




Понимание глубокого обучения с подкреплением (DRL): подробное руководство
Краткий ответ: Глубокое обучение с подкреплением (Deep Reinforcement Learning, DRL) — это область ИИ, в которой агент учится принимать решения, взаимодействуя со средой и со временем улучшаясь на основе обратной связи или «наград». DRL объединяет обучение с подкреплением (RL), метод обучения через пробы и ошибки, с глубоким обучением, которое позволяет агенту обрабатывать сложные данные, такие как изображения или показания датчиков. DRL может использовать глубокие нейронные сети, чтобы обучать агентов ориентироваться в сложных задачах с высокоразмерными входными данными. Оно широко используется в таких областях, как робототехника и игры, где традиционные методы обучения испытывают трудности из-за сложности и изменчивости среды.
Понимание глубокого обучения с подкреплением (DRL): подробное руководство
В 2016 году, когда AlphaGo победила чемпиона мира Ли Седоля в го — игре, в которой возможных ходов больше, чем атомов во Вселенной, — это стало переломным моментом в бизнес-технологиях. Секрет этой победы? Глубокое обучение с подкреплением — метод, который обучает компьютеры совершенствоваться через практику, подобно теннисисту, который годами на корте оттачивает свою подачу. Там, где традиционные компьютерные программы испытывают трудности с неожиданными изменениями, эта технология особенно эффективна в ситуациях, которые постоянно меняются, — от управления роботами на загруженных складах до принятия быстрых решений в биржевой торговле. Этот новый подход к машинному обучению открывает для бизнеса новые возможности, помогая решать задачи, которые раньше были слишком сложными для обычного программного обеспечения.
Это руководство предлагает глубокое исследование глубокого обучения с подкреплением, выделяя ключевые концепции, его различные применения, преимущества и проблемы, которые могут возникнуть при его внедрении.
Что такое глубокое обучение с подкреплением?
Глубокое обучение с подкреплением (Deep Reinforcement Learning, DRL) объединяет две эффективные техники ИИ, обучение с подкреплением (Reinforcement Learning, RL) и глубокое обучение, позволяя ИИ-агентам изучать оптимальные действия методом проб и ошибок в сложных средах. В RL агент взаимодействует со своей средой и корректирует свое поведение на основе наград и стратегий обучения, чтобы максимизировать долгосрочные награды. Глубокое обучение добавляет возможность обрабатывать подробные представления состояний с помощью нейронных сетей.
Например, робот, перемещающийся по лабиринту, сначала движется случайным образом, но со временем учится эффективно достигать цели благодаря обратной связи. DRL помогает агентам адаптироваться к динамическим средам и решать сложные задачи без подробных инструкций. Оно полезно в видеоиграх, беспилотных автомобилях и персональных рекомендациях. Объединяя обучение с подкреплением и глубокое обучение, DRL-агенты могут эффективно справляться со сложными реальными задачами.
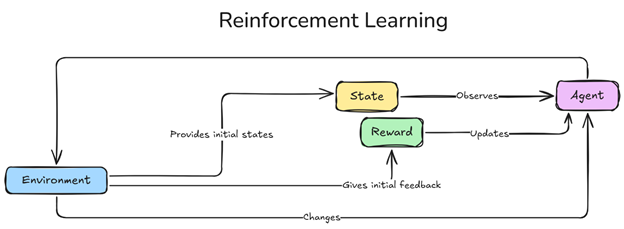 Рисунок 1. Схема обучения с подкреплением.png
Рисунок 1. Схема обучения с подкреплением.png
Как работает глубокое обучение с подкреплением
Чтобы понять, как работает DRL, важно знать его ключевые компоненты:
Агент
Среда
Состояние
Действия и награды
Политика
Агент
Агент — это лицо, принимающее решения, которому поручено ориентироваться в среде и делать выбор, чтобы со временем максимизировать совокупные награды. Через повторяющиеся взаимодействия (эпизоды обучения) агент совершенствует свою стратегию на основе обратной связи, корректируя свое поведение для достижения долгосрочного успеха. Подобно игроку в игре, действия агента направляются политикой — набором правил, изученных со временем для повышения эффективности и достижения оптимальных результатов.
Среда
Среда — это структурированное пространство, в котором действует агент, определяющее возможные состояния, действия и награды. Она реагирует на каждое действие агента, предоставляя обратную связь, которая влияет на будущие решения агента и формирует его процесс обучения.
Состояние
Состояние представляет собой снимок среды в определенный момент, содержащий информацию, важную для принятия решений агентом. Например, состояние может включать позицию агента и препятствия в лабиринте или скорость транспортного средства и его близость к другим автомобилям. Каждое состояние помогает агенту оценить свою ситуацию и выбрать наиболее выгодное действие.
Действия и вознаграждения
Действия представляют собой варианты выбора агента в каждом состоянии, направляя его путь через среду. Действия могут быть:
Дискретные действия: Ограниченные варианты, такие как движение вверх, вниз, влево или вправо, в сеточных средах упрощают агентам исследование и разработку политик.
Непрерывные действия: Они включают диапазон значений, например регулировку скорости или угла, что требует продвинутых моделей для работы с возросшей сложностью.
Агент стремится со временем совершать оптимальные действия и максимизировать вознаграждения.
Вознаграждения обеспечивают обратную связь, направляющую обучение агента. Положительные вознаграждения сигнализируют об успешных действиях, тогда как отрицательные вознаграждения наказывают за ошибки. Вознаграждения могут включать:
Немедленные вознаграждения: Они предоставляются непосредственно после действия, например начисление очков за взятие фигуры соперника в шахматах.
Отложенные вознаграждения: Получаются после завершения последовательности действий, например прохождения лабиринта.
Важно проектировать структуру вознаграждений, известную как формирование вознаграждения. Например, промежуточные вознаграждения на сложном пути могут ускорить обучение, мотивируя агента выполнять конкретные шаги к конечной цели.
 Рисунок- архитектура обучения с подкреплением.png
Рисунок- архитектура обучения с подкреплением.png
Рисунок: архитектура обучения с подкреплением
Процесс обучения
Процесс обучения или тренировки глубокого обучения с подкреплением представляет собой итеративный цикл взаимодействия, обратной связи и улучшения, который включает:
Исследование
Использование
Глубокие нейронные сети
Обратное распространение ошибки
Исследование
Изначально агент не знает среды. Он начинает с случайного исследования, пробуя различные действия и наблюдая последствия. Этот этап исследования важен для сбора информации о среде и обнаружения действий, приносящих вознаграждение.
Использование
По мере того как агент исследует и накапливает опыт, он начинает выявлять действия, которые приводят к положительным вознаграждениям. Затем он использует эти знания, выбирая такие действия чаще, чтобы максимизировать свои вознаграждения.
Глубокие нейронные сети
Агент использует глубокие нейронные сети для аппроксимации политики агента и функции ценности.
Сеть политики: Эта сеть принимает текущее состояние на вход и выводит вероятность выполнения различных действий.
Сеть ценности: Эта сеть оценивает долгосрочную ценность нахождения в определенном состоянии, помогая агенту принимать решения, которые приводят к более высоким совокупным вознаграждениям. Эти нейронные сети позволяют агенту изучать сложные закономерности и связи в среде, помогая принимать более интеллектуальные решения.
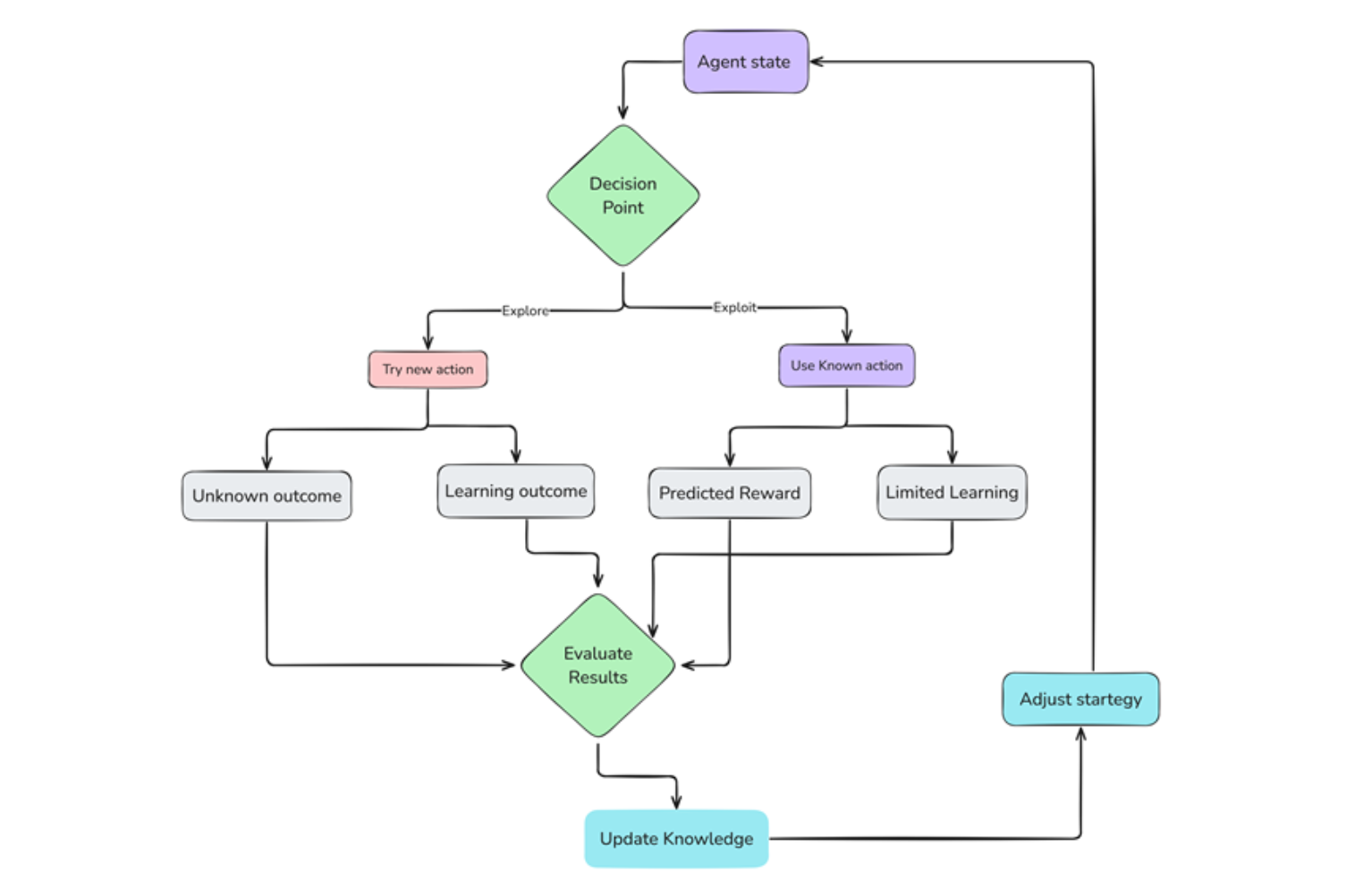 Процесс исследования и использования .png
Процесс исследования и использования .png
Рисунок 3 Процесс исследования и использования
Обратное распространение ошибки
Обратное распространение ошибки, сокращенно от "backward propagation of errors," является ключевым алгоритмом при обучении нейронных сетей. Оно корректирует веса в нейронной сети, чтобы минимизировать ошибку в прогнозах.
Обратное распространение ошибки помогает агентам улучшать свои модели принятия решений за счет обучения на основе обратной связи. Когда агент выполняет действие, он получает обратную связь о том, насколько хорошим или плохим было это действие (в форме вознаграждения). Затем обратное распространение ошибки корректирует веса нейронной сети, уменьшая ошибку между предсказанными результатами и фактическими вознаграждениями. При многократном применении обратного распространения ошибки нейронная сеть учится лучше аппроксимировать функции ценности или политики, что приводит к более точным решениям. Этот процесс позволяет агенту постепенно улучшать свое понимание среды и со временем принимать все более оптимальные решения, что необходимо для освоения сложных задач в динамических, высокоразмерных средах.
Популярные алгоритмы в глубоком обучении с подкреплением
DRL использует множество алгоритмов, каждый из которых предназначен для решения различных задач в процессе обучения. Вот некоторые из наиболее широко используемых методов:
Q-Learning: Q-Learning — один из фундаментальных алгоритмов обучения с подкреплением. Он оценивает ценность пар «состояние-действие», называемых Q-значениями, помогая агенту определить, какие действия предпочтительны в определенных состояниях. Алгоритм обновляет эти Q-значения на основе немедленных вознаграждений и ожидаемых будущих вознаграждений, постепенно уточняя выбор агента в пользу действий с более высокой долгосрочной ценностью.
Deep Q-Networks (DQN): DQN улучшает Q-learning, используя нейронные сети для аппроксимации Q-значений. Этот подход делает DQN эффективными в сложных средах, таких как игровой ИИ, роботизированная навигация и автономное вождение.
Policy Gradients: В отличие от методов, основанных на ценности, алгоритмы градиентов политики напрямую оптимизируют политику агента, корректируя веса нейронной сети на основе полученных вознаграждений. Этот подход позволяет агенту повышать производительность, увеличивая вероятность успешных действий, что особенно важно в задачах управления, требующих точных корректировок, таких как манипулирование роботизированной рукой.
Actor-Critic Methods: Гибридные подходы объединяют сильные стороны методов, основанных на политике, которые стремятся оценить ценность каждого действия в данном состоянии, и методов, основанных на ценности, которые сосредоточены на прямом обучении оптимальной политике. В этой схеме актор отвечает за выбор действий, а критик оценивает эти действия и предоставляет обратную связь. Эта обратная связь обеспечивает постоянное улучшение политики.
Сравнение глубокого обучения с подкреплением с другими концепциями
Глубокое обучение с подкреплением (DRL) часто сравнивают с другими подходами ИИ. Чтобы прояснить различия и сходства, разберем ключевые аспекты:
| Аспект | Глубокое обучение с подкреплением (DRL) | Обычное обучение с подкреплением (RL) | Обучение с учителем | Обучение без учителя | |
| Основная концепция и работа с данными | Объединяет RL с глубокими нейронными сетями; обрабатывает многомерные, сложные данные | Сосредоточено на RL с более простыми моделями; хорошо работает в средах с низкой размерностью | Обучается на размеченных данных с заранее заданными выходами; опирается на размеченные наборы данных | Находит закономерности в неразмеченных данных; работает с неразмеченными наборами данных | |
| Процесс обучения | Метод проб и ошибок через взаимодействие со средой. | Метод проб и ошибок через обратную связь от среды. | Изучает закономерности на размеченных парах «вход-выход». | Выявляет кластеры или структуры в данных. | |
| Цель | Максимизировать совокупное вознаграждение с течением времени. | Максимизировать совокупное вознаграждение с течением времени. | Предсказывать выходы на основе входных данных. | Обнаруживать скрытые закономерности или группировки в данных. | |
| Применения | Сложные задачи: ИИ для игр, робототехника, автономные транспортные средства. | Базовые системы управления и простые задачи принятия решений. | Классификация, регрессия, прогнозное моделирование. | Кластеризация, снижение размерности, обнаружение аномалий. |
Преимущества и вызовы глубокого обучения с подкреплением
Глубокое обучение с подкреплением обладает множеством возможностей, но важно понимать, в чём оно сильно и где может оказаться недостаточно эффективным. Рассмотрим некоторые основные преимущества и вызовы DRL.
Преимущества:
Адаптивность: Одно из ключевых преимуществ DRL — его адаптивность. Агенты DRL могут справляться с новыми и неожиданными ситуациями без необходимости дополнительного программирования. Например, автономный автомобиль на базе DRL может реагировать на внезапные изменения на дороге, такие как препятствия или неблагоприятная погода, корректируя своё поведение для безопасного движения.
Оптимальное принятие решений: DRL также обеспечивает более умное и зачастую более эффективное принятие решений. В отличие от традиционных систем, основанных на правилах, модели DRL могут находить стратегии, которые могли бы упустить даже разработчики-люди. Например, в финансах DRL успешно применяется для создания торговых ботов, которые часто принимают более прибыльные решения, чем традиционные системы.
Потенциал автоматизации: DRL позволяет автоматизировать задачи в таких областях, как перемещение товаров, медицинская помощь и обслуживание клиентов. В этих часто сложных и постоянно меняющихся сферах DRL помогает упрощать процессы за счёт их автоматизации.
Вызовы:
Эффективность выборки: Один из самых больших вызовов DRL — его потребность в огромных объёмах обучающих данных. Моделям DRL обычно требуется обширный набор данных для хорошей работы, сбор которого может быть дорогостоящим и трудоёмким. Такие методы, как experience replay, помогают, позволяя моделям учиться на прошлых данных, но для того, чтобы сделать DRL более практичным, всё ещё необходимы улучшения в эффективности использования данных.
Проектирование вознаграждения: Ещё один вызов заключается в разработке эффективных функций вознаграждения. Правильная настройка вознаграждений имеет решающее значение, потому что плохо спроектированные вознаграждения могут привести к непреднамеренному и иногда проблемному поведению агентов. В результате проектирование вознаграждений в DRL требует тщательного планирования, чтобы гарантировать, что агенты действуют в соответствии с заданными целями.
Стабильность и сходимость: Наконец, обучение DRL может быть нестабильным. Иногда модели застревают на неидеальных стратегиях или не достигают стабильного решения. Повышение стабильности обучения крайне важно для того, чтобы сделать модели DRL более надёжными, особенно для приложений с высокими ставками, где ключевое значение имеет согласованность.
Реальные применения глубокого обучения с подкреплением
Теперь, когда мы изучили принципы работы глубокого обучения с подкреплением (DRL), давайте переключим внимание на его практические применения. DRL используется для решения реальных проблем в различных областях. Включая:
Игры: DRL позволило создавать продвинутых AI-агентов, которые превосходно справляются с такими играми, как Chess, Go и Dota 2. Для тех, кто интересуется практическим изучением, Unity ML-Agents предоставляет доступный набор инструментов для экспериментов с обучением на основе игр.
Робототехника: В робототехнике DRL обучает машины таким навыкам, как навигация и манипулирование объектами. DRL оказывается высокоэффективным на складах, позволяя роботам адаптироваться к новым планировкам и меняющимся задачам, повышая эффективность операций.
Автономные транспортные средства: В беспилотных автомобилях DRL играет важнейшую роль в принятии мгновенных решений при смене полосы, объезде препятствий или регулировке скорости. Waymo, например, использует DRL, чтобы помогать своим автомобилям принимать безопасные решения в сложных дорожных ситуациях.
Финансовая торговля: DRL также широко используется в финансах для разработки торговых ботов, которые реагируют на изменения рынка. Используя такие подходы, как Deep Q-Learning, торговые боты на базе DRL анализируют исторические тренды и данные в реальном времени, чтобы принимать обоснованные решения о покупке, удержании или продаже, часто достигая лучших результатов, чем ручные торговые стратегии.
Персонализированные рекомендации: DRL лежит в основе всё более продвинутых систем рекомендаций. Чтобы предоставлять персонализированные рекомендации, алгоритмы DRL анализируют поведение и предпочтения пользователей в стриминговых сервисах, интернет-магазинах и социальных сетях. Наблюдая за действиями пользователей, DRL может рекомендовать контент или продукты, которые более точно соответствуют индивидуальным предпочтениям.
Часто задаваемые вопросы о глубоком обучении с подкреплением
- Как агент обучается в глубоком обучении с подкреплением?
В DRL агент обучается, выполняя действия в среде и получая обратную связь в виде вознаграждений. Агент использует исследование (пробует новые действия), чтобы находить эффективные стратегии, и использование (применяет известные действия), чтобы максимизировать вознаграждения. Глубокие нейронные сети помогают агенту обобщать свой опыт и адаптироваться к сложным сценариям.
- Как модели глубокого обучения с подкреплением балансируют исследование и использование?
Модели DRL балансируют исследование (пробуют новые действия, чтобы обнаружить лучшие стратегии) и использование (применяют известные действия, чтобы максимизировать вознаграждения) с помощью алгоритмов вроде epsilon-greedy или Thompson Sampling. Эти методы помогают поддерживать баланс, обеспечивая агенту возможность обнаруживать новые стратегии и одновременно максимизировать известные вознаграждения.
- Как работают функции ценности в глубоком обучении с подкреплением?
Функции ценности оценивают ожидаемое вознаграждение от нахождения в определённом состоянии (функция ценности состояния) или выполнения конкретного действия в заданном состоянии (функция ценности действия). Они помогают агенту приоритизировать состояния и действия, ведущие к более высоким вознаграждениям, направляя принятие решений.
- Как можно использовать DRL с Milvus для AI-приложений?
Milvus может хранить и управлять высокоразмерными представлениями состояний, генерируемыми агентами DRL. Он может служить буфером воспроизведения для прошлого опыта или помогать в хранении представлений состояний, повышая эффективность оптимизации политики и оценки ценности.
- Каковы этические проблемы использования глубокого обучения с подкреплением?
Этические проблемы включают потенциальные смещения в обучающих данных, непреднамеренное поведение, возникающее из-за плохо спроектированных функций вознаграждения, и вопросы справедливости в чувствительных приложениях. Чтобы снизить эти риски, крайне важно внедрять надежное тестирование, прозрачность и объяснимый ИИ.
Связанные ресурсы
Для дальнейшего изучения рассмотрите эти ресурсы:
- Что такое глубокое обучение с подкреплением?
- Как работает глубокое обучение с подкреплением
- Популярные алгоритмы в глубоком обучении с подкреплением
- Сравнение глубокого обучения с подкреплением с другими концепциями
- Преимущества и вызовы глубокого обучения с подкреплением
- Реальные применения глубокого обучения с подкреплением
- Часто задаваемые вопросы о глубоком обучении с подкреплением
- Связанные ресурсы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно