




Approximate Nearest Neighbor Search in Recommender Systems
Introduction
In February 2024, we heard from Yury Malkov at the SF Unstructured Data Meetup about Approximate Nearest Neighbor (ANN) and its key role in recommender systems. ANN search is already integrated into the production stacks of the world’s most popular tools. Yury helps us understand the key concepts and background that have driven ANN’s adoption in large-scale recommender systems.
Link to the YouTube replay of Yury Malkov’s talk: Watch the talk on YouTube
Why should you care about ANN?
Yuri Malkov is literally a genius. If you don’t believe me check out his Google Scholar listing https://scholar.google.com/citations?user=KvAyakQAAAAJ&hl=en. Physicist, laser researcher, and inventor of HNSW - a graph-based indexing algorithm now integrated into all major vector databases out of the box. He now works for OpenAI as Research Scientist. Tell me that doesn’t sound like a plausible Tony Stark bio in 2024.
With that, let's dig into Yuri’s talk on “Approximate Nearest Neighbor Search in Recommender Systems.”
What is ANN Search?
We’ll keep this brief as we’ve already covered the basics of ANN Search in short and at length.
Nearest neighbor searches are a set of statistical techniques that we can use to do similarity searches in machine learning or data science applications. Unlike their special K flavored cousin KNN which compares every datapoint in a system to each other when completing their search, ANN search algorithms use various indexing techniques to return approximate nearest neighbors. ANN searches have become core to many applications and technologies that are customer facing today. From search engines (like Google, not vector search) to social media sites, ANN and recommender systems are already integrated through the stack, in production.
ANN wasn’t the only solution for recommender systems. So how did we get here? We’ll go through mature ANN solutions in the market today, what make recommender systems a tough problem for nearest neighbor algos, how developers have structured recommender systems, and how researchers are using ANN to rewrite the recommender system stack. Yuri notes in his talk that many mature ANN solutions exist. Many of these topics are covered in-depth in our Visual Guide to Choosing a Vector Index but I’ve put together a table of the tools listed in Yuri’s presentation.
Table of ANN indices mentioned
| ANN Index | Classification | Scenario |
|---|---|---|
| LSH | Graph-based index | - Large highly complex multidimensional datasets - Uses euclidean distance to bucket datapoints - Only returns closest results |
| HNSW | Graph-based index | - Very high-speed query - Requires a recall rate as high as possible - Large memory resources |
| SCANN | Quantization-based index | - Very high-speed query - Requires a recall rate as high as possible - Large memory resources |
| IVF_PQ | Quantization-based index (inverted) | - Inverted Index - Very high-speed query - Limited memory resources - Accepts substantial compromise in recall rate |
| IVF_HSNW | Graph-based index (inverted) | - Inverted Index - HSNW Based - Requires a recall rate as high as possible - Large memory resources |
| DiskANN | Multiple nearest neighbor indices | - ANN Modifications and toolkit for ANN Searches |
| ANNOY | Multiple nearest neighbor indices | - LSH or KDtrees implementations - Memory-efficient and fast search in high-dimensional spaces |
| Many More | - | - FAISS, cuHNSW, ngt, song |
About ANN Benchmarks
Yuri breezes through ANN Benchmarking lightning fast - pointing to ANNBenchmarks with a caveat that benchmarking inverse ANN algorithms can get tricky. Lets slow that down:
What is ANN-Benchmarks?
ANN-Benchmarks is a benchmarking environment that evaluates various approximate nearest neighbor search algorithms, providing results split by distance measure and dataset on their website. The benchmarks display performance metrics like recall rate and queries per second, and users can contribute by submitting their code via GitHub pull requests.
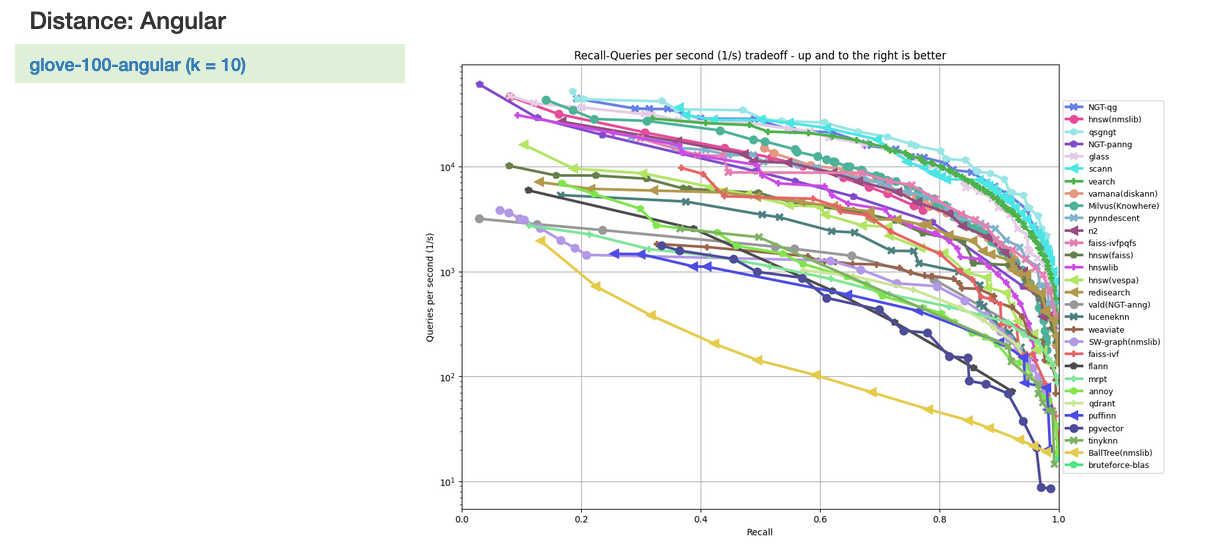
While you can find ANN algorithm benchmarking data many places (github, ANN-Benchmarks, even product documentation) you’ll always see charts plotting QPS - queries per second. More QPS more better! Vroom vroom!
A note on choosing ANN (and other vector search) algorithms
If looking at algorithm benchmarking gives you a nosebleed, you’re not alone. That’s why the Milvus team built Knowhere. Knowhere is the core open-source vector execution engine of Milvus which incorporates several vector similarity search libraries including Faiss, Hnswlib and Annoy. Knowhere controls on which hardware (CPU or GPU) to execute index building and search requests. This is how Knowhere gets its name - knowing where to execute the operations. More types of hardware including DPU and TPU will be supported in future releases.
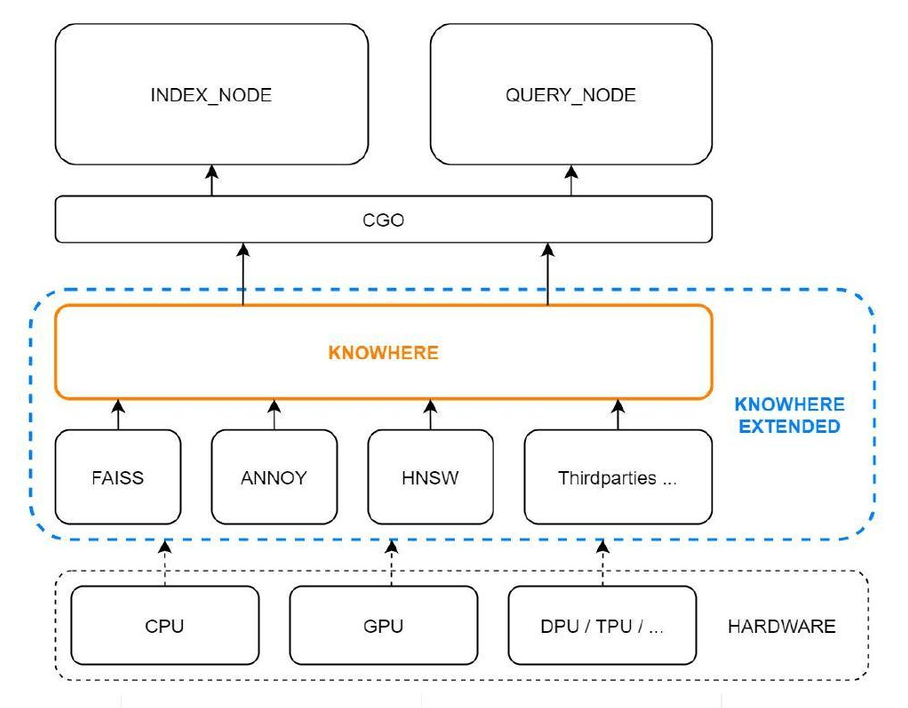
Building upon Knowhere - the Zilliz Cloud team released Cardinal which is Zilliz’s core vector search engine. This search engine has already demonstrated a threefold increase in performance compared to the previous version, offering a search performance (QPS) that reaches tenfold that of Milvus. ANN search has long been integrated into recommender systems. To find out why ANN search algorithms have become so popular in recommender systems in production, we need to take a step back and look at the motivations, architecture, and novel solutions that ANN outcompeted.
Recommendation system applications at scale: motivations and challenges
Goal: The basic goal of all recommender systems is to return an item (video, product, document, message) to a query (user, application, context). Remember this item-query relationship - it’s important to understanding search (recommender) algorithms.
Market: Recommender technologies have presented and represent a large market given their ability to generate consumer behavior.
Typical Challenges at Scale:
Generability:
- Traditionally recommender systems have had low generability - largely due reliance on internal data, models and infrastructure.
Huge corpuses:
- Large datasets (million to trillions of items, queries) generate large inference costs.
- Efficiency and constraining inference costs is very important.
- Heavy video and image processing has required dedicated engineers to maintain infrastructure.
Solutions, maturity:
- Homegrown solutions/infrastructure usually home grown (eg. Google, Meta, X,)
- Typically a multi staged recommender funnel (see below) to save inference costs
- Out of the box tools have been gaining popularity and traction in the rise of vector databases and LLMs.
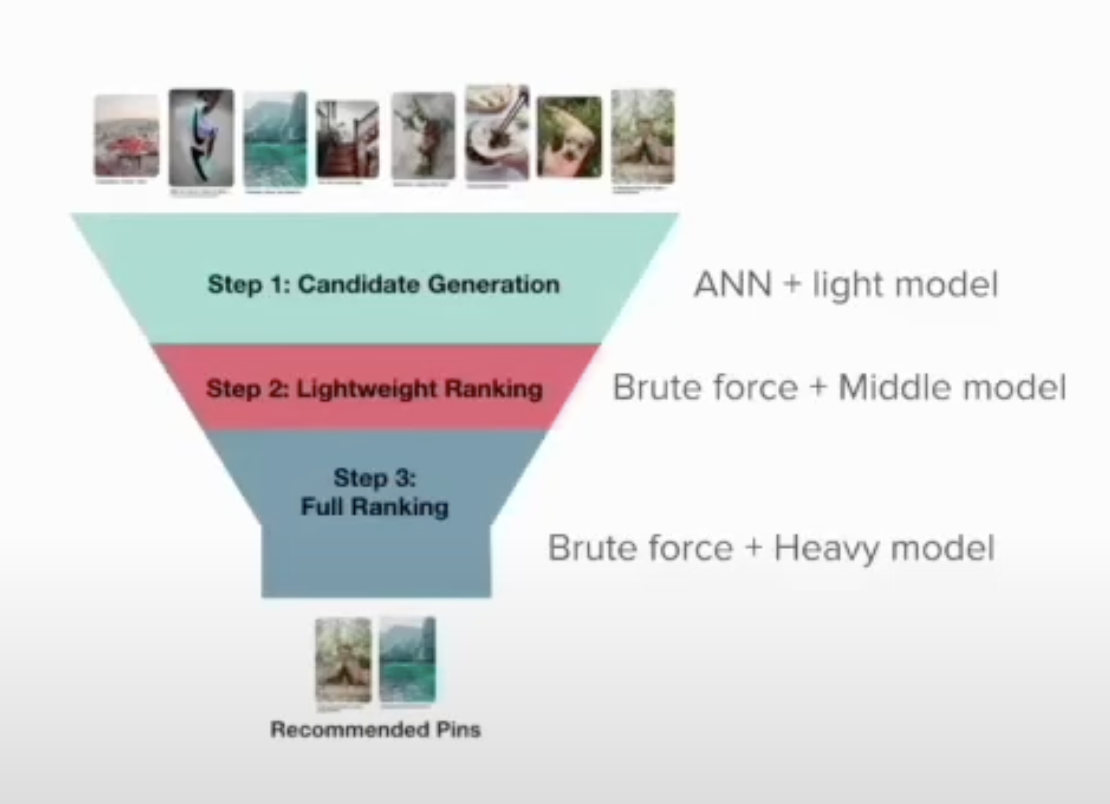
Typical Multi Staged Funnel
Yuri digs into a diagram of a typical recommender system in production. In the example below for video recommendation, an application is handed items and a query and must return a video recommendation pin. These applications are multi staged funnels where item candidates are generated and run through successive ranking models to refine search results.
Step 1: Candidate Generation - ANN + Light Model
In this initial stage, the system uses approximate nearest neighbors to quickly sift through the vast video database and identify a preliminary list of candidate videos that are relevant to the user’s query. This process is designed to be fast and efficient, dealing with potentially millions of items by focusing on those most likely to match the query characteristics. The 'Light Model' used in this step is typically a simpler, less computationally intensive model that helps to narrow down the pool of candidates to those that best align with the user's interests or search terms.
Step 2: Lightweight Ranking - Brute Force + Middle Model
Once a candidate set is generated, the next step involves a more detailed examination of these candidates. This is done using a 'Brute Force' approach where each candidate is evaluated more thoroughly using a 'Middle Model' which is more complex than the Light Model used in the first step. This model takes additional features into account, such as user engagement metrics, contextual relevance, and content quality, to rank the candidates in a way that the most relevant videos are pushed towards the top of the recommendation list. This step strikes a balance between performance and precision, refining the selection by focusing more on quality and relevance.
Step 3: Full Ranking - Brute Force + Heavy Model
The final step in the recommendation process is the Full Ranking stage, which employs a 'Heavy Model'—the most sophisticated and resource-intensive of the models used. This model incorporates a wide array of signals and data points, including deeper user profile analysis, long-term preferences, detailed content analysis, and possibly real-time data like current viewing trends. The Brute Force method applied here ensures that each video is comprehensively scored and ranked, ensuring that the final recommendations are highly personalized and relevant. This step ensures the highest quality recommendations but requires more processing power and time, making it suitable for the final refinement of the recommendations list.
Why HSNW falters for traditional recommender systems and (imperfect) solutions Knowing that large scale production recommendation systems are constrained by large datasets and the costs associated, Yuri asserts that items and queries lay on two - incompatible planes. When queries and items reside in different and incompatible spaces, traditional similarity search algorithms like Hierarchical Navigable Small World (HNSW) face challenges because these algorithms depend on a measurable relationshpp or distance function directly between the query and the items. Without a clear metric to evaluate closeness, HNSW cannot effectively perform its function, which is to navigate through a graph of items to find the closest matches to a query.****
A Review of Novel Solutions to Item-Query Incompatibility
L2 Distance on Data Vectors
How it works: Uses the L2 distance between vectorized data inputs to create a surrogate graph structure for recommendation systems.
Pros: Simplifies the process by using a straightforward distance calculation, offering a speed advantage during candidate generation and re-ranking phases.
Cons: May not capture complex relationships or nuances between items and queries as effectively as more sophisticated models, potentially leading to less personalized recommendations.
Bipartite Graph Ranking
How it works: Projects items and queries into a bipartite graph where items are linked to their closest users or queries, allowing edges to be generated based on these relationships.
Pros: Effective in structuring relational data between users and items, though direct comparisons with other methods are limited.
Cons: Construction and maintenance of the bipartite graph can be resource-intensive, and the effectiveness can vary greatly depending on the density and quality of the graph connections.
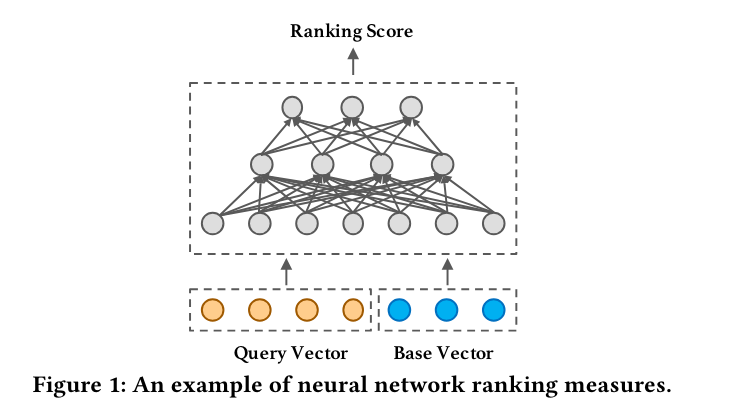
Image source: https://www.vldb.org/pvldb/vol15/p794-tan.pdf
Graph Re-ranking (Text-Focused)
How it works: Utilizes a graph created from vectors for candidate generation, directly applying a heavy ranker to the graph for text retrieval, which improves result quality.
Pros: Eliminates the traditional multi-staged funnel, allowing for correction of errors made in earlier stages of candidate filtering.
Cons: Primarily effective for text-based retrieval; may not be as effective in other contexts where non-textual features dominate, limiting its applicability.
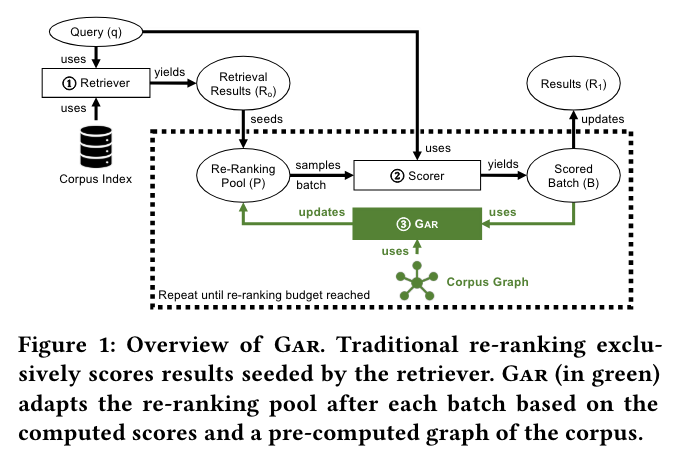
Image source: https://arxiv.org/pdf/2208.08942
Cascaded Graph Search
How it works: Begins with a light distance function for initial search and seamlessly transitions to a heavier distance function during the search process.
Pros: Provides flexibility by adapting the distance function in real-time, optimizing for both speed and accuracy throughout the search process.
Cons: The complexity of managing and optimizing dual distance functions can increase the computational overhead and complexity of the system, potentially impacting scalability.
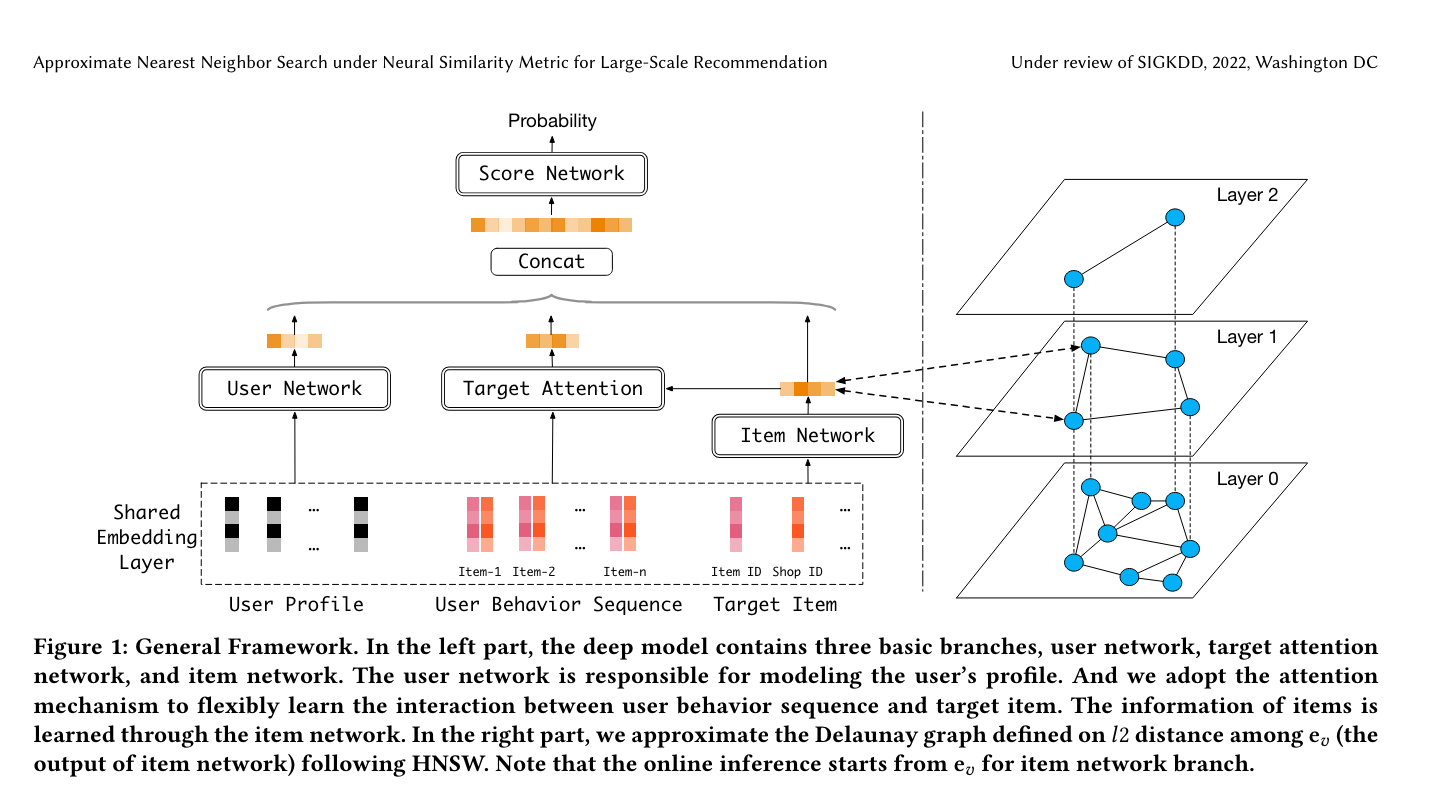
Image source: https://arxiv.org/pdf/2202.10226
Why ANN Search is so popular?
Putting that all together – Yuri has painted a good picture of why ANN algorithms have seen such extensive implementation, especially in applications (like large scale recommender systems) that work with highly dimensional datasets.
- Good enough (or better) Matching - If you don’t need a perfect match, an ANN flavor is always almost a better solution than other NN algorithms.
- Flexibility - with a wide range of implementations a developer can choose cost
- Maturity - ANN have been implemented in all major programming languages, and there are several popular frameworks for selecting and executing ANN searches.
Further Resources
Link to the YouTube replay of Yury Malkov’s talk: Watch the talk on YouTube

Keep Reading

Announcing the General Availability of Zilliz Cloud BYOC on Google Cloud Platform
Zilliz Cloud BYOC on GCP offers enterprise vector search with full data sovereignty and seamless integration.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.

Proactive Monitoring for Vector Database: Zilliz Cloud Integrates with Datadog
we're excited to announce Zilliz Cloud's integration with Datadog, enabling comprehensive monitoring and observability for your vectorDB deployments.