




SPLADEスパース・ベクターとBM25の比較
一般的に、ベクトルには密なベクトルと疎なベクトルの2種類がある。密なベクトル」と「疎なベクトル」です。これらは同じようなタスクに利用できますが、それぞれに利点と欠点があります。この投稿では、スパース埋め込みの2つの一般的なバリエーションについて掘り下げます:BM25 と SPLADE です。
シリーズ全体を読む
- Exploring BGE-M3 and Splade: Two Machine Learning Models for Generating Sparse Embeddings
- Comparing SPLADE Sparse Vectors with BM25
- Exploring ColBERT: A Token-Level Embedding and Ranking Model for Efficient Similarity Search
- Vectorizing and Querying EPUB Content with the Unstructured and Milvus
- What Are Binary Embeddings?
- A Beginner's Guide to Website Chunking and Embedding for Your RAG Applications
- An Introduction to Vector Embeddings: What They Are and How to Use Them
- Image Embeddings for Enhanced Image Search: An In-depth Explainer
- A Beginner’s Guide to Using OpenAI Text Embedding Models
- DistilBERT: A Distilled Version of BERT
- Unlocking the Power of Vector Quantization: Techniques for Efficient Data Compression and Retrieval
言語のベクトル表現は、自然言語処理 (NLP)を進める上で極めて重要である。簡単に言えば、テキストをベクトルに変換することで、コンピュータはテキストの内容と意味を効果的に捉えることができる。
これらのベクトルによって、感情分析、文書クラスタリング、質問応答、テキスト生成、意味類似性、ベクトル検索など、さまざまなNLPタスクが可能になる。似たようなコンテキストを表すベクトルは、以下の視覚化で示されるように、ベクトル空間内で互いに近接して配置される。
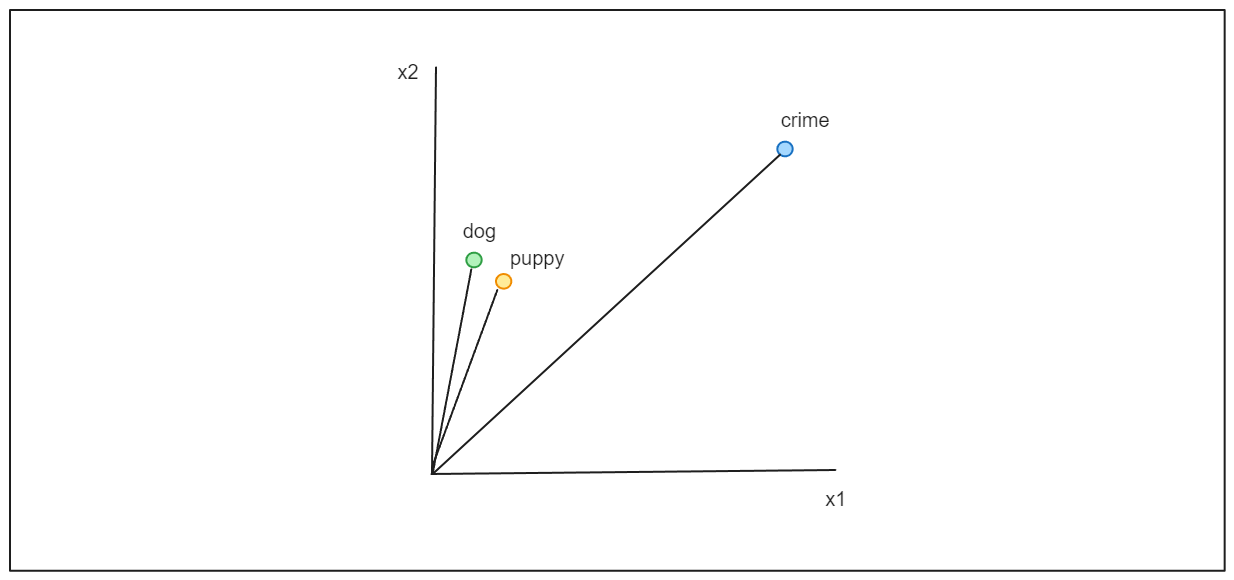
一般に、ベクトルには2つのタイプがあります:密なベクトルと疎なベクトルである。これらは似たようなタスクに利用できますが、それぞれに利点と欠点があります。
テキストエンティティをコンパクトに表現する密なベクトルの次元数は、テキストをベクトルに変換するために使用される深層学習モデルによって決定される。例えば、BERTは各トークンに対して768次元のベクトルを生成する。対照的に、スパース・ベクトルは密なベクトルよりも次元が高いが、その値のほとんどはゼロであるため、「スパース」と呼ばれる。
この投稿では、スパース埋込みの2つの一般的なバリエーションについて掘り下げます:BM25 と SPLADE です。まず、古い手法であるBM25から始めましょう。
BM25の基礎
ベストマッチング25(BM25)は、項頻度-逆文書頻度(TF-IDF)アルゴリズムの拡張とみなすことができるテキストマッチングアルゴリズムである。TF-IDFは情報検索アルゴリズムであり、文書集合に対する文書内のキーワードの重要度を測定する。
例えば、"machine learning"というキーワードがあり、このキーワードに基づいて、コレクションの中で最も関連性の高い文書を見つけたいとする。TF-IDFアルゴリズムは、次のような式を使用して、各文書内のキーワードの関連性スコアを計算します:

最も高い関連性スコアを持つドキュメントがユーザーに推薦される。
BM25はTF-IDFを強化したものと考えることができる:
文書の長さを考慮する。
キーワード飽和項の概念を取り入れている。
では、なぜこれらの改良が重要なのか、その理由に飛び込んでみよう。従来のTF-IDFアルゴリズムは、文書の長さを考慮していない。その結果、キーワードがより頻繁に出現する可能性は文書の長さとともに高くなるため、長い文書の方が短い文書よりも有利になる。BM25アルゴリズムは、項頻度(TF)式で文書の長さを正規化することで、この問題に対処している。
一方、BM25では飽和項を導入することで、文書内の潜在的なキーワードスパミングの問題に対処している。TF-IDFでは、文書内にキーワードが追加出現するごとにTF式は線形に増加する。しかし、1回から2回になることの影響は、100回から101回になることよりも大きいはずだと主張できるかもしれない。
BM25アルゴリズムの飽和項は、キーワードの出現頻度が高くなるにつれて、キーワードの出現による影響を徐々に減少させることで、この問題を解決する。さらに、飽和項の値を調整することで、キーワードの出現が飽和点に達するスピードをコントロールすることができる:
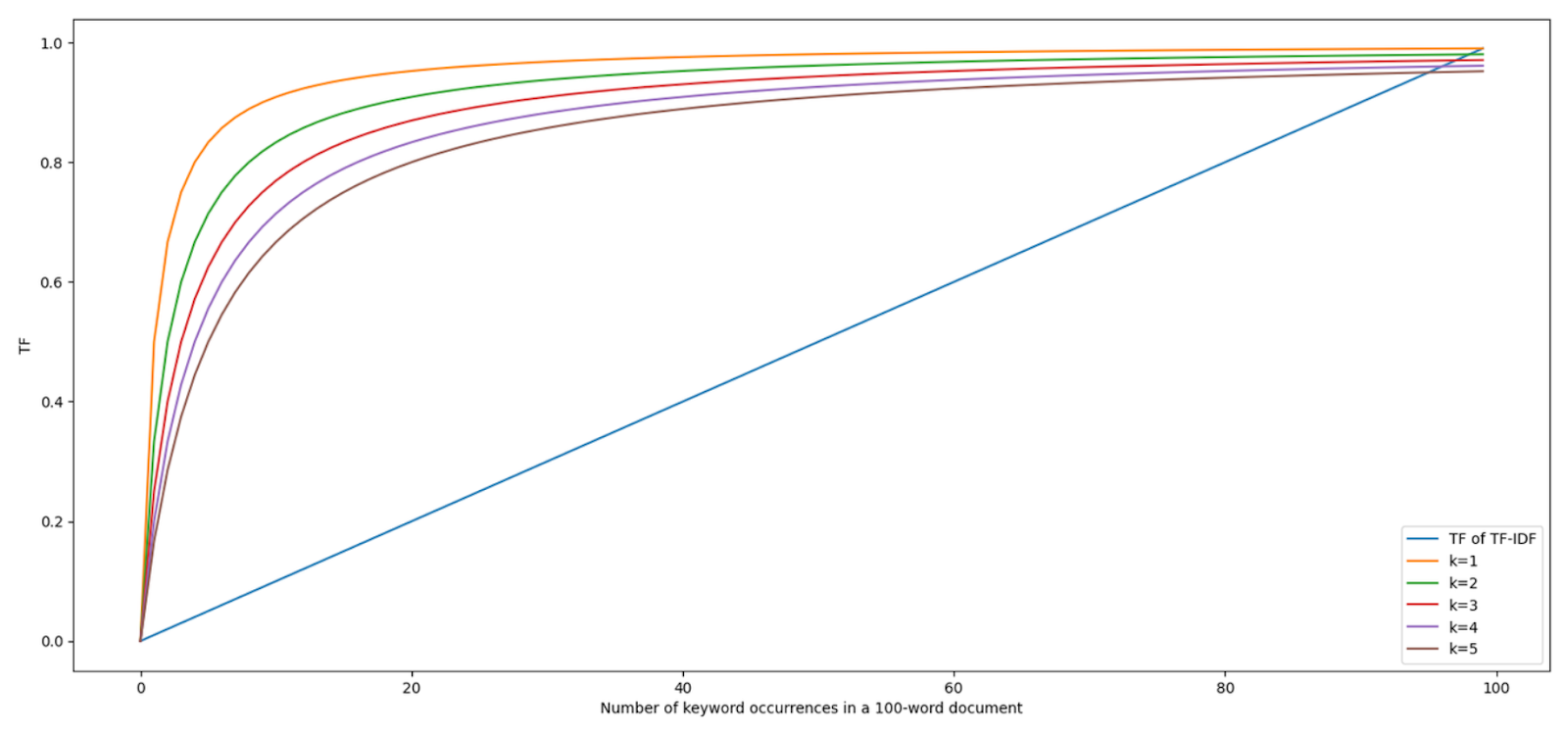
これらの重要な機能強化がBM25式に組み込まれることで、このアルゴリズムは従来のTF-IDFアプローチと比較して、情報検索結果を改善することができる。
BM25はスパース埋込みの一種であり、生成されるベクトルは主にゼロ値から構成される。BM25ベクトルの次元は、文書コレクション内のエンティティ(サブワード、単語、トークン)のユニークな数に依存する。BM25ベクトルのゼロ以外のエントリは、クエリキーワードが存在する次元に対応し、値はキーワードの関連性スコアを表す。
単一単語のキーワードがあり、各エンティティが単語を表す場合、BM25 ベクトルの 1 つの要素だけがゼロ以外の値を持つことになります。この条件は、キーワードの完全一致が文書内で見つかる場合に適用されます。そうでない場合は、ベクトル内のすべての値がゼロになります。
これは従来のスパースベクトルの欠点を浮き彫りにしている。クエリーキーワードの完全一致が文書内で見つからない場合、BM25のスパースベクトルは、文書が類似のトピックを論じていても、キーワードの重要性を捉えることができない。
この限界に対処するため、最近スパース埋め込みが進歩し、SPLADEが開発された。しかし、SPLADEを掘り下げる前に、SPLADEはこの強力なTransformer-encoderモデルに大きく基づいているため、BERTの基本概念を簡単に再確認しておこう。
BERTの基礎
トランスフォーマーからの双方向エンコーダー表現(BERT)は、最先端のトランスフォーマーエンコーダーベースのモデルで、多くの自然言語処理タスクで目覚ましい性能を発揮します。その名が示すように、このモデルは有名なTransformerアーキテクチャを構成要素としている。
![]()
Transformerは、さまざまなモダリティにわたってさまざまなタスクを実行できる、強力なエンコーダー・デコーダーベースのモデルです。Transformer アーキテクチャの主な特徴は、各エンコーダおよびデコーダブロック内の自己注 意レイヤであり、これにより、BERT を含む Transformer から派生したモデルは、テキスト入力の意味的な意味を効 果的に捉えることができる。
BERT は、複数の Transformer エンコーダブロックから構成され、これらのエンコーダブロックの数は、特定の BERT バリアントに依存する。たとえば、BERT Base モデルは 12 個のエンコーダブロックで構成され、BERT Large モデルには 24 個のエンコーダブロックがあります。
![]()
BERT モデルの事前学習プロセスには、マスク言語モデリング(MLM)として知られる技法が含まれる。この手法では、入力トークンの一定割合がランダムに [MASK] トークンに置き換えられ、このマスクされたトークンを予測することが目的である。BERT で使用される Transformer エンコーダの双方向性により、モデルは、入力シーケンス全体のコンテキ ストに基づいて、任意の位置で最も可能性の高いトークンを予測することができる。
SPLADE の基礎
SPLADE は学習可能なスパース・ベクトルを生成し、通常のスパース・ベクトルを超える。SPLADE は、その構築において BERT の MLM 機能を活用している。このプロセスは、BERTと同じサブワードレベルのトークン化プロセスを使用して、文書とクエリの両方をトークン化することから始まる。次に SPLADE は、各トークンに対して MLM アプローチを採用し、シーケンス全体のコンテキストを考慮しながら、30,522 個のトークンからなる BERT の語彙から、各位置に対して最も可能性の高いトークンを予測する。
その後、SPLADE は、全ポジションにわたる各トークンについてこれらの確率を結合し、対数飽和法を適用してデータ のスパース性を導入する。結果として得られる重みは、各ボキャブラリー・トークンと入力トークンとの関連性を示し、これにより学習されたスパース・ベクトルが作成される。
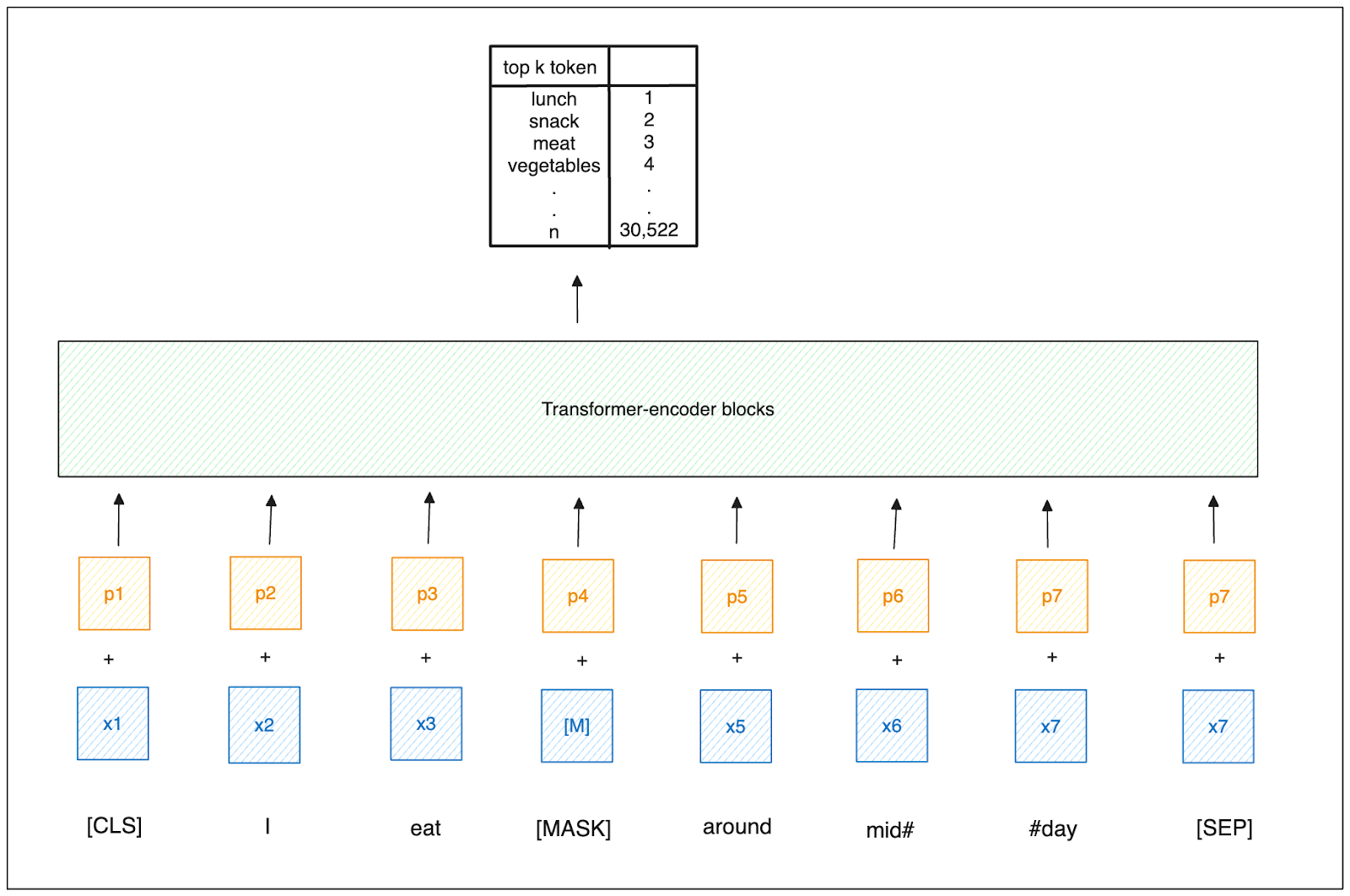
ご想像の通り、SPLADEによって生成される非ゼロ値は、BM25のような従来のスパースベクトルよりもはるかに高い傾向があります。
これを説明するために、"study"のようなキーワードを考えてみよう。BM25を使ってスパースベクトルに変換すると、対応するベクトルには非ゼロ値が1つしかない。対照的に、SPLADEを使えば、"learn"、"research"、"investigate"のような類似の用語に関連するベクトル要素も非ゼロになるため、複数の非ゼロ値を持つ可能性が高くなります。
SPLADEは、キーワードが完全に一致しなくても、意味的に類似した用語を捉えることができるため、与えられたクエリに対してより関連性の高い文書を検索することができる。
BM25とSPLADEの実装
BM25とSPLADEの主な違いを理解したところで、テキスト検索を行うためにMilvusを使って両者を実装してみよう。
もしよろしければ、提供されている notebookで実装コードをご覧ください。
BM25のような伝統的なスパース埋め込みを使うには、コーパスとなるデータが必要です。この目的のために、HuggingFaceで利用可能な 気候変動データをコーパスとして使います。データをダウンロードすることから始めよう。
import pymilvus
from pymilvus import MilvusClient
from pymilvus import (
ユーティリティ
FieldSchema, CollectionSchema, DataType、
Collection, AnnSearchRequest, RRFRanker, connections、
)
from pymilvus.model.sparse.bm25.tokenizers import build_default_analyzer
from pymilvus.model.sparse import BM25EmbeddingFunction,SpladeEmbeddingFunction
from datasets import load_dataset
dataset = load_dataset("climate_fever")
データセットを見てみると、4つのカラムがある:claim_id、claim、claim_label、evidencesである。BM25のコーパスでは、claimカラムだけを使うことにする。以下はclaim` カラムの中身の例である。
corpus_text = dataset['test']['claim'].
print(corpus_text[:5])
"""
出力:
['地球温暖化がホッキョクグマを絶滅に向かわせている'、
'太陽は凍てつくような天候、地震、飢饉を引き起こす可能性のある「ロックダウン」に入ったと科学者は言う'、
ホッキョクグマの個体数は増加している、
「皮肉なことに、CO2の増加が地球をわずかに冷やしたという研究結果が出ている、
人為的なCO2添加は現在の測定値の誤差の範囲内であり、CO2の漸増は主に、地球が最後の氷河期から徐々に脱却する際の海洋の脱ガスによるものである。]
"""
コーパスのテキストができたので、それを使ってBM25モデルをフィットさせてみよう。
analyzer = build_default_analyzer(language="en")
# Analyzerを使ってBM25EmbeddingFunctionをインスタンス化する
bm25_ef = BM25EmbeddingFunction(analyzer)
# コーパスの統計量を得るために、コーパスにモデルをフィットする
bm25_ef.fit(corpus_text)
一方、SPLADEはBERTモデルを活用しているため、特定のコーパスにSPLADEモデルを当てはめる必要はない。そのため、テキストをスパース埋め込みに変換するためにすぐに使うことができる。
今、5つのテキストがあり、それらをスパース埋め込みに変換したいとしましょう。Milvusの encode_documents() メソッドを使えば、簡単にできます。
documents = ["現在、世界の食料の多くを供給しているこれらの場所のうち、科学者が信頼できる供給源となる場所はない、
「今後25、30年の間に、気候は徐々に温暖化するだろう、と科学者は言う。しかし、人間の排出をゼロにすれば、この現象は食い止められるとも研究者は言っている、
「ジェット気流は寒い北と暖かい南の境界を形成しているが、気温差が小さくなったため、風が弱くなった、
「サンゴはストレスを受けて藻類を排出し、白化する、
「気候の急激な変化は、人間や他の生物種に深刻な影響を及ぼすかもしれない。エチオピアでは深刻な干ばつが数百万人の食糧不足を引き起こし、インドネシアでは降雨不足が激しく広範囲に及ぶ森林火災を引き起こし、大量の温室効果ガスを排出した。]
# ドキュメントの埋め込みを作成する
bm25_docs_embeddings = bm25_ef.encode_documents(documents)
print("Sparse dim:", bm25_ef.dim, list(bm25_docs_embeddings)[0].shape)
splade_ef = SpladeEmbeddingFunction(
model_name="naver/splade-cocondenser-ensembledistil"、
device="cpu"
)
"""
出力
スパース dim: 3432 (1, 3432)
"""
splade_docs_embeddings = splade_ef.encode_documents(documents)
print("Sparse dim:", splade_ef.dim, list(splade_docs_embeddings)[0].shape)
"""
出力
スパース dim: 30522 (1, 30522)
"""
BM25とSPLADEのスパースベクトルの次元は上記のように異なる。BM25ベクトルの次元はコーパステキスト内の語彙サイズによって決定され、SPLADEベクトルの次元はベースとなるディープラーニングモデルに対応する。SPLADEが30,522の語彙サイズを持つBERTに基づいて構築されていることを考えると、SPLADEのベクトル次元も30,522である。
5つのテキストをそれぞれBM25とSPLADEのベクトル埋め込みに変換した後、次のステップは、それらを保存し、必要に応じて効率的に検索するためのデータベースを構築することである。これを実現するために、ベクトルデータベースとしてMilvusを利用する。まず、コレクションのスキーマを定義する必要がある。コレクションには4つのフィールドが必要である:ID、テキスト、BM25埋め込み、SPLADE埋め込みである。
エンベッディングを格納する前に、ベクトルのインデックス方法を決定することも重要である。Milvusはスパースベクトルに対して、inverted indexまたはWeak-AND(WAND)アルゴリズムの2つのインデックス作成方法を提供しています。スパースベクトルの次元数が高いため、転置インデックス法が推奨されます。この方法は、各次元を埋め込み内の非ゼロ値にマップし、検索時に関連データへの直接アクセスを容易にします。
Milvusは現在、ベクトル検索に使用されるメトリクスのうち、内積のみをサポートしています。したがって、ベクトル検索操作にはこのメトリックを使用することにします。
connections.connect("default", host="localhost", port="19530")
fields = [
フィールドスキーマ(name="pk", dtype=DataType.VARCHAR、
is_primary=True, auto_id=True, max_length=100)、
FieldSchema(name="text",dtype=DataType.VARCHAR,max_length=512)、
FieldSchema(name="bm25_vector", dtype=DataType.SPARSE_FLOAT_VECTOR)、
FieldSchema(name="splade_vector", dtype=DataType.SPARSE_FLOAT_VECTOR)、
]
schema = CollectionSchema(fields, "")
col = Collection("bm25_splade_demo", schema)
sparse_index = {"index_type":index_type": "SPARSE_INVERTED_INDEX", "metric_type":"IP"}。
col.create_index("bm25_vector", sparse_index)
col.create_index("splade_vector", sparse_index)
# スキーマにデータを挿入
エンティティ = [documents, bm25_docs_embeddings, splade_docs_embeddings] # スキーマにデータを挿入する
col.insert(entities)
col.flush()
埋め込みデータをベクトルデータベースに格納したので、クエリに基づいてベクトル検索を行い、BM25とSPLADEの結果を比較してみましょう。
次のようなクエリがあるとする:「科学者は気候について何を言っているのか?BM25とSPLADEの結果を比較してみよう。
クエリをベクトル埋め込みに変換するには、単純に encode_queries() メソッドを使います。
def get_relevant_text(query_embeddings, anns_field):
res = client.search(
コレクション名="bm25_splade_demo"、
data=query_embeddings[0]、
anns_field=anns_field、
limit=1、
search_params={"metric_type":"IP", "params":{}},
output_fields =["text"])
)
print(res)
# Milvusクライアントのセットアップ
クライアント = MilvusClient(
uri="<http://localhost:19530>"
)
collection = Collection("bm25_splade_demo") # 既存のコレクションを取得します。
collection.load()
queries = ["科学者は気候について何を言っているのか?"] # # コレクションを読み込む
bm25_query_embeddings = bm25_ef.encode_queries(queries)
"""
出力
{'id': '449467966088806767', 'distance':7.698919773101807, 'entity':{'text': '今後25、30年の間に、気候は徐々に温暖化する可能性が高いと科学者は言う。しかし、研究者たちは、人間の排出量をゼロにすれば、この現象を食い止めることができるとも言っている。]
"""
splade_query_embeddings = splade_ef.encode_queries(queries)
"""
[[{'id': '449467966088806767', 'distance':16.795665740966797, 'entity':{'text': '今後25、30年の間に、気候は徐々に温暖化する可能性が高いと科学者は言う。しかし、研究者たちは、人間の排出量をゼロにすれば、この現象を食い止めることができるとも言っている。]
"""
ご覧のように、BM25もSPLADEも、クエリーに従って最も関連性の高い文書をフェッチすることができる。クエリに含まれる"scientists"、"climate"、"say"という単語は、結果の文書にも含まれているので、この結果は予想通りである。
では、別のクエリーを試し、両方のアルゴリズムの結果をもう一度確認してみましょう。今度は、"What will get incrementally hotter?"というクエリーです。先ほどと同じ方法で、以下のような結果が得られます。
queries = ["What will get incrementally hotter?"] クエリー = ["What will get incrementally hotter?
bm25_query_embeddings = bm25_ef.encode_queries(queries)
splade_query_embeddings = splade_ef.encode_queries(queries)
get_relevant_text(bm25_query_embeddings, "bm25_vector")
"""
出力
[[]]
"""
get_relevant_text(splade_query_embeddings, "splade_vector")
"""
出力
[[{'id': '449467966088806767', 'distance':6.944008827209473, 'entity':{'text': '今後25、30年の間に、気候は徐々に温暖化する可能性が高いと科学者は言う。しかし、研究者たちは、人間の排出量をゼロにすれば、この現象を食い止めることができるとも言っている。]
"""
この例では、BM25とSPLADEは異なる結果を出している。BM25は与えられたクエリにマッチする文書を見つけることができないが、SPLADEは最も関連性の高い文書を特定することができる。
これはBM25が文字列の完全一致アルゴリズムであるためである。クエリと文書の間に語彙の不一致がある場合、その文書は、たとえクエリと意味的に類似した意味を持っていたとしても、マッチすることはできない。
一方、SPLADE は、洗練された BERT モデルを活用することで、クエリと文書内容の意味的類似性を把握することができる。これによりSPLADEは、クエリ内の特定の用語が文書内の用語と完全に一致しない場合でも、最も関連性の高い文書を検索することができる。
BM25とSPLADEの考察
BM25とSPLADEは、それぞれ長所と短所を持つ2つの疎な埋め込みベクトルです。
BM25は直感的な情報検索アルゴリズムであり、予測可能な動作と容易に説明可能な結果を提供する。そのベクトルは、SPLADEに比べて非ゼロ値が少ないため、検索プロセスが向上し、優れた検索効率につながります。
また、BM25は正確な文字列マッチングに依存しており、特定の学習可能なディープラーニングモデルに依存していないため、追加の微調整は必要ない。ただし、クエリで使用される語彙はコーパス内でも見つかる必要があり、そうでない場合はマッチング結果が返されないリスクがある。
対照的に、SPLADEはより多くの非ゼロ値を含むベクトルを生成するため、検索処理が遅くなる。しかし、SPLADEには各入力単語に対して意味的に類似した用語を含める機能があるため、この特性は優れた結果をもたらす可能性がある。また、BERTを基盤としているため、クエリの語彙がコーパスに存在しない場合でも、良好な結果を得られる可能性がある。
しかし、同じモデルを異なるデータ・ドメインに使用した場合、SPLADEの性能がBM25より優れている保証はない。他のディープラーニングモデルと同様に、SPLADEもBM25を大きく上回るためには、特定のデータに応じて微調整する必要がある。
結論
この記事では、テキストをスパース埋め込みに変換するための最も人気のある2つのアルゴリズムについて説明した:BM25とSPLADEである。BM25は、高速で効率的な文書検索を可能にする完全一致アルゴリズムです。もし大規模なコーパスがあり、ドキュメントのコレクションが同じドメイン内にある場合、BM25は強力なベースラインとして使用できます。
一方、SPLADEはより洗練されたアルゴリズムであり、BERTを活用してクエリと文書の両方で語彙を拡張する。これにより、SPLADEは、クエリに含まれる正確な用語がどの文書にも見つからない場合でも、関連する文書を検索することができる。

読み続けて

BGE-M3とSplade: スパース埋め込みを生成する2つの機械学習モデルの探究
このブログでは、ベクトル埋め込みという複雑な世界を旅し、BGE-M3とSpladeがどのように学習されたスパース埋め込みを生成するのかを探ってきました。

ColBERTの探求:効率的な類似検索のためのトークン・レベルの埋め込みとランキング・モデル
BERTのような従来の埋め込みモデルは、埋め込みを単一のベクトルにプールすることに重点を置いているが、ColBERTは個々のトークン表現を保持する。革新的なレイト・インタラクション・メカニズムにより、より正確できめ細かな類似度計算が可能です。

ベクトル量子化のパワーを解き放つ:効率的なデータ圧縮と検索のテクニック
ベクトル量子化(VQ)は、データ圧縮技術の一つで、セントロイドと呼ばれる、より小さな代表ベクトルの集合で、類似したデータ点の大きな集合を表現する。