




Locality Sensitive Hashingのマスター:包括的なチュートリアルと使用例
効率的な類似検索テクニックとしての Locality Sensitive Hashing を理解する。LSHの実用的なアプリケーション、課題、Python実装を学ぶ。
シリーズ全体を読む
- 非構造化データ入門
- ベクトルデータベースとは?その仕組みとは?
- ベクトルデータベースについて: ベクトルデータベース、ベクトル検索ライブラリ、とベクトル検索プラグインの比較
- Milvusベクトルデータベース入門
- Milvus Quickstart:五分間だけでMilvus ベクトルデータベースをインストール
- ベクトル類似検索入門
- ベクター・インデックスの基本について知っておくべきすべてのこと
- スカラー量子化と積量子化
- 階層的航行可能小世界(HNSW)
- おおよその最近接者 ああ(迷惑)
- プロジェクトに適したベクトルインデックスの選択
- DiskANNとヴァマナアルゴリズム
- データの完全性を守る:ベクターデータベースにおけるバックアップとリカバリ
- AIにおける高密度ベクトル:機械学習におけるデータの可能性の最大化
- ベクターデータベースとクラウドコンピューティングの統合:現代のデータ課題に対する戦略的ソリューション
- 初心者のためのベクターデータベース導入ガイド
- ベクトル・データベースにおけるデータの完全性の維持
- 行と列からベクトルへ:データベース技術の進化の旅
- ソフトマックス活性化関数の解読
- ベクトル・データベースにおけるメモリ効率のための積量子化の利用
- ベクターデータベースにおける検索性能のボトルネックを発見する方法
- ベクターデータベースの高可用性の確保
- Locality Sensitive Hashingのマスター:包括的なチュートリアルと使用例
- ベクターライブラリ vs ベクターデータベース:どちらが適しているか?
- 微調整テクニックでGPT 4.xのポテンシャルを最大限に引き出す
- マルチクラウド環境におけるベクターデータベースの展開
- ベクトル埋め込み入門:ベクトル埋め込みとは何か?
データの次元が大きくなると、最近傍を見つけるような検索タスクは困難になる。これは、データ点間の距離が増加することで、次元の呪い、距離の集中、空白現象が発生するためである。その結果、距離の計算と類似性の比較は疲弊した作業になる。
Locality-sensitiveハッシュ(LSH)は、意味的類似検索を行う際に、高次元データ検索の課題に対処するための画期的な方法である。LSHは、データ間の局所的な距離を保持しながら、類似するアイテムをハッシュ値でマッピングすることで、効率的なデータ検索のための検索空間を縮小する。
LSHは科学や機械学習(ML)におけるビッグデータで重要な役割を果たし、「次元の呪い」に対抗し、実用的な情報検索を可能にする。類似データをクラスタリングすることで、LSHは効率的な最近傍探索、データクラスタリング、および大規模データセットにおける類似検索を必要とする他のタスクを可能にする。
##LSHを理解する
ベクトル同士のベクトル比較は、O(n)の線形時間複雑度を持ちます。各ベクトルを他のベクトルと比較すると、複雑さは指数関数的に増大し、O(n^2)となります。
LSHは、探索空間を縮小することによって、この探索複雑度を軽減することを目的としている。すべてのデータ点が存在する高次元ユークリッド空間を使用し、類似したデータ点を同じバケツにグループ化する。
これは、ある距離の閾値内にある類似データ点を同じバケツにハッシュすることで達成される。距離が大きいほどハッシュテーブルがいっぱいになり、明確なハッシュができる確率が高くなる。さらに、LSHは各データポイントに対して複数のバケットを作成し、それぞれが異なるハッシュ関数を用いて形成される。これによりロバスト性が増し、検索の関連性が向上する。
LSH の主要な原理
LSHアルゴリズムには2つの重要なステップがある。以下の2つです:
1.複数のハッシュ関数を作成し、各データポイントのハッシュコードを生成する。
2.同じハッシュコードを持つデータポイントを同じハッシュバケットに割り当てる。
 バケットハッシュ.png
バケットハッシュ.png
バケットハッシュとして知られるこのプロセスは、LSHの重要な原則を定義している:
1.この特性により、高次元データにおける近似的な類似性検索とクラスタリングが保証される。
2.感度 感度とは、ハッシュ化後の距離に基づいて異なるバケットにマッピングされた非類似点のことである。これにより、類似性検索時に非類似なデータ点がフィルタリングされることが保証される。
3.近似結果 LSHは近似的な検索を行うが、これは非類似の点が同じバケツに、類似の点が異なるバケツに入る可能性があることを意味する。このようなエラーが発生する可能性は、ハッシュ関数の設計とハッシュテーブルの数に依存する。しかし、探索空間の削減とスケーラビリティは、エラーの可能性を上回ります。
LSHアルゴリズムと実装の探求
高次元情報検索の課題に対処するために、様々なLSHアルゴリズムを使用することができる。
Minhash LSH
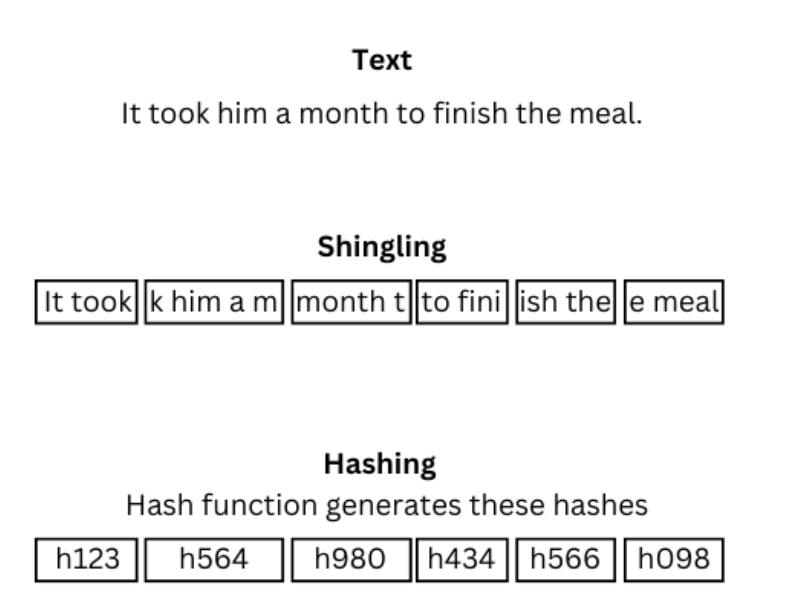
Minhashは、高次元の文書や集合に適したLSHアルゴリズムである。Minhashは、集合の重複する断片を作成するシングリング法を使用する。次に、ランダムなハッシュ関数のセットがシングルのセットを受け取り、それらを単一のハッシュ関数または値にマッピングする。
これにより、似たような文書が似たようなハッシュバケツに入ることが保証される。検索クエリは検索中にハッシュ化され、その最小ハッシュ化されたシグネチャが類似バケット内の文書の最小ハッシュと比較される。
以下のコードはPythonによるLSHの基本的な実装を示している:
from collections import defaultdict
# シングリングを行い、MinHashシグネチャを作成する関数
def minhash(data, num_perm):
minhash_signatures = defaultdict(list)
# ハッシュ関数のリストを作成する
hash_functions = [lambda x, i=i: hash(str(x) + str(i)) for i in range(num_perm)] # ハッシュ関数のリストを作成する。
for element in data:
# 各要素について、各ハッシュ関数に対するハッシュ値の最小値を計算する
for hash_function in hash_functions:
minhash_signatures[element].append(min(hash_function(x) for x in element.split()))
return minhash_signatures
# LSH インデックスを作成し、項目をバケットに割り当て、類似性検索を実行する関数
def lsh(data, num_perm):
# 各データポイントに対してMinHashシグネチャを作成します。
minhash_dict = minhash(data, num_perm)
index = defaultdict(list)
# MinHashシグネチャに基づいて、データポイントをバケットに割り当てる
for point, signature in minhash_dict.items():
bucket_id = tuple(signature)
index[bucket_id].append(point)
# 同じバケツ内のデータポイントを見つけることで類似検索を行う
similar_items = {} とする。
for query, query_signature in minhash_dict.items():
bucket_id = tuple(query_signature)
candidates = index[bucket_id]
similar_items[query] = candidates
return similar_items
# データセットの例
data = ["ネコ イヌ ウサギ", "イヌ トカゲ 鳥", "ネコ クマ カラス", "ライオン トカゲ パンダ"].
# 必要に応じて順列の数を調整する
num_perm = 16
# 類似アイテムを見つける
similar_items = lsh(data, num_perm)
# 類似項目を表示する
print("Similar items:")
for query, items in similar_items.items():
print(f"\tQuery: {query}")
print(f"\tItems: {items}")
Jaccard 類似性のための局所性を考慮したハッシング
Jaccard Similarity のための Locality Sensitive Hashing は、集合や binary vector に最適です。これは、Jaccard類似度に基づいて、類似する文書や集合を識別する。このアイデアは、ランダムな超平面の集合を定義し、超平面の同じハッシュ値の同じ側にある文書に類似のバケツを割り当てるというものです。文書間のJaccard類似度は正確さを保証するために計算され、類似したJaccardスコアを持つ文書は類似したバケツに入る。
検索中、検索クエリはバケツ分けに使用された超平面に投影され、クエリと同じ超平面に着地したデータポイントが更なる評価のために検索される。これは、超平面の同じ側にあるクエリポイントに着地したバケット内の文書が、さらなる評価のために検索されることを意味する。
Pythonのdatasketchライブラリは、LSHを実装するための簡単な構文を提供しています。以下はPythonでJaccard SimilarityのLSH関数を実装したコードです:
from datasketch import MinHash
from datasketch import MinHashLSH
# 128個の順列を持つLSHインデックスを作成する
minhash = MinHash(num_perm=128)
# ジャカード類似度の閾値を指定する
lsh_jaccard = MinHashLSH(threshold=0.5, num_perm=128)
# "item1 "をシングルに分割し、minhashを計算する
minhash.update("item1".encode('utf8'))
# "item1 "をラベル "item1 "を持つ関連するバケットに割り当てる
lsh_jaccard.insert("item1", minhash)
# "item1 "をシングルに分割し、minhashを計算する
minhash.update("item2".encode('utf8'))
# "item2 "をラベル "item2 "を持つ関連バケットに割り当てる
lsh_jaccard.insert("item2", minhash)
# 似た minhash を持つアイテムを見つける
result = lsh_jaccard.query(minhash)
print(result)
球状の LSH
球面 LSH アルゴリズムは、地理空間データのように単位球面上に存在するデータ点に適しています。ランダムな球面部分空間を使用して、類似するデータ点を見つけます。同じ球面部分空間上のデータ点は、類似したバケットにマッピングされます。コサイン類似度がデータ点間で計算され、類似性が検証される。検索中、検索クエリはバケッティングに使われたのと同じ球面部分空間に投影される。検索クエリと同じ球面部分空間に着地した点は、コサイン類似度を用いてさらなる類似性評価のために検索される。
Python の lshash ライブラリは球面 LSH を実装するためのシンプルな構文を提供します。以下はPythonで実装したコードです:
Python from lshash import LSHash
8次元の入力データに対して6ビットのハッシュ関数を作成する
lsh_hash = LSHash(6, 8)
8 次元の入力データに対してハッシュ関数を適用する
lsh_hash.index([2, 3, 4, 5, 6, 7, 8, 9]) lsh_hash.index([10, 12, 99, 1, 5, 31, 2, 3])
類似データ1点を問い合わせる
num_similar_point = 1 nn = lsh_hash.query([1, 2, 3, 4, 5, 6, 7, 7], num_results=num_similar_point, distance_func="cosine") print(nn)
### LSH の実用的なアプリケーション
LSHは大規模データベースからの情報検索に欠かせない。精度を保ちながら検索速度を大幅に向上させるデータサイエンスへの応用例としては、以下のようなものがある:
LSHは大規模な[データベース](https://zilliz.com/glossary/ai-database)からの情報検索に欠かせない。LSHは、大規模な[データベース]()からの情報検索に極めて重要である。精度を保ちながら検索速度を大幅に向上させるLSHのデータサイエンス・アプリケーションのいくつかは以下の通りである:
1.**画像検索** 何百万枚もの画像のリポジトリから関連画像を検索するのは、計算量が膨大になる。LSHは画像から特徴ベクトルを抽出し、より小さな次元空間に投影します。類似の画像は類似の特徴ベクトルを持ち、それらは類似のハッシュテーブルに格納される。これにより、データセットのサイズが大幅に縮小され、検索が高速化される。
2.**剽窃検出*** LSHはテキスト文書をシングルの集合に変換する。剽窃検出の際、アルゴリズムは類似したシングルを持つ文書を識別し、剽窃の可能性を示す。関連する文書は、剽窃を検証するためにさらに評価される。これにより、結果を正確に保ちながら、より短時間で大量の文書から剽窃を検出することができる。
3.**ニア・デュプリケート検出(Near-Duplicate Detection)**ニア・デュプリケート文書とは、ほとんど同じような内容を持つが、同一ではない文書のことである。Jaccard LSHはランダムな超平面上に文書を投影することで、ニアダプリケート文書を検出するのに適したLSHアルゴリズムである。そしてJaccard類似度を用いて、類似文書を類似ハッシュテーブルにマッピングする。これにより、検索時にスキャンする文書数が減り、より高速で効率的なニアデュープリケート検出が実現する。
正確な情報検索のために大規模なデータセットを効率的にナビゲートする LSH の能力は、効率的な近似近傍検索に不可欠なツールとなっている。高い精度を維持しながら類似検索の計算負荷を軽減する LSH は、膨大なデータから正確な洞察を引き出します。
## 結論
この局所性を考慮したハッシングのPythonチュートリアルを気に入っていただけたでしょうか。また、近傍探索を効率化するためにハッシュ関数がどのように機能するのか理解していただけたでしょうか!Locality Sensitive Hashingは大規模データベースからの最近傍検索を高速化する強力なテクニックです。そのロバストなハッシュ関数と類似度測定のおかげで、精度に妥協することなくこれを実現します。これは LSH があなたの仕事において重要なツールとなる重要な側面です。
これらの利点により、LSH は高次元データベースの取り扱いを容易にし、AI システムの効率を高めます。LSH は、データ検索手法に革命をもたらす大きな可能性を秘めた技術なのです。
Pythonの**lshash**や**datasketch**のようなライブラリを使えば、LSHを簡単に実装できます。これらのライブラリはタスクを簡素化しますが、アルゴリズムの効率はよくチューニングされた構成に依存します。うまく調整された設定を設計するには、実践的な知識と十分な練習が必要です。ですから、LSHの真の可能性を受け入れるために、さまざまなLSHテクニックで遊んでみてください。 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
読み続けて

ベクトルデータベースについて: ベクトルデータベース、ベクトル検索ライブラリ、とベクトル検索プラグインの比較
ベクトルデータベースをより深く理解し、ベクトル検索ライブラリやベクトル検索プラグインと比較しましょう。

Milvusベクトルデータベース入門
Zilliz はこれから、世界初のオープンソースのベクトルデータベースであるMilvusの構築について語り始めます。これは、始まりであり、大切なことであり、そして未来でもあります。

ベクターデータベースにおける検索性能のボトルネックを発見する方法
Milvusのようなベクターデータベースで、検索パフォーマンスを監視し、ボトルネックを発見し、パフォーマンスを最適化する方法を学びます。