットボットまで、業界全体で採用されるようになった。その成熟度を見てみよう。
ハイブリッド検索とリランカーによる品質向上
クロスエンコーダーベースのリランカーは、 ベクトル類似度だけに頼るのではなく、クエリとドキュメントの関連性を直接スコアリングすることで、検索精度を向上させる。通常、 Approximate Nearest Neighbor (ANN)検索による最初の検索後に適用されるリランカーは、深い文脈分析を行い、最も関連性の高い結果に優先順位をつける。この微妙なアプローチは、RAGが生成する回答の精度と質を向上させることができる。

図:リランカーはどのようにRAGアプリを強化しますか?
オフライン・ラベリングとメタデータのフィルタリング
オフラインのLLMによるラベル抽出は、バージョン番号やカバーされた機能などのメタデータを文書に自動タグ付けします。例えば、"Milvus 2.5でサポートされているインデックスタイプは?"のようなクエリが、他のバージョンからの無関係な結果を避け、関連する情報のみを取得することをメタデータフィルタが保証します。
これらの技術革新により、より高い回答品質や回答に対するより細かい制御を必要とする複雑なシナリオにおけるRAGの適応性が強化されました。その結果、RAGの用途は、カスタマーサポート、技術文書、企業ナレッジマネジメントなど、多様なユースケースに広がりました。
LLMによる文書解析と前処理の強化
大規模言語モデル(LLM)をドキュメントの前処理に統合することで、PDFファイルやスキャン画像などの[非構造化データ]の取り扱いに革命をもたらしました。LlamaIndexのLlamaParseや Unstructured.ioのようなツールは、複雑な文書から構造化データを抽出することを可能にした。現在、多くの文書処理ツールにはOCR機能が搭載されており、中には視覚言語モデルを活用して表データや生テキストを抽出するものまである。この機能は、表形式データに大きく依存することが多い、法律、医療、金融などの業界で特に有用です。
さらに、より洗練されたデータ処理技術は、LLMをプリプロセッサとして活用し、大きな進歩をもたらしている。その一例がコンテキスト検索で、文書チャンキングの際に失われるコンテキストに対処することで、情報検索の精度を高める。LLMは、各チャンクをより広い文書から得られる特定の文脈的詳細で充実させることで、検索されたコンテンツがより包括的であることを保証し、その結果、検索がより容易になり、ユーザーの質問に直接答えることができる。例えば、財務報告書の生のチャンクには、議論されている会社や関連する期間などの重要なコンテキストが欠けている可能性があります。レポート全体から追加のコンテキストを要約することは有益です。ハイブリッド検索や再ランク付けと組み合わせることで、このアプローチは検索品質の関連性を高め、RAGをより実用的なものにする。コンテキスト検索は、プロンプト・キャッシングと組み合わせることで、費用対効果を高めることができる。キャッシング機能は、同じコンテンツを繰り返し処理する必要性を回避することでコストを削減するからである。

図:ドキュメントの構文解析と前処理を強化するためのLLMの使用例
ColBERT と ColPali:既成概念にとらわれない
従来の検索モデルは、通常、文書全体を表現する単一ベクトル埋め込みに依存しており、クエリと文書間のきめ細かな関係を捉える能力に限界があった。ColBERT (Contextualized Late Interaction over BERT)は、マルチベクトルまたはトークンレベルの表現を活用する変換型レイトインタラクションメカニズムを導入し、より詳細でコンテキストを考慮した検索を可能にした。ColBERTは、文書を単一のベクトルに折りたたむ代わりに、文書とクエリをコンテキスト埋め込みセットにエンコードする。そして、MaxSim オペレーションは、各クエリトークンを最も類似したドキュメントトークンとマッチングさせ、全体的できめ細かな関連性スコアを生成する。このアプローチは、計算効率を維持しながら検索精度を向上させ、文書埋め込みを事前に計算することをサポートする。

図:ColBERTの仕組み
ColPaliは、Vision Language Models (VLMs)を統合することで、ColBERTのイノベーションを拡張し、テキスト、画像、図などのマルチモーダルコンテンツを統一的な埋め込みとして表現した。このアプローチは、ドキュメントの視覚的・構造的完全性を維持し、従来のOCRとセグメンテーションの課題を回避し、マルチモーダルデータのRAG性能を向上させた。
ColBERTをベースにしたColPaliは、ビジョン言語モデル(VLM)を統合することで、この技術革新をマルチモーダル検索に拡張します。これにより、テキスト、画像、図を含む多様なコンテンツ・タイプの統一的な表現が可能になります。ColPaliは、従来の光学式文字認識(OCR)手法の落とし穴を回避し、文書の構造的・視覚的特徴を保持します。この進歩により、マルチモーダルなデータセットに対するRAGの性能が大幅に向上し、テキスト情報と視覚情報を理解する必要があるアプリケーションにとって理想的なツールとなっています。

図:ColPaliの仕組み
LLM時代の知識工学
2024年、オントロジーやナレッジグラフ(KG)のような構造化された知識ツールが復活を遂げ、大規模言語モデル(LLM)を事実データに基づいた回答で補完するようになった。このアプローチは、幻覚を減らし、より正確な、ドメインに特化した検索システムを可能にした。注目すべき革新的な技術として、Graph RAGがある。これは、KGを検索プロセスに統合することで、従来のRAGシステムを拡張したものである。意味的類似性だけに焦点を当てたベースラインRAGとは異なり、グラフRAGはマルチホップ推論をサポートし、異種データ点をリンクすることで、歴史的関係を辿ったり、複雑なデータセットをナビゲートしたりするような複雑なクエリに答える能力を高めている。
LLMは現在、構造化されていないテキストを、実体とその相互関係を表す構造化された知識グラフにシームレスに変換することができる。KGと組み合わせることで、これらのシステムはセマンティック推論を促進し、従来のRAGパイプラインの限界を克服して、より深い洞察を提供します。これらの進歩は、特にデータ集約的でリスクの高い業界において、ドキュメントの構文解析と前処理におけるLLMの変革的なインパクトを強調するものです。

図KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation | 出典
Text2SQL:データアクセスの民主化
SQLやデータベース・スキーマの複雑さにより、データ・アクセスは熟練したアナリストに制限されることが多い。2024年、Text-to-SQLテクノロジーは、技術者でないユーザーにも平易な言語を使ってデータベースへのクエリを実行できるようにした。このようなテクノロジーは、LLMを使用して自然言語を正確なSQLクエリに変換し、分析ワークフローを変革し、組織全体のデータ主導の意思決定を民主化する。
RAGパイプラインと統合されたText2SQLは、構造化データベースと非構造化検索システムのギャップを埋め、AI主導の洞察をより身近なものにした。一方、ベクトル・データベースは、関連するカーディナリティの高いデータや関連するSQL例を格納することで、LLMがSQLを構成するのを助ける重要なツールである。
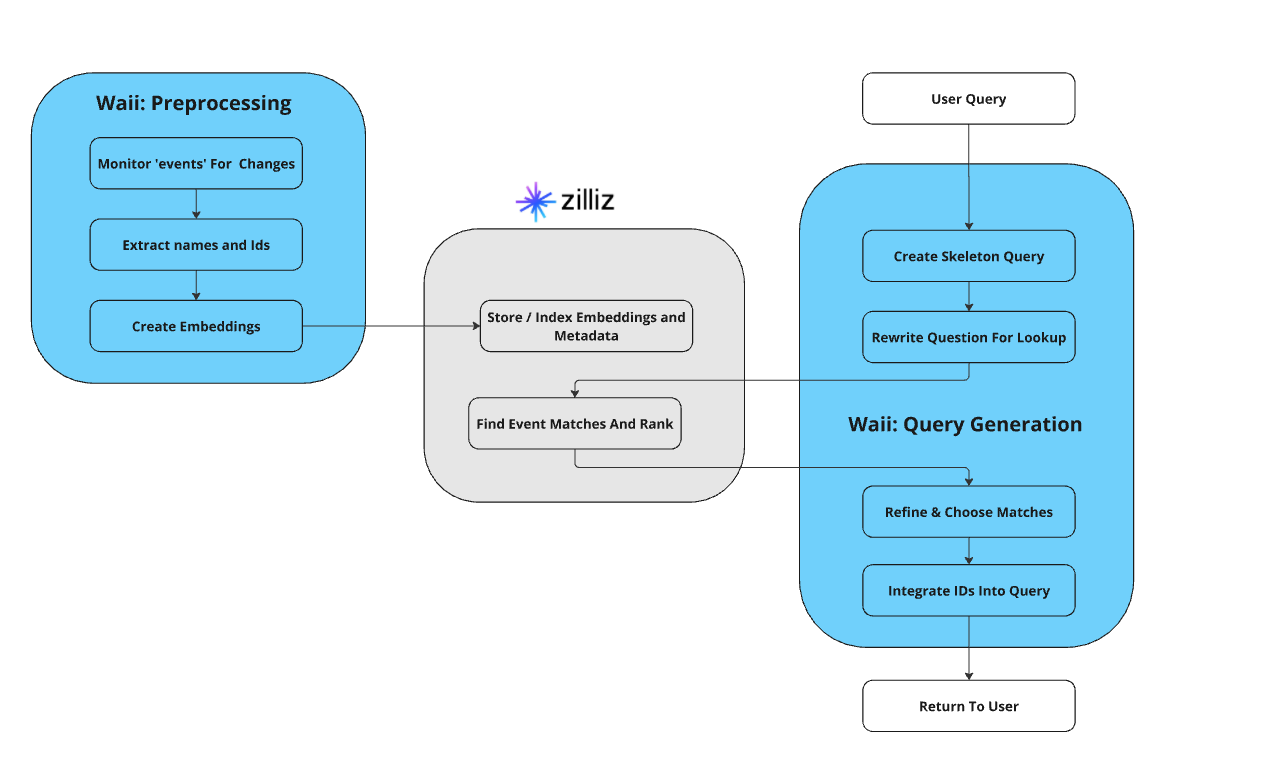
図- Text2SQLを実装するためのZilliz CloudとWaiiの仕組み
2024年の変革期を振り返る
2024年は[情報検索(IR)]にとってターニングポイントとなった年である(https://zilliz.com/learn/what-is-information-retrieval) ディープラーニングと大規模言語モデル(LLM)の進歩により、情報の検索、処理、分析方法が再定義された。
テキスト埋め込みモデルは現在、従来の全文検索システムを補完、あるいは代替し、より正確で文脈を考慮した結果を提供している。画像検索は目覚ましい進歩を遂げている。かつては何百もの特殊な分類モデルを必要としていたタスクが、multimodal embedding modelsによって合理化され、テキスト、画像、その他のデータ形式を単一の効率的なフレームワークに統合している。同様に、LLMは知識エンティティのラベリングをより速く、よりコスト効率よくし、完全に自動化された知識グラフの生成を可能にした。一方、自律エージェントがSQLクエリを生成してリレーショナルデータベースから洞察を取得するようになり、分析が簡素化され、データアクセシビリティが向上した。
長年にわたり情報検索に深く携わり、Milvusベクトルデータベースを開発した者として、このような変革的な変化を目の当たりにするのはエキサイティングなことだ。2024年のイノベーションは強固な基盤を築き、2025年はこの勢いをベースに、RAG(Retrieval-Augmented Generation)、マルチモーダル・エンベッディング、そしてagentic workflowsを活用した革新的なアプリケーションの急増が約束されている。
2025年のビジョン:MilvusとAIインフラの未来
AIの成熟が進むにつれ、堅牢でスケーラブルなデータインフラの必要性がますます高まっている。Milvusのようなベクターデータベースや、ディープラーニングベースのIRの要であるZilliz Cloudは、この課題に立ち向かおうとしています。Zilliz](https://zilliz.com/)の2025年に向けたビジョンは野心的なもので、検索速度の高速化、ストレージコストの削減、既存のデータエコシステムや様々な新興AI技術とのシームレスな統合を実現することです。
今度リリースされるMilvus 3.0は、ベクトルデータベースの新時代の幕開けとなる。数千億のデータポイントを比類のないスピードと効率で処理できるクラウドネイティブなベクトルレイクを導入する。10ミリ秒以下のクエリー・レスポンスタイムとほぼリアルタイムのインタラクティブなデータ探索により、Milvus 3.0はAIを活用したアプリケーションの可能性を再定義します。ベクターデータベースが最新のAIインフラストラクチャの礎石としての役割を確固たるものにするにつれて、AI駆動型アプリケーションの次の波への機会が解き放たれるでしょう。

AIの2025年への期待に胸を膨らませているのであれば、今が構築を始める絶好の機会です。包括的なガイドとチュートリアルをご覧になり、最先端のAIアプリケーションを作成するための第一歩を踏み出してください。

読み続けて

Zilliz Skills Breakdown: How AI Agents Master Vector Databases
Zilliz's Milvus Skill (pymilvus, 7 files) and Zilliz Cloud Skill (zilliz-cli, 14 modules) bring vector-DB dev and ops into one Claude Code session.

Announcing the General Availability of Zilliz Cloud BYOC on Google Cloud Platform
Zilliz Cloud BYOC on GCP offers enterprise vector search with full data sovereignty and seamless integration.

What is the K-Nearest Neighbors (KNN) Algorithm in Machine Learning?
KNN is a supervised machine learning technique and algorithm for classification and regression. This post is the ultimate guide to KNN.