




Создание многоязычного RAG с помощью Milvus, LangChain и OpenAI LLM
За последние два года Retrieval Augmented Generation (RAG) быстро стала одной из самых популярных техник для создания приложений GenAI на основе больших языковых моделей (LLMs). По своей сути RAG улучшает результаты работы LLM, предоставляя контекстную информацию, на которой модель не была предварительно обучена. Многоязычный RAG - это расширенный RAG, который работает с текстовыми данными на нескольких языках.
Юцзянь Тан, генеральный директор OSS4AI, недавно выступил на Unstructured Data Meetup, организованном Zilliz. Он рассказал о RAG и его фундаментальных компонентах, а также продемонстрировал, как построить многоязычный RAG для решения различных реальных языковых задач.
В этом посте мы расскажем о ключевых моментах из презентации Юдзяна и подскажем, как реализовать многоязычную RAG. Если вы хотите узнать больше о выступлении Юдзяна, рекомендуем посмотреть его презентацию на YouTube.
.Что такое RAG и как он работает?
Одним из основных ограничений приложений, работающих на LLM, является их зависимость от данных, на которых они были обучены. Если во время предварительного обучения LLM не была представлена определенная информация или целая область знаний, он не сможет понять лингвистические связи, необходимые для создания точных ответов. Отсутствие данных может привести к тому, что LLM либо признается, что не знает ответа, либо, что еще хуже, "галлюцинирует" и предоставит неверную информацию.
RAG - это популярная техника, которая решает проблему галлюцинаций у LLM, предоставляя им дополнительную контекстную информацию. Она также позволяет разработчикам и предприятиям получить доступ к частным или проприетарным данным, не беспокоясь о проблемах безопасности.
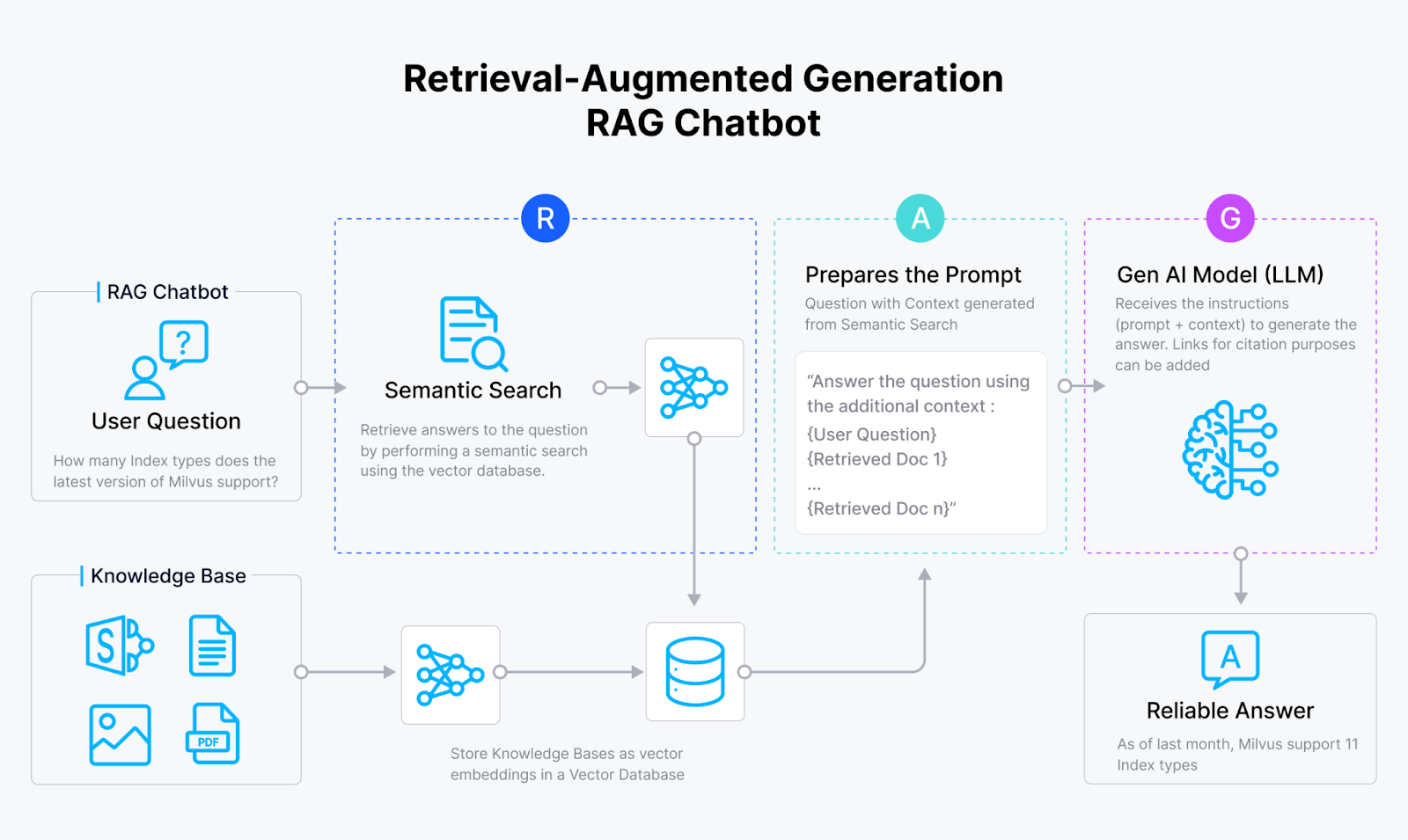 Рисунок 1 - Как работает RAG
Рисунок 1 - Как работает RAG
RAG начинается с модели встраивания, которая преобразует текстовые данные в векторные встраивания, числовые представления, отражающие семантический смысл текста. Затем система RAG хранит эти векторы в векторной базе данных, например Milvus или Zilliz Cloud, которая индексирует их для поиска сходстваh.
Когда пользователь отправляет запрос, модель встраивания также преобразует его в вектор. Затем система RAG сравнивает сходство вектора запроса с векторами в базе данных векторов, вычисляя их расстояние в высокоразмерном векторном пространстве. Если соответствующие данные найдены, система RAG извлекает эту информацию и добавляет ее к исходному запросу, чтобы сформировать новый запрос для LLM. LLM использует эту дополнительную информацию для генерации более точного и контекстуально релевантного ответа, превосходящего тот, который он мог бы выдать, основываясь только на обучающих данных.
Что такое многоязычный RAG?
Многоязычный RAG расширяет возможности традиционного RAG для поддержки нескольких языков. В него интегрирована модель встраивания, обученная на разных языках, что позволяет системе обрабатывать и генерировать ответы на разных языках. Используя этот многоязычный подход, система RAG может обрабатывать запросы на любом языке, получать релевантную информацию независимо от языка оригинала и предоставлять точные, контекстуально релевантные ответы на предпочтительном для пользователя языке.
Как создать многоязычное приложение RAG: пошаговое руководство
Теперь, когда мы узнали основные концепции и компоненты RAG, давайте шаг за шагом реализуем многоязычное приложение RAG.
Этот пример содержит две части: веб-скребок и основное приложение.
Веб-скрепер** берет нужный набор данных из интернета.
Основное приложение** создает векторные вкрапления, выполняет поиск векторного сходства и генерирует ответы.
Веб-скребок
Сначала мы возьмем данные из Wikipedia и используем их в качестве контекстной информации для этого примера RAG.
Определение названий: Мы начинаем с определения списка
wiki_titles, который содержит список городов. Каждый город представляет собой текстовый файл, который веб-скрепер будет заполнять содержимым соответствующей записи Википедии. Например, "Atlanta.txt" будет содержать текст, взятый со страницы Атланты в Википедии.Скрап данных: Мы перебираем каждый город в
wiki_titles, делаем GET-запрос к Wikipedia API и извлекаем содержимое страницы из JSON-ответа. Затем текст сохраняется в соответствующий текстовый файл для каждого города.
from pathlib import Path
импорт запросов
wiki_titles = [
"Атланта",
"Берлин",
"Бостон",
"Каир",
"Чикаго",
"Копенгаген",
"Хьюстон",
"Карачи",
"Лиссабон",
"Лондон",
"Москва",
"Мюнхен",
"Париж",
"Пекин", # французское название Пекина
"Сан-Франциско",
"Сиэтл",
"Шанхай",
"Токио",
"Торонто",
]
data_path = Path("./french_city_data")
data_path.mkdir(exist_ok=True) # Убедитесь, что каталог существует
for title in wiki_titles:
response = requests.get(
"https://fr.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": "title",
"prop": "extracts",
"explaintext": True,
},
).json()
page = next(iter(response["query"]["pages"].values()))
wiki_text = page.get("extract", "") # Используйте .get(), чтобы избежать KeyError
if wiki_text: # Проверьте, не пуст ли экстракт
with open(data_path / f"{title}.txt", "w") as fp:
fp.write(wiki_text)
else:
print(f "Не найден экстракт для {title}")
Подготовка окружения
Сначала настройте среду разработки, установив необходимые библиотеки: Milvus vector database, LangChain, OpenAI и sentence transformers.
Кроме того, вам нужно будет указать свой API-ключ, если вы подключаетесь к LLM через API, например, OpenAI. Этот ключ можно хранить в отдельном файле .env и получить к нему доступ с помощью load_dotenv() и os .
Вот код для установки библиотек и загрузки ключа API:
!pip install -qU pymilvus langchain sentence-transformers tiktoken openai
из dotenv import load_dotenv
импортировать os
load_dotenv() # Загрузите переменные окружения из файла .env
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY") # Установка ключа API
Установка библиотек: Используйте
pipдля установкиpymilvus,langchain,entence-transformers,tiktoken, иopenai.Загрузка переменных окружения: Используйте
dotenvдля загрузки переменных окружения из файла.env.Установка ключа API: Получите ключ API OpenAI из переменных окружения и установите его.
Убедитесь, что ваш файл .env содержит ваш ключ OpenAI API в следующем формате:
OPENAI_API_KEY=ваш_api_ключ_здесь
Инициализация LLM
После настройки среды следующим шагом будет определение LLM, который вы будете использовать в своем приложении. В приведенном ниже фрагменте кода мы достигли этого, импортировав библиотеку OpenAI и определив LLM с помощью конструктора OpenAI.
from langchain.llms import OpenAI
llm = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
Вы можете выбрать LLM с открытым исходным кодом, чтобы избежать расходов, связанных с вызовами API OpenAI. Hugging Face предлагает сотни тысяч моделей глубокого обучения, с которыми можно экспериментировать. Чтобы использовать LLM с открытым исходным кодом от HuggingFace, вам нужно импортировать библиотеку Transformers.
from transformers import pipeline
llm = pipeline('text-generation', model='gpt2') # Замените 'gpt2' на нужную вам модель
Вы можете переключаться между OpenAI и моделью с открытым исходным кодом, изменяя соответствующий код импорта и инициализации.
Выбор подходящей модели встраивания
При создании многоязычной RAG-системы выбор модели встраивания так же важен, как и выбор LLM, поскольку модель встраивания должна быть совместима с языком, с которым вы работаете. Для данного примера, где языком является французский, достаточно вкраплений HuggingFace, используемых по умолчанию. Однако вы должны определить и использовать наиболее подходящую модель встраивания для других языков.
MTEB Leaderboard на HuggingFace - ценный ресурс для поиска моделей встраивания. На этой доске лидеров перечислены наиболее эффективные модели встраивания для различных языков, например, китайские и польские встраивания, определенные Юдзяном. При выборе модели встраивания необходимо указать имя модели в качестве параметра.
Вот как настроить модель встраивания:
from langchain_community.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings()
# Как вариант, для китайских вкраплений модель # передается в качестве параметра, например,
# HuggingFaceEmbeddings(model_name="TownsWu/PEG")
Загрузка и разбиение данных на фрагменты
Далее загрузите файлы с данными о городах, которые мы взяли из Википедии, и разделите их на сегменты, или куски. Разбивая текст на фрагменты, мы избегаем сравнения запроса со всем документом, что повышает эффективность поиска информации. Чем меньше кусок, определяемый параметром chunk_size, тем выше точность, но тем больше операций поиска требуется. Чем больше перекрытие между фрагментами, определяемое параметром chunk_overlap, тем меньше вероятность потери контекста - ценой увеличения избыточности.
from langchain.text_splitter import CharacterTextSplitter
из langchain.schema import Document
files = os.listdir("./french_city_data")
file_texts = []
for file in files:
with open(f"./french_city_data/{file}") as f:
file_text = f.read()
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=512, chunk_overlap=64,
)
тексты = text_splitter.split_text(file_text)
for i, chunked_text in enumerate(texts):
file_texts.append(Document(page_content=chunked_text,
metadata={"doc_title": file.split(".")[0], "chunk_num":i})
Загрузка документов в Milvus
После разбивки файлов с городскими данными и сохранения их в виде списка документов нам необходимо загрузить их в векторное хранилище - в данном случае в векторную базу данных Milvus. Приведенный ниже код обрабатывает первоначальную загрузку и обновления, когда городские данные сохраняются в Milvus.
from langchain_community.vectorstores import Milvus
# Для первого запуска
vector_store = Milvus.from_documents(
file_texts,
embedding=embeddings,
connection_args={"host": "localhost", "port": 19530},
collection_name="french_cities"
)
# если ваши данные уже хранятся в Milvus
vector_store = Milvus(
embedding_function=embeddings,
connection_args={"host": "localhost", "port": 19530},
collection_name="french cities"
)
Создайте ретривера
Далее мы инициализируем наш ретривер - интерфейс, который возвращает документы из определенного источника на основе заданного запроса. В приведенном ниже коде в качестве ретривера используется векторное хранилище, которое мы создали на предыдущем шаге, и оно присваивается переменной.
retriever = vector_store.as_retriever()
Создание шаблона подсказки с использованием LangChain
Шаблоны подсказок позволяют вам точно форматировать ввод LLM в вашем приложении. Они особенно полезны в тех случаях, когда вы хотите повторно использовать один и тот же шаблон подсказки, но с небольшими изменениями - как в нашем многоязычном приложении RAG, где мы можем использовать один и тот же шаблон подсказки для разных языков.
Шаблоны подсказок также позволяют создавать подсказки на основе динамического ввода, например, пользовательского ввода или данных, получаемых из векторного хранилища. В нашем приложении мы будем динамически включать вопрос, который будет передаваться в цепочку напрямую, и контекст, полученный ретривером из векторного хранилища.
from langchain.prompts import ChatPromptTemplate
template="""
Вы являетесь помощником при решении задач, связанных с ответами на вопросы. Используйте следующие фрагменты полученного контекста, чтобы ответить на вопрос. Если вы не знаете ответа, просто скажите, что не знаете.
Используйте не более трех предложений и будьте лаконичны в ответе.
Отвечайте на французском языке.
Вопрос: {вопрос}
Контекст: {контекст}
Ответ:"""
prompt = ChatPromptTemplate.from_template(template)
Соединение компонентов вместе для создания приложения RAG
Цепочка - это процесс, соединяющий компоненты для создания сквозных приложений искусственного интеллекта, что является одной из ключевых возможностей LangChain.
Приведенный ниже код демонстрирует, как построить цепочку, включающую следующие элементы: контекст от ретривера, входной запрос, обрабатываемый функцией runnablepassthrough(), шаблон запроса, LLM и stroutparser(), который выводит ответ от вызова цепочки.
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
цепочка = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
Создание запросов с помощью цепочки
После того как цепочка построена, вы можете вызывать ее с помощью различных запросов. Например:
response = chain.invoke("Расскажите мне исторический факт о Карачи").
Этот запрос дает следующий ответ на французском языке!
"Карачи упоминается в первый раз в книге "История растений Теофраста III века". J.-C. В 1839 году она была оккупирована британцами в начале XIX века и стала столицей Синда. В 1876 году будущий основатель Пакистана Мухаммад Али Джинна родился и вырос в Карачи".
Чтобы продемонстрировать возможности многоязычия, вот еще один запрос - на этот раз на французском:
response_2 = chain.invoke("Racontez-moi un fait historique sur Karachi.")
Несмотря на один и тот же основной вопрос, разные языки (английский и французский) приводят к разным вкраплениям, что приводит к разным результатам:
"Карачи - это город, основанный британцами в начале XIX века и ставший столицей провинции Синд. Он стал важным экономическим центром и быстро развивался, в том числе благодаря своему порту. С 1980 года город стал ареной этнических и религиозных конфликтов, а в 2012 году в нем произошел промышленный пожар, ставший самым страшным в истории страны".
Поздравляем! Вы успешно создали многоязычное приложение RAG. Помните, что вкрапления играют центральную роль в том, как LLM интерпретирует языки. Выберите наиболее подходящую вставку для поддержки нескольких языков и интегрируйте ее в свое приложение.
Резюме
Ух ты! Это довольно длинный пост. Давайте вспомним некоторые ключевые моменты.
Retrieval augmented generation (RAG) - это фреймворк, который расширяет вывод LLM, вставляя дополнительные данные в подсказки ввода. RAG может решить раздражающие проблемы галлюцинаций в LLM.
Многоязычный RAG - это расширенный RAG, который работает с многоязычными документами.
Модели встраивания, векторные базы данных и LLM - три основных компонента приложений RAG.
Ключевым моментом при разработке многоязычных приложений RAG является выбор модели встраивания. Доска лидеров HuggingFace MTEB - отличный ресурс для поиска подходящей модели для вашего приложения.
Дополнительные ресурсы
Top Performing Embedding Models for Your GenAI Apps | Zilliz
Техники улучшения RAG:
Читать далее

Introducing Zilliz Cloud Global Cluster: Region-Level Resilience for Mission-Critical AI
Zilliz Cloud Global Cluster delivers multi-region resilience, automatic failover, and fast global AI search with built-in security and compliance.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.