




MLOps (機械学習オペレーション)
MLOps (機械学習オペレーション)
機械学習](https://zilliz.com/learn/AI-and-ML-with-Vector-Databases)(ML)モデルが日常的なビジネスプロセスに統合されるようになるにつれ、組織は、現実の環境においてモデルの精度と関連性を維持する上で、いくつかの課題に直面している。大きな問題の1つはデータドリフトです。モデルが依存するデータが時間とともに変化し、精度が低下することです。このため、予測が有効であり続けるように、モデルの継続的モニタリング、再トレーニング、再展開が必要となる。
このようなモデルの管理は、適切なシステムなしでは、エラーが発生しやすく、時間がかかり、高価になる可能性がある。MLOps(Machine Learning Operations)は、プロセス全体を自動化し合理化することで、この問題を解決します。
MLOpsが、データ準備からモデルデプロイメントとモニタリングまで、エンドツーエンドの機械学習ライフサイクルをどのように簡素化・自動化するかを理解しよう。
MLOpsとは?
Machine Learning Operations (MLOps)は、機械学習、DevOps、データエンジニアリングを組み合わせて、機械学習のライフサイクルを合理化する。MLOpsは、データ収集、モデル開発からモデルデプロイメント、モニタリング、再トレーニングに至るまで、本番環境においてMLモデルを大規模に確実にデプロイし、維持することを目的としている。
DevOpsがソフトウェア開発に自動化と統合のプラクティスをもたらしたように、MLOpsは機械学習にも同じことを行う。継続的インテグレーション(CI)と継続的デプロイメント(CD)の原則を適用することで、チームは本番環境での堅牢なモニタリングとパフォーマンスを確保しながら、より迅速にモデルを反復することができます。
MLOpsの仕組み
MLOpsプロセスには、機械学習のライフサイクル全体を効率化するために連携する複数のステージが含まれます。以下がその例です:
1.モデル開発
2.モデル提供
3.モデル・モニタリング
4.モデルのメンテナンス
5.データ管理
6.自動化
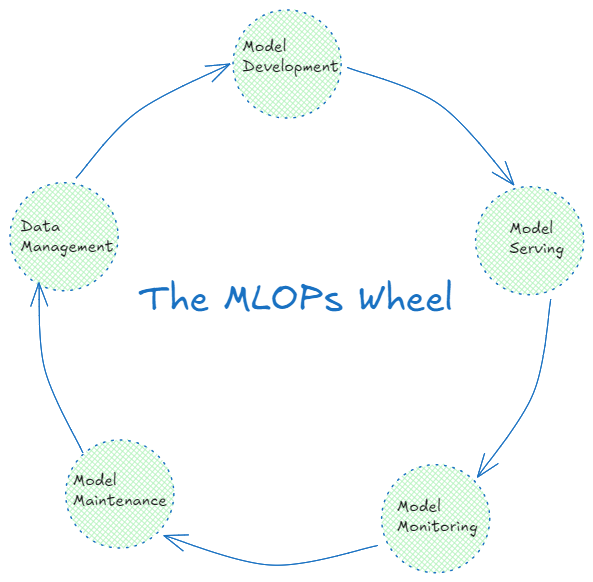 図- MLOpsワークフローにおける複数のステージ.png
図- MLOpsワークフローにおける複数のステージ.png
図MLOpsワークフローにおける複数のステージ
モデル開発
MLOpsの最初のステップは、あらゆる機械学習プロジェクトの基礎となるモデル開発であり、これにはいくつかの重要なサブステップが含まれる:
データの準備:** データは、モデルを学習する前にクリーニングされ、整理されなければならない。これは、無関係な情報の削除、欠損値の補填、データの正規化、MLモデルに適した形式への変換を含む。
フィーチャーエンジニアリング:** フィーチャーエンジニアリングは、新しい有益なフィーチャーを作成したり、既存のフィーチャーを変換したりして、モデルにとってより有用なものにする。例えば、データサイエンティストは、予測精度を向上させるために、気象予測モデルにおいて「風速の2乗」や「温度勾配」のような新しい特徴を作成するかもしれない。
モデルのトレーニング:***データを準備した後、MLモデルはトレーニングされる。データサイエンティストは、アルゴリズムやハイパーパラメータを用いて複数のモデルを訓練し、最も性能の良いモデルを見つける。
モデルのテスト:*** モデルがトレーニングされると、新しい未見のデータでも正確な予測ができることを確認するために、別のデータセットでテストされます。訓練されたMLモデルの性能を評価するために、様々な評価指標も使用されます。
モデルサービング
モデルが開発されたら、リアルタイムで予測を行えるように、本番環境にデプロイする必要がある:
デプロイメント:** これは、ユーザーやアプリケーションがモデルを利用できるようにすることを含む。モデルは多くの場合、他のシステムとやり取りするためにAPIを介してデプロイされる。Kubernetes](https://zilliz.com/learn/efficiently-deploying-milvus-on-gcp-kubernetes)やDockerのようなデプロイ・ソリューションは、モデルがスケーラブルでメンテナンスが容易であることを保証することによって、このプロセスを管理するのに役立ちます。
コンテナ化: モデルは(Dockerのような)コンテナで分離され、一貫性を確保します。コンテナには、必要なコンポーネント-コード、依存関係、設定-がすべて含まれているため、モデルは異なる環境でも一貫して動作します。
モデルのモニタリング
デプロイメント後、モデルのパフォーマンスを継続的に監視し、正確さと妥当性を維持する必要があります:
モニタリングシステムはモデルのパフォーマンスをモニターします。例えば、モデルが不正確な予測をし始めた場合、これはモデルが扱うデータが時間の経過とともに変化した(データ・ドリフト)ことを示している可能性があります。
ロギング:*** すべてのモデル活動は、入力、出力、およびエラーの記録を維持するためにログに記録されます。これは問題のトラブルシューティングや、モデルの使用方法のパターンを特定するのに役立ちます。
モデルのメンテナンス
機械学習モデルは、良好なパフォーマンスを維持するために定期的にメンテナンスする必要がある:
更新と再トレーニング:** MLOpsは、新しいデータが利用可能になったときやパフォーマンスが低下したときに、モデルの更新と再トレーニングを容易にします。定期的な再トレーニングにより、モデルは常に最新かつ正確な状態に保たれ、変化するデータ・パターンに適応します。MLOpsはこのプロセスを自動化するため、効率的でミスが少なくなります。
バージョン管理:モデルの異なるバージョンを追跡するために、MLOpsはGitHub、MLflow、DVCなどのバージョン管理システムを使用しています。これらのシステムは、モデルの各バージョンを、モデルの作成に使用されたデータとコードとともに記録します。
データ管理
データはあらゆる機械学習システムのバックボーンであり、それを効果的に管理することはMLOpsの重要な部分である:
データの取り込みと保存:** MLOpsは様々なソースからMLパイプラインへのデータフローを管理し、データをZilliz CloudやMilvusのようなスケーラブルなクラウドストレージに保存する。
データガバナンス](https://zilliz.com/learn/safeguarding-data-security-and-privacy-in-vector-database-systems):** MLOpsはデータの品質、セキュリティ、および規制のコンプライアンスを保証します。また、許可された個人のみがデータにアクセスできるようにし、個人情報保護法が遵守されるようにします。
オートメーション
MLOpsの主な目標の1つは、反復タスクを自動化し、機械学習モデルの長期的な管理を容易にすることである:
ワークフロー・オーケストレーション:**自動化ツールは、データ処理からモデルのトレーニングやデプロイまで、MLパイプラインの多くのステップを処理できる。これにより、手作業による干渉の必要性を減らし、モデルの構築とデプロイ時の一貫性を維持するのに役立ちます。
継続的インテグレーション/継続的デプロイメント(CI/CD):** CI/CDパイプラインは、合理化され自動化されたアプローチで、チームが継続的にモデルを構築、テスト、デプロイするのに役立ちます。CI/CDにより、モデルを迅速に更新、テストし、最小限の遅延で本番稼動させることができます。
比較MLOps vs. DevOps vs. LLMOps
MLOps、DevOps、LLMOpsは、一見似たような用語に見える。それぞれのプラクティスは開発ワークフローの改善に焦点を当てているが、ソフトウェア開発とAIの分野では異なる課題に取り組み、独自のソリューションを提供している。
| :--------:| :--------------------------------------------------------------------------------------------------------------------------------------------------------------------:| :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------:| :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | Aspect|DevOps|MLOps|LLMOps**||定義 | 定義|ソフトウェア開発とIT運用を自動化するための一連のプラクティス。 | MLモデルのライフサイクルを自動化するためにDevOpsの原則を拡張する。 | 大規模言語モデル](https://zilliz.com/glossary/large-language-models-(llms)) (LLMs)のライフサイクル管理に焦点を合わせる。 | | フォーカス|ソフトウェアデリバリパイプライン(CI/CD)を自動化し、コラボレーションを改善し、開発ライフサイクルを短縮する。 | データ準備からモデルのデプロイ、モニタリングに至るMLワークフローの自動化。 | 本番環境におけるLLMのデプロイ、微調整、管理の最適化。 | | 主なツール| - CI/CDのためのGitLab。 - モニタリングのためのGrafana。 - コンテナ・オーケストレーションのためのDockerとKubernetes。| ワークフローの自動化にはKubeflowとApache Airflowを使用。モデル学習にはScikit-learnとTensorFlowを使用。| - Hugging Face 微調整用のトランスフォーマー。 - 大規模推論ツール(Ray Serve、ONNX)。| | ユースケース|- ソフトウェアアップデートの迅速な展開。 | MLモデルの再トレーニングと再デプロイメントの自動化。 | NLP](https://zilliz.com/learn/A-Beginner-Guide-to-Natural-Language-Processing) タスクのための大規模な言語モデルのデプロイ。 |
MLOps メトリクス
MLOpsでは、メトリクスがモデルのパフォーマンスとMLパイプライン全体を測定するための鍵となります。MLOpsにおけるKPIは、従来のMLモデルのメトリクスにとどまらず、ライフサイクル全体に及びます。モデルの精度、精度、リコール、F1スコアは依然として基本的なものですが、MLOpsでは新しいものが導入されます。デプロイメントの頻度は、新しいモデルやアップデートが本番環境にデプロイされる頻度や、MLパイプラインの俊敏性を測定する。MTTR(Mean Time to Recovery:平均復旧時間)は、実稼働モデルの問題がどれだけ速く特定され、解決されるかを測定します。リソース利用メトリクスは、クラウドにおけるコスト管理に重要な計算効率を測定します。データ・ドリフトとモデル・ドリフトのメトリクスは、入力データが変更された場合に、時間の経過とともにモデルがどの程度うまく機能するかを測定します。推論のレイテンシーとスループットは、リアルタイム・アプリケーションにとって重要であり、応答時間と処理能力を測定します。A/Bテスト・メトリクスは、新しいモデルのパフォーマンスを、実稼働中の既存のモデルのパフォーマンスと比較します。パイプラインの自動化レベルは、必要な人的介入のレベルを測定する。最後に、モデルのバージョニングと再現性のメトリクスは、実験とデプロイメントを追跡し、再現できるようにします。これらのメトリクスによってMLOpsの全体像を把握し、MLのプロセスと成果を継続的に改善することができます。
MLOps の利点と課題
MLOpsは、機械学習オペレーションの効率性と有効性を高める数多くの利点を提供する一方で、組織がナビゲートしなければならないいくつかの課題も提示します。メリットと課題を理解することは、MLOpsの実践を成功させ、最適な成果を達成するために極めて重要である。
MLOps のメリット
パイプラインの自動化:**手作業による介入を減らし、データサイエンティストやエンジニアがコアタスクに集中できるようにする。
合理化されたワークフローと自動化により、モデルのイテレーションとリリース・サイクルが短縮されます。
パフォーマンスの向上:** 継続的なモニタリングと再トレーニングのサイクルにより、動的な実世界のシナリオで優れたパフォーマンスを発揮する堅牢なモデルを構築します。
スケーラビリティ:** MLOpsフレームワークにより、異なる環境にまたがる何千ものモデルのデプロイと管理が可能になります。
継続的な改善:**モデルは継続的にモニタリングされ、再トレーニングされます。この手法により、新しいデータや状況の変化に適応し、高いパフォーマンスを維持することができます。
MLOpsの課題
複雑さ:*** MLOps を導入するには、複雑なインフラとワークフローを設定する必要があり、リソースを大量に消費する。
ツールの統合:** データ管理、モデルのトレーニング、デプロイメント、モニタリングのための異なるツールの統合は困難である。
モデルのバージョニングと再現性:***機械学習モデルのすべての異なるバージョンと、それらに付随する依存関係や設定を追跡し、管理することは困難です。また、様々な環境で結果を再現し、検証することも問題になります。
コスト:*** MLOpsは長期的には効率性とスケーラビリティを向上させることができるが、MLOpsフレームワークをセットアップするための初期コストは高くつく可能性がある。組織は、MLOpsイニシアチブを確実に成功させるために、適切なツール、インフラ、人材に投資する必要がある。
コラボレーション:** MLOpsは共通のプロセスとツールを導入し、データエンジニア、サイエンティスト、開発者、ITエンジニア間の効果的なコラボレーションを促進する。
MLOps におけるツールとテクノロジー
MLOpsは、機械学習のライフサイクルを管理するために様々なツールとテクノロジーに依存している。以下に、最も一般的に使用されるMLOpsツールをいくつか紹介する:
MLflow:**実験のトラッキング、モデルのバージョニング、デプロイメントなど、機械学習のライフサイクル全体を管理するためのオープンソースのプラットフォーム。
DVC (Data Version Control):** データ管理、MLパイプライン自動化、実験管理のためのオープンソースのバージョン管理システム。
Kubeflow:**本番環境で機械学習モデルをデプロイ、スケーリング、管理するためのKubernetesベースのプラットフォーム。
Apache Airflow:** データパイプラインを管理し、データ取り込みとモデルトレーニングのタスクをスケジュールするワークフロー自動化ツール。
TensorFlow Extended (TFX):** TensorFlowを使用した本番機械学習パイプラインをデプロイするためのエンドツーエンドのプラットフォーム。TFXは、データ検証、モデル提供、継続的トレーニングのためのツールを提供します。
ベクトルデータベース](https://zilliz.com/learn/what-is-vector-database) (Milvus,** Zilliz Cloud): 多くのMLOpsシナリオでは、画像、テキスト、音声などの非構造化データを扱うことが重要です。そこで役立つのがベクトル・データベースだ。Milvusは、このようなデータのベクトル埋め込みや数値表現を保存し、クエリすることに特化している。Milvusはオープンソースのベクトルデータベースで、大規模なデータセットや複雑なクエリの処理に優れている。
MLOps トレンド
MLOpsの状況は急速に変化しており、いくつかのエキサイティングなトレンドが出現している。AutoML(自動機械学習)は、フィーチャーエンジニアリングとハイパーパラメータチューニングを自動化し、急成長している。エッジMLはより重要になりつつあり、モデルはエッジデバイス上で実行できるため、待ち時間が短縮され、プライバシーが向上する。データを非公開にしながら、分散化されたデバイス間でモデルをトレーニングするFederated Learningが台頭している。XAI(Explainable AI)ツールがMLOpsパイプラインに追加され、モデルの解釈可能性と透明性に対するニーズの高まりに対応している。微妙なモデルの劣化やデータのドリフトをリアルタイムで検出できるML専用のモニタリング・ツールに注目が集まっている。LLM(大規模言語モデル)は、より高度なNLPタスクを実行するためにMLOpsワークフローに追加されています。持続可能性への関心が高まるにつれ、リソースの使用を最適化し、MLのカーボンフットプリントを削減するグリーンMLOpsが台頭しています。これらのトレンドは、MLOpsがより自動化され、効率的で、解釈可能で、環境に優しいものになる未来を指し示しています。
##MLOpsに関するFAQ
1.**MLOpsは何に使われるのか?
機械学習オペレーション(MLOps)は、機械学習(ML)モデルのワークフローとデプロイメントプロセスを合理化・自動化するために設計されたプラクティスの集合体である。機械学習と人工知能(AI)を取り入れることで、企業は現実世界の複雑な課題に取り組み、価値ある顧客ソリューションを生み出すことができる。
2.**MLOpsとDevOpsの違いとは?
MLOpsは、機械学習モデルの迅速なテストとデプロイに焦点を当てたデータサイエンスのプラクティスである。しかし、DevOpsは、ソフトウェア開発の効率性、信頼性、およびセキュリティを強化するために、開発とIT運用を統合する。
3.**MLOpsとAIOPsの違いは何ですか?
AIOpsは、IT運用とデータサイエンスチームが予測アラート管理を実装し、データセキュリティを強化し、DevOpsワークフローをサポートすることを可能にする。MLOpsソリューションは、企業が機械学習モデルのデプロイをスピードアップし、データサイエンス・チームとオペレーション・チーム間のコラボレーションを改善し、AIへの取り組みを組織全体に拡大することを支援する。
4.**MLOpsは需要があるか?
企業がデータ主導のソリューションを採用するにつれ、機械学習モデルを効率的に展開・管理するMLOps専門家の需要が急速に高まっている。
5.**MLOpsに最適な言語は?
Pythonは現在、機械学習とMLOpsに最も適した言語です。Pythonの人気は、NumPy、TensorFlow、Keras、PyTorchなど、機械学習に利用可能なツールやライブラリが充実していることに起因している。これらのライブラリを使用することで、機械学習モデルの構築やデータエンジニアリングタスクの処理が容易になり、機械学習プロジェクトのMLOpsプロセス全体が簡素化される。
関連リソース
Zilliz Cloudを使い始める](https://zilliz.com/cloud)
Milvusドキュメント - Milvusの公式ドキュメント](https://milvus.io/docs/quickstart.md)
MLOps: Best Practices - MLOpsのベストプラクティスに関する詳細ガイド](https://zilliz.com/blog/get-started-with-llmops-build-better-ai-applications)
大規模言語モデルと検索](https://zilliz.com/learn/large-language-models-and-search)
LLMOpsを始めよう:より良いAIアプリケーションの構築](https://zilliz.com/blog/get-started-with-llmops-build-better-ai-applications)
LLM-Eval: A Streamlined Approach to Evalating LLM Conversations](https://zilliz.com/learn/streamlined-approach-to-evaluating-llm-conversations)