




DeepRAG:大規模言語モデルのためのステップバイステップの検索への思考
あなたがドライブ旅行を計画しているとき、デジタル・アシスタントに「今、山へ行く最速ルートは?しかし、交通状況のライブ更新があれば、通行止めを検知し、より早く景色を楽しめるルートを案内してくれるはずだ。これは、大規模言語モデル(LLMs)の核となる限界を浮き彫りにしている。静的で事前に訓練された知識に依存するLLMsは、しばしば時代遅れの回答や不完全な回答につながる。検索補強型生成(RAG)は、LLMsをデータベースや検索エンジンのような外部の知識ソースと組み合わせることで、これに対処する。保存された知識だけに頼るのではなく、RAGは関連する情報を検索し、モデルの回答に組み込む。これは、最近の出来事や専門的なトピックに関する質問に答えるのに便利である。しかし、従来のRAGシステムは完璧とは言い難い。論文DeepRAG: Thinking to Retrieval Step by Step for Large Language Modelsで紹介されたDeepRAGは、より適応的なアプローチでこれらの問題を解決する。検索を単一のステップとして扱うのではなく、複雑な質問をより小さなサブクエリに分割し、各段階で内部知識に依存するか外部データをフェッチするかを決定する。さまざまな回答経路を探索するバイナリーツリー探索や、専門家の例を用いてモデルを学習させる模倣学習などの技術は、DeepRAGが必要なものだけを検索するのに役立つ。このステップバイステップのアプローチは無駄な検索を減らし、回答の精度を向上させる。この記事では、DeepRAGがどのように機能するのかを探り、その主要なコンポーネントを解き明かし、MilvusやZilliz Cloudのようなベクトルデータベースがどのように検索能力をさらに強化できるのかを示す。
静的知識とナイーブ検索の欠点
大規模な言語モデル(LLM)は、首尾一貫した応答を生成することに優れているが、クエリが最新の、特定の、または深い文脈の知識を要求する場合には不十分である。これは、LLMの知識が学習中に収集された静的なデータセットに基づいているため、リアルタイムまたは特殊な情報を必要とする質問に対する回答能力が制限されるためです。トレーニングが完了すると、その知識は凍結されるため、適時性、特異性、動的な文脈を要求するクエリには信頼できない。
時事問題やライブ・アップデートのようなトピックでは、LLMは時代遅れの情報を提供する。今年のワールドカップで優勝したのは誰ですか」*** と尋ねられると、モデルは最新の結果ではなく、過去の大会に基づいて答えるかもしれない。
LLMは、医学、法律、技術標準のようなニッチな領域で失敗することが多い。例えば、FDAが承認したアルツハイ マー病の最新の治療法に関するクエリは、時代遅れの推奨事項を出すかもしれない。
ダイナミックコンテキスト:株価、ソーシャルメディアトレンド、天候など、急速に進化する情報は、彼らの手の届かないところにある。外部からのアップデートがなければ、モデルは情報に基づいた回答を提供するのではなく、推測することになる。
検索補強型生成(RAG)は、応答を生成する前にデータベース、検索エンジン、またはAPIから外部情報を取り込むことで、LLMの能力を拡張する。しかし、従来のRAGシステムには独自の問題がある:
- 過剰検索:** RAGがあまりにも多くの無関係な文書を検索すると、モデルにノイズが殺到し、回答の精度が低下する。例えば、"2023年のハワイの山火事の原因は?"と質問された場合、従来のRAGシステムは、特定の原因ではなく、山火事防止や歴史的な火事に関する様々な記事を検索するかもしれない。
- 不十分な検索: 不十分な検索や広すぎる検索は、重要な詳細を見逃してしまう可能性があります。ハワイの山火事の原因」だけを検索すると、原因が送電線の切断にあるとする公式な調査報告が除外される可能性があります。
- 大量の不必要な情報を検索し処理することは、回答の質を向上させることなく、応答時間とコストを増加させます。
これらの問題の根本は、従来のRAGシステムがすべてのクエリを同じように扱い、それが必要かどうかを評価することなく、無差別に外部情報を検索していることにある。このような適応性の欠如は、単純な質問に対しては非効率的であり、複雑な質問に対しては不完全な回答をもたらす。光合成とは何か」*のような単純なクエリは、答えがすでにモデルの内部知識の中にあるため、外部からの検索を必要としません。対照的に、「mRNAワクチンの有効性を異なる年齢層で比較する」のような複雑な質問や複数ステップの質問では、外部からの情報が必要となり、最も関連性の高いデータを取得するために、クエリをサブクエリに分割する必要があります。
このような硬直的なアプローチは、内部知識と外部検索のバランスを取り、各クエリの複雑さと要件に基づいて戦略を調整できる、より適応的なシステムの必要性を強調している。
ステップバイステップでDeepRAGが検索を適応させる方法
DeepRAGは、人間が複雑な質問にどのようにアプローチするかを反映した適応プロセスを導入することで、従来のRAGシステムの限界に対処している。DeepRAGは、情報を一度に、あるいはクエリごとに取得するのではなく、質問をより小さく管理しやすいサブクエリに分解し、各ステップで外部情報が必要かどうかを判断する。この適応的なプロセスは、不必要な検索を減らし、精度を向上させる。
DeepRAGのアプローチの鍵は、検索プロセスをどのように構造化し、ナビゲートするかにある。クエリを単一のブロックとして扱うのではなく、検索ナラティブ、つまり、各サブクエリが前のステップを土台にして徐々に完全な答えを形成していく論理的シーケンスに従う。すべての段階で、DeepRAGはアトミックな判断を行い、内部の知識に依存するか、外部データを取得するかを決定する。
DeepRAGが人間の思考をどのように反映するかを示す以下の図を見てください。
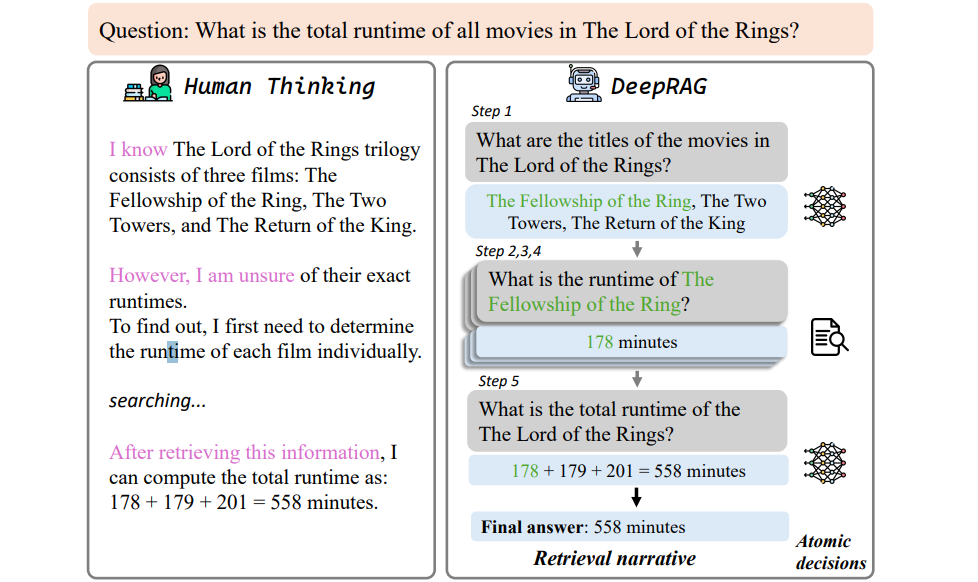
図1_:DeepRAGがどのように人間の思考を反映するかを示す図_。
DeepRAGは、明確に定義された検索ナラティブを通して推論プロセスを構造化し、各ステップで正確な原子決定を行うことにより、必要なときだけ検索し、適切なときは内部知識に依存することを保証する。このバランスの取れたアプローチは、過剰な検索や無関係な検索に関連する計算コストを削減しながら、より効率的で正確な回答を導く。この適応型フレームワークは、回答品質を向上させるだけでなく、リソース使用量を最適化し、DeepRAGを複雑な情報検索タスクにとってより実用的でスケーラブルなソリューションにする。
DeepRAGの適応検索を支えるコアコンポーネント
DeepRAGの適応的検索プロセスは、複雑な質問を分解し、外部情報を取得するタイミングについて情報に基づいた決定を行い、学習を通じて推論戦略を洗練させる構造化されたアプローチに依存している。このプロセスは、マルコフ決定過程(MDP)モデリング、バイナリーツリー探索、模倣学習、キャリブレーションの連鎖という4つの相互接続されたコンポーネントの上に構築されており、これらすべてが、質問に答える際の効率と精度のバランスをとるために協働する。
マルコフ決定過程(MDP)の概要
DeepRAGの意思決定プロセスの中心はマルコフ決定過程(MDP)フレームワークであり、システムが質問に答えるために必要なステップを体系的にマッピングするのに役立つ。MDPは4つの要素から構成される:
状態(S):**質問に対する回答の現在の進捗状況を表す。状態には、元の質問と、これまでに生成されたサブクエリおよびそれ に対応する回答が含まれる。
アクション(A):** 各状態において、モデルはアクションを導くために2つの決定を行います。終了の決定は、モデルが停止して最終的な答えを提供すべきか、サブクエリを生成して続行すべきかを決定します。原子決定は、モデルが次のサブクエリに対処するために、内部知識を使用すべきか、外部情報を取得すべきかを決定する。
遷移(P):**選択されたアクションに基づいて、システムがある状態から別の状態へ移動する方法を定義します。
報酬(R):** 正解を見つけたモデルには報酬を与え、不必要または過剰な検索にはペナルティを与える採点システム。
例えば、システムが"ロード・オブ・ザ・リングの全映画の合計上映時間は?"と尋ねられたとする。初期状態s_0は質問のみを含む。モデルの最初のアクションは、"ロード・オブ・ザ・リングの映画のタイトルは?"のようなサブクエリを生成することです。そして、内部知識を使用するか、外部データを取得するかを決定します。映画のリストが得られると、システムは新しい状態s_1に遷移する。次に、"The Fellowship of the Ring? "のようなサブクエリを生成し、必要な情報をすべて収集するまで、同様の決定を続ける。最後に、ランタイムを合計し、合計を提供し、終端状態に達する。
バイナリーツリー探索戦略
この意思決定プロセスを効率的に管理するために、DeepRAGはバイナリツリーサーチを使用する。この戦略により、システムは各決定をツリーのノードとして扱うことで、複数の推論パスを探索できる。各サブクエリに対して、DeepRAGは2つのブランチを生成する:
1つの枝は、パラメトリック知識(内部知識)の使用を表す。
もう一方は、外部文書の検索を表す。
システムはツリーを探索しながら、最終的な回答につながるサブクエリと回答のシーケンスである検索ナラティブを構築する。バイナリツリー探索は、モデルが異なる推論経路を評価し、検索が必要な場合と内部知識で十分な場合を決定するのに役立つ。
このアプローチにより、DeepRAGは複雑なクエリをより小さく管理しやすいサブクエリに分解し、各ステップで適応的な決定を行うことができる。バイナリーツリーをナビゲートすることで、モデルは事前に訓練された知識に依存することと外部データを検索することのトレードオフのバランスをとることができ、最終的に応答の精度と効率を向上させることができる。バイナリツリー探索の構造化された性質により、DeepRAGは必要なときに情報を取得するだけでなく、不必要な取得を回避し、回答の質を維持しながら計算リソースを最適化する。
模倣学習
バイナリツリー探索はDeepRAGが推論パスを探索するのに役立つが、どのパスが最も効率的かを学習する必要がある。そこで、模倣学習 が役割を果たす。模倣学習は、以下のアルゴリズムに従って、最適な推論パスの例、つまり検索回数を最小にしながら正しい答えを導くパスの例を示すことで、DeepRAGに学習させる。
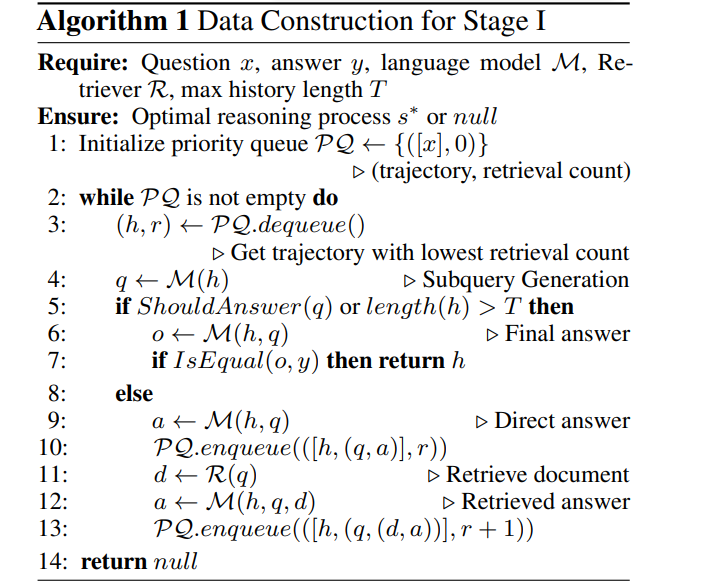
図: DeepRAGが最適推論経路を構築するためのアルゴリズム。
上図は、DeepRAGが模倣学習を利用して最適な推論経路を構築する方法の概要である。このシステムは、推論の軌跡を探索するために優先キューを採用し、検索回数が少ないパスを優先する。アルゴリズムの仕組みは以下の通りである:
1)初期化:検索回数がゼロの優先キューに元の質問を入れることから始める。
2)パスの探索: アルゴリズムは、検索回数が最も少ないパスをデキューし、次のサブクエリを生成します。
3)意思決定:各ステップにおいて、モデルは、停止して最終的な回答を提供するか(終了の意思決定)、サブクエリの生成を継続するかを決定する。
4)回答生成:* モデルが直接回答することを選択した場合、このパスをキューに追加する。文書を検索することを決定した場合、検索カウントをインクリメントした新しいパスを追加する。
5)終了: アルゴリズムが最小の検索量で正しい答えに到達する推論パスを特定 するまで、プロセスは継続する。
校正の連鎖
模倣学習後でさえ、DeepRAGは外部情報を検索するタイミングと内部知識に頼るタイミングを見極めるのに苦労するかもしれない。意思決定プロセスを洗練させるために、DeepRAGは較正の連鎖を用いる。較正の連鎖は、各サブクエリに対して好ましい行動(検索または内部知識)を示す例であるプリファレンスペアに基づいて、モデルの検索行動を微調整する:
L = - log σ [ β log ( πθ(yw | si, qi) / πref(yw | si, qi) )- β log ( πθ(yl | si, qi) / πref(yl | si, qi) )]
この式がどのように機能するかは以下の通りである:
σ**はロジスティック関数で、モデルの出力を正規化する。
β**はハイパーパラメータで、好ましい決定パスから外れる場合のペナルティを制御します。
πθ(yw|si,qi)は、パラメトリック知識を用いて、状態siでサブクエリqi**に答える確率を表します。
πθ(yl | si, qi) は、検索された文書に基づいてサブクエリに答える確率を表す。
- πref**は比較のベースラインとして使われる参照モデルである。
この損失関数は、模倣学習中に提供された最適な例に基づいて、内部知識を使用するか外部データを検索するかを決定し、最も効率的な推論経路を優先するようにモデルを促す。モデルが不必要に情報を検索したり、必要なときに検索できなかったりした場合、キャリブレーションの連鎖がこれらの傾向を修正し、システムが効率と精度のバランスを達成するのを助ける。
次の図は、DeepRAGがバイナリツリー探索、模倣学習、キャリブレーションの連鎖をどのように統合し、効率的な推論経路を構築しているかを示している。これは、DeepRAGが内部知識と外部検索のバランスをとることを可能にする、クエリの分解、意思決定、モデルの較正の段階的プロセスを示している。
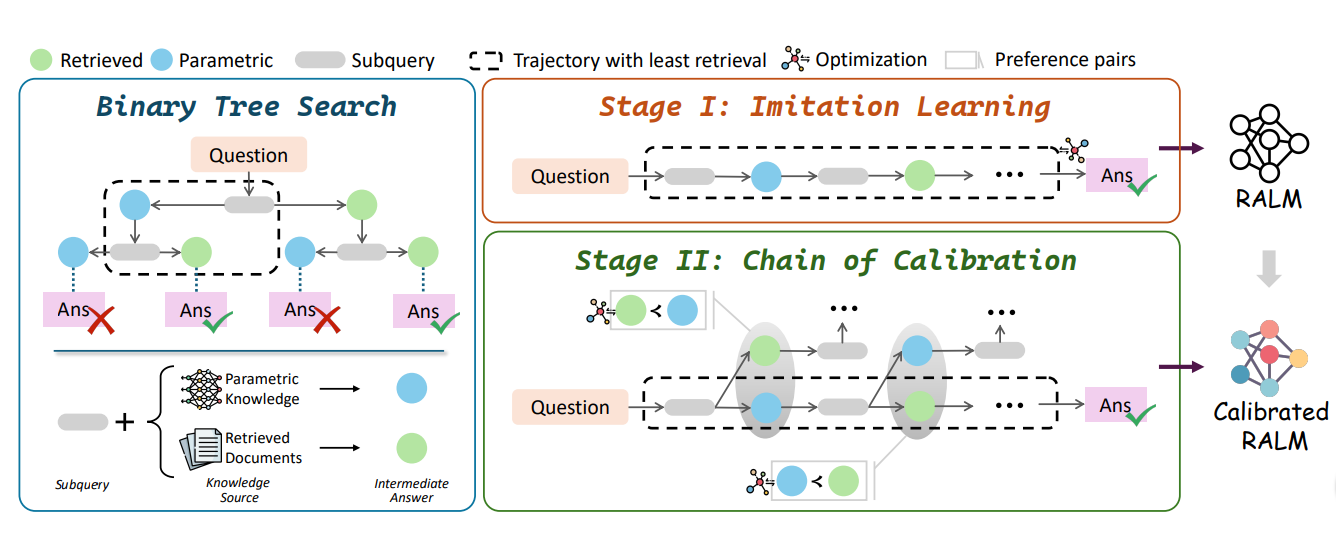
**DeepRAGは、MDPモデリング、バイナリツリー探索、模倣学習、キャリブレーションの連鎖を統合することで、複雑で多段階の質問に対応できる適応的な検索プロセスを実現する。
ベンチマークにおけるDeepRAGの性能
検索戦略と適応的推論プロセスを改良した後、DeepRAGは複数のオープンドメインの質問応答(QA)ベンチマークで強力な性能を実証した。これらのベンチマークは、DeepRAGが複雑なクエリを分解し、効率的な検索決定を行い、動的またはマルチホップなシナリオでも正確に回答を生成する能力を評価するものである。DeepRAGは5つの多様なデータセットで評価されている:HotpotQAと2WikiMultihopQAはマルチホップのファクトQA、CAGは時間に敏感なクエリ、PopQAとWebQuestionsはオープンドメインのQAタスクである。各データセットは、多段階推論、データの時間的シフト、分布外のクエリの処理など、ユニークな課題を提示する。
HotpotQAにおいて、DeepRAGは51.54のF1スコアを達成し、UAR(34.2)やFLARE(32.0)を凌駕した。複雑なマルチホップ推論を必要とする2WikiMultihopQAでは、DeepRAGはF1で53.25を達成し、マルチステップクエリにしばしば苦戦するベースラインモデルを凌駕している。CAGのような時間に敏感なタスクでは、DeepRAGは59.8の完全一致(EM)スコアに達し、従来のRAGシステムを凌駕している。PopQAやWebQuestionsのようなオープンドメインのQAデータセットでは、DeepRAGはそれぞれ43.2と38.8のEMスコアを達成し、不要な検索を減らしながら高い精度を維持している。これらの結果は、DeepRAGの検索効率と回答精度のバランスをとる能力を強調するものであり、外部情報を取得するタイミングと内部知識に依存するタイミングを効果的に判断することで、従来のRAGシステムや密な検索器を凌駕している。
検索を強化するためのDeepRAGとベクトルデータベースの統合
DeepRAGの強みの一つは、外部情報を取得するタイミングと内部知識に依存するタイミングを決定する能力である。しかし、検索の質と効率は、データの保存と検索に使用するシステムにも依存する。そこで、MilvusやZilliz CloudのようなベクトルデータベースがDeepRAGのパフォーマンスを向上させ、大量の非構造化データを扱うためのスケーラブルで効率的なソリューションを提供する。
ベクトルデータベースは、データを 高次元ベクトルとして格納し、高速で正確な類似性検索を可能にする。DeepRAGのワークフローでは、システムが外部情報を必要とするサブクエリを生成すると、Milvusのようなベクトルデータベースに問い合わせ、意味的類似性に基づいて最も関連性の高いドキュメントを見つけることができる。このアプローチは、検索データの速度と関連性の両方を向上させ、DeepRAGの回答の品質に直接影響する。
Milvusは、高性能な類似検索用に最適化されたオープンソースのベクトルデータベースであり、10億規模のベクトルデータを扱うことができる。Milvusの上に構築されたZilliz Cloudは、スケーリングとメンテナンスを簡素化するマネージドクラウドベースのソリューションを提供する。これらのデータベースは、DeepRAGが特に大規模なアプリケーションで効率的な検索を実行するために必要なインフラストラクチャを提供する。
例カスタマーサポートの自動化 DeepRAGとMilvusを統合し、複雑な顧客からの問い合わせに対応するカスタマーサポートシステムを考えてみよう。ユーザが質問を送信します:この質問には複数のステップがあり、企業のドキュメントのさまざまなセクションからの情報が必要です。
1)DeepRAG は、複雑なクエリをより小さく管理しやすいサブクエリに分解することから始めます。この場合、2 つの異なるサブクエリを特定します:アカウントを別のユーザに転送するにはどうすればよいですか?この分解により、DeepRAGはユーザのリクエストの各部分に個別に答えることに集中でき、検索効率と最終的なレスポンスの質の両方が向上する。
2)サブクエリが生成されると、DeepRAGはMilvusを使用して関連ドキュメントを検索する。各サブクエリはベクトルに変換され、Milvusに格納された文書と照合される。Milvusもベクトルとしてindexedされている。最初のサブクエリに対して、システムは"Transferring Account Ownership "というタイトルの文書を検索する。2つ目のサブクエリでは、"Updating Your Billing Details "**というドキュメントを見つけ、ユーザーが支払い情報を変更する方法を概説する。Milvusのセマンティック検索は、最も関連性の高い文書のみを確実に検索し、不必要なデータを最小限に抑える。
3)ステップ3 - 答えの組み立て:* 文書を検索した後、DeepRAGは最も有用な詳細を抽出するために情報を処理する。検索された記事の内容に目を通し、重要なステップを要約します。口座振替サブクエリの場合、DeepRAG は以下のような応答を生成します:アカウントを譲渡するには、[設定] > [アカウント管理] に移動し、[所有権の譲渡] を選択します。新しいユーザの詳細を入力し、変更を確認します:課金情報を更新するには、課金設定にアクセスし、「支払い方法を編集する」をクリックします。必要な変更を行い、保存してください」** このステップにより、ユーザーは特定の質問に合わせた明確で簡潔な指示を受け取ることができます。
4)ステップ4 - 最終回答:* 最後に、DeepRAGは個々の回答を首尾一貫した回答にまとめ、ユーザーの複数の部分からなる問い合わせに直接対応する。システムは、両方のサブクエリからのガイダンスをシームレスな回答に統合し、複数の文書に目を通させることなく、ユーザーに必要なすべての情報を提供する。このサブアンサーの統合により、ユーザーの問題を効率的に解決する、完全で有益な回答が得られます。
この例では、DeepRAGとMilvusの統合により、システムは複雑なクエリを効率的に処理できる。DeepRAGのステップバイステップの推論とMilvusの高速かつ正確な検索が組み合わされることで、ユーザは無関係な文書に目を通すことなく、正確で完全な回答を得ることができる。
このアプローチは、MilvusやZilliz CloudのようなベクトルデータベースがDeepRAGの検索プロセスをどのように強化できるかを浮き彫りにし、効率的で正確な情報検索が重要な実世界のアプリケーションに適している。
DeepRAGの今後の方向性
DeepRAGは検索補強型生成において大きな進歩を遂げたが、今後の研究でその能力をさらに高めることができる領域がある:
1)マルチモーダル検索の統合:画像、音声、動画などのマルチモーダルデータを扱えるようにDeepRAGを拡張すれば、その適用範囲は大きく広がる。この拡張により、システムは多様なソースからの情報を処理・検索できるようになり、テキスト以外の知識を必要とする、より複雑なクエリに回答できるようになる。例えば、医療現場において、DeepRAGはテキストレポートと関連する医療画像の両方を取得し、より包括的な回答を提供することができる。
2)コンテキストを考慮した検索判断:よりコンテキストを考慮した検索判断を行うDeepRAGの能力を向上させることは、次のステップとして極めて重要である。現在、システムは外部データを取得するタイミングを決定するために、MDPベースのフレームワークに依存しているが、将来の反復では、クエリの意図とコンテキストのより微妙な理解を組み込むことができる。そうすることで、検索が必要なタイミングをより適切に評価し、複雑であいまいなクエリに対してアプローチを調整し、効率と精度の両方を向上させることができるだろう。
3)リアルタイムかつ動的なデータ検索:*リアルタイムのデータソースにアクセスして処理するDeepRAGの能力を強化することで、時間に敏感なアプリケーションに対してより効果的になる。ニュースフィードや株式市場の更新のようなライブデータストリームを統合することで、DeepRAG は最新の情報を必要とするクエリを処理できるようになる。この機能は、金融、ニュースアグリゲーション、緊急対応など、最新データへのアクセスが重要な領域で特に価値がある。
結論
DeepRAGは、適応的なクエリ分解と効率的な検索ストラテジーを組み合わせることで、不要な検索を最小限に抑えながら、より正確な回答を導く、検索拡張世代を進化させる。ベンチマークにおけるその強力な性能は、推論と検索効率を向上させ、複雑なマルチステップクエリを処理する能力を浮き彫りにしている。コアモデルは独立して動作するが、DeepRAGをMilvusやZilliz Cloudのようなベクトルデータベースと統合することで、大規模アプリケーションにおける検索能力をさらに強化することができる。マルチモーダルな検索、コンテキストを考慮した判断、リアルタイムのデータアクセスなど、今後の改良により、DeepRAGは複雑な情報検索タスクに幅広く対応する汎用的で強力なソリューションになる可能性が高い。
その他のリソース
論文
[2502.01142] DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
[2304.03765] マルコフ意思決定プロセス設計A Framework for Integrating Strategic and Operational Decisions](https://arxiv.org/abs/2304.03765)
ロバストなマルコフ決定過程:AIと形式手法の出会いの場](https://arxiv.org/html/2411.11451v1)
論文
Milvusベクトルデータベース・ドキュメント](https://milvus.io/docs)
読み続けて

Migrating Self-Managed Milvus to Zilliz Cloud for >99% Latency Reduction
Step-by-step guide to migrating 50M vectors from self-managed Milvus to Zilliz Cloud using milvus-backup. Achieve >99% query latency reduction with zero data loss.

Build Multimodal Search for 3D Assets with Tripo and Zilliz Cloud
Generate 3D assets with Tripo, then search them by text, image, and metadata with multimodal embeddings and Zilliz Cloud.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.