




情報検索とは何か?
情報検索(IR)とは、構造化されていない、または半構造化されたデータの大規模なコレクションから、関連する情報を効率的に検索するプロセスである。
今日のデータ主導の世界では、毎日2.5億バイト以上のデータが生成されている。データ生成の膨大な量と速度により、インターネットをナビゲートすることは、鬱蒼としたジャングルを探検するようなものだ。情報検索**(IR)なしでは、特定の情報を見つけることはほとんど不可能である。
今日は、情報検索の概念を一から解き明かし、この技術のあらゆる側面について説明する。
情報検索とは?
情報検索(IR)とは、非構造化または半構造化データの大規模なコレクションから、関連する情報を効率的に検索するプロセスです。IRシステムの主要部分はIRモデルであり、クエリと文書を同様に表現することで、ユーザーのクエリに基づいて文書をランク付けする。マッチング関数を使用して、各文書に検索ステータス値(RSV)を割り当てる。
例えば、検索エンジンはキーワードクエリとの関連性に基づいてページをランク付けする。
IRの重要性は以下の点に集約される:
効率的な情報アクセス:** 膨大な量のデータや文書への迅速かつ適切なアクセスを容易にする。
パーソナライゼーション:ユーザーの好みや過去のインタラクションに基づいて検索結果を調整する。
スケーラビリティ:テキストからマルチメディアまで、大量のデータと多様なタイプのコンテンツを処理します。
アクセシビリティ: **専門知識のない人も含め、幅広いユーザーが情報に簡単にアクセスできるようにします。
2つの概念の混同を解く良い機会だ:情報検索とデータ検索である。検索エンジンのように、情報検索はクエリに基づいて関連する文書やデータを見つける。データ検索は、顧客記録のようなデータベースから特定の構造化されたデータを取得する。
この2つの違いは他にもあります:
| 特徴** | 情報検索 | データ検索 | データの種類 | フリーテキスト、構造化されていないデータのようなもの。 |
| 文書やウェブページのようなフリーテキスト、非構造化データ。 | データベースのテーブル内の構造化データ。 | |||
| キーワード、直感的な検索のための自然言語。 | SQL、正確で構造化されたクエリのための関係代数。 | |||
| マッチング**|関連性に基づく近似マッチ。 | 完全一致は特定の条件に基づいています。 | |||
| 結果の整理**|結果は関連性によってランク付けされます。 | 明示的に並べ替えが行われない限り、結果は並べ替えられないことが多い。 | |||
| ユーザー能力**|専門家以外でも使用可能。 | 複雑なクエリーには知識のあるユーザーか自動化されたプロセスが必要。 |
情報検索の歴史と進化
情報検索(IR)の起源は、インターネットが登場するはるか以前の、デジタル以前の時代にさかのぼる。
初期の始まり:**初期のIRシステムは、20世紀初頭の技術革新に触発され、1940年代には開発されていた。これらの初期のコンピュータベースの検索システムは、検索エンジンが現代のデジタル空間でユビキタスになるずっと前に、商業および情報アプリケーション用に設計されたものであった。時間の経過とともに、プロセッサの速度とストレージ容量が増加するにつれ、IRシステムは手動からより自動化され洗練されたアプローチへと進化した。
現代のIRシステムの発展:**現代の情報検索(IR)システムは、基本的なキーワード検索から高度なアルゴリズムへと大きく発展してきた。1940年代と1950年代、ユニバックのような初期のIRシステムは、単純なテキストマッチング技術を使用していた。1960年代には、Gerard Saltonによって開拓されたベクトル空間モデルや関連性フィードバックなど、より洗練された手法が登場した。1970年代にはtf-idf重み付けスキームが導入され、文書のランキング精度が向上した。1980年代と1990年代には、LSI(Latent Semantic Indexing)とBM25ランキング関数の導入が大きな進歩をもたらした。
1990年代半ばのインターネットの台頭は、ウェブクローラーによるコンテンツ取得の自動化や、PageRankやHITSのようなリンク分析技術の導入による不正操作への対抗によって、IRに革命をもたらした。その結果、スペルミスの修正、検索クエリの拡張、関連性の高いさまざまな結果の提供といった改善がもたらされた。
検索エンジンの役割:** YahooとGoogleは、異なるアルゴリズムを持つ主要な検索エンジンであった。ヤフーの初期の検索エンジンは、人間が作成したディレクトリと基本的なキーワードマッチに大きく依存していた。グーグルのPageRankアルゴリズムは、ページを指すリンクの量と質を評価する。その人気にもかかわらず、ヤフーのアルゴリズムが弱かったため、新規参入のグーグルがヤフーを追い抜き、瞬く間に検索エンジン市場の覇者となった。
IRの歴史を探ったところで、現代のIRシステムの主要コンセプトについて説明しよう。
情報検索システムの主要概念
情報検索では、ユーザーのクエリを処理して関連用語を特定し、その関連性に基づいて文書をランク付けする。システムは様々なデータオブジェクト(テキスト、画像など)にインデックスを付け、IRモデルを使ってマッチする文書のスコアを計算する。結果はランク付けされたリストで表示され、IR検索はデータベース検索と区別される。各コンポーネントをひとつずつ見ていこう。
インデックス作成
IRにおける索引付けとは、用語に基づいて文書を効率的に検索できるようにするためのデータ構造(インデックス)を作成するプロセスのことである。インデックスには、用語と文書間のマッピングが格納され、迅速な検索操作が可能になる。
インデックス作成は、検索プロセスを大幅にスピードアップさせるため、非常に重要である。これによって、大規模な検索エンジンやIRシステムが膨大な量のデータを効率的に扱えるようになる。これがなければ、関連情報の検索には計算コストがかかり、時間もかかる。
**インデクシング手法の種類
転置インデックス](https://zilliz.com/glossary/inverted-index):** これは最も一般的なインデックス方法で、各用語はそれが出現する文書のリストと関連付けられる。
シグネチャファイル:** 文書を表すビット列(シグネチャ)を使用し、より詳細なチェックを行う前に素早くフィルタリングを行うことができる。
文書の接尾辞を格納するインデックスで、部分文字列検索に便利。
B-Trees(Bツリー):** 数値やアルファベットのデータにインデックスを付けることができる、バランスの取れたツリーデータ構造。
k-dツリー:** k次元空間の点を整理する空間データ構造で、多次元データのインデックス付けに便利。
クエリー処理
インデックスがどのように機能するかを理解した上で、情報検索(IR)システム内でクエリがどのように処理されるかを探ります。以下は、IRシステムに渡されるクエリのステップです:
**クエリはどのようにIRシステムで処理されるか?
クエリの解析:クエリをコンポーネント(用語、演算子など)に分解し、ユーザーの意図を解釈する。
クエリの変換:** ステミング、レマタイゼーション、同義語によるクエリの拡張が含まれる場合があります。
検索操作:*** 変換されたクエリは、関連文書を検索するためにインデックスと照合される。
スコアリングとランク付け:*** 取得された文書は関連性に基づいてスコアリングされ、それに応じてランク付けされる。
結果の提示:***ランク付けされたドキュメントは、多くの場合、文脈の中でクエリの用語を示すスニペットやハイライトとともに、ユーザーに提示される。
クエリの種類:*。
ブールモデル:**
論理演算子(AND、OR、NOT)を使用して項を結合する。
例:**"machine AND learning "は両方の用語を含む文書を返す。
ベクトル空間モデル
文書やクエリを多次元空間の[ベクトル埋め込み]として表現する。
類似度は文書とクエリのベクトル間の余弦類似度を用いて測定される。
例:**クエリは、クエリベクトルとの余弦類似度が高い文書を返す。
確率モデル:
与えられた文書がクエリに関連する確率に基づく。
例:** ベイズの定理を使用し、関連確率に基づいて文書をランク付けする。
関連性とランキング
関連性とは、文書がクエリによって表現された情報ニーズを満たす度合いのことである。これは主観的なものであり、ユーザーの意図、文脈、その他の要因によって変化する。用語の頻度、文書の長さ、文書の新しさ、ユーザーの行動(クリックスルー率)などの要因が関連性に影響を与えます。
ランキングアルゴリズムは関連性を測定する:
ランキングアルゴリズムの概要:*
TFT-IDF (Term Frequency-Inverse Document Frequency):** コーパス全体の重要度に対する文書内の用語の重要度を考慮する重み付けスキーム。
BM25:用語の飽和と文書の長さの正規化を取り入れることで、TF-IDFを改良した高度なランキング関数。
PageRank:**Googleのような検索エンジンで使用され、ドキュメントへのリンクの数と質に基づいてドキュメントをランク付けします。
クリックスルー率や関連性のフィードバックなどの特徴から学習し、機械学習モデルを使用して文書をランク付けする方法です。
評価指標
情報検索(IR)システムのパフォーマンスを評価するために、いくつかの評価指標が一般的に使用されています。IRシステムの評価に使用される一般的な指標は以下の通りです:
- 検索された文書のうち、関連性のある文書の割合。
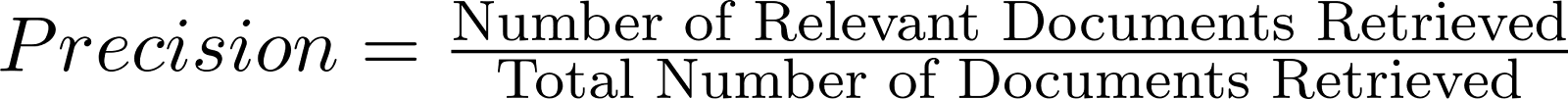 計算式 - 精度.png
計算式 - 精度.png
- Recall: 検索された関連文書の割合。
 formula - recall.png
formula - recall.png
- F1-Score:精度と想起の調和平均、2つのメトリクスのバランスをとる。
 数式-f1score.png
数式-f1score.png
Mean Average Precision (MAP): クエリのセットの平均精度スコアの平均で、異なるリコールレベルでの精度を反映します。
Normalized Discounted Cumulative Gain (nDCG): 実際のランキングと理想的なランキングを比較することで、ランキングの質を測定します。
評価指標](https://zilliz.com/learn/information-retrieval-metrics)についての詳細はこちらをご覧ください。
情報検索モデルの種類
情報検索モデルは、関連する情報を検索する際の特定の課題に対処するために開発されている。最も一般的なタイプは以下の通り:
ブール検索モデル
ブール検索モデルは、ブール論理(AND、OR、NOT)に依存し、特定のクエリ条件を正確に満たすドキュメントとマッチします。ユーザーはこれらの演算子で用語を組み合わせてクエリーを作成します。このモデルはシンプルで正確なため、完全一致には効果的です。しかし、部分的な関連性を扱えず、ランク付けのメカニズムもないため、結果が多すぎたり少なすぎたりする可能性があり、柔軟性に欠ける。
ベクトル空間モデル
ベクトル空間モデルでは、ドキュメントとクエリは多次元空間のベクトルとして表現されます。関連性はベクトル間の余弦類似度を測定することで計算される。用語は、用語頻度-逆文書頻度(TF-IDF)を使用して、その重要性に基づいて重み付けされる。
図1 TF-IDFの計算式.png](https://assets.zilliz.com/Fig_1_Formula_for_TF_IDF_22a0f44e8c.png)
図1:TF-IDFの公式
確率的検索モデル
確率的検索モデルは、ある文書が与えられたクエリに関連する確率を推定する。この推定された関連確率に基づいて文書がランク付けされ、最も関連性の高い文書が最初に表示される。BM25は一般的な確率的検索モデルで、用語頻度と文書の長さの正規化を用いて文書をスコアリングし、ランク付けする。
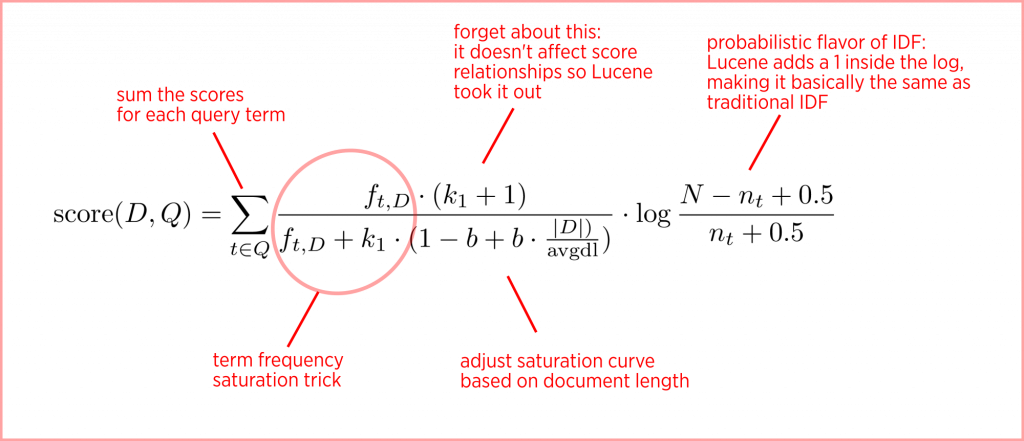 図2 BM25アルゴリズムの概要.png
図2 BM25アルゴリズムの概要.png
図2:BM25アルゴリズムの概要
BM25はTF-IDFと同様のアイデア(用語頻度や逆文書頻度など)を取り入れているが、文書の長さの正規化も考慮し、用語頻度の影響を確率的に調整する。これにより、基本的なTF-IDFよりも洗練され、柔軟性が増している。
潜在意味解析
潜在意味解析(LSA)は、似たような文脈に現れる単語は関連した意味を持つ傾向があるという原則に基づいている。例えば、健康に関する複数の記事において、「栄養」、「運動」、「ウェルネス」のような用語が頻繁に共起する可能性がある。
LSAでは、文書中の単語の出現頻度を表す行列を構築する。次に、特異値分解(SVD)と呼ばれる数学的手法を適用し、列間の類似構造を維持したまま行数を減らす。この削減により、元の大きな行列は、単語と文書間の本質的な関係を捉えたより小さな行列に変換される。
ニューラル情報検索
IRのためのニューラル・ランキング・モデルは、クエリに基づいて検索結果をランク付けするために、浅いまたは深いニューラルネットワークを利用する。従来のランキング学習モデルは、ニューラルネットワークを含む教師ありの機械学習(ML)技術を、手作業で作成したIR特徴量に適用している。対照的に、新しいニューラル・モデルは、生のテキストから直接言語表現を学習し、クエリと文書間の語彙ギャップを埋めるのに役立つ。従来のランク学習モデルや非ニューラルIRアプローチとは異なり、これらの高度なML技術は、効果的に導入する前に大規模な学習データを必要とする。
情報検索の応用
IRは現代社会における多くのアプリケーションに力を与えている。そのいくつかを紹介しよう:
検索エンジン
IRはどのように検索エンジンに力を与えるか:** IRアルゴリズムは、ユーザーのクエリにマッチするようにウェブページをインデックスし、ランク付けし、最も関連性の高い検索結果を返す。
例:** Google PageRank は、リンク分析を使用してウェブページの重要性と関連性を判断し、検索結果の精度を高めています。
デジタルライブラリー
デジタル・ライブラリーやアーカイブにおけるIRの利用:*** IR技術は、デジタル文書や歴史的記録の索引付け、検索、取得に役立ち、大量のテキストをアクセスしやすく、管理しやすくする。
例:** The Digital Public Library of America (DPLA) は、何百万もの写真、原稿、その他の文化遺産へのアクセスを提供するために IR を利用している。
推薦システム
レコメンデーションシステム構築におけるIRの役割:** IRの手法は、ユーザーの嗜好や行動を分析して関連するアイテムを提案し、パーソナライズされたレコメンデーションを通じてユーザー体験を向上させる。
例:** Netflix's Recommendation Engine は、ユーザーの視聴履歴や嗜好に基づいて映画やテレビ番組を提案するためにIR技術を使用している。
電子商取引
Eコマースにおける商品検索と推薦のためのIRアプリケーション:** IR技術は、商品検索機能を強化し、ユーザーのクエリや閲覧履歴に基づいて商品を推薦するために使用され、顧客満足度と売上を向上させる。
例:** Amazon's Product Search and Recommendation Systemは、ユーザーが商品を検索し、閲覧や購買行動に基づいてパーソナライズされた推薦を受けるのを助けるためにIRアルゴリズムを採用している。
ヘルスケア
研究、診断、治療のために医学文献や患者記録を検索する。
例:** PubMedは、医学研究と臨床研究の包括的なデータベースにアクセスするためにIR技術を採用している。
情報検索の課題
情報検索は検索の課題に取り組んでいるが、膨大なデータをふるいにかけることは障害となる。そのいくつかを紹介しよう:
スケーラビリティ:*** 情報検索(IR)システムを拡張して大規模なデータセットを扱うには、ストレージ要件の増加や処理時間の延長といった課題がある。膨大な量のデータを効率的に管理するには、分散コンピューティング・ソリューションが必要になることがよくあります。
検索結果における高い関連性と精度の確保は、効果的なランキングアルゴリズムと、進化するユーザークエリやコンテンツに対応するための継続的なモデル更新の必要性から、困難な課題となっています。
ユーザーのプライバシー:**効果的なIRとユーザーのプライバシーのバランスを取るには、パーソナライズされた正確な検索結果を提供しながら、強固なデータ保護対策を実施する必要があります。匿名化や安全なデータ処理のような技術は非常に重要です。
マルチモーダルデータの取り扱い:テキスト、画像、動画など、多様なデータタイプからの情報の処理と検索には、異なるデータ処理技術を統合する必要があります。検索システムは、包括的な検索結果を得るために、これらのモダリティを効果的に扱い、組み合わせる必要がある。
結論
20世紀から21世紀初頭にかけて、情報へのアクセスに革命が起きた。1912年当時、情報を探すには図書館を訪れ、カードカタログを利用する必要があり、知識の範囲は図書館の蔵書に限られていた。アップル社が1987年に発表したKnowledge Navigatorは、音声認識、自然な対話、専門家との接続機能を含む広範なデータベースアクセスを備えた高度なIRシステムを構想していた。この構想は、今日の検索エンジンを支える最新のIRシステムに結実した。
今日、私たちは、あらゆる分野のダイナミクスを変えつつある人工知能(AI)によって約束された別のビジョンを目の当たりにしている。OpenAIのChatGPT](https://zilliz.com/learn/ChatGPT-Vector-Database-Prompt-as-code)やGoogleのGeminiのような大規模言語モデル(LLMs)のおかげで、先進的なIRシステムが出現しつつある。LLMsは、ユーザーに調査のための多数のリンクを氾濫させることなく、正確な情報を直接生成することができる。テクノロジーが急速に進化する中、競争に勝ち残ることは非常に重要である。以下は、さらなる参考文献とリソースである。
書籍と研究論文
情報検索入門」(https://www.cambridge.org/highereducation/books/introduction-to-information-retrieval/669D108D20F556C5C30957D63B5AB65C#overview) マニング、ラガバン、シュッツェ著
"Modern Information Retrieval:検索を支える概念と技術" by Ricardo Baeza-Yates and Berthier Ribeiro-Neto
コミュニティとフォーラム
Stack Overflow - 情報検索 スタックオーバーフローへ
Reddit - r/MachineLearning: 議論に参加する
GenAI、RAG、ベクターデータベースに関するZillizのリソース
生成AIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)
あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models)
ZillizのAI学習記事](https://zilliz.com/learn)
AI開発者のMilvusコミュニティに参加する](https://zilliz.com/community)
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS


