




Mixture-of-Agents (MoA): How Collective Intelligence Elevates LLM Performance
The rapid advancement of large language models (LLMs) is like a double-edged sword. On one hand, having numerous state-of-the-art LLMs gives us many options to solve our use cases. On the other hand, this abundance of choices can be overwhelming.
Furthermore, since different organizations and companies develop these LLMs, they are trained on different datasets, resulting in LLMs with varied specialties. Some LLMs excel at solving mathematical problems, while others are better suited for coding tasks. This diversity makes it challenging to select the most suitable LLM for our needs, especially when dealing with multi-domain use cases.
In this article, we will explore one method to address this challenge: the Mixture-of-Agents (MoA) approach, which combines several LLMs with different specialties into a single system. So, without further ado, let's start with some motivations behind MoA.
The Motivation Behind Mixture-of-Agents (MoA)
The rapid advancement of LLMs has blessed us with numerous options when choosing the best model for our use case. However, the no-free-lunch theorem still applies to LLMs - no single model performs equally well across all tasks. Different LLMs excel at different tasks due to their varied training data. Therefore, selecting an LLM that best suits the specific problem we're trying to solve is crucial.
A challenge arises when we’re dealing with multi-domain use cases that require expertise from multiple LLMs. This raises an important question: Can we collectively use multiple LLMs to harness their individual strengths and create a more capable, robust system? The Mixture-of-Agents (MoA) method attempts to answer this question.
What is MoA?
In short, Mixture-of-Agents (MoA) is a framework where multiple specialized LLMs, or "agents," collaborate to solve tasks by leveraging their unique strengths.
The concept behind MoA is straightforward: we combine several LLMs with different strengths and capabilities into a single system. When a user submits a query, each LLM in the system generates a response. Then, a designated LLM at the end synthesizes all these responses into one coherent answer for the user, as shown in the visualization below:
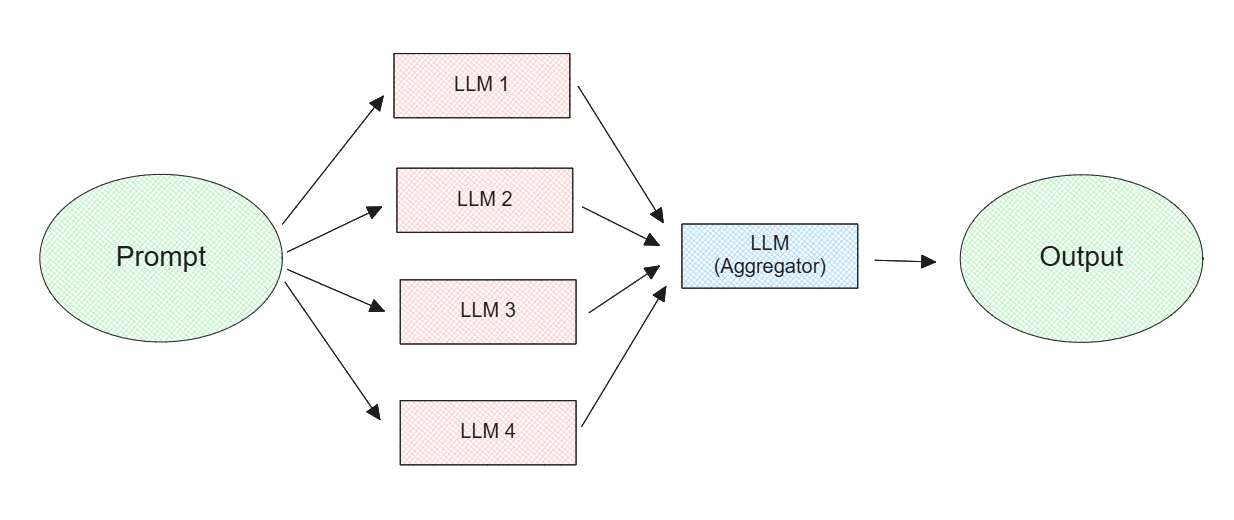 Figure: Mixture-of-Agents concept
Figure: Mixture-of-Agents concept
Figure: Mixture-of-Agents concept.
While the MoA concept is simple, it’s surprisingly effective. The authors of the MoA paper discovered that LLMs tend to generate higher-quality outputs when presented with responses from other LLMs.
This phenomenon was demonstrated through benchmark testing on the AlpacaEval 2.0 dataset using six different LLMs, including Qwen, Wizard, Mixtral, Llama 3, and dbrx. The authors compared LLMs’ response quality under two conditions: using direct input prompts versus using responses from other models. They measured quality using the Length Controlled (LC) win rate metric, which evaluates output quality independently of factors like response length that can significantly influence evaluation results.
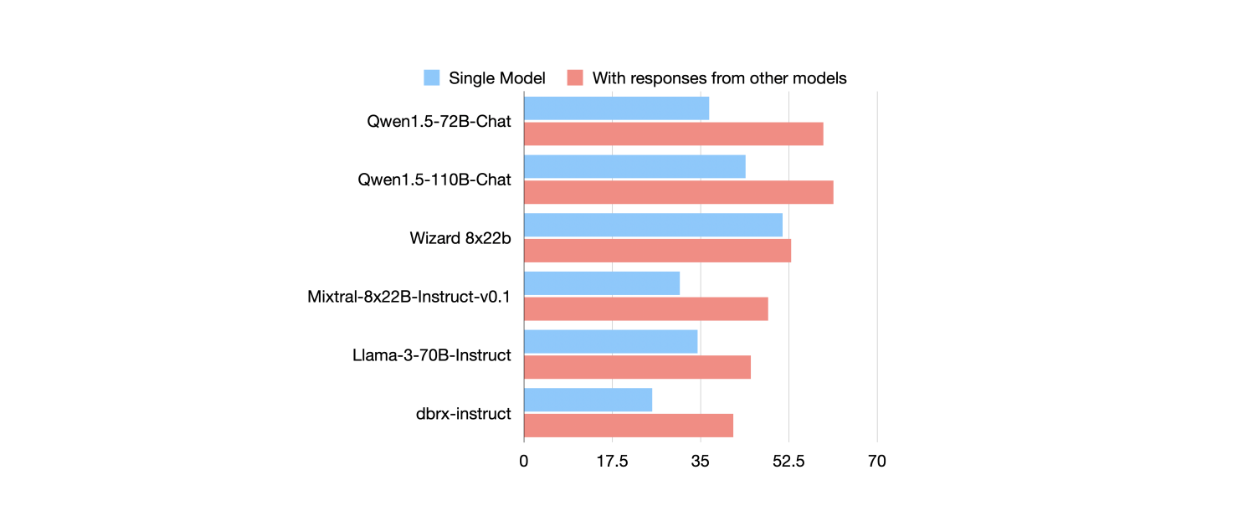 Figure: AlpacaEval 2.0 LC win rates comparison of each LLM from two different inputs: directly from the user prompt and from the output of other models
Figure: AlpacaEval 2.0 LC win rates comparison of each LLM from two different inputs: directly from the user prompt and from the output of other models
Figure: AlpacaEval 2.0 LC win rates comparison of each LLM from two different inputs: directly from the user prompt and from the output of other models. Source.
The results were consistent across all six LLMs: they achieved better LC win rate scores when working with outputs from other LLMs compared to processing input prompts directly. Based on these findings, the authors developed the MoA concept, which we'll explore in detail in the next section.
The Fundamental of Mixture-of-Agents (MoA)
MoA integrates several LLMs into one system to iteratively improve response generation quality.
The system consists of multiple layers, each containing several LLMs of different sizes and capabilities. The LLMs in the first layer independently generate responses to the input prompt. These responses are then presented to the LLMs in the second layer as inputs, which generate their own independent responses. This cycle continues through subsequent layers until reaching the final layer. At the end, a single LLM synthesizes the responses from the last layer into a final response for the user.
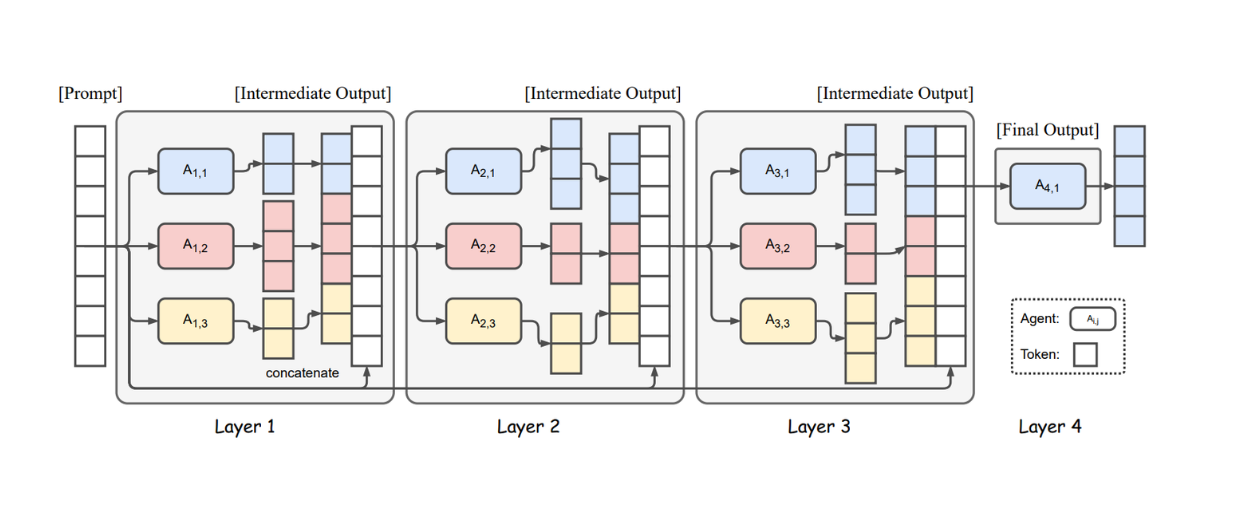 Figure: Illustration of the Mixture-of-Agents Structure
Figure: Illustration of the Mixture-of-Agents Structure
Figure: Illustration of the Mixture-of-Agents Structure. Source.
Based on this concept, the LLMs used in MoA can be classified into two categories: proposers and aggregators.
Proposers generate responses within each layer of the MoA system, contributing to the quality of the final response.
Aggregators collect all responses from the LLMs in the last layer and synthesize them into one high-quality response for the user.
Given the different capabilities and specialties of various LLMs, we need to pay attention when selecting which models to use as proposers and aggregators. Some LLMs excel as proposers, while others perform better as aggregators, and some can effectively serve both roles. We'll discuss detailed results in the next section.
Since MoA can comprise many layers, the same LLM can be reused as a proposer either within the same layer or across different layers. For example, we can build an MoA system with 5 layers, each containing 5 LLMs, and use the Llama3 70B model in all of them as a single-proposer.
Once the proposers in the last layer generate their responses, all outputs are structured into a single, coherent prompt for the aggregator to generate the final response.
Here's an example of such a prompt:
 Figure: Prompt example to synthesize and aggregate responses from several LLMs
Figure: Prompt example to synthesize and aggregate responses from several LLMs
Figure: Prompt example to synthesize and aggregate responses from several LLMs. Source.
While this concept is similar to the Mixture-of-Experts (MoE) approach used in traditional neural networks, there's a key difference. In traditional neural networks, MoE layers are implemented as several sub-networks within a single model's architecture. Therefore, once we have new data that deviates a lot from training data, we need to fine-tune the weights of each MoE layer to optimize the performance.
Meanwhile, MoA relies entirely on prompting. Therefore, there's no need to fine-tune the LLMs to improve the system's overall performance. This offers greater flexibility, as we can freely choose different LLMs as proposers or aggregators, regardless of their size and architecture. This also means that if we have a new state-of-the-art model in the future, we can implement this model directly into our MoA system as a proposer or an aggregator.
MoA also offers competitive performance and serves as an effective alternative to other multi-agent methods designed to leverage diverse LLM capabilities, such as:
LLM ranker: this method uses multiple LLMs as proposers to independently generate responses to input queries. A standalone LLM then selects the best response from among these proposers.
RouteLLM: this method uses a trained router function to analyze query complexity and determine which LLMs should process the input.
Evaluation Results on Benchmark Datasets
MoA has been evaluated on three benchmark datasets: AlpacaEval 2.0, MT-Bench, and FLASK.
Three different variants of MoA were tested:
MoA: A three-layer system with six proposers per layer (Qwen1.5-110B-Chat, Qwen1.5-72B-Chat, WizardLM-8x22B, LLaMA-3-70B-Instruct, Mixtral-8x22B-v0.1, dbrx-instruct) and Qwen1.5-110B-Chat as the aggregator.
MoA with GPT-4o: The same setup as above but using GPT-4o as the aggregator.
MoA-lite: A two-layer system using the same six proposers and aggregator as the standard MoA.
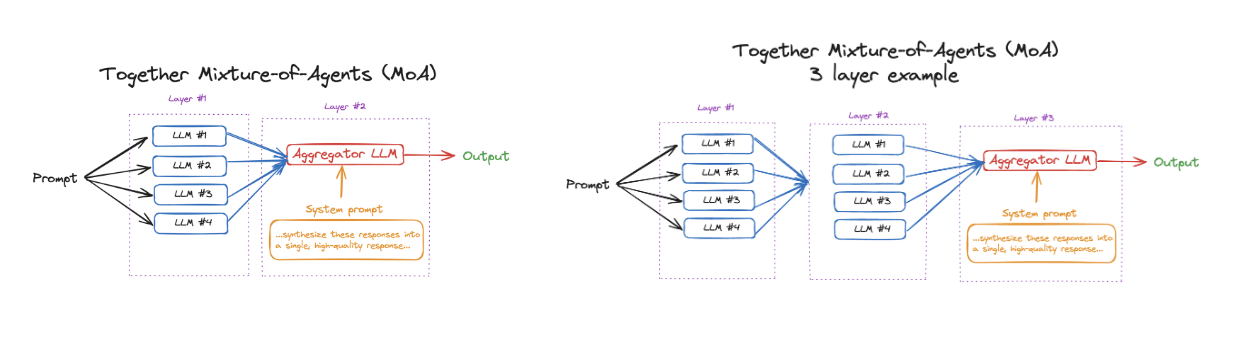 Figure: 2-layers MoA (left) vs 3-layers MoA (right)
Figure: 2-layers MoA (left) vs 3-layers MoA (right)
Figure: 2-layers MoA (left) vs 3-layers MoA (right). Source.
On the AlpacaEval 2.0 dataset, all three MoA variants outperformed the state-of-the-art model, GPT-4 Omni, by up to 8.2%. The MoA setup with GPT-4o as the aggregator achieved the highest LC win rate among the variants.
All three MoA variants also demonstrated competitive performance on the MT-Bench dataset. While the current state-of-the-art model, GPT-4 Turbo, performed exceptionally well, MoA with GPT-4o as the aggregator surpassed it. The performance comparison between MoA variants and other state-of-the-art models is shown below:
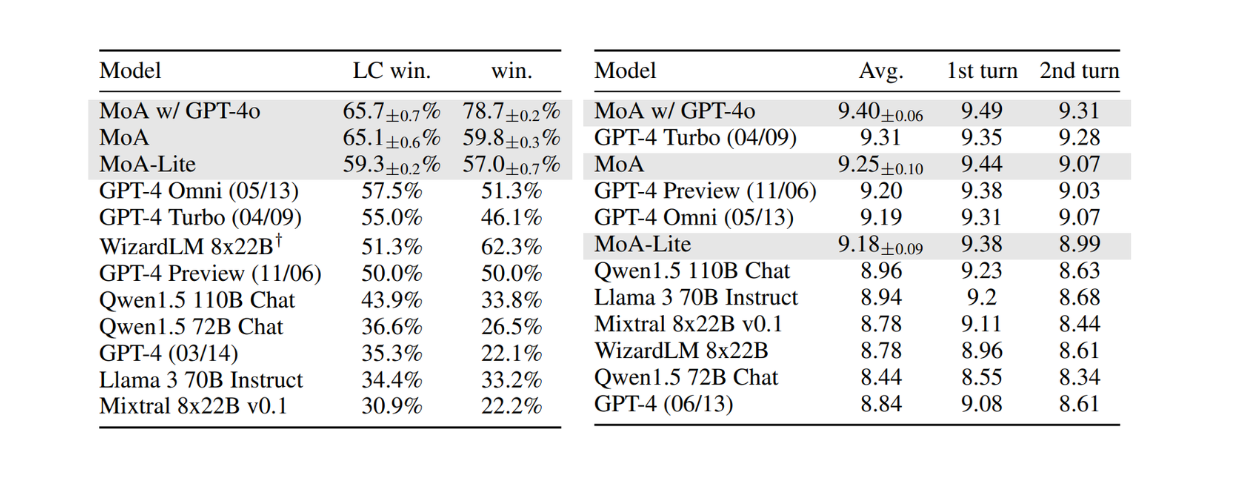 Figure: Results on AlpacaEval 2.0 (left) and MT-Bench (right)
Figure: Results on AlpacaEval 2.0 (left) and MT-Bench (right)
Figure: Results on AlpacaEval 2.0 (left) and MT-Bench (right). Source.
The FLASK dataset provides a more granular evaluation than AlpacaEval 2.0 and MT-Bench, assessing 12 aspects: robustness, correctness, efficiency, factuality, common sense, comprehension, insightfulness, completeness, metacognition, readability, conciseness, and harmlessness.
The MoA setup with Qwen1.5-110B-Chat as the aggregator outperformed GPT-4 Omni in five aspects: correctness, factuality, insightfulness, completeness, and metacognition. Meanwhile, the performance of other metrics are quite comparable to GPT-4 Omni aside from conciseness. The MoA setup showed a notable decline in conciseness, as illustrated below:
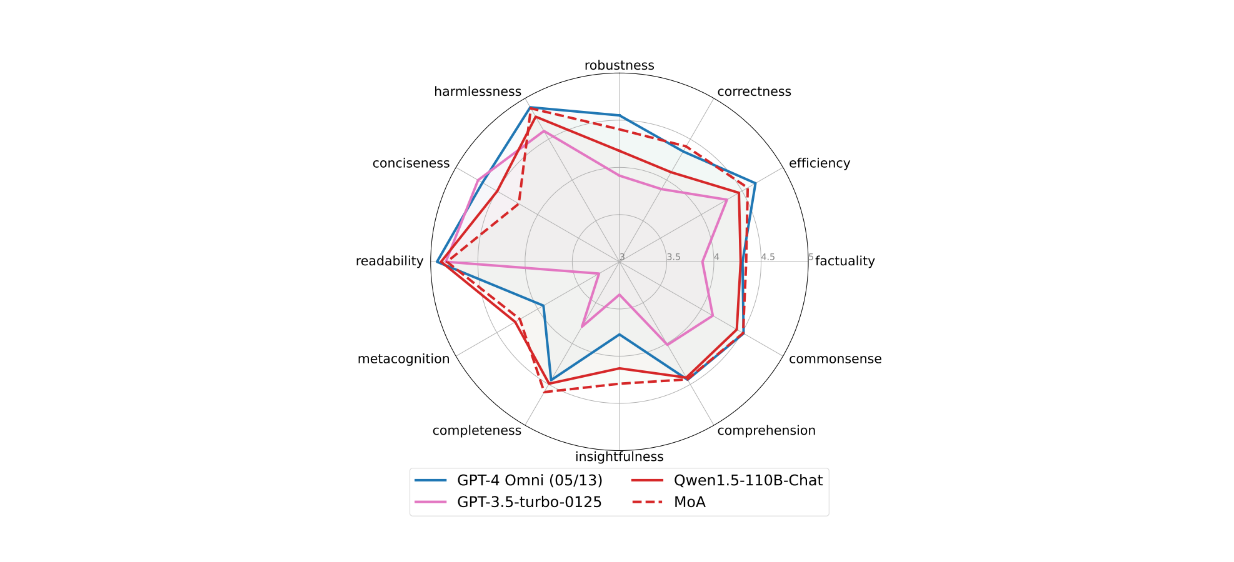 Figure: Results on FLASK
Figure: Results on FLASK
Figure: Results on FLASK. Source.
Now that we know its performance against state-of-the-art models like the GPT-4 family, it’s also interesting to see its performance against other related mixture-of-agent methods.
As mentioned in the previous section, an example of another mixture-of-agent-like method is the LLM ranker, which uses multiple LLMs (proposers) to generate independent responses to an input prompt. Instead of using an aggregator, the LLM ranker selects the best response from among the proposers.
For evaluation, both MoA and LLM ranker used the same six proposers: Qwen1.5-110B-Chat, Qwen1.5-72B-Chat, WizardLM-8x22B, LLaMA-3-70B-Instruct, Mixtral-8x22B-v0.1, and dbrx-instruct. Each proposer was tested as an aggregator for MoA, while the LLM ranker used only Qwen1.5-110B-Chat to select the best response.
In evaluations on the AlpacaEval 2.0 dataset, MoA consistently outperformed LLM rankers regardless of the aggregator used. This shows the potential of the MoA method, where the aggregator in the end doesn’t simply pick one of the responses from proposers, but rather generates an aggregation over all proposers’ responses to create a more capable and robust final response.
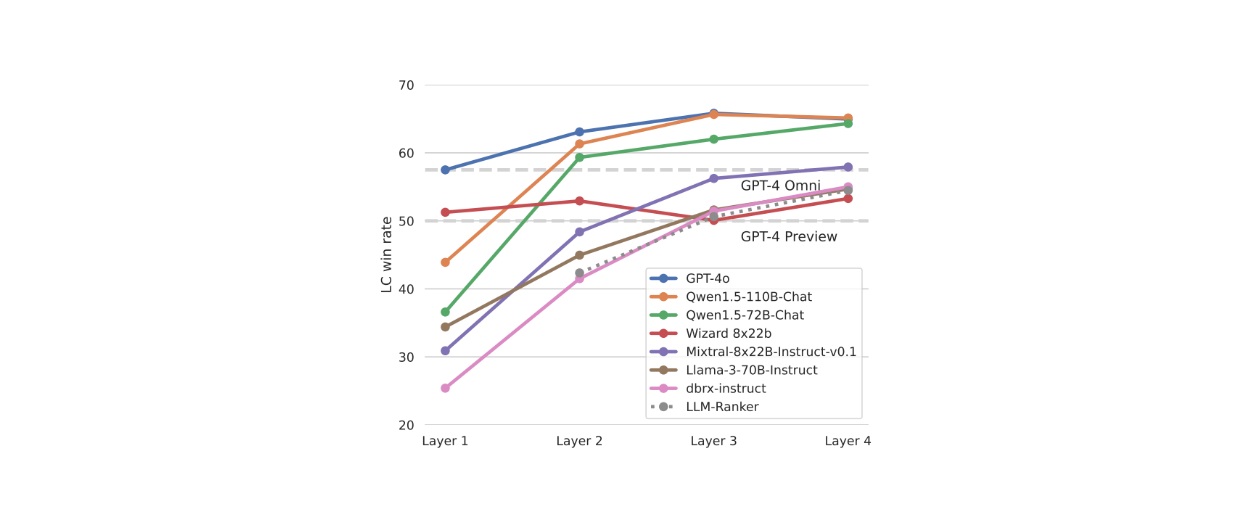 Figure: LC win rate on AlpacaEval 2.0 with different aggregators in an MoA setup with 6 proposers
Figure: LC win rate on AlpacaEval 2.0 with different aggregators in an MoA setup with 6 proposers
Figure: LC win rate on AlpacaEval 2.0 with different aggregators in an MoA setup with 6 proposers. Source.
Mixture-of-Agents (MoA) Setup Recommendations
Now that we've seen MoA's performance against the GPT-4 family using three variants with six different proposers each, two key questions arise: How does the number of proposers impact MoA's overall performance? And what happens if we use multiple identical LLMs as proposers instead of different ones?
To determine the impact of proposer count, the author of the MoA paper evaluated MoA on AlpacaEval 2.0 with varying numbers of proposers. They measured the LC win rate of 2-layer MoA configurations using 6, 3, 2, and 1 different proposers. The results indicate that more proposers help the aggregator generate more robust responses.
Furthermore, MoA setups using a single-proposer (identical LLMs as proposers) performed worse than multi-proposer configurations. This suggests that MoA benefits from having a diverse set of LLMs with different specialties rather than using one identical LLM.
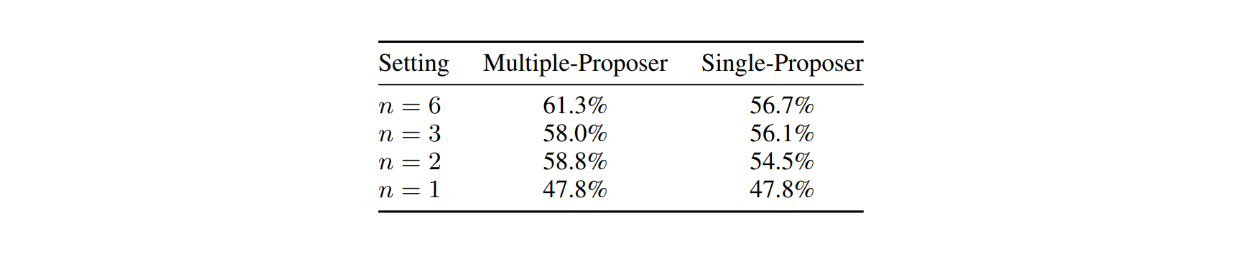 Figure: Effects of the number of proposers on AlpacaEval 2.0.
Figure: Effects of the number of proposers on AlpacaEval 2.0.
Figure: Effects of the number of proposers on AlpacaEval 2.0. Source.
Given the advantages of multi-proposer setups, it's also important to understand which LLMs work best in these configurations. Testing of six different LLMs on AlpacaEval 2.0 revealed that models like GPT-4o, Qwen, and Llama 3 are versatile enough to serve as both proposers and aggregators. However, models like WizardLM perform notably better as proposers than aggregators.
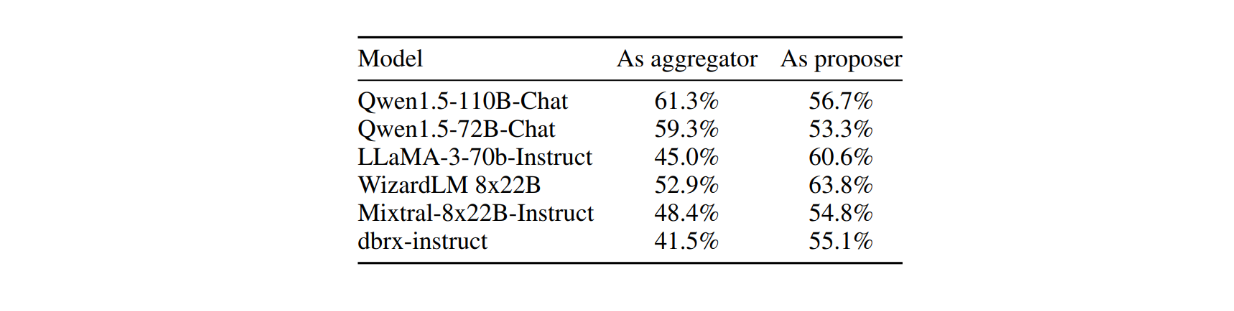 Impact of different LLMs used as proposers vs aggregators
Impact of different LLMs used as proposers vs aggregators
Impact of different LLMs used as proposers vs aggregators. Source.
Regarding costs, MoA's reliance on multiple LLMs makes its cost-to-performance ratio particularly interesting when compared to state-of-the-art models like GPT-4o and GPT-4 Turbo. Experiments show that MoA-Lite can outperform GPT-4 Turbo by approximately 4% on AlpacaEval 2.0 while cutting costs by more than half. The cost on MoA-Lite here is calculated based on pricing information available from TogetherAI. However, if we have no issue in spending more to maximize performance, then the 3-layers MoA would be a better choice.
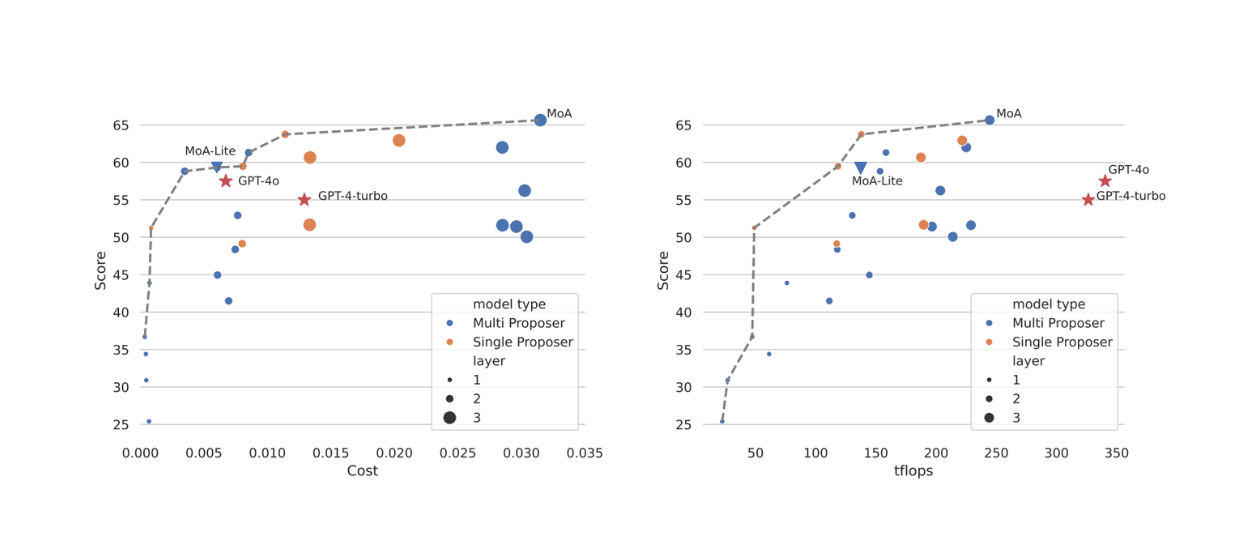 Figure: Performance trade-off vs cost (left) and performance trade-off vs TFLOPS (right).
Figure: Performance trade-off vs cost (left) and performance trade-off vs TFLOPS (right).
Figure: Performance trade-off vs cost (left) and performance trade-off vs TFLOPS (right). Source.
For latency evaluation, the authors used TFLOPS as their metric. TFLOPS refers to the system’s ability to perform a trillion floating-point operations in one second. Although TFLOPS is not exactly comparable to latency, the author used TFLOP as a proxy for latency because latency can vary depending on the inference systems. The experimentation result showed that the 3-layer MoA setup optimizes its TFLOPS to maximize the LC win rate, as shown by the Pareto dashed-line in the visualization above.
However, the GPT-4 family demonstrates higher TFLOPS compared to MoA setups. This is expected since MoA must process multiple LLM responses before generating its final output. This leads to its main limitation: Time to First Token (TTFT), which can negatively impact user experience. Future work aims to address this by implementing chunk-wise response aggregation instead of entire-response aggregation, potentially reducing TTFT while maintaining its performance.
Conclusion
The Mixture-of-Agents (MoA) method offers a promising solution to take advantage of the diversity and specialization of modern LLMs. By utilizing multiple LLMs with various strengths through a system of proposers and aggregators, MoA creates a more capable and robust final response. Its flexibility and reliance on prompt engineering, rather than fine-tuning, make it a cost-effective and adaptable approach, particularly for multi-domain use cases.
Benchmark evaluations on datasets like AlpacaEval 2.0 and MT-Bench show MoA superior performance over state-of-the-art models like GPT-4 family. To further optimize the performance, it’s recommended to use multi-proposer instead of single-proposer setup. However, MoA is not without limitations. The reliance on multiple LLMs increases latency, impacting user experience due to higher Time to First Token (TTFT). Therefore, further refinements, such as chunk-wise response aggregation, are necessary to optimize its efficiency.
Related Resources
MoA GitHub Repo: https://github.com/togethercomputer/MoA
MoA Paper: Mixture-of-Agents Enhances Large Language Model Capabilities
Keep Reading

Stop Building AI Data Infra for the Wrong Stage
Learn how AI data infrastructure should evolve from prototype to enterprise scale, and when Vector Lakebase becomes the right architecture for AI apps.

Data Deduplication at Trillion Scale: How to Solve the Biggest Bottleneck of LLM Training
Explore how MinHash LSH and Milvus handle data deduplication at the trillion-scale level, solving key bottlenecks in LLM training for improved AI model performance.

Cosmos World Foundation Model Platform for Physical AI
NVIDIA's Cosmos platform enables safe, digital twin training of GenAI models for physical applications, overcoming data scarcity and safety challenges.