




ColBERTの探求:効率的な類似検索のためのトークン・レベルの埋め込みとランキング・モデル
BERTのような従来の埋め込みモデルは、埋め込みを単一のベクトルにプールすることに重点を置いているが、ColBERTは個々のトークン表現を保持する。革新的なレイト・インタラクション・メカニズムにより、より正確できめ細かな類似度計算が可能です。
シリーズ全体を読む
- BGE-M3とSplade: スパース埋め込みを生成する2つの機械学習モデルの探究
- SPLADEスパース・ベクターとBM25の比較
- ColBERTの探求:効率的な類似検索のためのトークン・レベルの埋め込みとランキング・モデル
- UnstructuredとMilvusによるEPUBコンテンツのベクトル化とクエリ
- バイナリ・エンベッディングとは?
- RAGアプリケーションのためのウェブサイト・チャンキングと埋め込み入門ガイド
- ベクトル埋め込み入門:ベクトル埋め込みとは何か?
- 画像検索のための画像埋め込み:詳細な説明
- OpenAIのテキスト埋め込みモデルを使うための初心者ガイド
- DistilBERT:BERTの蒸留バージョン
- ベクトル量子化のパワーを解き放つ:効率的なデータ圧縮と検索のテクニック
ベクトル検索は、特に大規模言語モデル(LLM)の登場以降、近年爆発的な成長を遂げている。この人気により、学術研究では、学習データの拡大、高度な学習方法、新しいアーキテクチャによる埋め込みモデルの強化に大きな注目が集まっている。
以前の記事](https://zilliz.com/learn/bge-m3-and-splade-two-machine-learning-models-for-generating-sparse-embeddings)では、効果的な情報検索のために調整された様々なタイプのベクトル埋め込みとモデルについて紹介しました。これらには、長所と短所を持つ特定のユースケースのために設計された、密な、疎な、バイナリ埋め込みが含まれます。さらに、密なベクトル生成と検索のためのBERTや、疎な埋め込み生成と検索のためのSPLADEやBGE-M3など、様々な埋め込みモデルについても議論しました。
本稿では、効率的な類似検索のために設計された革新的な埋め込み・ランキングモデルであるColBERT,について解説する。
BERT の簡単なまとめ
洗練されたモデルである ColBERT は、BERT によって確立された原則の自然な拡張である。ColBERTの複雑さを探る前に、BERTを簡単に再確認しておこう。この比較は、ColBERT がもたらす進歩と改善を理解するのに役立つ。
BERTは、Bidirectional Encoder Representations from Ttransformersの略で、変換器アーキテクチャに基づく言語モデルであり、高密度の埋め込みと検索モデルに優れている。BERT は、文の左から右へ、またはその逆へ移動する従来の逐次的な自然言語処理手法とは異なり、単語列全体を同時に分析することで 単語の文脈を把握し、高密度の埋め込みを生成します。では、BERT はどのようにしてこれらの埋め込みを生成するのだろうか。
BERTはどのようにしてベクトル埋め込みを生成するのか】(https://assets.zilliz.com/How_BERT_generates_vector_embeddings_567afa0152.png)
まず、BERT は、文をトークンと呼ばれる単語の断片にトークン化します。そして、生成されたトークン列の先頭に特別なトークン[CLS]を、トークンの末尾にトークン[SEP]を付加して、文を区切り、終わりを示します。
次に、埋め込みと符号化が行われる。BERT は、埋め込み行列と複数層のエンコーダを通して、各トークンをベクトルに変換します。これらの層は、シーケンス内の他のすべてのトークンによって提供される文脈情報に基づいて、各トークンの表現を洗練します。
最後に、すべてのトークン・ベクトルは、プーリング演算を使用して結合され、統一された密な表現が形成されます。
BERTの仕組みに関するより包括的な洞察については、BERTに関するこの詳細なブログ記事を参照してください。
ColBERTとは?
ColBERTは、Contextualized Late Interaction over BERTの略で、BERTのような従来の埋め込みモデルからのパラダイムシフトを意味します。トークン・ベクトルを単数表現に統合するBERTとは異なり、ColBERTはトークンごとの表現を維持し、類似度計算においてより細かい粒度を提供する。ColBERT を際立たせているのは、クエリとドキュメントの類似性比較のために、新しいレイト・インタラクション・メカニズムを導入していることである。このメカニズムは、検索プロセスの最終段階までクエリと文書を別々に扱うことで、効率的で正確なランキングと検索を可能にする。
要するに、BERT やその他の従来の埋め込みモデルが、各文書に対して単一のベクトルを生成し、クエリとの関連性を示す単一の数値スコアをもたらすのに対して、ColBERT は、クエリの各トークンが文書の各トークンとどのように整合するかを示すベクトルのリストを提供する。このアプローチは、クエリと文書間の意味的関係のより詳細で微妙な理解を提供する。
ColBERT アーキテクチャーの理解
下図は、ColBERT の一般的なアーキテクチャを示している:
クエリーエンコーダー
文書エンコーダ
レイトインタラクションメカニズム
クエリ q と文書 d が与えられた場合の ColBERT の一般的なアーキテクチャ](https://assets.zilliz.com/The_general_architecture_of_Col_BERT_30db3739a3.png)
クエリ Q と文書 D を処理するとき、ColBERT はクエリエンコーダーを利用して Q を Eq と呼ばれる固定サイズの埋め込みセットに変換し、文書エンコーダーを利用して D を別の埋め込みセット Ed に変換する。EqとEdの各埋め込みは、QとD` 内の周囲の用語から文脈情報を得ている。
EqとEdを手にした ColBERT は、最大類似度(MaxSim)演算の集約と定義する後期相互作用アプローチによって、QとDの関連性スコアを計算する。具体的には、このアプローチはEq内の各vとEd` 内のベクトルの最大余弦類似度を特定し、合計によってこれらの結果を結合する。コサイン類似度の他に、ColBERT はベクトルの類似度を測定するメトリックとして L2 距離の二乗も使用する。
概念的には、この後発の相互作用メカニズムは、クエリ内のコンテキストを考慮しながら、各クエリ語 tq を文書の埋め込みと比較する。この処理では、tq と文書内の用語 td との間で最も高い類似度スコアを特定することで、「一致」の程度を定量化する。ColBERT は、すべてのクエリ用語にわたる一致エビデンスを統合することで、これらの用語スコアを集約して、文書の関連性を推定する。
クエリーエンコーダー
クエリ Q を処理するとき、クエリエンコーダは BERT ベースのモデルを利用して Q をトークン化し、q1, q2, ..., ql と表記されるワードピーストークンにする。さらに、BERTのシーケンス開始トークン[CLS]の直後に特別な[Q]トークンを挿入する。クエリが事前に定義された閾値 Nq よりも少ないトークンを含む場合、長さ Nq に達するまで、[mask]トークンでパディングされる。逆に Nq 個のトークンを超える場合は、最初の Nq 個のトークンに切り詰められる。この調整された入力トークンのシーケンスは、次に BERT の深層変換アーキテクチャに供給され、各トークンについて文脈化された表現を生成する。結果として得られる出力は、以下のように定義された埋め込みベクトルの集合から構成される:
Eq :=正規化( CNN( BERT("[Q], q0, q1, ...ql, [mask], [mask], ..., [mask]") ))_
ここで、Eq は、特別な[Q]トークンとパディングされたトークンを含む調整されたトークン列を BERT の変換層に通し、さらに洗練するために畳み込みニューラルネットワーク(CNN)演算を適用することによって得られる正規化出力を表す。
ドキュメントエンコーダ
ドキュメントエンコーダはクエリーエンコーダと同様に動作する。文書 D が提示されると、それをトークン化して、d1, d2, ..., dn と表記される単語トークンにする。この処理に続いて、文書エンコーダは、文書の開始を示すために、BERT の開始トークン [CLS] の直後に特別な [D] トークンを挿入する。クエリトークナイゼーション処理とは異なり、[mask]トークンは文書に追加されない。
この入力シーケンスを BERT と後続の線形レイヤに通した後、文書エンコーダは、事前に定義されたリストに基づいて、句読点記号に対応する埋め込みを識別して除去する。このフィルタリングステップは、文書あたりの埋め込み数を減らすことを目的としており、文脈化された埋め込みでさえも、このようなフィルタリングの恩恵を受ける可能性があるという仮説の下で動作する。
出力は Ed と表記されるベクトルの集合からなる:
Ed := Filter( Normalize( CNN( BERT("[D], d0, d1, ..., dn") ) )) )_
ここで、Ed は、トークン化された文書を BERT の変換レイヤーを通して処理し、畳み込みニューラルネットワー ク演算を適用し、句読点記号に関連する埋め込みをフィルタリングすることによって得られる、正規化されフィルタリング された出力を表す。
後期相互作用メカニズム
情報検索において「相互作用」とは、クエリと文書のベクトル表現を比較することで、その関連性を評価することを指す。「後期相互作用」とは、この比較が、クエリと文書が独立してエンコードされた後に行われることを意味する。このアプローチは、BERTのような "早期相互作用 "モデルとは対照的であり、クエリとドキュメントの埋め込みは、より早い段階、多くの場合、エンコード前やエンコード中に相互作用する。
ColBERTは、クエリー表現と文書表現の事前計算を可能にする後期相互作用メカニズムを採用する。そして、既に符号化された表現の類似性を比較するために、終盤に合理化された対話ステップを採用する。早期相互作用アプローチと比較して、後期相互作用は、検索時間の短縮と計算要件の低減をもたらし、広範な文書コレクションを効率的に処理するのに適している。
では、後期相互作用プロセスはどのように機能するのだろうか?
先に述べたように、エンコーダーはクエリと文書をトークンレベルの埋め込み Eq と Ed のリストに変換する。そして、レイトインタラクションステージでは、コサイン類似度またはL2距離の二乗メトリクスのいずれかを用いて、一連の最大類似度(MaxSim)計算を行う。そして、これらの計算を集約して、トークン・ベクトルの関連性スコア(Sq,d)を計算する。この計算の数学的表現を以下に示す:
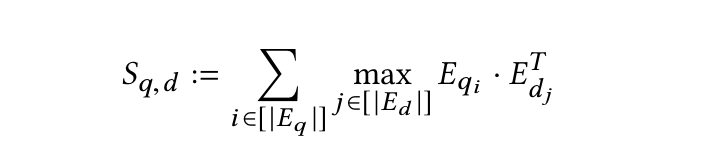 maxsim計算
maxsim計算
このアプローチ独自の値により、トークン埋め込みを詳細かつきめ細かく比較することができ、クエリとドキュメント内の様々な長さのフレーズやセンテンス間の類似性を効果的に捉えることができます。この方法は、テキストセグメント間の正確なマッチングが必要とされるユースケースで特に有用であり、検索やマッチングプロセスの全体的な精度を向上させる。
ColBERTv2: 改良型ColBERTによる検索効果と保存効率の向上
ColBERT は、クエリーとドキュメントを個別にエンコードし、正確な類似性測定のために詳細なレイト・インタラクションを採用することで、その有効性を確立してきた。文ごとに1つのベクトルを生成するSentence-BERTとは異なり、ColBERTは、文内の各単語ピース・トークンに1つのベクトルを生成する。このアプローチは、類似性検索において効果的であるが、これらのモデルの空間フットプリントを桁外れに増大させ、検索システムにおける実用的な展開の際に、ストレージ消費を増大させる必要がある。
これらの課題に対処するために、ColBERTv2が導入された。この反復では、積量子化(PQ)をセントロイドベースの符号化戦略と統合することで、ColBERTを強化している。積量子化を適用することで、ColBERTv2はトークン埋め込みを大幅な情報損失なしに圧縮することができ、モデルの検索効果を維持しながらストレージコストを削減することができる。この変更により、ストレージ効率が最適化され、モデルのきめ細かな類似性評価機能が維持されるため、ColBERTv2は大規模検索システムにとってより現実的なソリューションとなる。
ColBERTv2 におけるセントロイドベースの符号化
ColBERTv2 では、デコーダによって生成されたトークン・ベクトルは、セントロイドによって示され る個別のグループにクラスタ化される。このアプローチでは、セントロイド・インデックスが各ベクトルを記述し、そのセントロイドからの偏差をキャプチャする残差成分がある。この残差の各次元は、効率的にわずか1~2ビットに量子化される。その結果、元のベクトルは、セントロイド・インデックスと量子化された残差の組み合わせによって、実際のベクトルとのわずかなズレだけで効果的に表現できる。このような不一致が検索精度全体に与える影響はごくわずかである。
セントロイドベースのベクトルで類似検索を行う方法
セントロイドベースを使った類似検索の方法](https://assets.zilliz.com/How_to_conduct_similarity_retrieval_with_centroid_based_vectors_86750bde01.png)
まず、ColBERTv2 は、セントロイドとそれに関連する量子化された残差で各文書を表現する、先に説明したセントロイドベースの方法を用いて文書を効率的にエンコードする。同様に、エンコーダはクエリをトークンレベルのベクトル集合に変換する。
検索フェーズでは、各クエリベクトル qi に対して、あらかじめ決められた数のセントロイド(nprobe)を検索することから始める。次に、これらのセントロイドに対応するベクトルを低ビットの量子化残差から再構成し、文書IDに基づいてグループ化する。この整理により、その後のマッチング処理が効率化される。
文書IDによってベクトルを分類したら、目標は各qiに最も類似するベクトルを特定することに移る。例えば、クエリベクトル q1 が文書1のベクトル d1 と密接に一致し、この文書のグループに {d1, d3, d5} が含まれる場合、{d1, d2, d3, d4, d5} の完全なMaxSimを計算する必要はない。これは、ベクトル d2 と d4 は最初の nprobe クラスタに含まれないため、クエリベクトル qi と一致する可能性が低いからである。最も関連性の高いグループ分けを特定した後、システムは上位K個の最も類似した文書を検索する。最終的な再ランク付けのために、これらの文書の全ての完全なベクトルをロードする。
要約
ColBERTをレビューすることで、トークンレベルの埋め込みとランキングに対する新しいアプローチが明らかになった。BERTのような埋め込みを単一のベクトルに集約することに焦点を当てた従来の埋め込みモデルとは異なり、ColBERTは個々のトークン表現を保持し、革新的な後期相互作用メカニズムによって、より正確できめ細かい類似度計算を可能にする。
また、積の量子化とセントロイドベースのエンコーディングにより、前作のストレージ要求を軽減した反復であるColBERTv2も取り上げた。これらの革新は、ストレージ効率を改善し、モデルの検索効果を維持する。ColBERT モデルの継続的な改良と革新は、エンベッディング技術のダイナミックな進歩を浮き彫りにし、将来の検索シス テムにおける精度と効率のさらなる向上への有望な見通しを示している。
参考文献
 David Wang
David WangDavid Wang, Algorithm Engineer at Zilliz, brings extensive expertise in computer vision and natural language processing. His contributions to advanced embedding algorithm research, including projects like Towhee and GPTCache, reflect his commitment to advancing AI technologies. Before joining Zilliz, he worked at Alibaba Cloud for large-scale object recognition and classification projects. David holds a Master's degree from Dalian University of Technology.
読み続けて

UnstructuredとMilvusによるEPUBコンテンツのベクトル化とクエリ
この投稿では、MilvusとUnstructuredフレームワークを使用してEPUBデータのベクトル化と検索を探求し、LLMのパフォーマンスを向上させるための実用的な洞察を開発者に提供します。

ベクトル埋め込み入門:ベクトル埋め込みとは何か?
このブログポストでは、ベクトル埋め込みという概念を理解し、その応用、ベストプラクティス、埋め込みを扱うためのツールを探ります。

DistilBERT:BERTの蒸留バージョン
DistilBERTは、BERTの言語理解能力の97%を維持しながら、40%の小型化と60%の高速化を実現している。