




10 Open-Source LLM Frameworks Developers Can’t Ignore in 2025
2024 was a banner year for large language models (LLMs), and as we step into 2025, the momentum shows no signs of slowing. From GPT-4 and Gemini’s multimodal capabilities to real-time adaptive AI systems, LLMs are no longer just cutting-edge—they’re essential. They’re powering chatbots, search engines, content creation tools, and even automating workflows we once thought only humans could handle.
But here’s the thing: having a powerful LLM is only half the battle. Building scalable, efficient, and production-ready LLM applications can be challenging—that’s where LLM frameworks come in. They simplify workflows, enhance performance, and integrate seamlessly with existing systems, helping developers unlock the full potential of these models with less effort.
In this post, we’ll spotlight 10 open-source LLM frameworks that AI developers can’t ignore heading into 2025. These frameworks are the secret weapons helping developers scale, optimize, and innovate faster than ever. If you’re ready to level up your AI projects, let’s dive in!
LangChain: Powering Context-Aware, Multi-Step AI Workflows
LangChain is an open-source framework designed to streamline the development of applications powered by large language models (LLMs). It simplifies building workflows that combine LLMs with external data sources, APIs, or computational logic, enabling developers to create dynamic, context-aware systems for tasks like conversational agents, document analysis, and summarization.
Key Capabilities
Composable Pipelines: LangChain makes it easy to chain multiple LLM calls and external functions together, enabling complex multi-step workflows.
Off-the-Shelf Chains: LangChain offers pre-configured chains, organized assemblies of components designed to accomplish specific higher-level tasks. These off-the-shelf chains simplify the initiation of projects.
Prompt Engineering Utilities: Includes tools for crafting, managing, and optimizing prompts tailored to specific tasks.
Memory Management: Offers built-in capabilities for retaining conversational context across interactions, enabling more personalized applications.
LangChain has connected with third-party APIs, vector databases, LLMs, and various data sources. In particular, LangChain integration with vector databases such as Milvus and Zilliz Cloud further enhances its potential. Milvus is an open-source, high-performance vector database for managing and querying billion-scale embedding vectors. It complements LangChain’s capabilities by enabling fast and accurate retrieval of relevant data. Developers can leverage this integration to build scalable Retrieval-Augmented Generation (RAG) systems where Milvus retrieves contextually relevant documents. LangChain uses a generative model to produce accurate and insightful outputs. For more information, check out the below resources:
LlamaIndex: Connecting LLMs to Diverse Data Sources
LlamaIndex is an open-source framework that enables large language models (LLMs) to efficiently access and leverage diverse data sources. It simplifies the ingestion, structuring, and querying of unstructured data, making it easier to build advanced AI applications like document retrieval, summarization, and knowledge-based chatbots.
Key Capabilities
Data Connectors: Provides a robust set of connectors for ingesting structured and unstructured data from diverse sources such as PDFs, SQL databases, APIs, and vector stores.
Indexing Tools: Allows developers to create custom indices, including tree, list, and graph-based structures, to optimize data querying and retrieval.
Query Optimization: Offers advanced querying mechanisms that enable precise and contextually relevant responses.
Extensibility: Highly modular, making it easy to integrate with external libraries and tools for enhanced functionality.
LLM-Optimized Framework: Designed to work with LLMs, ensuring efficient use of computational resources for large-scale tasks.
LlamaIndex has integrated with various purpose-built vector databases like Milvus and Zilliz Cloud to support scalable and efficient RAG workflows. In this setup, Milvus acts as a high-performance backend for storing and querying embedding vectors, while LlamaIndex structures and organizes the retrieved data for LLMs to process. This combination allows developers to retrieve the most relevant data points and enables LLMs to deliver more accurate, context-aware outputs. For more information, check out the below resources:
Haystack: Streamlining RAG Pipelines for Production-Ready AI Applications
Haystack is an open-source Python framework designed to facilitate the development of LLM-powered applications. It enables developers to create end-to-end AI solutions by integrating LLMs with various data sources and components, making it suitable for tasks such as RAG, document search, question answering, and answer generation.
Key Capabilities
Flexible Pipelines: Haystack allows the creation of modular pipelines for tasks like document retrieval, question answering, and summarization. Developers can combine different components to tailor workflows to their specific needs.
Retriever-Reader Architecture: Combines retrievers for efficient document filtering with readers (e.g., LLMs) to generate precise and contextually aware responses.
Backend Agnostic: Supports multiple vector database backends, including Milvus and FAISS, ensuring flexibility in deployment.
LLM Integration: Provides seamless integration with language models, allowing developers to leverage pre-trained and fine-tuned models for various tasks.
Scalability and Performance: Optimized for handling large-scale datasets and high-throughput queries, suitable for enterprise applications.
In March 2024, Haystack released Haystack 2.0, introducing a more flexible and customizable architecture. This update allows for creating complex pipelines with features like parallel branching and looping, enhancing support for LLMs and agentic behavior. The new design emphasizes a common interface for storing data, providing integrations with various databases and vector stores, including Milvus and Zilliz Cloud. This flexibility ensures that data can be easily accessed and managed within Haystack pipelines, supporting the development of scalable and high-performance AI applications. For more information, check out the below resources:
Haystack GitHub: https://github.com/deepset-ai/haystack
Integration: Haystack and Milvus
Tutorial: Retrieval-Augmented Generation (RAG) with Milvus and Haystack
Tutorial: Building a RAG Pipeline with Milvus and Haystack 2.0
Dify: Simplifying LLM-Powered App Development
Dify is an open-source platform for building AI applications. It combines Backend-as-a-Service with LLMOps, supporting mainstream language models and offering an intuitive prompt orchestration interface. Dify provides high-quality RAG engines, a flexible AI agent framework, and an intuitive low-code workflow, enabling both developers and non-technical users to create innovative AI solutions.
Key Capabilities
Backend-as-a-Service for LLMs: Handles backend infrastructure, allowing developers to focus on building applications rather than managing servers.
Prompt Orchestration: Simplifies crafting, testing, and managing prompts tailored for specific tasks.
Real-Time Analytics: Provides insights into model performance, user interactions, and application behavior to optimize workflows.
Extensive Integration Options: Connects with third-party APIs, external tools, and popular LLMs, offering flexibility for custom workflows.
Dify integrates well with vector databases like Milvus, enhancing its ability to handle complex, large-scale data retrieval tasks. By pairing Dify with Milvus, developers can create systems that efficiently store, retrieve, and process embeddings for tasks like RAG.
Tutorial: Deploying Dify with Milvus
Letta (Previously MemGPT): Building RAG Agents with Extended LLM Context Window
Letta is an open-source framework designed to enhance LLMs by equipping them with long-term memory. Unlike traditional LLMs that process inputs statically, Letta allows the model to remember and reference past interactions, enabling more dynamic, contextually aware, and personalized applications. It integrates memory management techniques to store, retrieve, and update information over time, making it ideal for creating intelligent agents and conversational systems that evolve with user interactions.
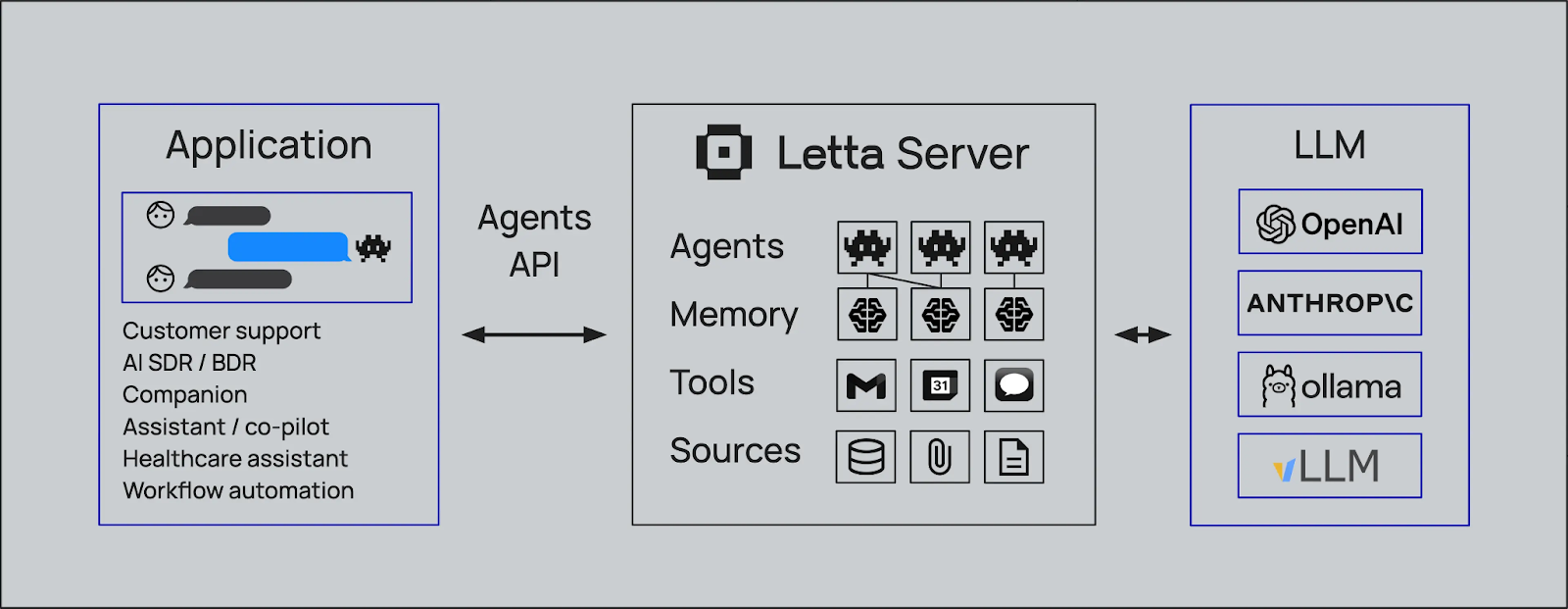 Figure- How Letta works with various AI tools
Figure- How Letta works with various AI tools
Key Capabilities
Self-Editing Memory: Letta introduces self-editing memory, allowing agents to autonomously update their knowledge base, learn from interactions, and adapt over time.
Agent Development Environment (ADE): Provides a graphical interface for creating, deploying, interacting with, and observing AI agents, streamlining the development and debugging process.
Persistence and State Management: Ensures that agents maintain continuity across sessions by persisting their state, including memories and interactions, enabling more coherent and contextually relevant responses.
Tool Integration: Supports the incorporation of custom tools and data sources, allowing agents to perform a wide range of tasks and access external information as needed
Model Agnostic Architecture: Designed to work with various LLMs and RAG systems, providing flexibility in choosing and integrating different model providers
Letta has integrated with mainstream vector databases to enhance its memory and retrieval capabilities for advanced RAG workflows. By leveraging scalable vector storage and efficient similarity search, Letta enables AI agents to access and retain long-term contextual knowledge, ensuring fast and accurate data retrieval. This integration allows developers to build smarter, context-aware applications tailored to specific domains, such as customer support or personalized recommendations, while maintaining persistent and scalable memory. Check out the resources below for more information.
- Tutorial | MemGPT with Milvus Integration
Blog | Introduction to MemGPT and Its Integration with Milvus
Paper | [2310.08560] MemGPT: Towards LLMs as Operating Systems
Vanna: Enabling AI-Powered SQL Generation
Vanna is an open-source Python framework designed to simplify the generation of SQL queries through natural language inputs. By leveraging RAG techniques, Vanna enables users to train models on their specific data, allowing them to pose questions and receive accurate SQL queries tailored to their databases. This approach streamlines the process of interacting with databases, making it more accessible to users without extensive SQL expertise.
 Vanna
Vanna
Key Capabilities
Natural Language to SQL Conversion: Vanna enables users to input questions in natural language, which it then converts into precise SQL queries executable on the connected database.
Support for Multiple Databases: The framework offers out-of-the-box support for various databases, including Snowflake, BigQuery, Postgres, and more. It also allows for easy integration with any database through custom connectors.
User Interface Flexibility: Vanna provides multiple user interface options, such as Jupyter Notebooks, Slackbot, web apps, and Streamlit apps, allowing users to choose the front end that best fits their workflow.
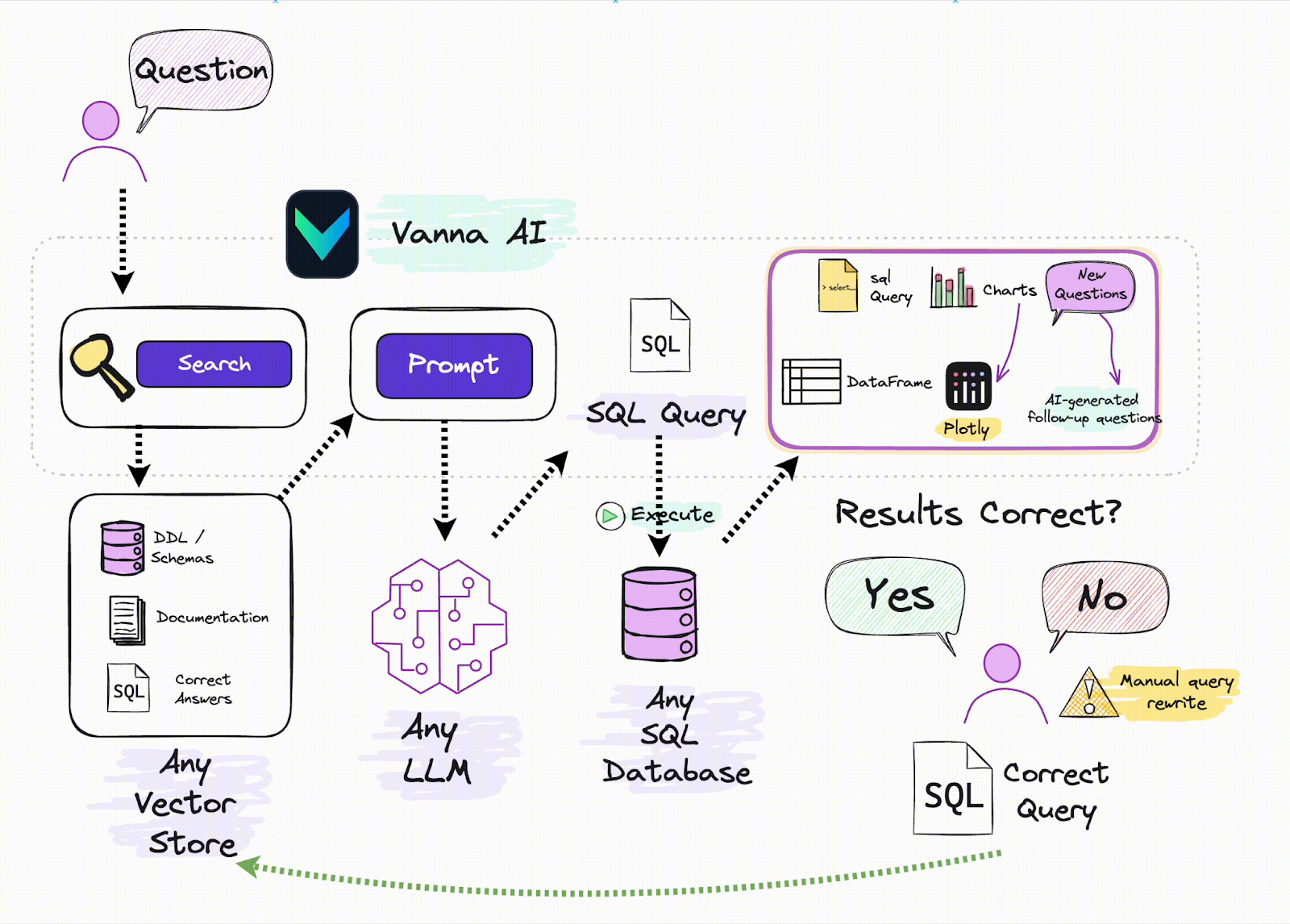
Vanna and vector databases are a great combination for building effective RAG systems. When a user inputs a natural language query, Vanna utilizes a vector database to retrieve relevant data based on pre-stored vector embeddings. This data is then used to help Vanna generate an accurate SQL query, making it easier to retrieve structured data from a relational database. By combining the power of vector search with SQL generation, Vanna simplifies working with unstructured data and allows users to interact with complex datasets without needing advanced SQL knowledge. For more information, check out the resources below:
Kotaemon: Building AI-Powered Document QA
Kotaemon is an open-source, customizable RAG UI for chatting with your documents. It provides a clean, multi-user document QA web interface supporting local and API-based language models. kotaemon offers a hybrid RAG pipeline with full-text and vector retrieval capabilities, enabling multi-modal QA for documents with figures and tables.
Designed for both end users and developers, kotaemon supports complex reasoning methods like ReAct and ReWOO. It features advanced citations with document previews, configurable settings for retrieval and generation, and an extensible framework for building custom RAG pipelines.
 Kotaemon
Kotaemon
Key Capabilities
Easy Deployment: Kotaemon offers simple interfaces to deploy LLMs into production with minimal setup, enabling rapid scaling and integration.
Customizable Pipelines: It allows developers to easily customize AI workflows, combining LLMs with external APIs, databases, and other tools.
Advanced Prompting: Features built-in tools for prompt engineering and optimization, making it easier to fine-tune model outputs for specific tasks.
Performance Optimization: Designed for high-performance operations, Kotaemon ensures low-latency responses and efficient use of resources.
Multi-Model Support: The framework supports various LLM architectures, giving developers the flexibility to choose the best model for their specific use case.
Kotaemon integrates with vector databases such as Milvus, enabling the fast retrieval of relevant data for tasks such as Retrieval-Augmented Generation (RAG). By leveraging Milvus’s efficient vector search capabilities, Kotaemon can enhance the context and relevance of AI-generated outputs. This integration allows developers to build AI systems that generate content and retrieve relevant information from large datasets, improving overall performance and accuracy.
vLLM: High-Performance LLM Inference for Real-Time AI Applications
vLLM is an open-source library developed by UC Berkeley's SkyLab, designed to optimize LLM inference and serving. With a focus on performance and scalability, vLLM introduces innovations like PagedAttention, which boosts serving speeds by up to 24x while cutting GPU memory usage in half compared to traditional approaches. This makes it a game-changer for developers building demanding AI applications that require efficient utilization of hardware resources.
Key Capabilities:
PagedAttention Technology: Enhances memory management by allowing non-contiguous storage of attention keys and values, reducing memory waste and improving throughput by up to 24x.
Continuous Batching: Aggregates incoming requests in real-time, maximizing GPU utilization and minimizing idle time, resulting in higher throughput and lower latency.
Streaming Outputs: Provides real-time token generation, allowing applications to deliver partial results immediately—ideal for real-time user interactions like chatbots.
Broad Model Compatibility: Supports popular LLM architectures like GPT and LLaMA, ensuring flexibility for many use cases and seamless integration with existing workflows.
OpenAI-Compatible API Server: Offers an API interface that mirrors OpenAI’s, simplifying deployment and integration into existing systems for developers familiar with OpenAI APIs.
vLLM becomes a cornerstone for building high-performance RAG systems when combined with vector databases like Milvus. Vector databases efficiently store and retrieve high-dimensional embeddings critical for retrieving contextually relevant information. vLLM complements this by delivering optimized LLM inference, ensuring that retrieved information is processed seamlessly into accurate, context-aware responses. This integration enhances application performance and addresses challenges like AI hallucinations by grounding outputs in retrieved data. Check out the resources below for more information.
Unstructured: Making Unstructured Data Accessible for GenAI
Unstructured is an open-source library that streamlines the ingestion and pre-processing of unstructured data of diverse data formats, including PDFs, HTML, Word documents, and images. It offers modular functions for partitioning, cleaning, extracting, staging, and chunking documents, facilitating the transformation of unstructured data into structured formats. This toolkit is beneficial for optimizing data workflows in Large Language Model (LLM) applications.
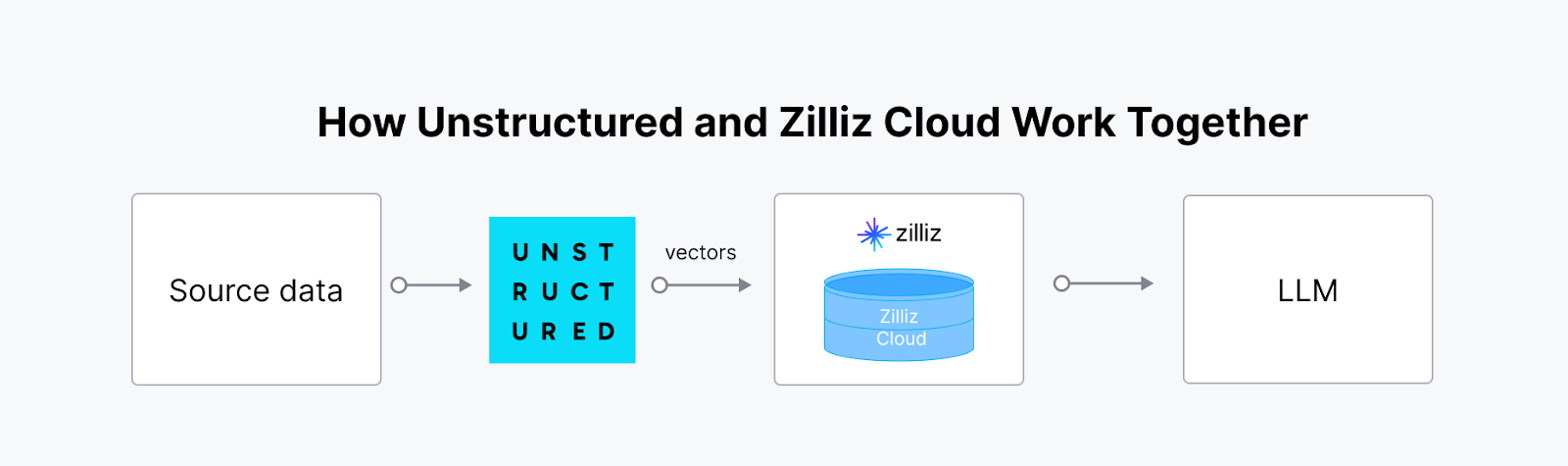
Integrating Unstructured with a vector database like Milvus creates a powerful, scalable solution for managing and leveraging unstructured data in AI applications. The Unstructured platform ingests, processes, and transforms unstructured data from various file types into AI-ready vector embeddings. These embeddings are crucial for advanced AI workflows, yet storing, indexing, and querying them effectively requires a specialized vector database. The synergy between Unstructured and Milvus (or Zilliz Cloud) enables a streamlined end-to-end pipeline, which is particularly valuable for Retrieval-Augmented Generation (RAG) and other AI-driven applications like smart chatbots and personalized recommendation systems.
 Unstructured
Unstructured
Tutorial | Build a RAG with Milvus and Unstructured
Blog | Vectorizing and Querying EPUB Content with the Unstructured and Milvus
Langfuse: Better Observability and Analytics for LLM Applications
Langfuse is an open-source LLM engineering platform that assists teams in collaboratively debugging, analyzing, and iterating their LLM applications. It offers features such as observability, prompt management, evaluations, and metrics, all natively integrated to accelerate the development workflow.
Key Capabilities
End-to-End Observability: Tracks LLM interactions, including prompts, responses, and performance metrics, to ensure transparency and reliability.
Prompt Management: Offers tools to version, optimize, and test prompts, streamlining the development of robust AI applications.
Flexible Integration: Works seamlessly with popular frameworks like LangChain and LlamaIndex, supporting a wide range of LLM architectures.
Real-Time Debugging: Provides actionable insights into errors and bottlenecks, allowing developers to iterate quickly.
Integrating Langfuse with vector databases enhances RAG workflows by providing observability into embedding quality and relevance. This integration allows developers to monitor and optimize vector search performance and accuracy through detailed analytics, ensuring that the retrieval processes are finely tuned and aligned with user needs. Check out the following tutorial to get started.
Conclusion
As 2025 begins, it’s clear that open-source frameworks are no longer just helpful add-ons—they’re foundational to building robust LLM applications. Frameworks like LangChain and LlamaIndex have transformed how we integrate and query data, while vLLM and Haystack are setting new benchmarks for speed and scalability. Emerging frameworks like Langfuse and Letta bring unique strengths in observability and memory, opening doors to smarter, more responsive AI systems.
These frameworks empower developers to tackle complex challenges, experiment with bold ideas, and push the limits of what’s possible. With these frameworks at your fingertips, 2025 is your year to build smarter, faster, and more impactful GenAI applications.

Keep Reading

Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
Vector Lakebase: a unified, lake-native data foundation for AI workloads — and an answer to what happens after vector databases succeed.

Zilliz Skills Breakdown: How AI Agents Master Vector Databases
Zilliz's Milvus Skill (pymilvus, 7 files) and Zilliz Cloud Skill (zilliz-cli, 14 modules) bring vector-DB dev and ops into one Claude Code session.

What is the K-Nearest Neighbors (KNN) Algorithm in Machine Learning?
KNN is a supervised machine learning technique and algorithm for classification and regression. This post is the ultimate guide to KNN.