




Exploring DSPy and Its Integration with Milvus for Crafting Highly Efficient RAG Pipelines
Introduction
Large language models (LLMs) possess transformative generative capabilities and are augmented with tools such as knowledge bases and retrievers, fueling advanced GenAI applications like chatbots and agents. Central to interacting with LLMs are prompts, which are instructions that guide these models to perform specific tasks. However, crafting effective prompts is a nuanced and intricate process, often requiring sophisticated techniques such as Chain-of-Thought and ReAct. With that added, prompts are becoming more and more complex. Moreover, even identical prompts can yield divergent results across different LLMs, such as GPT-4 and Gemini, due to variations in their pre-training methods and datasets. This challenge has spurred a surge of interest in Prompt Engineering—a labor-intensive task focused on tweaking and optimizing prompts for better and tailored results.
While manual prompt crafting works fine for simple LLM applications, it becomes frustrating and time-intensive for complex LLM-based pipelines involving multiple components. DSPy represents a paradigm shift in how developers interact with language models by introducing a programmable interface enabling algorithmic optimization of model prompts and weights, leading to more efficient language model development. DSPy has seamlessly integrated the Milvus vector database, automating the optimization of Retrieval Augmented Generation (RAG) applications using a programmatic approach.
In the following sections, we’ll explore the essence of DSPy and its operational mechanics and provide a practical example demonstrating how to construct and optimize a RAG application using DSPy and the Milvus vector database.
What is DSPy?
DSPy, introduced by the Stanford NLP Group, is a programmatic framework designed to optimize prompts and weights in language models, which is particularly useful when LLMs are integrated across multiple pipeline stages. It provides various composable and declarative modules for instructing LLMs in Pythonic syntax.
Unlike traditional prompting engineering techniques that rely on manually crafting and tweaking prompts, DSPy learns query-answer examples and imitates this learning to generate optimized prompts for more tailored results. This approach allows for the dynamic reassembly of the entire pipeline, explicitly tailored to the nuances of your task, thus eliminating the need for ongoing manual prompt adjustments.
Key Concepts and Fundamental Components
In DSPy, three foundational elements—Signatures, Modules, and Optimizers (formerly referred to as Teleprompters)—form the core building blocks for automated prompt optimization and model fine-tuning.
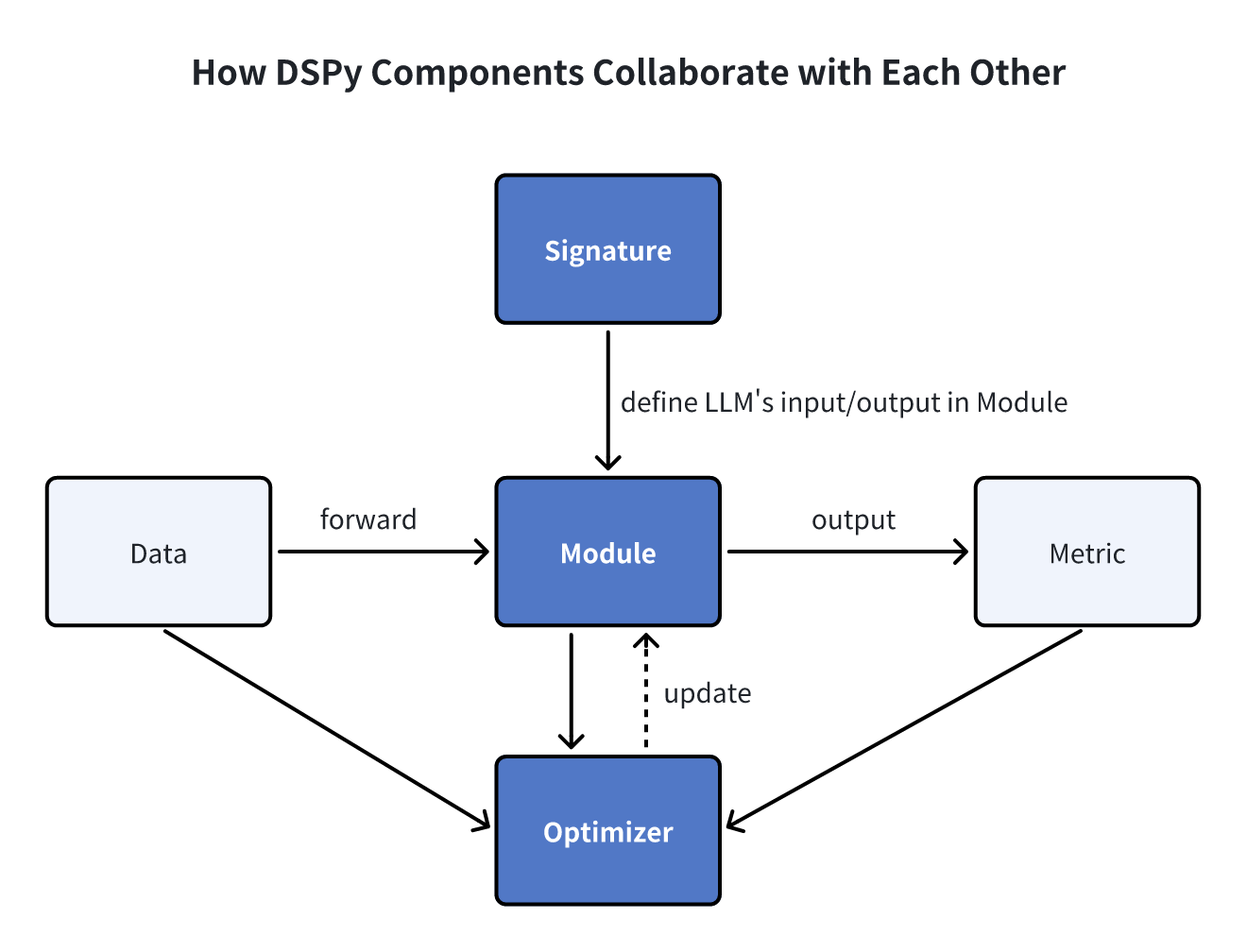
Signatures
Signatures are declarative specifications defining the input/output behavior of a DSPy module. They tell the language model what tasks it should execute rather than how we should prompt the language model.
- A signature comprises three essential elements:
- A concise description of the sub-task the language model aims to solve.
- A description of one or more input fields (e.g., input questions) that we give to the language model.
- A description of one or more output fields (e.g., answers to questions) that we expect from the language model.
Here are examples of signatures for popular LLM tasks:
- Question Answering:
"question -> answer" - Sentiment Classification:
"sentence -> sentiment" - Retrieval Augmented Question Answering:
"context, question -> answer" - Multiple-Choice Question Answering with Reasoning:
"question, choices -> reasoning, selection"
These signatures guide DSPy in efficiently orchestrating LLM operations within various modules, fostering streamlined and precise task execution.
Modules
DSPy modules abstract conventional prompting techniques within an LLM pipeline. They have three key characteristics:
- Each built-in module abstracts a specific prompting technique (such as Chain of Thoughts or ReAct) and handles DSPy Signatures.
- DSPy modules have learnable parameters, including prompt components and LLM weights, enabling them to process inputs and generate outputs.
- DSPy modules can be combined to create larger, more complex modules.
- DSPy provides seven built-in modules for various purposes, including
dspy.ReAct,dspy.ChainofThought,dspy.Predict,dspy.ProgramOfThought,dspy.ReAct,dspy.MultiChainComparisonanddspy.Retrieve.
Optimizers
DSPy Optimizers, formerly Teleprompters, are algorithms designed to fine-tune the parameters of a DSPy program—such as prompts and LLM weights—to maximize specified metrics like accuracy. A typical DSPy optimizer requires three inputs:
Your DSPy program: can be a single module (e.g.,
dspy.Predict) or a complex multi-module program.Your chosen metric: a function that evaluates the program's output and assigns it a score (higher scores denote better results).
A small set of training inputs: often just 5 to 10 examples.
Once you define your training data, modules, and metrics, the optimizer optimizes the LLM weights, prompt instructions, and few-shot demonstrations to enhance program efficiency. For instance, the BootstrapFewShot optimizer generates answers that align with the specified metric, while modules like COT (Chain of Thought) generate structured reasoning to arrive at accurate answers. DSPy records these successful instances and rationales as few-shot demonstrations for handling future test queries.
In addition to the core building blocks mentioned above, DSPy incorporates data, metrics, and assertions as supplementary components, enriching its functionality and adaptability. Refer to DSPy documentation for more details.
DSPy Workflows: Building Efficient LLM Pipelines
How exactly does DSPy function in constructing LLM pipelines? For clarity, we can break down the process into several key steps.
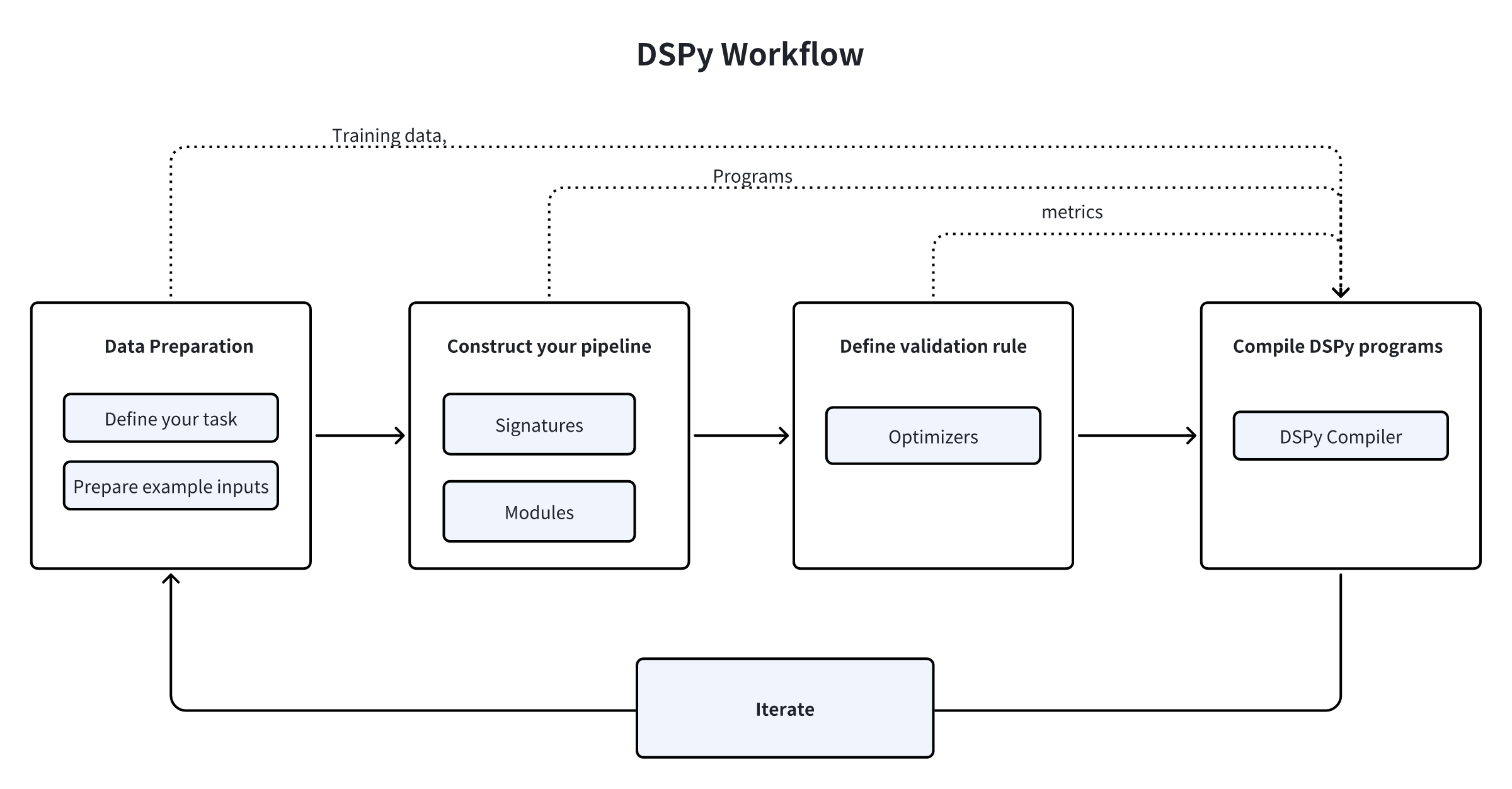
- First, you must define your task and prepare a few example inputs—often without labels (or solely with labels for the final outputs, if your metric requires them).
- Second, construct your pipeline by choosing from the built-in modules, assigning each module a signature (input/output specification), and seamlessly incorporating these modules into your Python code.
- Third, define the validation logic for your pipeline, including what metrics and example inputs to use to evaluate the quality of prompts and the final results.
- Fourth, compile your code using a DSPy optimizer, which generates high-quality instructions, automatic few-shot examples, or updated LLM weights.
- Finally, engage in an iterative process of refining your dataset, program, or validation logic to achieve the desired performance level for your pipeline. Continuously assess and improve to meet evolving requirements and optimize results.
DSPy vs. LlamaIndex/LangChain/AutoGPT
DSPy stands out with its approach compared to many other popular AI frameworks like LangChain, LlamaIndex, and AutoGPT. Here's a closer look at how they differ and align:
LangChain is a toolkit for creating customized applications. It leverages various language models and utility packages, allowing developers to tailor applications to specific needs.
LlamaIndex is an orchestration framework designed to streamline the integration of various private data sources with language models. It simplifies data handling and processing tasks.
AutoGPT is an advanced AI agent powered by GPT-4 and GPT3.5. It is programmed to make decisions and take actions based on predefined rules and goals. It emphasizes autonomy and decision-making capabilities.
DSPy's distinctive features:
- DSPy optimizes and automates prompt construction for enhanced interaction with language models.
- Unlike LangChain and LlamaIndex, which cater to high-level application development with pre-built modules, DSPy provides powerful and general-purpose modules capable of learning to prompt or fine-tune LLMs within custom pipelines. DSPy's strength lies in its ability to dynamically adapt prompts and fine-tune LLMs based on changing data, program control flow adjustments, or target language variations. This automated optimization process can lead to superior-quality outputs with minimal effort, especially when developers are open to scaling their simple or prototyping programs into more sophisticated ones for production purposes.
- DSPy is ideal for use cases requiring a lightweight yet automatically optimizing programming model rather than relying on predefined prompts and integrations offered by libraries like LangChain and LlamaIndex.
DSPy Integration with Milvus Vector Database
Milvus is a highly flexible, reliable, and blazing-fast cloud-native, open-source vector database. It powers vector similarity search and is particularly beneficial in building various GenAI and Retrieval Augmented Generation (RAG) applications.
Milvus has been integrated into the DSPy workflow as a retrieval module in the form of the MilvusRM Client, making it easier to implement a fast and efficient RAG pipeline.
Building a RAG Application with DSPy and Milvus
Retrieval Augmented Generation (RAG) is a method that empowers LLMs to access external knowledge repositories, search these repositories for contextual information relevant to user queries, and generate refined responses.
In this demonstration, we'll build a simple RAG application using GPT-3.5 (gpt-3.5-turbo) for answer generation. We use Milvus as the vector store through MilvusRM and DSPy to configure and optimize the RAG pipeline.
Prerequisites
Before building the RAG app, install the MilvusRM Client and Milvus.
- To Install MilvusRM, run the following code.
pip install dspy-ai[milvus]
- Install Milvus. Refer to the Milvus documentation for detailed instructions.
Loading the dataset
In this example, we use the HotPotQA, a collection of complex question-answer pairs, as our training dataset. We can load them through the HotPotQA class.
from dspy.datasets import HotPotQA
# Load the dataset.
dataset = HotPotQA(train_seed=1, train_size=20, eval_seed=2023, dev_size=50, test_size=0)
# Tell DSPy that the 'question' field is the input. Any other fields are labels and/or metadata.
trainset = [x.with_inputs('question') for x in dataset.train]
devset = [x.with_inputs('question') for x in dataset.dev]
Import data into the Milvus vector database
Ingest the context information into the Milvus collection for vector retrieval. This collection should have an embedding field and a text field. We use OpenAI's text-embedding-3-small model as the default query embedding function in this case.
import requests
MILVUS_URI = "http://localhost:19530"
MILVUS_TOKEN = ""
from pymilvus import MilvusClient, DataType, Collection
from dspy.retrieve.milvus_rm import openai_embedding_function
client = MilvusClient(
uri=MILVUS_URI,
token=MILVUS_TOKEN
)
if 'dspy_example' not in client.list_collections():
client.create_collection(
collection_name="dspy_example",
overwrite= True,
dimension=1536,
primary_field_name="id",
vector_field_name="embedding",
id_type="int",
metric_type="IP",
max_length=65535,
enable_dynamic=True
)
text = requests.get('https://raw.githubusercontent.com/wxywb/dspy_dataset_sample/master/sample_data.txt').text
for idx, passage in enumerate(text.split('\n')):
if len(passage) == 0:
continue
client.insert(collection_name="dspy_example", data = [{"id": idx , "embedding": openai_embedding_function(passage)[0], "text": passage}])
Define MilvusRM.
Now, you need to define the MilvusRM.
from dspy.retrieve.milvus_rm import MilvusRM
import os
import dspy
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>"
retriever_model = MilvusRM(
collection_name="dspy_example",
uri=MILVUS_URI,
token=MILVUS_TOKEN, # ignore this if no token is required for Milvus connection
embedding_function = openai_embedding_function
)
turbo = dspy.OpenAI(model='gpt-3.5-turbo')
dspy.settings.configure(lm=turbo)
Building signatures
Now that we have loaded the data, let's start defining the signatures for the sub-tasks of our pipeline. We can identify our simple input question and output answer, but since we are building a RAG pipeline, we’ll retrieve contextual information from Milvus. So let's define our signature as context, question --> answer.
class GenerateAnswer(dspy.Signature):
"""Answer questions with short factoid answers."""
context = dspy.InputField(desc="may contain relevant facts")
question = dspy.InputField()
answer = dspy.OutputField(desc="often between 1 and 5 words")
We include short descriptions for the context and answer fields to define clearer guidelines on what the model will receive and should generate.
Building the pipeline
Now, let's define the RAG pipeline.
class RAG(dspy.Module):
def __init__(self, rm):
super().__init__()
self.retrieve = rm
# This signature indicates the task imposed on the COT module.
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
def forward(self, question):
# Use milvus_rm to retrieve context for the question.
context = self.retrieve(question).passages
# COT module takes "context, query" and output "answer".
prediction = self.generate_answer(context=context, question=question)
return dspy.Prediction(context=[item.long_text for item in context], answer=prediction.answer)
Executing the pipeline and getting the results
Now, we’ve built this RAG pipeline. Let's try it out and get results.
rag = RAG(retriever_model)
print(rag("who write At My Window").answer)
# The result:
# 'Townes Van Zandt'
We can evaluate the quantitative results on the dataset.
from dspy.evaluate.evaluate import Evaluate
from dspy.datasets import HotPotQA
evaluate_on_hotpotqa = Evaluate(devset=devset, num_threads=1, display_progress=False, display_table=5)
metric = dspy.evaluate.answer_exact_match
score = evaluate_on_hotpotqa(rag, metric=metric)
print('rag:', score)
# The result:
# rag: 50.0
Optimizing the pipeline
After defining this program, the next step is compilation. This process updates the parameters within each module to enhance performance. The compilation process depends on three critical factors:
- Training Set: We'll utilize the 20 question-answer examples from our training dataset for this demonstration.
- Validation Metric: We will establish a simple
validate_context_and_answermetric. This metric verifies the accuracy of the predicted answer and ensures that the retrieved context includes the answer. - Specific Optimizer (Teleprompter): DSPy's compiler incorporates multiple teleprompters designed to optimize your programs effectively.
from dspy.teleprompt import BootstrapFewShot
# Validation logic: check that the predicted answer is correct.
# Also check that the retrieved context does contain that answer.
def validate_context_and_answer(example, pred, trace=None):
answer_EM = dspy.evaluate.answer_exact_match(example, pred)
answer_PM = dspy.evaluate.answer_passage_match(example, pred)
return answer_EM and answer_PM
# Set up a basic teleprompter, which will compile our RAG program.
teleprompter = BootstrapFewShot(metric=validate_context_and_answer)
# Compile!
compiled_rag = teleprompter.compile(rag, trainset=trainset)
# Now compiled_rag is optimized and ready to answer your new question!
Now, let’s evaluate the compiled RAG program.
score = evaluate_on_hotpotqa(compiled_rag, metric=metric)
print(score)
print('compile_rag:', score)
# The result:
# compile_rag: 52.0
The evaluation score has increased from its previous value of 50.0 to 52.0, indicating an enhancement in answer quality.
Summary
DSPy marks a leap in language model interactions through its programmable interface, which facilitates algorithmic and automated optimization of model prompts and weights. By leveraging DSPy for RAG implementation, adaptability to varying language models or datasets becomes a breeze, drastically reducing the need for tedious manual interventions.
Moreover, DSPy introduces a MilvusRM retriever module within its workflow by integrating the Milvus vector database. With this new integration, developers can automate prompt optimization and model parameter adjustments within RAG applications for enhanced answer quality. If you’d like to learn more, check out the detailed guide to MilvusRM in the DSPy documentation!
References
DSPy GitHub page: https://github.com/stanfordnlp/dspy
DSPy paper: https://arxiv.org/pdf/2310.03714
DSPy documentation: https://dspy-docs.vercel.app/quick-start/installation/
MilvusRM guide: https://dspy-docs.vercel.app/docs/deep-dive/retrieval_models_clients/MilvusRM
Milvus Documentation: https://milvus.io/docs

Keep Reading

Expanding Our Global Reach: Zilliz Cloud Launches in Azure Central India
Zilliz Cloud expands to Azure Central India. This new region helps customers meet compliance, reduce latency, and optimize cloud costs when building AI applications.

Legal Document Analysis: Harnessing Zilliz Cloud's Semantic Search and RAG for Legal Insights
Enhance legal document analysis with Zilliz Cloud’s Semantic Search and RAG. Improve accuracy, efficiency, and scalability for contracts, case law, and compliance.

Why Deepseek is Waking up AI Giants Like OpenAI And Why You Should Care
Discover how DeepSeek R1's open-source AI model with superior reasoning capabilities and lower costs is disrupting the AI landscape and challenging tech giants like OpenAI.