




Представляем DeepSearcher: Локальное глубокое исследование с открытым исходным кодом
 deep researcher.gif
deep researcher.gif
В предыдущей заметке "Я построил глубокое исследование с открытым исходным кодом - и вы тоже можете!" мы объяснили некоторые принципы, лежащие в основе исследовательских агентов, и создали простой прототип, генерирующий подробные отчеты по заданной теме или вопросу. Статья и соответствующий блокнот продемонстрировали фундаментальные концепции использования инструментов, декомпозиции запросов, рассуждения и рефлексии. Пример в нашей предыдущей заметке, в отличие от Deep Research от OpenAI, выполнялся локально, с использованием только моделей и инструментов с открытым исходным кодом, таких как Milvus и LangChain. (Я рекомендую вам прочитать вышеупомянутую статью, прежде чем продолжить).
В последующие недели произошел взрыв интереса к пониманию и воспроизведению глубоких исследований OpenAI. Смотрите, например, Perplexity Deep Research и Hugging Face's Open DeepResearch. Эти инструменты отличаются по архитектуре и методологии, хотя имеют общую цель: итеративно исследовать тему или вопрос, просматривая веб-страницы или внутренние документы, и выдать подробный, обоснованный и хорошо структурированный отчет. Важно, что базовый агент автоматизирует рассуждения о том, какие действия следует предпринять на каждом промежуточном этапе.
В этом посте мы развиваем наш предыдущий пост и представляем проект с открытым исходным кодом Zilliz DeepSearcher. Наш агент демонстрирует дополнительные концепции: маршрутизация запросов, условный поток выполнения и ползание по паутине как инструмент. Он представлен в виде библиотеки Python и инструмента командной строки, а не блокнота Jupyter, и является более полнофункциональным, чем наш предыдущий пост. Например, он может вводить несколько исходных документов и задавать модель встраивания и используемую векторную базу данных через конфигурационный файл. Несмотря на свою относительную простоту, DeepSearcher является отличным примером агентного RAG и еще одним шагом на пути к созданию современных приложений ИИ.
Кроме того, мы изучаем потребность в более быстрых и эффективных сервисах вывода. Модели рассуждений используют "масштабирование выводов", то есть дополнительные вычисления, для улучшения своих результатов, и это в сочетании с тем фактом, что один отчет может потребовать сотни или тысячи вызовов LLM, приводит к тому, что пропускная способность выводов становится основным узким местом. Мы используем модель рассуждений DeepSeek-R1 на аппаратном обеспечении SambaNova, которая в два раза быстрее по количеству выдаваемых токенов в секунду, чем ближайший конкурент (см. рисунок ниже).
SambaNova Cloud также предоставляет услуги по обработке выводов для других моделей с открытым исходным кодом, включая Llama 3.x, Qwen2.5 и QwQ. Сервис обработки выводов работает на собственном чипе SambaNova под названием reconfigurable dataflow unit (RDU), который специально разработан для эффективной обработки выводов в моделях генеративного ИИ, снижая стоимость и увеличивая скорость обработки выводов. Подробнее на их сайте
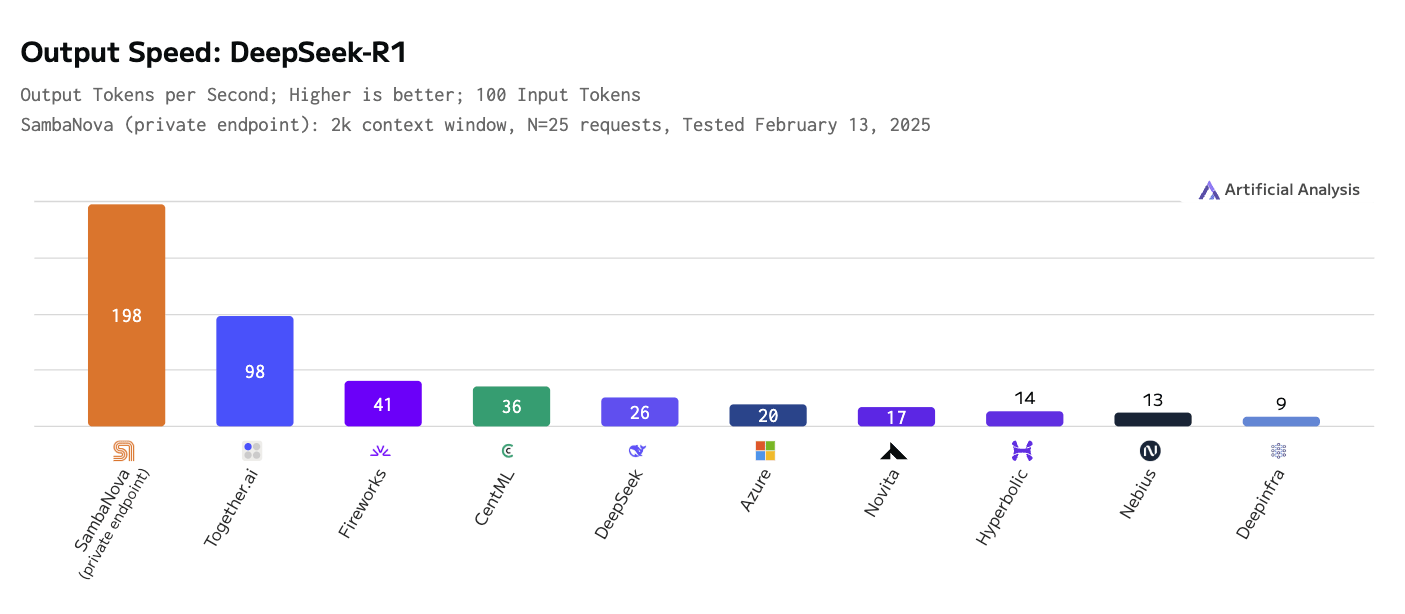 Output speed- deepseek r1.png
Output speed- deepseek r1.png
Архитектура DeepSearcher
Архитектура DeepSearcher соответствует нашему предыдущему посту, разбивая проблему на четыре этапа - определение/уточнение вопроса, исследование, анализ, синтез - хотя на этот раз с некоторым дублированием. Мы пройдемся по каждому шагу, отмечая улучшения DeepSearcher.
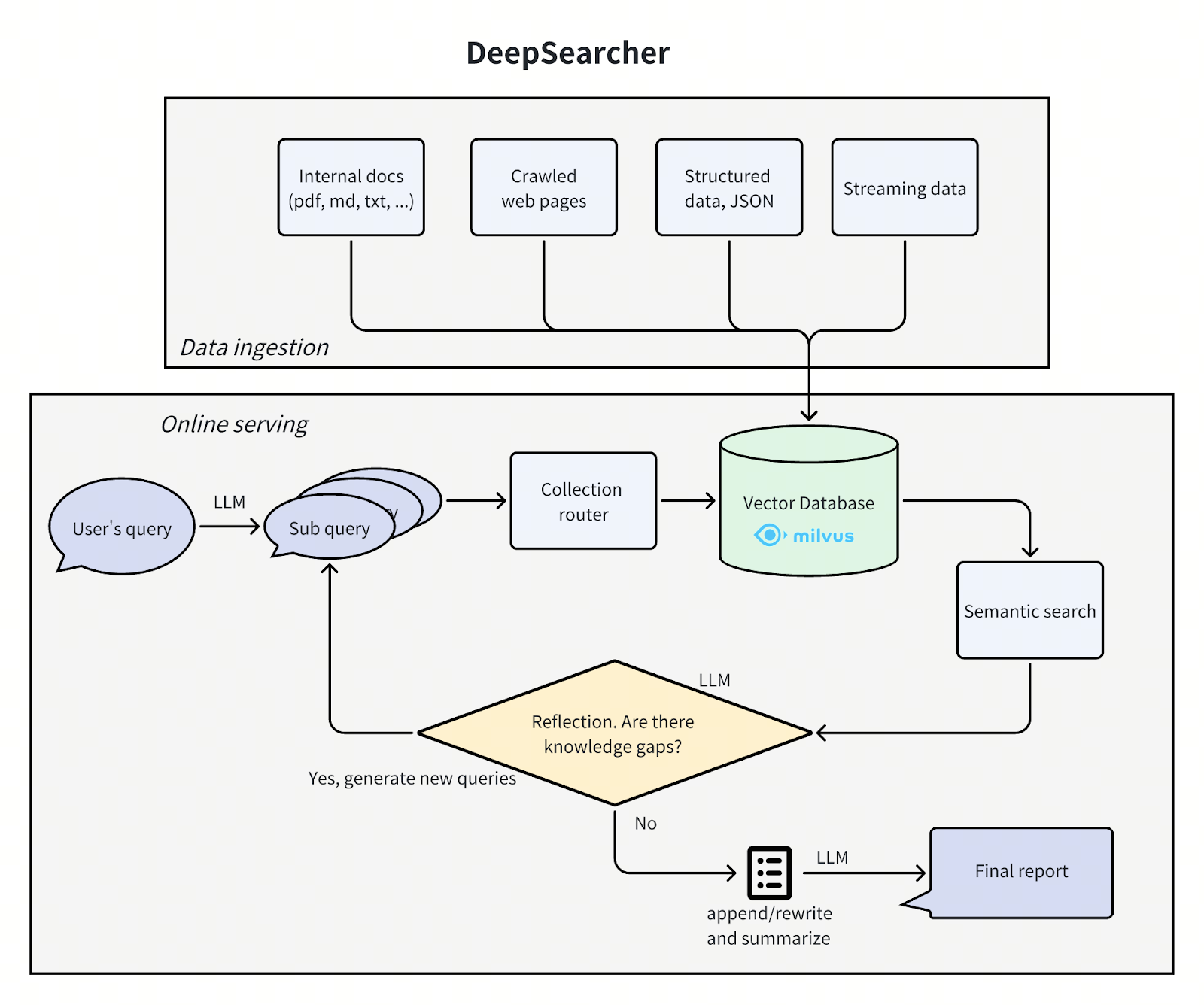 deepsearcher architecture.png
deepsearcher architecture.png
Определение и уточнение вопроса
``txt Разбейте исходный запрос на новые подзапросы: [ 'Как изменилось культурное влияние и общественная значимость "Симпсонов" с момента их дебюта до настоящего времени?', 'Какие изменения в развитии персонажей, юморе и стиле повествования произошли в разных сезонах "Симпсонов"?', Как менялся стиль анимации и технология производства "Симпсонов" с течением времени?", 'Как менялись демографические показатели аудитории, прием и рейтинги "Симпсонов" на протяжении всего сериала?']
При разработке DeepSearcher границы между исследованием и уточнением вопроса размыты. Первоначальный запрос пользователя декомпозируется на подзапросы, как и в предыдущем посте. См. выше исходные подзапросы, созданные на основе запроса "Как менялся сериал "Симпсоны" с течением времени?". Однако на следующем этапе исследования вопрос будет уточняться по мере необходимости.
### Исследование и анализ
Разбив запрос на подзапросы, агент приступает к исследовательской части. В ней, грубо говоря, четыре этапа: _маршрутизация_, _поиск_, _рефлексия и условное повторение_.
#### Маршрутизация
Наша база данных содержит множество таблиц или коллекций из разных источников. Было бы эффективнее, если бы мы могли ограничить семантический поиск только теми источниками, которые релевантны рассматриваемому запросу. Маршрутизатор запросов предлагает LLM решить, из каких коллекций следует извлекать информацию.
Ниже приведен метод формирования запроса-маршрутизатора:
``python
def get_vector_db_search_prompt(
вопрос: str,
collection_names: List[str],
collection_descriptions: List[str],
контекст: List[str] = None,
):
sections = []
# общая подсказка
common_prompt = f"""Вы - продвинутый аналитик по проблемам ИИ. Используя свои способности к рассуждениям и историческую информацию о разговорах, основанную на всех существующих наборах данных, получите абсолютно точные ответы на следующие вопросы и сгенерируйте подходящий вопрос для каждого набора данных в соответствии с описанием набора данных, которое может быть связано с вопросом.
Вопрос: {question}
"""
sections.append(common_prompt)
# подсказка для набора данных
data_set = []
for i, collection_name in enumerate(collection_names):
data_set.append(f"{имя_коллекции}: {описания_коллекций[i]}")
data_set_prompt = f"""Ниже приведена вся информация о наборе данных. Формат информации о наборе данных следующий: имя набора данных: описание набора данных.
Наборы данных и описания:
"""
sections.append(data_set_prompt + "\n".join(data_set))
# контекстная подсказка
if context:
context_prompt = f"""Ниже приводится сжатая версия исторического разговора. Эту информацию необходимо объединить в данном анализе, чтобы сгенерировать вопросы, приближенные к ответу. Запрещается генерировать одинаковые или похожие вопросы для одного и того же набора данных, а также повторно генерировать вопросы для наборов данных, которые были признаны несвязанными.
Историческая беседа:
"""
sections.append(context_prompt + "\n".join(context))
# подсказка к ответу
response_prompt = f""Исходя из вышесказанного, вы можете выбрать только несколько наборов данных из следующего списка наборов данных и сгенерировать соответствующие связанные вопросы для выбранных наборов данных, чтобы решить вышеуказанные проблемы. Формат выходных данных - json, где ключ - это название набора данных, а значение - соответствующий сгенерированный вопрос.
Наборы данных:
"""
sections.append(response_prompt + "\n".join(collection_names))
footer = """Отвечайте исключительно в правильном формате JSON, соответствующем точной схеме JSON.
Критические требования:
- Включать ТОЛЬКО ОДИН тип действия
- Никогда не добавлять неподдерживаемые ключи
- Исключить весь не JSON-текст, разметку или пояснения.
- Соблюдайте строгий синтаксис JSON"""
sections.append(footer)
return "\n\n".join(sections)
Мы заставляем LLM возвращать структурированный вывод в виде JSON, чтобы легко преобразовать его в решение о том, что делать дальше.
Поиск
После выбора различных коллекций баз данных на предыдущем шаге, шаг поиска выполняет поиск по сходству с Milvus. Как и в предыдущем посте, исходные данные были определены заранее, разбиты на куски, встроены и сохранены в векторной базе данных. Для DeepSearcher источники данных, как локальные, так и онлайн, должны быть указаны вручную. Мы оставляем онлайн-поиск для будущих работ.
Отражение
В отличие от предыдущего поста, DeepSearcher демонстрирует настоящую форму агентской рефлексии, вводя предыдущие результаты в качестве контекста в подсказку, которая "размышляет" о том, содержат ли заданные вопросы и соответствующие извлеченные фрагменты какие-либо информационные пробелы. Это можно рассматривать как шаг анализа.
Вот метод создания подсказки:
``python def get_reflect_prompt( вопрос: str, mini_questions: List[str], mini_chuncks: List[str], ): mini_chunk_str = "" for i, chunk in enumerate(mini_chuncks): mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n""" reflect_prompt = f"""Определите, нужны ли дополнительные поисковые запросы, основываясь на исходном запросе, предыдущих подзапросах и всех полученных фрагментах документов. Если требуется дальнейшее исследование, предоставьте список Python, включающий до 3 поисковых запросов. Если дальнейшее исследование не требуется, верните пустой список.
Если исходным запросом является написание отчета, но вы предпочитаете генерировать несколько дополнительных запросов, вместо этого верните пустой список.
Исходный запрос: {question}
Предыдущие подзапросы: {mini_questions}
Связанные блоки:
{mini_chunk_str}
"""
footer = """Отвечайте исключительно в формате List of str без какого-либо другого текста."""
return reflect_prompt + footer
И снова мы заставляем LLM возвращать структурированный вывод, на этот раз в виде интерпретируемых на Python данных.
Вот пример новых подзапросов, "обнаруженных" в результате размышлений после ответа на первоначальные подзапросы, приведенные выше:
Новые поисковые запросы для следующей итерации: [ "Как изменения в голосовом составе и съемочной группе "Симпсонов" повлияли на эволюцию сериала в разных сезонах?", "Какую роль сыграли сатира и социальные комментарии "Симпсонов" в их адаптации к современным проблемам на протяжении десятилетий?", "Как "Симпсоны" учитывали и учитывают изменения в потреблении медиа, такие как потоковые сервисы, в своих стратегиях распространения и контента?"]
#### Условный повтор
В отличие от нашего предыдущего поста, DeepSearcher иллюстрирует условный поток выполнения. Поразмыслив над тем, являются ли вопросы и ответы на них полными, если есть дополнительные вопросы, которые необходимо задать, агент повторяет описанные выше шаги. Важно отметить, что поток выполнения (цикл while) является функцией вывода LLM, а не жестко закодирован. В этом случае есть только бинарный выбор: _повторить исследование_ или _сгенерировать отчет_. В более сложных агентах их может быть несколько, например: _следовать по гиперссылке_, _извлекать фрагменты, сохранять в памяти, размышлять_ и т. д. Таким образом, вопрос продолжает уточняться по усмотрению агента, пока он не решит выйти из цикла и сгенерировать отчет. В нашем примере с Симпсонами DeepSearcher выполняет еще два раунда заполнения пробелов с помощью дополнительных подзапросов.
### Synthesize
Наконец, полностью разложенный вопрос и полученные фрагменты синтезируются в отчет с одной подсказкой. Вот код для создания подсказки:
``python
def get_final_answer_prompt(
вопрос: str,
mini_questions: List[str],
mini_chuncks: List[str],
):
mini_chunk_str = ""
for i, chunk in enumerate(mini_chuncks):
mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n"""
summary_prompt = f"""Вы - эксперт по анализу контента AI, хорошо умеете резюмировать контент. Пожалуйста, составьте конкретный и подробный ответ или отчет на основе предыдущих запросов и полученных фрагментов документов.
Исходный запрос: {question}
Предыдущие подзапросы: {mini_questions}
Связанные блоки:
{mini_chunk_str}
"""
return summary_prompt
Преимущество этого подхода по сравнению с нашим прототипом, который анализировал каждый вопрос отдельно и просто объединял результаты, состоит в том, что в результате получается отчет, в котором все разделы соответствуют друг другу, то есть не содержат повторяющейся или противоречивой информации. Более сложная система может сочетать в себе оба варианта, используя поток условного выполнения для структурирования отчета, подведения итогов, переписывания, отражения и разворота и т. д., что мы оставляем на будущее.
Результаты
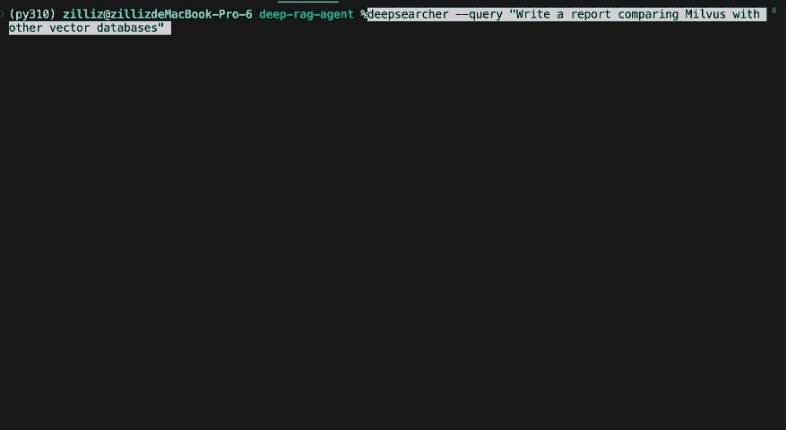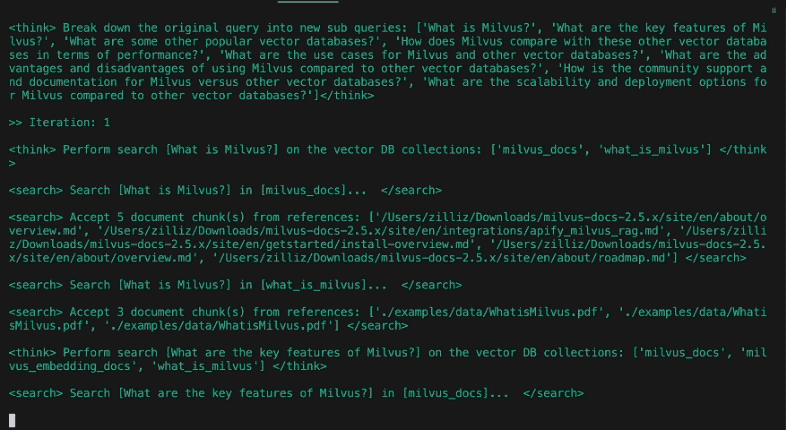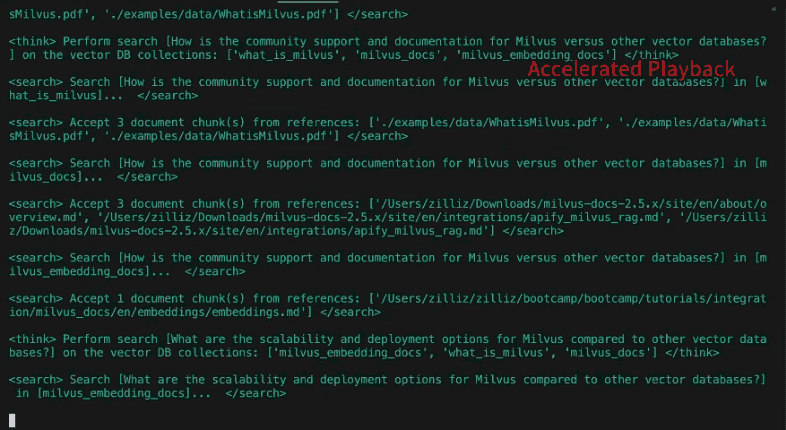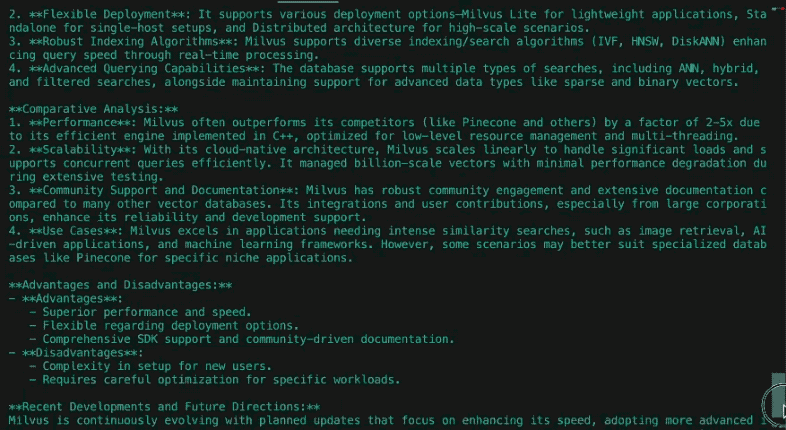
Вот пример отчета, сгенерированного по запросу "Как менялся сериал "Симпсоны" с течением времени?" с помощью DeepSeek-R1, передающего в качестве исходного материала страницу Википедии о "Симпсонах":
``txt Отчет: Эволюция "Симпсонов" (1989 - настоящее время)
- Культурное влияние и актуальность для общества Симпсоны" дебютировали как подрывная критика жизни американского среднего класса, получив известность благодаря своей смелой сатире в 1990-х годах. Изначально это был контркультурный феномен, он бросал вызов нормам в эпизодах, затрагивающих религию, политику и потребительство. Со временем его культурное доминирование пошло на убыль, поскольку конкуренты, такие как "Южный парк" и "Гриффины", раздвинули границы. К 2010-м годам шоу превратилось из законодателя моды в ностальгический институт, балансируя между привлекательностью наследия и попытками затронуть современные проблемы, такие как изменение климата и права ЛГБТК+, хотя и с меньшим общественным резонансом. ... Заключение Симпсоны" превратились из радикальной сатиры в телевизионный институт, преодолевая изменения в технологиях, политике и зрительских ожиданиях. В то время как гениальность "золотого века" остается непревзойденной, его адаптивность - благодаря потоковому вещанию, обновленному юмору и глобальному охвату - сохраняет за ним место культурного ориентира. Долголетие шоу отражает как ностальгию, так и прагматичное отношение к переменам, даже когда оно решает проблемы актуальности в условиях фрагментированного медиаландшафта.
Полный текст отчета здесь] (https://drive.google.com/file/d/1GE3rvxFFTKqro67ctTkknryUf-ojhduN/view?usp=sharing), а также [отчет, подготовленный DeepSearcher с помощью GPT-4o mini] (https://drive.google.com/file/d/1EGd16sJDNFnssk9yTd5o9jzbizrY_NS_/view?usp=sharing) для сравнения.
## Обсуждение
Мы представили [DeepSearcher](https://github.com/zilliztech/deep-searcher), агента для проведения исследований и написания отчетов. Наша система построена на идее, изложенной в предыдущей статье, с добавлением таких возможностей, как условный поток выполнения, маршрутизация запросов и улучшенный интерфейс. Мы перешли от локального вывода с небольшой 4-битной квантованной моделью рассуждений к онлайн-сервису вывода для массивной модели DeepSeek-R1, что качественно улучшило наш выходной отчет. DeepSearcher работает с большинством сервисов вывода, таких как OpenAI, Gemini, DeepSeek и Grok 3 (скоро выйдет!).
Модели рассуждений, особенно используемые в исследовательских агентах, требуют большого количества выводов, и нам повезло, что мы смогли использовать самую быструю модель DeepSeek-R1 от SambaNova, работающую на их специализированном оборудовании. Для нашего демонстрационного запроса мы сделали шестьдесят пять обращений к сервису вывода DeepSeek-R1 от SambaNova, ввели около 25 тыс. лексем, вывели 22 тыс. лексем и потратили $0,30. Мы были впечатлены скоростью вывода, учитывая, что модель содержит 671 миллиард параметров и имеет размер 3/4 терабайта. [Подробности здесь!](https://sambanova.ai/press/fastest-deepseek-r1-671b-with-highest-efficiency)
Мы продолжим развивать эту работу в следующих постах, рассматривая дополнительные агентные концепции и пространство дизайна исследовательских агентов. А пока мы приглашаем всех попробовать [DeepSearcher](https://github.com/zilliztech/deep-searcher), [отметить нас на GitHub](https://github.com/zilliztech/deep-searcher) и поделиться своими отзывами!
## Ресурсы
- [**Zilliz's DeepSearcher**](https://github.com/zilliztech/deep-searcher)
- Справочное чтение: [**_"Я построил глубокое исследование с открытым исходным кодом - и вы тоже можете!"_**](https://milvus.io/blog/i-built-a-deep-research-with-open-source-so-can-you.md)
- [_[__SambaNova запускает самый быстрый DeepSeek-R1 671B с высочайшей эффективностью__](https://sambanova.ai/press/fastest-deepseek-r1-671b-with-highest-efficiency)_"_".
- DeepSearcher: [Отчет DeepSeek-R1 о сериале "Симпсоны"](https://drive.google.com/file/d/1GE3rvxFFTKqro67ctTkknryUf-ojhduN/view?usp=sharing)
- DeepSearcher: [GPT-4o mini report on The Simpsons](https://drive.google.com/file/d/1EGd16sJDNFnssk9yTd5o9jzbizrY_NS_/view?usp=sharing)
- [Milvus Open-Source Vector Database](https://milvus.io/docs)

Читать далее

How to Choose the Best Embedding Model for RAG in 2026: 10 Models Benchmarked
We benchmarked 10 embedding models on cross-modal, cross-lingual, long-document, and dimension compression tasks. See which one fits your RAG pipeline.

Why Context Engineering Is Becoming the Full Stack of AI Agents
Discover how context engineering unifies prompts, RAG, and tools to build smarter, production-ready AI agents powered by Milvus.

How to Use Anthropic MCP Server with Milvus
MCP + Milvus: Streamline AI agent development with standardized data access, eliminating integration hassles while enhancing context and flexibility.