




ArXiv Scientific Papers Vector Similarity Search with Milvus 2.1
Introduction
One of the best ways to learn any latest Data Science topic is by reading open-sourced research papers on arxiv.org. However, the vast number of research papers can be overwhelming even for the most seasoned researcher to sort through. Tools like connected papers can help, but they measure similarity based on the citations and bibliography shared between papers, not the semantic meaning of the text in these documents.
In this post, I set out to build a semantic similarity search engine, which takes a single “query” paper as input and uses state-of-the-art NLP to find the top-K most similar papers from the arxiv corpus of approximately 640K computer science papers! The search runs with <50ms latency on a single laptop! Specifically, in this post, I’ll cover
- Setup the environment and download the arXiv data from Kaggle
- Load the data into Python using Dask
- Implementing a scientific paper semantic similarity search application using Milvus vector database
The techniques used in this post can be used as a template to build any NLP semantic similarity search engine, not just scientific papers. The only difference would be the pre-trained model used.
For this post, we’ll use the arXiv Dataset from Kaggle, which the authors released under the CC0: Public Domain license.
I outlined the production-scale vector similarity search considerations in my previous post. All those considerations apply to this project as well. Milvus vector database is so well designed that many of the steps are exactly the same and are replicated here only for completeness.
Setup the environment and download the arxiv data from Kaggle.
Cornel University has uploaded the entire arXiv corpus to a Kaggle dataset and licensed it under the CC0: Public Domain license. We can directly download the dataset using the Kaggle API. If you’ve not already done so, please set up the Kaggle API on your system by following these instructions.
We’ll use a conda environment for this post called semantic_similarity. If you’ve not installed conda on your system, you can do so by installing the open-sourced mini forge from its GitHub repository. The steps below create the necessary directories and conda environment, install the required Python libraries, and download the arxiv dataset from Kaggle.
# Create the necessary directories
mkdir -p semantic_similarity/notebooks semantic_similarity/data semantic_similarity/milvus
# CD into the data directory
cd semantic_similarity/data
# Create and activate a conda environment
conda create -n semantic_similarity python=3.9
conda activate semantic_similarity
## Create Virtual Environment using venv if not using conda
# python -m venv semantic_similarity
# source semantic_similarity/bin/activate
# Pip install the necessary libraries
pip install jupyterlab kaggle matplotlib scikit-learn tqdm ipywidgets
pip install "dask[complete]" sentence-transformers
pip install pandas pyarrow pymilvus protobuf==3.20.0
# Download data using the kaggle API
kaggle datasets download -d Cornell-University/arxiv
# Unzip the data into the local directory
unzip arxiv.zip
# Delete the Zip file
rm arxiv.zip
Load the data into Python using Dask
The data we downloaded from Kaggle is a 3.3GB JSON file containing around 2 million papers! To efficiently process such a large dataset, it’s not a good idea to load the entire dataset into memory using pandas. Instead, we can use Dask to split the data into multiple partitions and only load a few partitions into memory at any given time.
Dask
Dask is an open-source library that allows us to apply parallel computing with an API similar to pandas easily. It’s straightforward to set up on your local machine by running,pip install dask[complete] as shown in the setup section. Let’s start by first importing the necessary libraries.
import dask.bag as db
import json
from datetime import datetime
import time
data_path = '../data/arxiv-metadata-oai-snapshot.json'
We’ll use two components of Dask to process the large arxiv JSON file efficiently.
- Dask Bag: It lets us load the JSON file in blocks of a fixed size and run some pre-processing functions on each row of data.
- Dask DataFrame: We can convert a dask bag into a dask dataframe to get access to pandas-like APIs
Step 1: Load the JSON file into a Dask bag
Let’s load the JSON file into a dask bag where each block is 10MB in size. You can adjust the blocksize argument to control how big you want each block to be. We then apply the json.loads function to every row of the dask bag using the .map() function to parse the JSON string into a Python dictionary.
# Read the file in blocks of 10MB and parse the JSON.
papers_db = db.read_text(data_path, blocksize="10MB").map(json.loads)
# Print the first row
papers_db.take(1)
 Image by Author
Image by Author
Step 2: Write pre-processing helper functions
From the printout, we see that each row contains several metadata related to a paper. Let’s write three helper functions to help us pre-process the dataset.
v1_date(): This function is to extract the date when the authors uploaded the first version of the paper to arXiv. We’ll convert the date to UNIX time and store it as a new field in that row.text_col(): This function is to combine the “title” and “abstract” fields using a “[SEP]” token so that we can feed these texts into the SPECTRE embedding model. We’ll talk more about SPECTRE in the next section.filters(): This function only keeps rows that meet some criteria, such as max text length in various columns and papers in the Computer Science category.
def v1_date(row):
"""
For each row in the dask bag,
find the date of the first version of the paper
and add it to the row as a new column
Args:
row: a row of the dask bag
Returns:
A row of the dask bag with added "unix_time" column
"""
versions = row["versions"]
date = None
for version in versions:
if version["version"] == "v1":
date = datetime.strptime(version["created"], "%a, %d %b %Y %H:%M:%S %Z")
date = int(time.mktime(date.timetuple()))
row["unix_time"] = date
return row
def text_col(row):
"""
It takes a row of a dataframe, adds a new column called 'text'
that is the concatenation of the 'title' and 'abstract' columns
Args:
row: the row of the dataframe
Returns:
A row with the text column added.
"""
row["text"] = row["title"] + "[SEP]" + row["abstract"]
return row
def filters(row):
"""
For each row in the dask bag, only keep the row if it meets the filter criteria
Args:
row: the row of the dataframe
Returns:
Boolean mask
"""
return ((len(row["id"])<16) and
(len(row["categories"])<200) and
(len(row["title"])<4096) and
(len(row["abstract"])<65535) and
("cs." in row["categories"]) # Keep only CS papers
)
Step 3: Run the pre-processing helper functions on the Dask bag
We can easily use the .map() and .filter() functions to run the helper functions on every row of the Dask bag, as shown below. Since Dask supports method chaining, we use this opportunity to only keep a few essential columns in our Dask bag and drop the rest.
# Specify columns to keep in the final table
cols_to_keep = ["id", "categories", "title", "abstract", "unix_time", "text"]
# Apply the pre-processing
papers_db = (
papers_db.map(lambda row: v1_date(row))
.map(lambda row: text_col(row))
.map(
lambda row: {
key: value
for key, value in row.items()
if key in cols_to_keep
}
)
.filter(filters)
)
# Print the first row
papers_db.take(1)
 Image by Author
Image by Author
Step 4: Convert the Dask Bag to a Dask DataFrame
The final step of the data loading is converting the Dask Bag into a Dask Dataframe to use pandas-like APIs on each block or partition of the data.
# Convert the Dask Bag to a Dask Dataframe
schema = {
"id": str,
"title": str,
"categories": str,
"abstract": str,
"unix_time": int,
"text": str,
}
papers_df = papers_db.to_dataframe(meta=schema)
# Display first 5 rows
papers_df.head()
 Image by Author
Image by Author
Implementing a scientific paper semantic similarity search application using Milvus vector database
Milvus is one of the most popular open-source vector databases built for highly scalable and blazing fast similarity search. We’ll use the Milvus Standalone for this post since we’re only running Milvus on our local machine.
Step 1: Install the Milvus vector database on your local
Installing the Milvus vector database is a breeze using Docker, so we first need to install Docker and Docker Compose. Then, all we need to do is download a docker-compose.yml and start up the docker containers, as shown in the code snippet below! The milvus.io website provides many other options to install both Milvus standalone and Milvus Cluster; please check it out if you need to install it on a Kubernetes cluster or install it offline.
# CD into milvus directory
cd semantic_similarity/milvus
# Download the Standalone version of Milvus docker compose
wget https://github.com/milvus-io/milvus/releases/download/v2.1.0/milvus-standalone-docker-compose.yml -O ./docker-compose.yml
# Run the Milvus server docker container on your local
sudo docker-compose up -d
Step 2: Create a Milvus collection
Now that we have the Milvus vector database server running on our local machine, we can interact with it using the pymilvus library. First, let’s import the necessary modules and connect to the Milvus server running on localhost. Feel free to change the alias and collection_name parameters. The model we use to convert our text to embeddings determines theemb_dim parameter’s value. In the case of SPECTRE, the embeddings are 768d.
# Make sure a Milvus server is already running
from pymilvus import connections, utility
from pymilvus import Collection, CollectionSchema, FieldSchema, DataType
# Connect to Milvus server
connections.connect(alias="default", host="localhost", port="19530")
# Collection name
collection_name = "arxiv"
# Embedding size
emb_dim = 768
# # Check for existing collection and drop if exists
# if utility.has_collection(collection_name):
# print(utility.list_collections())
# utility.drop_collection(collection_name)
Optionally, you can check if the collection specified by collection_name is already present on your Milvus server. For this example, if the collection is already available, I delete it. But in a production server, you would not do this and would instead skip the collection creation code below.
A Milvus collection is analogous to a table in a traditional database. To create a collection to store data, we first need to specify the collection’s schema. In this example, we’re leveraging Milvus 2.1’s ability to store string index and fields to store all the necessary metadata related to each paper. The primary key idx and other fields categories, title, abstract have VARCHAR datatype with reasonable max lengths, while the embedding is a FLOAT_VECTORfield containing the emb_dim dimension embeddings. Milvus supports a wide variety of data types, as shown in our documentation page.
# Create a schema for the collection
idx = FieldSchema(name="id", dtype=DataType.VARCHAR, is_primary=True, max_length=16)
categories = FieldSchema(name="categories", dtype=DataType.VARCHAR, max_length=200)
title = FieldSchema(name="title", dtype=DataType.VARCHAR, max_length=4096)
abstract = FieldSchema(name="abstract", dtype=DataType.VARCHAR, max_length=65535)
unix_time = FieldSchema(name="unix_time", dtype=DataType.INT64)
embedding = FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=emb_dim)
# Fields in the collection
fields = [idx, categories, title, abstract, unix_time, embedding]
schema = CollectionSchema(
fields=fields, description="Semantic Similarity of Scientific Papers"
)
# Create a collection with the schema
collection = Collection(
name=collection_name, schema=schema, using="default", shards_num=10
)
Once a collection has been created, we are now ready to upload our texts and vectors into it.
Step 3: Iterate over our Dask dataframe’s partitions, embed the texts using SPECTER, and upload them to the Milvus vector database
First, we need to convert the texts in the Dask dataframe into an embedding vector to run a semantic similarity search. My post below shares how we can convert texts to embeddings. In particular, we’ll use an SBERT Bi-Encoder model called SPECTRE for converting scientific papers to embeddings.
SPECTER [paper] [Github]: Scientific Paper Embeddings using Citation-informed TransformERs is a model to convert scientific papers to embeddings.
- Each paper’s Title and Abstract texts are concatenated with the [SEP] token and converted to embeddings using the [CLS] token of a pre-trained Transformer model (SciBERT).
- Use citations as a proxy signal for inter-document relatedness. If one paper cites another, we can infer they are both related.
- Triplet loss training objective: We train the Transformer model, so papers with shared citations are closer in the embedding space.
- In other words, a Positive paper is a paper cited in the Query paper, while a Negative paper is a paper not cited by the Query paper. Randomly sampled negatives are “easy” negatives.
- To improve performance, we create “hard” negatives using papers that are NOT cited by the Query paper but ARE cited by the Positive paper.
- We only need the Title and Abstract during inference. No citations are required, so SPECTER can produce embeddings even for new papers that don’t have any citations yet!
- SPECTER provides excellent performance (better than SciBERT) in topic classification, citation prediction, and recommendation of Scientific Papers.
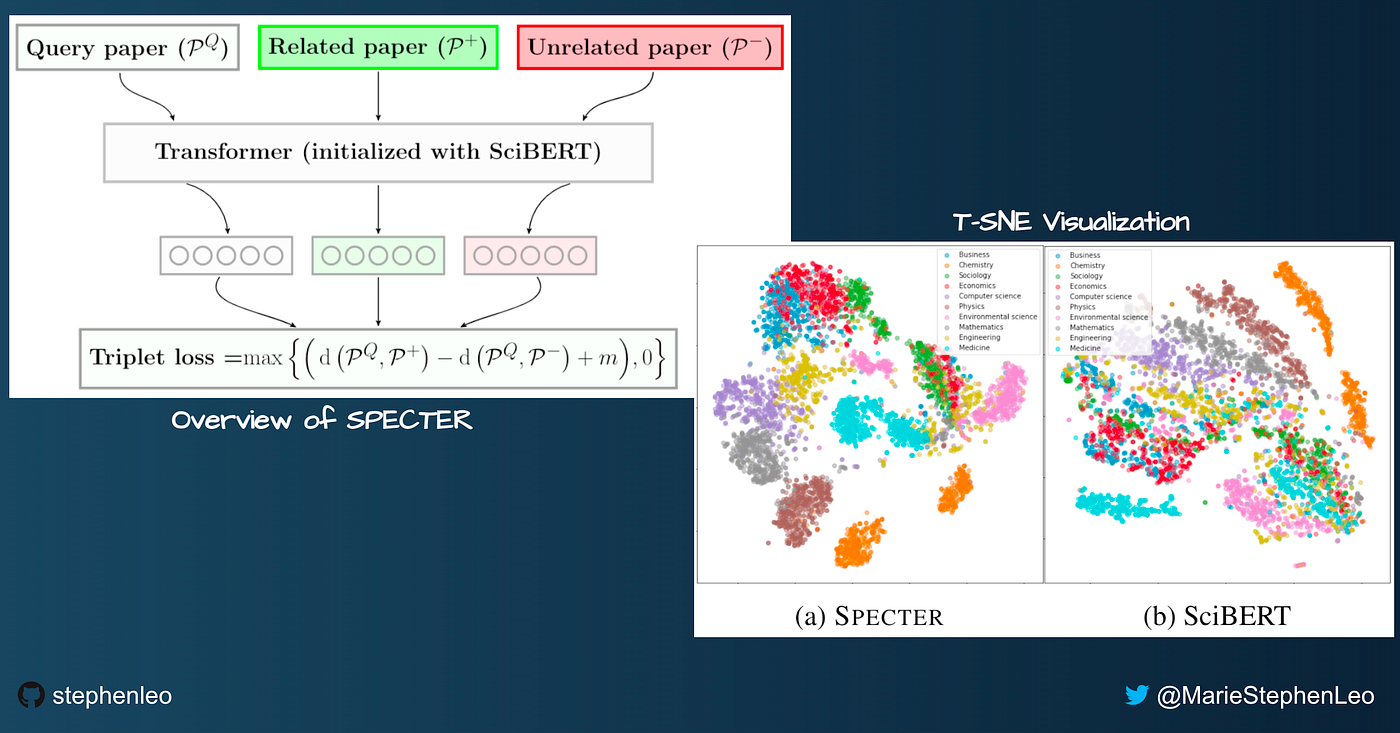 Image by Author using screenshots from open-sourced SPECTER paper
Image by Author using screenshots from open-sourced SPECTER paper
Using the pre-trained SPECTRE model is simple with the Sentence Transformer library. We can download the pre-trained model with just one line of code, as shown below. We also write a simple helper function to convert an entire column of texts from the Dask dataframe partition into embeddings.
from sentence_transformers import SentenceTransformer
from tqdm import tqdm
# Scientific Papers SBERT Model
model = SentenceTransformer('allenai-specter')
def emb_gen(partition):
return model.encode(partition['text']).tolist()
We need to iterate over the Dask dataframe’s partitions to upload the data into our Milvus collection. During each iteration, we load only the rows from that partition into memory and add the data from metadata columns to a variable data. We can use the dask .map_partitions() API to apply the embedding generation to every row in the partition and append the results back to the same data variable. Finally, we can upload the data to Milvus with collection.insert.
# Initialize
collection = Collection(collection_name)
for partition in tqdm(range(papers_df.npartitions)):
# Get the dask dataframe for the partition
subset_df = papers_df.get_partition(partition)
# Check if dataframe is empty
if len(subset_df.index) != 0:
# Metadata
data = [
subset_df[col].values.compute().tolist()
for col in ["id", "categories", "title", "abstract", "unix_time"]
]
# Embeddings
data += [
subset_df
.map_partitions(emb_gen)
.compute()[0]
]
# Insert data
collection.insert(data)
Please take note that the order of columns added into the data variable must follow the same order as the fields variable we defined during the schema creation!
Step 4: Create an Approximate Nearest Neighbors (ANN) index on the uploaded data
After we insert all the embeddings into the Milvus vector database, we need to create an ANN index to speed up the search. In this example, I’m using the HNSW index type, one of the fastest, most accurate ANN indexes. Look at the Milvus documentation for more information on the HNSW index and its parameters.
# Add an ANN index to the collection
index_params = {
"metric_type": "L2",
"index_type": "HNSW",
"params": {"efConstruction": 128, "M": 8},
}
collection.create_index(field_name="embedding", index_params=index_params)
Step 5: Run your Vector Similarity Search queries!
Finally, the data in our Milvus collection is ready to be queried. First, we must load the collection into memory to run queries against it.
# Load the collection into memory
collection = Collection(collection_name)
collection.load()
Next, I’ve created a simple helper function that takes in a query_text, converts it to the SPECTRE embedding, executes an ANN search across the Milvus collection, and prints out the results. We can control the search quality and speed using the search_params described on the HNSW documentation page.
def query_and_display(query_text, collection, num_results=10):
# Embed the Query Text
query_emb = [model.encode(query_text)]
# Search Params
search_params = {"metric_type": "L2", "params": {"ef": 128}}
# Search
query_start = datetime.now()
results = collection.search(
data=query_emb,
anns_field="embedding",
param=search_params,
limit=num_results,
expr=None,
output_fields=["title", "abstract"],
)
query_end = datetime.now()
# Print Results
print(f"Query Speed: {(query_end - query_start).total_seconds():.2f} s")
print("Results:")
for res in results[0]:
title = res.entity.get("title").replace("\n ", "")
print(f"➡️ ID: {res.id}. L2 Distance: {res.distance:.2f}")
print(f"Title: {title}")
print(f"Abstract: {res.entity.get('abstract')}")
We can now use the helper function with just one line of code to run a semantic arXiv paper search against the entire ~640K Computer Science papers stored in our Milvus collection. For example, I’m searching for some papers similar to the SimCSE paper I discussed in detail in my previous post. The top 10 results are quite relevant to my search query as they are mostly related to contrastive learning of sentence embeddings! It’s even more impressive that the entire search took only 30ms just running on my laptop, which is well within typical usage requirements for most applications!
# Query for papers that are similar to the SimCSE paper
title = "SimCSE: Simple Contrastive Learning of Sentence Embeddings"
abstract = """This paper presents SimCSE, a simple contrastive learning framework that greatly advances state-of-the-art sentence embeddings. We first describe an unsupervised approach, which takes an input sentence and predicts itself in a contrastive objective, with only standard dropout used as noise. This simple method works surprisingly well, performing on par with previous supervised counterparts. We find that dropout acts as minimal data augmentation, and removing it leads to a representation collapse. Then, we propose a supervised approach, which incorporates annotated pairs from natural language inference datasets into our contrastive learning framework by using "entailment" pairs as positives and "contradiction" pairs as hard negatives. We evaluate SimCSE on standard semantic textual similarity (STS) tasks, and our unsupervised and supervised models using BERT base achieve an average of 76.3% and 81.6% Spearman's correlation respectively, a 4.2% and 2.2% improvement compared to the previous best results. We also show -- both theoretically and empirically -- that the contrastive learning objective regularizes pre-trained embeddings' anisotropic space to be more uniform, and it better aligns positive pairs when supervised signals are available."""
query_text = f"{title}[SEP]{abstract}"
query_and_display(query_text, collection, num_results=10)
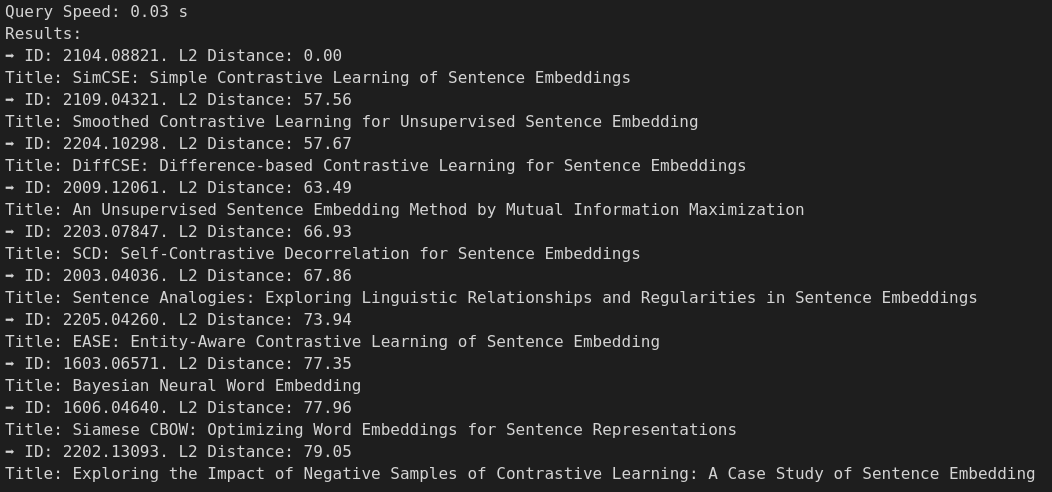 Image by Author
Image by Author
If we do not need to run any more queries, we can release the collection to free up our machine’s memory. Removing a collection from memory does not cause data loss as it is still stored on our disk and can be loaded again when needed.
# Release the collection from memory when it's not needed anymore
collection.release()
If you want to stop the Milvus server and delete all the data from the disk, you can follow the Stop Milvus instructions. Beware! This operation is irreversible and will delete all the data in your Milvus cluster.
Conclusion
In this post, we implemented an ultra-scalable Semantic Search of Scientific Papers service using SPECTRE embeddings and Milvus vector database in a few easy steps. This approach is scalable in production to hundreds of millions or even billions of vectors. We tested the search using a sample paper query that returned the top 10 results in just 30ms! Milvus’ reputation as a highly scalable and blazing fast vector similarity search database is well deserved!
For more inspiration on Milvus’ applications, please head to Milvus vector database demos and Bootcamp.
Keep Reading

Stop Building AI Data Infra for the Wrong Stage
Learn how AI data infrastructure should evolve from prototype to enterprise scale, and when Vector Lakebase becomes the right architecture for AI apps.

We spent 8 years making vector databases faster. Then we stopped.
Rarely queried embeddings still need to stay searchable. See how Vector Lakebase enables on-demand vector search without always-on compute costs.

Cosmos World Foundation Model Platform for Physical AI
NVIDIA's Cosmos platform enables safe, digital twin training of GenAI models for physical applications, overcoming data scarcity and safety challenges.