




ベクターデータベースにおける検索性能のボトルネックを発見する方法
Milvusのようなベクターデータベースで、検索パフォーマンスを監視し、ボトルネックを発見し、パフォーマンスを最適化する方法を学びます。
シリーズ全体を読む
- 非構造化データ入門
- ベクトルデータベースとは?その仕組みとは?
- ベクトルデータベースについて: ベクトルデータベース、ベクトル検索ライブラリ、とベクトル検索プラグインの比較
- Milvusベクトルデータベース入門
- Milvus Quickstart:五分間だけでMilvus ベクトルデータベースをインストール
- ベクトル類似検索入門
- ベクター・インデックスの基本について知っておくべきすべてのこと
- スカラー量子化と積量子化
- 階層的航行可能小世界(HNSW)
- おおよその最近接者 ああ(迷惑)
- プロジェクトに適したベクトルインデックスの選択
- DiskANNとヴァマナアルゴリズム
- データの完全性を守る:ベクターデータベースにおけるバックアップとリカバリ
- AIにおける高密度ベクトル:機械学習におけるデータの可能性の最大化
- ベクターデータベースとクラウドコンピューティングの統合:現代のデータ課題に対する戦略的ソリューション
- 初心者のためのベクターデータベース導入ガイド
- ベクトル・データベースにおけるデータの完全性の維持
- 行と列からベクトルへ:データベース技術の進化の旅
- ソフトマックス活性化関数の解読
- ベクトル・データベースにおけるメモリ効率のための積量子化の利用
- ベクターデータベースにおける検索性能のボトルネックを発見する方法
- ベクターデータベースの高可用性の確保
- Locality Sensitive Hashingのマスター:包括的なチュートリアルと使用例
- ベクターライブラリ vs ベクターデータベース:どちらが適しているか?
- 微調整テクニックでGPT 4.xのポテンシャルを最大限に引き出す
- マルチクラウド環境におけるベクターデータベースの展開
- ベクトル埋め込み入門:ベクトル埋め込みとは何か?
強力なコンピューター・システムや、電光石火の速さでタスクを実行するように設計されたアプリケーションがあるとします。しかし、ある部品が他の部品に追いついていないのです。この性能不足の部品は、瓶の細い首が液体の流れを制限するように、システム全体の能力を制限する。ソフトウェアでは、ボトルネックとはトランザクション・パス全体で最もスループットが低いコンポーネントのことである。機械の歯車のひとつが他の歯車と同じ速さで回転しなければ、すべてが減速してしまう。ボトルネックを特定し修正することで、コンピューターシステムやアプリケーションの効率を劇的に向上させることができるため、この概念は極めて重要である。
前回のブログでは、様々なベクターデータベースを決定する前に評価するための主な指標とベンチマークツールを紹介しました。今回は、Milvusベクトルデータベース、特にMilvus2.2以降のバージョンを例にとり、ベクトルデータベースにおける検索性能の監視、ボトルネックの発見、性能の最適化の方法について説明します。
性能評価と監視指標
ベクトルデータベースシステムにおいて、頻繁に使用され、最も重要な評価指標は、Recall、Latency、Queries Per Second (QPS)の3つです。これらの指標は、システムがどれだけ正確で、どれだけ速く、どれだけ多くのリクエストを処理できるかを表しています。これらについて詳しく見ていきましょう。
リコール
Wikipediaで定義されているように、recallとは、検索クエリにおいて関連するアイテムが正常に検索された割合のことである。与えられたクエリ・ベクトルに最も近い Top-K ベクトルのいくつが検索されたかを評価する。しかし、すべての近いベクトルが特定されるとは限りません。この不足は、ブルートフォース法を除くインデックス作成アルゴリズムが近似的であるためにしばしば発生します。これらのアルゴリズムは、高速化のために想起をトレードオフにしている。これらのインデックス作成アルゴリズムの構成は、特定の生産ニーズに合わせてバランスをとることを目的としています。詳細な情報については、ドキュメントのページを参照してください:インメモリインデックス と オンディスクインデックス を参照。
リコール計算はリソース集約的で、通常クライアント側で実行され、グランドトゥルースを確立するために必要な大規模な計算のため、通常モニタリングダッシュボードには反映されません。従って、以下のステップバイステップガイドでは、許容可能なリコールレベルが達成され、適切なインデックスパラメータがベクトルインデックス用に選択されたと仮定します。
レイテンシー
レイテンシとは応答速度のことで、クエリが開始されてから結果を受け取るまでにかかる時間のことです。レイテンシーが低いほどレスポンスは速くなり、これはリアルタイム・アプリケーションにとって極めて重要です。
QPS
QPS(Queries Per Second)は、システムのスループットを測定する重要な指標で、パイプを流れる水の流量のように、1秒間に処理できるクエリの数を示します。QPSの値が高いほど、システムの性能の重要な要素である、多数の同時リクエストを管理する能力が向上していることを意味します。
QPSとレイテンシの関係はしばしば複雑である。従来のデータベースシステムでは、一般にQPSがシステムの容量に近づき、そのリソースをすべて消費するにつれて待ち時間が増加する。しかし、Milvusの場合、システムはクエリーをまとめてバッチ処理することでパフォーマンスを最適化している。このアプローチにより、ネットワーク・パケット・サイズが削減され、待ち時間とQPSの両方を同時に増加させることができ、システム全体の効率が向上する。
パフォーマンス・モニタリング・ツール
Prometheusを使用してMilvusのパフォーマンス結果を収集・分析し、Grafanaダッシュボードを使用してパフォーマンスのボトルネックを可視化・特定します。
パフォーマンスのボトルネックを見つける方法:ステップバイステップガイド
このフローチャートは、Grafana を使用してパフォーマンスのボトルネックを効果的に特定するための合理的なアプローチの概要を示しています。黄色の菱形とボックスは、条件を評価する必要がある決定点を示し、水色のボックスは、特定のアクションを示唆するか、より詳細な情報への指示を提供します。次のセクションでは、フローチャートに描かれているように、パフォーマンスの問題を監視および検出するための各ステップを案内します。
パフォーマンスのボトルネックを見つける方法-ステップ・バイ・ステップ・ガイド](https://assets.zilliz.com/How_to_Find_Performance_Bottlenecks_A_Step_by_Step_Guide_74a6f1f21a.jpeg)
前提条件
Milvusのようなベクトルデータベースのパフォーマンス監視を始める前に、Kubernetes上に監視サービスをデプロイし、収集したメトリクスをGrafana Dashboardで可視化する必要があります。
詳細はドキュメントページを参照してください:
Kubernetesへのモニタリングサービスのデプロイ](https://milvus.io/docs/monitor.md)
MilvusクラスタとK8sを始める](https://milvus.io/blog/getting-started-with-milvus-cluster-and-k8s.md)
GrafanaでMilvusメトリクスを可視化する](https://milvus.io/docs/visualize.md)
重要な注意: Grafanaの最小間隔はパフォーマンス監視結果に影響を与える可能性がある
Grafanaを使用してMilvusの監視を開始する前に、Grafanaで表示するための最小間隔が指定された間隔と必ずしも一致するとは限らないことに注意することが重要です。その結果、関連する数値の一部のスパイクがより滑らかに表示されたり、平均化後に消失したりすることもあります。
この問題を解決するには
1.メトリック名をクリックし、Editを選択するか、e.を押します。
メトリック名の編集](https://assets.zilliz.com/2_storageio_distribution_5665e3d5f5.png)
2.クエリオプション**をクリックします。
クエリオプション](https://assets.zilliz.com/3_query_options_920d4ba8a5.png)
3.最小間隔を15s**に変更する。
最小間隔オプション](https://assets.zilliz.com/4_min_interval_options_604fe4f87e.png)
重要: NUMA設計のマシンはMilvusのパフォーマンスに影響を与える可能性があります。
NUMA(Non-Uniform Memory Access)はマルチプロセッサシステムで利用されるメモリ設計です。NUMAアーキテクチャでは、各CPUコアは特定のメモリセグメントに直接リンクされています。ローカルメモリ(現在のタスクを実行しているプロセッサに接続されているメモリ)へのアクセスは、リモートメモリ(別のプロセッサに接続されているメモリ)へのアクセスよりも高速です。プロセッサが直接接続されていないメモリセグメントからデータを必要とする場合、必要なパスが長くなるため、追加のレイテンシが発生します。
NUMA対応マシンにMilvusを導入する場合、numactlやcpusetなどのツールを使ってMilvusコンポーネントを割り当て、プロセッサの親和性を確保することをお勧めします。Sapphire Rapids のような最新のプロセッサは通常 NUMA ノードあたり 32 コアですが、古いプロセッサは通常ノードあたり 16 コアです。確認するには、インスタンス上で lscpu を実行します。
それでは、Milvusのパフォーマンスを監視し、ボトルネックになりそうな箇所を見つけましょう。
1.Grafanaダッシュボードを開く
Kubernetes上にモニターサービスを正常にデプロイし、Grafanaでメトリクスを可視化したら、Grafana Dashboardを開きます。すると以下のようなダッシュボードが表示されるはずです。
 Grafanaダッシュボード
Grafanaダッシュボード
**注:この記事では、パフォーマンスモニタリングとボトルネック分析にGrafana V2を使用しています。Grafana V1を使用している場合、モニタリングの手順が若干異なる可能性があることをご了承ください。
2.各コンポーネントのCPU使用率を確認する。
主要コンポーネントのCPU使用率を確認する必要があります:各コンポーネントのCPU使用率を確認するには、Overview** を展開し、CPU usage を選択します。
ポッドCPU使用率](https://assets.zilliz.com/6_pod_cpu_usage_744a8d16a4.png) ポッドCPU使用率](https://assets.zilliz.com/7_pod_cpu_usage_2_6722a83ff7.png)
**ポッドCPU使用率
1.MilvusでCPU使用率を監視する場合、メトリクスはポッドレベルで取得されます。Milvusをスタンドアロンモードで動作させると、単独のPodのCPU使用率を反映した単一のチャート線が表示されます。一方、Milvusをクラスタモードで実行すると、複数のポッドにまたがるCPU使用率を検査することができます。上のチャートでは、ProxyのCPU使用率が水色の線で明確に示されており、この線がしきい値の上限に達すると、CPU使用率が上限に達したことを示します。
2.パネルがなく、Service Qualityの下にチャートが見つからない場合は、以下のいずれかの方法があります:
- CPU Usage_** __under _Runtime を見てください。これはパーセンテージではなくKubernetes単位で使用量を表示します。
CPU使用率](https://assets.zilliz.com/8_CPU_Usage_0233e03fab.png)
または、ポッド使用状況パネルを追加します。
- Addボタンをクリックして、Visualization.**を選択します。
ビジュアライゼーションの追加](https://assets.zilliz.com/9_add_visualization_4e98c9b909.png)
- PromQL Queryを入力します。
sum(rate(container_cpu_usage_seconds_total{namespace="$namespace",pod=~"$instance-milvus.*",image!="",container!=""}[2m])) by (pod、namespace) / (sum(container_spec_cpu_quota{namespace="$namespace",pod=~"$instance-milvus.*",image!="",container!=""}/100000) by (pod、namespace)))
クエリ検査官](https://assets.zilliz.com/10_Query_inspector_98270bdf60.png)
- ユニットを選択してください。
標準オプション](https://assets.zilliz.com/11_standard_options_8f97c83199.png)
- 設定を保存します。
プロキシ
QPS が高い場合、プロキシはボトルネックになる可能性があり、大きな Top-K を持つベクターの検索、有効化されたパーティション・キー、出力フィールドにベクター自身を返すなど、ネットワーク集約的なタスクを実行する。
この問題を解決するには?
この問題に対処するには、単純にProxyを垂直方向(ホスト上でより多くのCPU/メモリを使用する)または水平方向(前面にロードバランサーを持つProxyポッドを追加する)に拡張します。
クエリノード
パフォーマンスがQueryNodeのCPU使用率によって制限されている場合、いくつかの原因が考えられます。
QueryNoteのパフォーマンスボトルネックの確認方法](https://assets.zilliz.com/12_how_to_check_query_note_perf_abd7d33a5a.png)
以下のようにQueryNodeのCPU使用率が100%になった場合、デリゲータが原因である可能性があります。
ポッドのCPU使用率](https://assets.zilliz.com/13_pod_cpu_usage_58a26a5854.png)
Milvusにおけるデリゲータの役割は部隊長のようなものである。検索リクエストがProxyにヒットすると、Proxyはまずデリゲータにリクエストをリダイレクトし、次に他のQueryNodeにリダイレクトして各セグメントで検索を開始する。検索結果は逆の順序で返される。QueryNodeがデリゲータであるかどうかは、以下を選択することで確認できます:クエリ・ノード > DML 仮想チャネル」を選択することで、クエリ・ノードがデリゲータであるかどうかを確認できます。
DML 仮想チャネル](https://assets.zilliz.com/14_SML_virtual_channel_020e560680.png)
セグメントの全体的な分布を観察するには、ダッシュボードで Query > Segment Loaded Num を選択します。
セグメントロード数](https://assets.zilliz.com/15_segment_loaded_num_4bc99537ec.png)
この問題を解決するには?
挿入したデータ量に対して、これほど多くの QueryNode を持つ必要がありますか?QueryNodes の数が多すぎると、デリゲータが処理しなければならないメッセージの数が増えるため、パフォーマンスが低下する可能性があります。そのため、QueryNodeの数を減らすことで、デリゲータの負担を軽減することができます。
さらに、QueryNodeの垂直スケーリングについて考えてみましょう。これは、CPUやメモリなど、QueryNodeを収容する単一のポッドまたはインスタンスの計算リソースを強化することを含みます。この調整により、デリゲータが管理するメッセージの負荷を増やすことなく、処理能力を大幅に向上させることができます。
静的データベースを保持している場合、デリゲータがセグメントを検索せず、リクエストの分散と結果の削減に集中するように、他のQueryNodeへのセグメントを手動でバランスさせることで、この問題を軽減できます。そのためには
1.Milvus YAML ファイルの autoBalance をオフにする。
2.SDK から LoadBalance API を呼び出す。参考: クエリ負荷のバランス
autoBalanceがオフで、新しいベクターがデータベースに挿入された場合、再度LoadBalance` をトリガーする必要があるかもしれません。
**Note: 上記をすべて実行してもデリゲータがボトルネックになる場合は、issueを提出するか、私たちに直接連絡してください。
インデックスノード
IndexNote の CPU 使用率が 100% になるのは、主に IndexNode がインデックスを構築しているためです。検索要求に対する緊急の時間的制約がなく、新しいデータの流入が一時的に停止している場合、IndexNode にインデックス構築プロセスを完了させることが推奨されます。このアプローチにより、検索操作が開始される前にすべてのインデックスが正常に構築されることが保証されます。システムへのデータ挿入と同時に検索クエリを実行すると、検索パフォーマンスが著しく低下する可能性があります。劣化の程度は、ベクターの挿入方法や、挿入直後に新しく挿入されたベクターが返されることを望むかどうかなど、いくつかの要因に依存します。
この問題を解決するには?
影響を最小限に抑えるためのヒントをいくつか紹介します:
1.可能であれば、ベクターを1つずつ挿入するのではなく、一括挿入を使用する。これにより、ネットワーク通信を減らし、セグメントを「成長」させるプロセスを省略することができます。したがって、挿入処理と検索が高速化される。詳細については、bulk insert documentation を参照してください。
2.視認性が重要でない場合は、以下のようにすることを推奨する:
1.https://milvus.io/docs/search.md のように、検索パラメーターに ignore_growing を渡す。
2.検索APIコールの一貫性レベルを Eventually に変更する。整合性レベルについては、https://milvus.io/docs/consistency.md を参照。
その他のコンポーネント
Milvusのアーキテクチャの中で、MixCoord、DataNodeなどのコンポーネントはそれぞれのタスクを効率的に処理するように設計されており、デフォルトの状態では検索操作の制限要因になることはほとんどありません。しかし、モニタリングの結果、CPU使用率がフル稼働に近づき、潜在的なボトルネックになっていることが判明した場合、これらのコンポーネントをスケールアップするための早急な対策が必要となる。
3 使用している Milvus のバージョンを確認する。
Milvus 2.3.x以降のバージョンを使用している場合は、このステップをスキップしてください。
Milvus 2.2.xおよびそれ以前のバージョンでは、CPUリソースの消費量を見積もることができます。しかし、この機能はパフォーマンスの問題を引き起こす可能性があるため、Milvus 2.3.x以降のバージョンでは削除されています。
下図のY軸はCPU数とパーセンテージの積を表しており、例えば12CPUのフル稼働はY軸上に1200と表示されます。
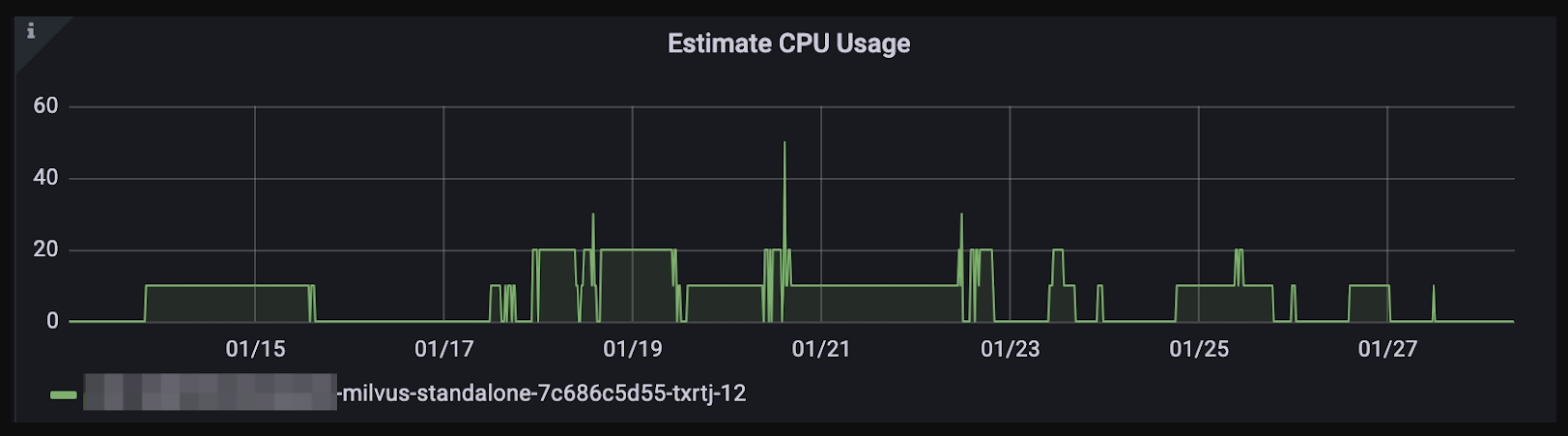 CPU使用率の見積もり
CPU使用率の見積もり
重要な注意: この見積もりでは、CPUの混み具合が不正確に認識されることがあり、実際のCPU使用率が低いにもかかわらず、タスクがキューイングされることがあります。
この問題を解決するには?
queryNode.scheduler.cpuRatio`を低い値(デフォルトは10.0)にチューニングする。
4 ディスクパフォーマンスのチェック
インデックス作成時にDiskANNを選択した場合は、ディスクのパフォーマンスをチェックする。
インデックスタイプが DiskANN の場合は NVMe SSD を推奨します。SATA SSD や HDD 上でのディスク・インデックスの構築と検索は、I/O 操作によって大きく制限される可能性があり、レイテンシが大きく QPS が低くなります。
ディスクのパフォーマンスをチェックするには、fio や同様の I/O ベンチマークツールを実行して IOPS をテストすることができる。NVMe SSDは約500k IOPSのはずだ。
# 書き込みテスト
fio -direct=1-iodepth=128 -rw=randwrite -ioengine=libaio -bs=4K -size=10G -numjobs=10 -runtime=600 -group_reporting -filename=/fiotest/test -name=Rand_Write_IOPS_Test
# 読み取りテスト
fio --filename=/fiotest/test --direct=1 --rw=randread --bs=4k --ioengine=libaio --iodepth=64 --runtime=120 --numjobs=128 --time_based --group_reporting --name=iops-test-job --eta-newline=1 --readonly
GrafanaでポッドレベルのIOPSを読み取るには:
1.右上の Pod をクリックし、Kubernetes / Compute Resources / Pod; V2 Dashboard の場合は、Milvus2.0 をクリックします。
Kubernetesコンピュートリソース](https://assets.zilliz.com/17_kubernetes_compute_resource_aeacad021b.png)
2.検査したいポッドを選択します:
CPU使用率](https://assets.zilliz.com/18_CPU_Usage_ac0178981b.png)
3.下にスクロールして、Storage IO を探す。
ストレージIO](https://assets.zilliz.com/19_Storage_IO_851bc9c60a.png)
この問題を解決するには?
現在のセットアップのレイテンシを減らすために、SATA SSDやHDDからNVMe SSDへのアップグレードを検討してください。AWSのような多くのクラウドプロバイダーは、NVMe SSDストレージオプションを提供しています。例えば、m6シリーズのAWS m6idインスタンスには、ローカルのNVMeベースのSSDが搭載されている。しかし、EBSはNVMeドライバを採用しているものの、ローカルのNVMe SSDのような低レイテンシのメリットは得られないことに注意する必要がある。
ディスク指標に関しては、NVMe SSDを選択することを強くお勧めします。しかし、すでにSATA SSDまたはHDDをお持ちの場合は、RAID(Redundant Array of Independent Disks)セットアップで構成することで、レイテンシを低減することができます。
5 帯域幅の確認
帯域幅の制限は、しばしばシステム内の重要なボトルネックとして現れることがあり、意図的に考慮しなければすぐにはわからないような問題を引き起こすことがあります。間接的な影響として、システム・パフォーマンスを向上させる努力にもかかわらず QPS(Queries Per Second)が停滞したり、gRPC などの操作の実行時間が予想外に長引いたりすることがあります。
このようなシナリオにおける帯域幅の役割を理解することは、パ フォーマンスの制限を診断し、対処する上で極めて重要である。たとえば、クエリ次元が1024でTopKが100に設定されたKNN検索リクエストでは、各リクエストがクライアントとプロキシ間の双方向通信に約4.8KBを消費する可能性がある。QPSが1000の場合、約4.7MBのデータがチャネルを流れることになる。したがって、QPSの上限を設定しないためには、帯域幅は少なくとも37 Mbpsを維持できる必要がある。
ワークフロー](https://assets.zilliz.com/20_workflow_97fd64a176.png)
これは当初は重要でないように思えるかもしれないが、より高いQPSを目指したり、 出力フィールドにベクターを含めると、必要な帯域幅が劇的に増加する可能性がある。たとえば、ベクターを含める必要がある場合、前述の例で は、必要帯域幅は少なくとも3Gbpsに跳ね上がります。
計算は面倒ですが、Grafanaのようなモニタリングツールを使えば、インバウンドとアウトバウンドの帯域幅をチェックして、システムパフォーマンスを効果的に評価することができます。
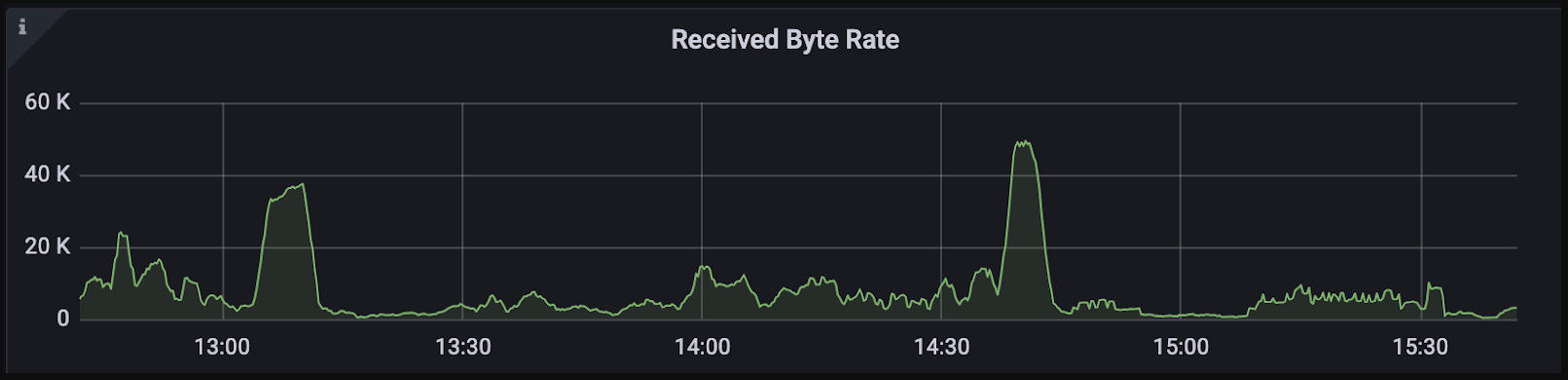 受信バイトレート
受信バイトレート
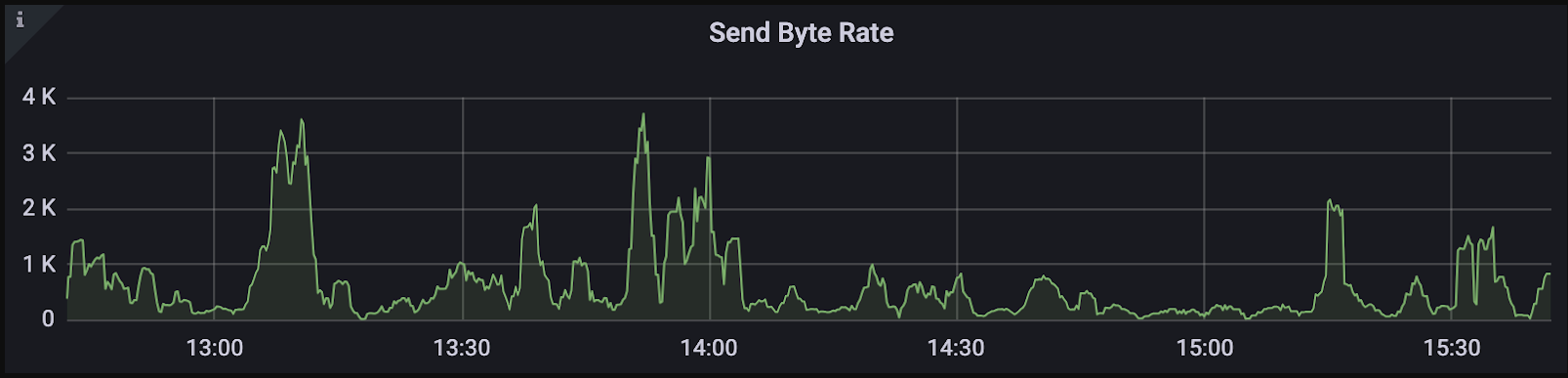 送信バイトレート
送信バイトレート
注意: Milvusをクラスタモードで展開する場合は、Milvusポッド内のポッド間の帯域幅を確認することを忘れないでください。
以下のグラフは他のポッドをチェックする際のプロキシのネットワーク使用量のみを示しています。ポッドの使用状況に移動すると表示されます:
帯域幅](https://assets.zilliz.com/23_bandwidth_588eb4faa6.png)
問題を解決するには?
- 帯域幅を増やす**。
帯域幅の制限に対処するには、クラウドコンソールを通じて帯域幅を増やすか、クラウドプロバイダーまたはDevOpsチームに連絡して支援を受けることを検討してください。
- 圧縮をオンにする
Milvusでは、Milvus内のコンポーネント間およびMilvusとSDKクライアント間のgRPC圧縮を実装できる新機能を構築中です。エンコード、デコード処理によりCPU使用率が高くなる可能性がありますが、圧縮することでデータ量を大幅に削減することができます。この機能はMilvus 2.4.xで利用可能になる予定です。
6 ベンチマーククライアントのチェック
蛇口が太いパイプにゆっくりと水を垂らすシナリオを考えてみましょう。蛇口からの流量がわずかであれば、パイプを容量いっぱいに満たすことはできません。同様に、クライアントが1秒間に数回しかリクエストを送信しない場合、より大量のデータを効率的に処理するように設計されているMilvusの機能をフルに活用することはできません。クライアントがボトルネックになっているかどうかを調べるには、次のようにしてみてください:
同時実行数を増やし、違いがあるかどうかを確認する。
異なるマシン/ホスト上で複数のクライアントを起動する。
問題を解決するには?
クライアントがパフォーマンスのボトルネックになっている場合は、リクエスト数を増やしてみてください。
1.データ・フローを制限している可能性のあるネットワーク・リミッターを見直して調整する。
2.PyMilvusを使用している場合
1.マルチプロセッシングでは fork の代わりに spawn を使う。
2.各プロセスで、from pymilvus import connections をインポートし、connections.connect(args) を実行する。
3.QPS が変化しなくなるまでクライアントを増やす。
お問い合わせ
このガイドにより、Milvusのパフォーマンスがお客様のニーズに完璧に合致するようターボチャージされたことを確信しております!しかし、パフォーマンスのボトルネックが特定できなかったり、そのような問題に対処するためのサポートが必要な場合は、遠慮なくご連絡ください。そのような課題を克服するために、私たちがお手伝いさせていただきます!
連絡先
GitHub Issue の提出](https://github.com/milvus-io/milvus/issues)
GitHub ディスカッションに参加する](https://github.com/milvus-io/milvus/discussions)
Milvus Discord コミュニティに参加する](https://discord.com/invite/8uyFbECzPX)
 Patrick Xu
Patrick XuSenior Software Engineer


