




Milvus: RAG開発の鍵 - 効率の改善、コストの削減、パフォーマンスの向上
#はじめに
前回のブログ](https://zilliz.com/blog/vector-database-are-the-base-of-RAG-retrieval)では、RAG(Retrieval Augmented Generation)が、幻覚やドメイン固有情報の必要性といった大規模言語モデル(LLMs)が直面する課題にどのように対処しているかを見てきた。また、データのプライバシーを確保し、リアルタイムの情報検索を可能にする役割も強調した。
基本的なRAGフレームワークの中心には、レトリーバーとジェネレーターという2つの重要な要素がある。Retrieverはvector databaseによって駆動され、ユーザのクエリにコンテキスト情報を提供する。一方、GeneratorはChatGPTのようなLLMによって駆動されることが多く、このコンテキストに基づいて最終的な応答を作成する。これらの技術的な側面を理解することで、RAGの複雑さについてより深く知ることができるでしょう。
開発者がRAGアプリケーションの限界を押し広げ、本番環境に移行するにつれ、より速く、より高品質で、より正確な回答が必要となります。このことは、検索効率と検索品質の向上を可能にする堅牢なベクターデータベースの重要性を強調しています。
最新リリースのMilvusは、ベクトルデータベース技術、特にRAG性能の向上において、注目すべき進歩を示している。本記事では、Milvusの最新機能を紹介し、その機能性に焦点を当て、RAGアプリケーションの開発においてMilvusが最高の選択肢である理由を説明します。
一般的なエンベッディングおよびレンランキングモデルとの統合によるRAG開発と検証の合理化
プロトタイピングや小規模なプロジェクトでは基本的なRAGのセットアップで十分ですが、量産可能なアプリケーションでは不十分です。開発者は、より複雑なRAGアプリケーションに進むにつれて、パイプラインに追加の技術コンポーネントを組み込み、開発の複雑さを増していきます。さらに、RAG関連技術の急速な進化とパラメータのバリエーションは、アプリの構築、微調整、検証にさらなるハードルを加えている。これらの課題に対処するために、多くのRAG開発者はLangChain、LlamaIndex、DSPyのようなフレームワークやライブラリを利用しています。これらは、合理化された開発と検証のための広範な機能を提供しています。
Milvusは、効率的なデータの保存と検索を可能にする、特殊なベクトルデータベースです。最新のリリースでは、Milvusは主流の埋め込みと再ランク付けモデルをシームレスに統合しており、ユーザはRAGパイプラインに埋め込みと再ランク付けのコンポーネントを追加することなく、テキストを検索可能なベクトルに簡単に変換し、より正確な回答のために検索結果を再ランク付けすることができます。その結果、この統合はRAGの開発と検証プロセス全体を合理化します。
Milvusは現在、OpenAI Embedding API, sentence transformers, BGE-M3, BM25, SPLADE, Voyage AI などの一般的なエンベッディングをサポートしています。
| ------------------------------- | --------------- | ---------------------- |
| OpenAI Embedding API|密|API||。 | 文の変換|密|オープンソース|BM25 | BM25|スパース|オープンソース | SPLADE|スパース|オープンソース | BGE-M3|ハイブリッド|オープンソース | ボヤージュAI|密|API|オープンソース
Milvusは現在、以下のリランキングモデルをサポートしています:BGE、Cross-encoder、Voyage AI、Cohere。
| ------------------------------- | ----------------------- | | 統合リランキング・モデル|APIまたはオープンソース||BGEリランカー|APIまたはオープンソース*||BGEリランカー|APIまたはオープンソース | BGEリランカー|オープンソース | クロスエンコーダ|オープンソース||Voyage AI rerankers | Voyage AIリランカー|API|オープンソース
今後数ヶ月でさらに多くのモデルをサポートする予定です。ご期待ください。Milvusドキュメント](https://milvus.io/docs/embeddings.md)は、これらの事前訓練された埋め込みモデルを活用するための詳細なガイダンスを提供しています。
ハイブリッド検索による検索品質の向上とマルチモーダルデータ検索
実世界のRAGアプリケーションは、テキストや画像、動画、音声などのマルチモーダルデータを扱う様々なユースケースで使用されています。豊富な情報を扱うには、マルチモーダルなクエリに対応するために、様々なデータタイプにまたがる埋め込みデータを効率的に格納・検索するベクトルデータベースが必要です。
Milvusは、マルチベクトル対応とハイブリッド検索フレームワークを提供することで、この課題に取り組みます。ユーザーは最大10個までの複数のベクトルフィールドを1つのコレクションに統合することができる。これらのフィールドのベクトルは、同じエンティティに関連するデータの異なる側面やモダリティを表すことができ、情報プールを大幅に豊かにする。
図1:Milvusのハイブリッド検索方法](https://assets.zilliz.com/How_Milvus_conducts_a_hybrid_search_290d37900d.png)
このハイブリッド検索機能とミックス・リランキング戦略は、マルチモーダルかつ多次元的な情報を検索する際の柔軟性を向上させる。写真、音声、指紋などの属性に基づき、ベクトル・ライブラリの中で最も類似した個人を特定するようなユースケースにおいて、非常に貴重なものとなる。
さらに、Milvusはハイブリッド検索を拡張し、領域外の知識やキーワード検索に広く利用されているスパースベクトルをサポートする。この拡張により、キーワード検索とベクトル埋め込み検索の混在検索が可能となり、より精度の高い検索結果が得られ、最終的なRAGアプリケーションの回答生成精度が向上します。
改良されたスカラーフィルター検索による検索速度と精度の向上
実用的なアプリケーションでは、すべてのデータがベクトル検索に適しているわけではありません。例えば、衣類の在庫に焦点を当てたチャットボットを考えてみよう。ベクトルだけでなく、データには色やサイズなど多数の属性が含まれている。このようなスカラーデータをベクトル検索の前または後にフィルタリングすると、ベクトルに変換するよりも効率的で迅速であることがわかる。
Milvusはスカラーフィルター検索をサポートし、検索の精度とスピードを強化します。この機能の最近のアップグレードは以下の通りです:
グルーピング検索機能**](https://milvus.io/docs/single-vector-search.md#Grouping-search):この機能はスカラーカラム集計を利用し、洗練されたハイレベルな集計データを提供します。特に、クエリに関連する特定の数の文書を検索するようなユースケースにおいて、検索を効率化します。
スカラー列のファジーマッチング**](https://milvus.io/docs/release_notes.md#Inverted-Index-and-Fuzzy-Match):スカラー列に対するファジー検索は、接尾辞と接尾辞マッチングを含むようになり、これまでサポートされていた接頭辞マッチングよりも検索品質が向上しました。
検索速度を加速する転置インデックス](https://milvus.io/docs/release_notes.md#Inverted-Index-and-Fuzzy-Match):転置インデックスの導入により、逆引き検索のユースケースにおいて10倍**以上のパフォーマンス向上が期待できます。
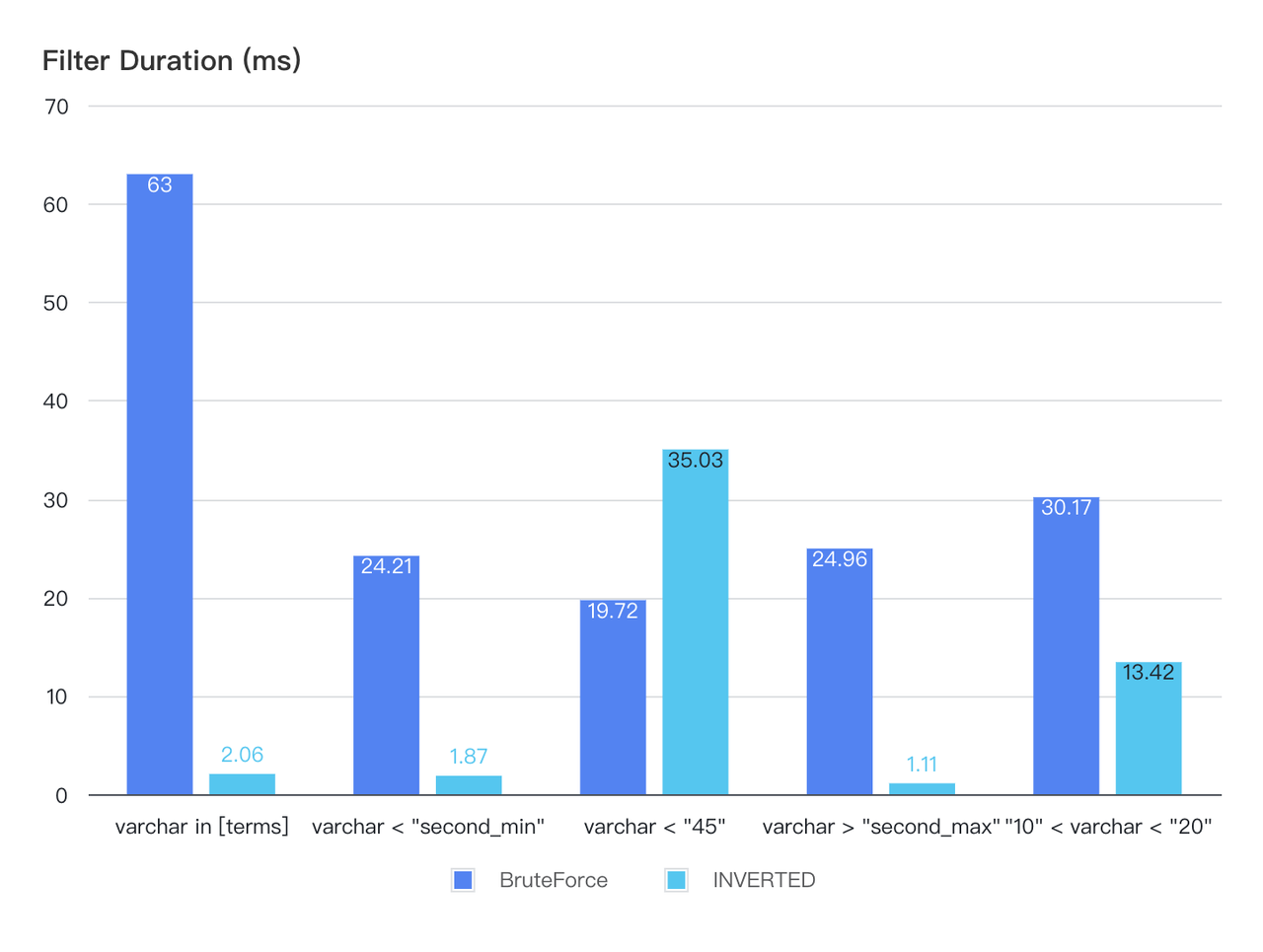 図2: インバーテッドインデックスで検索速度が10倍向上
図2: インバーテッドインデックスで検索速度が10倍向上
これらの機能強化により、RAGシステムは特定のビジネス要件に合わせたアプローチを行うことができます。例えば、ユーザーは事件の日付に基づいて法律文書を効率的に検索したり、地理的な場所によって関連する報道をフィルタリングすることができます。この多次元検索アプローチは、RAGアプリケーションの精度と効率性を向上させ、的を絞ったクエリを処理します。
コスト効率に優れたRAGソリューションの提供
RAGアプリケーションのために大規模なナレッジベースを構築し、維持することは、主にデータセットが拡大し続けるため、財政的に高くつく可能性があります。そのため、膨大なデータの管理を容易にする費用対効果の高いソリューションが必要とされています。
Milvusは、Apache-2.0ライセンスに基づくオープンソースのベクターデータベースとして、ライセンスコストのかからない費用対効果の高いソリューションを提供します。その一連の高性能な機能は、追加コストなしですぐに利用できる。
さらに、MilvusはMmapを統合し、メモリ消費を最小限に抑え、リソースの割り当てを最適化します。Milvusは、アクセス頻度やレイテンシ要件が異なるデータに対応するために、階層化されたコールドおよびホットデータストレージ機能を導入し、さらに一歩進んでいます。Milvusは、RAM、NVMe、EBS、S3などの異なるストレージメディアにデータを戦略的に配置し、クラウドストレージ機能を活用することで、ストレージコストを削減します。インテリジェントなキャッシングとデータシャーディング技術は、クエリ時のリソース効率にさらに貢献し、Milvusを搭載したRAGアプリケーションは、パフォーマンスを損なうことなく、より低いコストで運用することができます。
図3:階層化されたコールド・データ・ストレージとホット・データ・ストレージの仕組み](https://assets.zilliz.com/Fig3_How_the_tiered_cold_and_hot_data_storage_approach_work_32356d1342.png)
このアプローチにより、初期投資を最小限に抑え、継続的な運用効率を確保することができるため、Milvusはコスト重視のRAG導入に理想的な選択肢となります。
要約
一般的なエンベッディングモデルとの統合から、マルチモーダルデータ検索やアップグレードされたスカラーフィルタ検索に至るまで、Milvusベクトルデータベースは、開発者がこれまで以上に迅速かつ正確で汎用性の高いRAGアプリケーションを構築できるよう支援します。
さらにMilvusは、オープンソースの魂、高性能な機能、最適化されたストレージ戦略により、大規模なナレッジベースを構築・維持するための費用対効果の高いソリューションを提供します。メモリ消費を最小限に抑え、階層型データストレージを実装し、インテリジェントなキャッシングとデータシャーディング技術を活用することで、Milvusはパフォーマンスを犠牲にすることなく、低コストで効率的なRAGアプリケーションの運用を可能にします。
結論として、Milvusは、より速く、より正確で、コスト効率の高いアプリケーションを構築するためのツールを開発者に提供することで、RAG開発を変革します。Milvusにより、RAGイノベーションの可能性は無限に広がり、情報検索の未来はこれまで以上に明るいものとなるでしょう。

読み続けて

3 Easiest Ways to Use Claude Code on Your Mobile Phone
Run Claude Code from your phone with Remote Control, Happy Coder, or SSH + Tailscale. Comparison table, setup steps, and tools for typing, memory, and parallel tasks.

Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens
Learn how vector-based code retrieval cuts Claude Code token consumption by 40%. Open-source solution with easy MCP integration. Try claude-context today.

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.