




Semantic Search vs. Lexical Search vs. Full-text Search
In the digital world we live in today, search engines have become integral to our lives, helping us access information quickly and easily. At the heart of these search engines are information retrieval algorithms, which determine how information is retrieved.
Several information retrieval algorithms are available, ranging from traditional methods such as full-text and lexical search to more advanced techniques like semantic search. Each of these algorithms has its own advantages and disadvantages; therefore, it is crucial for us to choose the best information retrieval algorithm that suits our use case.
This article will discuss these information retrieval algorithms, specifically focusing on lexical, full-text, and semantic searches. Let’s start with the simplest one: lexical search.
Lexical Search
Lexical search, also known as keywords search, refers to a search algorithm based on the word-level analysis of text (hence the name). This information retrieval algorithm matches query terms exactly as they appear in the text. For example, if our search query is “run,” the algorithm will return all instances of the term “run” in a document.
Lexical search is the most basic information retrieval algorithm available, as it returns only those terms in a document that contain an exact match to our query. This makes lexical search particularly useful when precision and specificity are required, such as finding documents or records containing a specific string or word.

Figure: Illustration of simple lexical search.
However, the simplicity of lexical search also leads to several drawbacks. First, it does not tolerate typos in our query. For example, if we mistakenly enter “ron” instead of “run,” we will not get the results we are looking for. Second, lexical search does not account for synonyms, stemming, or lemmatization. Consequently, searching for “run” will not match similar words in different forms, such as “ran” or “running.”
Additionally, the lexical search may not be the best option if we are looking for the most relevant records based on our query. The documents or records that contain our query term lack any notion of order or ranking, making it difficult to assess the relevance of the results returned by lexical search.
As you can see, lexical search definitely has significant limitations when considering the demands of most information retrieval use cases. Moreover, users often require more flexibility regarding the terms included in the results, which lexical search also lacks. This is where full-text search comes into play.
Full-Text Search
A full-text search operates similarly to a lexical search, seeking to find records containing the terms in our query. However, full-text search offers broader and more advanced capabilities than lexical search, addressing the issues associated with lexical search.
Implementing full-text search often incorporates popular Natural Language Processing (NLP) techniques such as stemming and lemmatization. This means that when we search for the term “run,” all documents or records with similar words in different forms, such as “ran” or “running,” will also be included in the results.
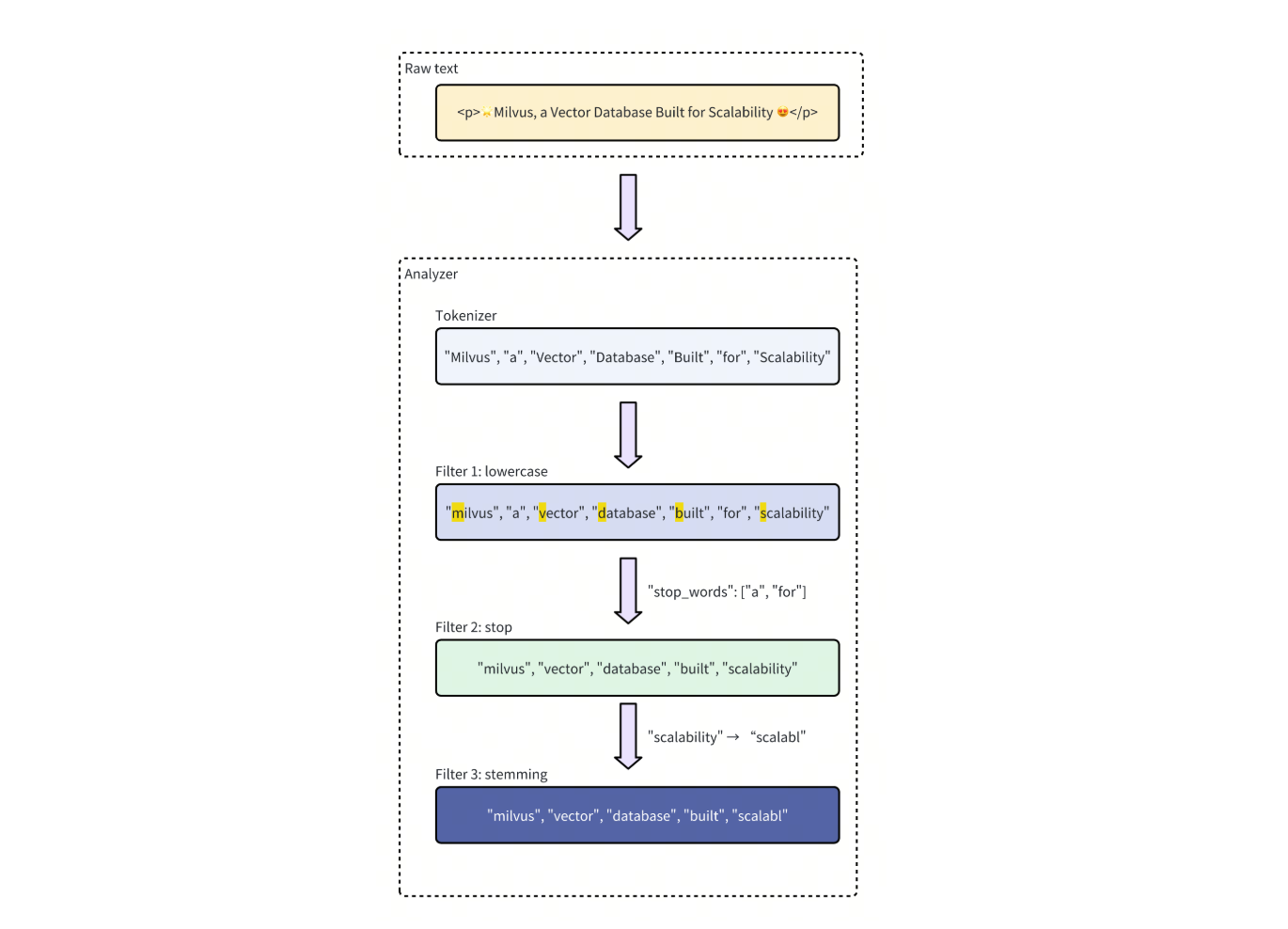
Figure: Illustration of full-text search advancement compared to traditional lexical search.
To sort search results based on relevance, we can also implement algorithms like TF-IDF and BM25. Let’s talk about these two algorithms further.
Fundamentals of TF-IDF and BM25
Term Frequency-Inverse Document Frequency (TF-IDF) uses a straightforward statistical method to determine the relevance of a document or record for a given term or query. It consists of two components:
Term Frequency (TF): This calculates the number of occurrences of the query term in a document. Therefore, the more frequently the query term appears in a document, the higher the TF score for that document.
Inverse Document Frequency (IDF): This calculates the proportion of documents in the entire collection that contain the query term.

The main goal of the IDF component is to penalize common and less meaningful terms such as “a,” “an,” “the,” and “and,” which tend to appear in almost all documents. For example, if our query term is “mix and match,” we want documents that are most relevant to contain many instances of “mix” and “match” rather than numerous occurrences of “and”. Finally, the final TF-IDF score for a document is obtained by multiplying the TF and IDF scores.
One main disadvantage of TF-IDF is that it does not consider the length of the document when calculating relevance. In reality, longer documents are more likely to contain our query term more frequently. For example, if our query term appears 10 times in a 1,000-word document (Document A), while it only appears 5 times in a 50-word document (Document B), we might argue that Document B could be more relevant despite having fewer occurrences.
BM25 addresses this limitation of TF-IDF by introducing additional terms and expanding the TF-IDF equation to account for document length.
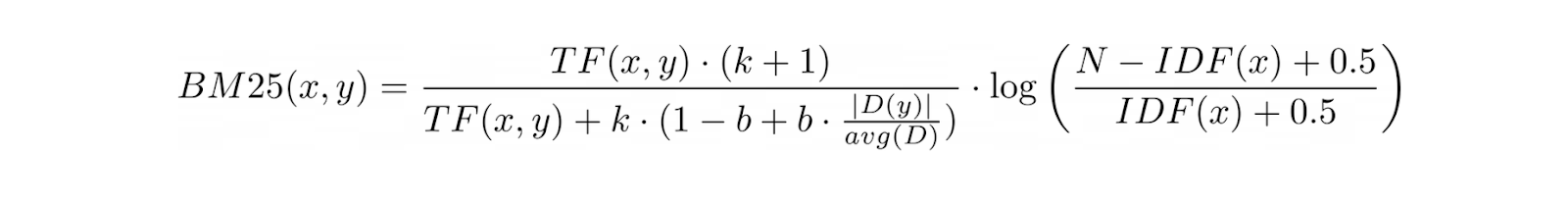
By doing so, BM25 eliminates bias toward longer documents when measuring the relevance of a document for any given query.
The Concept of Sparse Embedding
Both TF-IDF and BM25 can be represented as sparse embeddings. A sparse embedding is an n-dimensional vector, where the dimensionality depends on the number of unique terms in our corpus or collection of documents.
For example, let’s say we have 10 documents containing a total of 10,000 unique words. Each document would then be transformed into a 10,000-dimensional vector, with each dimension representing the importance of a particular term in that document.
![]()
Figure: Illustration of the document to sparse embedding transformation.
Since the dimensionality of the vector is determined by the number of unique terms in the corpus, we often end up with vectors of huge dimensionality. Additionally, because a document typically contains only a small fraction of the available terms, a vast majority of the elements of these vectors will be zero, as you can see in the image above. This is why such vectors are commonly referred to as sparse embeddings.
Now that all documents are represented as embeddings, we can calculate the similarity between any two embeddings using common algorithms like cosine similarity or Euclidean distance. The intuition is that two documents with similar terms of high importance will have high similarity.
Despite the advantages of sparse embeddings in full-text search, there is one significant drawback: they do not account for the semantic meaning of query terms. For instance, if our query is “Apple device,” documents that contain many instances of “apple” (the fruit) may rank higher than technology documents that are more relevant to our query but do not contain the term “Apple” (the company).
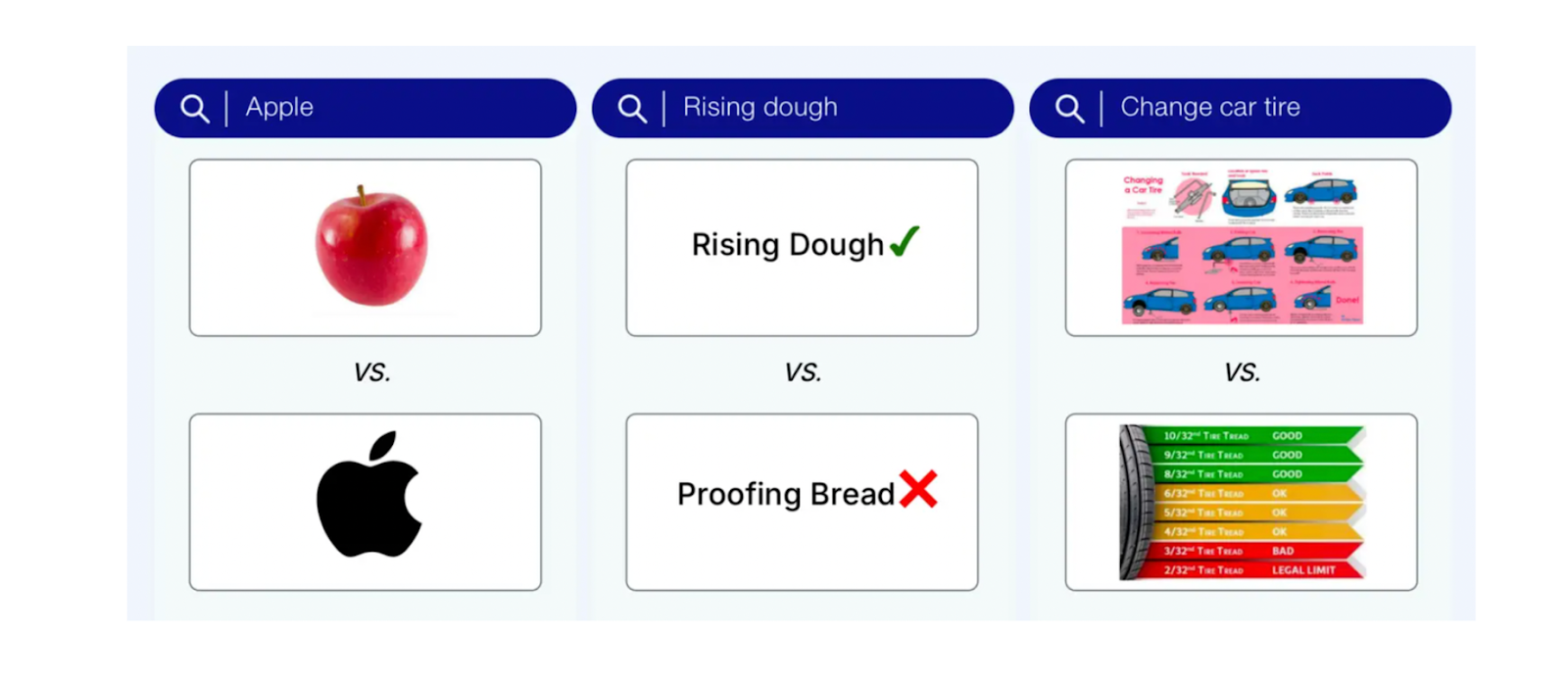
Figure: Example queries that require semantic understanding and context.
When including results with similar semantic meanings is a requirement for our use case, full-text search may not be the best information retrieval algorithm to use. This is where semantic search comes into play.
Semantic Search
Semantic search is a useful approach when we want search results that take semantic meaning into account. Using the example mentioned in the previous section, when we type in a query like “Apple device”, we are not actually looking for documents or records that contain the word “apple”. Instead, we seek documents that discuss technologies, preferably Apple devices. In this case, full-text search would yield unwanted results, making semantic search the better option.
The Concept of Dense Embedding
Semantic search works by utilizing sophisticated AI models to transform our documents and query terms into embeddings. However, the embeddings produced by these models, often called dense embeddngs, differ from the sparse embeddings discussed previously.
In dense embeddings, the values in each vector dimension are rarely exactly zero, and the dimensionality itself depends on the model used. However, the dimensionality of dense embeddings is much lower than sparse embeddings.
![]()
Figure: Illustration of the document to dense embedding transformation.
Dense embeddings contain semantically rich information about the content they represent. Therefore, to determine how semantically similar two dense embeddings are, we can simply use popular similarity algorithms like cosine similarity or Euclidean distance.
The Role of Vector Databases in Semantic Search
In real-world information retrieval applications, we are likely to deal with millions or even billions of dense embeddings. Therefore, it is impractical to store all of these embeddings in our computer's memory; and we need a database system capable of storing them efficiently.
A vector database is a system that enables us to store vast amounts of dense embeddings efficiently by employing advanced indexing methods such as approximate nearest neighbors (ANN) and hierarchical navigable small world (HNSW). It also provides functionality for performing vector search operations to find the most semantically relevant documents for our query using popular similarity algorithms like cosine similarity and Euclidean distance.
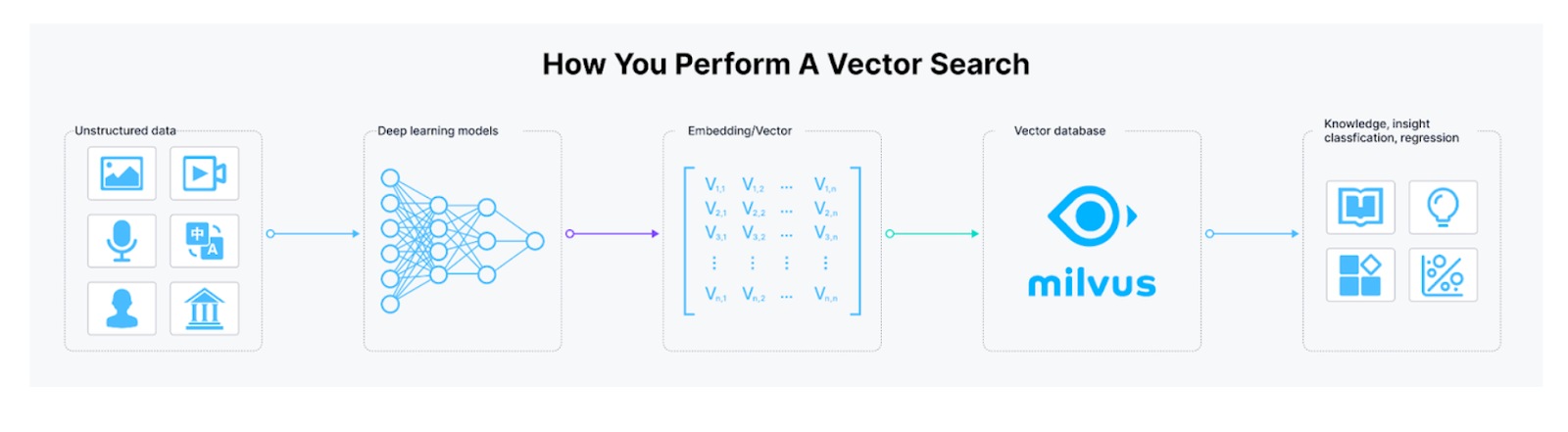
Figure: Workflow of performing a vector search operation.
Moreover, popular vector databases like Milvus offer advanced features such as hybrid search, which allows us to perform vector searches by combining the strengths of both dense and sparse embeddings. For a deeper explanation of how sparse and dense vectors actually work, see this guide.
Lexical Search vs. Full-Text Search vs. Semantic Search
Now that we have a detailed understanding of lexical, full-text, and semantic search, let’s compare their matching mechanisms, complexity, example use cases, and performance.
| Semantic Search | Lexical Search | Full-Text Search | |
|---|---|---|---|
| Mechanism | Context and intent | Exact match | Keyword and relevance |
| Complexity | High | Low | Medium |
| Performance | Slower | Fast | Moderate |
| Use Cases | NLP-based systems, Retrieval augmented generation (RAG), LLM-powered applications, recommendation systems | Simple search | Document-heavy systems |
Table: Lexical Search vs. Full-Text Search vs. Semantic Search
In terms of the matching mechanism, lexical search is the simplest of the three, as it matches exact terms in the query. Full-text search improves lexical search by scanning entire documents for occurrences of the query terms, allowing us to sort results based on their relevance to the query. Meanwhile, semantic search matches query terms to a collection of documents based on semantic meaning and context, utilizing advanced deep learning models and NLP techniques.
Regarding complexity, lexical search is also the simplest option. Full-text search is slightly more complex due to the introduction of algorithms like TF-IDF or BM25, which transform texts into sparse embeddings. Semantic search is the most complex because it employs advanced deep-learning models to convert texts into dense embeddings.
For example, lexical search is a great choice when exact matching is critical, such as locating a variable name in code searches or finding a product ID in a document. Full-text search is suitable for applications when finding documents with special terms or concepts in the query, such as searching academic databases or legal repositories. Semantic search is ideal for use cases where understanding context is the priority, such as customer support chatbots, recommendation systems, and content discovery.
In terms of performance, semantic and full-text searches are relatively slower due to their complexity, while lexical search is faster because of its straightforward approach.
The Concept of Hybrid Search
Considering the diversity and pros and cons of each information retrieval algorithm, choosing the best one is not easy and might not really meet all your requirements. In practical use cases, we may even need to employ more than one algorithm to meet various needs within our application, as effective information retrieval systems should provide both semantic understanding and exact keyword matching for users. Hybrid search is a concept designed to address this challenge.
Hybrid search allows us to combine two different search algorithms, most commonly the combination of semantic search with either full-text or lexical search. However, implementing a hybrid search presents challenges due to the different systems involved. Specifically, we need a vector database like Milvus to store dense embeddings and perform semantic searches and a search engine like Elasticsearch to perform full-text searches.
However, using two separate systems to accommodate different retrieval algorithms introduces new complexities. It means dealing with separate configurations and maintenance tasks, which can lead to integration issues down the line. This approach may also double our costs by requiring data storage in two infrastructures.
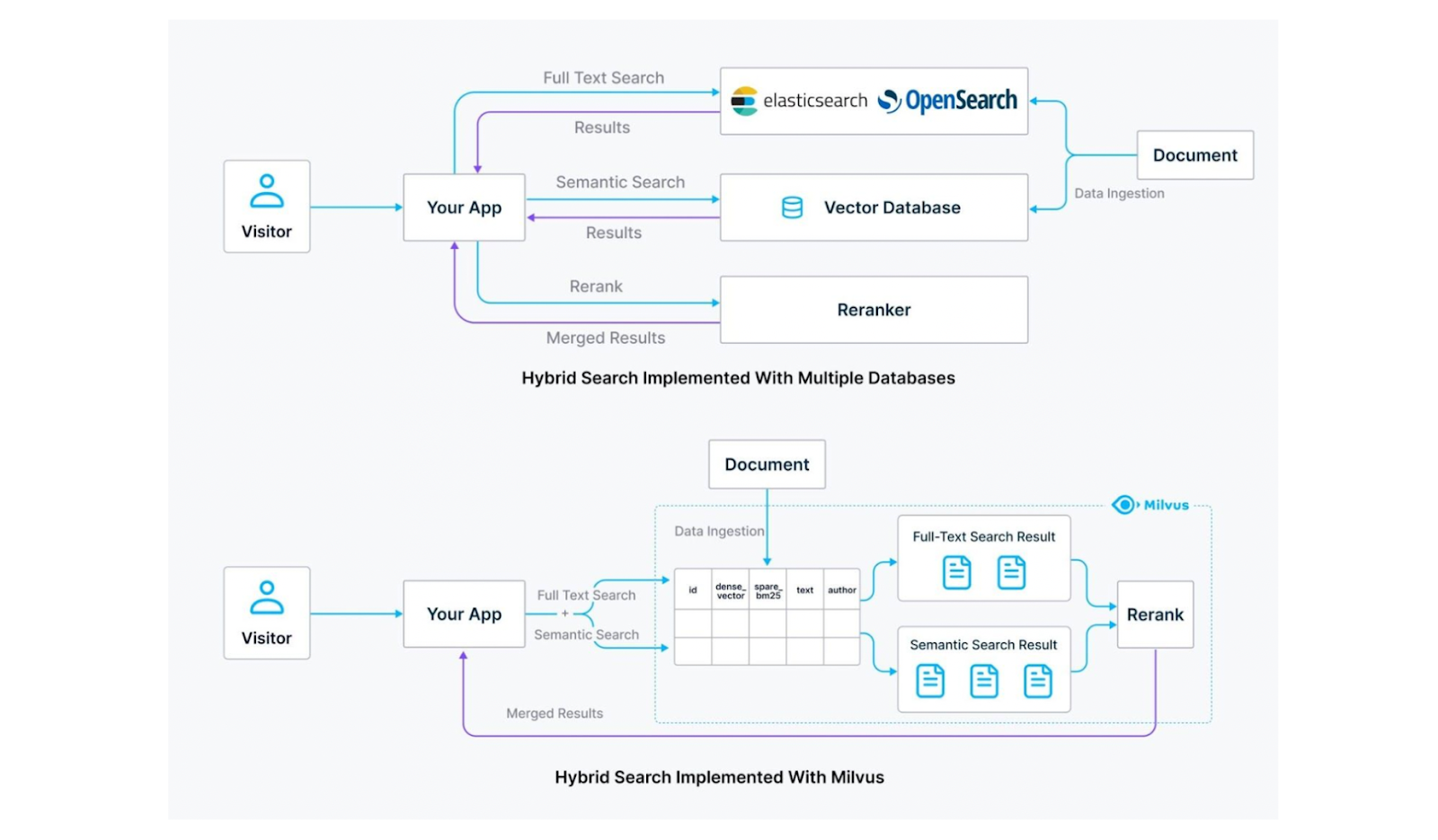
Figure: Elasticsearch vs Milvus on Hybrid search.
A better solution is to use a unified system capable of facilitating both semantic and full-text/lexical searches. Milvus is a perfect open-source vector database for this case, as it supports the implementation of hybrid semantic and full-text searches. In addition, Milvus also supports metadata filtering search, range search, and reranking to get the most accurate results.
With Milvus, we can store all necessary data for various types of searches, including dense embeddings, sparse embeddings, and metadata. This allows us to perform hybrid searches—such as semantic and full-text or lexical searches. Thanks to its advanced indexing methods, Milvus is also highly optimized for vector search operations, significantly speeding up the information retrieval process compared to Elasticsearch.
Conclusion
The choice of information retrieval algorithm plays an important role in determining the efficiency and relevance of search results in our application. Lexical search offers exact term matching, which makes it ideal for scenarios where exact matches are essential. Full-text search introduces advancements to lexical search by incorporating techniques like stemming, fuzzy matching, and relevancy ranking with algorithms like TF-IDF and BM25, making it suitable for document-heavy applications. Meanwhile, semantic search provides capabilities for understanding context and intent, making it highly useful for complex NLP-based systems like customer chatbots.
However, as the demand for flexible and efficient search systems grows, hybrid search becomes a practical solution to apply the strengths of multiple retrieval algorithms. By integrating both semantic and full-text/lexical search, Milvus offers flexibility and improved user experience. Check out this tutorial to try our semantic and full-text searches with Milvus.
Related Resources
Keep Reading

Why and How to Migrate from Self-Hosted Milvus to Zilliz Cloud
A simple, step-by-step guide to migrating from Milvus to Zilliz Cloud. Learn both endpoint and backup methods for a smooth, scalable vector database migration.

Legal Document Analysis: Harnessing Zilliz Cloud's Semantic Search and RAG for Legal Insights
Enhance legal document analysis with Zilliz Cloud’s Semantic Search and RAG. Improve accuracy, efficiency, and scalability for contracts, case law, and compliance.

Building RAG Pipelines for Real-Time Data with Cloudera and Milvus
explore how Cloudera can be integrated with Milvus to effectively implement some of the key functionalities of RAG pipelines.