




Building RAG Pipelines for Real-Time Data with Cloudera and Milvus
In the current era of big data, businesses generate massive amounts of data which require efficient processing to unlock its full potential. Therefore, performing large-scale data processing, adaptability to various cloud environments, and the ability to make decisions in real-time while maintaining data governance and security are some of the essential features required in a data management platform.
At a recent Unstructured Data Meetup hosted by Zilliz, Chris Burns, a principal Gen AI engineer at Cloudera, talked about how Cloudera - an enterprise data cloud platform for managing end-to-end data lifecycle, can be used to build efficient Retrieval Augmented Generation (RAG) pipelines. He discussed the importance of RAG for Large Language Model (LLM) applications, the challenges that can be faced, and the steps to build an RAG pipeline with Milvus to generate better data.
In this blog, we will recap his key points and explore how Cloudera can be integrated with Milvus to effectively implement some of the key functionalities of RAG pipelines. For more details, watch the full replay of his talk on YouTube.
A Brief About Cloudera
Cloudera is a comprehensive enterprise data platform that supports the entire data lifecycle - from ingestion and storage to analytics. It offers rapid deployment and the ability to build AI at scale with reduced cost and risk across any data center or cloud platform. With capabilities like real-time streaming, data engineering, multi-temperature storage, and adaptability to multimodal data, Cloudera is a great platform for building flexible Gen AI applications for enterprises.
Building RAG Pipelines with Real-Time Data
Retrieval Augmented Generation (RAG) is a technique to boost the performance of LLMs by accessing information from external sources such as databases. This additional information (lake) makes LLMs produce more contextually relevant and accurate responses grounded in specific domain knowledge which otherwise was not available with the training data of the LLM. It is an efficient technique to make LLM address specific use cases without retraining every time. The challenge lies in building a pipeline that can handle the complexities of real-time data ingestion, processing, and retrieval while maintaining low latency and cost along with high accuracy. This is where Cloudera’s robust infrastructure and tools like Milvus come into play which supports private AI and real-time retrieval.
Before we have a look at the ready workflows for RAG pipelines, let’s first understand some of the theoretical concepts involved.
How to go about building RAG pipelines?
Building an RAG pipeline involves several steps, from understanding the basic theory to implementing advanced configurations. Let’s break it down:
RAG - 101 - Common Challenges and Basic Setup
Chris begins by talking about the common challenge of hallucination that most LLMs suffer from. However, here, he rephrases to call it confabulation and fabrication. Confabulation refers to LLMs filling out the missing information with plausible-sounding but incorrect information whereas fabrication refers to creating some imaginary text. To handle these issues, Chris mentions that contextually understanding the query is very important in addition to performing multi-hop machine reasoning and maintaining traceability to track the flow of data or objects.
Having talked about the challenges, let’s understand the basic setup of a RAG system. At its core, an RAG pipeline consists of two main components:
Retriever: This component searches a large dataset (e.g., a vector database) to find relevant information based on a query.
Generator: This component uses the retrieved information to generate a coherent and contextually accurate response.
The retriever and generator work in tandem to ensure that the system provides accurate and relevant answers, even when dealing with complex queries. However, as Chris points out, a successful ML project requires not just good data but also domain expertise. Data must be relevant and consistent, and domain knowledge is critical for ensuring relevancy.
RAG - 201 - Statistical Analysis and Hybrid Inference
Statistical Analysis - To improve the performance of RAG pipelines, doing some statistical analysis may help to understand the response quality of the LLMs better.
Using a confusion matrix in the context of Gen AI might help to quantitatively understand the retrieval success rates.
Anthropomorphizing the LLM responses by denying the answers when they are not known rather than making up false statements could add more human touch to the answers.
- Hybrid Inference - Hybrid inference is a great technique for enterprises to balance performance and security within budget constraints. It uses a combination of pre-defined rules and machine learning models to handle edge cases and improve response quality. The aim here is to be able to reproduce outcomes in different platforms hence the focus should be on architectures that are agile, scalable, and suitable for real time.
RAG - 301 - Data Type Considerations
To store the data in the vector database efficiently, it’s essential to devise appropriate partitioning and chunking strategies. Partitioning refers to dividing the data into smaller, more manageable units whereas chunking refers to bundling these partitions together based on the content of the elements. To determine both, knowing the data type is crucial.
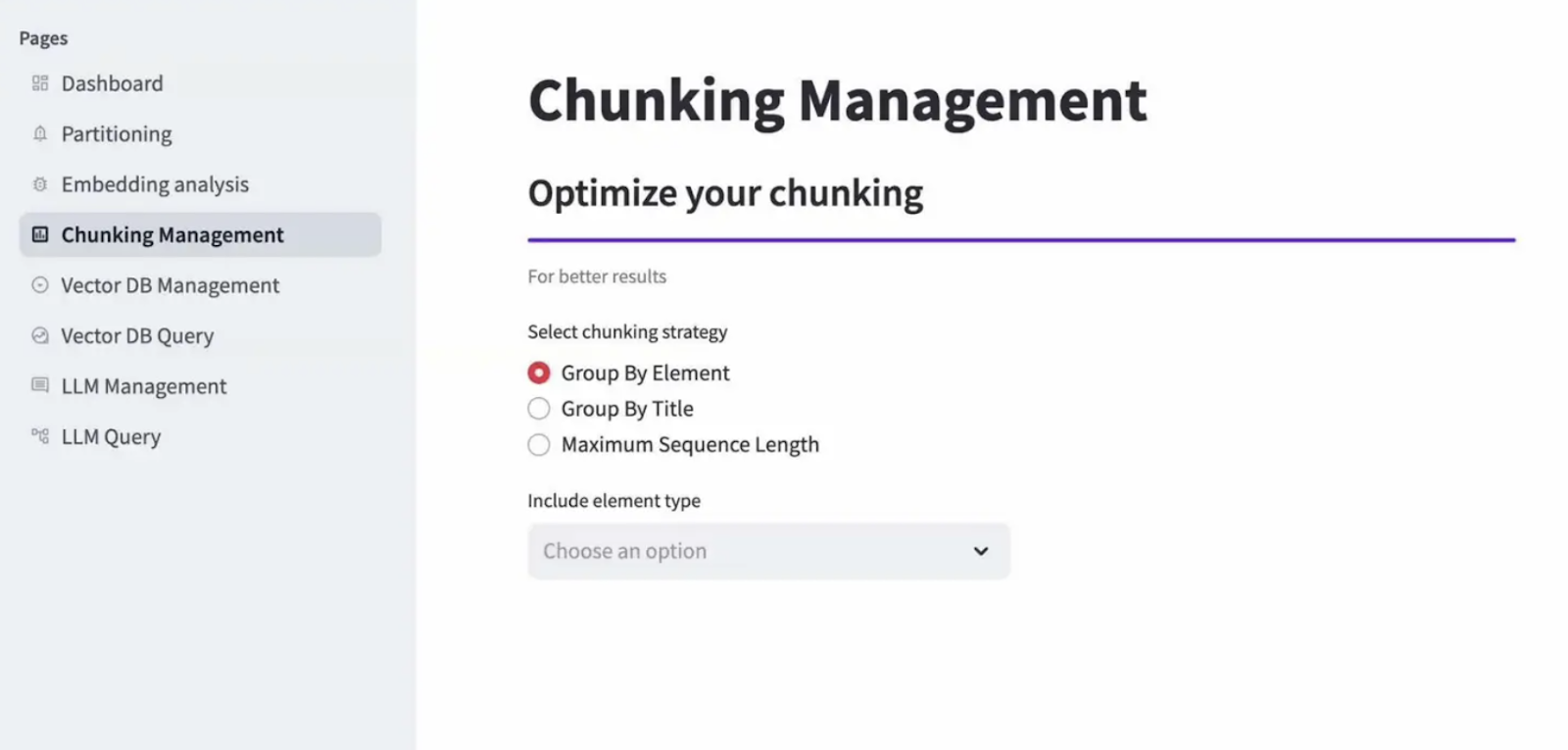 Types of Chunking Strategies
Types of Chunking Strategies
Types of Chunking Strategies
Data in the form of novels, technical docs, or emails is classified as dense data, i.e. having very few null values, which means each element is important. On the other hand, data such as sensor data, categorical or graph data is called sparse data as it has many null values.
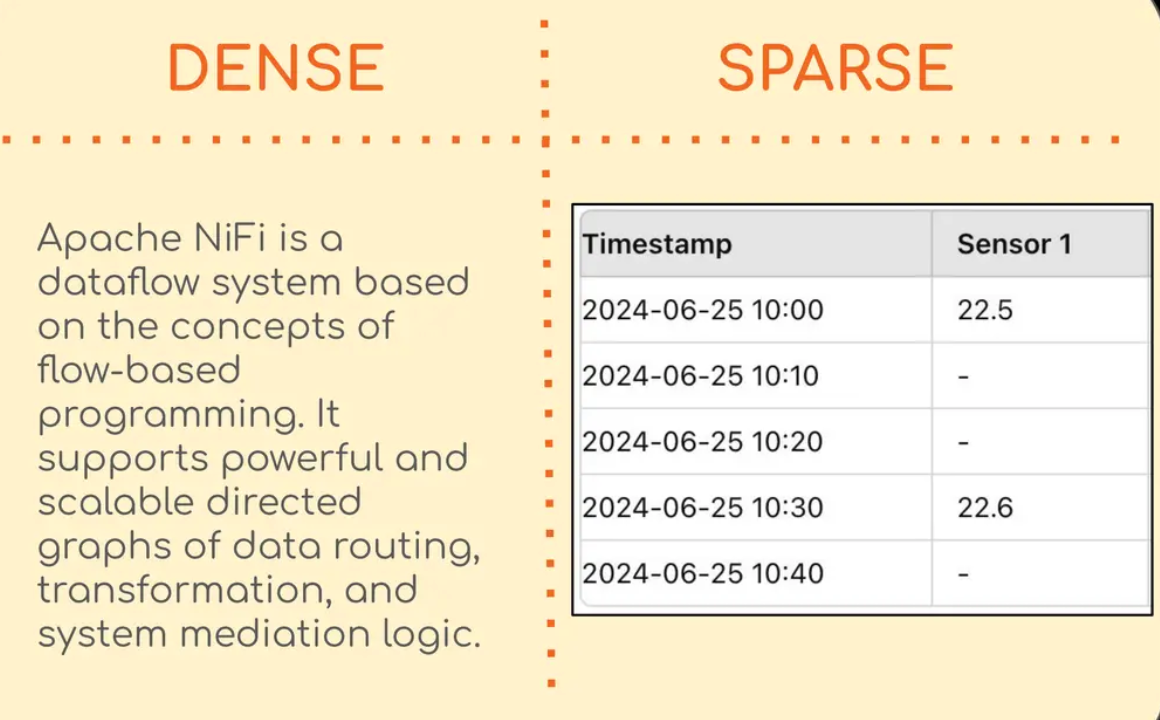 An example of dense and sparse data
An example of dense and sparse data
An example of dense and sparse data
The type of data being used in an RAG pipeline can have a significant impact on its performance and accuracy. Different types of data, such as text, images, and audio, require different processing and retrieval techniques. Understanding the type of data being used and how to process it effectively is crucial for building a successful RAG pipeline.
RAG - 401 - Milvus Vector DB Configurations
Milvus is an open-source vector database designed for efficient storage, indexing, and searching of high-dimensional vector embeddings. It is optimized for similarity search, making it ideal for recommendation systems, image retrieval applications, and RAG pipelines. Milvus can support large datasets and is highly scalable making it suitable for enterprise applications. The following capabilities of Milvus are particularly useful for RAG pipelines -
- Hybrid Search - Milvus supports hybrid search (multi-vector search) which involves performing simultaneous queries across multiple vector fields within the same dataset and integrating the results with re-ranking strategies. This allows the flexibility for the individual vectors to use different embedding models, data processing techniques, or any other custom operation.
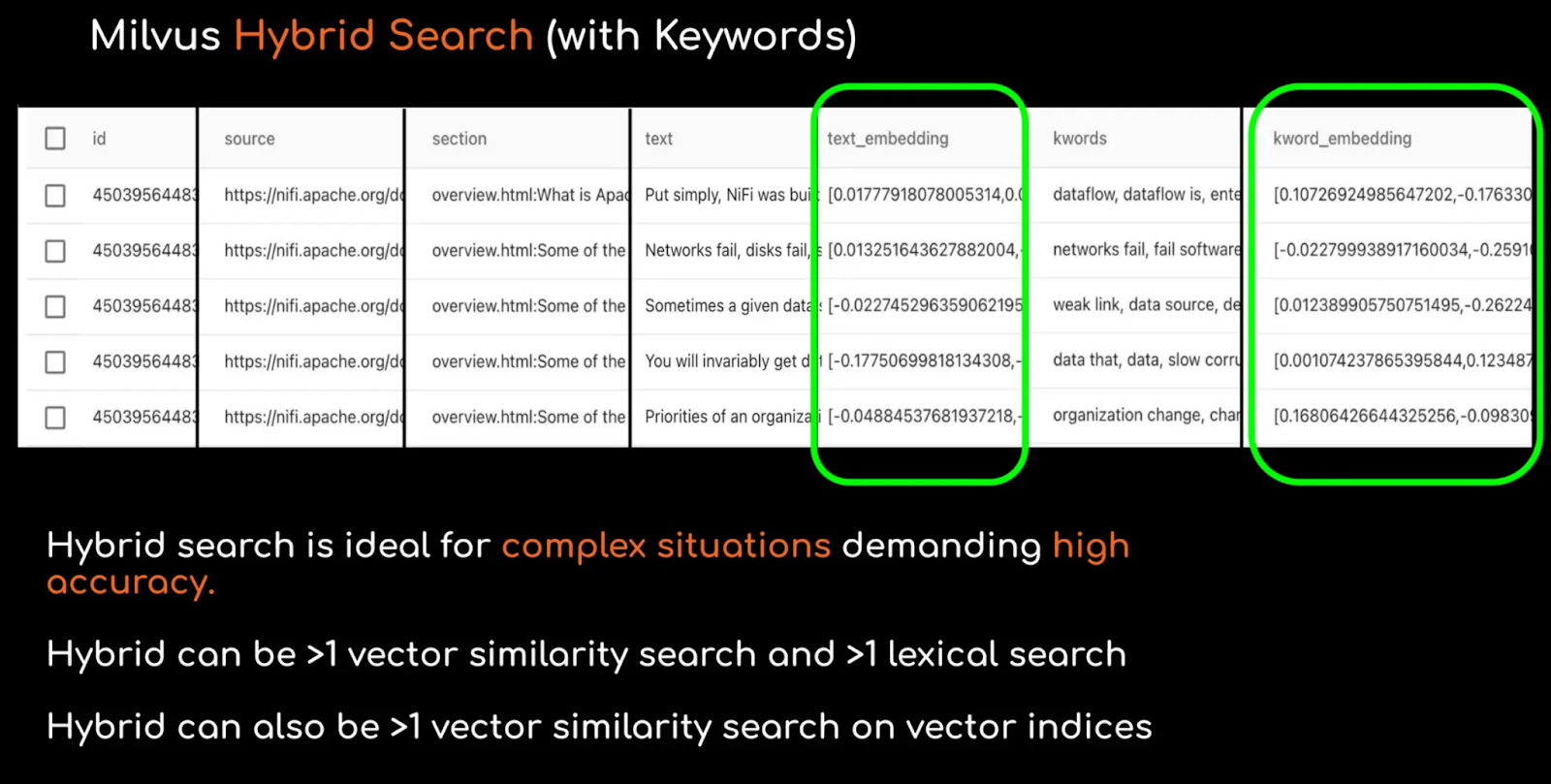 Hybrid search with Milvus
Hybrid search with Milvus
Hybrid search with Milvus
- Multi-trip Queries - Milvus supports advanced retrieval techniques for complex queries which can balance the trade-off between different search methods used in hybrid search. Through multi-trip queries, a query can be processed iteratively over multiple steps to improve search results. After the initial execution of the query, further queries can be executed based on reranking (sorting the results with a priority order), query expansion (expanding on a particular attribute), or filtering.
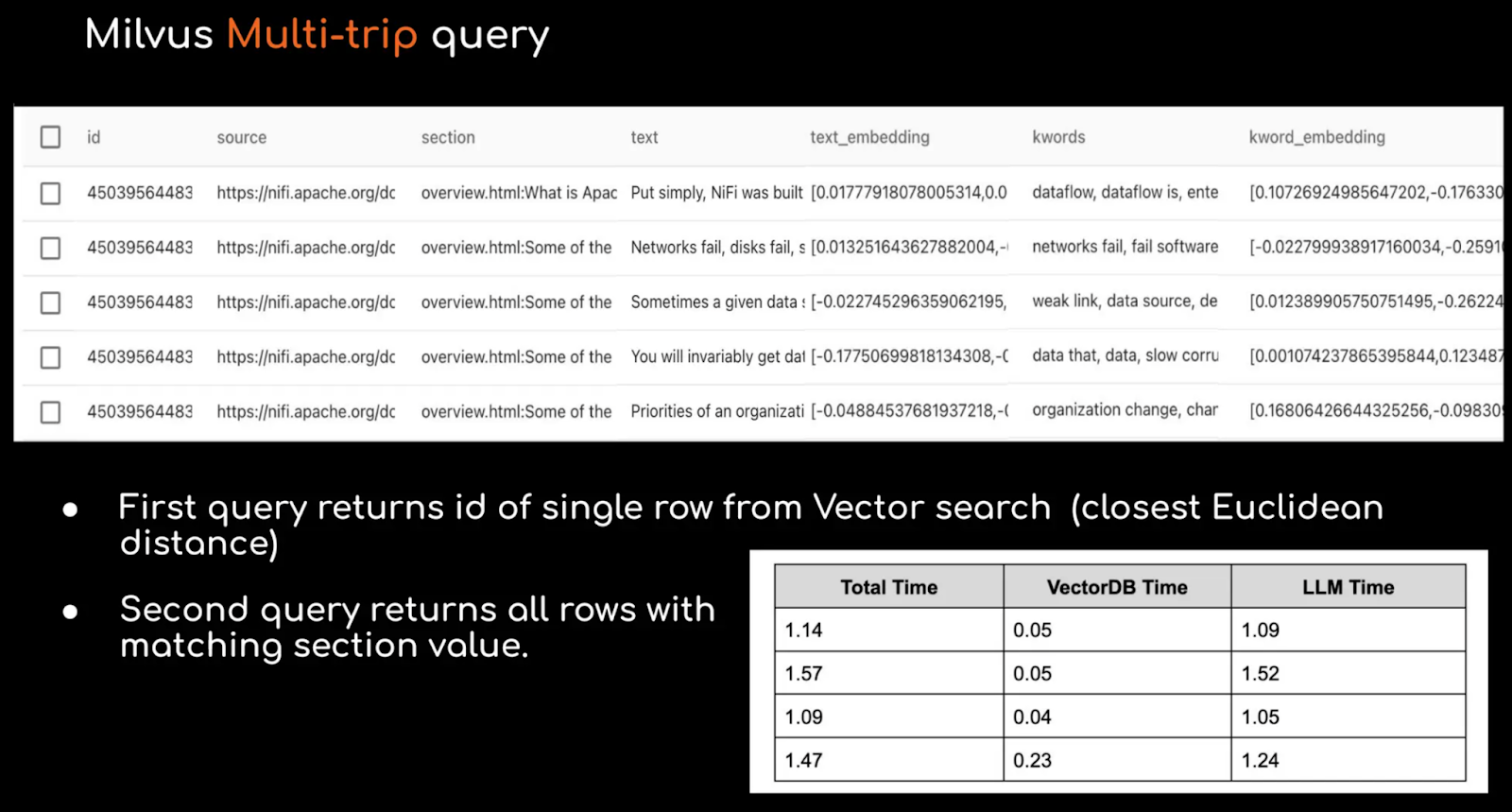 Multi-trip querying with Milvus
Multi-trip querying with Milvus
Multi-trip querying with Milvus
Finally, Milvus supports the use of gatekeepers, which are filters that can be applied to the retrieval process to ensure that only relevant information is retrieved before passing to the generator. This can be particularly useful in real-time RAG pipelines, where the volume of data can be very large, and it is important to filter out irrelevant information quickly.
Integrating Milvus and Cloudera for RAG Pipelines
Cloudera offers ready workflows for RAG which are powered by Apache NiFi 2.0 (a dataflow system based on flow-based programming). The workflows support various data stores, models, and vector databases including Milvus. Let’s briefly have a look at some of them.
- S3 to Milvus - The first step in RAG is to gather the data from the source, preprocess it, convert it to embeddings, and store it in a vector database.
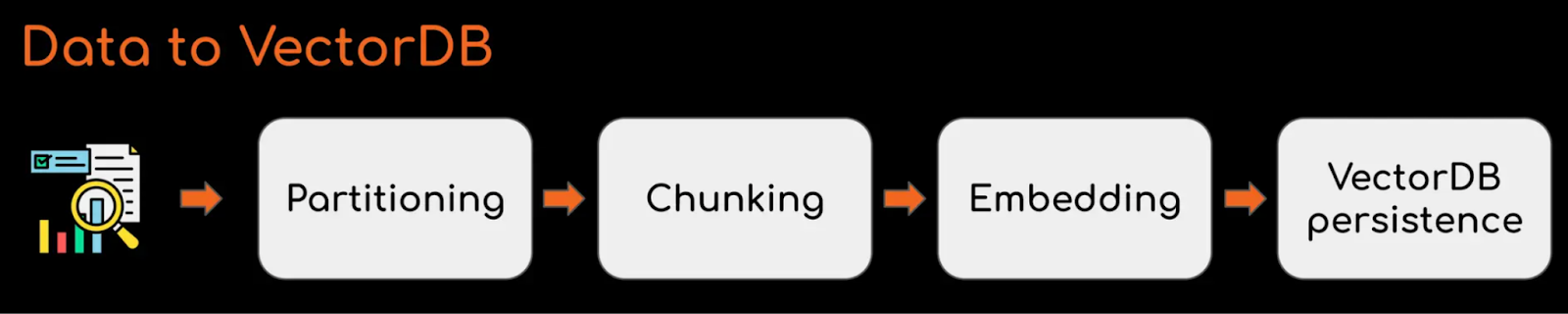 Data to VectorDB workflow
Data to VectorDB workflow
Data to VectorDB workflow
For example, this Cloudera workflow takes pdf documents from S3, vectorizes them using a huggingface model, and writes the results to Milvus. All the data processing steps such as partitioning and chunking can be performed simply by dragging, dropping, and running relevant connectors.
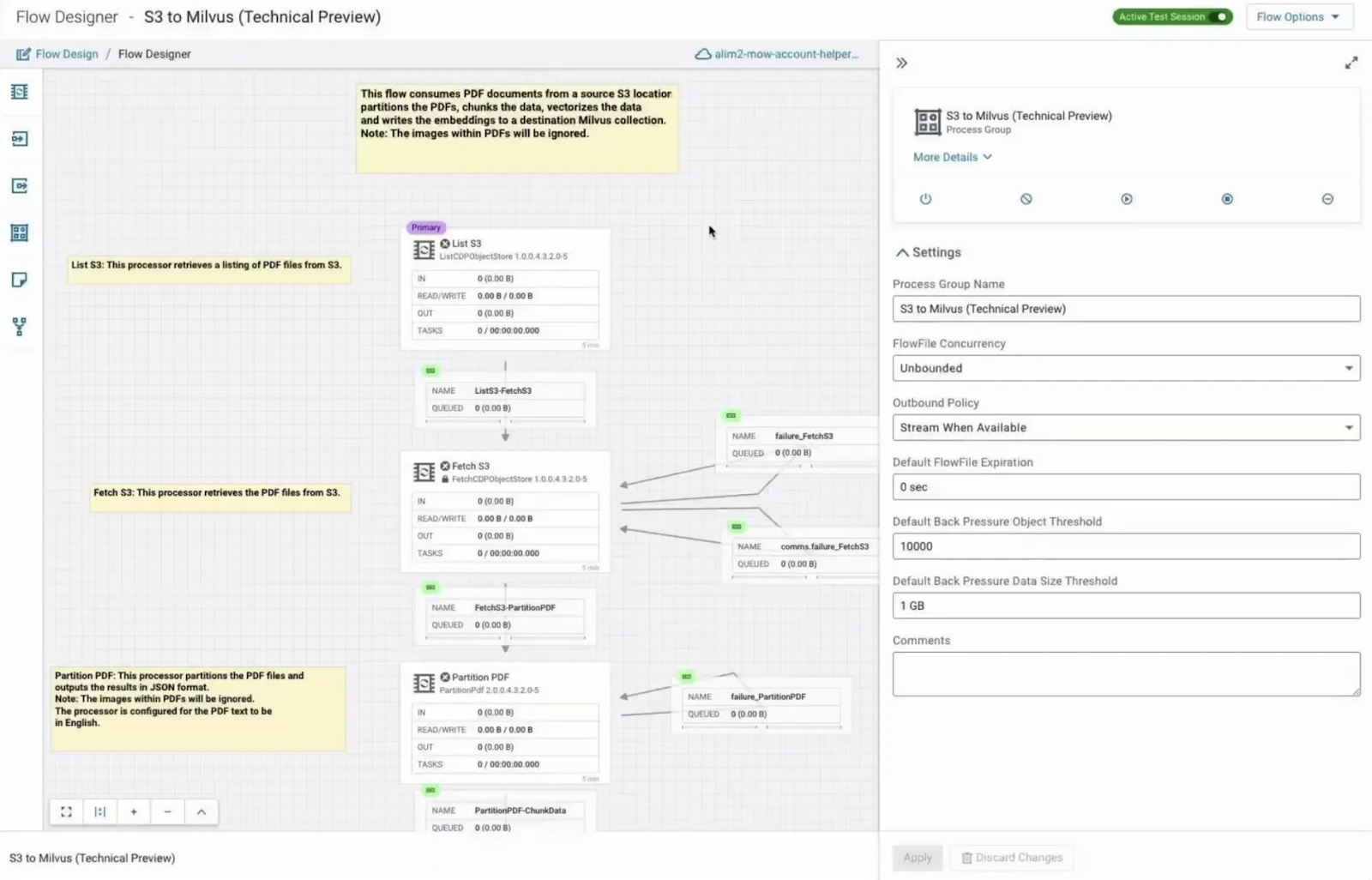 S3 to Milvus workflow by Cloudera
S3 to Milvus workflow by Cloudera
S3 to Milvus workflow by Cloudera
- RAG Query Milvus - The second step in RAG is to take the query as input, convert it to embeddings, and then perform a similarity search with the already stored embeddings in the vector database. The data whose embeddings are closest to the query embedding will be fetched. This information will act as an added context for the LLM to generate the response. Cloudera offers a ready workflow for querying Milvus for RAG.
 RAG Query Milvus workflow by Cloudera
RAG Query Milvus workflow by Cloudera
RAG Query Milvus workflow by Cloudera
Conclusion
In this blog, we talked about how you can build real-time RAG pipelines with Cloudera based on the talk given by Chris Burns at the Unstructured Data Meetup. As businesses are evolving by becoming larger day by day, we need advanced solutions to derive value from the vast amount of information efficiently. Through data lifecycle management platforms like Cloudera, Gen AI applications can be easily developed for enterprises with minimal effort. Additionally, integrating Milvus with Cloudera together provides a robust framework for building RAG pipelines.
Chris started by talking about the common challenges faced by LLMs such as confabulation and fabrication and ways to handle them. Furthermore, he stressed the importance of performing statistical analysis and hybrid inference to improve the performance of RAG pipelines. Milvus is a great vector database for the use-case of RAG as it supports hybrid inference, multi-trip queries, and gatekeepers, to ensure accurate, context-aware responses while maintaining security.
Keep Reading

Zilliz Cloud Delivers Better Performance and Lower Costs with Arm Neoverse-based AWS Graviton
Zilliz Cloud adopts Arm-based AWS Graviton3 CPUs to cut costs, speed up AI vector search, and power billion-scale RAG and semantic search workloads.

Zilliz Cloud Enterprise Vector Search Powers High-Performance AI on AWS
Zilliz Cloud on AWS powers secure, scalable, ultra-fast vector search for enterprise AI apps, with BYOC, sub-10ms latency, and zero-DevOps simplicity.

Zilliz Named "Highest Performer" and "Easiest to Use" in G2's Summer 2025 Grid® Report for Vector Databases
Zilliz shines in G2's Summer 2025 Grid® Report as both "Highest Performer" and "Easiest to Use," solving the performance-usability dilemma.