Sharding, Partitioning, and Segments - Getting the Most From Your Database

This post is written by Christy Bergman and Yi Wang.
Milvus has three main, parallel work streams: Data, Search, and Indexing. In this blog, we will take a closer look at optimizing the performance of your database from the point of view of a Data Practitioner. To maximize the database performance of the Milvus architecture, we need to delve into distributed data concepts, particularly sharding, partitions, and segments.
Sharding - for distributed data writing
In distributed data writes, a shard refers to a horizontal data partition in a database. Think of it like dividing a book into chapters, where each chapter resides on a separate server, and each chapter can be written concurrently. This speeds up writing by utilizing distributed systems.
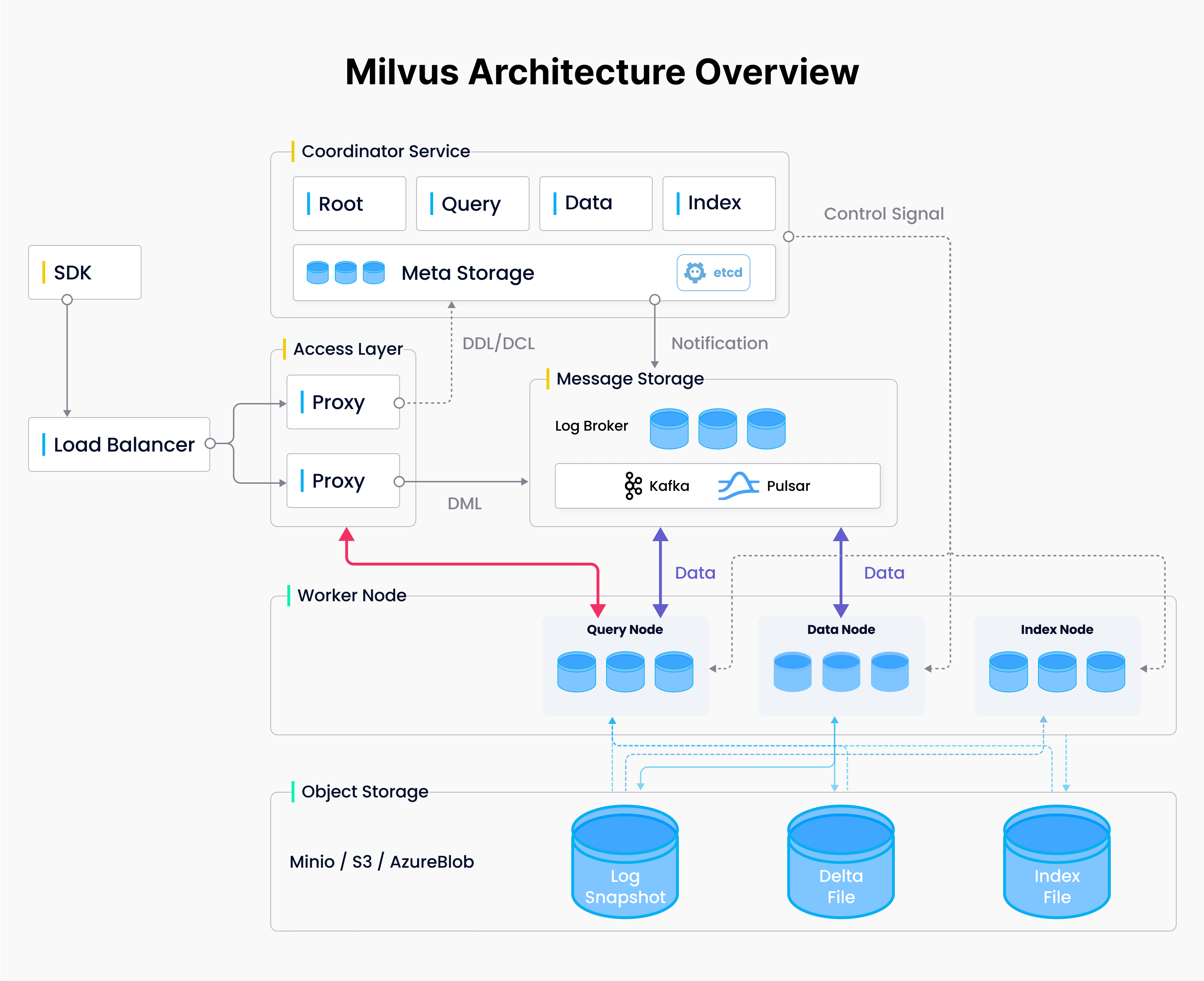
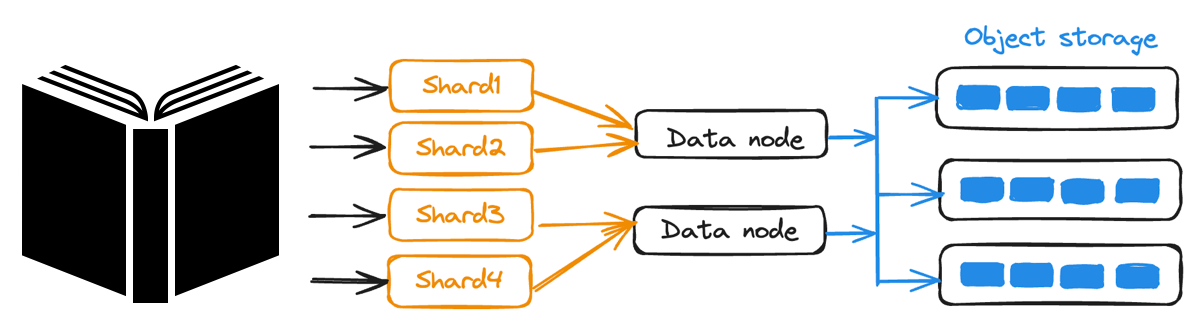 Collection shards map to channels (not shown), which map to Data Worker Nodes and Object Storage
Collection shards map to channels (not shown), which map to Data Worker Nodes and Object Storage
In Milvus, the mapping between shards, data nodes, and persisted object storage happens automatically.
When you add or delete data, proxies write messages using the `AsProducer()` interface of the MsgStream to a Log Broker, like a central message box.
Data is then split into channels ("shards") by hash(Primary key), so all Data Nodes are roughly balanced, and the data is temporarily stored on each channel.
Once a channel's temporary storage fills up (16MB by default), the data is permanently saved in object storage. The storage path is recorded in etcd by data coordinators.
🤔 For faster writes:
- Increase the number of shards, but not too much!
- Milvus uses time-tick machinery to maintain data consistency between data channels (shards). For each data channel, the rootCoord sends a timestamp message every 200 milliseconds. More channels will bring heavier pressure to Pulsar/Kafka.
- The best practice is to have one shard per 50-200 million data entities (rows). So, if you have 1 billion entities, it is best to have 4-8 shards. In most situations, 1-2 shards are recommended.
- Increase the number of data nodes if flush takes too long.
Add proxy servers if the network is the bottleneck.
Load test your configuration of proxy servers, shards, and data nodes per cluster for expected write throughput.
| Task | Documentation link | Notes |
|---|---|---|
| Define the number of shards | Define a collection | num_shards=2 is the default. num_shards is fixed once the collection is created. There is no way to increase or reduce the shard number after that. |
| Change the number of nodes | Scaling your cluster | 3 types of nodes in your cluster are Query, Data, and Index nodes |
Partitioning - for targeted data reading
In distributed data reads, partitioning involves organizing data for efficient retrieval. Imagine a book with chapters and a reader interested in a specific subject. They will read through the book based on specific criteria, akin to using a database key.
For instance, imagine a French cookbook with chapters on meat, vegetables, sauces, and pastry. Suppose a cook wants to make a perfect steak with Béarnaise Sauce, gratin dauphinois, and a green salad. For the steak, they would read only the steak segment of the meat chapter and the Béarnaise segment from the sauces chapter.
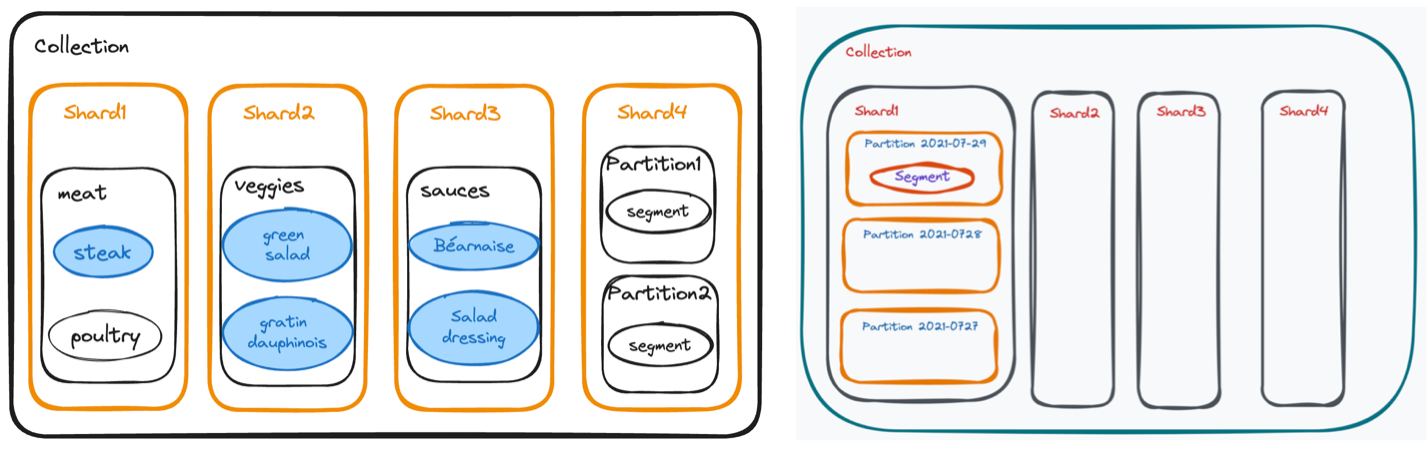
Left: Conceptually, shards are for evenly distributing data for faster writing, while partitions are for targeted retrieval. Right: In Milvus, each shard usually has multiple partitions.
In Milvus, each shard usually has multiple partitions since data in real life is scooped up by the bucket full; data is not necessarily pre-organized by book chapters! Partitioning optimally places related data on the same Query Node to minimize cross-node communication for faster targeted reads. The advantage is the system only needs to search the specific partition that contains the given key.
Milvus supports manual or automatic partitioning. Both types are equally as fast! We recommend using Automatic partitioning since it is less error-prone.
Manual Partitioning: You must ensure roughly equal entity distribution (20K-100K each). Why? Because Milvus does not build an index for fewer than 1024 entities (rows). An anti-pattern is 1 million entities in 1000 partitions, meaning no index is built, and search is slow! The best practice for manual partitions is to define a partition key and use the partition key name in searches. The partition key prevents Milvus from scanning irrelevant partitions when filtering by the key field. Manually naming, loading, and dropping your partitions is possible, but not as fast as using partition keys.
Automatic Partitioning: Let Milvus automatically distribute entities into different partitions by hash (Partition key). In this case, you do not need to create or specify partition key values when searching. Milvus will automatically translate where to find the data from your search and metadata filter expression.
🤔 For targeted reading:
BEST PRACTICE is Automatic Partitioning with metadata filters if desired.
For Manual partitions, we recommend to us partition keys:
You need to understand how your users will search; these will be your partition keys.
Aim for partitions with ~20-100K rows each.
Specify a particular field, for example, the date field as your partition key.
Define the partition key when creating the collection and use it during search.
Multi-tenancy manual use case: `tenant_id` as the partition key. Note: In Milvus today, this is just logical isolation, not real RBAC, which is defined at the collection level.
| Task | Documentation link | Notes |
|---|---|---|
| Define partition keys | Define a collection | In the schema: is_partition_key=True or partition_key_field="store_address" Limit is 4096 before v2.3.4, 10K after |
| Specify partition key values during the search | Use partition-key | Partition keys go in the metadata filter expr: expr='<partition_key> in ["xxx", "xxx"]' The search filter must include the partition keys. |
Segments
Think of segments as being in the intersection of shards and partitions. By design, segments cannot cross shard or partition boundaries. Each segment contains many data entities (rows) with a unique primary key, timestamp, and vector field. The Milvus system is constantly checking if small segments can be merged; since fewer segments are more efficient for search performance.
Segments are the smallest unit in Milvus for load balancing. Indexes built on separate data segments don’t depend on each other, which enables distributed search. Segments come in two types: growing and sealed. Growing segments are written until reaching a size limit (110 MB by default), at which point they are sealed. The system reads data from both growing and sealed segments for streaming access.
Indexes are typically built only on sealed segments, posing challenges when dealing with rapidly changing data like user clicks on a shopping site. In Milvus 2.3.4, a new, automatic feature utilizes binlogs (binary logs that track operations like inserts and deletes within segments for data recovery and accuracy) on growing segments. This allows faster indexing, making searches within growing segments 10 times quicker.
🤔Segment size:
Usually, you should not tune the segment size.
Inserted data is accumulated in growing segments in query nodes for search, so only if you have very large machine resources, increasing segment size might speed up search. In this case, fewer segments might be more efficient since aggregation is unnecessary during partitioning. However, this could lead to unbalanced query nodes. Quick guide:
For query node sizes of 4GB-8GB, use 512MB segments.
For query nodes <16GB, use 1GB segments.
For query nodes >16GB, opt for 2-4GB segment sizes.
For more information see our cluster sizing guide.
Segments are flushed to seal segments for indexing. By default, a growing segment is flushed when its size reaches 110MB, based on 512MB*0.23 = 110MB. In most cases, there is no need to change the sealProportion.
For fast-changing data, use Milvus >=2.3.4 for faster searches on growing segments. The default parameters for fast indexing are defined in the v2.3.4 milvus.yaml.
| Task | Documentation link | Notes |
| Increase segment size | Configure the Data Coordinator | Default size: 512MB Please keep in mind that you need to restart the cluster to adopt the new value. These are cluster-level settings, any changes here apply to every collection on your cluster. |
Summary
Both sharding and partitioning optimize performance but for different operations. Sharding evenly distributes data across different Data Nodes for faster write speeds. Partitioning optimally places related data on the same Query Node to minimize cross-node communication for faster targeted reads.
Partitioning can be Automatic or Manual. Logical multi-tenants is a use case for Manual partitions; otherwise, Automatic partitioning is recommended, letting the Milvus system handle query optimization automatically.
Segments are in the intersection of shards and partitions and are the smallest Milvus unit for load balancing. The default segment size is 512 MB, and it should only be adjusted if you have a large machine that can fit all your data in memory on a single node.
Reference Links
Engineering Deep Dive into Milvus Architecture:
Overview of Milvus Architecture
Data Insertion and Data Persistence in a Vector Database
Building a Vector Database for Scalable Similarity Search
Collections docs page about specifying num_shards and partitions: https://milvus.io/docs/create_collection.md
Example specifying partition key values during Search:
https://docs.zilliz.com/docs/use-partition-key
Specify the number of Data Nodes and Query Nodes in cluster configuration:
https://milvus.io/docs/scaleout.md
Specify segment size in cluster configuration:
https://milvus.io/docs/configure_datacoord.md#dataColor segment maxSize
Cluster sizing guidelines:
https://milvus.io/tools/sizing
Cluster fast indexing configuration:
https://github.com/milvus-io/milvus/blob/master/configs/milvus.yaml
GitHub Milvus project (give our Milvus project a star!):
https://github.com/milvus-io/milvus
 Christy Bergman
Christy BergmanChristy Bergman is a passionate Developer Advocate at Zilliz. She previously worked in distributed computing at Anyscale and as a Specialist AI/ML Solutions Architect at AWS. Christy studied applied math, is a self-taught coder, and has published papers, including one with ACM Recsys. She enjoys hiking and bird watching.
- Sharding - for distributed data writing
- Partitioning - for targeted data reading
- Segments
- Summary
- Reference Links
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Smarter Autoscaling in Zilliz Cloud: Always Optimized for Every Workload
With the latest upgrade, Zilliz Cloud introduces smarter autoscaling—a fully automated, more streamlined, elastic resource management system.

Beyond PGVector: When Your Vector Database Needs a Formula 1 Upgrade
This blog explores why Postgres, with its vector search add-on, pgvector, works well for smaller projects and simpler use cases but reaches its limits for large-scale vector search.

Vector Databases vs. NewSQL Databases
Use a vector database for AI-powered similarity search; use a NewSQL database for scalable transactional workloads requiring strong consistency and relational capabilities.