




ナレッジグラフ(KG)とは何か?
ナレッジグラフは、情報をエンティティとその関係のネットワークとして表現するデータ構造である。
インターネットは、時間とともに増え続ける情報の海である。この事実が、データの複雑さと量の増大を引き起こしている。データを管理し、解釈し、そこから意味を導き出すことは、ますます困難になってきている。ナレッジグラフ(KG)は、この課題に対処するために、データを接続し文脈化する構造化されたアプローチを提供する。KGは、実体とその関係をグラフィカルなフォーマットで表現するセマンティック・ネットワークであり、異なるデータ間のつながりに焦点を当てている。
ナレッジグラフ」という言葉は1980年代にはすでに登場していたが、セマンティックネットワーク、オントロジー、セマンティックウェブ、リンクデータから発展した。しかし、2012年にGoogleが検索結果を改善するためのKnowledge Graph projectを発表したことで人気を博し、その後、Amazon、Facebook、Microsoftなど他の企業もナレッジグラフを発表した。
それ以来、ナレッジグラフは、検索エンジンや推薦システムから人工知能やデータ分析に至るまで、様々な分野で重要なものとなっている。ナレッジグラフは、関係性や文脈をより深く理解し、システムにより多くの情報に基づいた意思決定を可能にする。
この記事では、ナレッジグラフについて、その構成要素、構築方法、さまざまな応用例などを詳しく紹介する。
ナレッジグラフ(KG)とは?
**ナレッジグラフは、情報をエンティティとその関係のネットワークとして表現するデータ構造である。
知識グラフには3つの重要な構成要素がある:**ノード(実体)、エッジ(関係)、ラベルです。
ノードは、人、会社、コンピュータなど、現実世界のあらゆる実体を表すことができる。エッジは、企業と個人の間の顧客関係や2台のコンピュータ間のネットワーク接続など、2つのノード間の関心のある関係をキャプチャします。グラフのわかりやすさを向上させるために、ラベル は、ノードとエッジに関する追加情報を提供します。これらは、関係の性質を指定するエンティティの属性です。
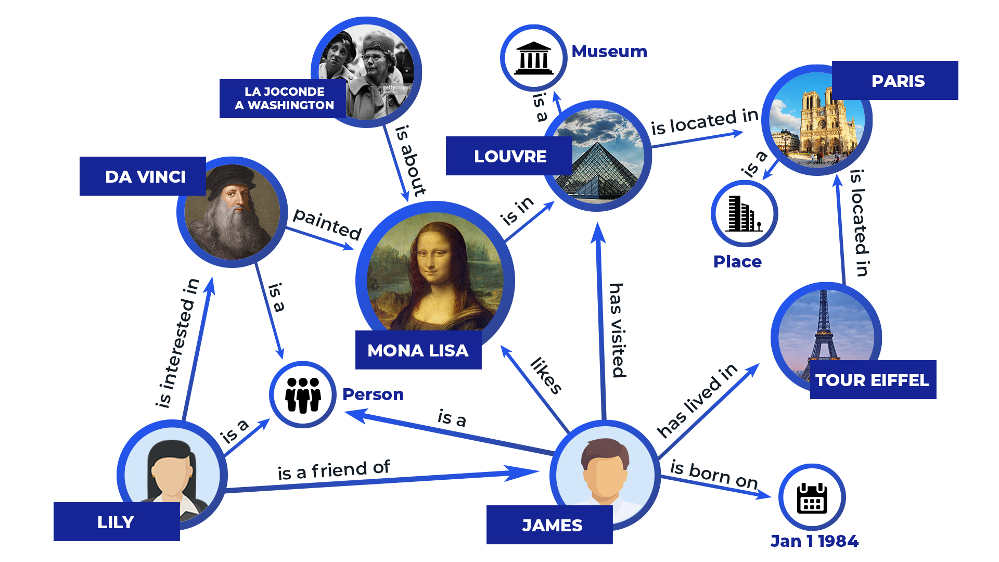 図1 知識グラフの図解.png
図1 知識グラフの図解.png
図1: 知識グラフ図解 (画像ソース)
ナレッジグラフが従来のデータベースのテーブルのような他のデータ構造と異なるのは、エンティティ間の複雑な相互リンク関係を扱えることである。ナレッジグラフは通常、Neo4jやArangoDBのようなグラフデータベースに格納される。
ナレッジグラフは、より動的で相互接続された方法でデータを格納する。次の図は、データを表とグラフでどのように表現できるかを示している。グラフの利点の1つは、スキーマの柔軟性を提供し、定義済みの "テーブル・ヘッダー" による制限を取り除くことである。その結果、グラフはデータストアを混乱させることなく進化させることができる。
図2 表とグラフで表現されるデータ.png](https://assets.zilliz.com/Figure_2_Data_represented_in_the_table_and_graph_bf534e074d.png)
図2:表とグラフで表現されるデータ
知識グラフの核となる特徴
ナレッジグラフは、エンティティ間の複雑な相互接続とその関係を捉えるために設計された構造化データセットである。ナレッジグラフにはいくつかの重要な特徴があり、さまざまな用途に利用できる。
1.エンティティの相互リンク記述
2.形式的意味論とオントロジー
3.複数のソースからのデータを統合する能力
4.拡張性と柔軟性
エンティティの相互リンク記述
知識グラフは孤立した事実を保存するだけではない。知識グラフは、相互にリンクされたエンティティの記述のコレクションを表します。知識グラフでは、各エンティティは人などのノードとして表現され、エッジは1つのエンティティを別のエンティティに結合する意味的なリンクを示します。これらの接続は、情報のネットワークを作成し、エンティティ間のコンテキストと関係の深い理解を提供します。
図3 グラフ表現の例.png](https://assets.zilliz.com/Figure_3_An_example_of_Graph_representation_Image_by_the_Author_5e54d43b2e.png)
図3 グラフ表現の一例(画像は筆者による)_。
形式的意味論とオントロジー
知識グラフの文脈では、形式的意味論とオントロジーは、明確な説明と一貫したデータ編成を可能にする重要な構成要素である。形式的セマンティクスとは、情報を表現し推論するために、明確に定義されたルールを使用することを指し、ナレッジグラフはこれに大きく依存している。つまり、あらかじめ定義された構造(オントロジー)を使用して、エンティティのタイプと関係を定義する。
オントロジーは通常、以下のような構成になっている:
クラス**は、"人"、"場所"、"イベント "など、知識グラフのエンティティのタイプを定義する。
プロパティ**は、エンティティの属性とエンティティ間の関係を記述します。例えば、"Person" クラスは、"Name"、"Age"、"Address" などのプロパティを持ちます。
インスタンス:*** ナレッジ・グラフの実際のデータ・ポイントは、特定のクラスを表します。
ナレッジグラフは、オントロジーを使用して一貫性のある構造的な方法でデータを整理し、分析を容易にすることができます。
複数のソースからのデータを統合する能力
多数のソースからのデータを統合することは複雑な場合がある。構造化データ(データベースのような)、半構造化データ(XMLファイルのような)、非構造化データ(テキストのような)をまとめると、混乱することがあります。ありがたいことに、ナレッジグラフは柔軟性が高く、これらの断片を1つの明確な画像に統合することに優れている。これは、人間の理解と認知を反映した形式で、実体と関係を表現できるからである。
例えば、ナレッジグラフは、映画データベース(構造化データ)と複数のウェブサイトからの映画レビュー(非構造化データ)および異なるソースからの評価(半構造化データ)を接続することができます。この統合により、各映画について、キャスト、監督、ジャンル、評価、人々の意見など、より包括的な分析と洞察が可能になる。
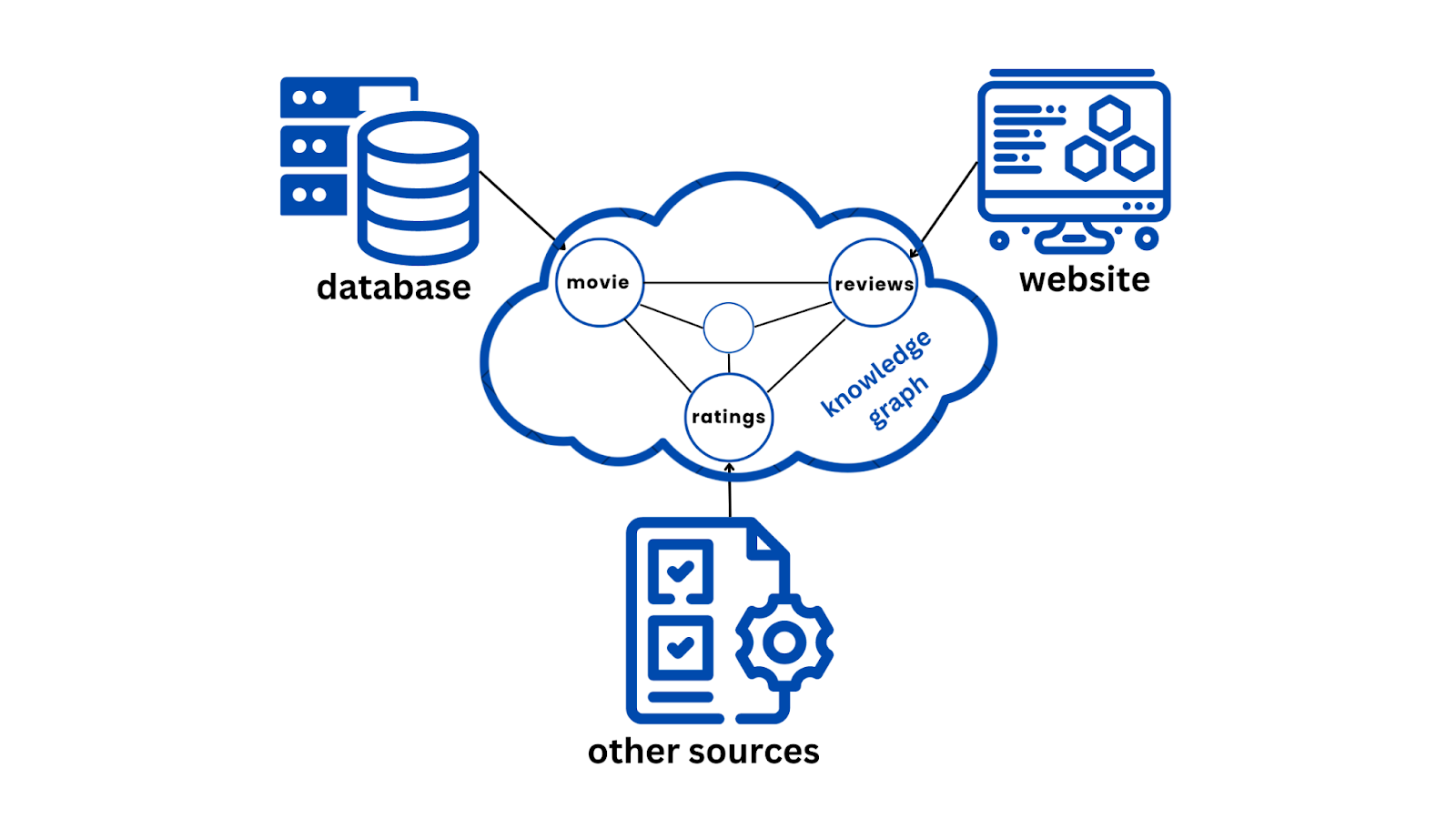 図4 複数のソースからKGへのデータ.png
図4 複数のソースからKGへのデータ.png
図4:複数のソースからKG_へのデータ
スケーラビリティと柔軟性
ナレッジグラフはスケーラブルで柔軟である。データセットの成長に伴い、より多くのエンティティ、リレーションシップ、クエリを効率的に管理することで、成長に対応できるように設計されています。
スケーラビリティは主に2つの方法で達成できる:
垂直方向のスケーラビリティ:** メモリの増設など、単一のシステムの容量を増やすことである。グラフを格納するデータベース・システムをアップグレードして、より多くのデータや複雑なクエリを処理できるようにする。
水平スケーラビリティ:*** これは、複数のシステムにデータを分散させることです。知識グラフを異なるマシンに分割し、それぞれがグラフの一部を処理することができる。
ナレッジグラフはグラフベースであるため、大量のデータを扱うために容易に拡張することができ、データの統合や変更を容易に行うことができます。
図5 縦と横のスケーラビリティ.png](https://assets.zilliz.com/Figure_5_Vertical_and_horizontal_scalability_f2e27e14d7.png)
図5:垂直方向と水平方向のスケーラビリティ
知識グラフ vs ベクトル埋め込み
知識グラフとベクトル埋め込みは、どちらも最新のデータシステムで使われているデータ表現ですが、基本的に異なる方法で動作します。
ナレッジグラフは、エンティティ(人、組織、概念など)をノードとし、これらのエンティティ間の関係をエッジとする構造化された表現です。これにより、さまざまな情報がどのように相互に関連付けられているかを視覚的かつ論理的にマッピングするグラフのような構造が作成されます。ナレッジグラフは、明確で解釈可能な関係や、明示的な接続に対する推論を必要とするシナリオに適しています。例えば、ナレッジグラフは、"アルバート・アインシュタイン "が "相対性理論 "と "開発された "という関係を通してつながっていることを示し、関連する概念の明確で理解しやすいマップを提供します。
一方、ベクトル埋め込みは、高次元空間におけるデータの数値表現であり、通常、単語、文、あるいは文書全体の意味的な意味を捉えるために使用される。各エンティティや情報の断片はベクトルに変換され、これらのベクトル間の距離は意味的な類似性を反映する。例えば、ベクトル空間では、"king "と "queen "という単語は近接しており、関連する意味を反映している。ベクトル埋め込みは、テキストや画像のような非構造化データを扱う際に特に有用で、知識グラフのように簡単に定義できない微妙で暗黙的な関係を捉えることが目的です。
ナレッジグラフは通常グラフデータベースに格納されるが、ベクトル埋め込みはMilvusやZilliz Cloud(Milvusのフルマネージド版)のようなベクトルデータベースに格納される。AI、特に大規模言語モデル(LLMs)の進歩により、ベクターデータベースとグラフデータベースは、強力な検索拡張世代(RAG)アプリケーションを構築するために、別々に、あるいは組み合わせて、LLMsと統合することができる。
知識グラフとベクトル埋め込みを活用して、より高度なRAGアプリケーションを作成する方法については、以下のリソースを参照してください:
RAGとは](https://zilliz.com/learn/Retrieval-Augmented-Generation)
WhyHowとMilvusを使用した知識グラフによるRAGの拡張](https://zilliz.com/blog/enhance-rag-with-knowledge-graphs#What-is-WhyHow-How-Does-It-Enhance-RAG-with-Knowledge-Graphs)
グラフRAGとは](https://zilliz.com/blog/graphrag-explained-enhance-rag-with-knowledge-graphs)
Neo4jとMilvusへのドキュメントの同時取り込み](https://neo4j.com/developer-blog/ingest-documents-neo4j-milvus/)
ベクトルデータベースとグラフデータベース:正しいソリューションの選択](https://zilliz.com/learn/vector-database-vs-graph-database)
ナレッジグラフをRAGに統合する方法については、こちらのビデオチュートリアルもご覧ください。
ナレッジグラフ構築の主な検討事項ナレッジグラフの構築は、知識の構造化された表現を作成するために、さまざまなソースからデータを収集、処理、統合する複雑なプロセスです。このプロセスにはいくつかの重要なステップがあります。
データソース
抽出技術
統合と融合
データソース
ナレッジグラフの基盤は、それを構成するデータである。データはさまざまなソースから取得でき、それぞれ構造や形式が異なります。堅牢なナレッジグラフを構築するには、これらの異なるデータソースを理解することが重要です。
構造化データ: ** 構造化データは、あらかじめ定義された形式に編成された情報であり、多くの場合、リレーショナル・データベースやスプレッドシートに格納されている。これは高度に組織化されており、異なる情報間の関係が明確である。
非構造化データ:** 非構造化データは、あらかじめ定義された構造を持たない。主にテキスト、画像、動画の形で見られる。テーブルやリレーショナルデータベースにきちんと収まらないため、このデータタイプを扱うのは難しい。
半構造化データ:**半構造化データは、構造化データと非構造化データの中間に位置する。構造化データの場合もあれば、非構造化データの場合もある。JSONファイルは半構造化データの良い例で、「Name」、「Price」、「Description」のようなキーで商品情報を格納しており、「Description」フィールドには自由形式のテキストが含まれています。
抽出テクニック
関連するデータソースを選択したら、次のステップはナレッジグラフに入力するために必要な情報を抽出することです。エンティティ(グラフのノード)とそれらの間の関係(エッジ)を識別するために、さまざまな技法を使用してこの情報を抽出することができます。
自然言語処理(NLP)技術**](https://zilliz.com/learn/top-10-nlp-techniques-every-data-scientist-should-know):テキストデータから情報を抽出する。これらの技法は、構造化されていないテキストを処理し、エンティティとそれらのエンティティ間の関係を識別することによって、知識グラフを構築する。
機械学習アプローチ:** 機械学習は、データからの情報抽出を自動化するためにも使用できる。機械学習アルゴリズムは、ラベル付けされたデータセットでモデルを学習することで、新しいデータのパターンと関係を発見することを学ぶことができる。
統合と融合
次のステップは、このデータを知識グラフに統合することである。このプロセスには、エンティティの解決やデータのクリーニングなど、さまざまな手法が含まれる。
エンティティ解決:*** エンティティ解決は、ナレッジグラフ内で重複するエンティティを見つけ、統合します。データが複数のソースから来ている場合、同じエンティティ(人や場所)が異なる方法で表現されていることがよくあります。確率的マッチング、ルールベースのマッチング、機械学習アプローチなどのエンティティ解決技術は、等価なエンティティを見つけ、リンクします。エンティティ解決は、同じエンティティへのすべての参照が知識グラフの単一のノードにリンクされることを保証します。
データのクリーニングと正規化:*** ナレッジグラフに統合する前に、データをクリーニングし、正規化することが重要である。データのクリーニングには、エラーの修正、重複の削除、情報の欠落や矛盾の処理が含まれる。文のセグメンテーション、音声タグ付け、名前付きエンティティ認識などの技術を使用して、テキスト・データのエラーを特定し、修正することができる。正規化では、データを知識グラフに統合しやすい標準形式に変換する。
##自然言語処理による知識グラフの構築
以下のセクションでは、文のセグメンテーション、係り受け解析、品詞タグ付け、エンティティ認識などのNLPテクニックを使って、テキストから知識グラフを構築する。本記事で使用したデータセットとコードはKaggleで公開されている。
依存関係のインポートとデータセットのロード
インポート re
import pandas as pd
インポート bs4
インポートリクエスト
インポート spacy
from spacy import ディスプレーシー
nlp = spacy.load('en_core_web_sm')
from spacy.matcher import Matcher
from spacy.tokens import Span
import networkx as nx
import matplotlib.pyplot as plt
from tqdm import tqdm
pd.set_option('display.max_colwidth', 200)
matplotlib インライン
# import wikipedia sentences
候補文 = pd.read_csv("../input/wiki-sentences/wiki_sentences_v2.csv")
候補センテンス.shape
文のセグメンテーション
知識グラフを構築する最初のステップは、テキスト文書を文に分割することである。次に、主語と目的語を正確に1つずつ持つ分割文だけをショートリスト化する。
doc = nlp("the drawdown process is governed by astm standard d823")
for tok in doc:
print(tok.text, "...", tok.dep_)
エンティティの抽出
文から 1 語のエンティティを抽出するのは簡単です。品詞(POS)タグを使用すると、このタスクを簡単に実行できます。エンティティは名詞と固有名詞になります。しかし、エンティティが複数の単語にまたがる場合、品詞タグは不十分である。文の係り受けツリーを解析する必要がある。知識グラフを作成する場合、ノードとそれらを接続するエッジが最も重要な要素である。
これらのノードは、ウィキペディアの文章に存在するエンティティになります。これらの項目を結びつける接続はエッジと呼ばれる。これらの要素を教師なし、つまり文の文法を用いて抽出する。
def get_entities(sent):
ent1 = ""
ent2 = ""
prv_tok_dep = "" # 文の前のトークンの依存タグ
prv_tok_text = "" # 文中の前のトークン
prefix = ""
修飾子 = ""
for tok in nlp(sent):
# もしトークンが句読点なら、次のトークンに進む
if tok.dep_ != "punct":
# トークンが複合語かどうかをチェックする
if tok.dep_ == "compound":
prefix = tok.text
# 前の単語も「複合語」だった場合、現在の単語をそれに加える
if prv_tok_dep == "compound":
プレフィックス = prv_tok_text + " + tok.text
# トークンが修飾語かどうかのチェック
if tok.dep_.endswith("mod") == True:
修飾子 = tok.text
# もし前の単語も「複合語」だった場合、現在の単語をそれに加える
if prv_tok_dep == "compound":
修飾子 = prv_tok_text + " "+ tok.text
if tok.dep_.find("subj") == True:
ent1 = modifier +" "+ prefix + " "+ tok.text
prefix = ""
修飾子 = ""
prv_tok_dep = ""
prv_tok_text = ""
if tok.dep_.find("obj") == True:
ent2 = modifier +" "+ prefix +" "+ tok.text
# 変数の更新
prv_tok_dep = tok.dep_
prv_tok_text = tok.text
ent1.strip(), ent2.strip()] を返す。
get_entities("映画には200件の特許があった")
entity_pairs = [].
for i in tqdm(candidate_sentences["sentence"]):
entity_pairs.append(get_entities(i))
entity_pairs[10:20]
**出力

図7: エンティティ抽出の出力(画像は筆者による)_。
ご覧のように、これらのエンティティ・ペアには、"she"、"we"、"it "などの代名詞がいくつか含まれています。代わりに、固有名詞や名詞が欲しいところです。get_entities()`関数を拡張して、代名詞を除外することができます。
関係の抽出
エンティティ抽出は仕事の半分を終えた。知識グラフを構築するには、ノード(エンティティ)を接続するエッジ(関係)が必要である。このエッジは、ノードのペア間の関係である。このような述語は、以下の関数を使って文章から抽出することができる。ここでは、SpaCyのルールベースのマッチングを使用した。
def get_relation(sent):
doc = nlp(sent)
# Matcher クラスのオブジェクト
matcher = Matcher(nlp.vocab)
#パターンを定義する
pattern = [{'DEP':'ROOT'}、
{'DEP':'prep','OP':"?"}、
{'DEP':'agent','OP':"?"}、
{'pos':'adj','op':"?"}].
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
k = len(matches) - 1
span = doc[matches[k][1]:matches[k][2]].
return(span.text)
get_relation("John completed the task")
relations = [get_relation(i) for i in tqdm(候補_文['文'])].
ナレッジグラフの作成
抽出されたエンティティ(主語と目的語のペア)と述語(エンティティ間の関係)を使って知識グラフを作成する。
エンティティと述語のデータ・フレームを作ろう:
# 主語を抽出する
ソース = [i[0] for i in entity_pairs]
# オブジェクトを抽出
target = [i[1] for i in entity_pairs] ``` # オブジェクトを抽出する。
kg_df = pd.DataFrame({'source':source, 'target':target, 'edge':relations})
次に、networkx ライブラリを使って、このデータフレームからネットワークを作成する。このネットワークでは、ノードはエンティティを示し、ノード間のエッジやリンクはそれらの関係を示している。
これは有向グラフであり、どのノードのペア間の接続も一方通行であることを意味する。関係は一方のノードから他方のノードに流れ、双方向ではない。
# データフレームから有向グラフを作る
G=nx.from_pandas_edgelist(kg_df, "source", "target"、
edge_attr=True, create_using=nx.MultiDiGraph())
ネットワークをプロットしてみよう。
plt.figure(figsize=(12,12))
pos = nx.spring_layout(G)
nx.draw(G, with_labels=True, node_color='skyblue', edge_cmap=plt.cm.Blues, pos = pos)
plt.show()
**出力
 図6 すべての関係を持つKG.png
図6 すべての関係を持つKG.png
図6: すべての関係を持つKG
上のグラフは、我々が持っているすべての関係を使って作成したものである。関係や述語が多すぎると、グラフを視覚化するのが難しくなる。
ですから、グラフを視覚化するためには、いくつかの重要な関係だけを使うのがベストです。では、関係をひとつずつ見ていこう。まず、"composed by "という関係から始めよう:
G=nx.from_pandas_edgelist(kg_df[kg_df['edge']=="composed by"], "source", "target"、
edge_attr=True, create_using=nx.MultiDiGraph())
plt.figure(figsize=(12,12))
pos = nx.spring_layout(G, k = 0.5) # kはノード間の距離を調節します。
nx.draw(G, with_labels=True, node_color='skyblue', node_size=1500, edge_cmap=plt.cm.Blues, pos = pos)
plt.show()
**出力
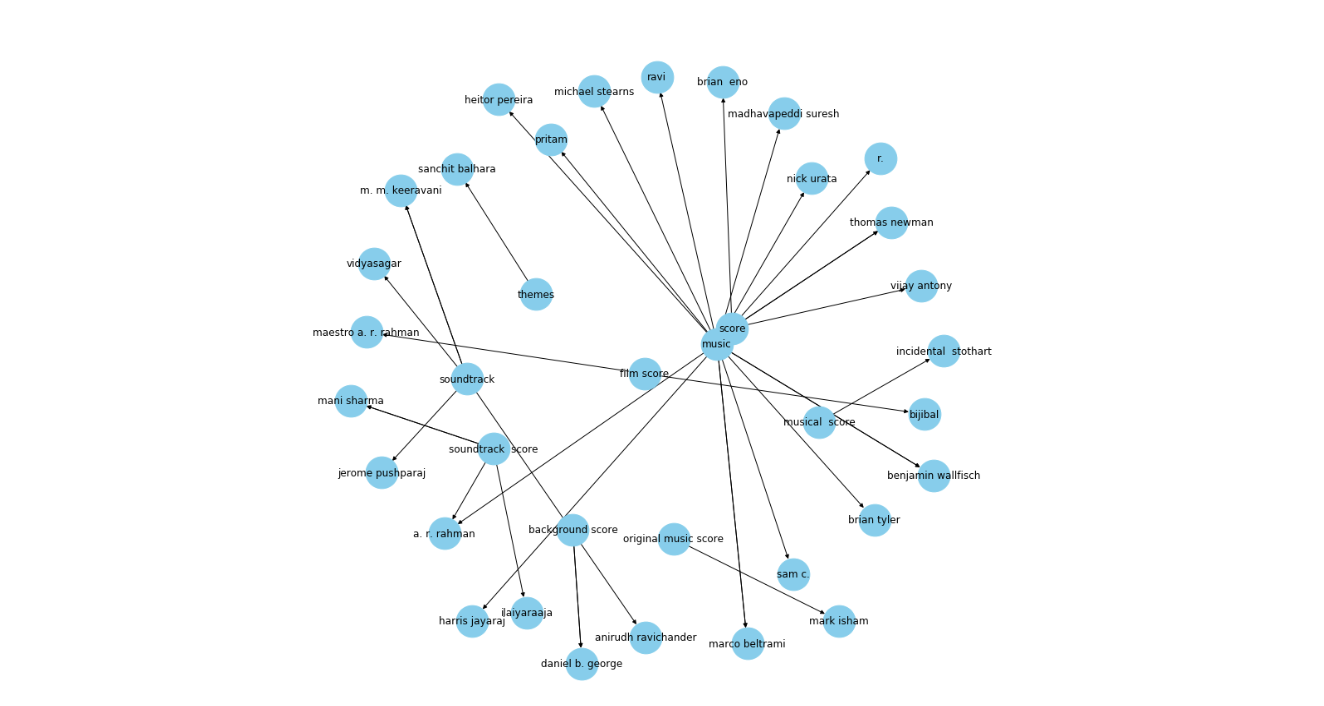 図7 関係が1つのKG.png
図7 関係が1つのKG.png
図7: 関係詞を1つ持つKG
出力は、よりすっきりとしたグラフを示す。ここで、矢印は作曲家を指している。例えば、Daniel b. Georgeは、上のグラフで、"background score "や "soundtrack "といったエンティティがつながっている。
もう少し関係を調べてみましょう。今度は、"written by "関係のグラフを可視化します:
G=nx.from_pandas_edgelist(kg_df[kg_df['edge']=="written by"], "source", "target"、
edge_attr=True, create_using=nx.MultiDiGraph())
plt.figure(figsize=(12,12))
pos = nx.spring_layout(G, k = 0.5)
nx.draw(G, with_labels=True, node_color='skyblue', node_size=1500, edge_cmap=plt.cm.Blues, pos = pos)
plt.show()
**出力
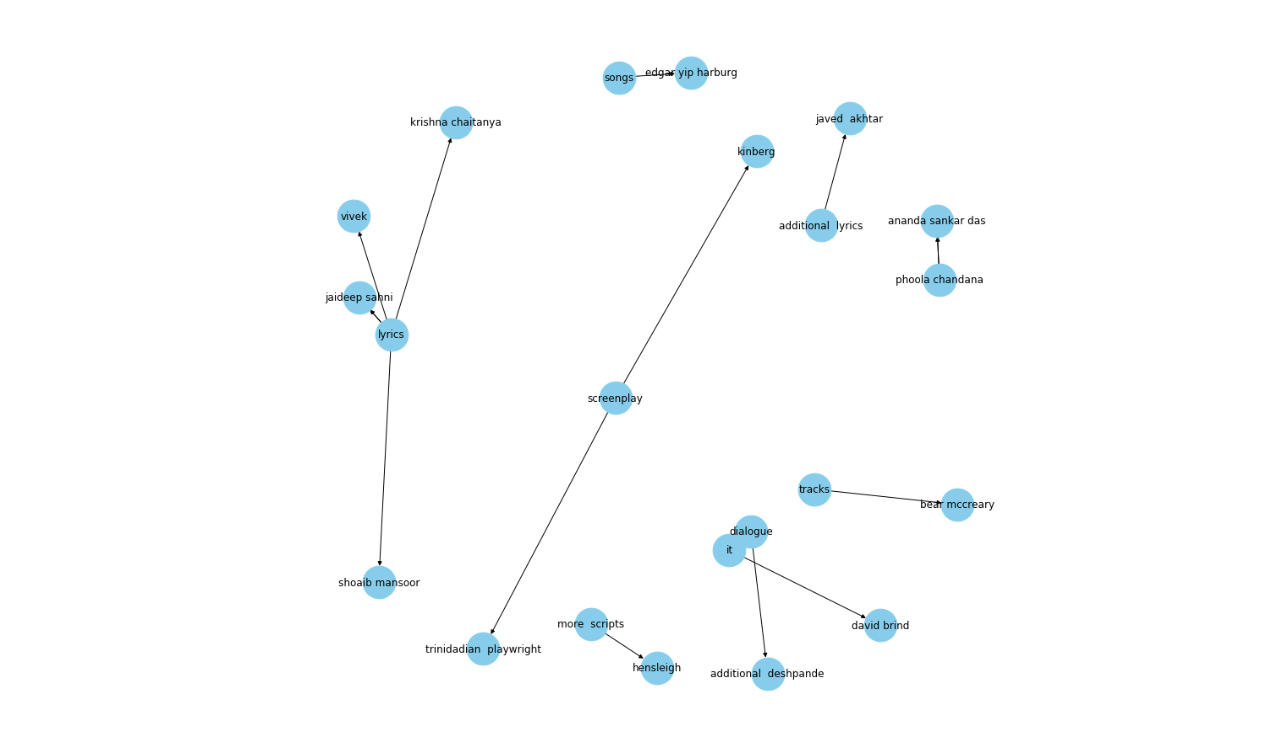 図8 関係が1つのKG.png
図8 関係が1つのKG.png
図8:KGが1つの関係
この知識グラフは卓越した洞察を提供し、有名な作詞家同士のつながりを見事に示している。
もう一つの重要な述語、すなわち「発売元」の知識グラフを見てみよう:
G=nx.from_pandas_edgelist(kg_df[kg_df['edge']=="released in"], "source", "target"、
edge_attr=True, create_using=nx.MultiDiGraph())
plt.figure(figsize=(12,12))
pos = nx.spring_layout(G, k = 0.5)
nx.draw(G, with_labels=True, node_color='skyblue', node_size=1500, edge_cmap=plt.cm.Blues, pos = pos)
plt.show()
**出力
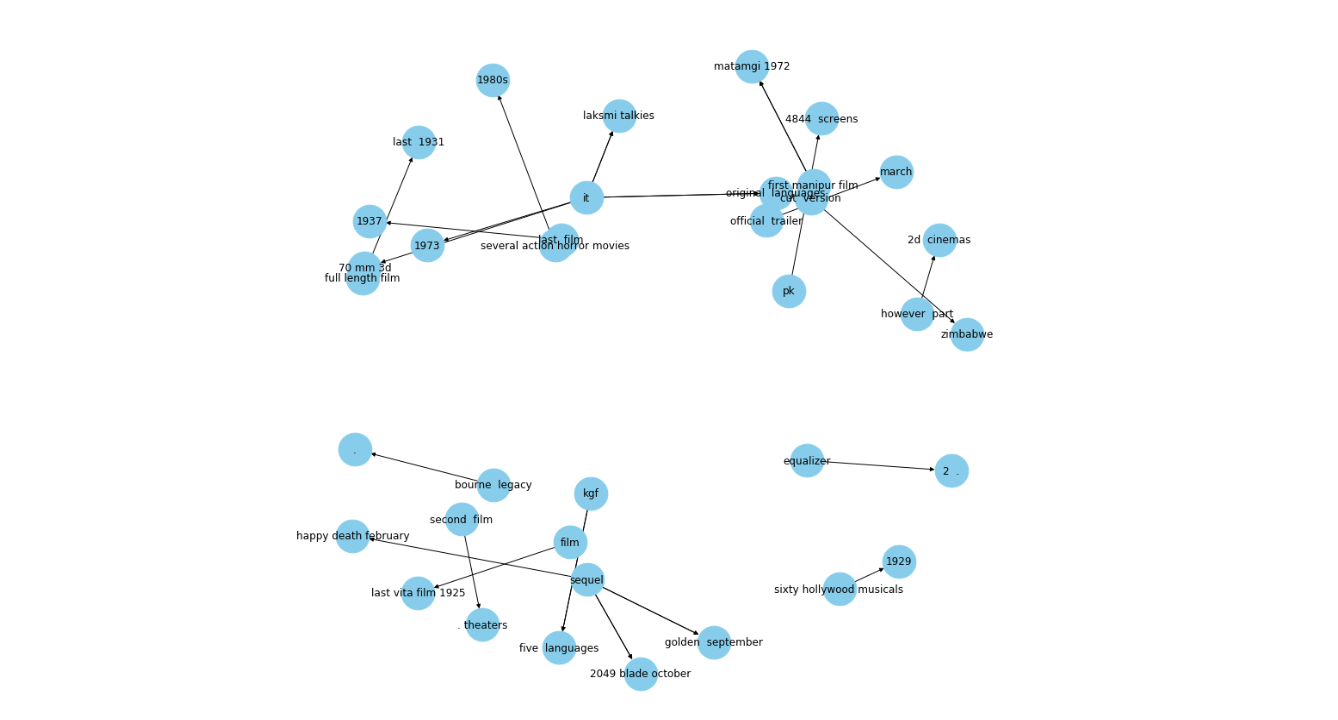 図9 関係が1つのKG.png
図9 関係が1つのKG.png
この知識グラフは、日付や映画のような実体を表しており、線はそれらの公開日 "released in" を表している。では、知識グラフの重要な応用例を見てみよう。
知識グラフの応用
ナレッジグラフは、情報を意味のある形で表現し、結びつけることができるため、さまざまな業界で幅広く活用されています。いくつかの主要な分野でどのように使用されているかを見てみましょう。
検索エンジン
ナレッジグラフの最も一般的な用途の一つは検索エンジンである。ナレッジグラフによって、検索エンジンは単純なキーワードマッチングを超え、ユーザーのクエリの背後にあるコンテキストを理解し、より包括的で有益な検索結果を提供することができる。検索エンジンのナレッジグラフとして現在最も普及しているのは、GoogleのナレッジグラフとMicrosoftのBingナレッジグラフの2つである。
Googleのナレッジグラフ](https://blog.google/products/search/introducing-knowledge-graph-things-not/):** 2012年、Googleはナレッジグラフを導入し、検索結果の提供方法を変えた。ナレッジグラフは、Googleが異なるエンティティ間の関係を理解し、より関連性の高い情報を提供することを可能にしました。
セマンティック検索機能:従来の検索エンジンは、検索結果を返すためにキーワードのマッチングに依存しており、これは無関係な結果を導く可能性があります。ナレッジグラフの助けを借りて、検索エンジンはユーザーのクエリの背後にある意味的な意味を理解し、より正確な結果を提供することができます。
推薦システム
ナレッジグラフは、長い間レコメンデーションシステムを支えてきた。NetflixやSpotifyのような人気のあるストリーミング・サービスは、ナレッジグラフを使ってユーザーにコンテンツを推薦している。これらのグラフは、映画、俳優、ユーザーの好みなど、異なるエンティティ間の相互接続された情報と関係をキャプチャする。この情報を分析することで、システムはパターンを特定し、よりパーソナライズされた推薦を提供することができる。
質問応答システム
バーチャルアシスタントやチャットボットも、ナレッジグラフを利用してユーザーのクエリに的確に回答する。KGを使用する仮想アシスタントは、クエリで言及されたエンティティ間の関係を理解することによってクエリを解釈し、適切に応答します。例えば、ユーザーが最新のジェームズ・ボンド映画の監督について質問した場合、アシスタントはKGを使用して「ジェームズ・ボンド」のエンティティを特定します。次に、最新の映画を見つけ、監督を決定する。
ビジネスインテリジェンス
ビジネスインテリジェンス(BI)システムは、ナレッジグラフを使用して、さまざまなソースからのデータを統合し、分析します。これにより、組織はデータ内のパターン、傾向、関係を見つけ、効率性を向上させ、ビジネスの成功を促進するデータ主導の意思決定を行うことができます。
ナレッジグラフの利点
ナレッジグラフには、以下のような多くの利点があります:
データの文脈性の向上: **ナレッジグラフは、関連する情報を結び付け、物事がどのように関連しているかを確認し、全体像を理解することを容易にします。
データ発見の強化: **ナレッジグラフは、複雑なデータの探索、傾向の特定、新しい洞察の発見、および最初は明らかでないかもしれない関連付けを容易にします。
ナレッジグラフは、データの傾向や関係を特定することで、組織の革新、新たな機会の特定、根拠に基づく意思決定を支援します。
柔軟性と拡張性:** ナレッジグラフは、データとともに成長し、変化することができるため、情報が常に更新される環境に最適です。
ナレッジグラフの課題
ナレッジグラフには利点の他に課題もあります:
データの品質と一貫性: **ナレッジグラフの情報が正しく一貫性があることを保証することは、特に複数のソースからのデータを組み合わせる場合、難しいかもしれません。
大規模グラフのスケーラビリティ:*** ナレッジグラフが大きくなるにつれて、特にパフォーマンスやストレージの面で、管理や維持が難しくなる可能性がある。
ナレッジグラフを最新の状態に保つには、新しい情報を継続的に統合する必要があり、古い情報を修正する必要があるため、継続的な努力が必要となる。
プライバシーとセキュリティの懸念:***機密情報が含まれる場合、プライバシーとセキュリティが大きな懸念となる。データを保護し、誰がアクセスできるかを管理することが重要です。
今後の動向
ナレッジグラフ技術が進歩するにつれ、複雑な情報の理解を助ける新しいツールやアプリケーションとの統合が期待される。主な将来のトレンドを見てみよう:
AIや機械学習との統合
産業界が機械学習をますます採用するようになるにつれ、ナレッジグラフ・テクノロジーは手を携えて進化していくだろう。機械学習は、学習データをアルゴリズムに供給するための有用なフォーマットであるだけでなく、 グラフ・データベースを迅速に構築・構造化し、データ・ポイント間のつながりを描くことができる。この統合によって、予測分析や自動意思決定のような、より高度なアプリケーションが可能になる。
さらに、テクノロジーの台頭により、構造や意味的な意味をベクトル埋め込みとして知識グラフに格納できるようになった。これは、エンティティや関係を機械学習モデルで使用できるベクトル表現に変換することを含む。この技術は、予測や推奨の精度を向上させるのに役立つ。
分散型知識グラフ
分散型ナレッジグラフは、ブロックチェーン技術から着想を得たコンセプトである。ブロックチェーンが成長し続けるにつれ、ナレッジグラフを分散化することへの関心が高まっており、そこではデータは単一の中央機関によって管理されるのではなく、オープンなデータ構造上にホストされる。
マルチモーダル知識グラフ
マルチモーダルナレッジグラフは、画像、動画、音声などの異なるデータタイプを追加することで、従来のナレッジグラフの概念を拡張する。効果的なデータ管理と利用により、KGは開発における重要なトピックとなっている。異なるデータタイプを統合することで、マルチモーダルナレッジグラフは、エンティティや関係性のより有益な表現を提供することができる。
結論
ナレッジグラフは、急速に成長する今日のデジタル社会において重要なものとなっている。ナレッジグラフは、情報の構造化された相互接続表現を提供する。ナレッジグラフは、実体とその関係をネットワークとして表現することで、大量のデータを整理、接続、理解するのに役立つ。
ナレッジグラフの進化、拡張、新しい情報への適応能力は、検索エンジン、バーチャルパーソナルアシスタント、レコメンデーションなどのアプリケーションにとって価値がある。しかし、プライバシーとセキュリティの懸念に対処する必要があり、大規模なグラフの要求に対応するスケーラブルなソリューションを開発する必要がある。
参考資料
非構造化データ入門](https://zilliz.com/learn/introduction-to-unstructured-data)
マルチモーダル知識グラフ](https://adasci.org/a-simplified-guide-to-multimodal-knowledge-graphs/)
ベクトルデータベース vs グラフデータベース](https://zilliz.com/learn/vector-database-vs-graph-database)
知識グラフによるRAGの強化](https://zilliz.com/blog/enhance-rag-with-knowledge-graphs)
RAG(検索拡張世代)とは](https://zilliz.com/learn/Retrieval-Augmented-Generation)
NLPとMilvusによるインテリジェントなQAシステムの構築](https://zilliz.com/blog/building-intelligent-chatbot-with-nlp-and-milvus)
グラフデータベースとは何か - グラフDB解説 - AWS (amazon.com)](https://aws.amazon.com/nosql/graph/)
FiftyOne、LlamaIndex、Milvusでより良いマルチモーダルRAGパイプラインを構築する](https://zilliz.com/blog/build-better-multimodal-rag-pipelines-with-fiftyone-llamaindex-and-milvus)
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS


