




Exploring Multimodal Embeddings with FiftyOne and Milvus
What’s the first step to building a multimodal retrieval augmented generation (RAG) app? Getting multimodal vector embeddings. In some ways, saying an embedding is multimodal is a misnomer. There are many ways to work with multiple modalities within vectors, but we focus on vector embeddings produced by multimodal models for this tutorial.
In this piece, we cover:
- What Does “Multimodal” Mean?
- How Does Milvus Handle Multimodal Embeddings?
- Examples of Multimodal Models
- Using FiftyOne and Milvus for Multimodal Embedding Exploration
- Multimodal Embedding Exploration for CIFAR 10 via FiftyOne and CLIP
- How Can We Further Customize FiftyOne for Data Exploration with Milvus?
- Summary of Exploring Multimodal Embeddings with FiftyOne and Milvus
What Does “Multimodal” Mean?
When discussing "multimodal," we refer to the models' abilities. Both the large language model/foundational model and the embedding model in a RAG stack can be multimodal. We explore multimodal embeddings from an open-source model for this example. How do we get a vector embedding? Vector embeddings come from the second to last layer of an embedding model.
This is because each layer of the model learns some information about the input, and the last layer makes a prediction. Since we don't want a prediction but rather to be able to work with a numerical representation of the data, we cut off the last layer and take the output from the second to the last layer, which contains all of the information the model has learned. We use FiftyOne to facilitate the exploration and Milvus to hold the vectors.
How Does Milvus Handle Multimodal Embeddings?
The neat thing about multimodal embeddings, or vector embeddings in general, is that they do not need special treatment. Vector embeddings are just numerical representations of a specific type of input data. Regarding the actual data type, vector embeddings are just vectors, a list of numbers. Milvus handles all of these vectors in the same fashion.
Vectors can be dense or sparse. Dense vectors are typically made up of floats and are produced by deep learning models, an example of which we’ll see today. Sparse vectors are sometimes called binary vectors and are made up of 0s and 1s. Something important to keep in mind when working with vectors is that only vectors of the same size or dimensionality can be compared. Moreover, even when they are the same size, embeddings generated by different models cannot necessarily be compared apples-to-apples.
Multimodal embeddings are especially tricky. Most deep learning models are designed to deal with one type, or modality, of data. This could be images, text, video, or something more bespoke. However, because these models are only optimized for one type of data, they cannot process or represent other modalities — a model trained to accept text input typically won’t be able to accept images.
Multimodal models are trained to interact with multiple types of data. For our purposes, we are interested in multimodal models that produce vector embeddings for multiple data modalities. In particular, we are interested in models that embed textual and visual data in the same space so that the dimensions of the generated vectors are the same and we can sensibly treat them similarly.
The most common multimodal model for generating text and image embeddings is CLIP, from OpenAI, which uses contrastive techniques to align the image embeddings of photographs with the text embeddings of their captions.
Using FiftyOne and Milvus for Multimodal Embedding Exploration
FiftyOne is the leading open-source library for curation and visualization of unstructured data. FiftyOne integrates with multiple vector store backends, with Milvus being particularly well suited for flexibly working with large, growing datasets. In this example, we use Milvus Lite, an embedded version of Milvus that you can start right in your notebook. For an in-depth look, check out this end-to-end guide to Milvus Lite.
Before diving into the code, ensure all the proper prerequisites are installed. You must run pip install milvus pymilvus fiftyone torch torchvision. The first step is to spin up our Milvus Lite instance. We can do this by importing default_server from Milvus and calling the start() function.
from milvus import default_server
default_server.start()
Now that we have an instance of Milvus ready to go, we can link it to FiftyOne for vector embedding comparisons. We import FiftyOne, the FiftyOne Brain, and the FiftyOne Zoo and load the test split of the CIFAR 10 dataset.
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
# Step 1: Load your data into FiftyOne
dataset = foz.load_zoo_dataset("cifar10", split="test")
We will use the CLIP model to embed our images in this example. Then, we’ll use the compute_similarity function from the FiftyOne Brain. This function first generates embeddings for our samples using a specified model, then creates a Milvus collection from these embeddings and attaches it to the FiftyOne sample collection. With FiftyOne and vector search backends, you can generate a similarity index over images, object patches, and even video frames!
The compute_similarity function takes in the FiftyOne dataset and various named parameters. The brain_key is a unique key that FiftyOne uses to keep track of runs. The backend key tells FiftyOne which vector database backend to use, and the model takes in the name of the model FiftyOne will leverage to create embeddings.
fob.compute_similarity(
dataset,
brain_key="clip_sim",
backend="milvus",
model="clip-vit-base32-torch",
)
The last step we look at here before exploring is to use FiftyOne to launch the FiftyOne App. We pass the dataset and set auto=False so the window doesn’t open in the notebook but can be accessed through a Chrome tab on localhost:5151.
session = fo.launch_app(dataset, auto=False)
Multimodal Embedding Exploration for CIFAR 10 via FiftyOne and CLIP
It’s time to explore! Let’s look at how to use text to find semantically similar images. Let’s look at three words: Ferrari, Mustang, and Pony.
Our first search for a Ferrari is a car.
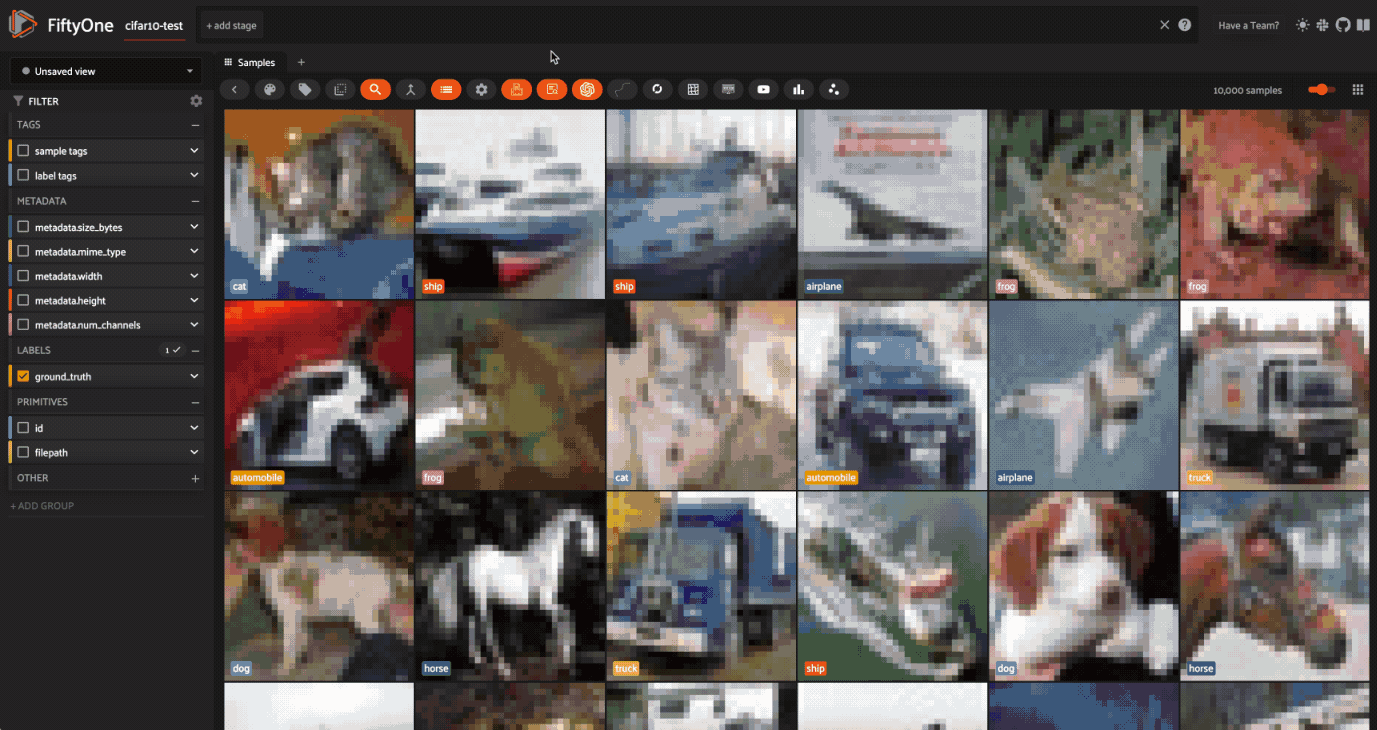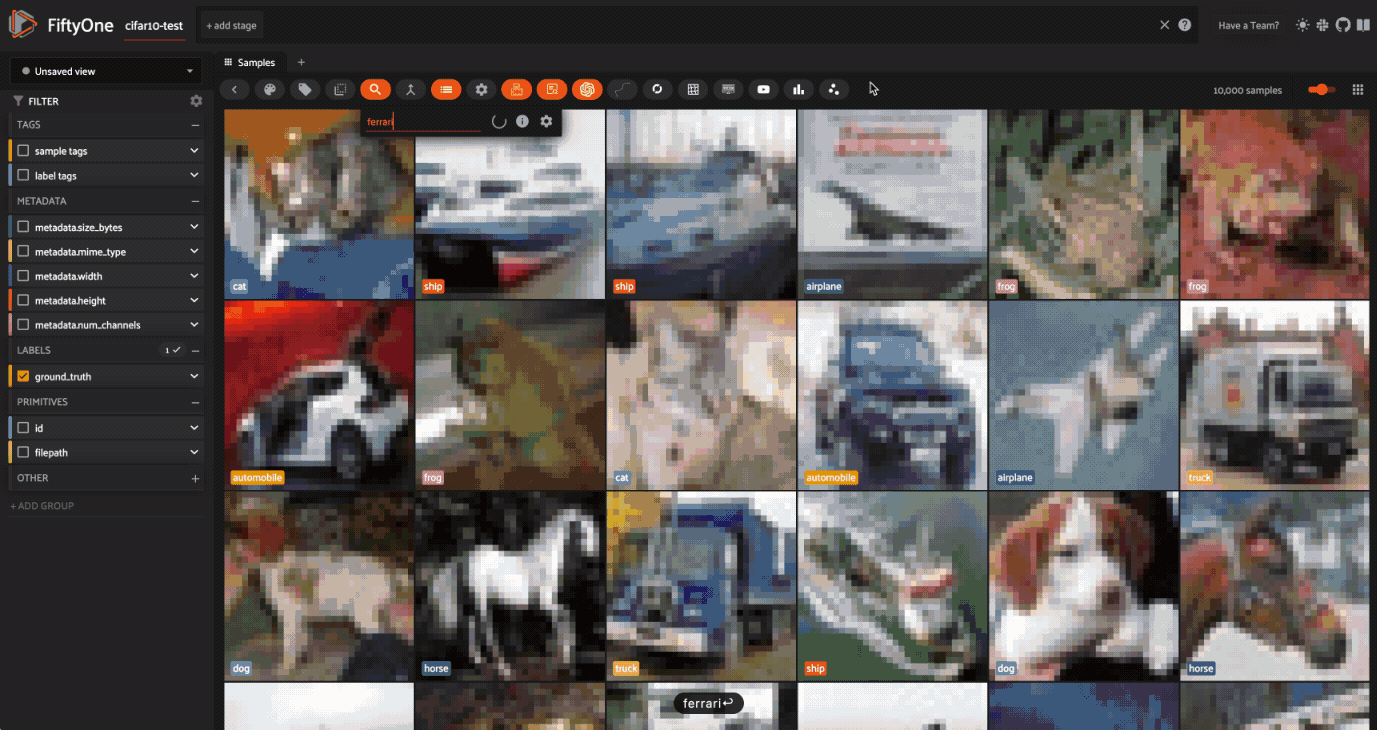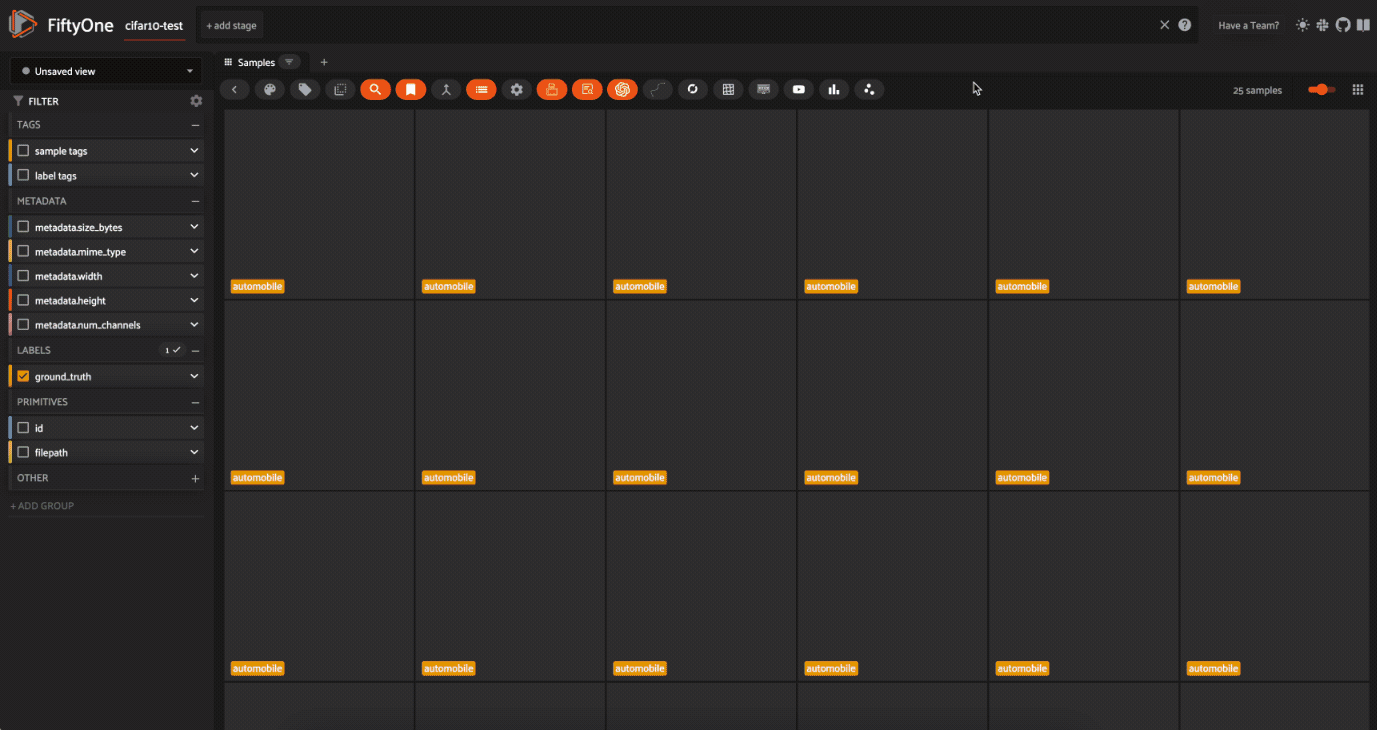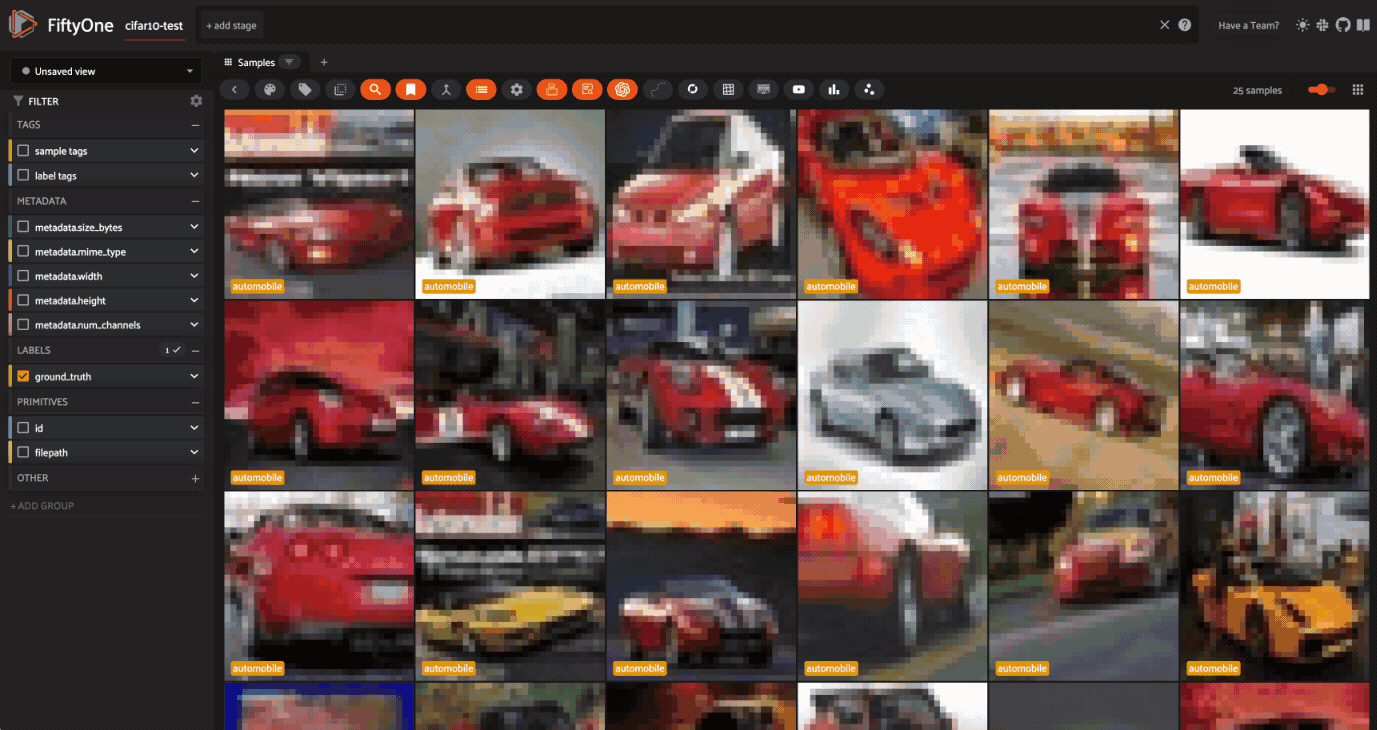
The next search, “pony”, clearly gives us pictures of horses.
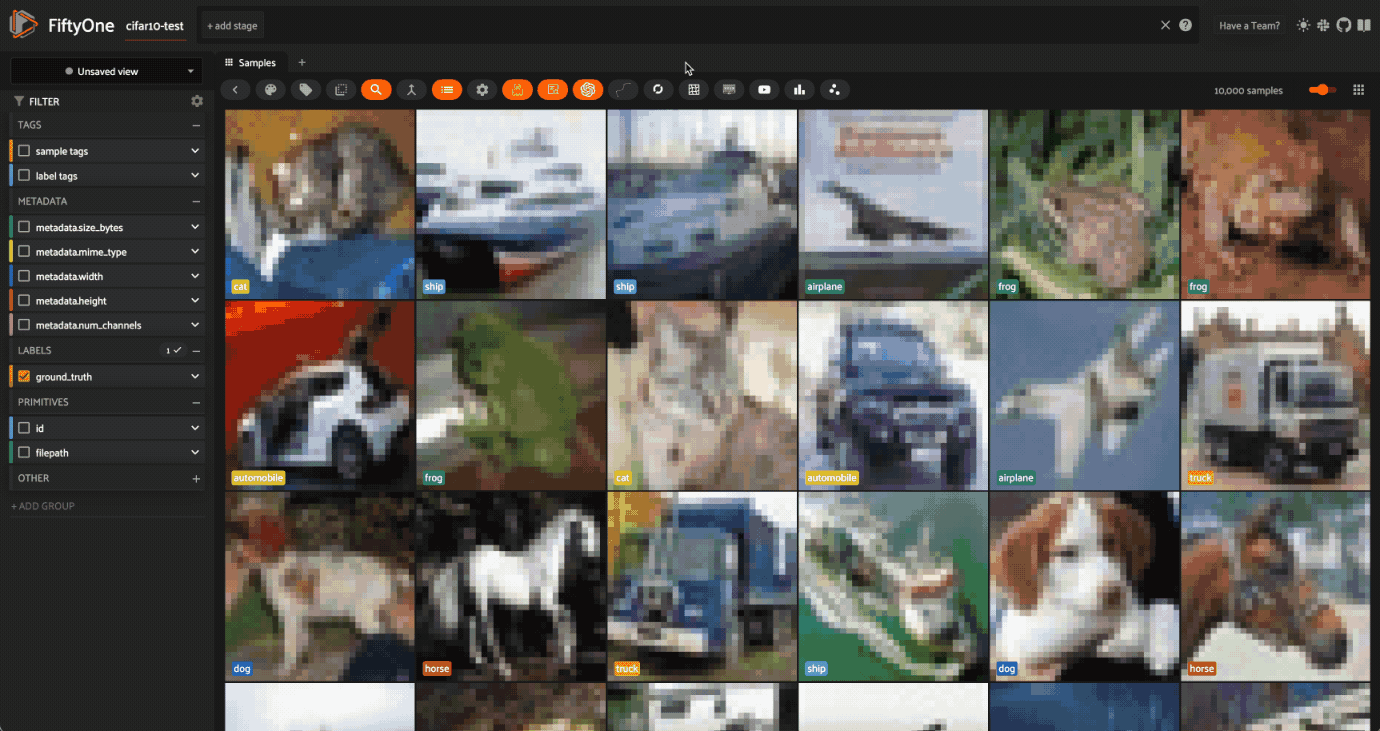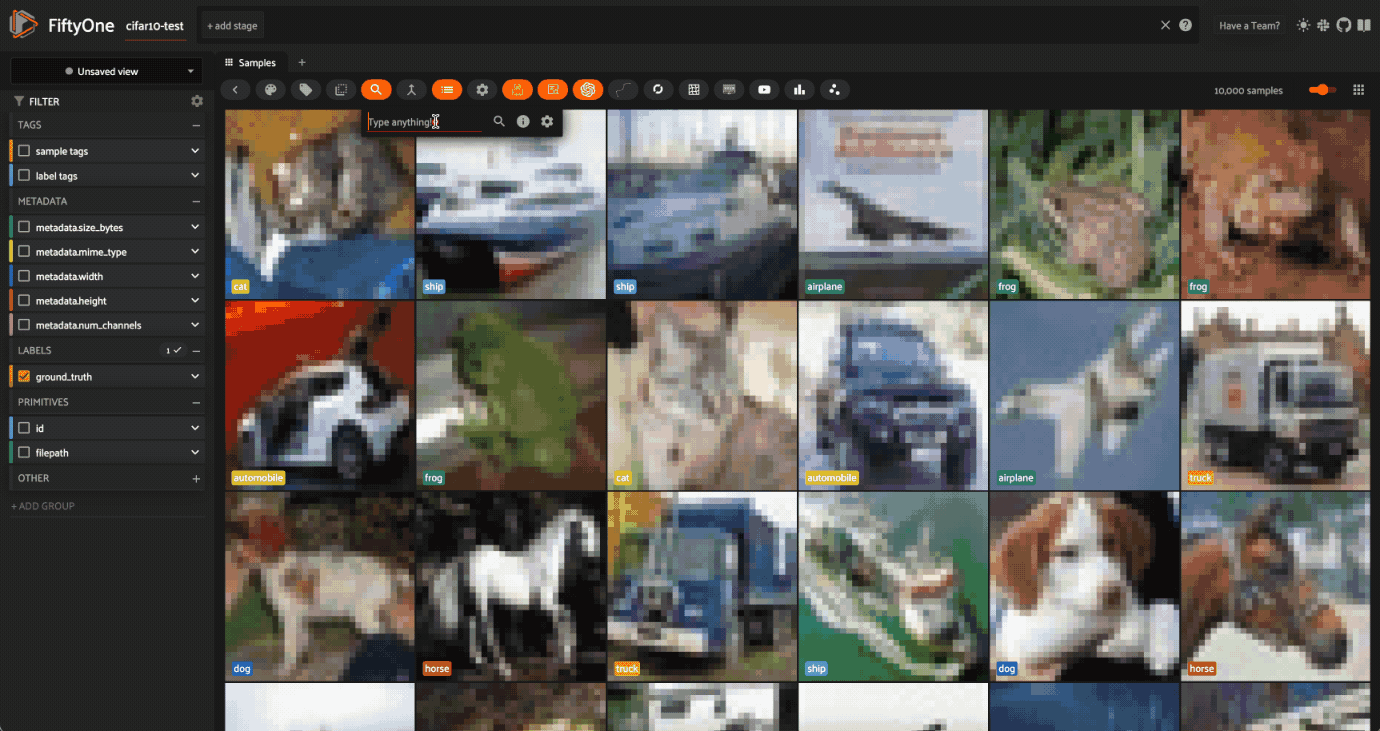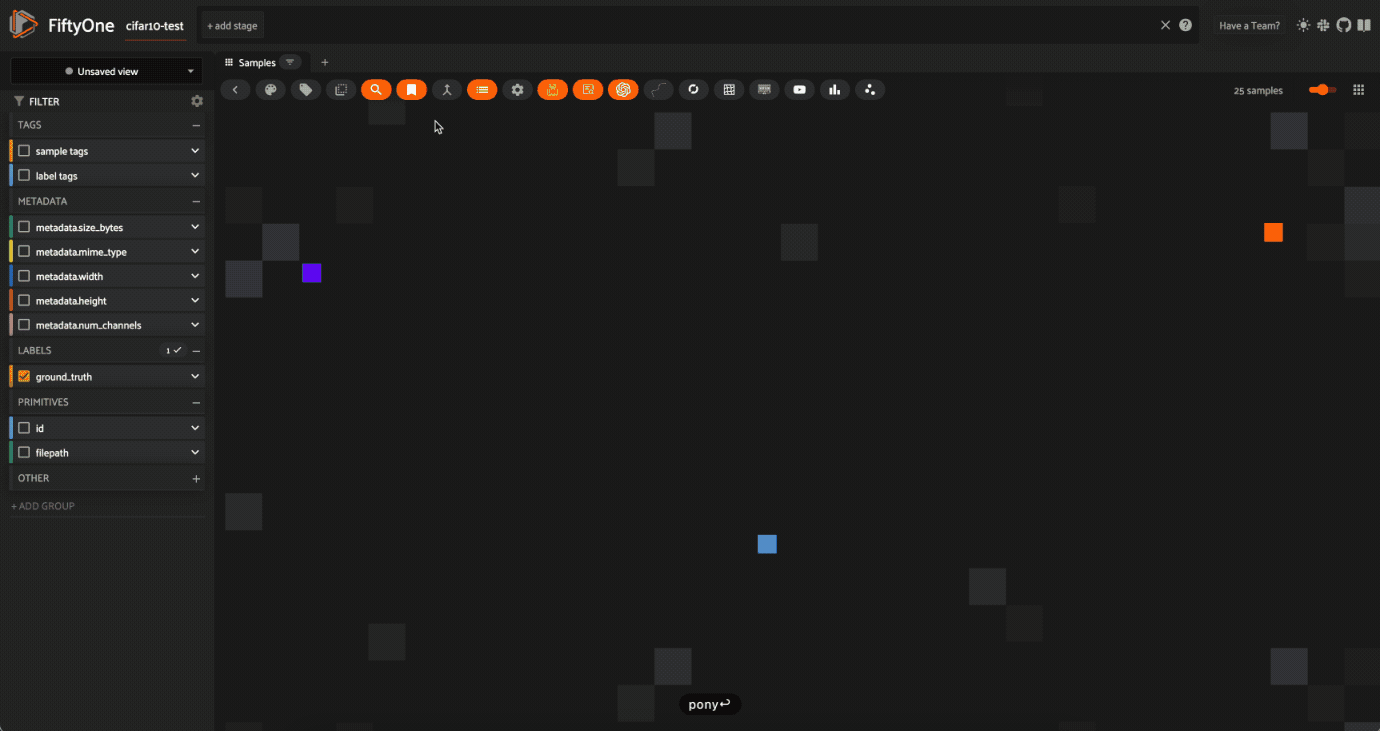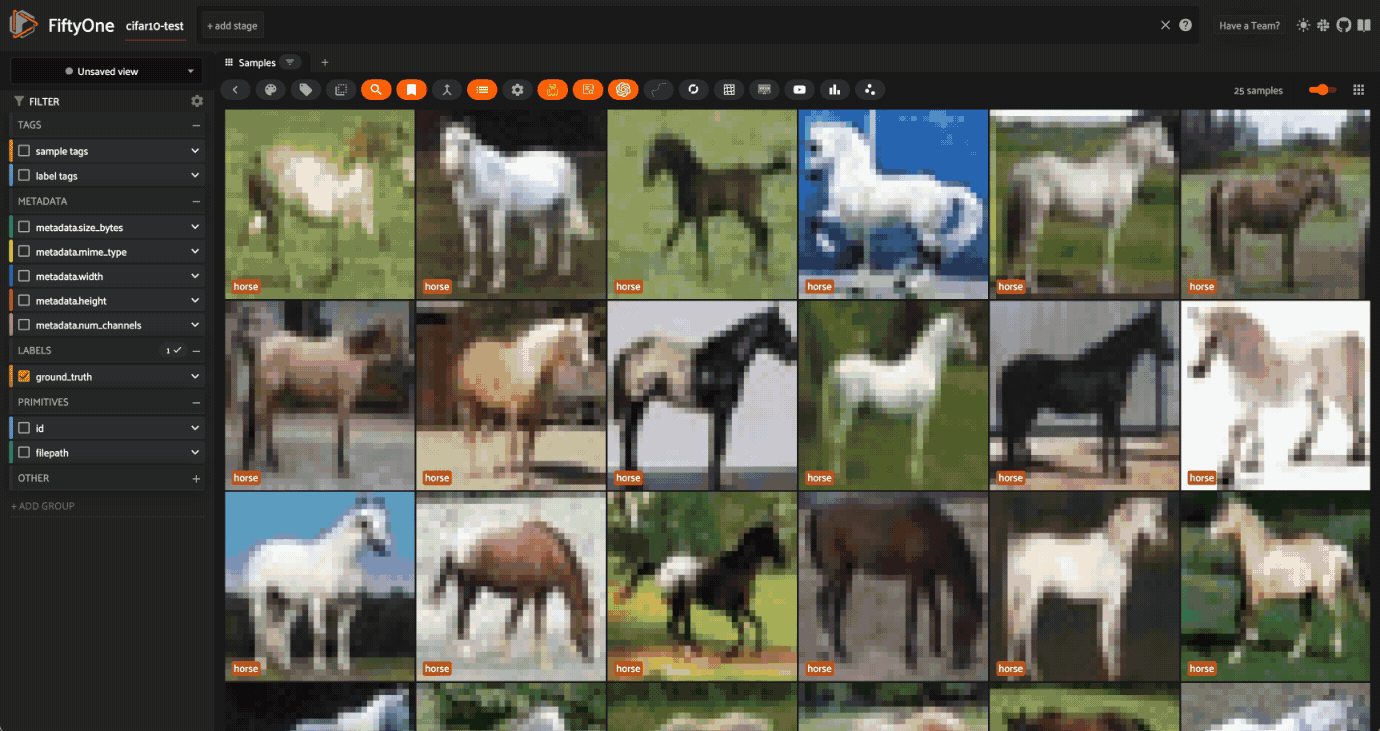
But, if we search for “mustang”, we get a mix.
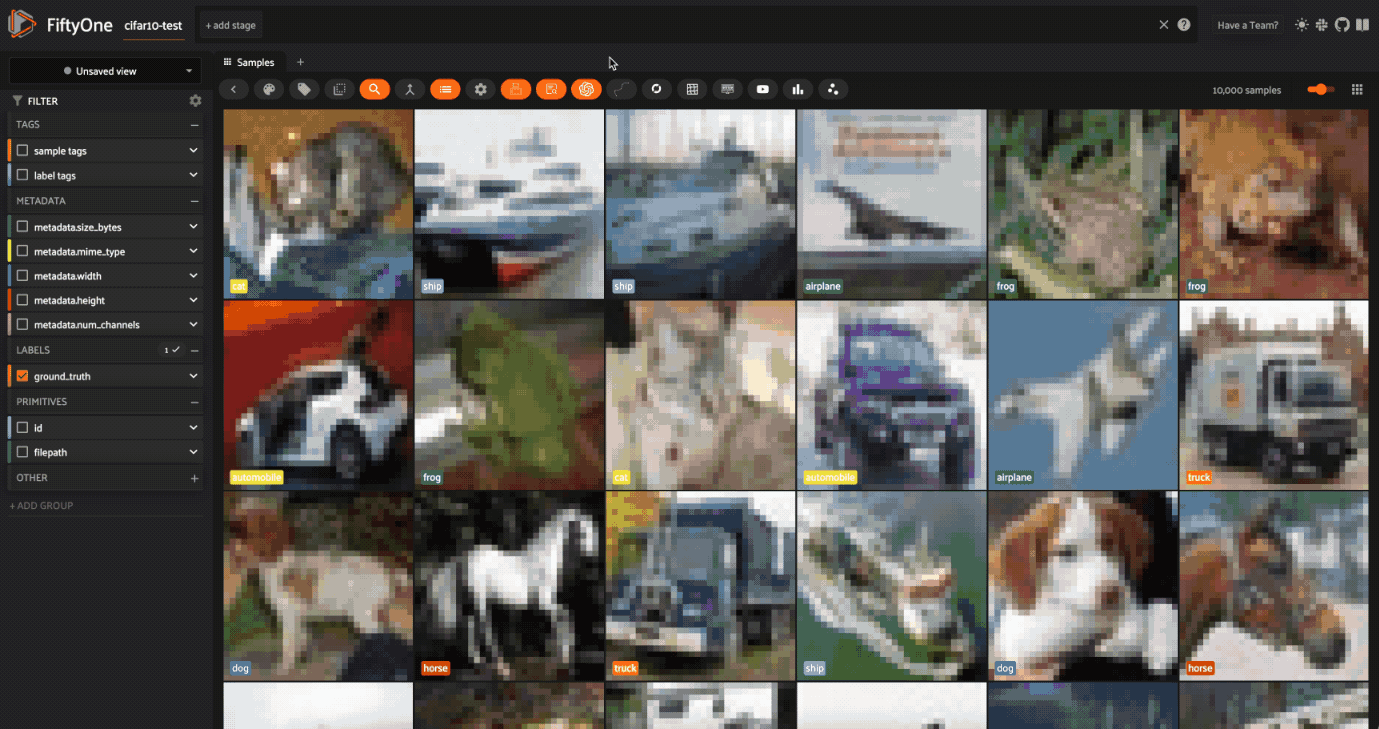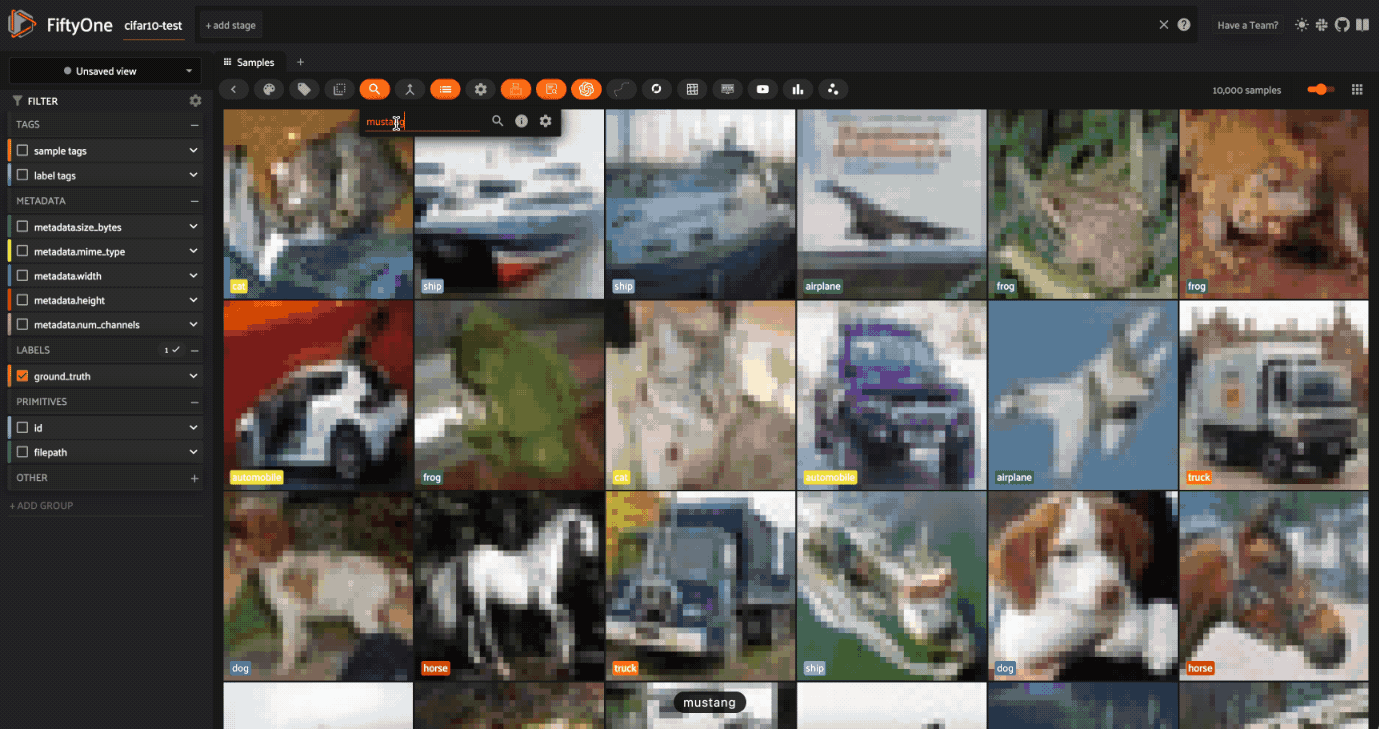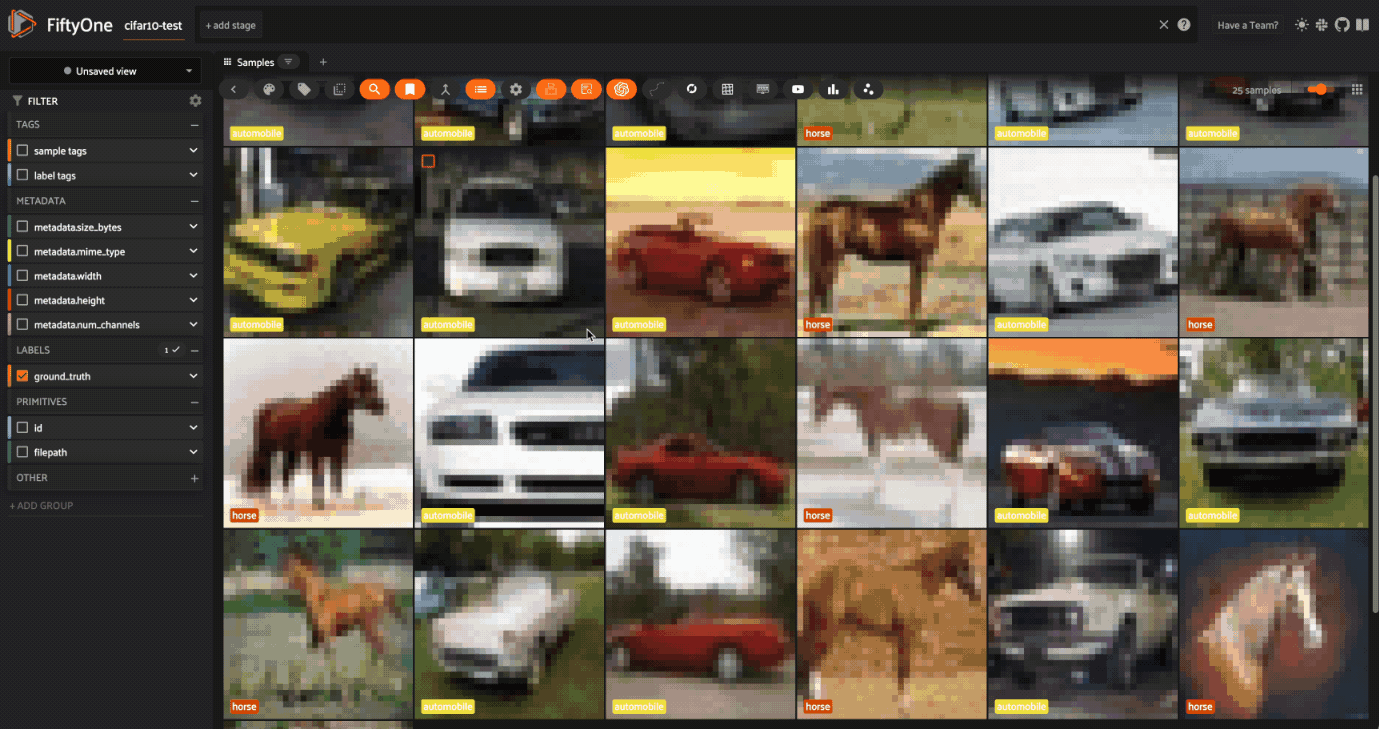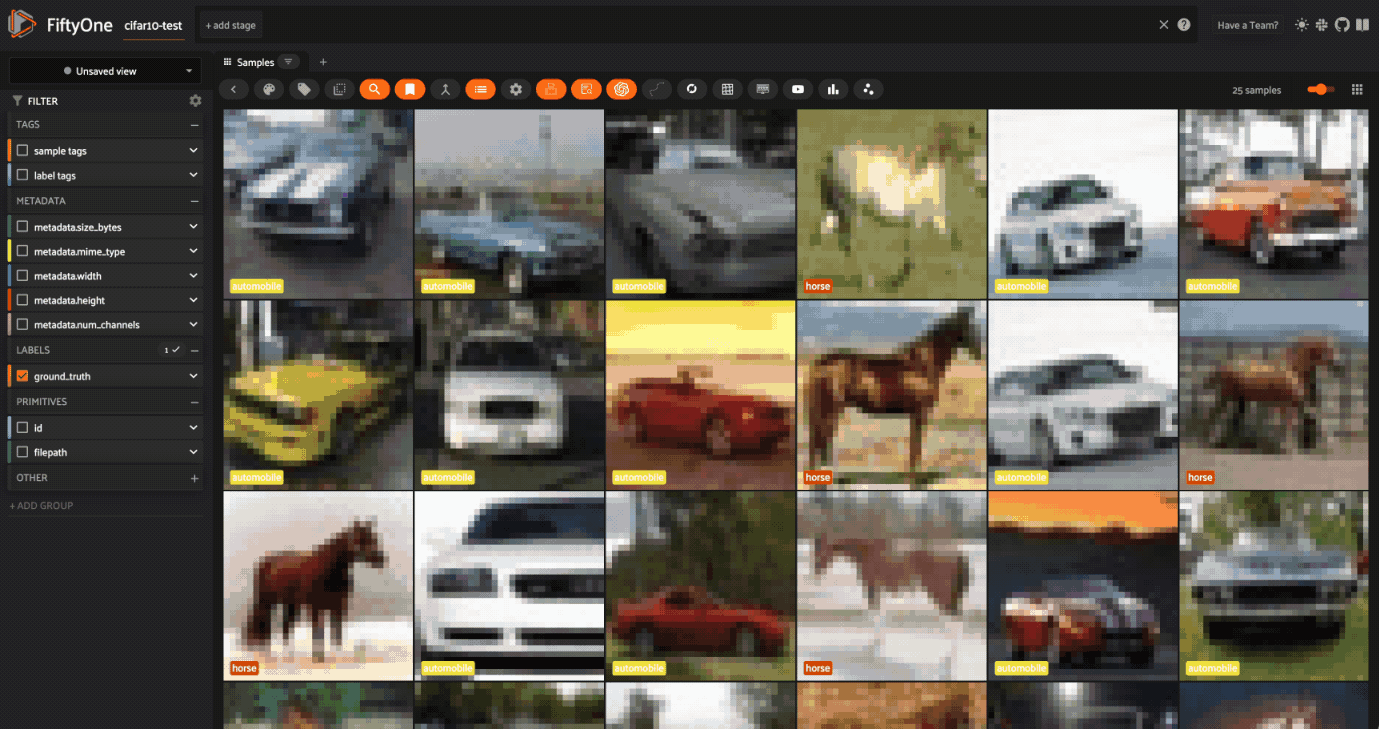
This step shows that it’s essential to evaluate your dataset and understand the context of your data!
How Can We Further Customize FiftyOne for Data Exploration with Milvus?
To set Milvus as the default “backend” for vector search in FiftyOne, we can source the following environment variable:
export FIFTYONE_BRAIN_DEFAULT_SIMILARITY_BACKEND=milvus
For any given index, we can also specify the collection name, what consistency level to use, and what metric to use to assess similarity. Here’s a second similarity index that uses a Euclidean metric and Bounded consistency:
fob.compute_similarity(
dataset,
brain_key="clip_euclid",
model="clip-vit-base32-torch",
metric="euclidean",
consistency_level="Bounded"
)
If we have multiple similarity indexes on a dataset, we can select which one we want to use in the app by clicking on the gear icon next to the search bar under the magnifying glass, and choosing the index by its brain key:
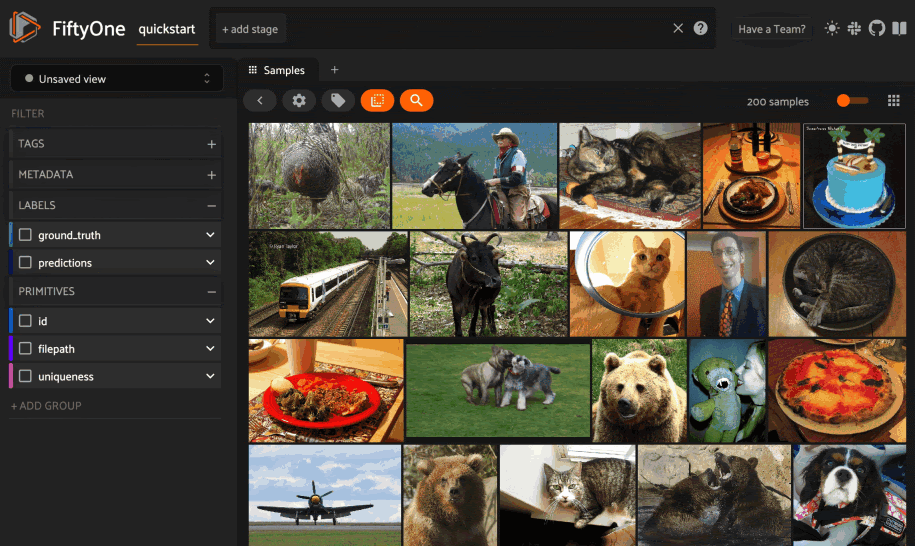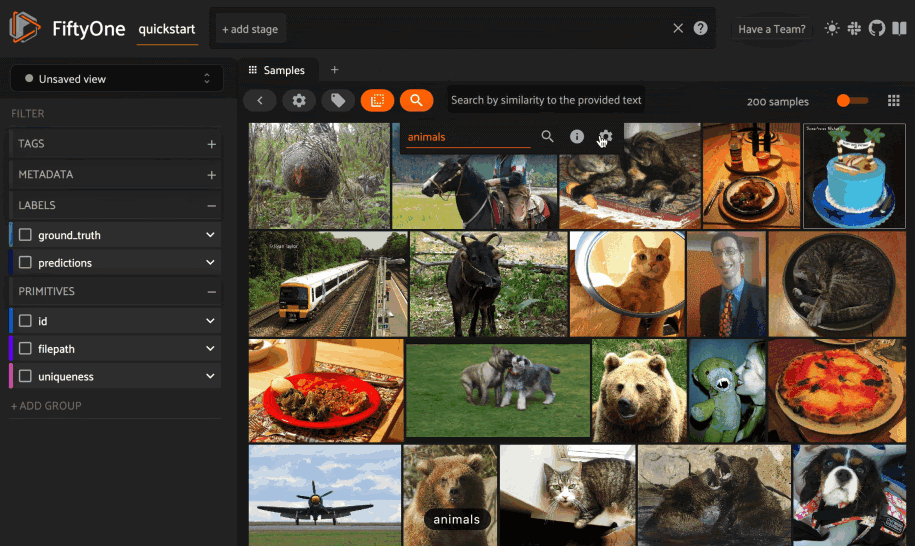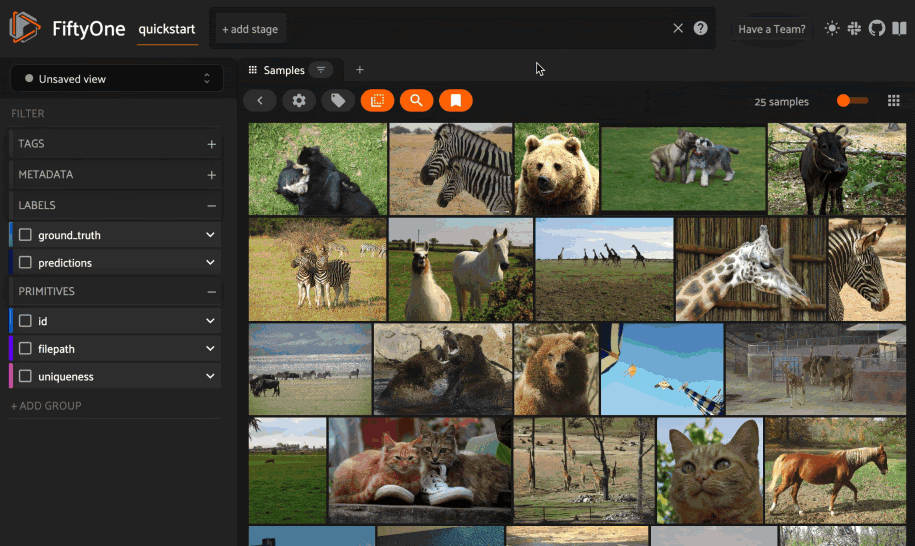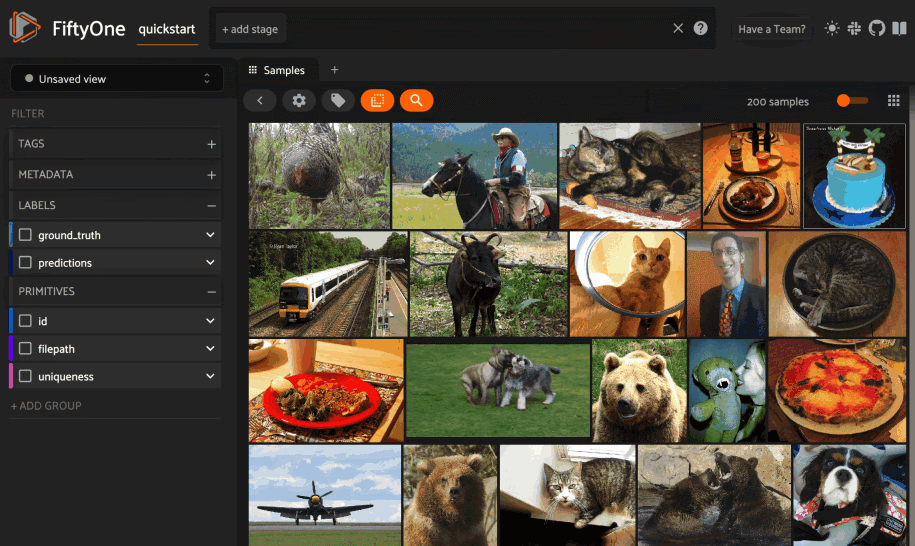
We can also use a different multimodal model to generate our image and text embeddings. In fact, we can do so with any OpenCLIP model (we will have a better link here in a few days), or any zero-shot prediction model from Hugging Face’s Transformers library. As an example, here is an index constructed with AltCLIP:
!pip install transformers
fob.compute_similarity(
dataset,
brain_key="altclip",
model="zero-shot-classification-transformer-torch",
name_or_path="BAAI/AltCLIP",
)
Summary of Exploring Multimodal Embeddings with FiftyOne and Milvus
This post explored how multimodal embeddings work with FiftyOne and Milvus. We showed how you can explore a popular multimodal model - CLIP - on a popular dataset - CIFAR 10. You use CLIP to create the embeddings of the input data, Milvus to store the embeddings of the multimodal data (sometimes termed “multimodal embeddings”), and FiftyOne to explore the embeddings.
Using CLIP like this allows you to search through images with text. With that, we explored the space using natural language to compare images of words that may have different meanings in different contexts. We looked at how “pony” is clearly a horse, “Ferrari” is clearly a car, but “mustang” could be either.

Keep Reading

Stop Building AI Data Infra for the Wrong Stage
Learn how AI data infrastructure should evolve from prototype to enterprise scale, and when Vector Lakebase becomes the right architecture for AI apps.

Zilliz Cloud Introduces Advanced BYOC-I Solution for Ultimate Enterprise Data Sovereignty
Explore Zilliz Cloud BYOC-I, the solution that balances AI innovation with data control, enabling secure deployments in finance, healthcare, and education sectors.

Proactive Monitoring for Vector Database: Zilliz Cloud Integrates with Datadog
we're excited to announce Zilliz Cloud's integration with Datadog, enabling comprehensive monitoring and observability for your vectorDB deployments.