




How to Choose the Right Milvus Deployment Mode for Your AI Applications
Milvus is an open-source vector database that stores, indexes, and retrieves billion-scale vector embeddings. It is also an indispensable component of retrieval augmented generation (RAG), a popular and effective technique for mitigating hallucination issues in large language models (LLMs).
Unlike other open-source vector search projects like Qdrant, Weaviate, and Chroma, Milvus offers developers three major deployment options catered to different sizes of datasets, use cases, and business requirements. While having multiple choices is a benefit, it can also be a bit overwhelming. Many developers are unsure how to select the best deployment mode for their specific AI applications. In this blog post, we’ll provide a clear and detailed guide to help you choose the correct Milvus version for your projects.
Milvus Lite vs. Standalone vs. Distributed
Milvus offers three deployment options: Milvus Lite, Standalone, and Distributed.
Milvus Lite
Milvus Lite is a Python library and an ultra-lightweight version of Milvus. It’s perfect for rapid prototyping in Python or notebook environments and for small-scale local experiments. You can install it directly through the pymilvus package with a simple line of pip install pymilvus. There's no need to run a separate server, and it handles data persistence using local files, making it easy to set up and use.
Milvus Standalone
Milvus Standalone is the single-node deployment option for Milvus, using a client-server model. You can think of it as the Milvus equivalent of MySQL, while Milvus Lite is like SQLite. All Milvus Standalone components come bundled in a Docker image, making server deployment straightforward. Running a single Milvus Standalone instance on a machine with sufficient memory will work well for most projects that don't require extensive scaling. Additionally, Milvus Standalone offers high availability with a primary backup mode, making it a dependable choice for production environments.
Milvus Distributed
Milvus Distributed is the distributed mode of Milvus, which is ideal for enterprise users building large-scale vector database systems or vector data platforms. It adopts a cloud-native architecture with read-write separation to optimize performance. The key components of Milvus Distributed are equipped with built-in backups and additional instances, so if one part fails, others can seamlessly take over, ensuring the system remains uninterrupted. This level of redundancy enhances reliability and guarantees continuous availability. Of the three deployment options, Milvus Distributed offers the highest scalability and availability. It also provides component-level elasticity, allowing you to independently scale Proxy, query nodes, and index nodes based on your specific business load requirements.
The table below summarizes and compares the key capabilities of Milvus Lite, Milvus Standalone, and Milvus Distributed.
| Capabilities | Milvus Lite | Milvus Standalone | Milvus Distributed |
| SDK | Python | Python, Go, Java, Node.js, C#, RESTful | Python, Go, Java, Node.js, C#, RESTful |
| Data Types | Dense vectorsSparse vectorsBinary vectors Boolean scalars Integer scalars Float scalars Strings Arrays JSON | Dense vectors Sparse vectors Binary vectors Boolean scalars Integer scalars Float scalars Strings Arrays JSON | Dense vectors Sparse vectors Binary vectors Boolean scalars Integer scalars Float scalars Strings Arrays JSON |
| Search | Vector search (ANN search)Filtered vector search Range searchHybrid search Scalar expression query Primary key query (get) | Vector search (ANN search)Filtered vector search Range searchHybrid search Scalar expression query Primary key query (get) | Vector search (ANN search)Filtered vector search Range searchHybrid search Scalar expression query Primary key query (get) |
| Basic CRUD Capabilities | ✔️ | ✔️ | ✔️ |
| Advanced Capabilities | - | RBAC (role-based access control) | RBAC (role-based access control) Sharding Partition Partition Key Physical resource grouping |
| Consistency | Strong | Strong Bounded staleness Session Eventually | Strong Bounded staleness Session Eventually |
Table: Comparing Milvus Lite, Milvus Standalone, and Milvus Distributed
How to Select the Right Milvus Deployment for Each Stage of Development
Choosing the appropriate Milvus deployment option depends on the stage of your application development. These stages include Rapid Prototyping, Early Production Deployment, and Large-Scale Production Deployment. Let’s explore each stage in detail.
Milvus Lite for Rapid Prototyping of AI Applications
When developing and prototyping AI applications like a personal assistant, a semantic search engine, or an end-to-end RAG, the app speed and flexibility are usually prioritized over performance and stability. Therefore, Milvus Lite is an ideal choice at this stage. It allows you to quickly build end-to-end functionality within a notebook environment and conduct lightweight experiments focused on testing effectiveness.
Transition to Milvus Standalone for Validation on Large Datasets
Milvus Standalone is the next logical step if you need to validate your results on a large dataset. Milvus Lite and Standalone are designed to work seamlessly together, offering an easy transition from local prototyping to server-based validation. Since Milvus Lite, Standalone, and Distributed share the same client interface, you can reuse the same business logic for both local and large-scale data validations. Additionally, Milvus Standalone supports multiple users, making it easier for agile development teams to collaborate or share data using a single instance.
Milvus Standalone for Early Production Deployment
In the early stages of app production, when your project is newly launched and still finding its product-market fit, the business requests and data volumes are relatively low. The focus should be on business effectiveness and competitiveness rather than on infrastructure. Milvus Standalone is well-suited for this phase. For online services, deploying Milvus in a high-availability primary backup mode ensures reliability. For testing environments, a single-node deployment is usually sufficient.
Note: Milvus Standalone does not offer physical resource isolation between tables. If you have two critical, performance-sensitive applications, it's better to isolate their data using separate Milvus Standalone instances. While this might lead to some resource inefficiency, it remains more cost-effective than managing a Milvus Distributed setup at this stage.
You can continue to use Milvus Lite for specific debugging tasks but avoid doing so in the production environment where Milvus Standalone is deployed, as it could introduce performance and stability risks.
Milvus Distributed for Large-Scale Production Deployment
When your data outgrows the capacity of a single server or is rapidly expanding, it's time to prepare for future scalability. Milvus Distributed becomes essential at this stage.
This best practice involves running both Milvus Standalone and Milvus Distributed instances concurrently at the beginning and gradually shifting data traffic from Standalone to Distributed. Make sure to monitor the system for at least a month until Milvus Distributed operates stably.
During this phase, you'll also need to enhance your operations management. Milvus Distributed natively supports Prometheus and offers management tools like Attu. While Milvus provides a wide range of dedicated operational tools and ecosystem integrations, managing a large distributed system can be challenging. We encourage you to join the open and active Milvus community to ask for support, contribute code, attend events, and make many other valuable contributions.
How to Choose the Right Deployment for Your Vector Datasets
Milvus is designed to scale with your project, offering different deployment modes to match the evolving demands of your dataset. To clarify their differences, we'll break down how Milvus Lite, Standalone, and Distributed compare to each other and, more importantly, to other open-source vector databases in the market, like Chroma, Weaviate, and Qdrant.
Chroma has gained traction among developers since last year, particularly for small-scale projects. Like Milvus Lite, Chroma is a lightweight vector database. It's best suited for applications handling fewer than hundreds of thousands of vectors. Chroma offers basic functionalities such as vector data insertion and similarity search, making it a lightweight option for quick prototyping. However, its limited feature set and lack of production readiness mean that even Milvus Lite provides more robust capabilities.
For production-ready solutions, Milvus Standalone and Distributed, along with Weaviate and Qdrant, are stronger choices. Weaviate is well-known for its integration with AI applications, providing native support for various upstream models. Qdrant, on the other hand, focuses on core vector database functionalities with an emphasis on vector search performance. However, according to VectorDBBench, an open-source vector database benchmarking tool, Milvus still outperforms Qdrant in search performance, making it a top contender in this space.
Here's a breakdown of the suitable data scales for each vector database:
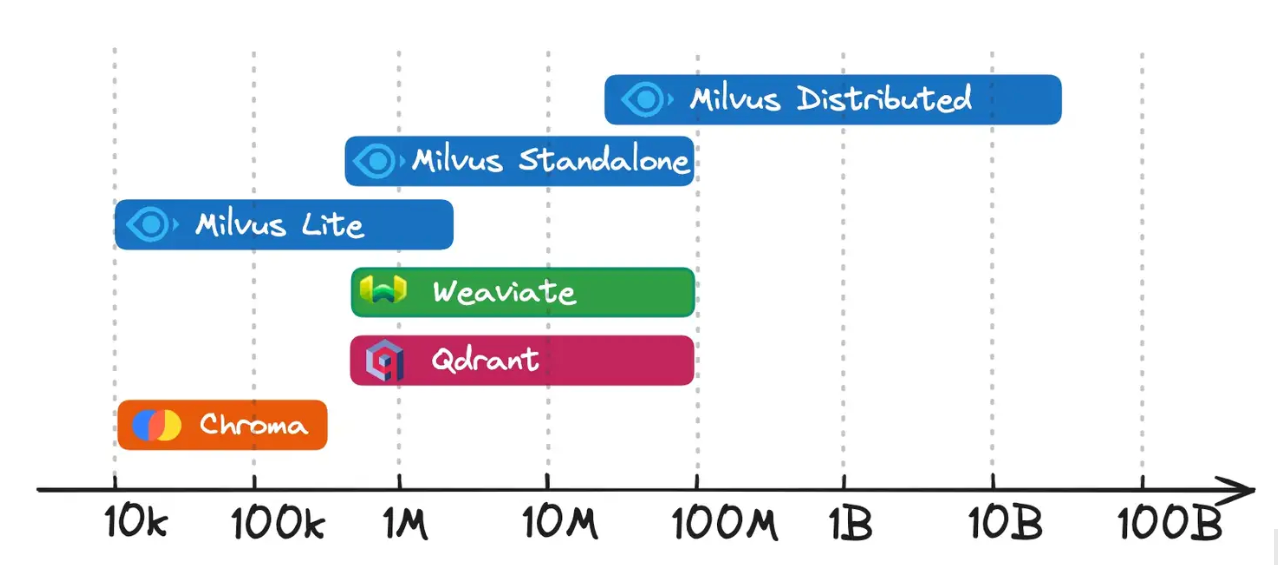 Figure 2- Milvus vs. Chroma vs Qdrant vs. Weaviate for vector storage and retrieval
Figure 2- Milvus vs. Chroma vs Qdrant vs. Weaviate for vector storage and retrieval
Milvus Lite and Chroma are ideal for data scaling up to one million vectors. They are designed for ease of use, sacrificing some system capabilities for simplicity.
Milvus Standalone, Weaviate, and Qdrant: Best for data scales ranging from one million to tens of millions of vectors. These databases strike a balance between powerful system capabilities and ease of use, making them suitable for early-stage production.
Milvus Distributed: Designed to handle data scales of tens of millions and beyond. The Milvus community has validated its support for billion-scale use cases, and it's now being implemented for situations involving tens of billions of vectors.
While other vector databases like Chroma, Weaviate, and Qdrant have their strengths, they often fall short in offering the same level of flexibility, scalability, and long-term support that Milvus provides. As your project grows, switching vector databases can become costly and complex. Milvus, with its versatile deployment options, supports mixed workflows across various data scales, ensuring that you don't outgrow your database solution.
Milvus Lite, Standalone, and Distributed Underlying Components
Milvus provides a consistent user experience and uniform evolution across its three deployment modes thanks to the shared underlying components. This design ensures that you benefit from the same core functionality, whether you're using Milvus Lite for lightweight tasks or Milvus Distributed for large-scale operations.
The diagram below illustrates the functional components covered by each of these Milvus deployment modes:
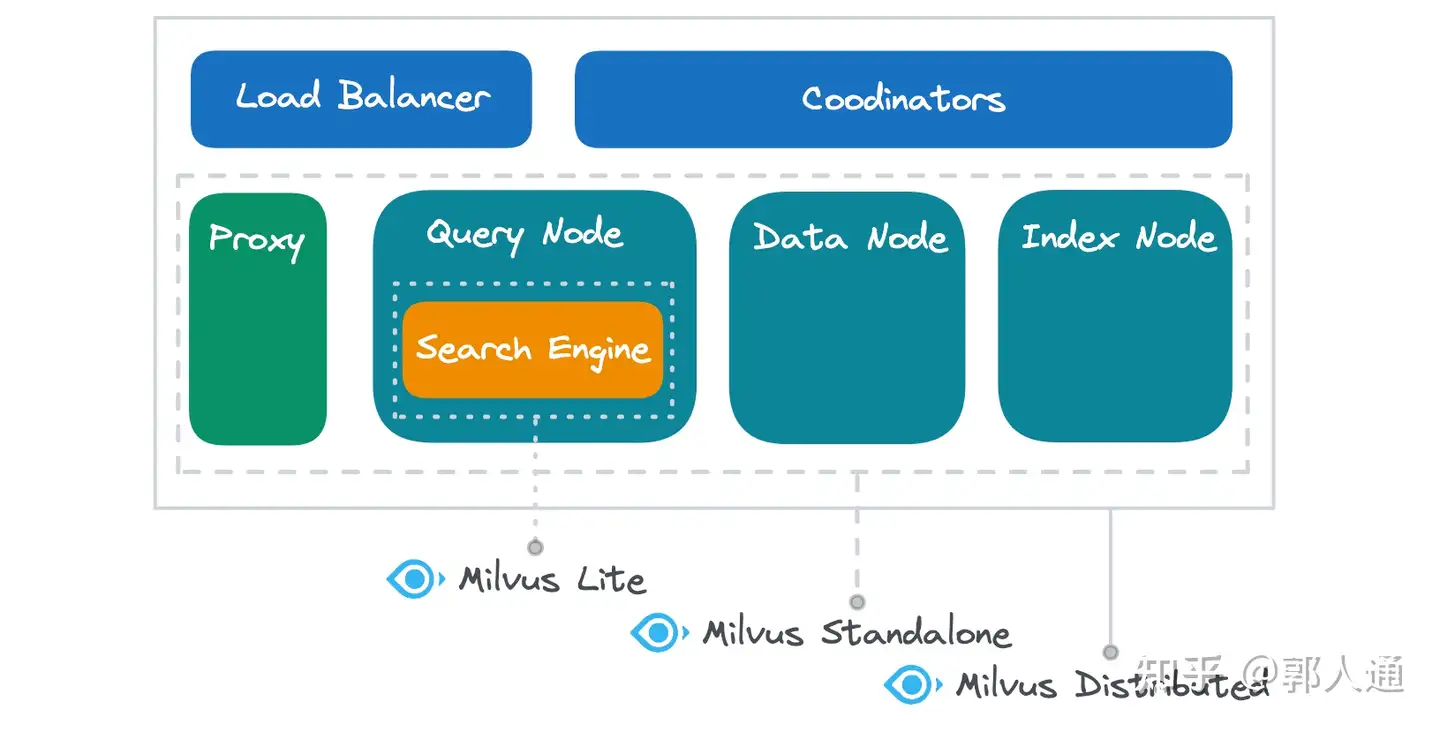 Figure 2- Milvus Lite vs. Standalone vs. Distributed on underlying components
Figure 2- Milvus Lite vs. Standalone vs. Distributed on underlying components
Milvus Lite primarily encapsulates the search engine while also offering local implementations for essential tasks such as data insertion, persistence, index building, and metadata management. Think of Milvus Lite as a powerful library rather than a simple tool. Compared to more basic libraries like Chroma, Milvus Lite's search engine delivers superior performance and query capabilities, making it ideal for vector embeddings. If you're seeking an alternative to FAISS or HNSWLib, Milvus Lite is a strong candidate, as it natively integrates mainstream vector search algorithm libraries and has undergone extensive optimization for both performance and functionality.
Milvus Standalone includes all the functional components of the Milvus system except for load balancing and multi-node management (coordinators). These components operate within the same Docker environment, facilitating efficient local communication and minimizing server latency.
Milvus Distributed boasts a full range of functional components. While both Standalone and Distributed modes contain a Proxy, Query Node, Data Node, and Index Node with identical functionalities, Milvus Distributed offers greater deployment flexibility. Each functional component can be deployed multiple times to handle higher loads, and multiple components can be deployed on the same physical node to share resources or on different nodes to ensure resource isolation. Additionally, the Distributed mode allows for independent scaling of each component, enabling you to adapt to varying load characteristics and improve resource utilization effectively.
Summary
In this post, we've explored the three deployment options that Milvus offers: Milvus Lite, Standalone, and Distributed. Each deployment mode is tailored to meet different development stages, data sizes, and use cases, ensuring that Milvus can scale alongside your project.
Milvus Lite is ideal for rapid prototyping and small-scale experiments within Python environments. It's easy to set up and use, making it perfect for developers who need a lightweight yet powerful solution for testing and development.
Milvus Standalone is the next step for those ready to move from prototyping to production. This single-node deployment option provides all the necessary components for early production environments, balancing performance and resource efficiency. It is well-suited for projects with moderate data sizes and growing user demands.
Milvus Distributed is designed for large-scale production deployments that require high availability, scalability, and flexibility. It’s the go-to choice for enterprises and applications dealing with massive amounts of data, ensuring that your vector database can grow with your business needs.
Further Resources

Keep Reading

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.

DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
Discover DeepRAG, an advanced retrieval-augmented generation (RAG) model that improves LLM accuracy by retrieving only essential data through step-by-step reasoning.