




画像検索のための画像埋め込み:詳細な説明
画像埋め込みは、最新のコンピュータビジョンアルゴリズムの中核です。その実装と使用例を理解し、さまざまな画像埋め込みモデルを探求する。
シリーズ全体を読む
- Exploring BGE-M3 and Splade: Two Machine Learning Models for Generating Sparse Embeddings
- Comparing SPLADE Sparse Vectors with BM25
- Exploring ColBERT: A Token-Level Embedding and Ranking Model for Efficient Similarity Search
- Vectorizing and Querying EPUB Content with the Unstructured and Milvus
- What Are Binary Embeddings?
- A Beginner's Guide to Website Chunking and Embedding for Your RAG Applications
- An Introduction to Vector Embeddings: What They Are and How to Use Them
- Image Embeddings for Enhanced Image Search: An In-depth Explainer
- A Beginner’s Guide to Using OpenAI Text Embedding Models
- DistilBERT: A Distilled Version of BERT
- Unlocking the Power of Vector Quantization: Techniques for Efficient Data Compression and Retrieval
画像埋め込みは、最新のコンピュータビジョンアルゴリズムの中核です。その実装と使用例を理解し、さまざまな画像埋め込みモデルを探求する。
画像埋め込みによって、高度なコンピュータシステムはさまざまな視覚データを認識できるようになります。したがって、テキストや画像のようなデータは、数値からなるベクトルに埋め込まれます。これらのベクトルはベクトルデータベースに格納され、高速、簡単、タイムリーなアクセスや検索が可能です。
手作業によるアノテーションから、視覚データの高密度ベクトル表現まで、複数の埋め込み技術が存在する。以前の技術では、コンピュータが作業するために、画像に一意の数値識別子を手動で割り当てる必要があったが、ディープラーニングモデルにより、埋め込み技術は一変した。現在では、コンピュータにテキストプロンプトを与えることで画像を生成できるほど進化している。
この記事では、そのようなテクニックを取り上げ、どのような場合に選択すべきかを強調する。その後、画像検索システムを実装する。
画像埋め込みを理解する
画像埋め込みは、画像に関する様々な情報を含む画像の密なベクトル表現です。この情報には、特徴、テクスチャ、色、構図、その他の画像セマンティクスが含まれます。コンピュータは画像埋め込みを処理し、画像分類、情報検索、セグメンテーションなどのタスクを実行することができます。
埋め込み画像とは、画像をあるベクトル空間で表現したベクトルのことです。画像埋め込みベクトルには、疎なベクトルと密なベクトルがあります。前者は非ゼロ要素のみを格納するためメモリ効率は良いが、情報量が失われる可能性がある。逆に後者は、画像の細部まで情報を提供し、複雑な作業をよりよく支援します。
以前の画像モデルは手作業によるエンコードに頼っており、面倒な作業だった。しかし、最新のエンコーダーは複雑なディープラーニング・アルゴリズムを使用し、複雑な画像データとパターンを捉える。ニューラルネットワークは微細なディテールを理解し、効率と精度を向上させるための微妙な接続を作り出すことができる。
##従来の画像埋め込み方法
従来の画像処理技術は限られており、小規模で特定のデータセットに最適であった。初期の技術では、カラーヒストグラムやBag of Visual Wordsの概念を使用していました。
カラーヒストグラムは、特定の色を表す各画像ピクセルの頻度をマッピングします。類似した画像は似たようなカラーヒストグラム構成を持つため、これらを画像の識別や検索に使用する。この技法は素晴らしいが、2つの画像が似たような色組成を持つ可能性を排除できず、曖昧さが生じる。さらに、空間的特徴に基づく分類にこの技法を使うことはできない。
![]()
図2: カラーヒストグラムが、画像全体の色ごとの画素数と異なる色チャンネルの値をどのように対応付けるかの表現
視覚的単語の袋(Bag of Visual Words)の概念は、画像の中で最も顕著な特徴のための辞書であり、その後、特定のクラスを定義する異なるカテゴリにクラスタリングされます。この辞書は視覚的な単語の袋として機能し、画像はこれらの単語と比較されます。そして、視覚的単語の袋の中で画像に最も頻繁に存在する特徴に基づいて画像が埋め込まれる。この手法の欠点は、視覚的単語の袋から無関係な特徴を高頻度にカウントしてしまう可能性があり、誤った情報や誤った解釈につながることである。

図3: 上の画像はBag of Visual Wordsの働きを示している。距離行列を使ってどのように領域が比較されるかを示している
これらの技術は、あまり成功しなかったとはいえ、画像埋め込み技術の進化をリードするものでした。
ディープラーニングのブレークスルー
CNN (Convolution Neural Networks)](https://zilliz.com/glossary/convolutional-neural-network)のようなディープラーニングモデルは、ImageNetのような大規模なデータセットで学習することができます。このアプローチにより、最も高い精度で効果的な埋め込みを生成する効率的なモデルが得られる。ImageNetは、モデル学習用の何百万もの注釈付き画像からなるデータセットである。これらの画像は複数のクラスとサブクラスに分類され、WordNetデータセットを用いて注釈が付けられる。
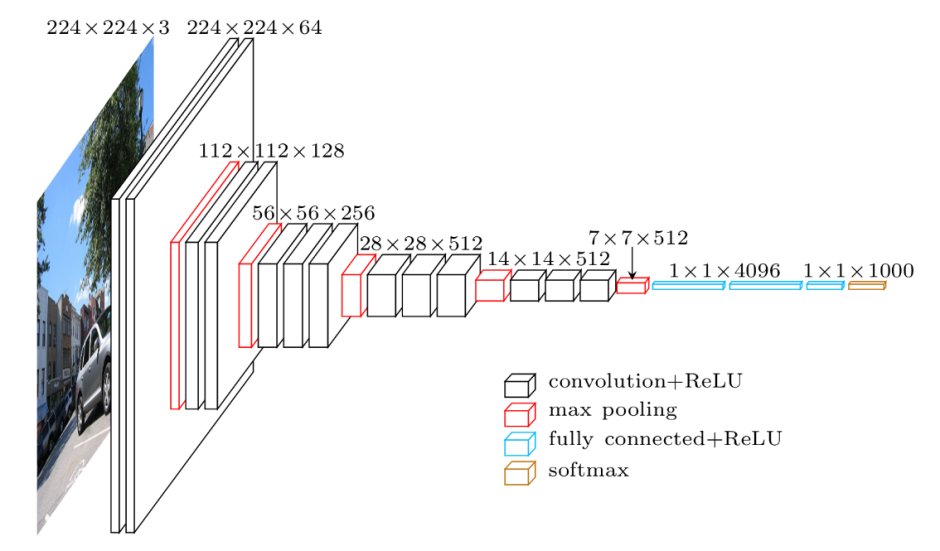
図4: 2014年に発表されたCNNモデルVGG-16のアーキテクチャ
CNNは、畳み込みブロックと分類ブロックの2つのブロックで構成される。畳み込みブロックは、複雑な画像を低次元の密なベクトルにスケールダウンする役割を担っており、このベクトルには画像のすべての情報が格納されている。この情報には、空間的特徴、色構成、テクスチャの詳細などが含まれる。畳み込みブロックに続いて、生成された出力は画像の本質をカプセル化した密なベクトルです。この埋め込まれた表現は、次に分類ブロックに進み、そこで画像に希望するクラスに対応するラベルが付与される。分類プロセスでは、分類ブロックの結果を実際のクラスラベルと比較する。
画像処理におけるトランスフォーマーの台頭
ViT(ヴィジョン・トランスフォーマー)は機械学習(ML)モデルであり、入力データを分類・処理するために自己アテンションと位置埋め込み技術を使用する。ViTは画像をパッチに分割し、内部レイヤーを通して、これらのパッチからベクトルを計算し、他のベクトルと比較してアライメントスコアを生成する。さらに、分類のためのクラス埋め込みと、パッチ配列の整合性を維持するための位置埋め込みである。
ViTのパッチベースのデザインは並列入力を可能にし、モデルの迅速な学習と大規模データセットでの事前学習を容易にする。これらの事前訓練されたモデルは、特定のユースケースに適応するように微調整することができる。
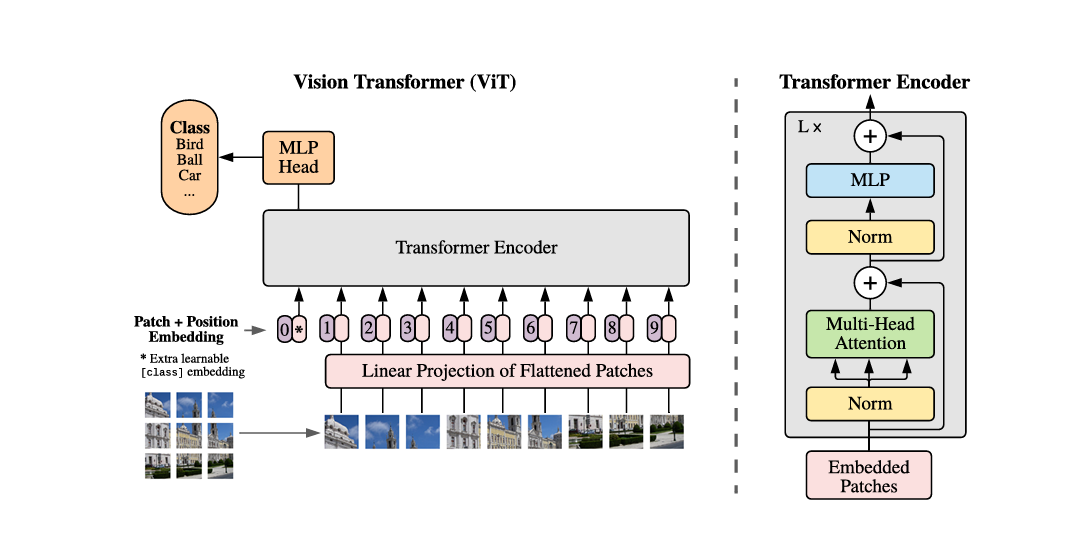
図5: ViTモデルの概要
ViT 対 CNN
CNNはすべてのピクセルを分析して画像を処理するのに対し、ViTは画像を小さなパッチに分割して処理する。CNNが生成するベクトルは高密度で、画像のあらゆる側面に関する情報を保持するのに対し、ViTでは異なるパッチのベクトルを用いてアライメント・スコアを計算する。ViTは画像全体を逐次的に処理するため、高速な計算が可能であるのに対し、CNNはすべてのピクセルを個別に処理しなければならない。
CLIPによるマルチモーダル・アプローチ
CLIP (Contrastive Language-Image Pretraining)は、テキストデータと視覚入力を使って画像を識別する高度な機械学習モデルである。CLIPには2つの異なる変換器があり、1つはテキスト埋め込みベクトルを符号化するためのもので、もう1つは画像埋め込みベクトルを符号化するためのものである。これらのベクトルは類似のベクトル空間にあり、類似の視覚データとテキストデータに対応する。
CLIPは、似たような意味を伝えるテキストと画像のペアで学習される。例えば、赤いリンゴの画像で、それを説明するテキストが "A sweet red apple "だとする。このペアはCLIPに渡され、テキストと画像の変換器によって類似ベクトルが生成される。このコンセプトは画像検索の改善に役立っている。

図6: CLIPモデルを動作させるための簡単な図。テキストと画像のペアがどのように学習に使われているかがわかる
CLIPはゼロショット物体分類と検出を可能にし、物体の検出と分類に事前の学習を必要としない。これは多くのアプリケーションを開拓した:
CLIPは、明示的にトレーニングされていないオブジェクトクラスであっても、テキスト記述のみに基づいて画像内のオブジェクトを見つけ、分類することができます。
CLIPのゼロショット機能は、テキストクエリで画像を検索するのに役立ち、画像検索システムに応用できる。
高度な埋め込み技術
CV空間における一つの興味深いブレークスルーは拡散モデルである。これらのモデルは、与えられた入力テキストや参照画像から画像を生成する。

図7: ステップごとに入力データにノイズを加え、ノイズ除去アルゴリズムを実行することで元のデータを構築しようとする
拡散モデルは、各層で入力データにノイズを加えることで学習される。最終層まで到達すると、生成された出力をノイズ除去することで、実際のデータまたは入力に類似したデータを再構築することを目指す。
埋め込みモデルとベクトルデータベースの統合
埋め込みモデルは、入力データの数値ベクトル表現を生成する。このようなベクトルは、ベクトルデータベースとして知られる専用のデータベースに格納されます。Milvus](https://milvus.io/intro)やZilliz Cloud(フルマネージドMilvusベクトルデータベース)のようなベクトルデータベースに格納された画像埋め込みを用いて、クエリに基づいた画像を検索することができる。
従来のデータベースによる精密検索とベクトルデータベースによるベクトル検索の違いは、精密検索は与えられたクエリに正確にマッピングして結果を検索することである。しかし、ベクトル検索は与えられたクエリに類似した結果を検索する。この類似検索は、近似最近傍(ANN)アルゴリズムを用いて実現される。ベクトル・データベースはこのアルゴリズムを使って、類似した空間を持つベクトルをマッピングし、検索する。このため、特定のクエリに対して、生成されたクエリに関連する複数の結果を得ることができる。
ベクトル・データベースは、非構造化データや半構造化データの保存とインデックス付けに役立つ。高次元のベクトルに適用される特殊なアルゴリズムは、生成されたクエリに関連する情報をほぼ瞬時に検索するのに役立ちます。
ロバストな画像検索システムの構築
このセクションでは、MilvusとTimmを使って、画像検索システム(image-to-image)をゼロから構築する。MilvusはオープンソースのトップベクターAI用データベースであり、数百万エントリの最近傍検索をサポートしています。同時に、Timmは画像埋め込みを生成するのに役立つモデルのコレクションを含むディープラーニングライブラリである。
セットアップ
以下は、画像検索システムを作成するために必要なインストールです:
pip install pymilvus --upgrade
!pip install timm
!pip install gdown
その前に、必要な依存関係がインストールされていることを確認してください。
トーチ
Numpy
sklearn
枕
インポート
コードを始めるのに必要なインポートは以下の通りです:
インポートトーチ
インポート gdown
インポート os
import timm
from sklearn.preprocessing import normalize
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
from pymilvus import MilvusClient
from PIL import Image
データセット
この記事では、101のカテゴリからオブジェクトの画像を含むCaltech-101データセットを使用します。各画像は1つの物体でラベル付けされている。各カテゴリには約40~800枚の画像があり、合計で約9,000枚の画像がある。画像サイズは様々で、一般的にエッジの長さは200~300ピクセルである。
データセットは次のようなディレクトリ構造になっている:
+---カルテック-101
|-テスト
| ʕ-̫͡-ʔ͡-ʔ
| ⅳ---0.jpg
| Ⅾ---1.jpg
| (´・ω・`)(´・ω・`)(´・ω・`)(´・ω・`)
| ♪列車
| 飛行機
| ˶---0.jpg
|-------1.jpg
| (゜Д゜)・゜・。
このドライブからダウンロードする前に、データセットの前処理が必要だった。これにはデータセットと、後で画像検索に使うCSVファイルが含まれている。以下の方法でダウンロードし、解凍する:
url = '<drive_url>'
出力 = 'Caltech-101.zip'
gdown.download(url, output, quiet=False)
ダウンロードが終わったら、以下のように解凍する:
!unzip -q -o /Caltech-101.zip
これをPandasで可視化すると以下のようになる:
df = pd.read_csv('Caltech-101/image_search.csv')
df.head()
こんな感じです:
| ID | パス | ラベル | 0 | ./train/ant/image_0033.jpg | ant |
| 0 | ./train/ant/image_0033.jpg | ant |
| 2 | ./train/ant/image_0013.jpg | ant |... | ... | ... | ... |
データセットの作成は終わった。では、Milvusでコレクションを作成しよう。
Milvusコレクション
従来のデータベースエンジンと同様に、Milvusではデータベースを作成し、特定のユーザに権限を割り当てて管理することができます。
MilvusClient**はPymilvusの使いやすいラッパーです。これはプロセスを簡素化し、オリジナルのSDKに見られる複雑さの多くを隠すように設計されている。クライアントからのcreate_collection APIは、他のパラメータでコレクションを作成します。これがその実装です。
client = MilvusClient(uri="example.db")
client.create_collection(
collection_name="image_embeddings"、
vector_field_name="vector"、
dimension=512、
auto_id=True、
enable_dynamic_field=True、
metric_type="COSINE"、
)
上記のコードでは、コレクション名とベクトル・フィールド名を指定しています。コレクションIDは自動的に生成される。これは埋め込みフィールドの主キー次元512として機能する。
Timm を使用した埋め込み
我々のテキスト画像検索システムは、ディープニューラルネットワークを用いて画像とテキストから埋め込みを抽出する。そして、これらの埋め込みをMilvusに格納されている埋め込みと比較します。
これを実現するために、PyTorchエコシステムの人気ライブラリであるTimm("PyTorch Image Models "の略)を利用しています。このライブラリは、最先端の事前訓練された画像分類モデルと、訓練と評価のためのユーティリティのコレクションを提供します。
このセクションでは、TimmのResnet-34を活用して、画像から埋め込みを抽出します。以下のコードでは、FeatureExtractorクラスを定義します。このクラスは、モデルと必要な設定をロードし、前処理後に画像をモデルに渡します。
クラス FeatureExtractor:
def __init__(self, modelname):
# 学習済みのモデルを読み込む
self.model = timm.create_model(
modelname, pretrained=True, num_classes=0, global_pool="avg" )
)
self.model.eval()
self.input_size = self.model.default_cfg["input_size"].
config = resolve_data_config({}, model=modelname)
self.preprocess = create_transform(**config)
def __call__(self, imagepath):
input_image = Image.open(imagepath).convert("RGB")
input_image = self.preprocess(input_image)
input_tensor = input_image.unsqueeze(0)
torch.no_grad()を使う:
出力 = self.model(input_tensor)
feature_vector = output.squeeze().numpy()
return normalize(feature_vector.reshape(1, -1), norm="l2").flatten()
Milvusへの画像埋め込み挿入
ここでは、先に定義した FeatureExtractor を利用して、指定したディレクトリ内の画像を処理しながらモデルの推論を行う。
extractor = FeatureExtractor("resnet34")
ルート = "./Caltech-101/train"
for dirpath, foldername, filenames in os.walk(root):
for filename in filenames:
if filename.endswith(".jpg"):
ファイルパス = dirpath + "/" + filename
image_embedding = extractor(filepath)
client.insert(
"image_embeddings"、
{"vector": image_embedding, "filename": filepath}、
)
これでMilvusへの埋め込みは完了だ。テストデータセットで確認してみよう。
Milvusのクエリ画像
ここでは、検索APIを使ってMilvusにクエリを実行します。検索指標として、コレクション、クエリ画像、COSINE distanceを指定します。
query_image = "./test/laptop/image_0001.jpg"
results = client.search(
"image_embeddings"、
data=[extractor(query_image)]、
output_fields=["filename"]、
search_params={"metric_type":"COSINE"}、
)
画像検索システムのテストと最適化:
画像検索業界において、テストは難しいプロセスです。ここでは、システムをテストするために採用できるいくつかのステップを紹介する:
1.多様なデータセットの選択:多様なデータセットの選択**:システムが扱うと予想される画像を代表する多様なデータセットを選択する。異なるカテゴリー、スタイル、解像度、照明条件の画像を含める。
2.**グランド・トゥルース・アノテーション検索システムの精度を評価するために、データセットに真実のラベルや注釈を付ける。これには、カテゴリ、タグ、説明などの関連するメタデータを含めることができる。
3.ベンチマーキング:既存のベンチマークや最先端の手法とシステムのパフォーマンスを比較し、相対的な有効性を評価し、改善すべき領域を特定する。
4.実世界シナリオ:実際の使用状況を模倣したシナリオでシステムをテストする。様々な入力クエリのタイプ、複雑さ、ユーザーの行動パターンなどの要因を考慮する。
5.**ユーザーからのフィードバックユーザーからのフィードバックを評価プロセスに取り入れ、システムを繰り返し改善する。
システムがテストされると、最適化が必要であることがわかるかもしれません。ここでは、画像検索システムを最適化するためのヒントをいくつか紹介します:
1.効果的なデータ型の選択:埋め込みデータを保存する際のストレージ効率を最適化するには、使用するデータ型の容量を最大限に活用することが重要です。多くの場合、MilvusのようにFLOAT16_VECTORのようなデータ型を利用することで、埋め込みデータを半精度で保存することができ、メモリと帯域幅を最適に利用することができます。
2.**より優れたモデルと平均的なモデルのトレードオフ:多くの人は、他よりはるかに優れたモデルに飛びつきますが、そのようなモデルはほとんどスケーラブルではありません。仕事をこなせるエンベッディングモデルを選びましょう。例えば、CLIPの2つのバリエーションViT-B/16とViT-B/32を見て、エンベッディングを素早く生成するためにサイズの小さい方を選ぶ(この場合はViT-B/16)。
3.常にGPUを使用する: GPUは並列処理が効率的で、システムの効率を大幅に向上させることができます。これにより、学習処理の分散が可能になり、埋め込み処理を大幅に高速化することができます。
4.**データベースのインデックスとは、データベース内のレコードに素早くアクセスするためのデータ構造の一種です。ここでは、IVF_FLAT型の埋め込みカラムにインデックスを作成します。このインデックスは、近似最近傍探索(ANNS)を用いた量子化ベースのインデックスで、高速な検索を実現します。以下はMilvusにおけるインデックスの作成方法です:
index_params = MilvusClient.prepare_index_params()
index_params.add_index(metric_type='COSINE'、
Index_type="IVF_FLAT"、
params={"nlist":512}.
)
client.create_index(collection_name="...",index_params=index_params)
ユースケースに応じて使用できるインデックスは他にもたくさんあります。以下はMilvusにある全リストである。
使用例と実際のアプリケーション
画像埋め込みは、画像検索システムにおいて非常に役立ちます:
電子商取引における画像埋め込みは、Mozatの機能に似た、類似画像を提供することで商品を検索する機能を可能にする。Mozatの画像検索システムは、ユーザが自分のデジタルクローゼットから似たような洋服アイテムを見つけ、洋服の組み合わせを提案し、閲覧履歴とクローゼットの中身に基づいてテーラーメイドのファッション写真を推薦することを可能にする。
画像埋め込みとベクトルデータベースは、製造中の画像の異常を検出することができる。低い類似度スコアを識別することで、品質管理を確実にします。
テキストから画像への検索は、ユーザーが望むものを正確に得るための貴重な手段を提供する。Airbnbは、画像埋め込みとベクトルデータベースを使用して、テキストの説明を関連する賃貸物件に変換します。
結論
本稿では、画像埋め込みとその様々な技術について説明した。カラーヒストグラムやBag of Visual Wordsのような伝統的な手法には欠点があり、それがCNNや変換器のような高度な手法の開発につながった。これらの新しいアプローチは、画像検索の分野で活躍し、最新の埋め込みモデルの基礎を築きました。
その後、DALL-EやImagenのような拡散モデルが競争に加わりました。このようなモデルは、テキスト記述を使ってゼロからリアルな画像を生成する。
AIの分野は急速に進歩しており、テキスト、画像、動画など、あらゆる種類のデータに対して同じことが言える。以下のリソースを読み、様々な埋め込みテクニックを試して、一歩先を行きましょう。
BGE-M3とSpladeを探る:疎な埋め込みを生成する2つの機械学習モデル ](https://zilliz.com/learn/bge-m3-and-splade-two-machine-learning-models-for-generating-sparse-embeddings)
SPLADEスパースベクターとBM25の比較](https://zilliz.com/learn/comparing-splade-sparse-vectors-with-bm25)
ColBERT: 効率的な類似検索のためのトークンレベルの埋め込みとランキングモデル](https://zilliz.com/learn/explore-colbert-token-level-embedding-and-ranking-model-for-similarity-search)
バイナリ埋め込みとは](https://zilliz.com/learn/what-are-binary-vector-embedding)
言語パワーを解き放つ:LangChain入門 ](https://zilliz.com/learn/LangChain)
ベクトルデータベース物語](https://zilliz.com/blog)
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
読み続けて

SPLADEスパース・ベクターとBM25の比較
一般的に、ベクトルには密なベクトルと疎なベクトルの2種類がある。密なベクトル」と「疎なベクトル」です。これらは同じようなタスクに利用できますが、それぞれに利点と欠点があります。この投稿では、スパース埋め込みの2つの一般的なバリエーションについて掘り下げます:BM25 と SPLADE です。

バイナリ・エンベッディングとは?
このブログでは、バイナリ埋込みの概念を紹介し、その定義的特徴、利点、および他の埋込みタイプとの比較メリットを明確にします。

OpenAIのテキスト埋め込みモデルを使うための初心者ガイド
OpenAIのテキスト埋め込みモデルを使った埋め込み作成とセマンティック検索の総合ガイド。