




バイナリ・エンベッディングとは?
このブログでは、バイナリ埋込みの概念を紹介し、その定義的特徴、利点、および他の埋込みタイプとの比較メリットを明確にします。
シリーズ全体を読む
- Exploring BGE-M3 and Splade: Two Machine Learning Models for Generating Sparse Embeddings
- Comparing SPLADE Sparse Vectors with BM25
- Exploring ColBERT: A Token-Level Embedding and Ranking Model for Efficient Similarity Search
- Vectorizing and Querying EPUB Content with the Unstructured and Milvus
- What Are Binary Embeddings?
- A Beginner's Guide to Website Chunking and Embedding for Your RAG Applications
- An Introduction to Vector Embeddings: What They Are and How to Use Them
- Image Embeddings for Enhanced Image Search: An In-depth Explainer
- A Beginner’s Guide to Using OpenAI Text Embedding Models
- DistilBERT: A Distilled Version of BERT
- Unlocking the Power of Vector Quantization: Techniques for Efficient Data Compression and Retrieval
#はじめに
ベクトル埋め込みは、複雑なデータをアルゴリズムに理解しやすい数値形式で表現することを容易にし、現代の機械学習やデータサイエンスにおいて不可欠なものとなっている。密な埋め込み](https://zilliz.com/learn/sparse-and-dense-embeddings)は、最小限の情報損失で意味的な意味を保持する能力で普及していますが、その計算要求とメモリ要件は、データ量が急増するにつれてエスカレートしています。このエスカレートは、開発者に、より効率的なデータ表現方法を求めるよう促す。
様々な手法がある中で、バイナリ埋め込みは、コンパクトさ、計算効率、意味のあるデータ表現のバランスを取る、説得力のあるソリューションとして登場しました。このブログでは、バイナリ埋込みの概念を紹介し、その定義的な特徴、利点、他の埋込みタイプとの比較のメリットを説明します。さらに、バイナリ埋め込みを生成する方法を掘り下げ、Milvus ベクトルデータベースを使ったバイナリ埋め込み検索の実装を説明します。
ベクトル埋め込みとは?
バイナリ埋め込みを取り上げる前に、ベクトル埋め込みについての基礎的な理解を深めることが重要です。
ベクトル埋め込みとは、離散的なデータ項目を数値で表現したもので、単語、文章、画像、その他の要素などのエンティティを含みます。各項目は、高次元空間内の実数からなるベクトルにマッピングされる。類似の項目はこの空間内で互いに接近し、非類似の項目は乖離する。
ベクトル埋め込みはどのように生成され、保存されるか](https://assets.zilliz.com/How_vector_embeddings_are_generated_and_stored_7e9c5a2a41.png)
ベクトル埋め込みはどのように生成され、保存されるか?
ベクトル埋め込みは、項目間の意味的な関係をカプセル化する能力に顕著に現れます。例えば、自然言語処理 (NLP)では、似たような意味や文脈上の関連性を持つ単語は、ベクトル空間内で密接に配置されたベクトルによって描写されるため、ニュアンスのある分析や解釈が容易になります。
ベクトル埋め込みは通常、MilvusやZilliz Cloud(フルマネージドMilvus)のような特殊なベクトルデータベースに格納される。
バイナリ埋め込みとは?
バイナリ埋め込みはベクトル表現の一種で、各次元が2進数1桁でエンコードされます。例えば、"cat "の2進数埋め込みは、[0, 1, 0, 1, 1, 0, 0, 1, ...]のように表現できます。
バイナリ埋め込みは、記憶効率と計算速度を提供します。次元あたり1ビットしか使用しないため、他のタイプの埋め込みよりも少ないメモリしか必要とせず、メモリリソースが限られているアプリケーションや大規模なデータセットに適しています。さらに、2進数を含む演算は、実数を含む演算よりも高速に実行されることが多い。
その効率性にもかかわらず、2値埋め込みは、ほとんどの次元またはすべての次元で実数値のエントリを含む密な埋め込みと比較して、精度を犠牲にする可能性があります。これは、バイナリ埋め込みが、簡略化されたバイナリ形式でデータを表現するため、元データのニュアンスや複雑さをすべて捉えることができない可能性があるためです。
密対疎対バイナリベクトル埋め込み
ベクトル埋め込みは、その次元数によって異なる特徴を示します。ここでは、密な埋め込み、疎な埋め込み、バイナリ埋め込みの違いについて説明します:
密な埋め込み**は、ほとんどの次元またはすべての次元において、実数値でゼロでないエントリを持つベクトルで構成され、高い精度を提供しますが、バイナリ埋め込みやスパース埋め込みよりも多くのストレージと計算を必要とします。例えば、密な画像埋め込みは、[0.2, -0.7, 1.1, 0.4, -0.3, 0.9, -0.1, ...]のように見えるかもしれません。
疎な埋め込み**は、多数のゼロ値を持つベクトルから構成され、メモリ効率は良いですが、特定の演算には計算コストがかかる可能性があります。例えば、疎な文の埋め込みは[0, 0, 2.5, 0, 0, -1.2, 0, 0, 0, 3.7, ...]のようになり、ほとんどの次元が0になります。
バイナリ埋め込み**では、各ベクトル次元は1ビット(0または1)で表現され、ストレージ効率と計算上の利点を提供します。しかし,密な埋め込みに比べ,精度が落ちる可能性があります.
これらの例では、バイナリ(0または1)、スパース(ほとんどが0)、デンス(実数値)エンベッディングの違いが明らかです。適切な埋め込みタイプの選択は、特定のアプリケーションに必要な精度、ストレージ、計算量のトレードオフにかかっています。
バイナリ埋め込みを生成する方法
バイナリ埋め込みを生成するには、いくつかの主要なアプローチがあります:ハッシュベースの方法、機械学習モデル、バイナリ量子化。
ハッシュベースの手法
ハッシュベースの手法は、局所性を考慮したハッシュ(LSH)やランダム投影を利用して、高次元の入力データを直接バイナリコードにマッピングする。LSHは、入力空間をハッシュバケットに分割し、各バケットにバイナリコードを割り当てることでバイナリコードを生成する。ランダム投影は、ランダム投影行列を用いて入力データを低次元空間にマッピングし、その後量子化してバイナリコードを得る。
機械学習モデル
ディープ・ビリーフ・ネットワーク(DBN)や制限付きボルツマン・マシン(RBM)などのディープ・ラーニング・アーキテクチャは、出力の一部としてバイナリ埋め込みを生成する。特にRBMは、確率的バイナリ活性化を適用することで、隠れ層でバイナリ表現を学習することができる。バイナリニューラルネットワークは、バイナリ埋め込みを生成するためのもう一つの選択肢です。
バイナリ量子化
量子化ベースの技術は、連続値の埋め込みを2値表現に変換します。k-meansクラスタリングのようなベクトル量子化手法は、各セントロイドがバイナリコードを表すコードブックを学習することができる。入力データは、最も近いセントロイドに割り当てられることで量子化され、バイナリ表現が得られる。バイナリ量子化は、組み込みシステムや大規模な機械学習モデルなど、メモリや計算リソースが限られている場合に特に有効です。
バイナリ量子化とは?
バイナリ量子化とは、下図に示すように、各ベクトルの次元を0か1のどちらかに閾値化することで、密または疎な埋め込みをバイナリ表現に変換する手法です。
バイナリ量子化の仕組み](https://assets.zilliz.com/How_binary_quantization_works_2efa7df40f.jpg)
バイナリ量子化の仕組み
すべての正の数は1としてマークされ、そうでない場合は0になります。
このプロセスは、単純な符号の閾値処理、スカラー量子化、あるいはベクトル量子化のようなより複雑な技術など、さまざまな量子化手法によって達成することができます。単純な符号閾値を使った2値量子化の方法を見てみよう。
バイナリ量子化を行う
必要なライブラリをインストールすることから始める:
pip install sentence_transformers scikit-learn
sentence-transformersパッケージは、文の埋め込みを生成するために事前に学習されたモデルを提供する。scikit-learn にはバイナリ量子化に使用する Binarizer クラスが含まれている。
上記のライブラリをコードにインポートして、サポートされているクラスとモジュールを使用する。
from sentence_transformers import SentenceTransformer
from sklearn.preprocessing import Binarizer
高品質な文の埋め込みを生成するために、事前にトレーニングされたモデルのいずれかを読み込みます。all-MiniLM-L6-v2`モデルは軽量で、テキストデータの大規模なコーパスで事前にトレーニングされています。これは密なベクトル埋め込みを生成するために使用するモデルです。
from sentence_transformers import SentenceTransformer
from sklearn.preprocessing import Binarizer
次に、読み込んだモデルの encode メソッドを使用して、入力文書に対して密な埋め込みを生成する。encode`メソッドは文字列のリスト(この場合は1つのドキュメント)を受け取り、Numpy配列のリストを返します。
# 埋め込むドキュメント
document = ("なぜZilliz Cloudなのか?Zilliz CloudはMilvusのフルマネージドサービスを"
"Milvusのクリエイターによって作られました。それは、Milvusのクリエーターによって作られた、Milvusのデプロイとスケーリングを簡素化" "するものです。
"複雑なインフラを構築し維持する必要性を排除することで、ベクトル検索アプリケーションの"
"複雑なインフラを構築・維持する必要がなくなる")
# 密な埋め込みを生成する
dense_embeddings = model.encode([document])
ドキュメントの密な埋め込みが生成されたので、次のステップはバイナリ量子化を行い、結果を表示することです。
# scikit-learn Binarizerを使った2値量子化
binarizer = Binarizer(threshold=0.0)
binary_embeddings = binarizer.transform(dense_embeddings)
print("密な埋め込み(最初の10次元):")
print(dense_embeddings[0][:10])
print("バイナリ埋め込み(最初の10次元):")
print(binary_embeddings[0,:10])
上記のコードでは、密な埋め込みデータに対して2値量子化を行い、2値埋め込みデータを得ています。まず、sci-kit-learn の Binarizer クラスのインスタンスを作成し、閾値を 0.0 に設定します。密な埋め込みにおける正の値はすべて1に変換され、負の値はすべて0に変換されます。
そして、Binarizer インスタンスの transform メソッドを用いて、密な埋め込みデータに対して2値量子化を行います。上記のコードを実行した結果のスクリーンショットを示します:
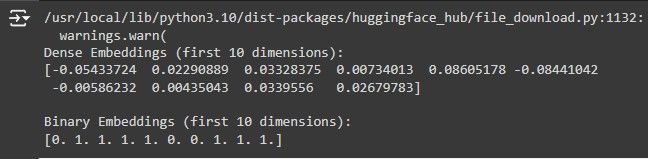
このスクリーンショットでは、バイナリ量子化によって、密な埋め込みとそれに対応するバイナリ埋め込みが得られています。それでは、2値埋め込み探索の方法を見てみましょう。
Milvusはどのようにバイナリ埋め込み探索を行うのか?
Milvusは、ベクトル埋め込みを効率的に格納・検索するためのオープンソースのベクトルデータベースです。Milvusは、BIN_FLATとBIN_IVF_FLATという2つの主要なインデックスを通して、バイナリ埋め込み検索を効率的にサポートしています。それぞれのインデックスがどのようにバイナリ埋め込み検索を行うかを見てみよう。
Milvusのバイナリインデックス
1.BIN_FLAT:BIN_FLATインデックスは、再現率100%が必須である比較的小さなデータセットに適した単純なアプローチである。これはクエリーベクトルとデータセット内の全てのベクトルを比較することで網羅的な検索を行い、正確な検索結果を保証する。しかし、この網羅的なアプローチは大規模なデータセットでは計算コストが高く、時間がかかるため、大規模なアプリケーションでは実用的ではない。 2.**BIN_IVF_FLAT:**BIN_IVF_FLATインデックスは検索速度と再現率のバランスをとる。これは量子化ベースのアプローチを採用しており、ベクトルデータを複数のクラスタ単位(nlist)に分割する。検索中に、クエリベクトルと各クラスタのセントロイドを比較し、最も類似したクラスタ(nprobe`)を選択して、そのクラスタ内の個々のベクトルとさらに比較する。この手法は、高い再現率を維持しつつ、比較をデータセットのサブセットに限定することで、検索時間を大幅に短縮する。
Milvusでバイナリ埋め込み検索を実行する方法をより良く理解するために、実用的な例を実装してみましょう:
Milvusによるバイナリ埋め込み検索の実行
Milvusでバイナリ埋め込み検索を行うには、文書を密なベクトル埋め込み表現にエンコードする必要があります。その後、バイナリ量子化を行い、Milvusからクエリに関連する埋め込みを格納・検索することができます。
以下は、Milvusでバイナリ埋め込み検索を行うためのステップバイステップガイドです。
ステップ1: 環境の構築
コーディングを始める前に、あなたのコンピュータにMilvusがインストールされ、Milvusに接続するために必要なライブラリがインストールされている必要があります。Milvusをインストールして実行するには、この包括的なガイドに従ってください。次に、ターミナルで以下のコマンドを実行し、必要なライブラリをインストールします。
pip install pymilvus[model].
このコマンドは Pymilvus をインストールし、コンピュータ上で動作する Milvus インスタンスとの接続を可能にするライブラリである。また、milvus-modelもインストールされ、Milvusがサポートするすべてのエンベッディングモデルにアクセスできるようになる。ライブラリをインストールしたら、必要なモジュールとクラスをインポートしてください。
from pymilvus import MilvusClient, DataType
from pymilvus.model.hybrid import BGEM3EmbeddingFunction
np として numpy をインポートする。
MilvusClientを使用してMilvusインスタンスに接続し、DataTypeを使用してコレクションフィールドのデータ型を定義します。BGEM3EmbeddingFunction に関しては、ドキュメントを密なベクトル埋め込みで表現するために使用する。BGE-M3モデルは多言語対応であるため、本ガイドではBGE-M3モデルを選択しています。
ステップ2:密ベクトルをバイナリベクトルに変換する関数の定義
この関数は、バイナリ量子化を行うのに役立ちます。この関数は BGEM3EmbeddingFunction によって生成された埋め込みベクトルを密な形式(Numpy配列)からバイナリに変換します。
# 密なベクトルをバイナリに変換する関数
def dense_to_binary(dense_vector):
return np.packbits(np.where(dense_vector >= 0, 1, 0)).
この関数は密なベクトルを入力として受け取り、NumPy の packbits 関数を使用してバイナリベクトルに変換します。packbits` 関数はバイナリ値(1 と 0 で表現される)をバイトにパックし、Milvus に効率的に格納したり取得したりできるようにする。
ステップ3:事前学習された文埋め込みモデルのインスタンス化
次に、pymilvus.model.hybridモジュールから事前学習された多言語文埋め込みモデルをインスタンス化する:
bge_m3_encoder = BGEM3EmbeddingFunction(
model_name='BAAI/bge-m3', device='cpu', use_fp16=False
)
このモデルを使用して、文書やクエリに対して密な埋め込みを生成します。これらの埋め込みは dense_to_binary 関数を用いてバイナリ形式に変換される。
ステップ4: Milvusインスタンスへの接続
MilvusClientクラスを使ってMilvusインスタンスに接続します:
client = MilvusClient(
uri="http://localhost:19530"
)
uri`をMilvusインスタンスの適切な接続詳細で置き換える。
ステップ 5: コレクションスキーマの定義
次に、Milvusコレクションのスキーマを定義します。このスキーマには、ドキュメントとそれに対応するバイナリ埋め込みが格納されます:
スキーマ = MilvusClient.create_schema(
auto_id=True、
enable_dynamic_field=True、
)
# スキーマにフィールドを追加
schema.add_field(field_name="doc_id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="doc_text", datatype=DataType.VARCHAR, max_length=65535)
schema.add_field(field_name="doc_binary_embedding", datatype=DataType.BINARY_VECTOR, dim=1024)
上のスキーマのフィールドが表すものは以下の通りである:
- doc_id`:各文書の一意な識別子(主キー)。
- doc_text`:ドキュメントのテキストコンテンツ。
- doc_binary_embedding`: ドキュメントのバイナリ埋め込み:類似検索に使用する文書のバイナリ埋め込み。
ステップ6:コレクションの作成または削除
スキーマができたので、次のステップはそれを使ってコレクションを作成することです。しかしその前に、同じようなコレクションが存在するかどうかをチェックし、存在する場合はそれを削除します。
コレクション名 = "binary_embedding_collection"
# 既存のコレクションがあれば、それを削除する
if client.has_collection(collection_name):
client.drop_collection(collection_name)
# コレクションを作成する
コレクションを作成する # client.create_collection(
collection_name=collection_name、
schema=schema、
description="バイナリ埋め込みコレクション"
)
特定のスキーマでコレクションを作成したので、後でこのスキーマにマッチするデータをコレクションに渡す必要があります。さもないと、ミスマッチエラーが発生します。
ステップ 7: 検索インデックスの作成
効率的な類似検索を行うために、doc_binary_embeddingフィールドにインデックスを作成する:
# インデックスのパラメータを作成する
index_params = [{ }] # インデックスのパラメータを作成する。
"field_name":"doc_binary_embedding"、
"index_type":"bin_ivf_flat"、
"metric_type":"JACCARD"、
「params":{"nlist":128}
}]
client.create_index(collection_name, index_params)
print("new index created successfully.")
上記のコードでは、先に説明した BIN_IVF_FLAT インデックスと JACCARD メトリックを使用している。これらはMilvusのバイナリ埋め込みに適している。Jaccard Metric` はバイナリベクトル間の類似度を測定します。これは両ベクトルで1であるビット数の総ビット数に対する比率を計算する。
ステップ 8: ドキュメントの挿入
コレクションを作成し、インデックス作成メソッドを定義したので、コレクションにドキュメントを 挿入できます:
# 挿入するドキュメント
ドキュメント = [
「Zillizはデータサイエンスとアナリティクスに特化した高性能データサイエンス企業である。高度な最適化と迅速な展開を提供し、科学的・技術的問題の解決を可能にする。"、
「Milvusは、ベクトルデータベースの市場で台頭しつつあるオープンソースソフトウェアプロジェクトです。データサイエンスと機械学習の分野において、非常に効果的でシンプルなソリューションであり、様々なユースケースのデータを効率的に処理することが可能です。Milvusは、ベクトルの類似性と近似クエリのためのデータを高速かつシンプルに処理するために特別に開発されました。"
]
# ドキュメントをコレクションに挿入する
for doc_text in documents:
doc_embedding = bge_m3_encoder.encode_documents([doc_text])['dense'][0].
binary_embedding = dense_to_binary(doc_embedding)
エンティティ = {
"doc_text": doc_text、
「doc_binary_embedding": binary_embedding.tobytes()
}
insert_result = client.insert(collection_name, [entity])
print(f "Inserted document: {doc_text[:20]}...")
documents` リストの各文書について、コードを記述する:
1.事前に学習した bge_m3_encoder モデルを用いて、密な埋め込みを生成する。
2.密な埋め込みを dense_to_binary 関数を用いてバイナリ埋め込みに変換する。
3.文書テキストとバイナリ埋め込みを含む実体辞書を作成する。
4.client.insert`メソッドを用いて、エンティティをMilvusコレクションに挿入する。
ステップ9: コレクションに対する類似検索の実行
文書とそれに対応するバイナリ埋め込みをMilvusに挿入することに成功したので、クエリに関連する文書を検索するために類似検索を実行する必要があります。
まず、作成したコレクションをメモリにロードします。
client.load_collection(collection_name)
次に、類似検索の検索パラメータを定義する。
search_params = {
"metric_type":"JACCARD"、
"params":params": { "nprobe":10}
}
nprobe` パラメータを 10 に設定すると、クエリ中に検索アルゴリズムがクエリベクトルに最も近い近傍クラスタを含む可能性の高い上位 10 クラスタを調べることになる。これにより、計算負荷が軽減され、検索処理が高速化されます。
最後に、サンプルクエリに対する類似検索の実行に進みます:
query_text = "Milvusとは?"
query_embedding = bge_m3_encoder.encode_queries([query_text])['dense'][0].
binary_query_embedding = dense_to_binary(query_embedding)
# 類似検索の実行
search_result = client.search(
collection_name=collection_name、
data=[binary_query_embedding.tobytes()]、
limit=10、
output_fields=["doc_text", "doc_binary_embedding"]、
search_params=search_params
)
上記のコードは以下のようになる:
1.クエリーテキストを受け取る:「ミルバスとは?
2.bge_m3_encoderモデルを用いて、クエリの密な埋め込みを生成する。 3.次に、dense_to_binary関数を用いて、密な埋め込みをバイナリ埋め込みに変換する。 4.最後に、client.search` メソッドを用いて、バイナリクエリの埋め込み、コレクション名、検索パラメータを渡して類似検索を行う。
ステップ 10:結果の印刷
Milvusによるバイナリ埋め込み検索の最終ステップです。類似検索の結果としてMilvusが返す結果を印刷します:
# 最初のヒットを表示する
if search_result and len(search_result[0]) > 0:
first_hit = search_result[0][0].
エンティティ = first_hit['entity']
print(f "Answer: {entity['doc_text']}")
# バイナリ埋め込みを表示する
query_binary_str = ''.join(format(byte, '08b') for byte in binary_query_embedding.tobytes())
print(f "Query Binary Embedding: {query_binary_str}")
first_hit_binary_str = ''.join(format(byte, '08b') for byte in np.frombuffer(entity['doc_binary_embedding'], dtype=np.uint8))
print(f "First Hit Binary Embedding: {first_hit_binary_str}")
else:
print("結果が見つかりません。")
上記のコードブロックは、検索結果が空でなく、少なくとも1つのヒット(類似文書)を含むかどうかをチェックします。検索結果が空でなく、少なくとも1つのヒットがある場合、クエリに最も類似したドキュメントである最初のヒットを抽出します。
これは、バイナリ埋め込みがクエリのバイナリ埋め込みに最も近い文書だからである。文書のテキストを表示した後、リスト内包と format 関数を用いて、クエリのバイナリ埋め込みと最初にヒットした文書のバイナリ埋め込みのバイナリ文字列表現を生成する。
以下は、クエリに対して類似性チェックを行った結果のスクリーンショットである:**Milvusとは何ですか?
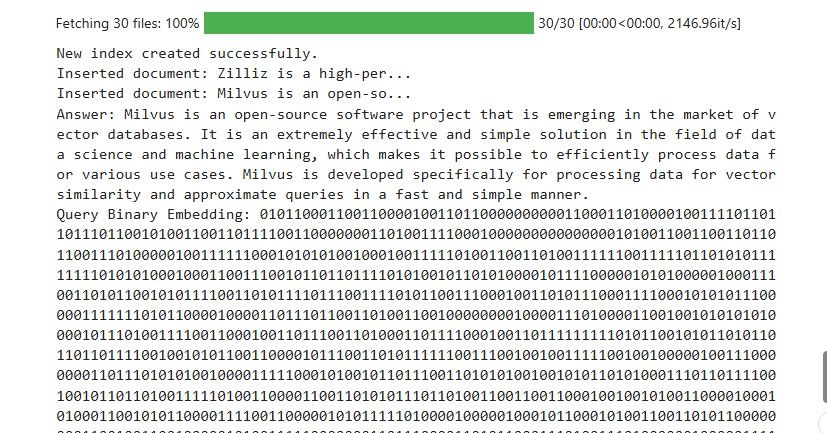 results.jpg
results.jpg
上のスクリーンショットは、Milvusから取得されたドキュメントが我々のクエリに対して正しいことを示している。
今後のMilvusのリリースでは、バイナリ量子化機能が追加される予定です。この機能追加により、Milvusのエコシステムの中でバイナリ埋込みの利点を直接活用することができるようになります。
結論
このガイドでは、バイナリ埋込みの概念について、密埋込みや疎埋込みと対比させ、ストレージ効率や計算速度の点でバイナリ埋込みが優れていることを説明しました。バイナリ埋め込みを生成するさまざまなアプローチと、バイナリ埋め込みをMilvusを使った効率的な類似検索に活用する方法について学びました。
バイナリ埋込みの特徴や実装方法を理解することで、バイナリ埋込みのパワーを効果的に活用し、実世界の機械学習やデータサイエンスの課題に取り組むことができます。
その他のリソース
詳細なコメント付きフルコード](https://www.kaggle.com/code/deniskuria/notebook19aedb6539)
疎な埋め込みと密な埋め込み - Zillizブログ](https://zilliz.com/learn/sparse-and-dense-embeddings)
Vector Index Milvus v2.1.xドキュメント](https://milvus.io/docs/v2.1.x/index.md#binary)
バイナリ埋め込みとスカラー埋め込みによる大幅な高速化と安価な検索](https://huggingface.co/blog/embedding-quantization)
 Denis Kuria
Denis KuriaDenis is a machine learning engineer who enjoys writing guides to help other developers. He has a bachelor's in computer science and loves hiking and exploring the world.
読み続けて

SPLADEスパース・ベクターとBM25の比較
一般的に、ベクトルには密なベクトルと疎なベクトルの2種類がある。密なベクトル」と「疎なベクトル」です。これらは同じようなタスクに利用できますが、それぞれに利点と欠点があります。この投稿では、スパース埋め込みの2つの一般的なバリエーションについて掘り下げます:BM25 と SPLADE です。
RAGアプリケーションのためのウェブサイト・チャンキングと埋め込み入門ガイド
この記事では、ウェブサイトからコンテンツを抽出し、それをRAGアプリケーションのLLMのコンテキストとして使用する方法について説明する。しかし、その前にウェブサイトの基礎を理解する必要がある。

OpenAIのテキスト埋め込みモデルを使うための初心者ガイド
OpenAIのテキスト埋め込みモデルを使った埋め込み作成とセマンティック検索の総合ガイド。