




Understanding Data Modeling

Understanding Data Modeling
In an era where data is a company's most valuable asset, efficiently collecting, storing, and managing extensive data is critical to ensuring a competitive edge. But how do organizations create meaning from disparate data sources? How do they know what data to collect and how to store it?
The answer lies in efficient data modeling - a technique that allows developers to visualize their data management system. It helps them understand what data they need to collect and how to identify critical relationships between multiple sources. The process allows decision-makers to identify relevant datasets for effective decision-making.
This post will explain data modeling, how it works, its techniques, processes, benefits, challenges, and the tools that can help you streamline modeling workflows.
What is Data Modeling?
Data modeling creates a blueprint representing an application’s or a system’s data structure. The data model is a diagram illustrating the relevant data entities, objects, relationships, and complex schemas for storage.
The data model also establishes data definitions, glossaries, and other crucial metadata to help multiple stakeholders extract meaningful insights for specific use cases. Stakeholders can include data analysts, developers, and administrators who analyze, organize, and manage access to data sources.
Efficient data modeling ensures the effective use of data assets across teams by fostering a shared understanding of data, eliminating data redundancies, and minimizing administrative hurdles. It also allows organizations to identify and resolve potential roadblocks and design constraints to build a scalable data management system.
How Does Data Modeling Work?
While the techniques for creating a data model may vary from case to case, they generally include developing a conceptual design, a logical framework, and a physical model.
Conceptual Design
The conceptual design is an abstraction that visualizes the overall data structure. It identifies the project’s scope and establishes the high-level requirements for creating the system.
The conceptual model also maps out the relevant data entities, relationships, integrations, and security protocols for business analytics tasks. For instance, the diagram below shows a straightforward conceptual model of a sales database system.
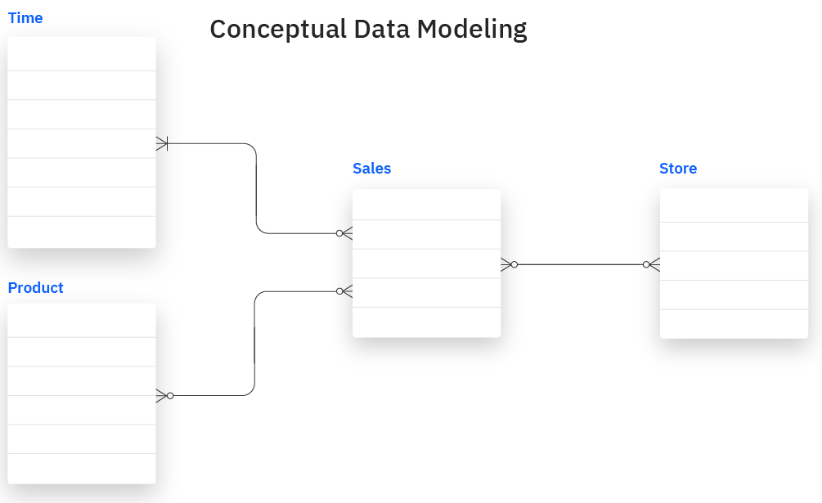 Conceptual Model.png
Conceptual Model.png
The objective is to address the data needs of business executives and help them discover crucial data elements and relationships to make effective data-driven decisions.
Logical Framework
The logical framework offers more detail by including data types, unique identifiers, and definitions. It uses formal data notations to mark entity relationships and allows users to visualize data attributes and relationships more clearly.
For instance, the logical framework for a sales database may contain the primary keys that connect the product and sales tables.
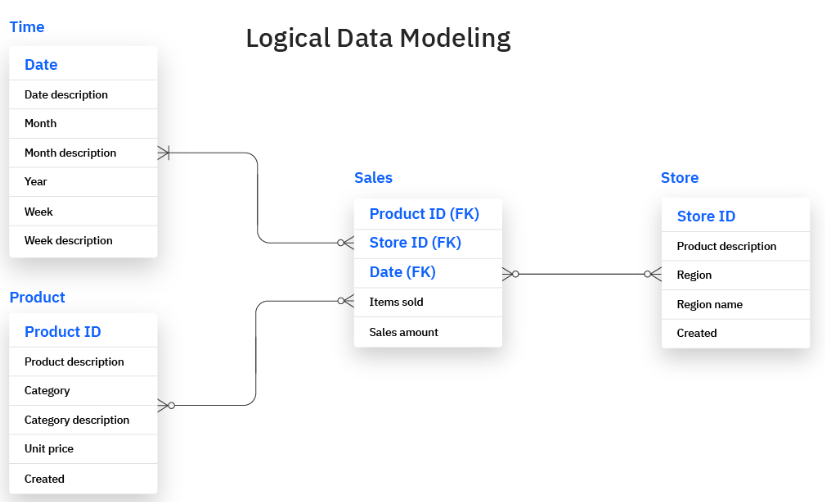 Logical Framework.png
Logical Framework.png
The logical model also helps users determine the nature of information required within each data entity and the rules for implementing the data structures.
Physical Data Model
The physical data model is a data-driven system's last and most detailed representation. It includes a detailed schema describing how the system will store the data assets.
For instance, the physical data model in a relational database system will consist of the names of each table, column, and corresponding data type.
 Physical Data Model.png
Physical Data Model.png
Physical models are system-specific and will change according to the type of model you are trying to build. The following section explains the different data model types in more detail.
Types of Data Models
With time, more complex database management systems (DBMS) have emerged with the increasing data volumes. The variety in DBMS architectures has resulted in multiple data model types to help organizations design management systems more efficiently.
While model types are still evolving, a few popular types include hierarchical, relational, entity-relationship, object-oriented, and dimensional data models.
Hierarchical data models
The hierarchical data model organizes data in a one-to-many tree-like structure with a single parent connected to multiple child records.
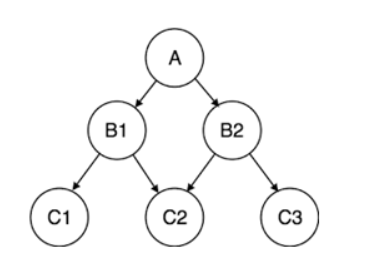 Hierarchical Model.png
Hierarchical Model.png
The IBM Information Management System (IMS) was the first to use the hierarchical structure introduced in 1966. Although the model is rare today, it is still used for organizing data in Extensible Markup Language (XML) files and Geographic Information Systems (GIS).
Relational data models
Relational data models, introduced by IBM researcher Edgar F. Codd in 1970, are more versatile than hierarchical structures. They organize data into tables with rows and columns, making it more manageable to discover multiple data elements and relationships.
| ID | Name | Address |
| 125 | Name 1 | Address 1 |
| 236 | Name 2 | Address 2 |
Table: Relational Model
Relational models allow users to join multiple tables based on primary keys and reduce data complexity. Structured Query Language (SQL) is mainly used to manipulate and analyze data in relational databases.
Entity-Relationship data models
Entity-relationship (ER) models organize data attributes according to entities and map relationships between multiple entities.
For instance, in a sales DBMS, a customer is an entity whose attributes may include the customer’s name, address, contact details, and other characteristics. The customer entity can relate to the product entity through the items that a particular customer purchased.
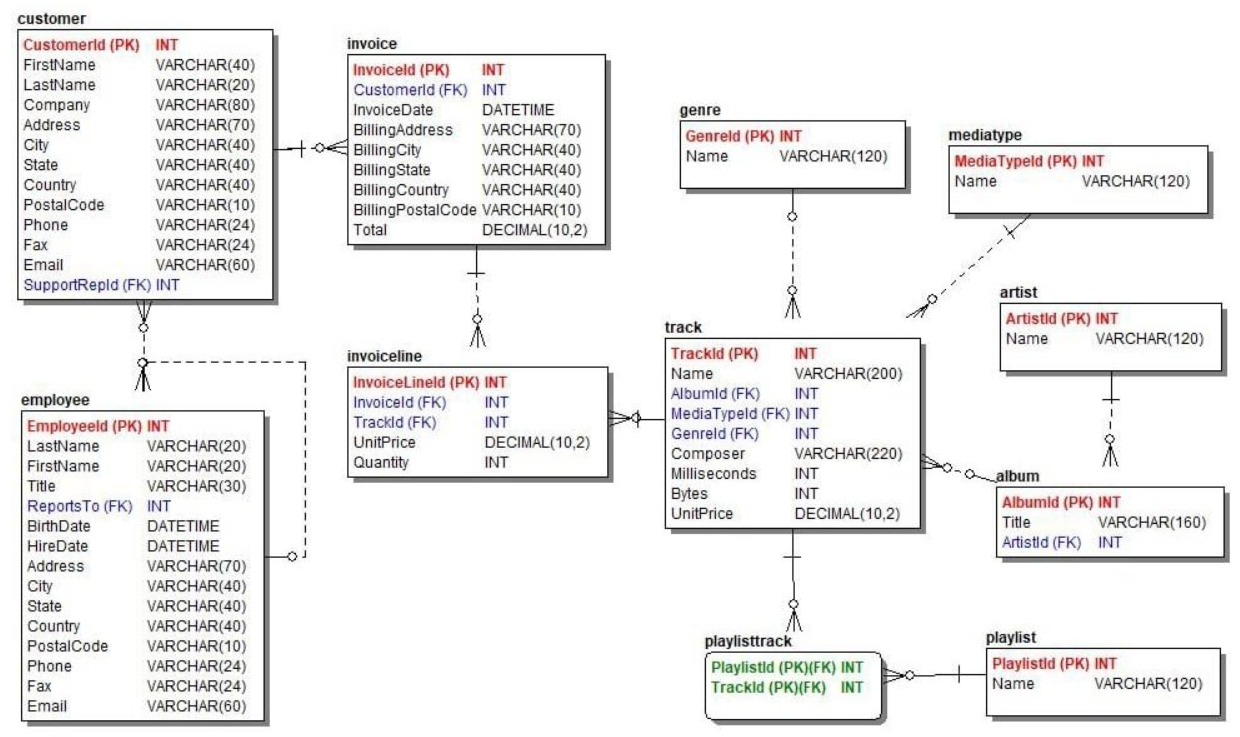 ER Model.png
ER Model.png
The structure is more dynamic than relational models as it helps capture and analyze transaction-based data more efficiently.
Object-oriented data models
Object-oriented data models have become popular with object-oriented programming, which organizes data objects according to their attributes.
Data objects with similar attributes are grouped into classes. Programmers can create new classes that can inherit the attributes of previous classes.
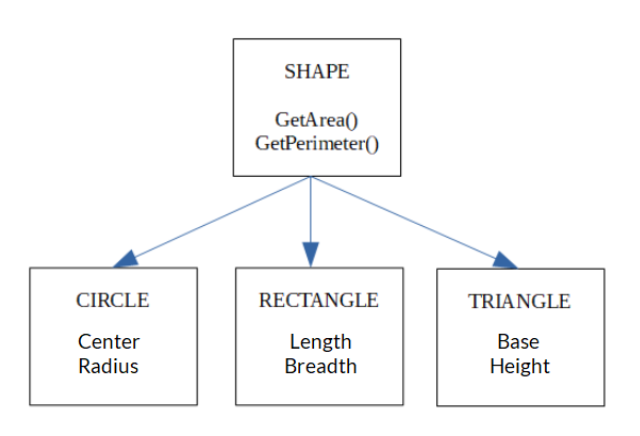 Object-oriented Data Model- .png
Object-oriented Data Model- .png
Object-oriented Data Model: The objects CIRCLE, RECTANGLE, and TRIANGLE inherit from the SHAPE __object. Each shape has its attributes.
For instance, in an object-oriented data model, customer and employee data may belong to the same class as they have identical attributes, such as name, address, and contact information. This differs from ER models, where customers and employees are separate entities.
Dimensional data models
Dimensional data models organize data entities as dimensions connected to factsheets, improving analytics in data warehouses and marts. A factsheet contains data on events, while dimensions contain information regarding the entities appearing within these events.
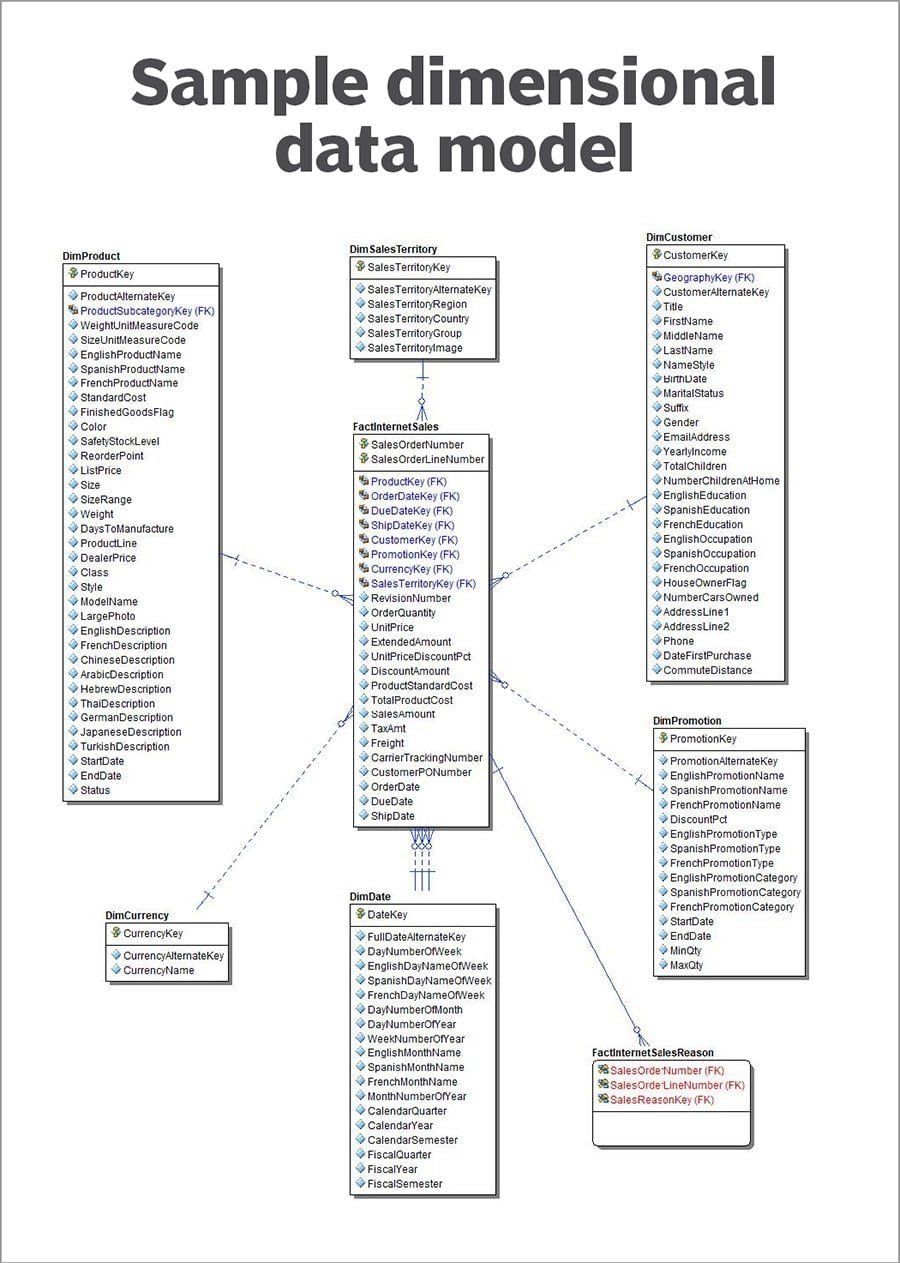 Dimensional Data Model- .jpg
Dimensional Data Model- .jpg
Dimensional Data Model: The sales factsheet relates to multiple dimensions of entities appearing in it.
For instance, a factsheet can be a table recording everyday transactions by multiple customers. However, users can find more information regarding each customer or product in dimension tables storing customer-related or product data.
The star schema is a famous dimensional data structure in which a single factsheet is connected to multiple dimensions. A more complex variant is the snowflake structure, in which numerous dimension tables are related to various factsheets.
Comparison with Database Design and Data Engineering
While database design and data engineering are similar concepts, they differ from data modeling in a few ways.
Data modeling versus Database Design: Data modeling is the initial phase in building a database. Database design is a less abstract process that determines the requirements for implementing the data model. Developers consider the most optimal database structure to improve scalability and data integrity. For instance, it can include the choice of primary keys, indexation techniques, and schema design.
Data Modeling versus Data Engineering: Data engineering is a broader concept that includes the development of automated data pipelines to process, transform, and move data between multiple platforms. An efficient data model can help build a robust database design, assisting developers to streamline data engineering workflows.
Data Modeling Process
Designing a data model requires input from multiple stakeholders to understand the database system’s scope, goals, and resource constraints.
Data experts must select the appropriate data model type to represent the data structure needed for a particular use case. They must also determine the relevant symbols and notational conventions to construct the model.
While the data modeling workflows can differ according to business needs and the nature of data, the following list offers a few steps for designing a model.
Entity Identification: The first step is identifying the relevant entities the data must include. The entities must be mutually exclusive and should form the basis of the model’s conceptual design.
Attribute Identification: Developers must identify the attributes unique to each entity. For instance, in a database with customers' banking details, “bank accounts” can be a separate entity with unique attributes such as the nature of the account, account number, creation date, initial amount deposited, etc.
Relationship between Entities: Map the relationships between multiple entities. For instance, the “bank account” entity can relate to the “customer” entity, with each customer having one more account.
Assigning Primary Keys: Developers must assign unique keys to entities to formally represent their relationships. For instance, the account number can be a primary key that relates the “customers” entity with the “bank accounts” entity.
Creating and Finalizing the Data Model: After identifying all the relevant entities, attributes, and relationships with primary keys, developers can determine the appropriate data model and finalize the design that best fulfills the business’ data needs.
Benefits of Data Modeling
A data model is the backbone of an effective data management system. It allows multiple stakeholders to use data assets to discover valuable insights for strategic decision-making.
The list below highlights a few benefits of an effective data model.
Better Communication: A data model helps communicate the data flow and concepts more easily to relevant stakeholders.
Consistent Documentation: Since the data model provides a standardized visualization of the overall data structure, documentation is more consistent, allowing for a more robust system design.
Enhanced Cross-team Collaboration: With a shared data understanding, teams from multiple domains can collaborate more effectively on projects.
Better Data Quality: A well-designed model ensures data integrity across data sources and allows users to develop fast and efficient data analysis workflows.
Data Modeling Challenges
While data modeling offers multiple advantages, it involves a few implementation challenges. Understanding these hurdles and ways to overcome them can help organizations realize data modeling benefits more quickly.
Below are a few challenges that developers may face when designing a data model.
Increasing Data Complexity: Modern DBMS must be dynamic and address changing business needs and increasing data variety. However, predicting future changes is complex and involves considerable speculation. Breaking down models into smaller components and using industry standards can help mitigate such issues.
Executive Team Buy-in: Convincing the executive team regarding the benefits of a data model can be tedious. The conversation can become too abstract for business users. To ensure support, data teams must approach top management with clear goals and objectives that align with the company’s overall mission and vision.
Changing Requirements: Designing a data model is an iterative process that may require changes in scope and goals. However, frequent changes may cause the design to go off track and increase development costs. Identifying and involving relevant stakeholders from the get-go and obtaining regular feedback can help overcome these problems.
Data Modeling Tools
Developers can use data modeling tools to create more efficient designs quickly. While multiple providers offer data modeling solutions, selecting the one that best suits your business needs takes time and effort. The list below highlights a few popular tools that can help you simplify your search.
Erwin Data Modeler: Helps create detailed schemas and design visualizations supporting multiple database systems. It features a version control system and allows users to reverse data models from existing data structures.
DbSchema: Features an intuitive user interface that allows users to interact with data models and build queries visually without using code.
ER/Studio: Supports multiple database systems, including relational and dimensional structures. Features collaboration tools that allow teams to understand data more effectively through activity and discussion streams.
FAQs about Data Modeling
- What is the difference between data modeling and database design?
Data modeling refers to identifying data entities, attributes, and relationships among different entities. It helps create the overall structure of how a database will store these entities and how users can leverage the relationships to perform analysis.
Database design comes after finalizing the data model and involves implementing the data model in a database management system (DBMS). It includes indexing techniques, schema names, and storage structures.
- What is normalization in data modeling?
Normalization organizes data into groups to eliminate redundancies and improve data consistency. For instance, consider the following table in a relational DBMS:
| Customer | Item Purchased | Price |
| A | Phone | $200 |
| B | Computer | $1500 |
| C | Charger | $50 |
| D | Phone | $200 |
Here, the user will remove an item’s price if they want to delete the record of a particular customer. Normalization will separate customer data from pricing information by creating two tables.
The process will ensure data remains consistent and the user can manipulate data more flexibly without changing the overall structure of the information.
- How do we design data models for unstructured data?
Unstructured data includes image, video, and text data. Models for unstructured datasets require different techniques as representing them is more complex than traditional schemas.
Developers can use vector databases to store and develop data models for unstructured datasets. The databases use artificial intelligence (AI) algorithms to convert data samples into embeddings, vectorized representations of each data point. Each element in the vector corresponds to a particular attribute of the data sample.
Once the samples are in vector form, users can compute similarity metrics to assess the similarity between different data points. They can use the similarity scores to organize data into groups and develop models representing relationships between them.
- What are some common mistakes to avoid in data modeling?
Developers often overcomplicate the model and fail to involve relevant stakeholders in the design phase. Also, including unnecessary data entities and failing to consider performance constraints are frequent slips that reduce the data model’s efficiency.
- How do you choose the right data modeling tool?
You must consider the following factors when investing in a data modeling solution:
Ease-of-use
Supported database systems
Visualization features
Collaboration tools
Scalability
Price
Related Resources
You can read more about unstructured data management and modeling techniques in the following articles.
- What is Data Modeling?
- How Does Data Modeling Work?
- Types of Data Models
- Dimensional data models
- Comparison with Database Design and Data Engineering
- Data Modeling Process
- Benefits of Data Modeling
- Data Modeling Challenges
- Data Modeling Tools
- FAQs about Data Modeling
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free