




Multimodal Pipelines for AI Applications
Success in artificial intelligence (AI) applications requires efficient data preparation and management. A more robust data pipeline leads to more accurate, reliable, and context-aware outputs. As AI workflows become increasingly complex, the need for scalable, intelligent pipelines to support them has become urgent.
Modern AI systems struggle with unstructured data, such as reports, images, and PDFs. Systems that employ retrieval augmented generation (RAG) require precise strategies for handling complex data while maintaining the accuracy of the results and keeping costs down.
Building such systems means parsing data from different formats, dealing with unpredictable AI outputs, and building pipelines that can scale efficiently. Recently, at the Unstructured Data Meetup organized by Zilliz, Sam, CTO of Datavolo with over 18 years of experience in data engineering and AI, addressed these challenges.
A platform built on Apache NiFi, DataVolo, was highlighted to address these issues. It simplifies unstructured data processing and allows for the creation of scalable, cloud-native pipelines. DataVolo also supports real-time responsiveness to metadata, permission changes, and strong evaluation frameworks to address non-deterministic AI models.
This article explains the key takeaways from the session on best practices for multimodal pipelines. We'll explore managing unstructured data and vector databases like Milvus for efficient retrieval and actionable strategies to enhance AI workflows.
The full video for the meetup can be found here.
Why Multimodal Pipelines are Critical for AI
A primary challenge businesses can face while implementing AI on a large scale is dealing with masses of complicated data. Conventional extract-transform-load (ETL) tools cannot handle tasks involving handling different formats like text, images, videos, and audio. Here’s why:
Unstructured Data Dominates: Over 80% of an enterprise's data is unstructured, including documents, images, and videos. This presents a challenge that cannot be addressed using traditional tools. Multimodal pipelines provide an integrated workflow with advanced AI algorithms to transform unstructured data into actionable intelligence. These pipelines bridge the gap between raw data and AI models, enabling organizations to use data for better decision-making.
Improving AI Accuracy: Large language models (LLMs), such as GPT, are robust but prone to errors, such as producing irrelevant or incorrect outputs. The accuracy of AI models improves due to the capability of multimodal pipelines to process various data types into a unified framework enriched with metadata. This metadata then acts as a guide to help AI systems retrieve the most relevant information related to a given query.
Improving Retrieval-Augmented Generation: RAG combines data retrieval with generative AI to produce more innovative, context-related outputs. The multimodal pipelines provide embeddings and metadata for seamless workflow optimizations. It ensures generative models give relevant answers by always pulling the relevant data during retrieval.
Scaling AI Workflows: Modern enterprises deal with increasing volumes of data. Multimodal pipelines automate tasks like chunking, embedding, and metadata management. This makes it easier to maintain performance while workflows scale upwards. These pipelines provide the scalability needed to meet those growing demands without giving up efficiency.
Real-time Updates: Enterprise data changes constantly, from content updates to access permissions. Multimodal pipelines ensure real-time synchronization. This keeps AI systems operating with the latest and most relevant information. It also supports dynamic use cases where real-time data is critical for accurate AI outputs.
These pipelines lay the foundations for efficient and innovative AI systems. They streamline the integration of diverse data sources and improve the performance of AI models in the real world.
Challenges in the AI Data Landscape
AI systems require high-quality data for training. However, managing various types of data comes with challenges. The complexity increases when the business handles massive amounts of unstructured data. Let’s take a look at some of the challenges in the AI data landscape:
Data Type Complexity: Data formats require specific tools or workflows to extract meaningful information. For example, PDF contains mixed data, including tables, text, and images. Therefore, it needs to be parsed to retrieve essential data. Models like layout detection can accurately process and arrange such data to preserve all vital information.
Metadata as a Backbone: Metadata is essential to increase the productivity of AI workflows. It provides advanced search, retrieval, and access control so that users can quickly access the data they need. Metadata is crucial to filtering, ranking, and securing access to retrieved information and, therefore, a key component of successful AI systems. Enriching the data with metadata empowers hybrid search approaches, binding semantic embeddings to the metadata filter. This will enhance precision and relevance in the AI systems.
Data Management: Data may change due to updates, corrections, or additions in large enterprises. They must have systems that can effectively support such dynamic flows in real-time. For example, active ingestion systems ensure the synchronization of source files into AI workflow systems without disruption.
Evaluation-First Approach: Continuous monitoring and evaluation of the AI system's results are critical to achieving a consistent and reliable output. Before the system goes to production, enterprises should create evaluation sets and metrics. This will help organizations measure how their systems process complex data to meet business objectives. Synthetic datasets can be used to test and refine strategies, including chunking and embedding.
Scalability and Integration: As the volume of data gradually increases, scalability becomes very important. AI systems should integrate with existing enterprise tools without performance degradation and increased workloads. Scalable solutions improve workflow efficiency as data size and complexity increase. Integrating advanced systems such as vector databases enhances functionality like vector search, ensuring smooth operation in real-world scenarios.
By addressing these, the enterprise can unleash the full power of data and make a strong basis for AI systems to work powerfully in dynamic environments. Modern pipelines bring transformative results by bridging the gap between raw data and operational workflows in AI.
DataVolo's Place within the AI Stack
DataVolo is a game-changing platform for building multi-modal data pipelines. Powered by Apache NiFi, DataVolo has a strong foundation for modern AI systems. Key features include:
Continuous and Automated Data Pipelines: Datavolo is built for continuous and event-driven ingestion. It scales up dynamically according to data volume fluctuation for predictable performance in times of high throughput. The platform supports various formats of data, including audio, video, images, sensor signals, structured JSON or XML, and text-based logs.
Parsing and Chunking: DataVolo can handle unstructured data with ease. It has specialized processors for advanced document parsing to break down complex documents into manageable sections. For example, the ChunkDocument processor uses structural information to form coherent chunks, while the ChunkText processor further refines these into smaller ones based on semantic meaning.
Cloud-Native Deployment: DataVolo is intrinsically cloud-native, and its architecture allows for flexible deployments across major providers like AWS, GCP, and Azure. It enables organizations to use their existing cloud infrastructures. It enables seamless operation in hybrid cloud environments, ensuring performance and manageability.
Observability: DataVolo integrates with OpenTelemetry for standardized data collection, thus allowing its interoperability with a variety of monitoring and analytics tools. Besides, it also integrates with a GenAI-based Flow Generator that translates natural language into NiFi flows. This makes it easier to create or manage data pipelines.
Focus on the Data Engineer Persona: Datavolo targets data engineers, introducing them to a visual, low-code interface for designing, planning, and maintaining pipelines. The platform offers a wide array of different prebuilt processors and connectors, thus effectively supporting a wide variety of sources and destinations. It provides flexibility in quickly adapting to the changes in AI technologies and data requirements. This makes data engineers effective in providing impactful AI solutions without these infrastructural complexities.
Integration with Vector Databases: DataVolo integrates very well with both Zilliz and Milvus for efficient vector database management. These two work synergically to empower enterprise-wide development of AI workflows that scale and perform well.
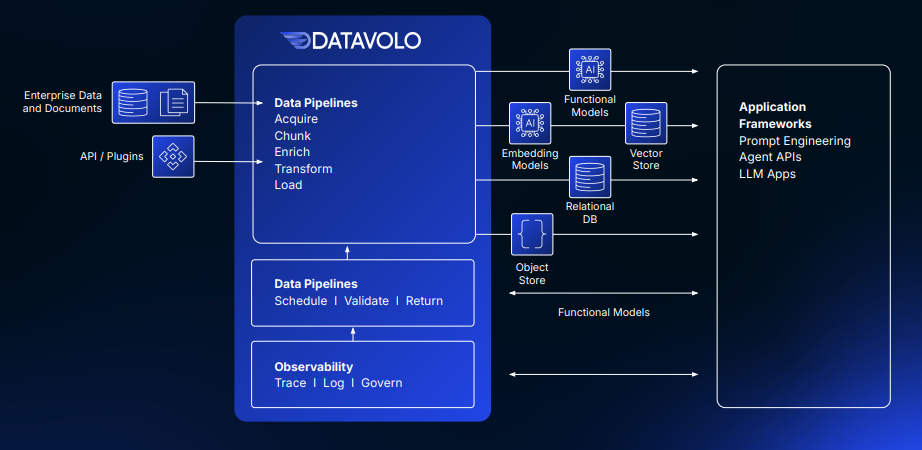
Working of DATAVOLO: Source
Case Study: Financial Data Analysis Chatbot
Processing unstructured documents such as financial reports requires innovative approaches to handle the intrinsic complexity. Most enterprises face serious challenges while extracting meaningful insights from such documents. Let’s uncover how to process such documents and create a scalable solution.
Challenge
Financial document processing, such as 10-K reports, is complex for an enterprise. These reports are usually hundreds of pages long and contain tables, charts, and data in text. The processing is highly time-consuming, error-prone, and inefficient if done manually.
Solution
A scalable, automated pipeline should integrate advanced techniques for data processing with vector databases. The solution contains the following processes:
Data Ingestion: Data is extracted from various sources, including S3 buckets, through automated ingestion. It adds essential details such as document type and source to make each document relevant and helpful in making decisions. In handling unstructured data with dynamic data flows, CDC (Change Data Capture), is implemented. It ensures that every update, correction, or addition in the source files is captured and synchronized with the target systems in real time.
CDC avoids using irrelevant information and maintains the integrity of data across workflows. Ingestion is further optimized with these listing strategies for avoiding reprocessing older:
Timestamp-Based Listing: It allows listing only those files that have been added or modified after a certain timestamp. This verifies that the ingestion of new or updated data happens without redundancy.
Hashing Techniques: It compares the content to identify and skip previously processed files, even when the filenames remain the same.
These capabilities ensure robust and efficient data ingestion pipelines that are adaptive to changes, dynamically keeping AI systems powered by accurate and current information.
Pre-processing: Pre-processing of the document involves following the following steps:
Layout Detection: Layout detection plays an important role in processing complex documents such as PDFs and financial reports. It applies the fine-tuned YOLO-X model to identify and label the components such as tables, images, and sections with bounding boxes. The tables retain structure, while there is contextual linkage of narrative text or descriptions. A document graph brings these elements hierarchically for better navigation and retrieval. OCR is used when the text layers are not present and capturing all document elements is necessary. It ensures that structure and context are maintained for data extraction to be accurate and reliable.
Chunking: Documents are divided into manageable chunks for efficient processing. The most naive approach is chunking by a fixed number of characters, such as 400. However, this may split semantically connected information, and hence, it is not effective. A more refined method is section-based chunking, where sections detected through the layout detection provide the boundaries. Accordingly, each chunk retains the context of a section, including the heading and the narrative text that appears in it. The other strategy for chunking uses the meaning of the text by applying the cosine similarity of consecutive sentences. When it is smaller than the given threshold, it performs the chunk. This retrieval strategy makes each semantically incoherent with increased accuracy of a user's query.
Metadata Extraction: Some metadata, such as document type and source URL, is statically set through configuration in the pipeline. Other metadata is automatically derived from the processing flow, such as details extracted through layout detection or enrichment with external data sources. For example, symbols present in the financial document would query the same symbol in a PostgreSQL table and append appropriate company-level metadata. This will enable more advanced use cases like hybrid search, ranked results, and secure access control based on enhanced metadata.
Embedding: Text chunks are transformed into dynamic high-dimensional vectors through cutting-edge embeddings. These vectors capture the essence of the data and reveal meaningful semantic connections. It makes information retrieval an intuitive experience while answering user queries.
Storage: These embeddings and metadata are stored in a high-performance vector database like Milvus. This allows for rapid retrieval even among millions of stored vectors through indexing. Metadata filtering brings precision by enabling queries to consider further context, such as date ranges or document sections.
Real-Time Updates: Continuous ingestion pipelines automatically update the data to maintain the accuracy and relevance of the system. It ensures that the users have access to the most recent data.
Outcome
This will help create a chatbot specifically for financial analysts. The bot may receive long-tail queries like, "What was Company X's net profit for 2023?" or "What are the main risks identified in the risk assessment section?" It will provide correct and contextually relevant answers in seconds, with proper citations from the original documents.
Key Benefits
Efficiency: Ingestion, pre-processing, and embeddings are automated to save the financial team time on higher-order tasks.
Scalability: Scalable support for storing and retrieving millions of vectors in advanced-vector databases simplifies analysis as data volumes increase.
Real-time Insights: Continuous updates ensure analysts have the latest information for time-sensitive decisions.
This use case highlights the power of multimodal pipelines in simplifying complex workflows. It illustrates how integrating advanced data processing with vector database solutions can deliver significant value.
Milvus: Accelerating Vector Search
Milvus extends enhanced support to multimodal AI pipelines by introducing a slew of features for easy integration and processing of different varieties of data like texts, images, and videos. Some of the key enhancements include:
Hybrid Vector-Keyword Search: Milvus integrates vector similarity and full-text keyword searches in a single platform. It enables efficient retrieval across different data modalities. This allows sophisticated AI applications that require semantic understanding and precision keyword matching.
Sparse-BM25 Technology: Milvus introduced Sparse-BM25 technology to enable a sparse vector version of the BM25 algorithm. It is one of the most popular algorithms used in full-text search systems. This technology remarkably improves keyword searching speed and accuracy to complement vector-based semantic searches. This enhances the performance of multimodal AI pipelines.
AI Development Toolkits Integration: Milvus natively integrates with the full suite of AI development toolkits, including LangChain, LlamaIndex, OpenAI, and HuggingFace. These toolkits make Milvus the vector store of choice for Generative AI applications that support RAG across various data modalities and reduce friction for developing multimodal AI.
These enhancements make Milvus robust and efficient in building and deploying a multimodal AI pipeline. This enables organizations to process and analyze different types of unstructured data in one place.
Continuous and Automated Data Pipelines
The dynamic and constantly changing nature of enterprise data requires automated workflows for the datasets feeding the AI systems. DataVolo addresses this with the following:
Real-Time Ingestion: DataVolo enables real-time ingestion by connecting to data sources like S3 buckets, Google Drive, and SharePoint. It automates ingest using event-driven mechanisms, reducing human intervention. It also provides configurable ingestion strategies to process it efficiently. These strategies include timestamp-based listing to identify and handle only new or updated files without creating any redundancy, hence optimizing resources.
Event-Driven Architecture: DataVolo pipelines are event-driven and automatically respond to any change in the upstream systems. Events such as changes to files, updates of metadata, or user permissions trigger the automatic update in the pipeline. Even sensitive metadata, like ACLs, is managed securely throughout this process.
Scalable and Fault-Tolerant Design: It features scalability and fault tolerance, drastically reducing performance degradation during high-throughput ingestion. Horizontal scaling is handled by Kubernetes-powered orchestration. With inbuilt retry logic, backfill processes, and upstream downtime management, it offers reliability and resilience while managing data pipelines.
AI Success through Evaluation
Evaluation forms an essential pillar for effective AI deployment. It measures the refinement of the systems toward accuracy, reliability, and satisfaction. The following metrics can help in evaluating the AI models:
Retrieval Metrics
Precision: The ratio of relevant data retrieved to the total results, so the system returns only the most pertinent information.
Recall: The ratio of relevant data retrieved to the total relevant data, ensuring no valuable information is missed.
F1 Score: This metric combines precision and recall into one score. It balances the trade-offs between these two and yields a comprehensive evaluation.
Language Model Metrics
Faithfulness: It verifies if the AI responses are from the context obtained and reduces hallucinations to maintain factuality.
Correctness: Compares AI-generated answers against the testing data to measure the accuracy of the outputs.
The challenge lies in evaluating non-deterministic models, for which the systems can give different outputs for the same input because of their probabilistic nature. Determining and evaluating "correct" responses is inherently complex. Perceptions of accuracy and relevance often vary depending on the user and the specific context. Dynamic feedback loops, iterations, various testing sets, and metrics sensitive to context are needed to resolve this.
Hyperparameter tuning is crucial in refining AI workflows, particularly retrieval-augmented generation (RAG) systems. Different chunking strategies require careful configuration of parameters like chunk size, overlap, and similarity thresholds. These include section-based chunking for broader context or semantic chunking for higher precision.
Iterative testing, combined with retrieval metrics, helps identify the optimal balance between precision and contextual richness, ensuring high-quality retrieval and generation.
Evaluation-first workflows allow AI systems to keep pace with ever-changing data and user needs landscapes. With iterative refinements and emphasis on robust metrics, outputs would remain credible, actionable, and contextual. By doing so, it fills in the gap from experimentation toward dependable, real-world deployment, thus trusting and satisfaction with the results of AI applications.
Conclusion
Robust multimodal pipelines are the backbone of scaling AI systems from experimental stages to full-scale production. These pipelines seamlessly handle diverse data types, enabling enterprises to build more innovative workflows.
It offers scalable, secure, high-performance data management by integrating advanced data pipeline platforms and vector databases like Zilliz and Milvus. Further, automating tasks such as data preprocessing, embedding, and metadata enrichment would reduce manual effort without compromising accuracy and scalability.
The transformations and real-time synchronization of AI systems will make them effective. It makes it easier to create AI workflows, enabling continuous assessment and improvement.
This helps enterprises continuously improve application performance, adapt to evolving data landscapes, and meet dynamic business needs. Such technologies can help businesses how they process data and deploy AI-driven applications.
Further Resources

Keep Reading

VDBBench Adds Cost-Aware Benchmarking for Vector Databases
Compare Zilliz Cloud, Pinecone, and turbopuffer with VDBBench cost-aware vector database benchmarks across latency, freshness, multitenancy, and cold starts.

Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
Vector Lakebase: a unified, lake-native data foundation for AI workloads — and an answer to what happens after vector databases succeed.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.