




GLiNER: Generalist Model for Named Entity Recognition Using Bidirectional Transformer
Named Entity Recognition (NER) is an important Natural Language Processing (NLP) task that identifies and classifies entities like names, locations, and organizations in text. This enables structured information extraction for various applications. NER can also handle tasks like building knowledge graphs, searching for information, and analyzing content.
Traditional NER models are good at identifying predefined entities. In contrast, Large Language Models (LLMs) can handle more complex, varied entities. However, LLMs are often resource-intensive, posing challenges for practical deployment. Existing fine-tuned open-source LLMs for named entity recognition (NER), like InstructUIE, UniNER, and GoLLIE, are effective but face challenges such as large size, slow token generation, and limited parallel entity extraction. To address these issues, researchers developed GLiNER, a compact and efficient NER model designed to improve efficiency, scalability, and multilingual performance while maintaining accuracy.
GLiNER is an open-source NER model using a bidirectional transformer encoder. It allows for parallel entity extraction and addresses the limitations of both traditional and LLM-based NER approaches. In zero-shot evaluations across various NER benchmarks, including those in multiple languages, it outperforms both ChatGPT and fine-tuned LLMs like UniNER. Even the smallest version of GLiNER surpasses large models like InstructUIE in zero-shot settings.
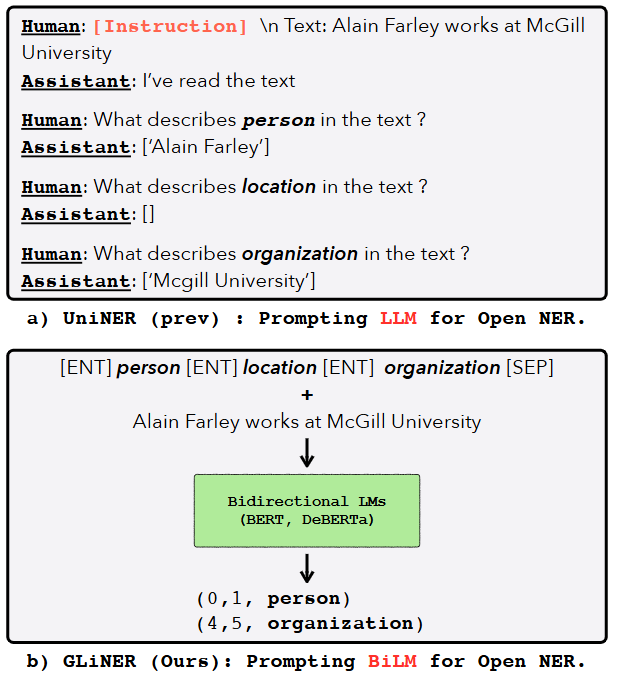 Figure: BiLM for open NER
Figure: BiLM for open NER
Figure: BiLM for open NER | Source
This blog will discuss GLiNER, its approach to NER, and its impact on the NLP domain. Further details can be found in the paper GLiNER.
Named Entity Recognition Overview
Named Entity Recognition (NER) is a fundamental task in Natural Language Processing (NLP) that identifies and classifies named entities within a text. These entities represent real-world objects like people, organizations, locations, dates, etc.
Key Components of NER
Entity Detection: Locating the boundaries of the named entities in text (e.g., identifying "Albert Einstein" as a span of interest).
Entity Classification: Assigning the correct label to each detected entity (e.g., labeling "Albert Einstein" as a Person).
Understanding the Architecture and Functionality of GLiNER
GLiNER uses bidirectional language models (BiLMs) like BERT and DeBERTa. These models are known for capturing rich contextual representations from text. The key concept behind GLiNER is to frame the NER task as a matching problem where entity type embeddings are compared to textual span representations in a shared latent space. This contrasts with traditional approaches that treat NER as a generation task.
GLiNER consists of three main components:
Pretrained Textual Encoder: The foundation of GLiNER is a pre-trained BiLM, such as DeBERTa, which serves as the textual encoder. The BiLM processes the input sequence, capturing contextual relationships between words and generating contextualized representations (embeddings) for each token.
Span Representation Module: This component is responsible for computing a representation for each possible span (a contiguous sequence of words) within the input text. The span representation is derived by combining the BiLM’s outputs for the start and end tokens of each span. These embeddings are optimized to align closely with the representations of relevant entity types.
Entity Representation Module: This component generates embeddings for each entity type the model aims to extract. Special tokens representing entity types are passed through the BiLM, and their outputs are refined using a feedforward network. These entity embeddings are then compared with span embeddings to determine matches.
 Figure: GLiNER architecture
Figure: GLiNER architecture
Figure: GLiNER architecture | Source
Here is how GLiNER works.
Input Formatting
GLiNER receives as input both the text from which entities are to be extracted and a list of potential entity types. These elements are combined into a single, unified sequence. Special tokens, including [ENT] and [SEP], play an important role in this sequence:
The
[ENT]token precedes each entity type in the list.The
[SEP]token acts as a separator between the entity type list and the input text.Both
[ENT]and[SEP]tokens are randomly initialized at the beginning of the training process.
 Figure: Example input format
Figure: Example input format
Figure: Example input format | Source
Token Representation with BiLMs
A pre-trained BiLM then processes the unified input sequence. The BiLM analyzes the entire sequence, understands the relationships between all tokens, and outputs contextualized vector representations for each token.
- The output for entity type tokens (those associated with
[ENT]) is represented as p.
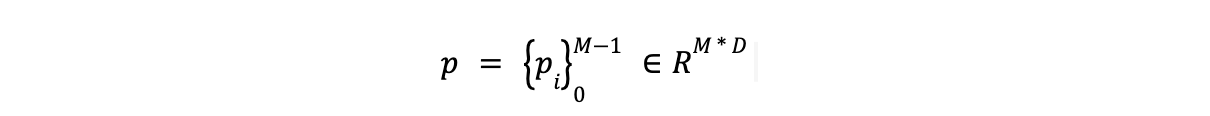
- The output for each word in the input text is represented as h.
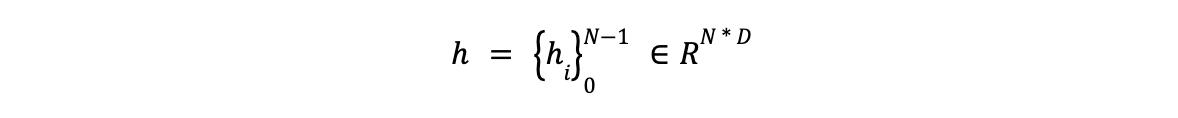
- For words broken down into subwords during tokenization, GLiNER uses the representation of the first subword, a common practice in NER.
Generating Entity and Span Embeddings
GLiNER aims to encode both entity types and text spans into a unified latent space where they can be effectively compared. This includes the following:
- Entity Representation Refinement: The initial representation of entity types (p) is refined using a two-layer feedforward network (FFN). This results in a new representation, denoted as q, which maps entity types into the latent space.
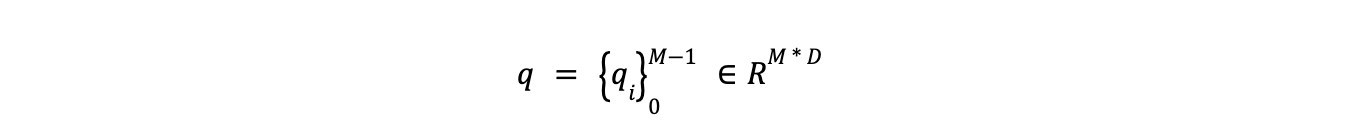
- Span Representation Calculation: A span is a sequence of consecutive words within the input text. GLiNER computes an embedding for each possible span using another two-layer FFN. This FFN operates on the concatenated representations of the start and end tokens of the span. This process allows GLiNER to capture the meaning of a span as a whole.
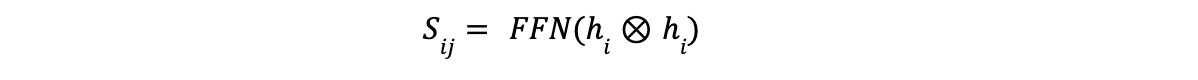
Matching Entity Types to Spans
Having encoded both entity types and spans into the same latent space, GLiNER determines the likelihood of a span belonging to a specific entity type by computing a matching score between their corresponding embeddings. The matching score is calculated using the dot product of the span embedding Sij and the entity embedding qt, followed by a sigmoid activation function. The resulting score (i, j, t) can be interpreted as the probability of the span (i, j) being of type t.
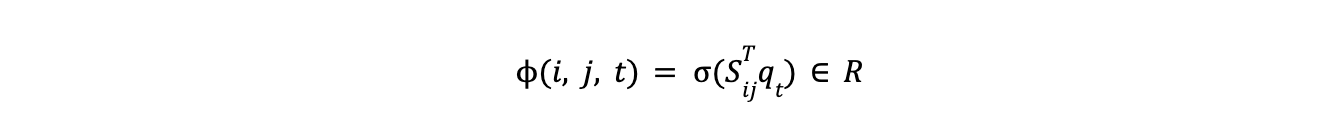
During training, using Binary Cross-Entropy Loss, the model maximizes matching scores for correct (positive) span-entity pairs and minimizes them for incorrect (negative) pairs.
Positive pairs are those where the span is actually labeled with the entity type in the training data.
Negative pairs are generated by randomly sampling entities from other examples within the same batch. This helps the model effectively discriminate between true and false entity assignments.
The training loss for an individual example is defined as:
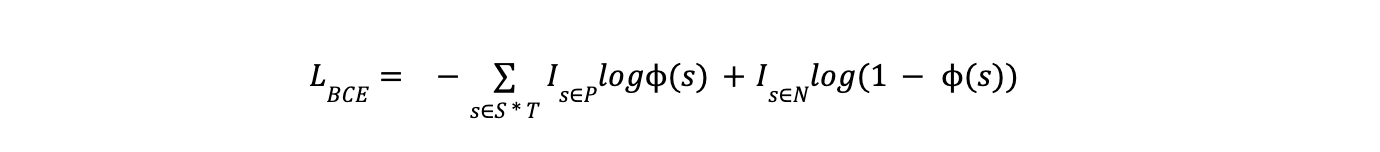 The training loss for an individual example
The training loss for an individual example
Decoding with Greedy Span Selection
GLiNER uses a greedy span selection algorithm to extract the most probable entities from the input text in the decoding phase. This algorithm prioritizes non-overlapping spans with the highest matching scores. It supports two modes of NER:
Flat NER: This mode selects only non-overlapping spans, prioritizing those with the highest scores.
Nested NER: This mode allows the selection of nested spans (spans fully contained within other entities) while avoiding partial overlaps.
This greedy approach ensures that GLiNER adheres to task-specific constraints while efficiently extracting relevant entities.
GLiNER's Experimental and Hyperparameter Settings
A carefully designed experimental setup and robust hyperparameter configuration were implemented to evaluate GLiNER’s effectiveness. The model is trained on the Pile-NER dataset, a collection of 44,889 passages with 240,000 entity spans and 13,000 unique entity types. This dataset was derived from the Pile corpus, with 50,000 texts sampled and annotated using ChatGPT. The annotations were generated without predefined type constraints, enabling the dataset to capture diverse entities.
 Prompting ChatGPT for entity extraction
Prompting ChatGPT for entity extraction
Figure: Prompting ChatGPT for entity extraction | Source
GLiNER employs the deBERTa-v3 model as its backbone due to its proven empirical strength. The model incorporates non-pretrained layers with a dimensional width of 768 and applies a dropout rate of 0.4 to mitigate overfitting.
The training process continues for a maximum of 30,000 steps, starting with a 10% warmup phase followed by a decay phase governed by a cosine scheduler. Negative entity types are randomly sampled from other examples in the same batch during training to improve the model's ability to handle cases where certain entity types are absent.
Several regularization strategies are implemented to improve the model's robustness and prevent overfitting. These strategies include:
Shuffling the entity order: This helps the model identify entities irrespective of their position within the input.
Randomly dropping entities: This forces the model to handle instances where information is missing or incomplete.
A constraint is imposed on the number of entity types processed per sentence to manage computational complexity during training. This limit is set to 25.
Analyzing the Performance of GLiNER
Once trained, the GLiNER's performance was tested on different NER benchmarks, and the factors contributing to its effectiveness were analyzed.
Zero-Shot Performance on English Datasets
GLiNER was evaluated in a zero-shot setting, meaning it was trained on the Pile-NER dataset and then directly tested on unseen datasets without further fine-tuning.
OOD NER Benchmark
The OOD (Out-of-Domain) NER Benchmark, consisting of seven diverse NER datasets, was used to assess GLiNER's ability to generalize to different domains. GLiNER, in all its size variations (small, medium, and large), exhibited impressive performance, outperforming models like ChatGPT, Vicuna, and even the much larger InstructUIE.
Notably, the medium-sized GLiNER achieved results comparable to the 13B UniNER model despite being 140 times smaller. The largest GLiNER model consistently outperformed its competitors, including GoLLIE (the best-performing LLM) and USM.
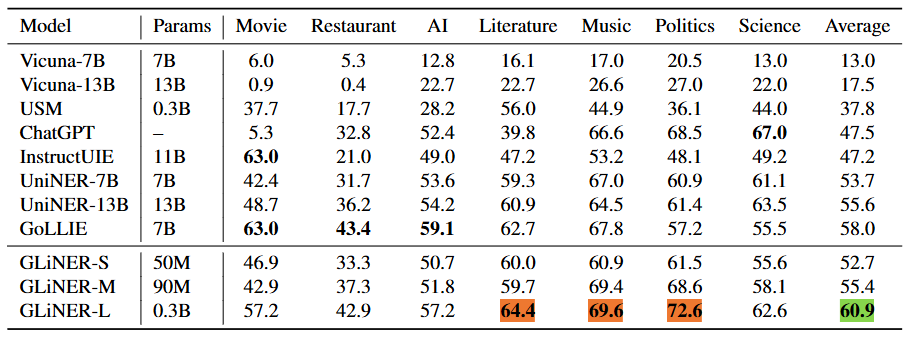 Figure: Zero-Shot scores on Out-of-Domain NER benchmark
Figure: Zero-Shot scores on Out-of-Domain NER benchmark
Figure: Zero-Shot scores on Out-of-Domain NER benchmark | Source
20 NER Benchmark
GLiNER was further evaluated on a benchmark of 20 NER datasets spanning various domains. It outperformed both ChatGPT and UniNER on most of these datasets, demonstrating its robustness and adaptability across different domains. However, it underperformed compared to UniNER on tweet-based NER datasets, highlighting a potential area for improvement in handling informal and noisy text.
 Zero-shot performance on 20 NER datasets
Zero-shot performance on 20 NER datasets
Zero-shot performance on 20 NER datasets | Source
Zero-Shot Multilingual Evaluation
To assess GLiNER's generalizability to unseen languages, it was evaluated on the Multiconer dataset, which contains data in 11 languages. Two variants of GLiNER were used:
One with an English DeBERTa backbone (GLiNER-En).
One with a multilingual DeBERTa backbone (GLiNER-Multi).
GLiNER-Multi performed remarkably well, surpassing ChatGPT in most languages. It
demonstrated cross-lingual transfer capabilities even though it was not trained in those languages. It even performed slightly better in Spanish than in English.
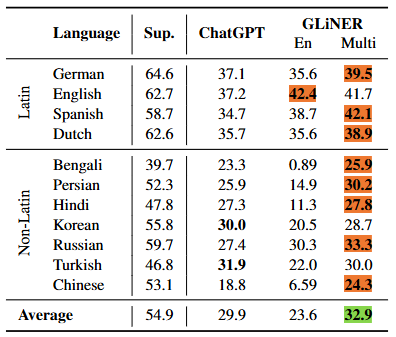 Zero-Shot scores on different languages
Zero-Shot scores on different languages
Zero-Shot scores on different languages | Source
In-Domain Supervised Fine-tuning
GLiNER was also fine-tuned on the 20 NER datasets to compare its performance against LLMs in a supervised setting. Its two variants were tested, one initialized with weights from the zero-shot model (pretrained on Pile-NER) and one trained from scratch. The pretrained variant consistently outperformed the non-pretrained variant, showcasing the benefits of pretraining on a diverse dataset.
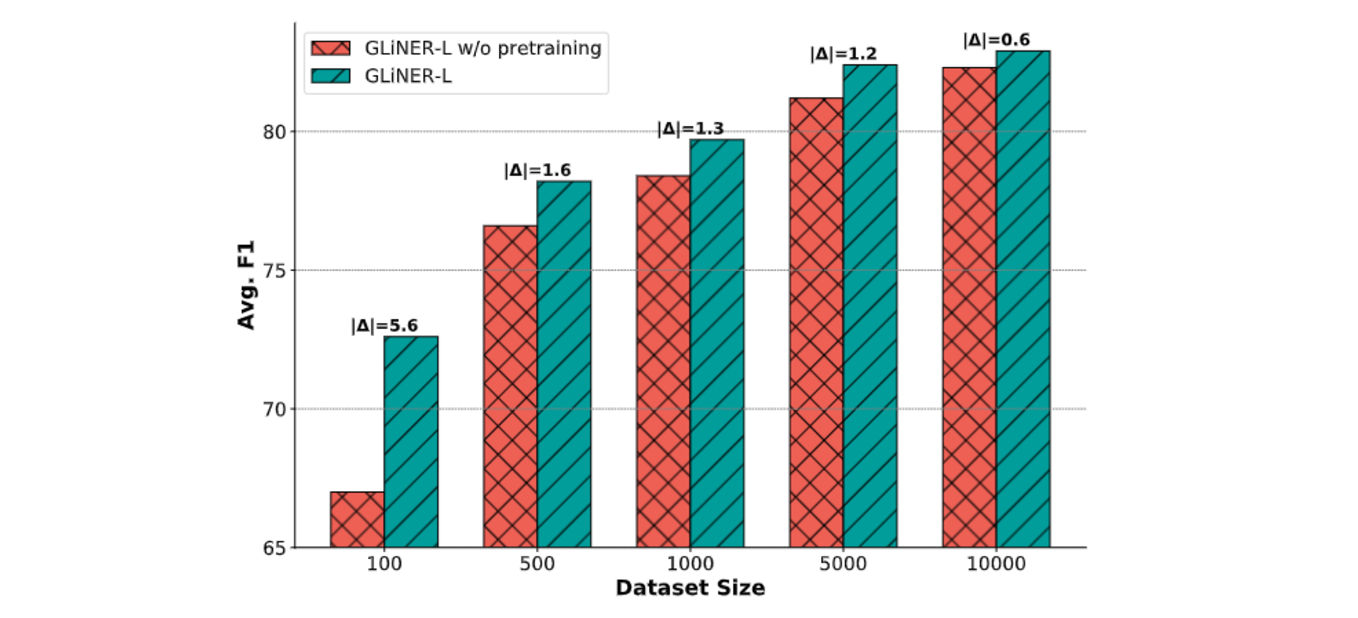 Supervised performance across different dataset sizes
Supervised performance across different dataset sizes
Supervised performance across different dataset sizes | Source
The pretrained GLiNER also outperformed the much larger InstructUIE, highlighting the efficiency of GLiNER's architecture. While it fell short compared to UniNER, GLiNER still achieved the highest scores on 7 out of 20 datasets.
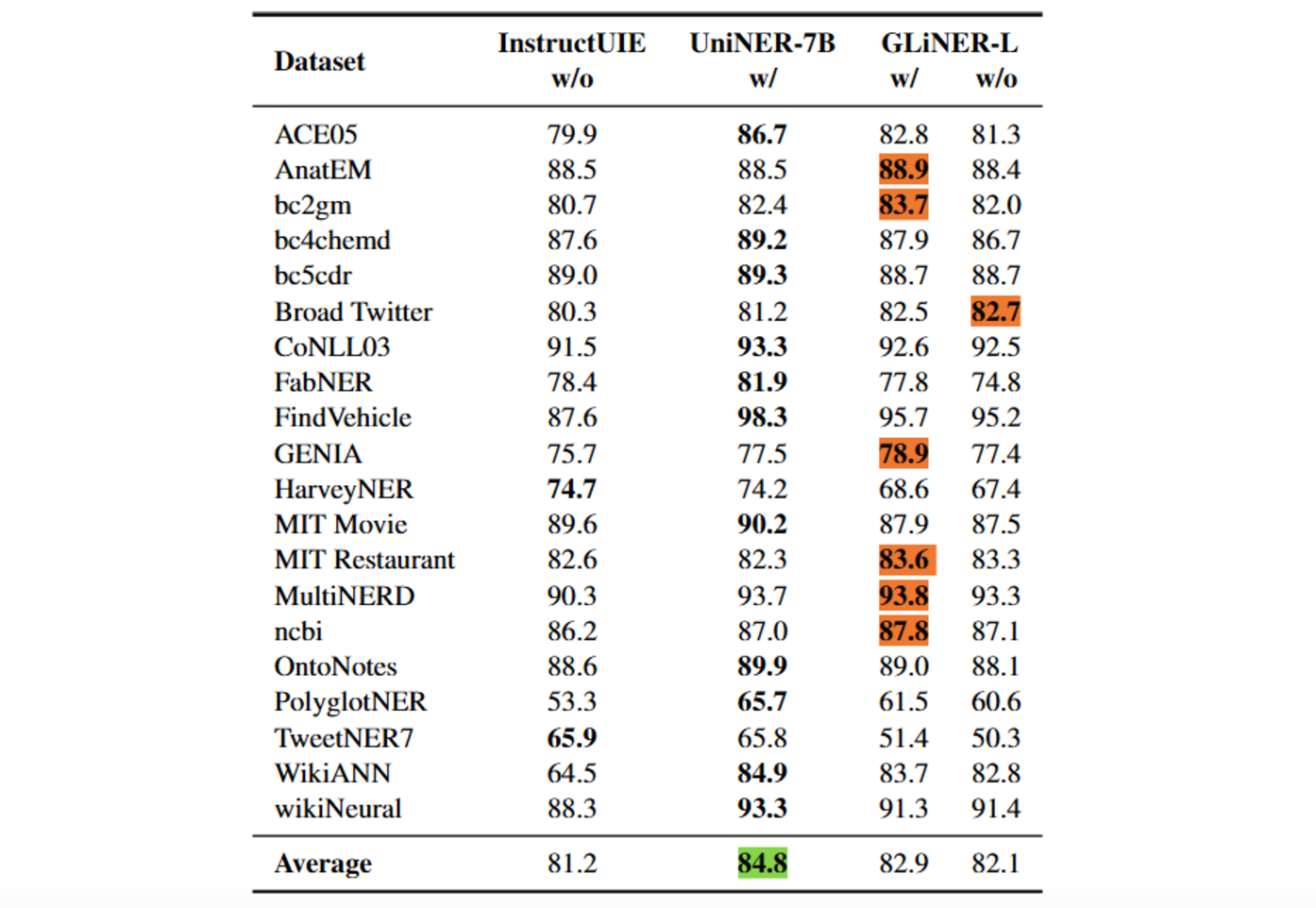 Figure: In-domain supervised finetuning
Figure: In-domain supervised finetuning
Figure: In-domain supervised finetuning | Source
w/ abbreviation stands for "with" and signifies that the GLiNER model was first trained on the Pile-NER dataset before fine-tuning on the 20 NER datasets.
w/o abbreviation stands for "without" and indicates that the GLiNER model was not pre-trained on the Pile-NER dataset.
Varied Architectural Choices and Training Strategies
Several architectural and training strategies were explored to optimize GLiNER’s performance and ensure adaptability across diverse scenarios.
Evaluating Different Backbones
GLiNER was further investigated using different BiLM backbones to see how they affect its performance. Various models, such as BERT, RoBERTa, ALBERT, and ELECTRA, were tested, with DeBERTa-v3 consistently showing the best performance. However, all backbones showed strong results compared to existing models. This suggested that GLiNER's architecture is effective across different BiLMs.
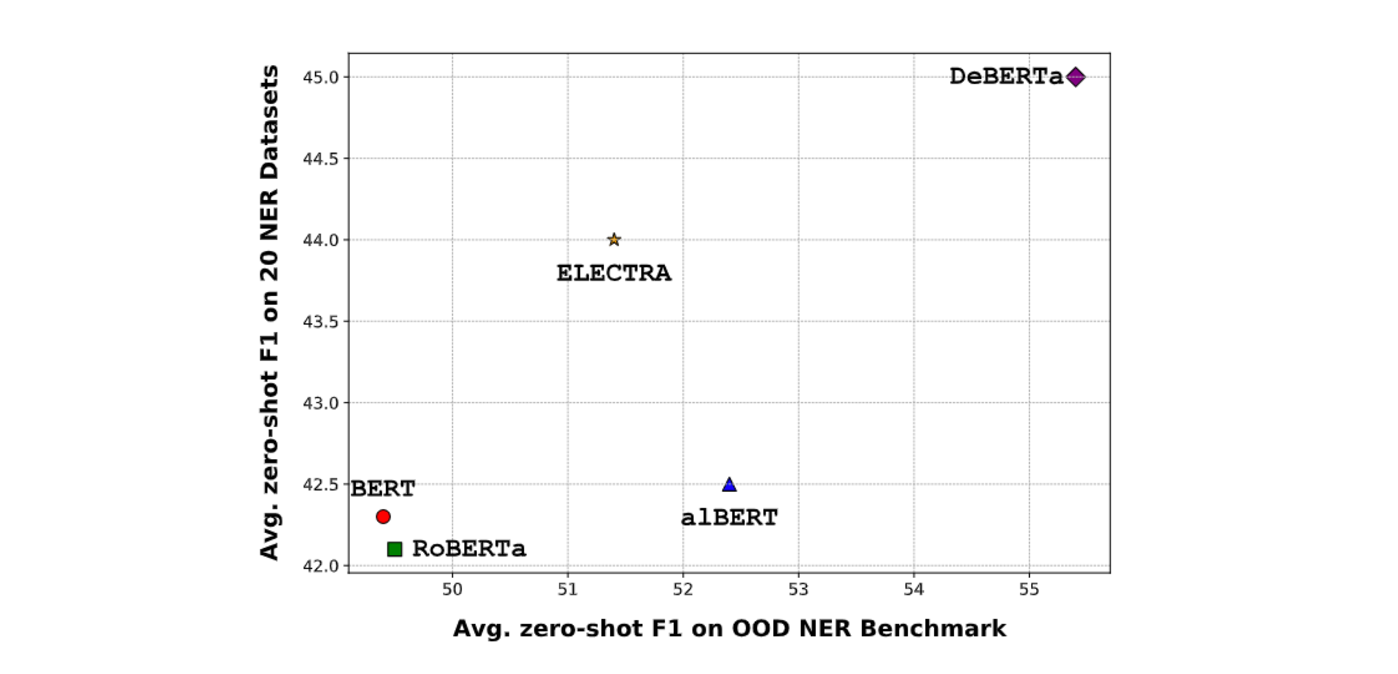 Figure: Zero-shot performance for different backbones
Figure: Zero-shot performance for different backbones
Figure: Zero-shot performance for different backbones | Source
Assessing the Impact of Negative Entity Sampling
Negative entity sampling is introduced during training to recognize that real-world data often lacks certain entity types. The model's performance is then evaluated using different negative sampling ratios (0%, 50%, and 75%), and a 50% ratio provides the best balance between precision and recall. Training with only positive entities leads to more false positives (lower precision), while a high negative sampling ratio makes the model overly cautious, resulting in missed entities (lower recall).
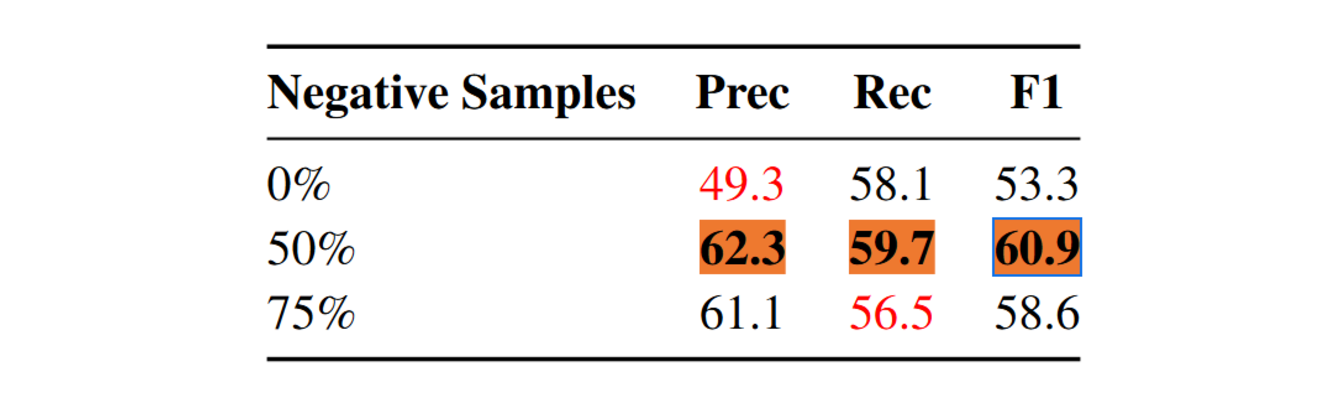 Figure: Effect of negative entity types sampling
Figure: Effect of negative entity types sampling
Figure: Effect of negative entity types sampling | Source
Evaluating the Benefits of Random Entity Type Dropping
Randomly dropping entity-type prompts during training enhances a model's robustness and adaptability to varying numbers of entities in real-world scenarios. This technique results in an average improvement of 1.4 points in out-of-domain evaluation.
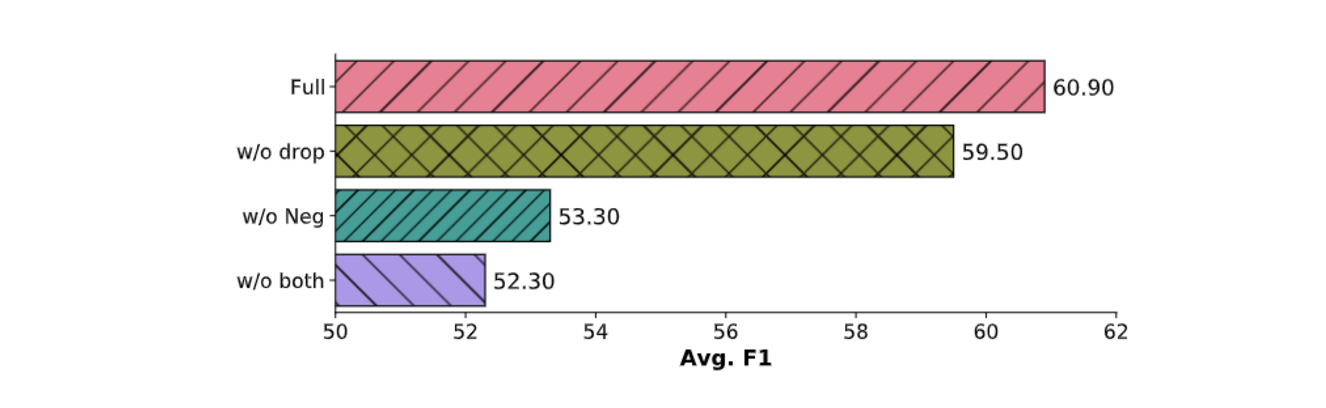 Figure: Randomly dropping entity types
Figure: Randomly dropping entity types
Figure: Randomly dropping entity types | Source
Implications of GLiNER's Development
The development of GLiNER has significant implications for the field of Named Entity Recognition (NER):
Resource Efficiency for NER: GLiNER advances NER by achieving strong performance with smaller model sizes than large LLMs. This efficiency is beneficial in resource-limited environments, making NER more accessible for various applications. GLiNER uses BiLMs effectively without the computational overhead of LLMs by framing NER as a matching task between entity-type embeddings and textual span representations in a latent space.
Zero-Shot Generalization Across Domains and Languages: GLiNER performs exceptionally well in zero-shot settings, achieving state-of-the-art results on NER benchmarks without task-specific fine-tuning. Its ability to generalize across various domains and languages makes it a promising solution for scenarios with limited labeled data.
Improved Performance with Pretraining: Pretraining on the Pile-NER dataset before fine-tuning for in-domain tasks leads to notable performance improvements. This is especially true when the amount of supervised data is limited. The gain is most significant with smaller datasets. This suggests that pretraining facilitates effective knowledge transfer, enhancing the model's ability to generalize and adapt to new domains and entity types.
Future Research Directions
Several avenues of research can be explored to further enhance GLiNER's capabilities:
Exploring Alternative Architectures: While GLiNER's current architecture is effective, there’s room for improvement by experimenting with different BiLM (Bidirectional Language Models) variants or introducing novel span representation techniques. Such innovations could lead to additional performance gains and enable GLiNER to tackle more complex tasks with greater efficiency.
Handling Noisy and Informal Text: Although GLiNER performs well in many contexts, its ability to handle noisy, informal text needs improvement. Social media content often includes slang, abbreviations, and non-standard grammar, which pose unique challenges. Future work could focus on refining GLiNER to better capture these nuances and improve its robustness in processing such unstructured text.
Incorporating External Knowledge: Integrating external knowledge sources, such as knowledge graphs or domain-specific gazetteers, could enhance GLiNER’s accuracy in entity disambiguation. By embedding these resources into the model's architecture, researchers could develop more precise and context-aware representations of named entities, improving performance.
Fine-Tuning for Domain-Specific Use Cases: While GLiNER’s zero-shot performance is impressive, there’s potential for further refinement through domain-specific fine-tuning. Areas like biomedical text mining or legal document analysis could benefit from this approach. This makes GLiNER more adaptable to specialized fields where entity recognition needs to capture intricate and technical language patterns.
Conclusion
GLiNER represents a significant advancement in NER. Through its compact bidirectional transformer models, it combines efficiency, adaptability, and accessibility. It achieves strong zero-shot and multilingual performance without the computational cost of larger models, outperforming alternatives like ChatGPT and UniNER.
Future research could explore alternative architectures, improve robustness in noisy and informal text, integrate external knowledge for better entity disambiguation, fine-tuning for domain-specific datasets, and enhance performance in low-resource languages through cross-lingual transfer. These directions hold great potential to further improve GLiNER’s effectiveness across diverse NER tasks.
Further Resources

Keep Reading

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Notion solved vector search scaling in two years. The next bottleneck — offline context engineering, unified data, and the real-time/offline gap — is harder.

What Exactly Are AI Agents? Why OpenAI and LangChain Are Fighting Over Their Definition?
AI agents are software programs powered by AI that can perceive their environment, make decisions, and take actions to achieve a goal—often autonomously.