




Scaling Search with Milvus: Handling Massive Datasets with Ease
People often ask me: "Why bother using a vector database like Milvus when I can just use NumPy or FAISS?" There are many reasons: scalability, ease of management, data persistence, and one of the most important ones: scale. When you're dealing with millions or billions of vectors, you need a solution built to handle that kind of volume.
In this blog post, we will see how we can work with an example use case of 40 millions of vectors with Milvus. We’ll also demonstrate how features like metadata filtering can significantly enhance your search results—an essential capability often missing in non-purpose-built vector databases, which is a major drawback.
Milvus: a Vector Database Built for Scale
Milvus is a popular open-source vector database that powers AI applications with highly performant and scalable vector similarity search.
Some of the key features that make vector searching at scale possible include:
- A Distributed Architecture: Milvus has a distributed architecture which allows it to seamlessly scale horizontally and distribute data and workload across multiple nodes. This capability ensures high availability and resilience, even under heavy load.
- Optimized Indexing: Milvus supports different indexing techniques such as IVF_FLAT and HNSW, but also a GPU Index to accelerate search speeds. It also supports DiskANN if you need to reduce the cost of your Vector DB, the search would be a bit slower but it would be significantly cheaper.
- Search Through Billions: One of the standout features of Milvus is its ability to handle and search through billions of vectors efficiently. This capability is crucial for applications that require high-speed and high-volume vector similarity searches.
- Different Computing Options: Milvus can leverage the power of GPUs and CPUs, intelligently allocating tasks to the most suitable hardware for optimal performance. This capability allows for parallel processing and significant speed improvements, especially for computationally intensive operations.
The Dataset: Millions of Wikipedia Article Embeddings
We are using a dataset from Wikipedia that has been transformed with a Cohere Embedding Model, it is freely available on Hugging Face.
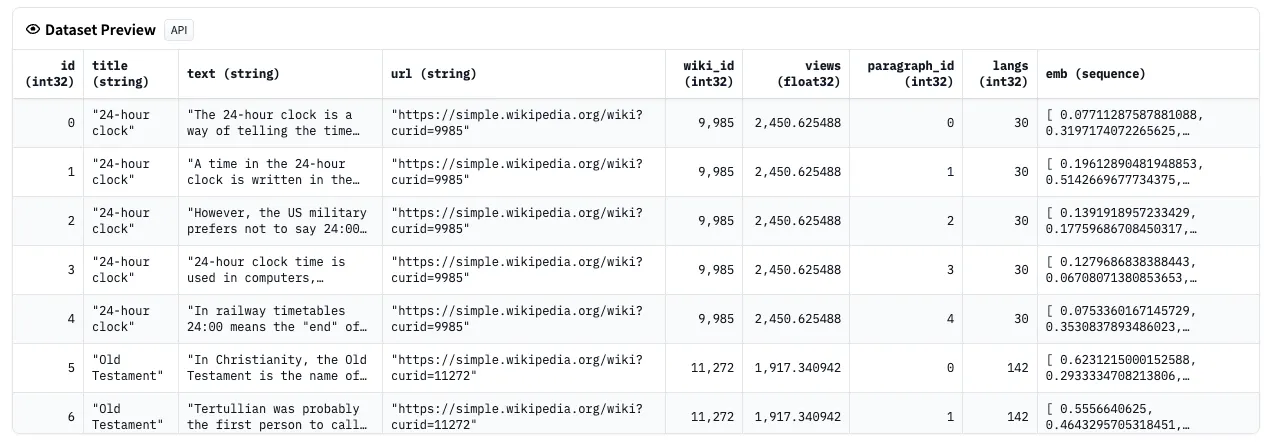 Preview of the dataset
Preview of the dataset
Figure 1: Preview of the dataset
Each example contains one full Wikipedia article with cleaning to strip markdown and unwanted sections (references, etc.).
The dataset contains more than 300 languages, but for our use case we will focus on English, which contains 41.5M vectors. The cool part is that the embeddings are cross-lingual! This means you can search across multiple languages and rely on the model's ability to find similar meanings, even in different languages.
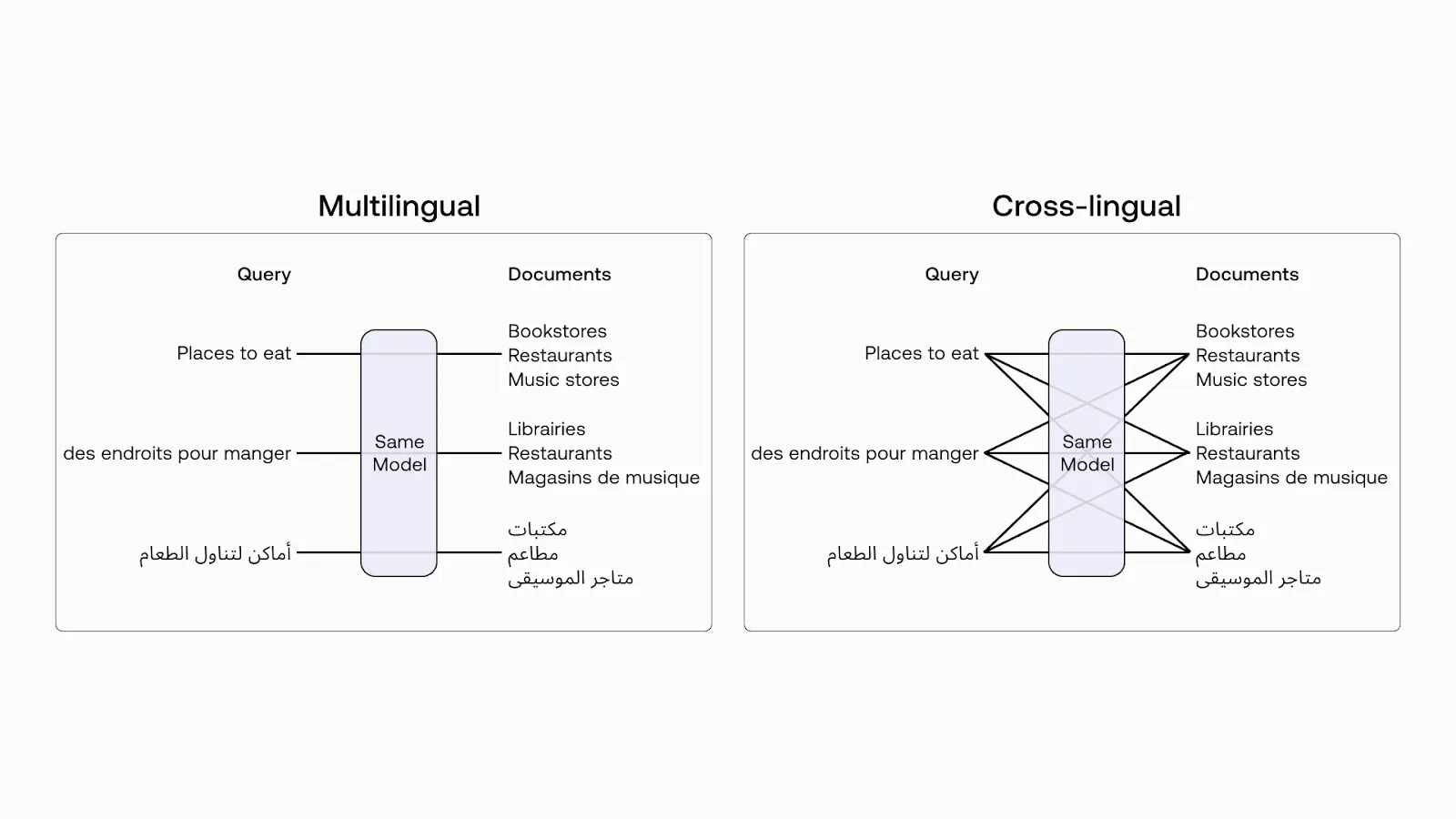 Multilingual vs Cross-lingual.png
Multilingual vs Cross-lingual.png
Figure 2: Multilingual vs Cross-lingual (Image source)
Getting Started with Milvus
In this section, we'll show you how to get started with Milvus, including installing Milvus SDK or setting up Zilliz Cloud, connecting to Milvus, creating collections etc.
Installing the Milvus SDK
Start by installing Milvus SDK by running pip install pymilvus. For the sake of simplicity, we will deploy Milvus on Zilliz Cloud (the fully managed version of Milvus). Given the scale of the data you use, you can either Deploy Milvus on Kubernetes or use Zilliz Cloud.
- If you have a larger scale of data, say more than one million vectors, you can set up a more performant Milvus server on Docker or Kubernetes. In this setup, please use the server uri, e.g.
http://localhost:19530, as your uri. - If you want to use Zilliz Cloud, the fully managed cloud service for Milvus, adjust the
uriandtoken, which correspond to the Public Endpoint and API key in Zilliz Cloud.
A Step-by-step Guide
- Connect to Milvus: First, establish a connection to your Milvus instance:
from pymilvus import MilvusClient
client = MilvusClient(uri=<ZILLIZ_CLOUD_URI>, token=<ZILLIZ_TOKEN>)
- Create a Schema: Define the Schema that will be used to create our Milvus Collection.
# Define the schema for the collection
embedding_dim = 1024
schema = [
{"name": "id", "dtype": "int64", "is_primary": True, "auto_id": True},
{"name": "text_vector", "dtype": "float_vector", "dim": embedding_dim},
{"name": "title", "dtype": "varchar", "max_length": 5000},
{"name": "text", "dtype": "varchar", "max_length": 5000},
]
- Create a Collection: Now, we create the Collection that we will use to store the Embeddings.
# Create the collection if it doesn't exist
collection_name = "cohere_embeddings"
if not client.has_collection(collection_name):
client.create_collection(collection_name=collection_name, schema=schema)
- Create an Index: To make Vector Search efficient, we need to create an index on the vector field we are interested in. A vector index is a specialized type of index that is designed to store and search vectors.
# Define and create index
index_params = {
"metric_type": "COSINE",
"index_type": "HNSW",
"params": {"M": 8, "efConstruction": 64},
}
client.create_index(collection_name=collection_name, field_name="text_vector", index_params=index_params)
# Load the collection
client.load_collection(collection_name=collection_name)
- Insert Data: Populate the collection
cohere_embeddingswith the Dataset from Hugging Face. Depending on the resources you have available, you might either want to download a subset of it, e.g. only a specific language, upload it to a Bucket like S3 or GCP, or you can also stream it from Hugging Face.
When a dataset is in streaming mode, you can iterate over it directly without having to download the entire dataset. The data is downloaded progressively as you iterate over the dataset, this is useful if you don’t have enough space on your disk to download the dataset, or if you don’t want to wait for your dataset to be downloaded before using it.
# Insert data into our collection
def insert_batch(client, collection_name, batch_data):
client.insert(collection_name=collection_name, data=batch_data)
batch_data.clear()
# Get the data from HuggingFace and create some batch
def insert_data(client, collection_name):
batch_size = 1000 # Adjust the batch size as needed
batch_data = []
docs = load_dataset(
"Cohere/wikipedia-2023-11-embed-multilingual-v3",
"en", # English only
split="train",
streaming=True, # Allows us to iterate over the dataset
)
for doc in tqdm(docs, desc="Streaming and preparing data for Milvus"):
title = doc["title"][:4500] # Titles can be very long
text = doc["text"][:4500] # Text can be very long
emb = doc["emb"] # The embedding vector
batch_data.append({"title": title, "text_vector": emb, "text": text})
if len(batch_data) >= batch_size:
insert_batch(client, collection_name, batch_data)
if batch_data:
insert_batch(client, collection_name, batch_data)
Scalar Filtering: A Powerful Tool at Scale
When you're dealing with millions or billions of vectors, filtering becomes more than just a nice-to-have—it's essential. And this is where Milvus really flexes its muscles.
Here's why Milvus's approach to filtering is a game-changer:
- Bitset Wizardry: Milvus uses compact bitsets to represent which vectors match your filter criteria. These bitsets can be manipulated faster than you can say "vector similarity search", thanks to low-level CPU operations. It's like having a supercomputer that can instantly sort through billions of data points.
- Search Space Reduction: Unlike some other solutions (e.g. pgvector) that only offers post-filtering, Milvus apply metadata filters before running the vector similarity search. It dramatically cuts down the number of vectors it needs to process. It also allows you to narrow down your search from billions of vectors to just the thousands that really matter—in milliseconds.
- Scalar Indexing (When You Need It): For those fields you filter on frequently, Milvus lets you create scalar indexes. Think of it as giving Milvus a cheat sheet for your data. While not always present by default, when properly set up, these indexes can turbocharge your filtering performance.
The beauty of Milvus is that it doesn't just offer these features — it makes them work at scale. Whether you're dealing with 40 million vectors or 40 billion.
Search with Exact Filtering
Find documents with a specific title.
FILTER_TITLE = "British Arab Commercial Bank"
res = milvus_client.query(
collection_name=collection_name,
filter=f'title like "{FILTER_TITLE}"',
output_fields=["title", "text"]
)
for elt in res:
pprint(elt)
This returns documents about the British Arab Commercial Bank
{'id': 450933285225527270,
'text': 'The British Arab Commercial Bank PLC (BACB) is an international '
'wholesale bank incorporated in the United Kingdom that is authorised '
'by the Prudential Regulation Authority (PRA) and regulated by the '
'PRA and the Financial Conduct Authority (FCA). It was founded in '
'1972 as UBAF Limited, adopted its current name in 1996, and '
'registered as a public limited company in 2009. The bank has clients '
'trading in and out of developing markets in the Middle East and '
'Africa.',
'title': 'British Arab Commercial Bank'}
{'id': 450933285225527271,
'text': 'BACB has a head office in London, and three representative offices '
'in Algiers in Algeria, Tripoli in Libya and Abidjan in the Cote '
"D'Ivoire. The bank has 17 sister banks across Europe, Asia and "
'Africa. It is owned by three main shareholders - the Libyan Foreign '
'Bank (87.80%), Banque Centrale Populaire (6.10%) and Banque '
"Extérieure d'Algérie (6.10%).",
'title': 'British Arab Commercial Bank'}
Search with Prefix/Infix/Postfix Filtering
Search for documents containing a specific word.
res = milvus_client.query(
collection_name=collection_name,
filter='text like "%Calectasia%"', # Infix
# filter='text like "Calect%"', # Suffix
# filter='text like "%lectasia"', # Prefix
output_fields=["title", "text"],
limit=5,
)
for elt in res:
pprint(elt)
This returns documents containing the word "Calectasia."
{'id': 450933285225527360,
'text': 'Calectasia is a genus of about fifteen species of flowering plants '
'in the family Dasypogonaceae and is endemic to south-western '
'Australia. Plants is this genus are small, erect shrubs with '
'branched stems covered by leaf sheaths. The flowers are star-shaped, '
'lilac-blue to purple and arranged singly on the ends of short '
'branchlets.',
'title': 'Calectasia'}
{'id': 450933285225527361,
'text': 'Plants in the genus Calectasia are small, often rhizome-forming '
'shrubs with erect, branched stems with sessile leaves arranged '
'alternately along the stems, long and about wide, the base held '
'closely against the stem and the tip pointed. The flowers are '
'arranged singly on the ends of branchlets and are bisexual, the '
'three sepals and three petals are similar to each other, and joined '
'at the base forming a short tube but spreading, forming a star-like '
'pattern with a metallic sheen. Six bright yellow or orange stamens '
'form a tube in the centre of the flower with a thin style extending '
'beyond the centre of the tube.',
'title': 'Calectasia'}
Search with Filtering with "Not In"
Exclude specific titles from your search.
res = milvus_client.query(
collection_name=collection_name,
filter='title not in ["British Arab Commercial Bank", "Calectasia"]',
output_fields=["title", "text"],
limit=10,
)
for elt in res:
pprint(elt)
This returns documents whose titles are not "British Arab Commercial Bank" or "Calectasia."
{'id': 450933285225527281,
'text': 'The Commonwealth Skyranger, first produced as the Rearwin Skyranger, '
'was the last design of Rearwin Aircraft before the company was '
'purchased by a new owner and renamed Commonwealth Aircraft. It was '
'a side-by-side, two-seat, high-wing taildragger.',
'title': 'Commonwealth Skyranger'}
{'id': 450933285225527282,
'text': 'The Rearwin company had specialized in aircraft powered by small '
'radial engines, such as their Sportster and Cloudster, and had even '
'purchased the assets of LeBlond Engines to make small radial engines '
'in-house in 1937. By 1940, however, it was clear Rearwin would need '
'a design powered by a small horizontally opposed engine to remain '
'competitive. Intended for sport pilots and flying businessmen, the '
'"Rearwin Model 165" first flew on April 9, 1940. Originally named '
'the "Ranger," Ranger Engines (who also sold several engines named '
'"Ranger") protested, and Rearwin renamed the design "Skyranger." The '
'overall design and construction methods allowed Rearwin to take '
'orders for Skyrangers then deliver the aircraft within 10 weeks.',
'title': 'Commonwealth Skyranger'}
Cohere 🤝 Milvus: A Powerful Combination Making Vector Similarity Search Easier and More Efficient
Let's perform a similarity search using Cohere embeddings. We'll embed the query Who founded Wikipedia and use it to search our Milvus collection. This is the same embedding model that was used to encode the Wikipedia Embeddings.
We will use the integration between Milvus and Cohere through PyMilvus Model, install it with pip install "pymilvus[model]" .
from pymilvus.model.dense import CohereEmbeddingFunction
cohere_ef = CohereEmbeddingFunction(
model_name="embed-multilingual-v3.0",
input_type="search_query",
embedding_types=["float"]
)
query = 'Who founded Wikipedia'
embedded_query = cohere_ef.encode_queries([query])
response = embedded_query[0]
print(response[:10])
This returns the most relevant Wikipedia articles about the founders of Wikipedia.
res = milvus_client.search(data=response, collection_name=collection_name, output_fields=["text"], limit=3)
for elt in res:
pprint(elt)
Which results in the following:
[{'distance': 0.7344469428062439,
'entity': {'text': 'Larry Sanger and Jimmy Wales are the ones who started '
'Wikipedia. Wales is credited with defining the goals of '
'the project. Sanger created the strategy of using a wiki '
"to reach Wales' goal. On January 10, 2001, Larry Sanger "
'proposed on the Nupedia mailing list to create a wiki as '
'a "feeder" project for Nupedia. Wikipedia was launched '
'on January 15, 2001. It was launched as an '
'English-language edition at www.wikipedia.com, and '
'announced by Sanger on the Nupedia mailing list. '
'Wikipedia\'s policy of "neutral point-of-view" was '
'enforced in its initial months and was similar to '
'Nupedia\'s earlier "nonbiased" policy. Otherwise, there '
"weren't very many rules initially, and Wikipedia "
'operated independently of Nupedia.'},
'id': 450933285241797095},
{'distance': 0.7239157557487488,
'entity': {'text': 'Wikipedia was originally conceived as a complement to '
'Nupedia, a free on-line encyclopedia founded by Jimmy '
'Wales, with articles written by highly qualified '
'contributors and evaluated by an elaborate peer review '
'process. The writing of content for Nupedia proved to be '
'extremely slow, with only 12 articles completed during '
'the first year, despite a mailing-list of interested '
'editors and the presence of a full-time editor-in-chief '
'recruited by Wales, Larry Sanger. Learning of the wiki '
'concept, Wales and Sanger decided to try creating a '
'collaborative website to provide an additional source of '
'rapidly produced draft articles that could be polished '
'for use on Nupedia.'},
'id': 450933285225827849},
{'distance': 0.7191773653030396,
'entity': {'text': "The foundation's creation was officially announced by "
'Wikipedia co-founder Jimmy Wales, who was running '
'Wikipedia within his company Bomis, on June 20, 2003.'},
'id': 450933285242058780}]
Let's check our cluster's performance metrics, focusing on the latency of our search queries. We'll use the Zilliz Cloud API to retrieve both the average and 99th percentile (P99) latency values.
First, we'll check the average latency:
> curl --request POST \
--url https://api.cloud.zilliz.com/v2/clusters/<cluster_id>/metrics/query \
[...]
"metricQueries": [
{
"name": "REQ_SEARCH_LATENCY",
"stat": "AVG"
}
}'
[{"name":"REQ_SEARCH_LATENCY","stat":"AVG","unit":"millisecond","values":[{"timestamp":"2024-08-26T11:09:53Z","value":"2.0541596873255163"}]}]
This query returns an average latency of 2.05 milliseconds.
Next, let's check the P99 latency:
> curl --request POST \
--url https://api.cloud.zilliz.com/v2/clusters/<cluster_id>/metrics/query \
[...]
"metricQueries": [
{
"name": "REQ_SEARCH_LATENCY",
"stat": "P99"
}
}'
[{"name":"REQ_SEARCH_LATENCY","stat":"P99","unit":"millisecond","values":[{"timestamp":"2024-08-26T11:09:53Z","value":"4.949999999999999"}]}]
The P99 latency is reported as 4.95 milliseconds.
These results show some impressive performance: our average query latency is just over 2 milliseconds, with 99% of queries completing in less than 5 milliseconds. This demonstrates the efficiency of our Milvus cluster in handling search operations, even at scale.
Create a Basic RAG System with Milvus
Retrieval Augmented Generation (RAG) is an advanced AI technique to mitigate hallucinations in large language models (LLMs) like ChatGPT.
In this example, we can use the results from Milvus to create a simple RAG system. This allows an LLM to access and utilize information stored in Milvus.
context = "\n".join(
[line_with_distance[0] for line_with_distance in retrieved_lines_with_distances]
)
question = "Who created Wikipedia?"
SYSTEM_PROMPT = """
Human: You are an AI assistant. You are able to find answers to the questions from the contextual passage snippets provided.
"""
USER_PROMPT = f"""
Use the following pieces of information enclosed in <context> tags to provide an answer to the question enclosed in <question> tags.
<context>
{context}
</context>
<question>
{question}
</question>
"""
from openai import OpenAI
client = OpenAI(
base_url = 'http://localhost:11434/v1',
api_key='ollama', # required, but unused
)
response = client.chat.completions.create(
model="llama3.1",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": USER_PROMPT},
],
)
print(response.choices[0].message.content)
According to the provided context, Larry Sanger and Jimmy Wales are the ones who started Wikipedia. Specifically, Jimmy Wales defined the goals of the project, while Larry Sanger created the strategy of using a wiki to achieve those goals.
Beyond the Basics: Advanced Features of Milvus for Enhanced Scalability
Milvus offers even more advanced features for handling massive datasets:
- Data Partitioning: For collections containing data from multiple users or tenants for example, Milvus offers partition keys and names to logically segregate data. This feature enables efficient metadata-filtering, such as by user ID or organization name.
- Range Search: Efficiently find vectors within a specified distance range from a query vector, enabling more precise and flexible similarity searches in high-dimensional spaces.
- Hybrid Search: Allows users to search across multiple vector columns in a single query. For instance, you can combine text vector and image vector for multi-modality data, or dense vector and sparse vector to use semantic search and full-text search. This feature offers versatile and flexible search functionality.
For more details, see the Milvus Documentation.
Conclusion
Milvus provides a robust and scalable solution for working with billions of vectors. Its powerful features like filtering and distributed architecture make it a perfect choice for demanding AI applications.
Our performance tests have showcased Milvus's impressive capabilities:
- Average query latency: 2.05 milliseconds
- 99th percentile (P99) latency: 4.95 milliseconds
These results demonstrate that Milvus can consistently deliver sub-5ms search times, even when dealing with millions of vectors. So, if you're looking to build applications that can handle massive datasets and deliver lightning-fast search results, Milvus is definitely worth exploring.
If you like this blog post, please consider giving us a start on GitHub. You’re also welcome to share your experiences with the Milvus community by joining our Discord.
Further Resources
- What is Retrieval Augmented Generation (RAG)?
- Building RAG with Milvus, vLLM, and Meta’s Llama 3.1
- Generative AI Resource Hub | Zilliz
- Top Performing AI Models for Your GenAI Apps | Zilliz
- Choosing the Right Embedding Model for Your Data
- The Landscape of GenAI Ecosystem: Beyond LLMs and Vector Databases

Keep Reading

Announcing VDBBench 1.0: Open-Source VectorDB Benchmarking with Your Real-World Production Workloads
Discover VDBBench 1.0, an open-source tool for benchmarking vector databases with real-world production data, streaming ingestion, and concurrent workloads.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.