




Understanding Consistency Models for Vector Databases
Distributed systems for your vector search applications are becoming indispensable, ranging from scalability and fault tolerance to enhanced performance and global accessibility. The fundamental principles that make distributed systems the backbone of resilient, high-performing applications require us to consider consistency, availability, and latency tradeoffs.
For example, consistency is critical for certain vector search use cases in your distributed application. Wouldn’t it suck if you queried for data that you expected to be there but wasn’t there? That would happen if your data weren’t consistent across all the replicas you have in your distributed systems. On the surface, it sounds simple. Of course, my data should be there after I put it there and replicated it across multiple nodes. But when should it be there? How do you ensure that?
In response to the consistency problem, the fully distributed Milvus vector database offers Tunable Consistency. Milvus has a unique architecture that allows you to scale out the way you write your data and ensure consistency without having to use extra tools. Leveraging a distributed infrastructure, Milvus is a loosely coupled pub-sub system, which means consistency can be easily managed and tuned via timestamps.
In this article, we will look at:
What is Consistency?
- Vector Database Consistency Requirements
Consistency, Availability, and Partitions
What Levels of Consistency Does Milvus Offer?
Eventual Consistency
Session Consistency
Bounded Consistency
Strong Consistency
Summary of Understanding Consistency for Vector Databases
What is consistency?
One of the definitions of consistency is “the achievement of a level of performance that does not vary greatly in quality over time.” Regarding consistency for your distributed database, it gives you the most accurate, up-to-date data you ask for. That’s why Milvus offers the ability to “tune” your consistency based on how recent the data you want access to needs to be.
Different types of databases have additional consistency requirements. For example, non-relational databases often have “eventual” or relaxed ACID (atomicity, consistency, isolation, and durability) requirements. You may get partially updated data when working with NoSQL databases.
On the other hand, ACID-compliant SQL databases like Postgres have different consistency requirements. These databases ensure you won’t get partially updated data back by enforcing consistency at a change level. So, when you query, you must wait for your entire change to take place to get the data from that change back.
Vector database consistency requirements
Meanwhile, vector databases have different consistency requirements from relational or non-relational databases. You can have valid data even before a batch change is fully done. However, you can’t have partially updated data. Vector databases work under the PACELC theorem. That is exactly what Milvus does through its pub-sub setup. Each row gets “published” through the write pipeline and “subscribed” to by the necessary nodes. This setup lets you search or query Milvus and get results based on the differences in timestamps.
Consistency, availability, and partitions (CAP)
CAP theorem is a computer science concept that states there is a tradeoff between consistency, availability, and partition tolerance. You can only choose two of the three. When there is a network partition, you must choose between availability and consistency. A system that demands high data availability requires replicas, which makes consistency more difficult.
The PACELC theorem is an extension of the CAP theorem. It’s the CAP theorem + else + latency + consistency. It states that you don’t need to worry about availability and consistency tradeoffs in a system without network partitions. However, you still have to choose between latency and consistency, as you need to wait for data to sync.
What levels of consistency does Milvus offer?
![]()
Milvus offers four different consistency levels. In order of least to most consistent, they are: Eventual, Session, Bounded, and Strong. Eventual consistency means you’re willing to wait until “... whenever” it happens. Strong consistency means you want to include all data the moment you send the query. Session and Bounded are in between. Let’s take a deeper look.
Can you guess which emojis represent which levels?
Eventual Consistency
Eventual (or “Eventually”) consistency means that the data will eventually be consistent across all the replicas. We use eventual consistency when we care more about the speed of an application than having the most up-to-date data or repeatable queries. For Milvus, this type of consistency means we implement the consistency requirement by skipping the timestamp check when reading.
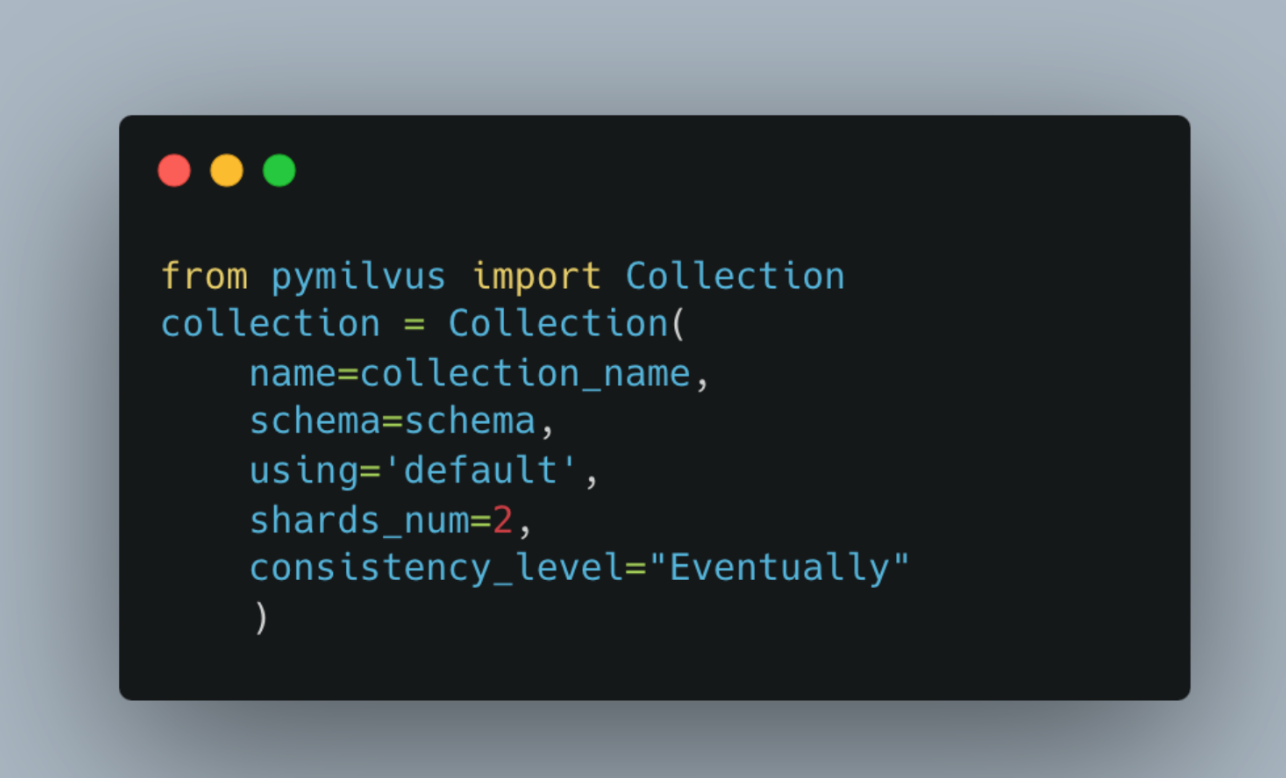
An example use case of this type of consistency level might be when pulling product reviews. Most users won’t read all the reviews on a product, so getting the most up-to-date reviews is not of high importance. If you want to create a collection with this level of consistency, the code below shows how to create a collection with “Eventually” level consistency in Milvus. It’s important to note that consistency_level is looking for the keyword “Eventually.”
Session Consistency
Session consistency means that each session is at least up to date based on its own writes. A session may have multiple replicas, so that’s the first latency-consistency trade-off. We use session consistency when we only need to save our state once per session. Milvus implements this type of consistency by setting the required timestamp to the time of the last write.
In practice, you can use session consistency when you need each client-server instance to have data consistency. An example of that is a video game server. You don’t want to let players do infinity glitches, so you must ensure consistency inside each instance or session. The code below shows how to do a vector search using a consistency level of “Session.”

Bounded Consistency
Bounded consistency (or bounded staleness) is one step “more consistent” than session consistency. With “Session” level consistency, the other instances, or sessions, are treated as eventually consistent. Bounded staleness forces each instance and replica to sync within a certain period.
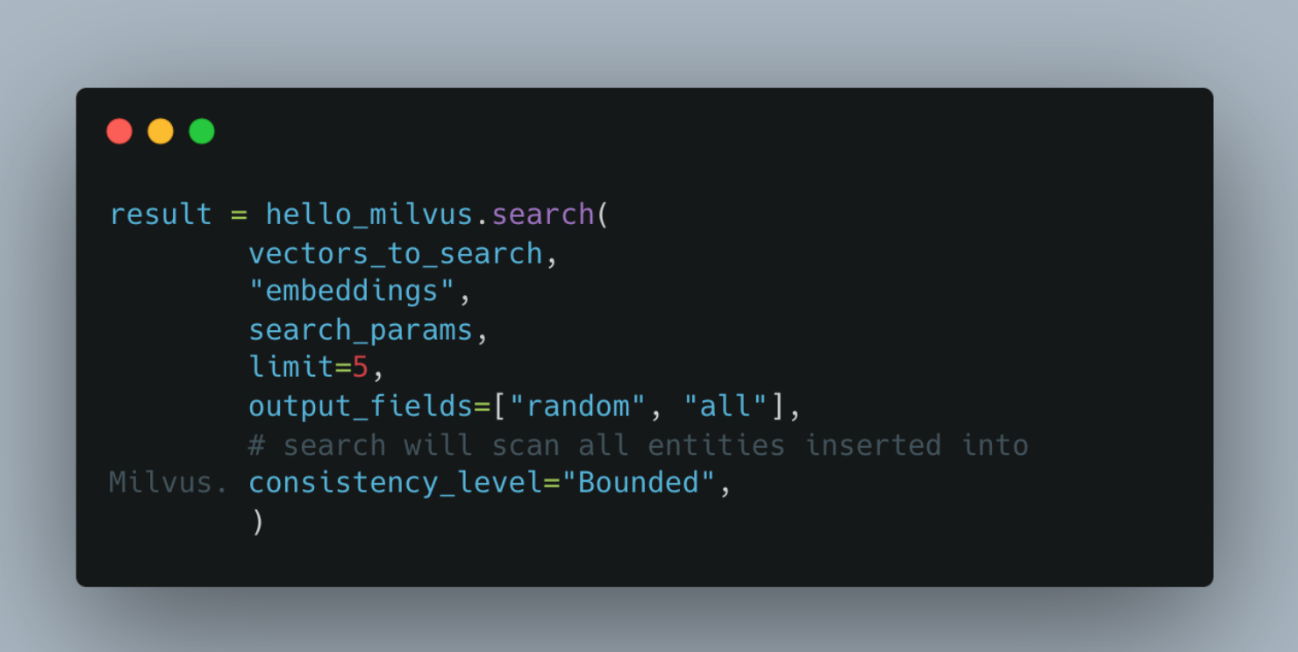
An example of bounded staleness could be a video recommendation engine. Users won’t need the latest videos immediately but should see them soon. A user’s changes should also promptly proliferate outside of their session. The code below shows how to search Milvus with a bounded consistency requirement.
Strong Consistency
Strong consistency makes data available the moment you insert it. Of course, this consistency comes with a latency tradeoff - we must wait for the system to change. In practice, Milvus implements this consistency by setting the required read timestamp to the latest update in the system. This raises our search latency to a minimum of 200ms.
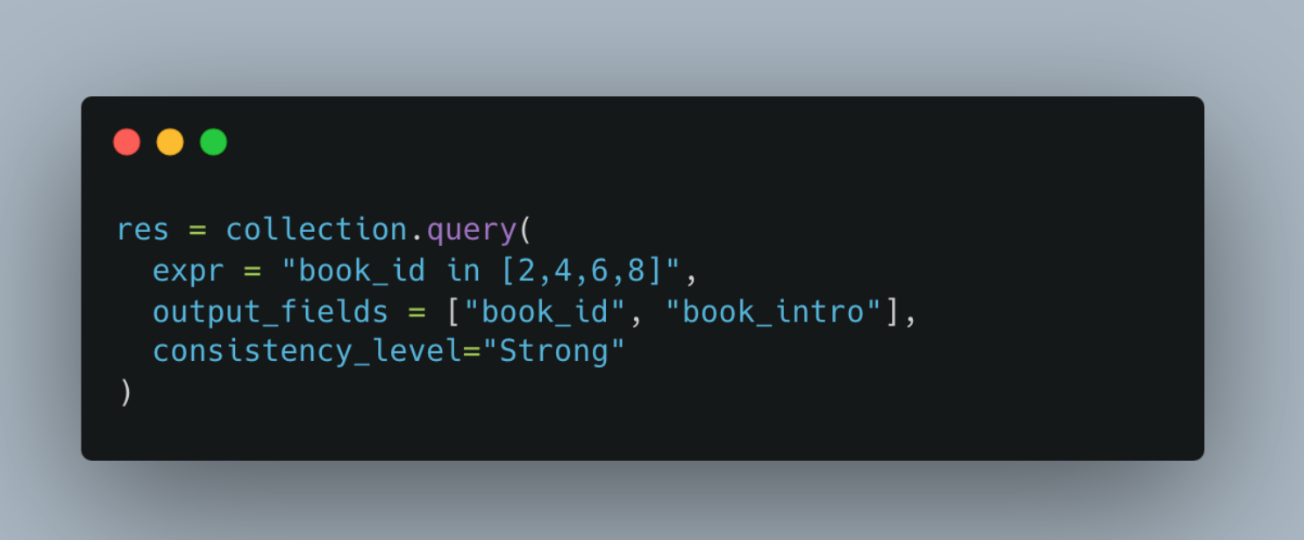
An example of strong consistency could be fraud detection. If someone uses your bank account for fraud, you must know and stop it immediately. Applications that need a read-after-write type set-up need strong consistency. The code below shows how to query a collection (filtered search without vectors) with a Strong consistency requirement.
Summary of Understanding Consistency for Vector Databases
Data consistency is one of the most important things to consider when building your distributed application. Every application needs data, and all data needs some consistency requirements. Regarding vector data, we must evaluate data consistency regarding row-based consistency requirements.
In alignment with these requirements, Milvus offers four levels of consistency based on timestamping the data. Note that this is possible only for row-based consistency and is not implemented in SQL or NoSQL databases. The four levels of consistency, from most to least consistent, are strong, bound, session, and eventually.
Strong consistency ensures that we have all the most up-to-date data available across the system (almost) immediately. This level of consistency is achieved by updating the timestamp to the latest insertion timestamp, ensuring that we can query all data inserted until the time of the request.
Bounded consistency ensures we have all the most up-to-date data across the system within a fixed period. Bounded consistency sets the timestamp to check for within a certain period from the request. This way, we have all the data within a bounded period. Bounded consistency is the default setting in Milvus.
Session consistency ensures that we have all the most up-to-date data in the current session we are working on. Milvus achieves this level of consistency by setting the timestamp for each instance to the last time that instance inserted data. This way, we have all the data inserted in (at least) the instance we use.
Finally, eventual consistency (keyworded “Eventually”) ensures that, eventually, the data across the system will all be consistent. Data can proliferate and is synced to replicas at whatever rate makes sense. Although we trade off some data consistency, we get better availability and performance in return. In practice, this level of consistency doesn’t take long. Milvus implements eventual consistency by skipping the timestamp check and executing searches or queries immediately.

Keep Reading

Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Notion solved vector search scaling in two years. The next bottleneck — offline context engineering, unified data, and the real-time/offline gap — is harder.

Why Context Engineering Is Becoming the Full Stack of AI Agents
Discover how context engineering unifies prompts, RAG, and tools to build smarter, production-ready AI agents powered by Milvus.

Cosmos World Foundation Model Platform for Physical AI
NVIDIA's Cosmos platform enables safe, digital twin training of GenAI models for physical applications, overcoming data scarcity and safety challenges.