




Pgvectorで始める:ベクターデータベースを探求する開発者のためのガイド
近年、生成AIや大規模言語モデルの進歩に伴い、より効率的なデータ保存・検索システムの必要性が重要になってきている。ベクトルデータベース](https://zilliz.com/blog/what-is-a-real-vector-database#What-is-a-vector-database)と呼ばれる新しいタイプのデータベースが登場し、AIコミュニティで広く人気を集めている。
ベクトルデータベースは、ベクトル埋め込みと呼ばれる高次元データの格納とクエリに優れており、複雑なデータ表現を扱うAIアプリケーションに最適である。従来のデータベースとは異なり、ベクトルデータベースは効率的に類似性検索を実行し、現代の多くのAIタスクに不可欠な非構造化データを扱うことができる。
それでも、MySQLやPostgreSQLのような伝統的なリレーショナル・データベースは、長い間、開発者がよく使う選択肢であり、古い習慣はなかなか消えない。これらのツールを選ぶ開発者の多くは、信頼できるシステムでベクトル検索に着手しようとしてきた。PostgreSQLのファンにとって、postgresのベクトルデータベースはPgvectorと呼ばれています。
この記事では、この広く使われているリレーショナルデータベースにベクトルインデックスの機能をもたらすPostgreSQLの拡張であるPgvectorについて調べます。インデックスの作成方法、近似最近傍検索の起動方法、Pgvectorの利点とその制限に焦点を当て、Pgvectorがどのようにベクトル類似の近似最近傍検索を行うかを調べます。さらに、Pgvectorと特殊なベクトルデータベースを比較し、それぞれのソリューションが最も適している場所を強調します。
もしあなたが従来のデータベースに慣れ親しみ、AI主導のデータ管理の進化する状況に適応しようとしている開発者であれば、このガイドはPgvectorを使い始めるための知識を提供します。
Pgvectorとは?
AIと機械学習は現在、テクノロジー、医療、自動車を含む多くの業界で使用されています。これらの分野では、データはしばしばベクトル埋め込み(画像やテキストの特徴をとらえた数値)として表現されます。似たようなベクトル埋め込みは、数学空間において互いに近接しています。
Pgvectorは、一般的なオープンソースデータベースシステムであるPostgreSQLの拡張です。これは、通常のデータと一緒にベクトル埋め込みを保存し、検索する機能を追加します。Many people call this their "postgres vector database."
Pgvectorでの作業は、標準的なSQLデータベースを使うのと同じです。ベクトル列を作成したり、ベクトルを含む新しいテーブルを作成したり、類似したベクトルを検索したりするコマンドは、SQLを知っている人にはおなじみのものです。
Pgvectorは、AIアプリケーション、推薦システム、retrieval augmented generation、複雑なデータを使用するプロジェクトのプロトタイピングに便利です。Pgvectorは、ベクトル・ストレージに関する広範な知識を必要とせずにベクトル値を格納する効率的な方法を提供します。
Pgvector の主な特徴は以下の通りです:
- ベクトルストレージ:PostgreSQLの通常のデータと一緒にベクトルの埋め込みを格納することができます。
- 類似検索:Pgvector は、AI アプリケーションで類似したアイテムを見つけるために重要な、厳密および近似最近傍探索の両方をサポートします。
- 汎用性:Pgvectorは様々なタイプのベクトル(単精度、半精度、binary、 sparse)に対応し、L2距離、内積、余弦距離、L1距離、ハミング距離、 ジャカード距離のような様々な類似性尺度をサポートします。
- 言語サポート:PostgreSQLに接続可能なあらゆるプログラミング言語で使用可能。
- データベース機能:PgvectorはPostgreSQLの標準機能であるデータの一貫性やリカバリを維持します。
- SQL統合:SQLに精通したユーザはPgvectorを簡単に扱うことができます。ベクトル列の作成と検索の実行に似たコマンドを使用するからです。
また、データ一貫性やリカバリのような通常のデータベース機能も提供します。
Pgvectorは2種類のインデックスを提供し、検索速度と精度のバランスをとることができます:
1.HNSW:多層グラフを作成する。HNSW]():多層グラフを作成します。クエリーは高速ですが、セットアップは遅く、より多くのメモリを使用します。
2.IVFFlat:ベクトルをグループに分割する。セットアップは早く、メモリ使用量も少ないが、HNSWほどクエリーは速くない。
これらのインデックスオプションにより、ユーザーはニーズに応じて検索速度と精度のバランスをとることができる。
この拡張機能はPostgreSQLとシームレスに統合されているため、ユーザは高度なベクトル操作を実行しながら使い慣れたSQL構文を活用することができます。これによりPgvectorは、伝統的なリレーショナルデータベースと最新のAIや機械学習のニーズの橋渡しをする強力なツールとなります。
Pgvectorのセットアップ
では、まずPgvectorをPostgreSQLと統合するためにセットアップするところから始めましょう。システムにPostgreSQLがインストールされていることを確認してください。Macの場合は、Homebrew経由で簡単にインストールできます:
brew install postgresql
PostgreSQLがインストールされているかどうかは、以下のコマンドを実行すればすぐに確認できる:
psql --バージョン
すると、以下のようにシステムにインストールされているPostgreSQLのバージョンが表示されます:

make`もインストールする必要がある。Homebrewを使って以下のコマンドを実行すれば簡単にインストールできる:
brew install make
すると、以下のように make がインストールされるはずだ:

ベクトルデータベースの世界に飛び込む前に、PgvectorをセットアップしてPostgreSQLと統合する必要があります。必要な手順を説明しましょう。
1.Pgvector のリポジトリをクローンします。
cd /tmp && git clone --branch v0.4.4 https://github.com/pgvector/pgvector.git
2.このディレクトリに移動し、以下の make コマンドを実行する:
cd pgvector && make && make install
Pgvector と Postgres の統合
以下のコマンドを使用して、PostgreSQLコマンドラインインタフェース(psql)を開きます。このステップでは、Postgresをコマンドラインで起動し、ターミナル上で直接Postgresコマンドを実行できるようにします:
psql
Postgresを使用するユーザーを作成するには、以下のコマンドを使用します:
CREATE USER <user> WITH PASSWORD <password>
その後、上記のコマンドで作成した認証情報を使用して、そのユーザにログインしてください。あるいは、スーパーユーザとしてPostgresにログインすることもできます:
psql -U postgres
では、次のコマンドで新しいデータベースを作成して作業してみよう:
データベース vectordb を作成する;
このデータベースを選択してみよう:
/c vectordb;
次に、vectordb データベースの Pgvector 拡張機能を有効にする:
拡張 pgvector を作成する;
この手順は、Pgvectorで使用する全てのデータベースに対して一度だけ実行する必要があります。
Pgvector の例
vectorsというテーブルにidとembedding` という2つのベクトルカラムを作ってみましょう。このテーブルとカラムはPostgreSQLのベクトルデータを格納する。
CREATE TABLE vectors (
id SERIAL PRIMARY KEY、
embedding float4[] -- ベクトル列
);
これで vectors テーブルにベクトルデータを挿入できるようになりました:
INSERT INTO vectors (embedding) VALUES
('{1.2, 0.8, -2.1}'),
('{-0.7, 2.4, 3.6}');
テーブルを表示するには、vectors テーブルに対して SELECT * クエリを実行すればよい。
SELECT * FROM vectors;
ベクトルの類似性検索に Pgvector を使う
ベクトルデータベースが類似性検索にどのように役立つかを説明しました。ここでは、与えられたクエリベクトルに似たベクトルを見つけるための簡単な類似検索クエリの書き方を説明します。
SELECT * FROM vectors
WHERE pgvector_cosine(embedding, '{0.9, -0.3, 1.8}') > 0.8;
通常の SELECT * クエリを WHERE 節で使用します。そして、 pgvector_cosine 関数を使用して、 embedding ベクトル列と与えられたクエリベクトル {0.9, -0.3, 1.8} の余弦類似度が 0.8 より大きい行を取得するように指定します。
Pgvector インデックスと制限
Pgvectorはベクトルを格納し、ベクトルを検索するための素晴らしい方法ですが、いくつかの明らかな欠点があります。
高次元のベクトルを扱う場合、Pgvectorにはスケーラビリティの問題があります。また、ベクトル・データを保存することは、追加のストレージやインデックス作成のオーバーヘッドをもたらすかもしれません。また、ベクトルデータが必要とするスペースと、それがクエリのパフォーマンスにどのような影響を与えるかを考慮することも重要です。
さらに、PgvectorはHNSWとIVFFlatの2種類のインデックス付きしかサポートしていません。この制限は、保存するデータセットのサイズだけでなく、保存するベクトルの特性にも影響します。それはまた、Pgvectorインデックスを使用したデフォルトのストレージ最適化がないことを意味します。
Pgvectorはvector embeddingsの格納と検索を可能にするPostgreSQL拡張であることを覚えておいてください。しかし、その能力や性能には限界があります。幸いなことに、Milvusのようなベクトル埋め込み専用のデータベースは、改良されたインデックスやアルゴリズムにより、遥かに良い仕事をしてくれます。
専用ベクトルデータベース
さて、Pgvectorとその応用と欠点について説明したところで、専用のベクトルデータベースの概念を紹介しましょう。
伝統的なデータベースの上にベクター検索プラグインを載せたPgvectorとは異なり、MilvusやZillizのような専用ベクターデータベースは、数百万から数十億の高次元ベクターデータを保存し、ほぼリアルタイムでクエリするために一から構築されています。これらは、高度なインデックス技術を活用して類似検索を効率的に処理し、類似性に基づく操作に優れたパフォーマンスを提供し、大規模なベクトルデータを処理し、AIや機械学習アプリケーションのための強力なAPIを提供します。
Milvus/Zillizのようなベクトルデータベース入門
Milvusのような専用のベクトルデータベースは、画像や動画の類似検索、自然言語処理、推薦システムなど、幅広いユースケースに対応しています。その汎用性の高さから、AI関連の多様なプロジェクトに適している。Milvus](https://zilliz.com/what-is-milvus)を理解し、Zilliz Cloudを使ってクラウドで活用する方法を理解しよう。
Milvus: オープンソースのベクトルデータベース
Milvusはオープンソースのベクトルデータベースであり、何十億もの高次元ベクトルの管理とクエリのための堅牢なソリューションを提供します。GPUインデックス、Arm64、範囲検索、upsert、CDCなど数多くのエキサイティングな機能を提供し、AIや機械学習アプリケーションの構築に最適なパフォーマンスとユーザーエクスペリエンスを保証します。これらの機能の詳細については、最新のMilvus 2.4リリースブログをチェックしてください。
Zilliz Cloud:クラウド上でMilvusインスタンスを利用できるフルマネージドサービス
Zillizクラウドは、MilvusインスタンスをSaaS(Software as a Service)の領域に取り込むクラウドベースのサービスとして運用されます。クラウドインフラストラクチャ、スケーラビリティ、運用サポートを提供することで、Milvusデータベースの展開と管理を簡素化します。Zillizは、開発者がインフラのセットアップやメンテナンスの複雑さを感じることなくMilvusの機能を利用できることを保証します。それはちょうどクラウドでPostgreSQLのためにAmazon RDSを使うようなものです。
Zilliz Cloudは無料ティアを提供し、すべての開発者がこのベクトルデータベースサービスに平等にアクセスできるようにしている。無料階層では、最大2つのコレクションが提供され、それぞれが768次元で最大50万ベクトルを収容し、より小規模なものではさらに多くのベクトルを収容することができる。この余裕のある容量により、インフラ投資を必要とせずに大きなデータ処理能力を得ることができます。
MilvusとZillizの選び方
データベースを完全にコントロールしたい場合は、セルフホスト型のMilvusインスタンスを選択することができます。ただし、ニーズやユースケースに応じてインフラを導入・管理する必要があります。
一方、クラウドベースのベクターデータベースを使用したい場合は、Zilliz Cloudを使用することができます。Zillizを利用することで、インフラストラクチャのメンテナンスを気にすることなく、クラウド上のMilvusを活用したアプリケーションの構築に集中することができます。
MilvusとZillizは、効率的なベクターデータ管理で開発者に力を与えますが、多様なデプロイの好みに対応しています。MilvusとZilliz](https://zilliz.com/zilliz-vs-milvus)のコラボレーションは、セルフホスティングの柔軟性を重視する場合でも、クラウドベースのシンプルさを重視する場合でも、プロジェクトの要求に沿ったオプションを提供します。
PgvectorとMilvusおよびZillizの比較
それでは、使いやすさ、パフォーマンス、柔軟性について、PgvectorとMilvus/Zillizを比較してみましょう。
使いやすさ
PgvectorはPostgreSQLとシームレスに統合されており、既にリレーショナルデータベースを使用している開発者には馴染みがあります。しかし、MilvusとZillizはSDKとAPIをインストールするために追加設定が必要です。良いニュースは、Milvus/Zillizを一度セットアップすれば、大規模な類似検索サービスを作成するのに1分もかからないということです。また、様々なプログラミング言語に対応したシンプルで直感的なSDKが用意されています。
インストールは別として、使用する際には少し学習曲線があります。PgvectorはPostgreSQLに精通しているので使いやすいようです。
パフォーマンスとスケーラビリティの分析
Pgvectorの大きな限界の一つは、インデックス作成機能が限られていることです。このベンチマーク](https://zilliz.com/blog/milvus-2.x-performance-benchmark-update)で実証されているように、複雑な類似検索の場合、Milvusは最適化されたインデックス作成機構によりPgvectorを凌駕します。
PgvectorとMilvusは、大規模なベクトルデータを効率的に扱うために設計された強力なベクトル検索スタックです。しかし、Milvus/Zillizはよりスケーラブルであり、数十億のベクトル埋め込みのデータセットを扱うことができる。
特徴セットと柔軟性
PgvectorがPostgreSQLにベクトル機能を提供するのに対して、Milvus/ZillizはAIアプリケーションに特化した機能を持つ専用のベクトルデータベースです。これらのデータベースはより機能が豊富で、カスタムベクトルデータベースの使用例に役立ちます。
Pgvector ベンチマーク vs. Milvus または Zilliz
VectorDBBenchはオープンソースのベクターデータベースのベンチマークツールです。市場で入手可能な主流のベクターデータベースとクラウドサービスを比較し、1秒あたりのクエリー数(QPS)、1ドルあたりのクエリー数(QP$)、P99レイテンシーに関する公平なベンチマーク結果を提供します。
例えば、VectorDBBenchを活用して、PgvectorとMilvusやZillizのベンチマークを行うことができます。ベンチマーク結果によると、MilvusとZillizはQPS、スピード、レイテンシに関してPgvector](https://zilliz.com/vector-database-benchmark-tool#comparison-section)を上回っています。
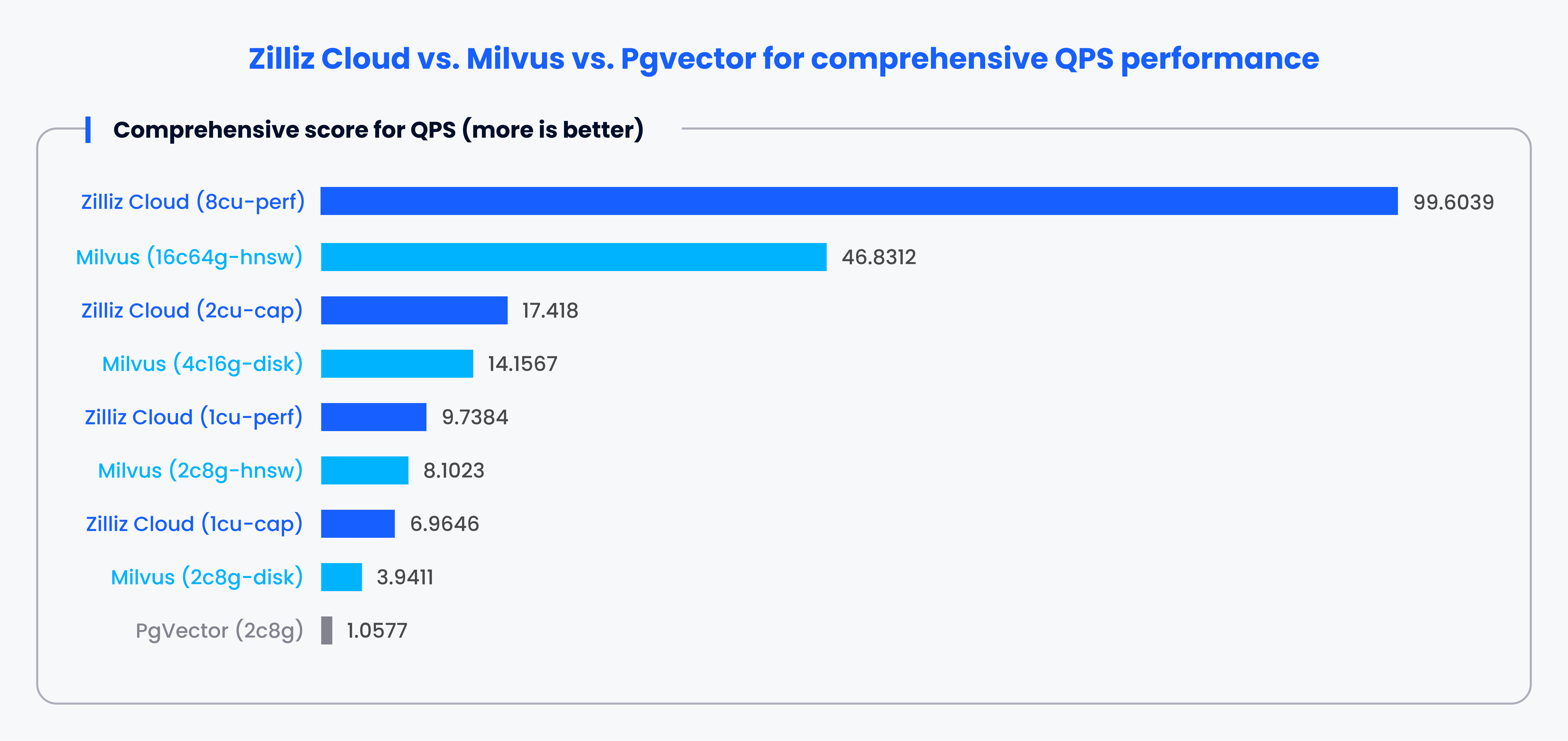
注:これは、特定のルールに従ったさまざまなケースにおける各システムの性能に基づく1~100のスコアである。スコアが高いほどパフォーマンスが高いことを示す。
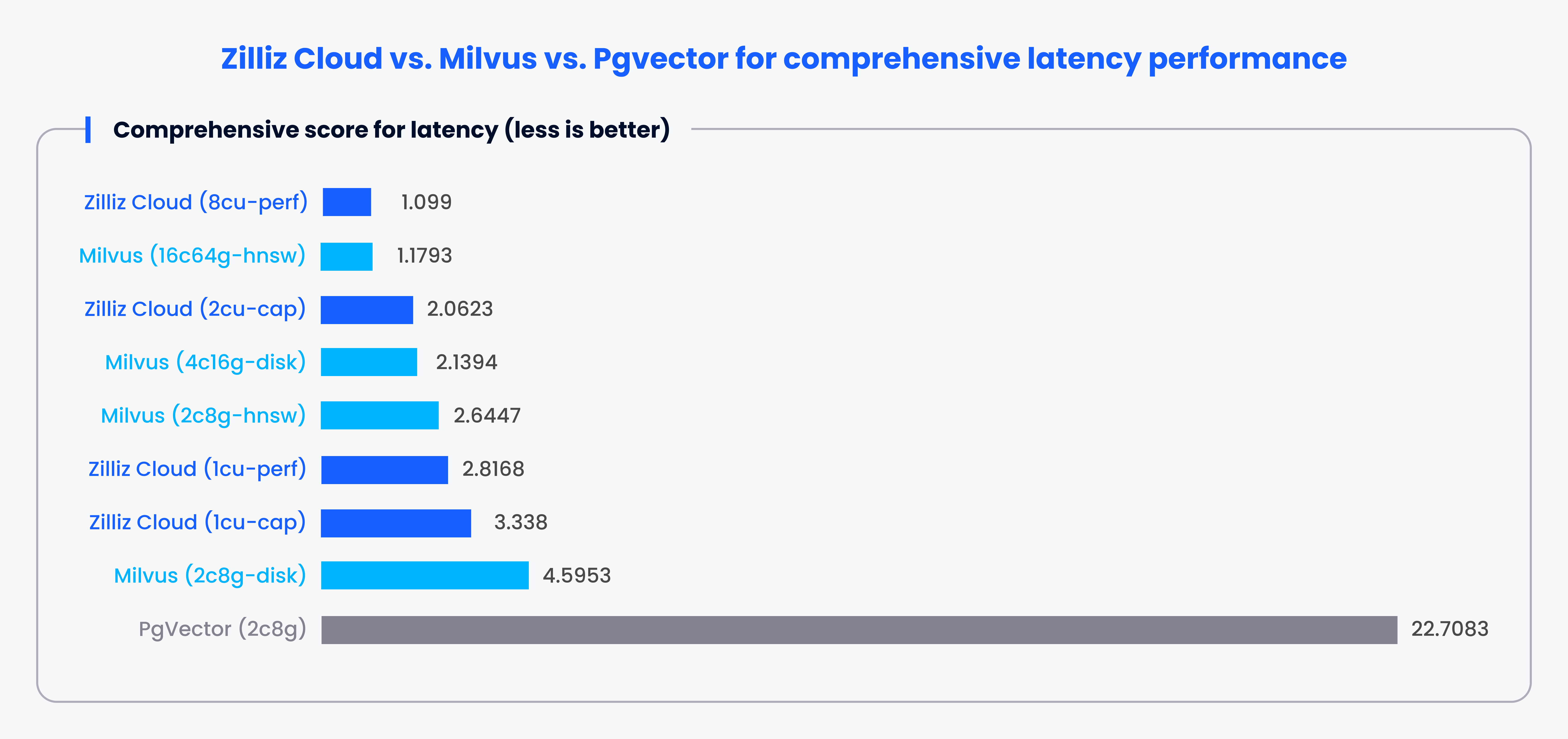
注: これは、特定のルール に従った さまざまなケース における各システムのパフォーマンスに基づく >1 スコアです。スコアが低いほどパフォーマンスが高いことを示す。
VectorDBBenchを使用すると、様々なメトリクスの観点から、どのデータベースがより良いパフォーマンスを発揮するかを素早く理解することができます。また、どのデータベースがあなたの特定のニーズに最も適しているかを判断することもできます。
PGvectorと他の目的別ベクトルデータベースの比較
Pgvectorはベクトル操作のためのPostgreSQL拡張としての利点を提供しますが、市場にある他の専用に構築されたベクトルデータベースとの比較を理解することは重要です。ベクトル検索ソリューションが拡大し続けるにつれて、開発者はPgvectorやMilvus以外の選択肢を持つようになりました。
Pgvector を選択する利点は以下の通りです。
PostgreSQLのネイティブ機能の強化:Pgvectorは、従来のリレーショナルデータと共にベクトルデータの効率的な格納、検索、問い合わせを可能にすることで、PostgreSQLの機能を拡張します。これにより、PostgreSQLは多様な種類のデータや複雑なクエリを扱うための汎用的なプラットフォームとなります。
ストレージと計算の分離:Pgvectorは、ストレージと計算処理の効果的な分離を可能にします。ベクターを他のアプリケーションデータとは別に保存することで、パフォーマンスとリソースの利用を最適化し、クエリ処理の合理化とスケーラビリティを実現します。
ポストグレス・ベクトルデータベースを選択する際の課題
プロセス内実行機能の制限:Pgvectorは、複雑なクエリ機能を必要とする非常に大規模なアプリケーションのために設計された専用のベクトルデータベースの性能レベルには及ばないかもしれません。Pgvectorは、専用のベクタデータベースと比較すると、インプロセス実行機能に制限があります。
他の技術との比較:Pgvector は、ベクターデータが補助的な役割を果たすような、適度な数のベクター(100K以下)の状況で優れています。しかし、スケーラビリティと複雑なクエリ機能で知られるいくつかの専用に構築されたベクトルデータベースと比較すると、大規模なアプリケーションや高度に専門化されたアプリケーションでは同じレベルのパフォーマンスを提供できないかもしれません。
誤解しないでいただきたいのですが、Pgvectorは既にPostgreSQLを使用していて、全く新しいデータベースシステムに切り替えることなくベクトル機能を追加する必要があるプロジェクトにとっては堅実な選択肢です。しかし、非常に大規模な、あるいは特殊なベクトル操作には、専用のベクトルデータベースがより良い性能とより高度な機能を提供するかもしれません。
ベクターデータベースとPgvectorの比較の詳細については、この比較ページを参照してください。
結論
PgvectorはPostgreSQL内でのベクトルデータの格納と問い合わせの新しい可能性を開きます。もしあなたが既にPostgreSQLに慣れ親しんでいて、ベクトルデータベースを探求したいのであれば、Pgvectorは素晴らしい出発点です。しかし、何百万、あるいは何十億ものベクトル類似性検索を行うAIアプリケーションにとっては、Pgvectorの性能では不十分かもしれません。MilvusとZillizは、パフォーマンスを最適化する特別な機能を提供している。プロジェクトの要件を検討し、これらのベクトル・データベースを探求して、アプリケーションにおけるベクトル・ストレージの可能性を最大限に引き出してください。
この投稿はSiddhant Varmaによって書かれました。Siddhantは、フロントエンドエンジニアリングの専門知識を持つフルスタックのJavaScript開発者である。彼はインドで複数のスタートアップのスケーリングに携わり、Ed-Techとヘルスケア業界での製品構築の経験がある。教えることに情熱を持ち、文章を書くのが得意。また、多くの卒業生にプログラミングを教え、彼らがより優れた未来の開発者になるよう支援している。
最終更新日最終更新日:2024年7月1日
 Siddhant Varma
Siddhant VarmaSiddhant is a full-stack JavaScript developer with expertise in front-end engineering. He’s worked with scaling multiple startups in India and has experience building products in the Ed-Tech and healthcare industries. Siddhant has a passion for teaching and a knack for writing. He's also taught programming to many graduates, helping them become better future developers.
読み続けて

Announcing the General Availability of Zilliz Cloud BYOC on Google Cloud Platform
Zilliz Cloud BYOC on GCP offers enterprise vector search with full data sovereignty and seamless integration.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.

Why DeepSeek V3 is Taking the AI World by Storm: A Developer’s Perspective
Explore how DeepSeek V3 achieves GPT-4 level performance at fraction of the cost. Learn about MLA, MoE, and MTP innovations driving this open-source breakthrough.