




Deploying a Multimodal RAG System Using vLLM and Milvus
Imagine you've spent months fine-tuning your AI application around a specific LLM through an API provider. Then, out of the blue, you receive an email: "We're deprecating the model you're using in favor of our new version." Sound familiar? While cloud API providers offer the convenience of powerful, ready-to-use AI capabilities, relying solely on them also introduces several significant risks:
- Lack of Control: You have no control over model versions or updates.
- Unpredictability: You may face sudden changes in model behavior or capabilities.
- Limited Insight: There's often limited visibility into performance and usage patterns.
- Privacy Concerns: Data privacy can be a critical issue, especially when handling sensitive information.
So, what's the solution? How can you take back control? How can you mitigate these risks while enhancing your system's capabilities? The answer lies in building a more robust, independent system using open-source solutions.
This blog will guide you through creating a Multimodal RAG with Milvus and vLLM. By leveraging the power of an open-source vector database combined open-source LLM inference, you can design a system capable of processing and understanding multiple types of data—text, images, audio, and even videos. This approach not only puts you in complete control of the technology but also ensures a system that's both powerful and versatile, surpassing traditional text-based solutions.
What We'll Build: a Multimodal RAG Fully Under Your Control
We're going to build a Multimodal RAG system using Milvus and vLLM, illustrating how you can self host your LLM and gain full control over your AI applications. Our tutorial will guide you through creating a Streamlit application that demonstrates the power of integrating multiple data types. Here’s what we’ll cover:
Process video input by extracting frames and transcribing the audio
Store and efficiently index multimodal data using Milvus
- We use OpenAI CLIP to encode the images into embeddings that can then be searched with Milvus
- We use the Mistral Embedding model to encode the text into embeddings.
Retrieve relevant context based on user queries using Milvus
Generate responses using Pixtral running with vLLM, leveraging both visual and textual understanding
By the end of this tutorial, you'll have developed a flexible, scalable system entirely under your control-no more worrying about API deprecations or unexpected changes.
What is Milvus?
Milvus is an open-source, high-performance, and highly scalable vector database that can store, index, and search billion-scale unstructured data through high-dimensional vector embeddings. It is perfect for building modern AI applications such as retrieval augmented generation (RAG), semantic search, multimodal search, and recommendation systems. Milvus runs efficiently across various environments, from laptops to large-scale distributed systems.
What is vLLM?
The core idea of vLLM (Virtual Large Language Model) is to optimize the serving and execution of LLMs by utilizing efficient memory management techniques. Here are the key aspects:
- Optimized Memory Management: vLLM implements advanced memory allocation and management techniques to fully leverage available hardware resources. This optimization helps to run large language models efficiently, preventing memory bottlenecks that can hinder performance.
- Dynamic Batching: vLLM adapts batch sizes and sequences based on the memory and compute capabilities of the underlying hardware. This dynamic adjustment enhances processing throughput and minimizes latency during model inference.
- Modular Design: The architecture of vLLM is modular, facilitating straightforward integration with various hardware accelerators. This modularity also enables easy scaling across multiple devices or clusters, making it highly adaptable to different deployment scenarios.
- Efficient Resource Utilization: vLLM optimizes the use of critical resources such as CPUs, GPUs, and memory. This efficiency allows the system to support larger models and handle increased numbers of simultaneous requests, which is essential in production environments where both scalability and performance are key.
- Seamless Integration: Designed to integrate smoothly with existing machine learning frameworks and libraries, vLLM provides a user-friendly interface. This ensures that developers can easily deploy and manage large language models across a range of applications without extensive reconfiguration.
Core Components of Our Multimodal RAG
The multimodal RAG app we are building comprises of the following key components:
- vLLM is the inference library we will use for the inference and serving of the Pixtral multimodal model.
- Koyeb provides the infrastructure layer for our deployment, offering a serverless platform specialized for AI workloads. With native vLLM integration and automated GPU resource management, it makes it easy to deploy LLM while maintaining production-grade performance and scalability.
- Pixtral from Mistral AI acts as our multimodal brain, combining a 400M parameter vision encoder with a 12B parameter multimodal decoder. This architecture allows it to process both images and text within the same context window.
- Milvus provides the vector storage foundation, efficiently managing embeddings from different modalities. Its ability to handle multiple vector types and perform fast similarity search makes it perfect for multimodal applications.
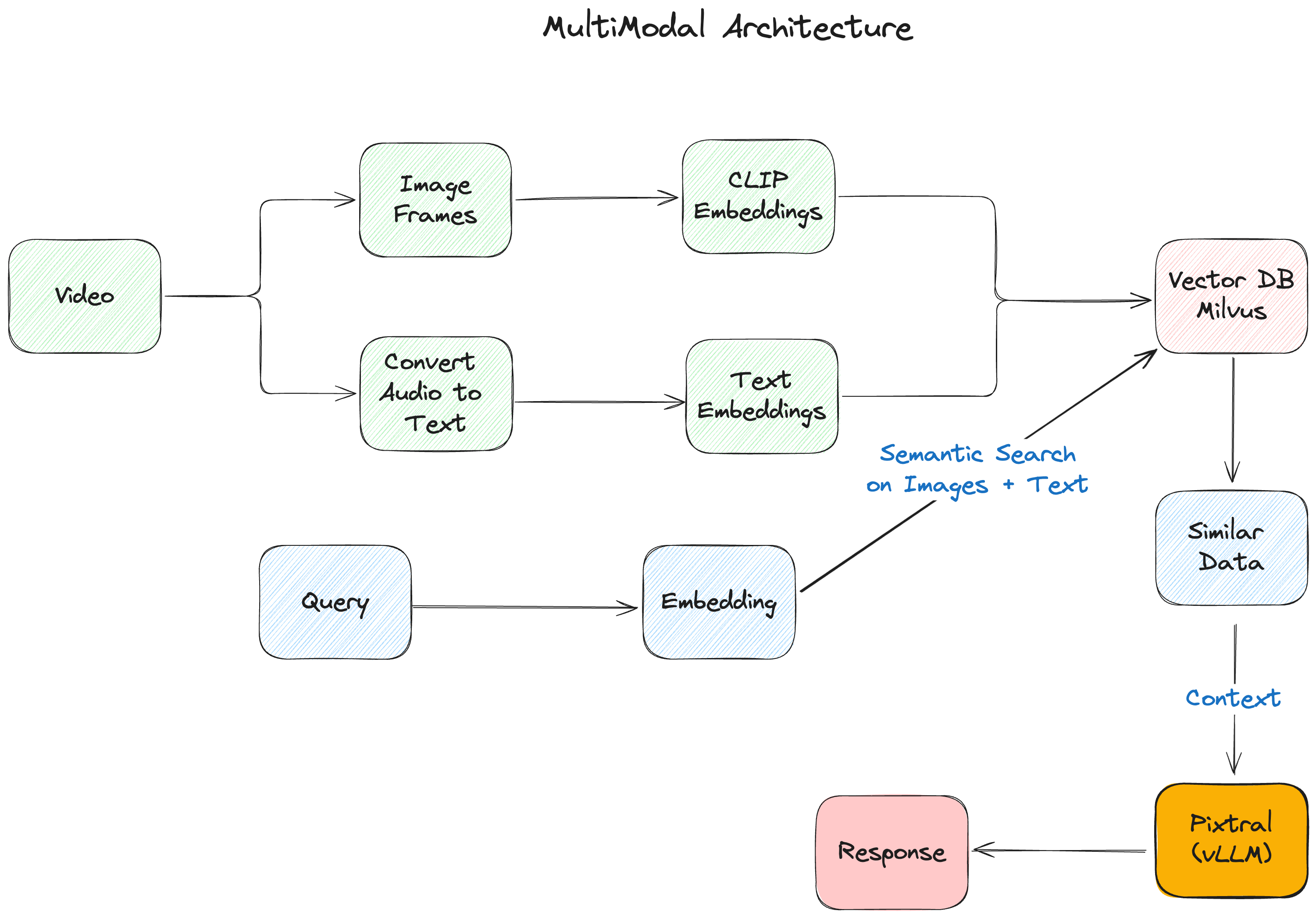 Figure- The multimodal RAG architecture.png
Figure- The multimodal RAG architecture.png
Figure: The multimodal RAG architecture
Getting Started
First, let's install our dependencies:
# Core LlamaIndex packages
pip install -U llama-index-vector-stores-milvus llama-index-multi-modal-llms-mistralai llama-index-embeddings-mistralai llama-index-multi-modal-llms-openai llama-index-embeddings-clip llama_index
# Video and audio processing
pip install moviepy pytube pydub SpeechRecognition openai-whisper ffmpeg-python soundfile
# Image processing and visualization
pip install torch torchvision matplotlib scikit-image git+https://github.com/openai/CLIP.git
# Utilities and infrastructure
pip install pymilvus streamlit ftfy regex tqdm
Setting Up the Environment
We'll start by configuring our environment and importing necessary libraries:
import os
import base64
import json
from pathlib import Path
from dotenv import load_dotenv
from llama_index.core import Settings
from llama_index.embeddings.mistralai import MistralAIEmbedding
# Load environment variables
load_dotenv()
# Configure default embedding model
Settings.embed_model = MistralAIEmbedding(
"mistral-embed",
api_key=os.getenv("MISTRAL_API_KEY")
)
Video Processing Pipeline
The heart of our system is the video processing pipeline, which transforms raw video content into data that our RAG system can understand and process efficiently.
def process_video(video_path: str, output_folder: str, output_audio_path: str) -> dict:
# Create output directory if it doesn't exist
Path(output_folder).mkdir(parents=True, exist_ok=True)
# Extract frames from video
video_to_images(video_path, output_folder)
# Extract and transcribe audio
video_to_audio(video_path, output_audio_path)
text_data = audio_to_text(output_audio_path)
# Save transcription
with open(os.path.join(output_folder, "output_text.txt"), "w") as file:
file.write(text_data)
os.remove(output_audio_path)
return {"Author": "Example Author", "Title": "Example Title", "Views": "1000000"}
This pipeline breaks down videos into:
- Image frames (extracted at 0.2 FPS)
- Audio transcription using Whisper
- Metadata about the video
Building the Vector Index
We use Milvus to store our multimodal embeddings. Here's how we create our index:
def create_index(output_folder: str):
# Create different collections for text and images
text_store = MilvusVectorStore(
uri="milvus_local.db",
collection_name="text_collection",
overwrite=True,
dim=1024
)
image_store = MilvusVectorStore(
uri="milvus_local.db",
collection_name="image_collection",
overwrite=True,
dim=512
)
storage_context = StorageContext.from_defaults(
vector_store=text_store,
image_store=image_store
)
# Load and index documents
documents = SimpleDirectoryReader(output_folder).load_data()
return MultiModalVectorStoreIndex.from_documents(
documents,
storage_context=storage_context
)
Query Processing with Pixtral
When a user asks a question, we need to:
- Retrieve relevant context from our vector store
- Process the query with Pixtral using both text and images
Here's our query processing function:
def process_query_with_image(query_str, context_str, metadata_str, image_document):
client = OpenAI(
base_url=os.getenv("KOYEB_ENDPOINT"),
api_key=os.getenv("KOYEB_TOKEN")
)
with open(image_document.image_path, "rb") as image_file:
image_base64 = base64.b64encode(image_file.read()).decode("utf-8")
qa_tmpl_str = """
Given the provided information, including relevant images and retrieved context
from the video, accurately and precisely answer the query without any
additional prior knowledge.
---------------------
Context: {context_str}
Metadata: {metadata_str}
---------------------
Query: {query_str}
Answer: """
# Prepare messages for Pixtral
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": qa_tmpl_str.format(
context_str=context_str,
query_str=query_str,
metadata_str=metadata_str
)
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{image_base64}"
}
},
],
}
]
completion = client.chat.completions.create(
model="mistralai/Pixtral-12B-2409",
messages=messages,
max_tokens=300
)
return completion.choices[0].message.content
Building the Streamlit Interface
Finally, we create a user-friendly interface with Streamlit:
def main():
st.title("MultiModal RAG with Pixtral & Milvus")
# Initialize session state
if 'index' not in st.session_state:
st.session_state.index = None
st.session_state.retriever_engine = None
st.session_state.metadata = None
# Video input
video_path = st.text_input("Enter video path:")
if video_path and not st.session_state.index:
with st.spinner("Processing video..."):
# Process video and create index
[... processing code ...]
if st.session_state.index:
st.subheader("Chat with the Video")
query = st.text_input("Ask a question about the video:")
if query:
with st.spinner("Generating response..."):
# Generate and display response
[... query processing code ...]
if __name__ == "__main__":
main()
Running the Application
Before starting the application, ensure you have:
- Set up your environment variables in
.env - Installed all required dependencies
Then launch the application:
streamlit run app.py
You'll see the homepage where you can:
- Upload videos for processing
- Ask questions about the content of the video
- Read the responses from Pixtral with relevant video frames
 Figure- The interface of your multimodal RAG app built with Milvus and Pixtral.png
Figure- The interface of your multimodal RAG app built with Milvus and Pixtral.png
Figure: The interface of your multimodal RAG app built with Milvus and Pixtral
From now on, you can interact with the video and for example, learn more about the the Gaussian Distribution.
 Figure- Performing the multimodal search.png
Figure- Performing the multimodal search.png
Figure: Performing the multimodal search
Conclusion
In this blog post, we've demonstrated how to build a powerful multimodal RAG system using Milvus, Pixtral, and vLLM. Through the combination of Milvus's efficient vector storage capabilities and Pixtral's advanced multimodal understanding, we've created a system that can process, understand, and respond to queries about video content. And this system is fully under your control.
We'd Love to Hear What You Think!
If you like this blog post, please consider:
- ⭐ Giving us a star on GitHub
- 💬 Joining our Milvus Discord community to share your experiences
- 🔍 Exploring our Bootcamp repository for more examples of multimodal applications with Milvus

Keep Reading

Balancing Precision and Performance: How Zilliz Cloud's New Parameters Help You Optimize Vector Search
Optimize vector search with Zilliz Cloud’s level and recall features to tune accuracy, balance performance, and power AI applications.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.

OpenAI o1: What Developers Need to Know
In this article, we will talk about the o1 series from a developer's perspective, exploring how these models can be implemented for sophisticated use cases.