




Operationalize AI at Scale with Software 2.0, MLOps, and Milvus
Building machine learning (ML) applications is a complex and iterative process. As more companies realize the untapped potential of unstructured data, the demand for AI-powered data processing and analytics will continue to rise. Without effective machine learning operations, or MLOps, most ML application investments will wither on the vine. Research has found that as little as 5% of the AI adoptions companies plan to deploy actually reach deployment. Many organizations incur "model debt," where changes in market conditions, and failure to adapt to them, result in unrealized investments in models that linger unrefreshed (or worse, never get deployed at all).
This article explains MLOps, a systemic approach to AI model life cycle management, and how the open-source vector data management platform Milvus can be used to operationalize AI at scale.
What is MLOps?
Machine learning operations (MLOps), also known as model operations (ModelOps) or AI model operationalization, is necessary to build, maintain, and deploy AI applications at scale. As companies seek to apply the AI models they develop to hundreds of different scenarios, it is mission critical that models in use, and those under development, are operationalized across the entire organization. MLOps involves monitoring a machine learning model throughout its lifecycle, and governing everything from underlying data to the effectiveness of a production system that relies on a particular model.
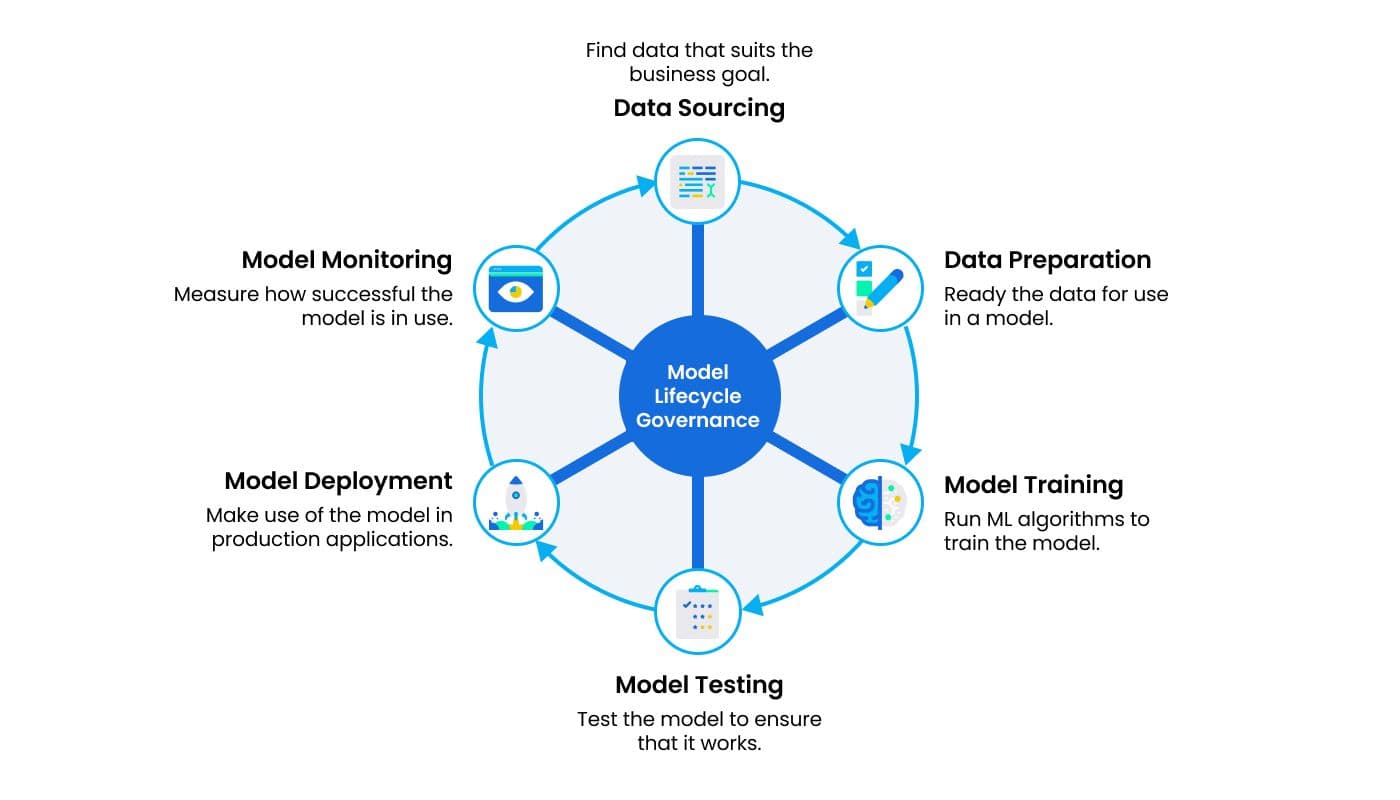 MLOps governs the life cycle of a machine learning model.
MLOps governs the life cycle of a machine learning model.
Gartner defines ModelOps as the governance and life cycle management of a wide range of operationalized artificial intelligence and decision models. The core functionality of MLOps can be broken down as follows:
Continuous integration/continuous delivery (CI/CD): A set of best practices borrowed from developer operations (DevOps), CI/CD is a method for delivering code changes more frequently and more reliably. Continuous integration promotes implementing code changes in small batches while monitoring them with strict version control. Continuous delivery automates the delivery of applications to various environments (e.g., testing and development environments).
Model development environments (MDE): A complex process for building, reviewing, documenting, and examining models, MDE help ensure models are created iteratively, documented as they are developed, trusted, and reproducible. Effective MDE ensures models can be explored, researched, and experimented on in a controlled manner.
Champion-challenger testing: Similar to A/B testing methodology used by marketers, champion-challenger testing involves experimenting with different solutions to aid the decision-making process that proceeds committing to a single approach. This technique involves monitoring and measuring performance in real time to identify which deviation works best.
Model versioning: As with any complex system, machine learning models are developed in steps by many different people—resulting in data management questions around versions of data and ML models. Model versioning helps manage and govern the iterative process of ML development where data, models, and code may evolve at different rates.
Model store and rollback: When a model is deployed, its corresponding image file must be stored. Rollback and recovery abilities allow MLOps teams to revert to a previous model version if needed.
Using just one model in a production application presents a number of difficult challenges. MLOps is a structured, repeatable method that relies on tools, technology, and best practices to overcome technical or business problems that arise during a machine learning model’s life cycle. Successful MLOps maintains efficiency across teams working to build, deploy, monitor, retrain, and govern AI models and their use in production systems.
Why is MLOps necessary?
As depicted in the ML model life cycle above, building a machine learning model is an iterative process that involves incorporating new data, retraining models, and dealing with general model decay over time. These are all issues that traditional developer operations, or DevOps, does not address or provide solutions for. MLOps has become necessary as a way to manage investment in AI models and ensure a productive model life cycle. Because machine learning models will be leveraged by a variety of different production systems, MLOps becomes integral to making sure requirements can be met across different environments and amid varying scenarios.
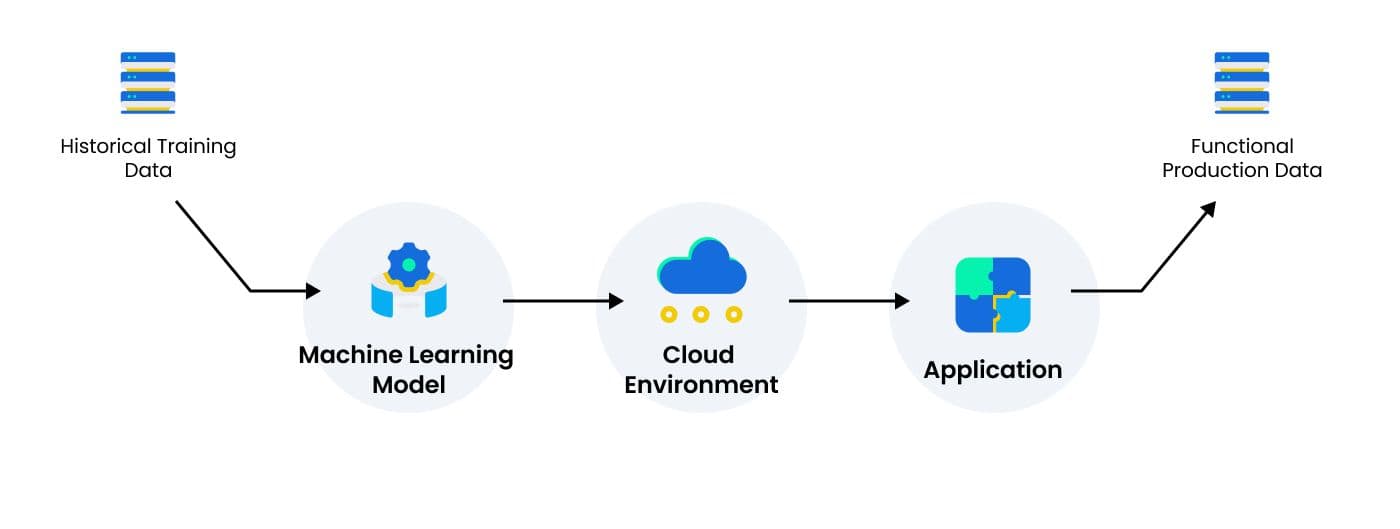 A machine learning model being deployed in a cloud environment that feeds into an application.
A machine learning model being deployed in a cloud environment that feeds into an application.
The simple illustration above depicts a machine learning model being deployed in a cloud environment that feeds into an application. In this basic scenario, a number of problems could arise that MLOps helps overcome. Because the production application relies on a specific cloud environment, there are latency requirements that the data scientists who developed the ML model don’t have access to. Operationalizing the model life cycle would make it possible for data scientists or engineers with deep knowledge of the model to identify and troubleshoot problems that arise in specific production environments.
Not only are machine learning models trained in different environments from the production applications they are used in, but they also often rely on historical datasets that differ from the data used in production applications. With MLOps the entire data science team, from those developing the model to people working at the application level, have a means of sharing and requesting information and assistance. The rate at which data and markets change make it imperative that there is as little friction as possible between all key stakeholders and contributors that will come to depend on a given machine learning model.
Supporting the transition to Software 2.0
Software 2.0 is the idea that software development will experience a paradigm shift as artificial intelligence increasingly plays a central role in writing AI models that power software applications. Under Software 1.0, development involves programmers writing explicit instructions using a specific programming language (e.g., Python, C++). Software 2.0 is far more abstract. Although people provide input data and set parameters, neural networks are difficult for humans to understand due to their sheer complexity— with typical networks containing millions of weights that impact outcomes (and sometimes billions or trillions).
DevOps was built around Software 1.0’s reliance on specific instructions dictated by programmers using languages, but never considered the life cycle of a machine learning model that powers a variety of different applications. MLOps addresses the need for the process of managing software development to change alongside the software under development. As Software 2.0 becomes the new standard for computer-based problem solving, having the right tools and processes for managing model life cycles will make or break investments in new technology. Milvus is an open-source vector similarity search engine built to support the transition to Software 2.0 and manage model life cycles with MLOps.
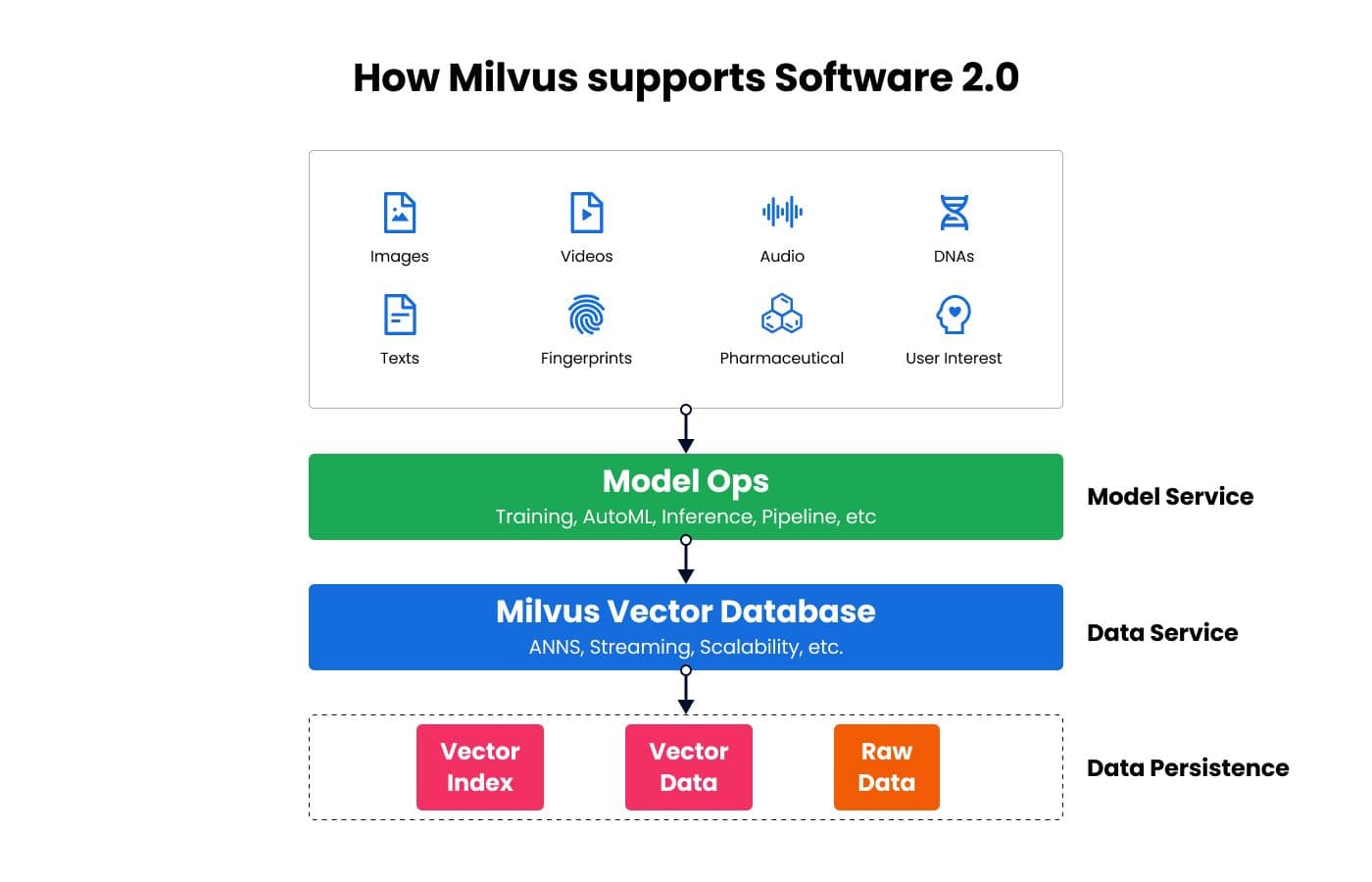 How Milvus supports the transition to Software 2.0.
How Milvus supports the transition to Software 2.0.
Operationalizing AI at scale with Milvus
Milvus is a vector database / vector data management platform that was made specifically for storing, querying, updating, and maintaining massive, trillion-scale vector datasets. The platform powers vector similarity search and can integrate with widely adopted index libraries, including Faiss, NMSLIB, and Annoy. By pairing AI models that convert unstructured data to vectors with Milvus, applications spanning new drug development, biometric analysis, recommendation systems and much more can be created.
Vector similarity search is the go-to solution for unstructured data data processing and analytics, and vector data is quickly emerging as a core data type. A comprehensive data management system like Milvus facilitates operationalizing AI in many ways, including:
Providing an environment for model training that ensures more aspects of development are done in one place, facilitating cross team collaboration, model governance, and more.
Offering a comprehensive set of APIs that support popular frameworks such as Python, Java, and Go, making it easy to integrate a common set of ML models.
Compatibility with Google Colaboratory, a Jupyter notebook environment that runs in a browser, simplifies the process of compiling Milvus from source code and running basic Python operations.
Automated machine learning (AutoML) functionality makes it possible to automate the tasks associated with applying machine learning to real world problems. Not only does AutoML lead to efficiency improvements, but it makes it possible for non-experts to take advantage of machine learning models and techniques.
Regardless of the machine learning applications you’re building today, or the plans you have for applications in the future, Milvus is a flexible data management platform created with Software 2.0 and MLOps in mind. To learn more about Milvus or make contributions, find the project on Github. To get involved with the community or ask questions, join our Slack channel. Hungry for more content? Check out the following resources:
Keep Reading

VDBBench Adds Cost-Aware Benchmarking for Vector Databases
Compare Zilliz Cloud, Pinecone, and turbopuffer with VDBBench cost-aware vector database benchmarks across latency, freshness, multitenancy, and cold starts.

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

Announcing the General Availability of Zilliz Cloud BYOC on Google Cloud Platform
Zilliz Cloud BYOC on GCP offers enterprise vector search with full data sovereignty and seamless integration.