




An Introduction to Milvus Architecture
In a survey of over 1200 users, we found one key repeating challenge: scalability. How can we scale our vector operations? This question leads to the development of Milvus as a distributed system. Vector databases, unlike traditional databases, have different usage requirements. Three main differences motivated us to build a cloud-native vector database from scratch.
First, vector data doesn’t require complex transactions.
Second, the diversity of the use cases requires a tunable tradeoff between performance and consistency.
Third, some vector data operations are computationally expensive, necessitating elastic resource allocation.
Milvus achieves horizontal scaling through its deliberate design as a distributed system. While single-instance databases can scale up to a certain point, they soon become hardware-limited. Milvus’s horizontal scaling capability overcomes this problem, allowing the database to extend across multiple instances. There are two ways to scale a database horizontally: directly integrating the functionality into the database or manually implementing scaling processes.
With Milvus, the scaling functionality is built into the system. While you can handle the scaling yourself, it’s not an ideal solution unless your mission-critical work involves scaling databases. Let’s examine three architectures and two search design choices that make Milvus so scalable.
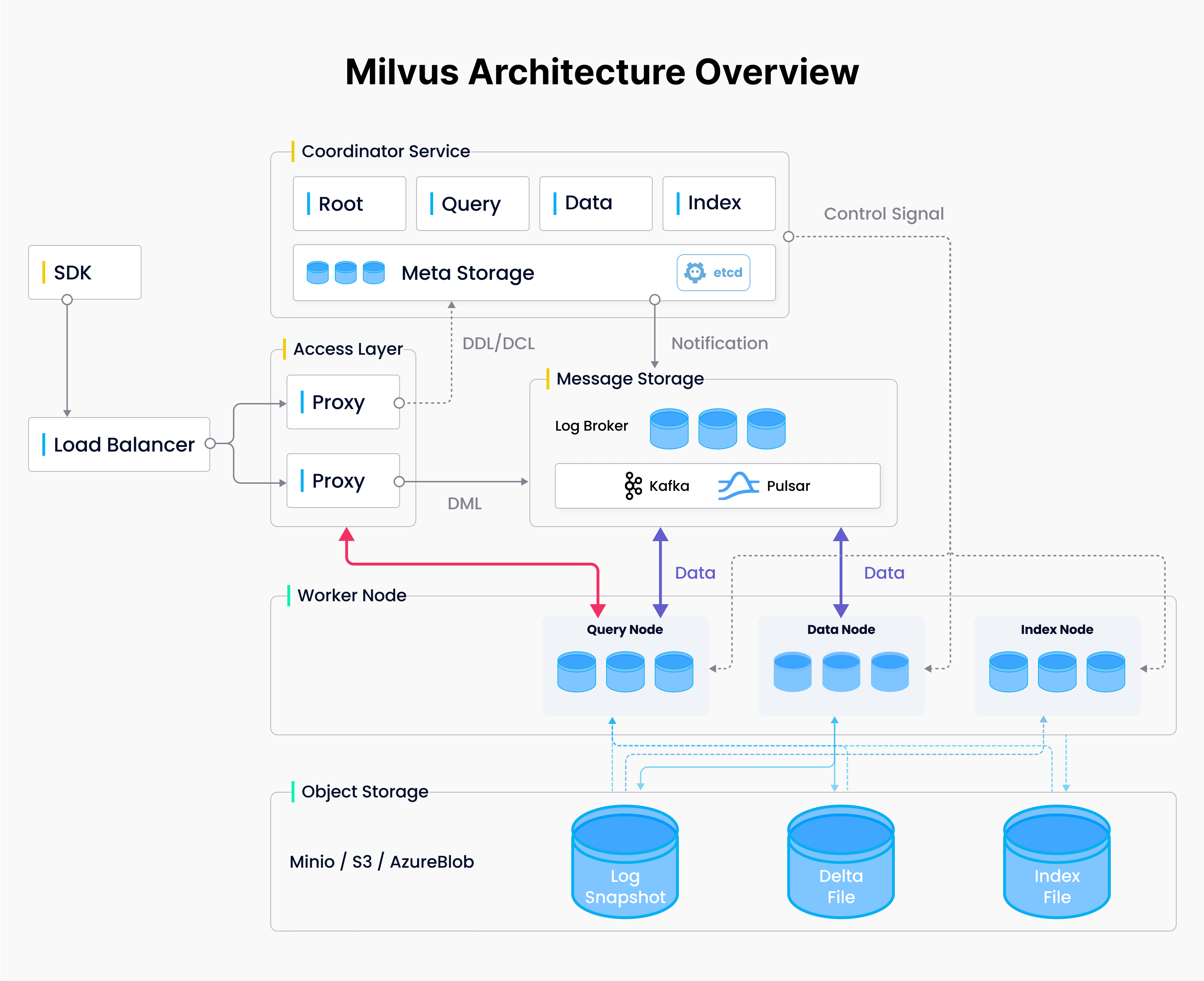
Cloud-native system architecture
Most software teams no longer deploy to the servers in the server room. Why? The available public clouds (AWS, Azure, GCP, etc.) allow software teams to move faster. Milvus is built to take advantage of the flexibility that working on the cloud provides.
Milvus contains four layers: access, coordination, worker, and storage. Stateless access nodes give access to the system. The workers and coordinators are designed in a serverless pattern. Stateful coordinators spin stateless workers up and down as needed. The storage layer stores the vector data and all the necessary information for the system to function.
Separation of concerns
When working with a vector database, there are three primary concern areas: querying, data ingestion, and indexing. These three functionalities will always scale at different amounts at different times. Milvus provides three different types of nodes that can scale independently.
Query nodes handle query functionality, meaning they must have enough memory to hold the in-memory indexes for multiple segments. Segments are blocks of data of a predefined size that Milvus uses for efficiency and scalability. Query nodes also help parallelize search by using some of their computing and memory to delegate, aggregate, and process search results from multiple segments, many of which may be held on other nodes.
As data comes in, it goes into both the query and data nodes. These nodes hold onto data in growing segments that have yet to reach their size limit. After the segment reaches capacity, the query node releases that data and replaces it with the generated index.
Data nodes handle data ingestion. After a segment reaches its size limit with a data node, it gets “sealed.” Sealed segments are then flushed to permanent storage from the data and query nodes. Once the data is flushed to the storage layer, the coordinators notify an index node.
Index nodes build indexes. When an index node gets notified, it reads the data segment from the storage layer. This setup naturally allows us to work with less data when creating the index. Since the index node reads data from storage, it can read only the attributes it needs to develop indexes on.
Large-scale write consistency
A natural part of scaling is running into consistency problems. Once you spin up the second replica or instance of Milvus or any other database system, you instantly encounter a data consistency problem. You must ensure a system-wide agreement about how consistent data should be.
Milvus has many options to tune your data consistency built into the system. Milvus is a pub/sub-system. The message storage block acts as a publishing system, timestamping each piece of data that comes through. The query and data nodes then read this publication log as subscribers.
Scaling write involves scaling the number of shards acting as writers. As data enters, its ID is hashed, and the hash determines which shard will write that piece of data.
Data segments for parallel search
As mentioned earlier, Milvus creates individual indexes on predefined amounts of data called “segments.” By default, Milvus creates segments on 512MB of data, which you can adjust to fit your needs.
Why do we create segments and build indexes this way? For more flexibility, scalability, and ease of mutation. Indexes are ways to access data. Imagine you build an index on some initial dataset. In a real-world scenario, your data changes over time, so you’ll have to continue adding data. Since the initial index was only built on the initial data, it doesn’t help with the new data.
The rational solution to this indexing problem would be continuously building new indexes at some predefined interval (like the amount of new data added). Milvus implements this solution across multiple instances and replicas.
This segment setup provides an efficient solution to inefficient indexing and makes querying more scalable. Since indexes built on separate data segments don’t depend on each other, we can search them in parallel, limited only by hardware.
Opting for a larger segment size enhances the efficiency of each search operation; however, it is essential to note that this choice also results in increased costs associated with compaction and index rebuilding.
Pre-filtering metadata search
Metadata filtering is an important feature for many people. This feature allows you to only look for vectors from specific dates, from specific authors, or with specific attribute values. When designing a vector search application, you can put the metadata filtering either before or after the vector search functionality.
Before conducting a vector search, Milvus generates a bitmask on the metadata. This pre-filtering operation is linear in time. Milvus reviews the data once and checks whether or not the metadata matches the provided filter expression. Pre-filtering the metadata diminishes the volume of data subjected to vector search, which makes the vector search operation more efficient.
In the upcoming release of Milvus 2.4, we will support the inverted index with tantivy, and the prefiltering speed will be dramatically increased.
Summary
Milvus adopts a distributed system architecture comprising four layers: access, coordination, worker, and storage. Given the diverse use cases of vector databases, an adaptable and evolving infrastructure is essential. Milvus models its data ingestion component in line with this requirement as a pub/sub (publish-subscribe) system.
Modeling data ingestion as a pub/sub-service gives us flexibility by allowing a decoupled service paradigm and helps with data consistency. The “publishing” service marks each piece of data with a timestamp as part of the consistency functionality.
When it comes to the three concerns (querying, data ingestion, and indexing) in a vector database, Milvus separates them all. Each of the three operations has its dedicated node. You can spin up and down the nodes independently, allowing Milvus to scale with the amount of data you have and the usage pattern.
Ensuring data consistency is one of the most challenging tasks as the amount of data you have scales. Milvus addresses this challenge through the use of “shards.” Data coming in gets hashed and then split into a shard based on its hash. Milvus has a tunable consistency with four levels to choose from to trade off how quickly your search responds and how quickly data is replicated across the many instances of the database.
Writing data at scale uses multiple shards. Reading data at scale uses segments. Indexes are built on individual segments. Each segment can now be searched in parallel at query time, massively reducing search time for large amounts of data.
When searching for data, you will likely want to be able to filter it in some way. Milvus implements metadata filtering as a pre-filtering operation. It then applies a bitmask to the dataset during vector search and skips any vectors that don’t fit. This approach can significantly reduce search time if many vectors are filtered out.
Milvus’ unique architecture provides many benefits, especially horizontal scaling. It is meticulously crafted as a cloud-native vector database for swift horizontal scaling while maintaining optimal performance. The deliberately decoupled architecture design makes it easy to evolve Milvus over time and allows for flexibility. This adaptability proves crucial given the rising prominence of vector databases and the expanding array of use cases they cater to.

Keep Reading

Vector Lakebase: End the AI Data Silo
Learn how Vector Lakebase unifies vector search, data lakes, and AI data operations so teams can serve RAG and agents without copy-and-sync pipelines.

Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Notion solved vector search scaling in two years. The next bottleneck — offline context engineering, unified data, and the real-time/offline gap — is harder.

Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens
Learn how vector-based code retrieval cuts Claude Code token consumption by 40%. Open-source solution with easy MCP integration. Try claude-context today.