




Retrieval Augmented Generation on Notion Docs via LangChain
This article was originally published in The Sequence and is reposted here with permission.
Do you have Notion docs you want to ask a language model to query for you? Let’s build a basic retrieval augmented generation (RAG) type app using LangChain and Milvus. We use LangChain for the operational framework and Milvus as the similarity engine. You can find the notebook for this blog on colab.
In this tutorial we go through the following:
Review of LangChain Self Querying
Working with Notion Docs in LangChain
Ingesting Your Notion Documents
Storing Your Notion Documents
Querying Your Notion Documents
Summary of Querying Notion Docs with LangChain and Milvus
Review of LangChain self querying
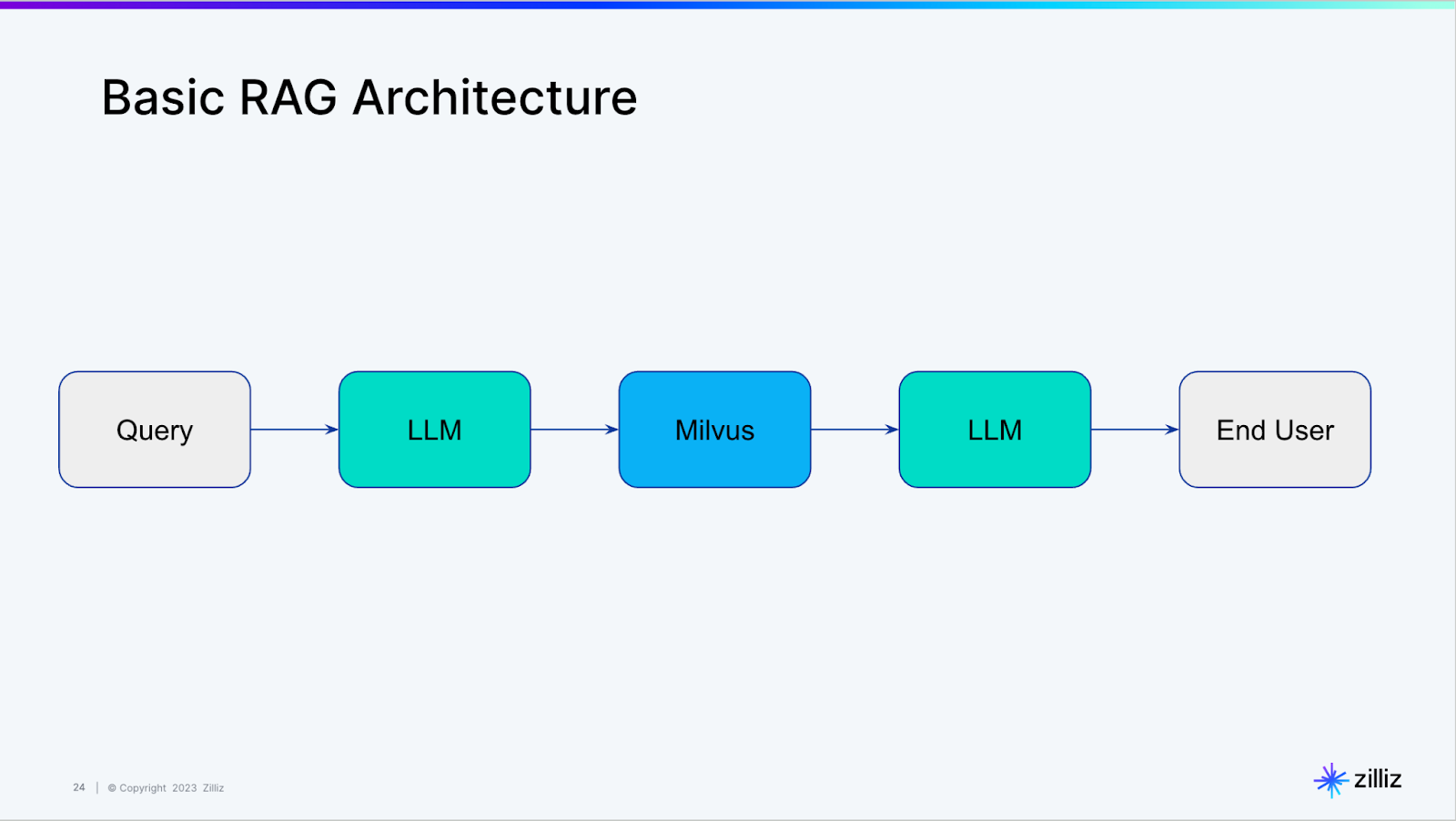
We recently covered how to use LangChain to query a vector database, an introduction to what LangChain dubs “self-querying”. Behind the scenes, the self-querying functionality in LangChain is constructing a basic RAG architecture like the one shown below.
Working with Notion docs in LangChain
I will split this into three steps: ingesting, storing, and querying. Ingestion covers getting your Notion documents and loading the contents into memory. Storage covers spinning up a vector database (Milvus), vectorizing the documents, putting them into the vector database, and querying covers asking a question about your Notion documents.
Ingesting your Notion documents
We use the NotionDirectoryLoader from LangChain to load the documents into memory. We provide the path to our docs and call the load function to get them. Once the documents are loaded in memory, we grab the markdown file, in this case, just one.
Next, we use the markdown header text splitter from LangChain. We feed it a list of dividers to split on and then pass the previously named md_file to get our splits. When you define your headers_to_split_on list, make sure you use the headers you use in your Notion doc, not just the examples I provided.
# Load Notion page as a markdownfile file
from langchain.document_loaders import NotionDirectoryLoader
path='./notion_docs'
loader = NotionDirectoryLoader(path)
docs = loader.load()
md_file=docs[0].page_content
# Let's create groups based on the section headers in our page
from langchain.text_splitter import MarkdownHeaderTextSplitter
headers_to_split_on = [
("##", "Section"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(md_file)
In the code below, we perform and examine our splits. We use LangChain’s RecursiveCharacterTextSplitter, which tests some different characters to split on. The four default characters to check are a newline, a double newline, a space, or no space. You can also opt to pass on your own with a separators parameter, which we did not use this time.
The two essential hyperparameters to define when chunking your Notion doc are the chunk size and the chunk overlap. For this example, we use a chunk size of 64 and an overlap of 8. In the future, we will cover testing these values and finding good values. Once we define the text splitter, we call its split_documents functions to get all our Document splits.
# Define our text splitter
from langchain.text_splitter import RecursiveCharacterTextSplitter
chunk_size = 64
chunk_overlap = 8
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
all_splits = text_splitter.split_documents(md_header_splits)
all_splits
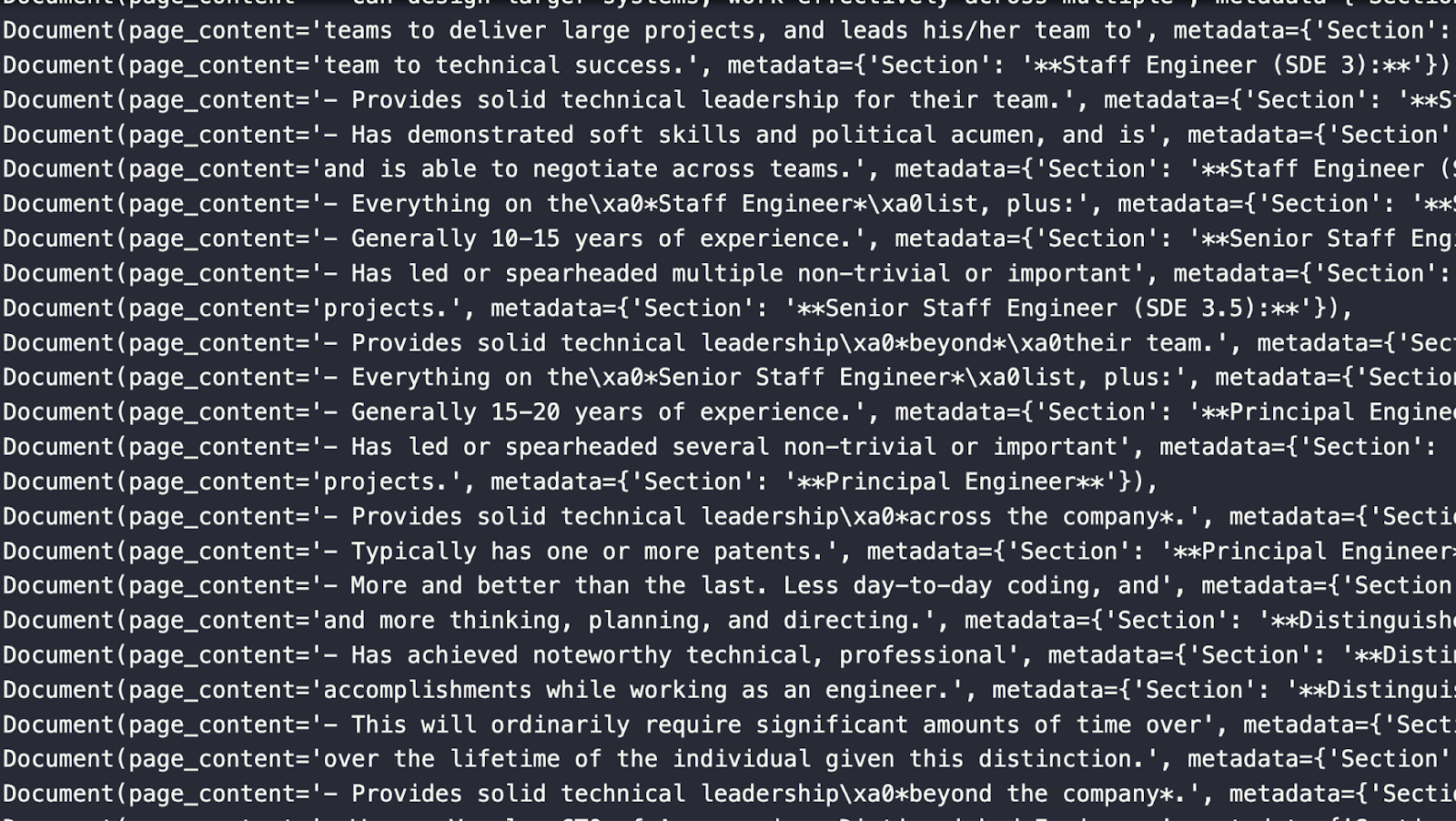
The image below shows some Document objects from the split above. Notice that it includes the page content and the metadata which includes the section that the content is pulled from.
Storing your Notion documents
With all the documents loaded and split, it’s time to store those splits. First, we spin up our vector database directly in our notebook using Milvus Lite. We also need to get the necessary LangChain modules - Milvus and OpenAIEmbeddings.
After the imports and standing up the vector database, we use LangChain’s Milvus module to create a collection from our documents. We need to pass it the document list, the embeddings to use, the connection parameters, and (optionally) a collection name.
from milvus import default_server
default_server.start()
from langchain.vectorstores import Milvus
from langchain.embeddings import OpenAIEmbeddings
vectordb = Milvus.from_documents(documents=all_splits,
embedding=OpenAIEmbeddings(),
connection_args={"host": "127.0.0.1", "port": default_server.listen_port},
collection_name="EngineeringNotionDoc")
Querying your Notion documents
Everything is set up and ready for querying. For this section, we need three more imports from LangChain - OpenAI for accessing GPT, the SelfQueryRetriever to make our basic RAG, and the “Attribute info” object to pass the metadata. To kick it off, we define some metadata. For this example, just the sections that we’ve been using so far.
We also give the self-query retriever a description of the documents. In this case, simply “major sections of the document”. Right before we instantiate our self-query retriever, we set a 0 temperature version of GPT to an llm variable. With the LLM, the vector database, the document description, and the metadata fields ready, we define the self-query retriever.
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
metadata_fields_info = [
AttributeInfo(
name="Section",
description="Part of the document that the text comes from",
type="string or list[string]"
),
]
document_content_description = "Major sections of the document"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(llm, vectordb, document_content_description, metadata_fields_info, verbose=True)
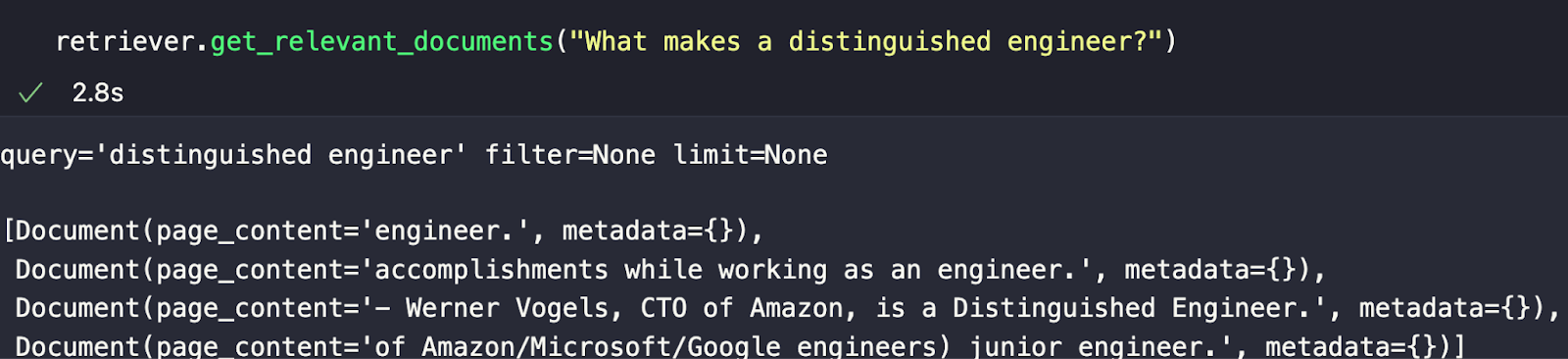
retriever.get_relevant_documents("What makes a distinguished engineer?")
My chosen example is “What makes a distinguished engineer?” From the response in the image below, we can see the most semantically similar chunks returned. As we can see, just because they are the most semantically similar responses doesn’t mean they’re the right ones. In future pieces, we will cover how to experiment with chunking and other techniques to improve our responses.
Summary of querying Notion docs in LangChain
In this tutorial, we covered how to load and parse a Notion doc into sections to query in a basic RAG architecture. We used LangChain as the orchestration framework and Milvus as our vector database. LangChain puts the pieces together, and Milvus drives the similarity search.
To take this tutorial further, there are many things we can test. Examples of two hyperparameters to check are the chunk size and the overlap size between chunks. We can use these to tune our responses and what they look like. Aside from tuning, we also need to evaluate the responses.
In future tutorials, we will look at different chunking strategies. Not only that, but we will also take deeper looks into embeddings, splitting strategies, and evaluation.

Keep Reading

Introducing Functions and Model Inference on Zilliz Cloud: Automatic Embedding and Reranking with Hosted Models
Zilliz Cloud Functions auto-generate embeddings via OpenAI, Voyage AI, Cohere, or Zilliz Hosted Models. Built-in reranking — just insert text and search.

How to Choose the Best Embedding Model for RAG in 2026: 10 Models Benchmarked
We benchmarked 10 embedding models on cross-modal, cross-lingual, long-document, and dimension compression tasks. See which one fits your RAG pipeline.

AI Integration in Video Surveillance Tools: Transforming the Industry with Vector Databases
Discover how AI and vector databases are revolutionizing video surveillance with real-time analysis, faster threat detection, and intelligent search capabilities for enhanced security.