




Понимание мультимодального искусственного интеллекта
Понимание мультимодального искусственного интеллекта
Запуск ChatGPT и многих других больших языковых моделей (LLMs) ознаменовал собой важнейшую веху в развитии ИИ. За это время модели ИИ перешли от нишевых приложений к повседневным, таким как письмо, кодирование, обслуживание клиентов и создание контента. Однако большая часть этого прогресса была ограничена одной модальностью: текстом.
Для достижения цели общего искусственного интеллекта (ОИ) недостаточно сосредоточиться только на одной модальности. По самому определению, ОИ требует способности понимать, рассуждать и действовать в нескольких областях, от языка и зрения до слухового и сенсорного ввода. Поэтому возникла мультимодальность; в этой статье мы расскажем вам об этой технике.
Что такое мультимодальный ИИ?
Системы искусственного интеллекта являются мультимодальными, если они обрабатывают и анализируют информацию из нескольких модальностей, таких как текст, изображения, аудио и видео. С другой стороны, ИИ, который может обрабатывать только один тип модальности, является унимодальным.
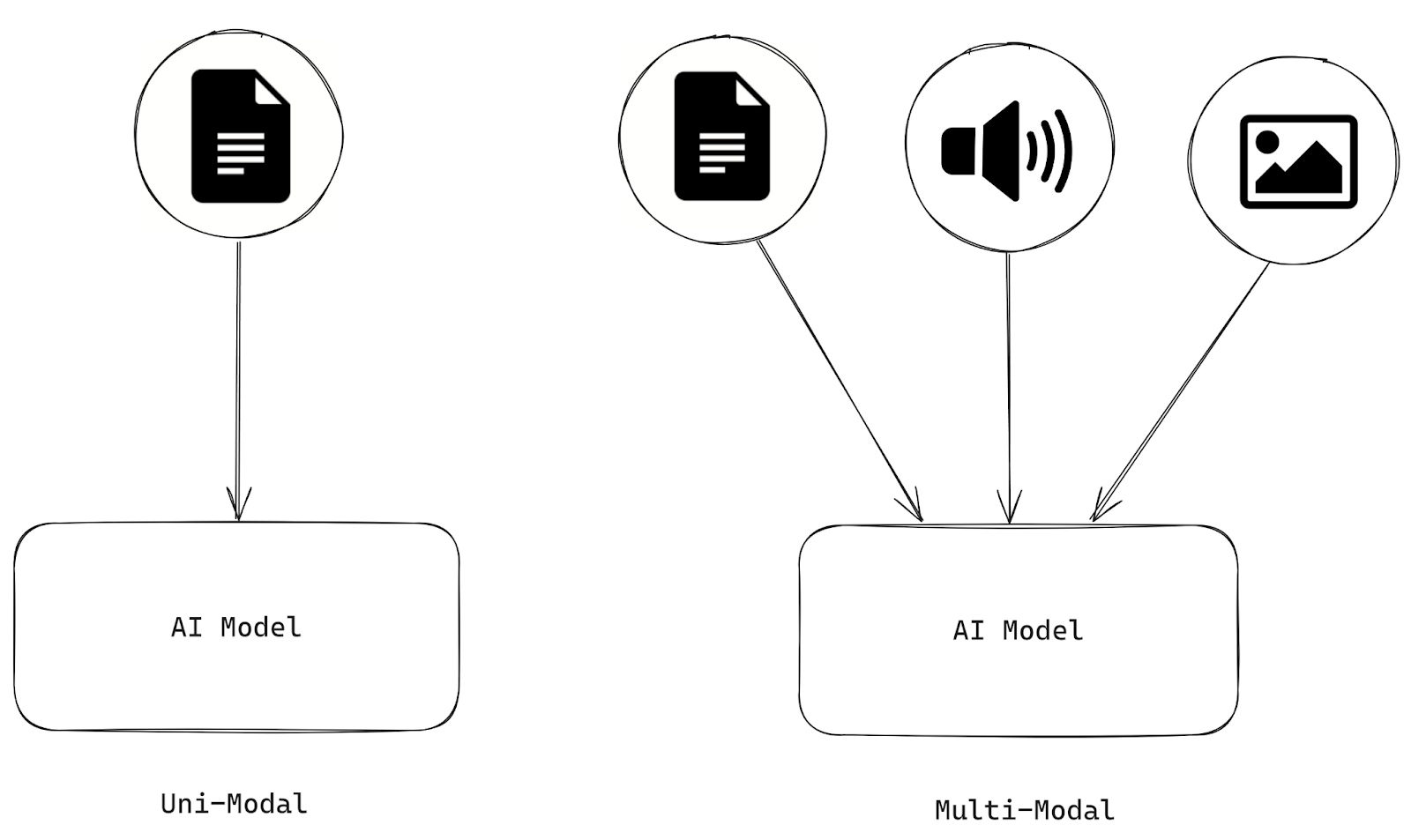 Рисунок 1- Различия между унимодальным и мультимодальным ИИ.png
Рисунок 1- Различия между унимодальным и мультимодальным ИИ.png
Рисунок 1: Различия между уни- и мультимодальным ИИ
Важно прояснить различие между двумя часто путаемыми терминами: мультимодальный и мультимодальный. Мультимодальный относится к системам, интегрирующим и обрабатывающим информацию из нескольких типов данных. Напротив, многомодельность описывает использование нескольких независимых моделей, которые работают параллельно или в комбинации для выполнения задачи. Эти модели могут работать с одними и теми же или разными типами данных, но остаются отдельными, а не интегрированными.
Мультимодальный ИИ может существенно повлиять на многие приложения. Например, мультимодальный ИИ в системе здравоохранения может использовать медицинские изображения, записи голоса пациентов и клинические заметки, чтобы поставить диагноз более точно, чем это могла бы сделать система, опирающаяся только на один источник данных. В этом отношении мультимодальные системы ИИ гораздо ближе к человеческому познанию и очень эффективны в задачах с критической потребностью во всеобъемлющем понимании.
Мультимодальный может быть одним или несколькими из следующих:
Ввод и вывод данных осуществляется в разных модальностях, например, текст-изображение или изображение-текст.
Входные данные являются мультимодальными (например, текст и изображения).
Выходные данные являются мультимодальными, например, одна система выдает текст и изображения.
В следующем разделе мы обсудим, как работают мультимодальные системы.
Как работает мультимодальный ИИ?
В мультимодальной модели различные компоненты работают вместе. Вот наиболее важные элементы и их работа:
Типы данных: Мультимодальный ИИ объединяет несколько типов данных, включая текст, изображения, аудио и видео, что позволяет комплексно понимать и генерировать контент в различных модальностях.
Представление: Мультимодальные представления в машинном обучении объединяют данные из разных модальностей в более значимые характеристики, которые могут использовать модели. Для достижения этой цели используются два различных подхода.
Совместные представления: Данные из разных модальностей преобразуются в единое пространство представлений, что позволяет использовать мультимодальные данные в процессе обучения и вывода. Стандартные методы включают нейронные сети и вероятностные графические модели. Хотя эти методы могут повысить производительность, они сталкиваются с проблемами, связанными с отсутствием данных.
Координированные представления: Каждая модальность обрабатывается отдельно, при этом накладываются ограничения, чтобы выровнять их в общем пространстве.
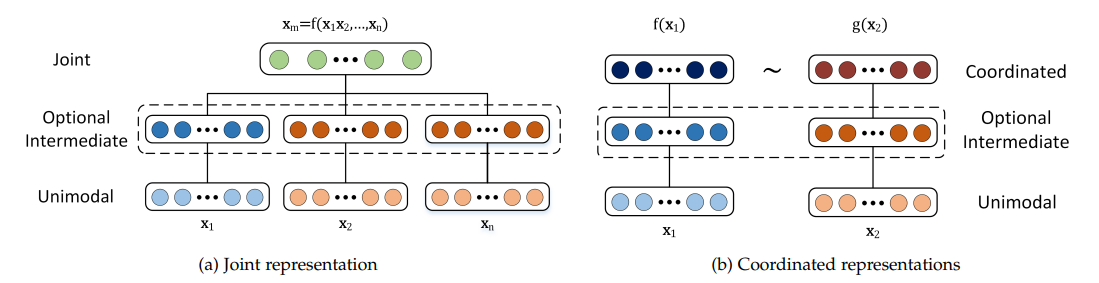 Рисунок 2- Структура совместных и согласованных представлений.png
Рисунок 2- Структура совместных и согласованных представлений.png
Рисунок 2. Структура совместных и согласованных представлений | [Источник](https://www.researchgate.net/figure/Structure-of-joint-and-coordinated-representations-Joint-representations-are-projected_fig1_317185818#:~:text=Joint%20representations%20are%20projected%20to,constraint%20(например, %20partial%20order)).
Извлечение признаков: Для извлечения признаков из каждого типа данных используются специализированные методы, такие как обработка естественного языка (NLP) для текста, компьютерное зрение для изображений и обработка сигналов для аудио.
Слияние данных**: Слияние объединяет информацию из двух или более модальностей для решения задачи предсказания. Существуют следующие подходы:
Раннее слияние: Данные объединяются перед анализом, обычно в низкоразмерном подпространстве с помощью таких методов, как PCA (анализ главных компонент) или ICA (анализ независимых компонент). Этот подход требует синхронизации модальностей, что может быть затруднено из-за различий в форматах данных и частоте дискретизации. Хотя такой подход эффективен для извлечения признаков, он может привести к потере данных и проблемам синхронизации.
Позднее слияние: Результаты отдельных модальностей объединяются на уровне принятия решения с помощью ансамблевых методов, таких как bagging, boosting или подходов, основанных на правилах (например, Bayes, max или average fusion). Этот метод лучше всего подходит для некоррелированных модальностей, обеспечивая гибкость, сходную с человеческим познанием.
Моделирование: Нейронные сети, способные обрабатывать множество модальностей, такие как трансформаторы или конволюционные нейронные сети (CNNs), используются для обучения на различных входных данных. Существуют и более сложные модели, которые дают превосходные результаты и часто называются LMM (Large Multimodal Models).
Популярные мультимодальные модели и их архитектуры
На рынке представлено множество мультимодальных моделей. Ниже представлены популярные модели и их архитектуры.
Video-Audio-Text Transformer (VATT)
Видео-Аудио-Текстовый Трансформатор (VATT)** - это архитектура без свертки, предназначенная для обработки нескольких модальностей (видео, аудио и текст) с помощью единого Трансформатора-основанного фреймворка. VATT начинает с подачи каждой модальности на слой токенизации, где исходный сигнал проецируется в вектор встраивания, который впоследствии обрабатывается трансформатором.
Существуют две основные конфигурации: одна, в которой для каждой модальности используются отдельные трансформаторы с уникальными весами, и другая, в которой единая основа трансформаторов с общими весами обрабатывает все модальности.
Независимо от конфигурации, трансформатор извлекает специфические для каждой модальности представления и отображает их в общее пространство для дальнейших задач. Архитектура повторяет стандартный конвейер трансформеров, широко используемый в [NLP] (https://zilliz.com/learn/nlp-technologies-in-deep-learning) и [Vision Transformers (ViT)] (https://zilliz.com/learn/understanding-vision-transformers-vit), с использованием входных лексем.
Кроме того, VATT включает в себя обучаемое относительное смещение для текста, что делает его совместимым с моделями типа T5. Такой подход позволяет VATT эффективно моделировать мультимодальные данные для таких задач, как классификация.
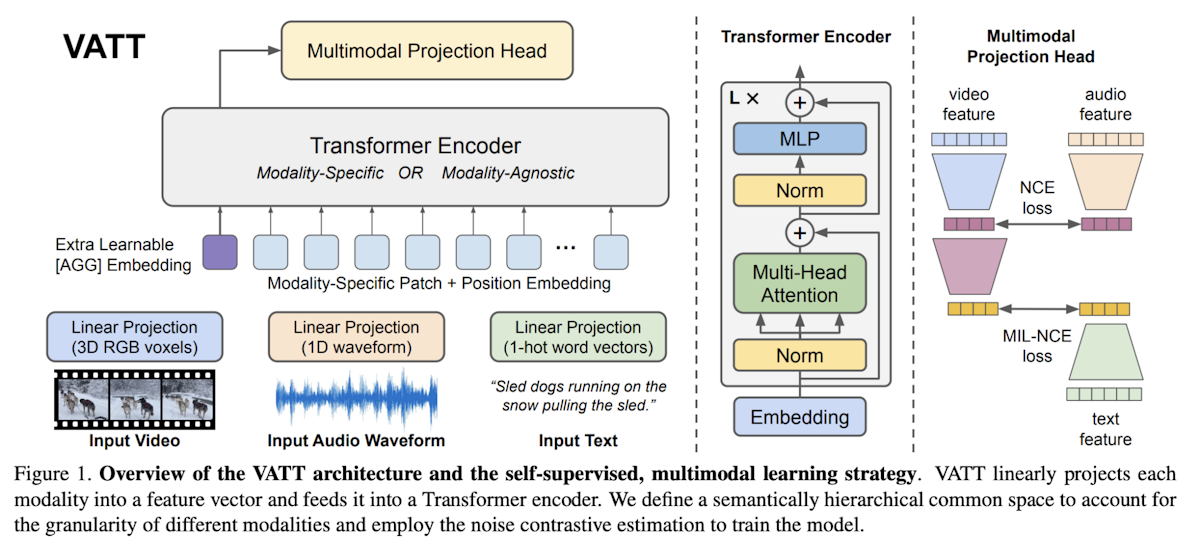 Рисунок 3- Трансформаторы зрения для мультимодального обучения.png
Рисунок 3- Трансформаторы зрения для мультимодального обучения.png
Рисунок 3: Трансформаторы зрения для мультимодального обучения | Источник
Мультимодальный вариационный автоэнкодер (MVAE)
Архитектура Multimodal Variational Autoencoder (MVAE) предназначена для обучения единому представлению текста и изображений. MVAE состоит из трех основных компонентов: кодера, декодера и прикладного модуля (в данном случае - детектора фальшивых новостей).
 Рисунок 4- Архитектура мультимодального вариационного автоэнкодера.png
Рисунок 4- Архитектура мультимодального вариационного автоэнкодера.png
Рисунок 4: Архитектура мультимодального вариационного автоэнкодера | Источник
Энкодер: Этот компонент обрабатывает текстовые и графические данные для создания общего латентного представления. Он состоит из двух субкодеров:
Текстовый кодировщик: Преобразует последовательность слов из сообщения в вкрапления слов с помощью предварительно обученной глубокой сети.
Визуальный кодировщик: Этот процесс извлекает визуальные признаки из изображений с помощью CNNs (например, VGG-19), чтобы уловить пространственную и объектную семантику.
Декодер: Декодер восстанавливает исходный текст и изображение из общего скрытого представления. Он повторяет структуру кодера и подразделяется на:
Текстовый декодер: Декодер восстанавливает текст, пропуская латентное представление через двунаправленные блоки LSTM и полностью связанный слой, предсказывая вероятность каждого слова.
Визуальный декодер: Реверсирует визуальное кодирование, восстанавливая особенности изображения VGG-19 через полностью связанные слои.
Детектор фальшивых новостей: Этот компонент предсказывает, является ли новостное сообщение настоящим или фальшивым, используя общее мультимодальное латентное представление.
CLIP (Contrastive Language-Image Pretraining)
Модель CLIP (Contrastive Language-Image Pretraining) предназначена для обучения совместным представлениям изображений и текста путем тренировки на обширном наборе данных пар "изображение-текст". В CLIP используются две отдельные нейронные сети: одна для изображений (часто это Vision Transformer или CNN) и одна для текста (обычно это Transformer).
Эти сети кодируют изображения и текст в векторы фиксированной длины в общем пространстве встраивания. В процессе обучения CLIP использует задачу контрастного обучения, которая объединяет вложения совпадающих пар изображений и текстов и отталкивает несовпадающие пары.
Благодаря этому процессу CLIP учится соотносить визуальную и текстовую информацию. Такой подход позволяет модели выполнять классификацию изображений с нулевого снимка, что дает ей возможность распознавать объекты на изображениях на основе описаний на естественном языке без необходимости обучения конкретной задаче. Эта мощная архитектура может быть использована в задачах, основанных на текстовых изображениях, для улучшения способности к обобщению.
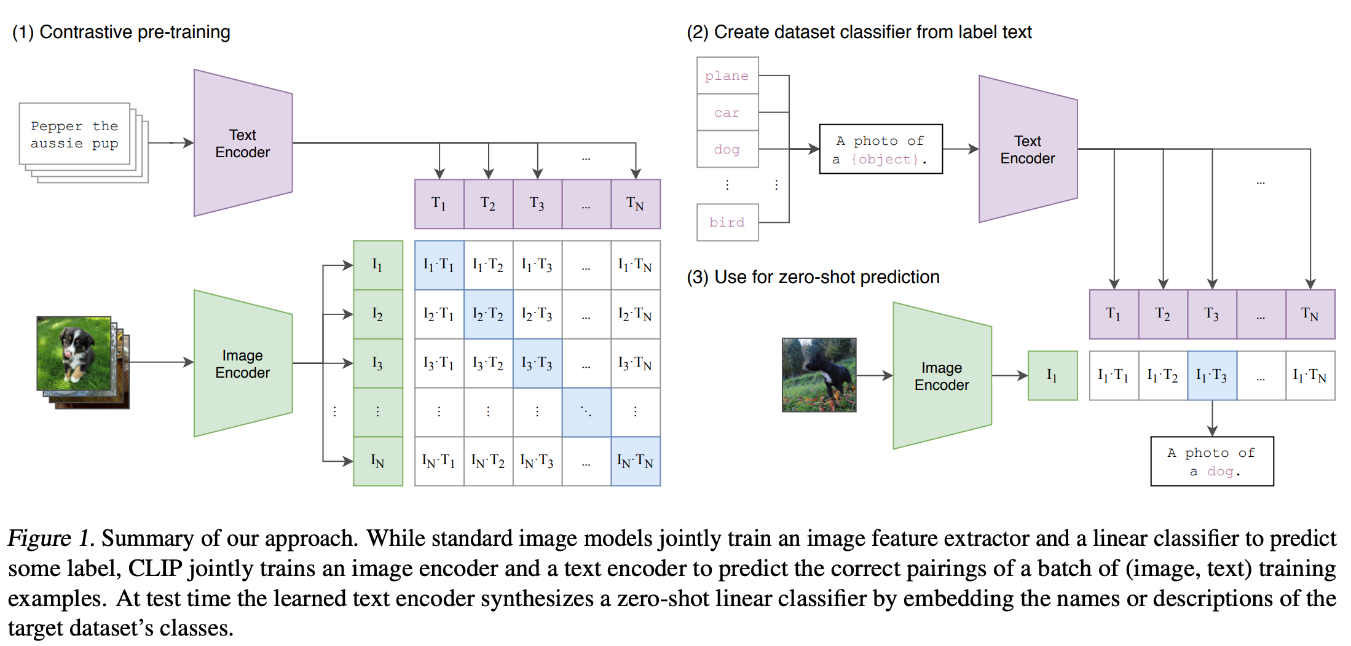 Рисунок 4- Архитектура модели CLIP.png
Рисунок 4- Архитектура модели CLIP.png
Рисунок 4. Архитектура модели CLIP
Некоторые закрытые модели этих архитектур включают:
Google Gemini: Мультимодальный LLM, отлично справляющийся с текстом, изображениями, видео и аудио, превосходящий GPT-4 по многим показателям.
ChatGPT (GPT-4V): Поддерживает текст, голос и изображения, позволяя пользователям взаимодействовать с голосами, генерируемыми ИИ, и генерировать изображения с помощью DALL-E 3.
Inworld AI: Создает интеллектуальных NPC для цифровых миров, позволяя общаться с помощью естественного языка, голоса и эмоций.
Meta ImageBind: Обрабатывает шесть модальностей, объединяя данные для таких задач, как создание изображений из аудио и обеспечение восприятия машинами окружающей среды.
Runway Gen-2: Генерирует и редактирует видео из текста, изображений или существующих видеозаписей, предлагая универсальные возможности создания контента.
Ознакомьтесь с этой статьей, чтобы узнать больше о мультимодальных моделях.
Мультимодальный RAG: выход за пределы текста
Retrieval Augmented Generation (RAG) - это метод получения контекстной информации для больших языковых моделей из внешних источников и генерации более точных результатов. Он также помогает смягчить галлюцинации ИИ и решить некоторые проблемы безопасности данных. Традиционный RAG был весьма эффективен для улучшения результатов работы LLM, но он по-прежнему ограничен текстовыми данными. Во многих реальных приложениях знания выходят за рамки текста, включая изображения, графики и другие модальности, которые обеспечивают критический контекст.
Ниже приведен обзор типичного рабочего процесса RAG на основе текста:
Пользователь отправляет в систему текстовый запрос.
Запрос преобразуется в векторное вложение, которое затем используется для поиска в векторной базе данных, такой как Milvus, где отрывки текста хранятся в виде вложений. Векторная база данных извлекает отрывки, которые близко соответствуют запросу, на основе векторного сходства.
Соответствующие отрывки текста передаются в LLM в качестве дополнительного контекста, обогащая его понимание запроса.
LLM обрабатывает запрос вместе с предоставленным контекстом, генерируя более обоснованный и точный ответ.
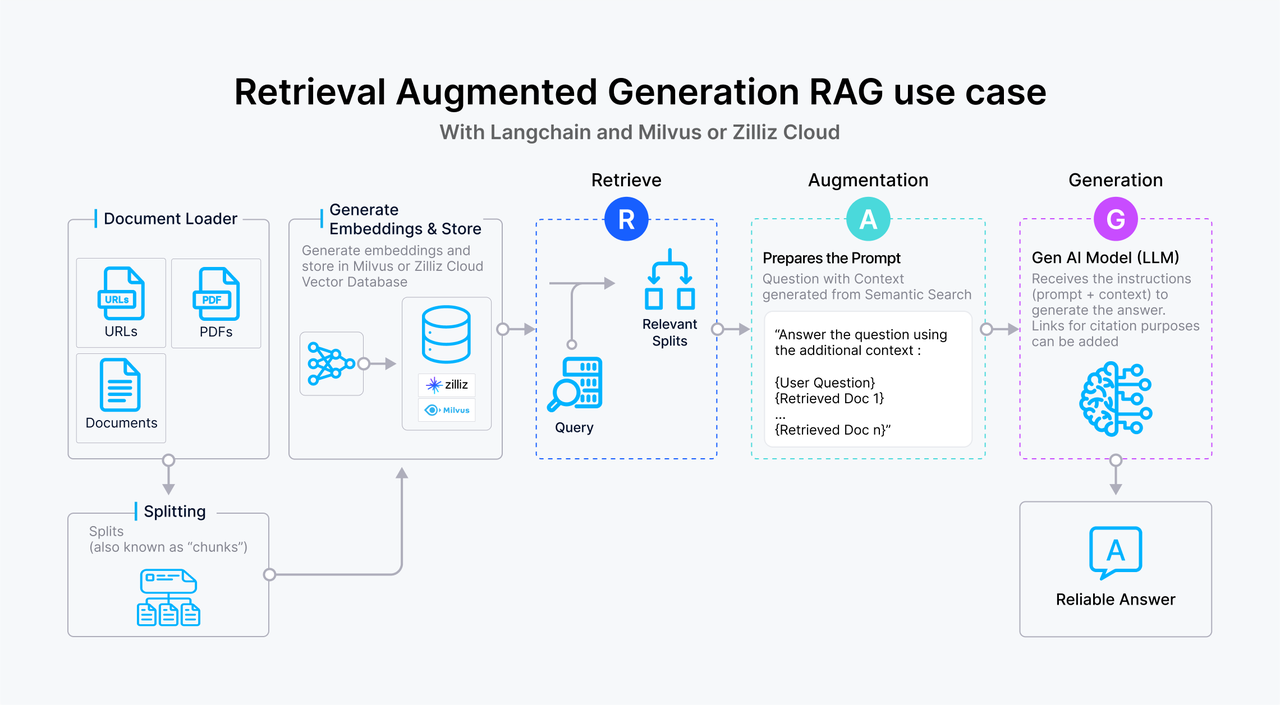 Рисунок 1 - Как работает RAG.png
Рисунок 1 - Как работает RAG.png
Рисунок: Как работает RAG
Мультимодальная система RAG устраняет вышеуказанное ограничение, позволяя использовать различные типы данных, обеспечивая лучший контекст для LLM. Проще говоря, в мультимодальной системе RAG компонент поиска ищет релевантную информацию в различных модальностях данных, а компонент генерации генерирует более точные результаты на основе полученной информации.
Чтобы создать такую систему, нам необходимо использовать мультимодальные модели для генерации вкраплений и LLM с мультимодальными возможностями, такие как LLAVA, GPT4-V, Gemini 1.5, Claude 3.5 Sonnet и т. д., для генерации ответов.
Существует несколько способов реализации мультимодального RAG:
Используйте модель мультимодального встраивания, например CLIP, для преобразования текстов и изображений в встраивания. Затем извлекаем релевантный контекст, выполняя поиск сходства между запросом и вкраплениями текста/изображения. Наконец, передайте исходный текст и/или изображение наиболее релевантного контекста в наш мультимодальный LLM.
Используйте мультимодальный LLM для создания текстовых обобщений изображений или таблиц. Затем преобразуйте эти текстовые обобщения во вкрапления с помощью модели вкрапления на основе текста. Затем выполните поиск текстового сходства между запросом и обобщенными вкраплениями. И наконец, передаем необработанное изображение наиболее релевантного резюме в наш LLM для генерации ответа.
Чтобы узнать больше о том, как создать мультимодальное приложение RAG, ознакомьтесь с нашими учебными пособиями по различным подходам, представленным ниже:
Build a Multimodal RAG with Gemini, BGE-M3, Milvus and LangChain
Build Better Multimodal RAG Pipelines with FiftyOne, LlamaIndex, and Milvus
Мультимодальная RAG: выход за пределы текста для более интеллектуального ИИ
Сравнение между унимодальной и мультимодальной системами
Мультимодальные системы отличаются от традиционных (унимодальных) тем, что они одновременно обрабатывают и интегрируют данные из нескольких типов входных модальностей (например, текст, изображения и аудио).
Мультимодальные системы имеют преимущество в понимании контекста, поскольку они извлекают информацию из двух источников: зрения и языка. Традиционные подходы более просты и ориентированы на конкретные области применения. Следующая таблица иллюстрирует некоторые критические различия между унимодальными и мультимодальными системами.
| Аспект | Традиционный ИИ | Мультимодальный ИИ | |
| Тип ввода | Использует один тип ввода (например, только текст, только изображение) | Обрабатывает несколько типов ввода (например, текст, изображения, аудио) | |
| Фокус обработки | Фокусируется на одной сенсорной модальности или модальности данных | Интегрирует и соотносит информацию с несколькими модальностями | |
| Сложность | Более простая и часто специфичная для конкретной области | Более сложная из-за необходимости интегрировать различные типы данных | |
| Понимание контекста | Ограничено информацией, доступной в одной модальности | Можно лучше понять контекст, используя различные модальности | |
| Применения | Классификация текста, обнаружение объектов, распознавание речи и т.д. | Взаимодействие человека и компьютера, робототехника, автономные транспортные средства, дополненная реальность и т. д. |
Преимущества и проблемы мультимодального ИИ
В этом разделе мы перечислим некоторые важные преимущества и связанные с ними проблемы, связанные с созданием и оценкой мультимодальных систем.
Преимущества
Ниже перечислены некоторые преимущества использования мультимодального ИИ:
Улучшенный контекст: Мультимодальные системы улавливают более широкий контекст за счет интеграции дополнительной информации из различных источников, например сочетания визуальных подсказок с языковыми для лучшей интерпретации.
Улучшенная производительность: Благодаря интеграции данных из нескольких модальностей мультимодальный ИИ может делать более точные прогнозы и принимать решения. Например, система медицинской диагностики может быть более надежной, если использовать изображения пациентов и медицинские карты.
Универсальность: Мультимодальный ИИ может применяться для решения различных сложных задач, включая создание подписей к изображениям, визуальные ответы на вопросы, медицинскую диагностику, автономное вождение и т. д., что делает его легко адаптируемым к различным областям.
Более человекоподобное понимание: Мультимодальный ИИ может лучше имитировать человеческое познание и обеспечивать более эффективное взаимодействие человека и компьютера в приложениях реального времени за счет обработки данных от различных органов чувств (модальностей).
Вызовы
Некоторые проблемы, связанные с использованием мультимодального ИИ, включают:
Представление: Метод или формат, в котором представлены модальности, извлекает дополнительную или избыточную информацию между несколькими модальностями. Мультимодальное представление данных является очень важным, но сложным из-за их неоднородной природы. Например, звук - это сигнал, а изображение - это 3D-представление с различными масштабами и размерами. Как привести их в одно общее пространство представления - важный момент реализации.
Перевод: Процедура может объяснить, как преобразовать или трансформировать данные из одной модальности в другую, если они неоднородны. Отношения между различными модальностями в основном субъективны. Например, перевод видео в соответствующее текстовое описание.
Слияние: Означает объединение данных из нескольких модальностей для улучшения прогнозирования. Например, при аудиовизуальном распознавании речи визуальное описание движения губ интегрируется с речевым сигналом для предсказания произносимых слов. Информация может поступать из разных модальностей и иметь различные уровни предсказательной силы, важности, вклада и топологии шума. По крайней мере в одной из модальностей имеются пропущенные значения данных.
Объяснимость: Недавно появившийся термин Explainable AI (XAI) направлен на объяснение осмысленных объяснений и рассуждений о модели. В случае с несколькими модальностями сложнее понять, как модели приходят к выводам, используя различные источники данных.
Часто задаваемые вопросы о мультимодальном ИИ
- **Что такое мультимодальный ИИ?
Мультимодальный ИИ - это тип системы искусственного интеллекта, которая может обрабатывать и анализировать информацию из различных модальностей, включая текст, изображения, аудио и видео.
- **Какие типы данных может использовать мультимодальный ИИ?
Мультимодальный ИИ использует различные типы данных, включая текст, изображения, аудио, видео, данные датчиков и графов.
- **Заменит ли мультимодальный ИИ традиционный ИИ?
Мультимодальный ИИ не заменяет традиционный ИИ, а расширяет его возможности за счет интеграции нескольких модальностей данных. Это расширение. Традиционные методы остаются важными, а мультимодальный ИИ предоставляет дополнительные возможности.
- **Каковы некоторые типичные области применения мультимодального ИИ?
Типичными приложениями мультимодального ИИ являются создание подписей к изображениям, визуальные ответы на вопросы, распознавание эмоций и автономное вождение.
- **Каковы преимущества мультимодального ИИ?
Мультимодальный ИИ имеет ряд преимуществ, включая надежность, эффективность, понимание контекста, разнообразную область применения и улучшенное взаимодействие человека и компьютера.
Связанные ресурсы
- Что такое мультимодальный ИИ?
- Как работает мультимодальный ИИ?
- Популярные мультимодальные модели и их архитектуры
- Мультимодальный RAG: выход за пределы текста
- Сравнение между унимодальной и мультимодальной системами
- Преимущества и проблемы мультимодального ИИ
- Часто задаваемые вопросы о мультимодальном ИИ
- Связанные ресурсы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно