




The Landscape of GenAI Ecosystem: Beyond LLMs and Vector Databases
Since the groundbreaking launch of ChatGPT 20 months ago, the GenAI space has experienced significant developments and innovations. Initially, Large Language Models (LLMs) and vector databases captured the most attention. However, the GenAI ecosystem is much broader and more complex than just these two components. As a builder of the vector database, a crucial piece of infrastructure that empowers GenAI applications, I'm excited to observe the rapid technological advancements and their impact on the industry. In this article, I'd like to review what has been happening and share insights into the landscape of the GenAI ecosystem.
Generative AI applications can be broadly categorized into two major types: Retrieval-Augmented Generation (RAG) and multimedia generation. RAG combines information retrieval techniques with generative language models to produce relevant and coherent outputs. On the other hand, multimedia generation leverages generative models to create complex visual content, including creative advertisements and digital twins.
Retrieval-Augmented Generation
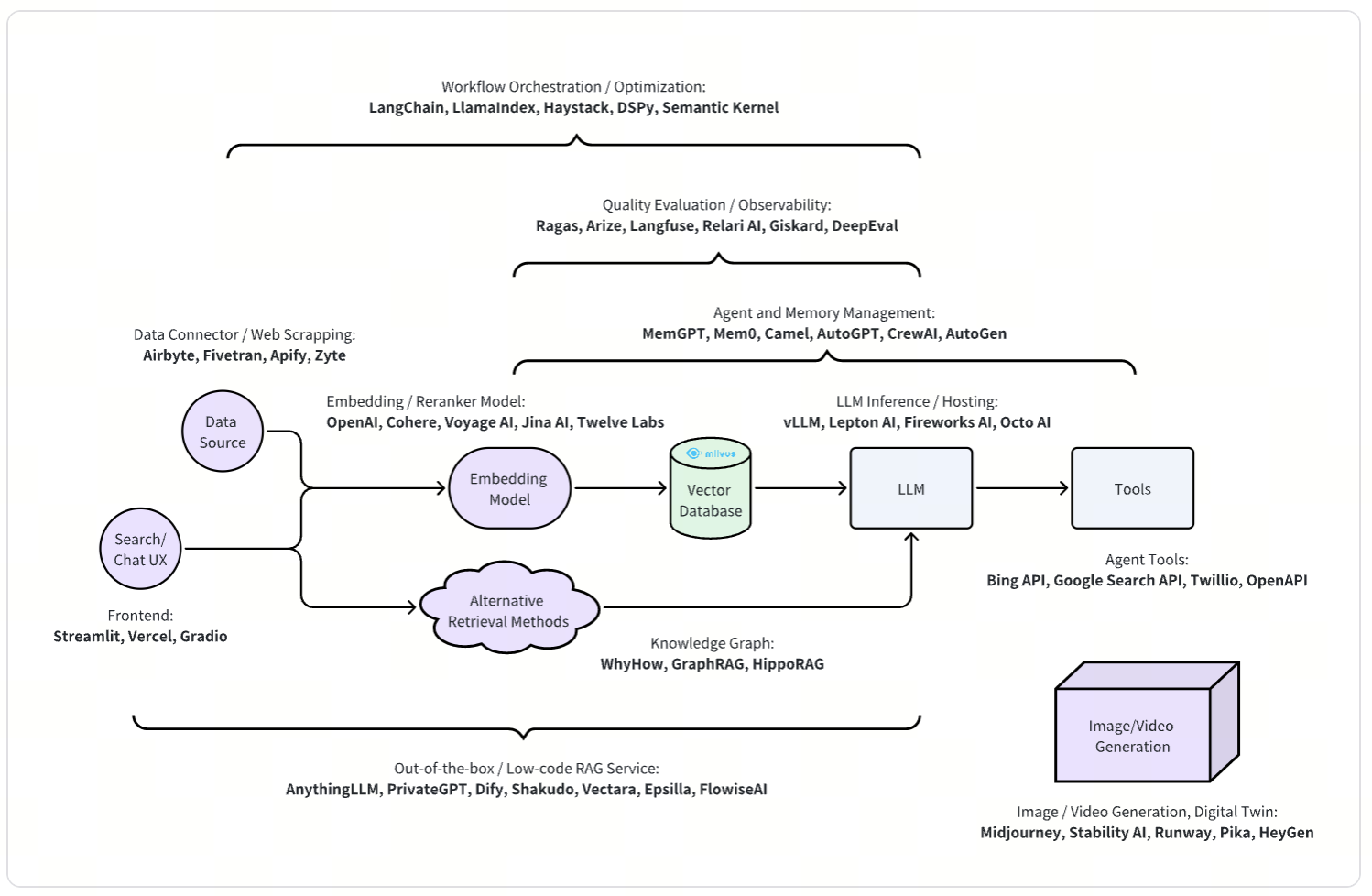
Retrieval-Augmented Generation (RAG) is currently one of the most popular use cases of generative AI. A simple RAG system consists of various components, including basic data cleaning, an embedding model, a vector database and an LLM. More advanced, production-level RAG systems typically include additional components to enhance quality and user experience. Since RAG systems resemble the architecture of traditional search systems, many components of search systems remain applicable to RAG today.
A typical search system can be divided into two main parts: the offline indexing part and the online query-serving part. Similarly, RAG consists of an indexing phase and an online query-serving phase:
Indexing Phase: The indexing phase involves data acquisition from various sources, including databases, APIs, and file systems. This data undergoes file parsing and text chunking to prepare it for analysis. After processing, the data is embedded into a suitable format and loaded into a vector database for efficient retrieval. Some RAG systems even incorporate advanced data mining techniques, such as label extraction, Knowledge Graph construction, and summarization, to enrich the data and improve the retrieval process.
Serving Phase: The online query-serving phase focuses on understanding the user's query intention and employs various retrieval methods, including vector similarity search, to find the most relevant information. The retrieval result is then sent to a Large Language Model (LLM) for generation. During this step, the LLM generates coherent and contextually relevant outputs based on the retrieved data. Additionally, the LLM can act as an agent, leveraging external tools to enhance its capabilities and provide more comprehensive and accurate responses.
As a result, many orchestration projects provide implementations of various components and configuration knobs. The complex nature of the architecture also necessitates evaluating the system both as a white box and a black box, which leads to the development of evaluation frameworks.
Each component also attracts developers who aim to build better and richer features, such as connectors for each data source and embedding models tailored for specific use cases. LLM inference frameworks offer more flexible deployment options for LLMs beyond just API services. Additionally, agentic frameworks help better leverage the reasoning and tool-using capabilities of LLMs.
Furthermore, some projects approach RAG from different perspectives, exploring alternative retrieval methods like knowledge graphs, developing web frontend frameworks for enhanced UI experiences, and creating out-of-the-box solutions that provide the entire RAG workflow, including chatbot UIs.
Workflow Orchestration and Optimization
To manage the complex workflows of RAG applications, SDKs such as LangChain, LlamaIndex, Haystack, DSPy, and Semantic Kernel are widely utilized. These orchestration frameworks enable developers to build, customize, and test RAG pipelines, ensuring that the pipelines are composed to achieve the best generative answer quality for specific use cases.
Example: LlamaIndex
LlamaIndex is a framework for building context-augmented applications using LLMs. It allows developers to integrate LLMs with private data by providing tools for data ingestion, parsing, indexing, and querying. This approach makes it easier to use LLMs for specific applications, such as question-answering, chatbots, and document understanding, by incorporating context from user-specific data sources like APIs, SQL databases, and documents. LlamaIndex offers convenient programmatic abstractions of commonly used components, such as various chunking strategies and hybrid search methods.
Quality Evaluation and Observability
Since RAG is a complex system, achieving optimal results in specific scenarios can be challenging. A scientific evaluation methodology is essential for addressing these challenges. Projects such as Ragas, Arize, Langfuse, Relari AI, Giskard, and DeepEval provide the necessary metrics and tools for evaluation and observability. They allow developers to quantitatively measure, monitor, and troubleshoot their RAG systems.
Example: Ragas
Ragas is a comprehensive framework for evaluating RAG pipelines. Ragas offers tools for assessing metrics of answer quality, such as faithfulness, relevance, and context precision. It supports the generation of synthetic test datasets, monitoring of RAG applications in production, and integration with AI tools and platforms like LangChain and LlamaIndex. By providing a harmonized Ragas score that encapsulates key performance aspects, this framework simplifies and quantifies the evaluation process, ultimately improving the effectiveness and reliability of RAG pipelines.
Data Connector and Web Scraping
The ability to seamlessly integrate and process data from multiple sources is crucial. Platforms like Airbyte, Fivetran are leading in providing robust data connectors as well as Apify, and Zyte for web-scraping. They enable businesses to collect, transform, and integrate data efficiently into RAG workflows, making it easier to harness the power of AI for critical missions. Data acquisition and connectivity were critical for traditional search systems, and they are as relevant in today's RAG, which is a new form of search to some extent.
Example: Airbyte
Airbyte is an open-source data movement platform designed to build extract and load (EL) data pipelines. Unlike many data pipeline platforms that primarily focus on major services, Airbyte also supports the integration of smaller, often overlooked services. By maintaining a vast array of connectors and fostering a community for sharing custom ones, Airbyte enables companies to create tailored solutions for their specific needs. Its robust data connectors can process unstructured data into embeddings and load into vector databases like Milvus for semantic similarity searches. This capability is helpful for businesses to efficiently collect, transform, and integrate data into RAG workflows, enhancing AI-driven decision-making and search applications.
Embedding and Reranker Models
Deep Neural Networks, such as embedding models, are transforming how unstructured data is processed and understood. Companies like OpenAI, Cohere, Voyage AI, Jina AI, and Twelve Labs are at the forefront of developing advanced models that convert textual and multi-modal data into numerical vectors. These embeddings enable Approximate Nearest Neighbor (ANN) vector searches, allowing applications to deliver highly relevant results and insights.
Beyond general-purpose embedding models, companies like Voyage AI create specialized models that improve quality in specific verticals such as legal and finance, while Twelve Labs focuses on video retrieval embedding models. Rerankers, which are purposely trained models that compare semantic relevance between a query and a small set of candidate documents, can further enhance the accuracy of results from the initial vector-based retrieval stage. Companies like Cohere, Voyage AI, and Jina AI offer rerankers to improve retrieval accuracy.
Example: Voyage AI
Voyage AI is a team of AI researchers from Stanford and MIT specializing in retrieval models, including embedding models and rerankers. Their leading model, voyage-2, trained through contrastive learning on text, offers higher retrieval accuracy, extended context windows, and efficient inference compared to industry standards like OpenAI’s text embedding model. Voyage AI provides both general-purpose and domain-specific models, optimized for fields such as finance, multilingual contexts, legal work, and code retrieval. Voyage AI also offers rerankers that enhance retrieval results.
LLM Inference and Hosting
With the growing demand for LLM applications, efficient hosting and inference solutions are essential. Projects like vLLM, Lepton AI, Fireworks AI, and Octo AI provide robust infrastructure for deploying and scaling LLMs. They incorporate various inference optimizations to ensure that models operate efficiently during serving time.
Example: vLLM
vLLM is an open-source library for optimized LLM inference and serving. It uses the PagedAttention mechanism to efficiently manage memory and supports continuous batching of incoming requests. The library leverages fast model execution through CUDA/HIP graphs and includes various quantization techniques such as GPTQ, AWQ, SqueezeLLM, and FP8 KV Cache. vLLM integrates seamlessly with popular HuggingFace models, providing high-throughput serving with decoding algorithms like parallel sampling and beam search. It supports tensor and pipeline parallelism for distributed inference, streaming outputs, and includes an OpenAI-compatible API server. Additionally, it offers experimental features like prefix caching and multi-Lora support, and is optimized for both NVIDIA and AMD GPUs.
Agent and Memory Management
The GenAI ecosystem is advancing in memory management and agent-based AI systems with solutions like MemGPT, Mem0, Camel, AutoGPT, and CrewAI. These innovations enable AI applications to remember conversation history, leverage tools and interact with each other, offering more personalized and context-aware interactions that significantly enhance user experiences.
Example: MemGPT
MemGPT is an open-source project aimed at simplifying the development and deployment of stateful LLM agents. By utilizing a memory hierarchy and control flow similar to traditional operating systems, MemGPT automatically and intelligently manages different storage tiers, thereby providing an extended context within the LLM’s limited context window. MemGPT facilitates connections to external data sources through RAG and supports defining and calling custom tools or functions, easing the development of advanced stateful LLM agents.
External Tools and API for Agents
The integration of AI models with various external tools and APIs is crucial for expanding the capabilities of agents. Services like Bing API, Google Search API, Twilio, and frameworks such as OpenAPI facilitate interaction of agents and tools, enabling applications to access and leverage external data, services, and functionalities.
Example: Bing API
The Bing Search API suite, which includes services like web and image search, provides safe, ad-free, and location-aware search results. This enables agents to access information from billions of web documents, images, videos, and news sources through a single API call.
Frontend and Search/Chat UI Experience
Creating intuitive interfaces for interacting with AI applications is essential for user adoption. Frameworks like Streamlit, Vercel, and Gradio simplify the development of AI applications by providing user-friendly UI experiences. Developers can leverage these frameworks to customize interfaces to meet the specific needs of AI interactions, such as chat boxes for RAG applications and features like image selection, cropping, and browsing for visual search.
Example: Streamlit
Streamlit is an open-source Python framework designed for data scientists and AI/ML engineers to create dynamic and interactive data apps with minimal coding effort. By focusing on intuitive syntax and eliminating the need for CSS, HTML, or JavaScript, Streamlit enables users to build and deploy polished applications quickly. It integrates with popular data libraries like Pandas and NumPy and supports backend components for developing AI-driven applications.
Knowledge Graph (KG)
Knowledge Graphs enhance Retrieval-Augmented Generation by providing structured data that improves the accuracy and relevance of information retrieval, resulting in more precise, context-aware AI-generated responses. Leading projects like WhyHow, GraphRAG, and HippoRAG combine Knowledge Graph structures with RAG techniques to improve the quality of retrieval results and generated answers.
Example: WhyHow
WhyHow is a platform designed to help developers organize and retrieve unstructured data more effectively, with a focus on enhancing complex Retrieval-Augmented Generation (RAG) systems using Knowledge Graphs. It offers tools for flexible data ingestion, supports multiplayer graph creation for collaboration between developers and non-technical domain experts, and allows for granular schema manipulation to tailor graphs to specific use cases. By emphasizing small, modular graphs and vector chunks, WhyHow improves information retrieval precision. The platform is compatible with vector databases and includes export features for various formats. Additionally, WhyHow provides an open-source Rule-based Retrieval Package to aid in creating more accurate retrieval workflows through advanced filtering techniques.
Out-of-the-box and Low-code RAG Services
There is also a significant demand for out-of-the-box and low-code solutions for RAG. Projects such as AnythingLLM, PrivateGPT, Dify, Shakudo, Vectara, Epsilla, and FlowiseAI offer easy-to-use solutions and a degree of customization that enable businesses to quickly deploy AI capabilities without the need for extensive development and domain expertise in data pipelines and search infrastructures.
Example: AnythingLLM
AnythingLLM is an all-in-one AI application that provides interactive RAG chatbots and AI Agents without the need for coding. It is designed for businesses seeking a private, zero-setup solution or a customizable AI application without requiring extensive coding expertise. AnythingLLM supports both commercial and open-source large language models (LLMs) and vector databases. The application facilitates full-stack experience through local and remote hosting. Key features include workspaces for organized document management, multi-user support with permission settings, agents for web browsing and code execution, a custom embeddable chat widget, and support for multiple document types. AnythingLLM also provides a developer API for custom integrations.
Image and Video Generation
The GenAI ecosystem is not limited to text-based applications; it also encompasses significant advancements in image and video generation:
Creative Generation and Digital Twin
Tools like Midjourney, Stability AI, Runway, Pika, and HeyGen are revolutionizing the creative industries by providing AI-powered solutions for generating high-quality images and videos. These platforms empower artists, marketers, and developers to create compelling visual content, pushing the boundaries of creativity and innovation.
Example: Midjourney
Midjourney is a generative AI program and service developed by Midjourney, Inc., an independent research lab in San Francisco. It creates high-quality images from natural language descriptions, or prompts, similar to OpenAI’s DALL-E and Stability AI’s Stable Diffusion. Users interact with Midjourney via a Discord bot, where they can generate images by typing prompts with the /imagine command, resulting in four images with options for upscaling. This tool highlights advancements in the GenAI ecosystem, impacting creative industries by expanding possibilities in digital content creation.
Closing Thought
The GenAI ecosystem is a dynamic and rapidly evolving landscape, characterized by its diverse components and complexity. From foundational technologies like LLMs and vector databases to innovations in data ingestion, orchestration, and image generation, GenAI is redefining the boundaries of artificial intelligence. As exploration and innovation continue, the potential for transformative impact across industries is immense. At Zilliz, as the creators of the Milvus vector database, we have collaborated with many partners in the GenAI landscape. We are eager to witness and contribute to GenAI’s ongoing evolution and look forward to the possibilities it will bring.

Keep Reading

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.

Why Context Engineering Is Becoming the Full Stack of AI Agents
Discover how context engineering unifies prompts, RAG, and tools to build smarter, production-ready AI agents powered by Milvus.

The Great AI Agent Protocol Race: Function Calling vs. MCP vs. A2A
Compare Function Calling, MCP, and A2A protocols for AI agents. Learn which standard best fits your development needs and future-proof your applications.