




MLOps (Machine Learning Operations)
MLOps (Machine Learning Operations)
As machine learning (ML) models become more integrated into everyday business processes, organizations face several challenges in keeping their models accurate and relevant in real-world environments. One major issue is data drift—when the data that models rely on changes over time, causing them to lose accuracy. This leads to the need for continuous monitoring, retraining, and redeployment of models to ensure their predictions remain valid.
Managing these models can become error-prone, time-consuming, and expensive without the right systems. MLOps (Machine Learning Operations) solves this problem by automating and streamlining the entire process.
Let's understand how MLOps simplifies and automates the end-to-end machine learning lifecycle, from data preparation to model deployment and monitoring.
What is MLOps?
Machine Learning Operations (MLOps) combines machine learning, DevOps, and data engineering to streamline the machine learning lifecycle. MLOps aims to reliably deploy and maintain ML models at scale in production environments, from data collection and model development to model deployment, monitoring, and retraining.
Just as DevOps brought automation and integration practices to software development, MLOps does the same for machine learning. It applies Continuous Integration (CI) and Continuous Deployment (CD) principles, allowing teams to iterate on models more quickly while ensuring robust monitoring and performance in production environments.
How MLOps Works
MLOps process includes multiple stages that work together to streamline the entire machine learning lifecycle. These are:
Model Development
Model Serving
Model Monitoring
Model Maintenance
Data Management
Automation
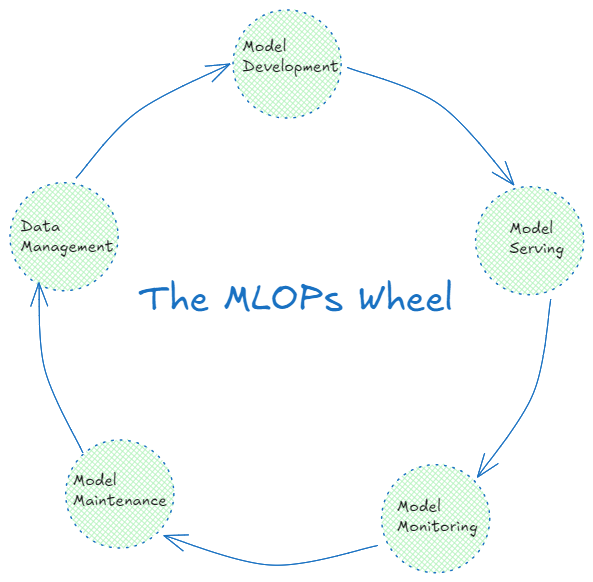 Figure- Multiple stages in MLOps workflow.png
Figure- Multiple stages in MLOps workflow.png
Figure: Multiple stages in MLOps workflow
Model Development
The first step in MLOps is the model development that is the foundation of any machine learning project, which includes several important sub-steps:
Data Preparation: Data must be cleaned and organized before training a model. This includes removing irrelevant information, filling in missing values, normalizing the data, and transforming it into a format suitable for an ML model.
Feature Engineering: Feature engineering creates new informative features or transforms existing ones to make them more useful for the model. For instance, data scientists might create new features like "wind speed squared" or "temperature gradients" in a weather prediction model to improve prediction accuracy.
Model Training: After preparing the data, ML models are trained. Data scientists train multiple models with algorithms and hyperparameters to find the best-performing one.
Model Testing: Once a model is trained, it's tested on a separate dataset to ensure it can make accurate predictions on new, unseen data. Various evaluation metrics are also used to assess the performance of the trained ML model.
Model Serving
Once a model is developed, it needs to be deployed to a production environment so it can make predictions in real-time:
Deployment: This includes making the model available to users or applications. The model is often deployed via an API to interact with other systems. Deployment solutions such as Kubernetes and Docker help manage this process by ensuring that models are scalable and easy to maintain.
Containerization: Models are isolated in containers (like Docker) to ensure consistency. Containers include all the necessary components—code, dependencies, and settings—so the model runs consistently across different environments.
Model Monitoring
After deployment, the model's performance needs to be continuously monitored to ensure it remains accurate and relevant:
Performance Tracking: Monitoring systems monitor the model's performance. For example, if a model starts making inaccurate predictions, this could indicate that the data it’s working with has changed over time (data drift).
Logging: All model activities are logged to maintain a record of inputs, outputs, and errors. This helps troubleshoot problems and identify patterns in how the model is used.
Model Maintenance
Machine learning models need to be maintained regularly to keep them performing well:
Updates and Retraining: MLOps facilitates updating and retraining models as new data becomes available or when performance declines. Regular retraining ensures that models stay up-to-date and accurate, adapting to changing data patterns. MLOps automates this process, making it efficient and less error-prone.
Versioning: To keep track of different versions of models, MLOps uses versioning systems such as GitHub, MLflow, and DVC. These systems record each version of a model, along with the data and code used to create it.
Data Management
Data is the backbone of any machine learning system, and managing it effectively is a key part of MLOps:
Data Ingestion and Storage: MLOps manages data flow from various sources into the ML pipeline and stores the data in scalable cloud storage like Zilliz Cloud and Milvus.
Data Governance: MLOps ensures data quality, security, and regulation compliance. It also ensures that only authorized individuals can access the data and that privacy laws are followed.
Automation
One of the main goals of MLOps is to automate repetitive tasks, making it easier to manage machine learning models over time:
Workflow Orchestration: Automation tools can handle many steps in the ML pipeline, from data processing to model training and deployment. This reduces the need for manual interference and helps maintain consistency when building and deploying models.
Continuous Integration/Continuous Deployment (CI/CD): CI/CD pipelines help teams continually build, test, and deploy models in a streamlined and automated approach. With CI/CD, models can be quickly updated, tested, and put into production with minimal delay.
Comparison: MLOps vs. DevOps vs. LLMOps
MLOps, DevOps, and LLMOps seem similar terms; each practice focuses on improving development workflows, but they address different challenges and offer unique solutions within the software development and AI field.
| Aspect | DevOps | MLOps | LLMOps |
| Definition | A set of practices to automate software development and IT operations. | Extends DevOps principles to automate the lifecycle of ML models. | Focuses on managing the lifecycle of large language models (LLMs). |
| Focus | Automating software delivery pipelines (CI/CD), improving collaboration, and shortening the development lifecycle. | Automating ML workflows from data preparation to model deployment and monitoring. | Optimizing the deployment, fine-tuning, and management of LLMs in production. |
| Main Tools | - GitLab for CI/CD.- Grafana for monitoring.- Docker and Kubernetes for container orchestration. | - Kubeflow and Apache Airflow are used for workflow automation.- Scikit-learn and TensorFlow for model training. | - Hugging Face Transformers for fine-tuning.- Large-scale inference tools (Ray Serve, ONNX). |
| Use Cases | - Rapid deployment of software updates.- Managing distributed systems. | - Continuous monitoring of model performance in production.- Automating retraining and redeployment of ML models. | - Deploying large language models for NLP tasks.- Fine-tuning models for specialized domains. |
MLOps Metrics
In MLOps, metrics are key to measuring model performance and the entire ML pipeline. KPIs in MLOps go beyond traditional ML model metrics to the entire lifecycle. Model accuracy, precision, recall, and F1 score are still fundamental, but MLOps introduces new ones. Deployment frequency measures how often new models or updates are deployed to production and how agile the ML pipeline is. Mean Time to Recovery (MTTR) measures how fast issues in production models are identified and resolved. Resource utilization metrics measure computational efficiency, important for cost management in the cloud. Data and model drift metrics measure how well models perform over time as input data changes. Inference latency and throughput are critical for real-time applications, measuring response time and processing capacity. A/B testing metrics compare the performance of new models to that of existing ones in production. The pipeline automation level measures the level of human intervention required; a higher level is better for more mature MLOps. Lastly, model versioning and reproducibility metrics ensure experiments and deployments can be tracked and replicated. These metrics give you a complete view of MLOps so you can continuously improve your ML processes and outcomes.
Benefits and Challenges of MLOps
While MLOps offers numerous advantages that enhance the efficiency and effectiveness of machine learning operations, it also presents several challenges that organizations must navigate. Understanding the benefits and challenges is crucial for successfully implementing MLOps practices and achieving optimal outcomes.
MLOps Benefits
Automated Pipelines: Reduces manual interventions, allowing data scientists and engineers to focus on core tasks.
Faster Time-to-Market: Streamlined workflows and automation enable quicker model iterations and release cycles.
Improved Performance: The continuous monitoring and retraining cycles build robust models that perform well in dynamic, real-world scenarios.
Scalability: MLOps frameworks allow for the deployment and management of thousands of models across different environments.
Continuous Improvement: Models are continuously monitored and retrained. This practice ensures they adapt to new data and changing conditions and maintain high performance.
MLOps Challenges
Complexity: Implementing MLOps requires setting up complex infrastructure and workflows, which are resource-intensive.
Tool Integration: Integrating different tools for data management, model training, deployment, and monitoring is challenging.
Model versioning and reproducibility: It can be hard to keep track of and manage all the different versions of machine learning models and the dependencies and settings that go with them. Another problem that can come up is reproducing and validating results in various environments.
Cost: While MLOps can improve efficiency and scalability in the long run, the initial cost of setting up an MLOps framework can be high. Organizations need to invest in the right tools, infrastructure, and talent to ensure the success of their MLOps initiatives.
Collaboration: MLOps introduces common processes and tools, fostering effective collaboration between data engineers, scientists, developers, and IT engineers, which remains a significant challenge.
Tools and Technologies in MLOps
MLOps depends on various tools and technologies to manage the machine learning lifecycle. Below are some of the most commonly used MLOps tools:
MLflow: An open-source platform for managing the complete machine learning lifecycle, including experiment tracking, model versioning, and deployment.
DVC (Data Version Control): An open-source version control system for data management, ML pipeline automation, and experiment management.
Kubeflow: A Kubernetes-based platform for deploying, scaling, and managing machine learning models in production environments.
Apache Airflow: A workflow automation tool that helps manage data pipelines and schedule tasks for data ingestion and model training.
TensorFlow Extended (TFX): An end-to-end platform for deploying production machine learning pipelines using TensorFlow. TFX provides tools for data validation, model serving, and continuous training.
Vector Databases (Milvus, Zilliz Cloud): In many MLOps scenarios, dealing with unstructured data like images, text, or audio is crucial. This is where vector databases can be helpful. They specialize in storing and querying vector embeddings and numerical representations of such data. Milvus is an open-source vector database that excels at handling large-scale datasets and complex queries.
MLOps Trends
The MLOps landscape is changing fast, and some exciting trends are emerging. AutoML (Automated Machine Learning) is taking off, automating feature engineering and hyperparameter tuning. Edge ML is becoming more important; models can run on edge devices, reducing latency and increasing privacy. Federated learning is emerging to train models across decentralized devices while keeping data private. XAI (Explainable AI) tools are being added to MLOps pipelines to address the growing need for model interpretability and transparency. There’s a growing focus on ML-specific monitoring tools that can detect subtle model degradation and data drift in real-time. LLMs (Large Language Models) are being added to MLOps workflows to do more advanced NLP tasks. As sustainability becomes a bigger concern, green MLOps are emerging to optimize resource usage and reduce the carbon footprint of ML. These trends point to a future where MLOps will be more automated, efficient, interpretable, and green.
FAQs about MLOps
- What are MLOps used for?
Machine Learning Operations (MLOps) are a collection of practices designed to streamline and automate the workflows and deployment processes of machine learning (ML) models. By incorporating machine learning and artificial intelligence (AI), businesses can tackle complex real-world challenges and create valuable customer solutions.
- What is MLOps vs DevOps?
MLOps is a data science practice focused on fast testing and deploying machine learning models. DevOps, however, integrates development and IT operations to enhance software development efficiency, reliability, and security.
- What is the difference between MLOps and AIOPs?
AIOps allows IT operations and data science teams to implement predictive alert management, enhance data security, and support DevOps workflows. MLOps solutions help businesses speed up the deployment of machine learning models, improve collaboration between data science and operations teams, and scale AI efforts across the organization.
- Is MLOps in demand?
As businesses adopt data-driven solutions, the demand for MLOps professionals to efficiently deploy and manage machine learning models is rapidly growing.
- What language is best for MLOps?
Python is currently the top choice for machine learning and MLOps. Its popularity stems from the extensive range of tools and libraries available for machine learning, such as NumPy, TensorFlow, Keras, and PyTorch. These libraries make it easier to build machine learning models and handle data engineering tasks, simplifying the entire machine learning projects MLOps process.
Related Resources
- What is MLOps?
- How MLOps Works
- Comparison: MLOps vs. DevOps vs. LLMOps
- MLOps Metrics
- Benefits and Challenges of MLOps
- Tools and Technologies in MLOps
- MLOps Trends
- FAQs about MLOps
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free