




Zilliz Cloud Global Cluster のご紹介:ミッションクリティカルな AI のためのリージョンレベルのレジリエンス
ビジネスが複数の大陸にまたがって顧客にサービスを提供しているなら、AI システムをどこでも高速かつ信頼性の高い状態に保つプレッシャーを感じたことがあるでしょう。単一のクラウドリージョンの障害が、瞬時に顧客体験の障害へと発展する可能性があります。たとえば、ヨーロッパの買い物客が突然パーソナライズされたレコメンデーションを受け取れなくなるかもしれません。東南アジアの乗客はリアルタイムのマッチングを利用できなくなり、ブラジルの従業員は GenAI アシスタントがタイムアウトするのを目にすることになります。障害が地域的なものであっても、ビジネスへの影響は現実のものです — 収益の損失、ユーザーの不満、そして取り戻すのが難しい信頼の低下です。
だからこそ、私たちは Zilliz Cloud の Global Cluster を導入します — ベクトル検索ワークロードに真のリージョンレベルのディザスタリカバリを提供する、組み込みのグローバルクラスタリング機能です。Zilliz Cloud はまた、ネイティブなグローバルクラスタリングとクロスリージョンの耐障害性を提供する、業界初のベクトルデータベースでもあります。Global Cluster があれば、リージョン障害がビジネス障害になることはありません。トラフィックは、コード変更ゼロ、接続文字列の更新ゼロ、手動フェイルオーバーのランブックなしで、最寄りの正常なリージョンへ自動的に切り替わります。インフラが機能しない場合でも、AI アプリケーションはユーザーのいる場所で引き続き稼働します。
リージョン障害はまれです — しかし十分にまれではありません
ステートフルなシステムを大陸間で稼働させることは、分散インフラにおいて常に最も難しい課題の一つでした。グローバルな展開範囲が広がるにつれて、常にトレードオフを管理することになります。データを安全に保ち、あらゆるリージョンのユーザーに低レイテンシを維持し、エンジニアリングチームにとって運用を管理しやすく保つ ことです。ベクトルワークロードでは、その難しさはさらに増します — 埋め込みは大きく、更新は継続的で、検索クエリはレイテンシに極めて敏感です。
クラウドプロバイダーはリージョンの耐久性を高めるよう設計していますが、現実世界の障害を免れるリージョンはありません。光ファイバーの切断、冷却システムの不具合、または連鎖的なネットワーク問題によって、リージョン全体が予告なくオフラインになることがあります。そして真のクロスリージョン戦略がなければ、その障害は即座にあなたの障害になります。そのリージョンのサービスは停止し、スナップショットやコールドバックアップからの復旧には何時間もかかります — リアルタイムのユーザー体験を支える AI アプリケーションにとっては、あまりにも遅すぎます。
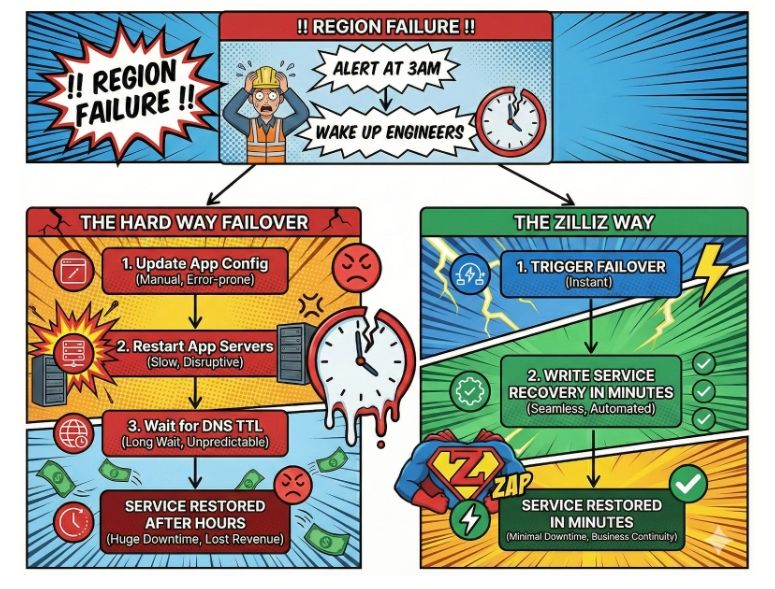
独自のマルチリージョンアーキテクチャを構築しようとするチームもあります。それは可能ではありますが、多くの場合、継続的な運用負担と障害時の高い調整コストという 2 つの大きな問題を生み出します。
保守と運用の負担: 日々の運用では、カスタムのレプリケーションスクリプト、自家製の同期パイプライン、デュアルライトロジックに、継続的なチューニングと慎重な監視が必要です。エンジニアは、採用された本来の仕事であるプロダクト開発ではなく、レプリケーション遅延やインデックスのずれの修正に追われることになります。
障害時の調整の摩擦: リージョンに障害が発生すると、隠れていた複雑さが一気に表面化します。手動フェイルオーバーはストレスが大きいだけではありません — 混乱そのものです。チームは、ダッシュボードが赤く点滅し、顧客がすでに影響を受けている中で、サービスの再起動、DNS の更新、データの鮮度確認、設定のずれの解消、そして経営層への対応を同時に行わなければなりません。これらはまさに、チームが避けたいと願う瞬間です。
Zilliz Cloud Global Clusters: グローバルに管理し、シンプルに運用する
大陸をまたいで AI システムを稼働させることは、多くの場合、リージョンクラスター、ばらばらのエンドポイント、カスタムのルーティングルール、そして実際のインシデント時にはうまく機能しないフェイルオーバープレイブックをやりくりすることを意味します。Zilliz Cloud Global Clusters は、そのようなオーバーヘッドをすべて取り除きます。 北米、ヨーロッパ、APAC にまたがるデプロイメントを、単一の統合システムであるかのように運用できます。
チームの視点では、クラスターの乱立も、リージョンごとの手作業での管理もありません。1つのデプロイメントと1つのグローバルトポロジーを操作するだけです。Zillizが、レプリケーション、ルーティング、フェイルオーバー、リカバリーといった重い処理を引き受けるため、エンジニアが対応する必要はありません。
一貫性のあるマルチリージョンアーキテクチャ
Global Clusterの中核には、チームが自ら設計する必要のない、シンプルで予測可能な構造があります。
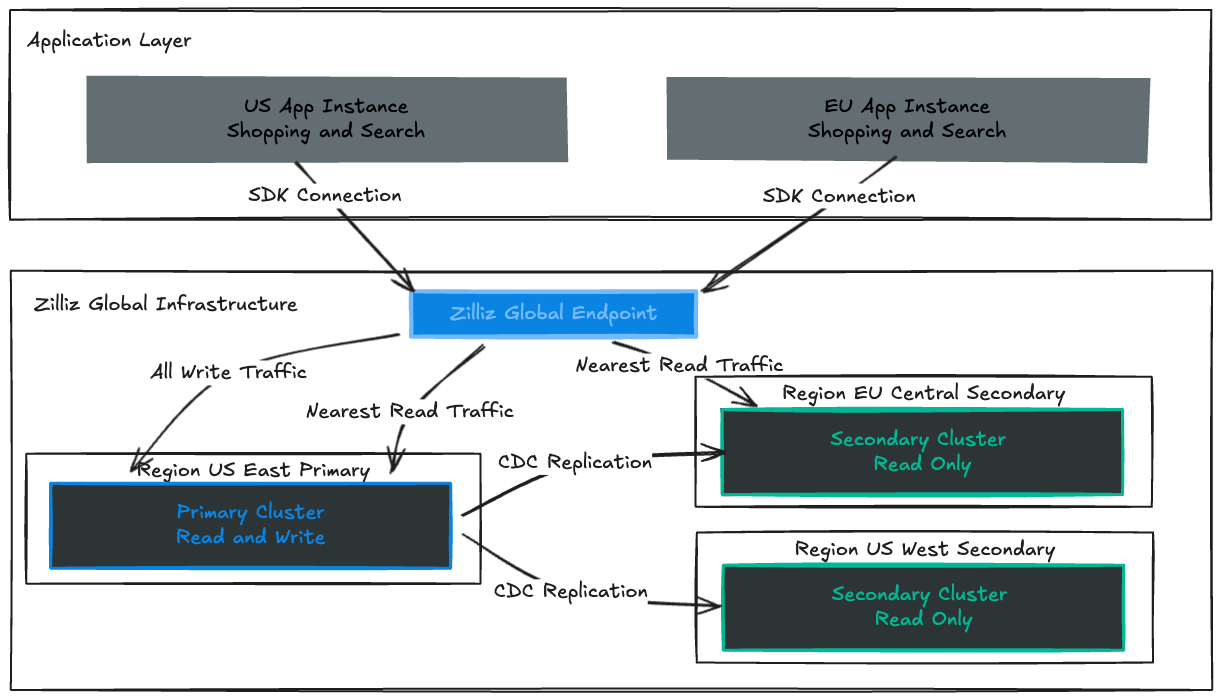
Primaryクラスターは信頼できる唯一の情報源として機能し、すべての書き込みを処理し、最もレイテンシーに敏感な操作を提供します。
Secondaryクラスターは、運用しているリージョンに配置されます。同期済みで、ウォーム状態で、いつでも利用可能です。近くのユーザーに高速なローカル読み取りアクセスを提供し、Primaryクラスターが利用できなくなった場合には即座に引き継げるよう待機します。
これにより、エンジニアに分散システムの専門家になることを強いることなく、グローバルなユーザーベースをサポートできます。このアーキテクチャはすぐに機能し、ビジネスの拡大に合わせてスケールします。
Global Endpoint: 緊急対応なしのフェイルオーバー
マルチリージョン運用を容易に感じさせる鍵は、Global Endpointです。これは、デプロイメント全体を単一の安定したエントリーポイントとして提示する、トポロジー認識型のルーティングレイヤーです。
1つの統合URL
アプリケーションは1つのURLに接続します。そのURLは、インフラストラクチャが進化しても決して変わりません。
インテリジェントなトポロジー認識型ルーティング
Global Endpointは、トラフィックを適切な宛先へ自動的にルーティングします。書き込みはアクティブなPrimaryへ、読み取りは最も近い健全なSecondaryへ送られます。ユーザーがシンガポール、フランクフルト、サンパウロのどこにいても、リージョン固有の設定を必要とせず、一貫したパフォーマンスを体験できます。
フェイルオーバー時のゼロコード移行
緊急フェイルオーバーや計画メンテナンスの切り替えが発生しても、移行は瞬時かつ不可視です。ルーティングは即座に更新され、アプリケーションは変更なしに稼働し続け、チームが設定変更や再デプロイに追われる必要はありません。緊急対応なし。午前3時の緊急パッチなし。あるのはスムーズな継続性だけです。
Global Clusterの仕組み
チームがクロスリージョンレプリケーションについて考えるとき、最初の懸念は通常パフォーマンスです。「フランクフルトにレプリケートしたら、バージニアのユーザーが遅くなるのでは?」
Zilliz Cloud Global Clusterなら、答えはノーです。書き込みはローカルにとどまり、高速で、ネットワーク距離の影響を受けません。
非同期CDC: グローバルレプリケーションを支えるエンジン
Zilliz Cloudは、PrimaryクラスターのWrite-Ahead LogからすべてのSecondaryリージョンへ、挿入、更新、削除、スキーマ変更をストリーミングする非同期Change Data Capture(CDC)パイプラインを使用します。この設計により、以下を実現します。
パフォーマンスの分離: レプリケーションは書き込み操作とは独立して実行されるため、Primaryクラスターの書き込みレイテンシーは、リージョン間ネットワーク遅延ではなくローカルシステムの状態によって決まります。
結果整合性: Secondaryリージョンのデータは、本番ワークロードに十分な程度まで最新に保たれ、通常は数秒程度の遅延にとどまりながら、予測可能な書き込みパフォーマンスを維持します。
効率的なリソース使用: Secondaryクラスターは単なるスタンバイレプリカとして機能するのではなく、ローカルの読み取りトラフィックを能動的に処理するため、同じインフラストラクチャで高可用性と低レイテンシーのリージョナルアクセスの両方をサポートできます。
運用ワークフロー: スイッチオーバーとフェイルオーバー
グローバルシステムは、2つの非常に異なる運用上の局面に対応する必要があります: 計画されたデータ移行 と 予期しない災害です。Zillizはその両方に対して明確で信頼性の高いワークフローを提供するため、重要なイベント時にチームが場当たり的に対応する必要はありません。
計画移行のためのスイッチオーバー
スイッチオーバーは、定期メンテナンス、コンプライアンス要件、またはリージョン間でのワークロード移動に使用されます。データ損失ゼロでPrimaryを別のリージョンへ移動できます。
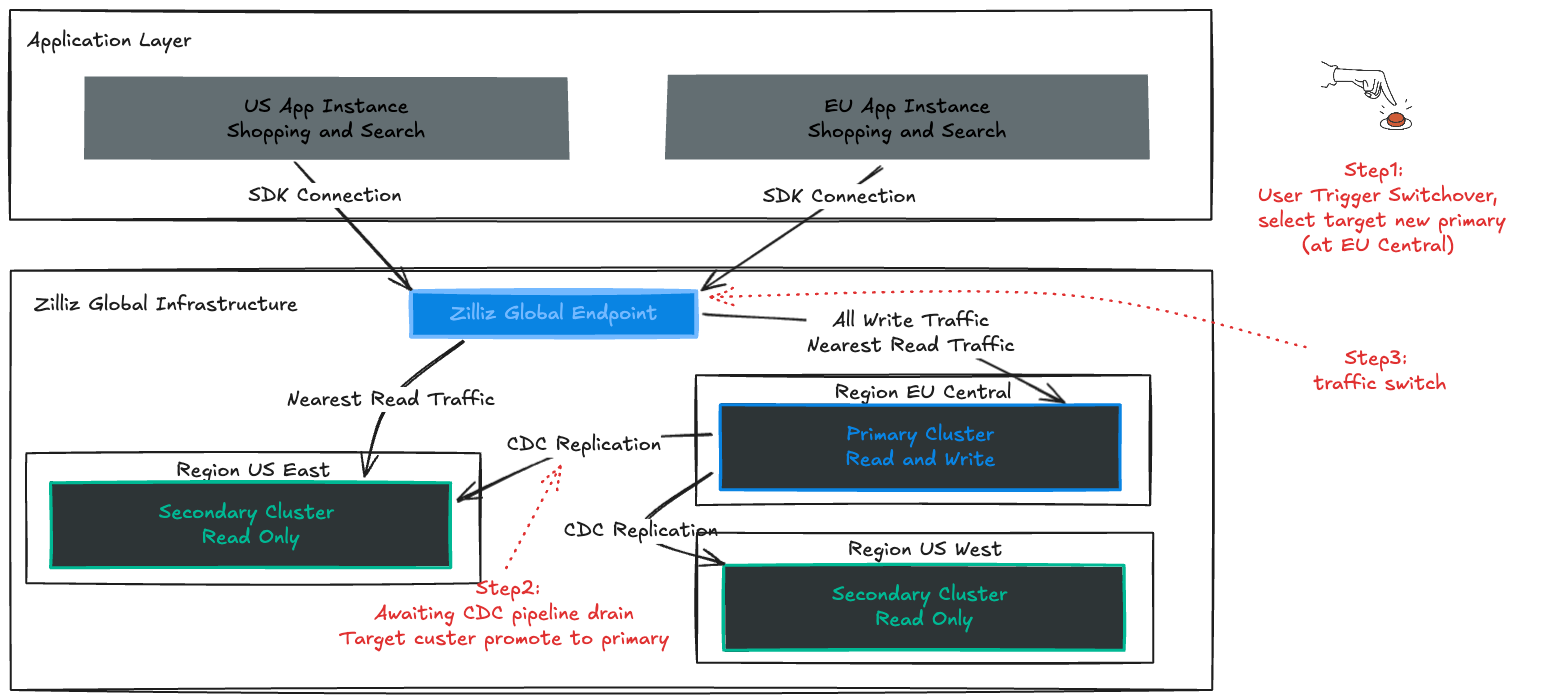
仕組みは次のとおりです:
トリガー: コンソールでターゲットリージョンへのスイッチオーバーを開始します。
ゼロデータ損失: システムは書き込みを短時間一時停止し、レプリケーションラグがゼロになるのを待つことで、完全な引き継ぎ(RPO = 0)を保証します。
シームレスな切り替え: Secondary が新しい Primary になります。Global Endpoint はルーティングを即座に更新し、アプリケーションは中断なく動作を継続します。
リージョン障害からの復旧のためのフェイルオーバー
フェイルオーバーは、誰も望まない瞬間のために設計されています — リージョンが停止する、ファイバー切断によってゾーンが孤立する、またはクラウドプロバイダーが重大なインシデントに見舞われるような場合です。
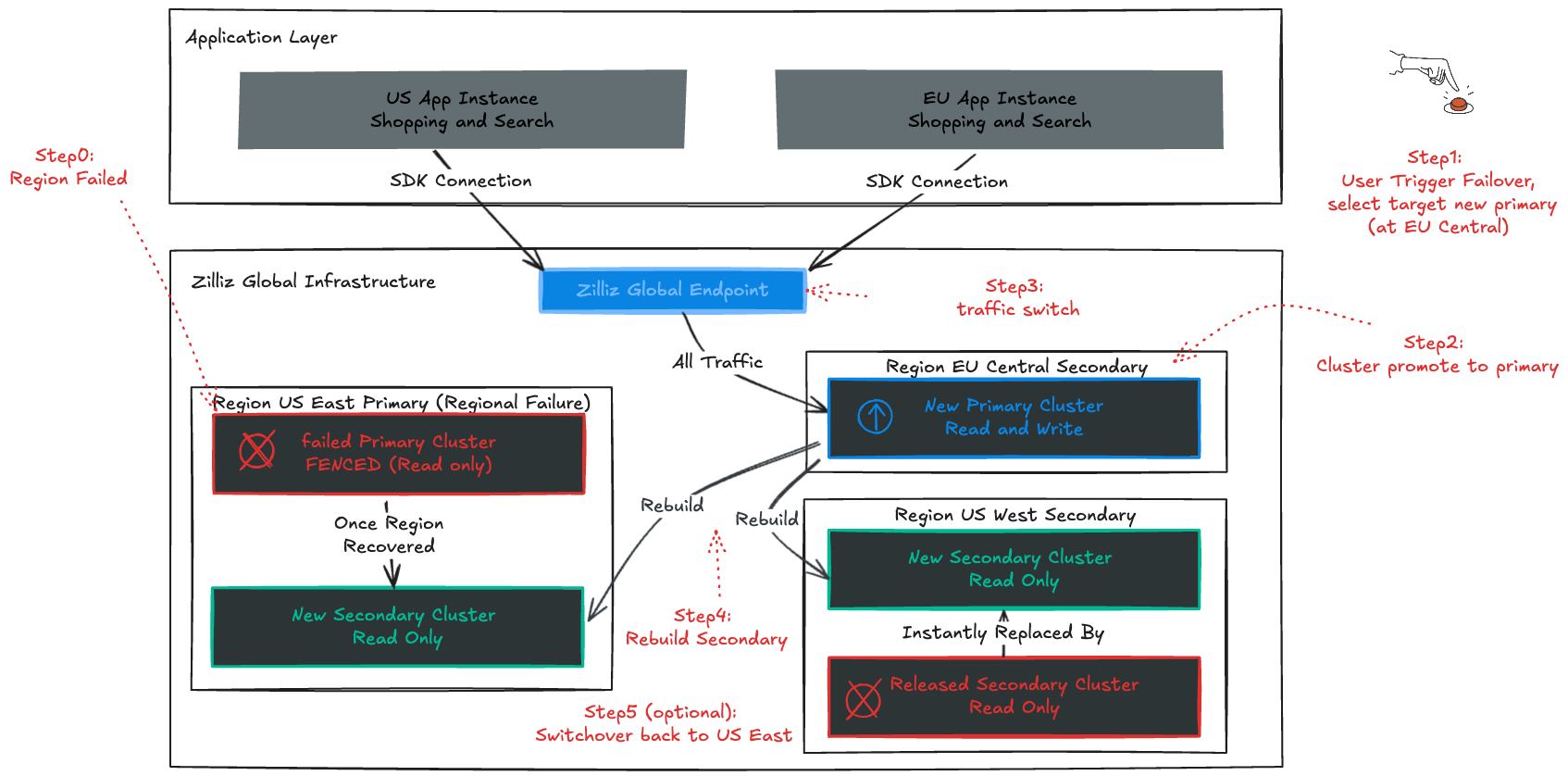
このワークフローの仕組みは以下のとおりです:
評価: Global Topology Dashboard を確認して、リアルタイムのレプリケーションステータスをチェックします。
実行: Force Failover コマンドを発行します。
安全インターロック(I/O フェンシング): システムは、到達不能になった古い Primary を暗号学的に「フェンス」します。これにより、「スプリットブレイン」シナリオ(古い Primary が復旧して競合する書き込みを受け付ける状況)を防ぎ、データ整合性を確保します。
復元: Secondary が Primary になります。トラフィックはリダイレクトされます。RTO は分単位で測定されます。
自己修復アーキテクチャ: 自動再構築
レジリエンスはフェイルオーバーで終わるものではありません — 真のグローバル継続性には、障害が発生したリージョンがオンラインに戻り次第、冗長性を復元することが必要です。Zilliz Cloud Global Cluster は、そのループを自動的に閉じます。フェンスされた Primary が最終的に復旧すると、システムはそのデータがもはや正当なものではないことを検出します。乖離のリスクを冒すのではなく、Zilliz Cloud は古い状態を安全にリセットし、リージョンを再プロビジョニングして、新しい Secondary として再構築します。
手動のクリーンアップも、実行するスクリプトも、複雑な再インデックス作成も不要です。クラスターはバックグラウンドで自己修復し、運用上の手間なくグローバルトポロジーを完全な状態に戻します。チームは対応を管理し、Zilliz が復旧を処理します。
今すぐ Day 2 に備える
Global Cluster は、「Day 2」の現実 — システムが現実世界の障害、予期しないトラフィック急増、または制御できないクラウドリージョン障害に直面する瞬間 — に対応するために構築されています。ファイバー切断、気象インシデント、プロバイダーの障害が発生することを止めることはできません。しかし、それらの問題が顧客に届かないようにするアーキテクチャを設計することはできます。
非同期 CDC レプリケーションによってデータを最新に保ち、Global Endpoint によってトラフィックルーティングを簡素化し、厳格なフェンシングプロトコルによって一貫性を保護することで、Zilliz Cloud は現代の AI アプリケーションが求めるレジリエンスをベクトルデータベースに提供します。これは単なる機能ではありません — グローバル規模でミッションクリティカルな AI を運用するチームにとっての事業継続性の基盤です。
グローバルなユーザー向けに AI 搭載製品を構築しているなら、ベクトルインフラストラクチャをあなたの野心と同じくらいレジリエントにする時です。
お問い合わせいただき、Global Cluster の詳細を確認し、早期導入者になりましょう。
制限なく構築する: Zilliz Cloud のエンタープライズ対応機能を詳しく見る
Global Cluster の導入により、Zilliz Cloud は、本番規模の AI 向けに最も高性能で、安全かつレジリエントなベクトルデータベースサービスとしてのリードをさらに広げます。しかし、レジリエンスはその一部にすぎません。Zilliz Cloud は、セキュリティとコンプライアンスから検索性能、運用のシンプルさまで、企業が自信を持ってインテリジェントアプリケーションを構築できるよう設計された包括的な機能スイートをまとめて提供します。
Elastic scaling とコスト効率 – ワンクリックデプロイ、サーバーレスオートスケーリング、従量課金制。
高度な AI 検索 – メタデータフィルタリング、動的スキーマ、マルチテナンシーを備えたベクトル、全文、ハイブリッド(スパース + デンス)検索。
エンタープライズグレードの信頼性とセキュリティ – 99.95% SLA、SOC 2 Type II および ISO 27001 認証、GDPR 準拠、HIPAA 対応準備、RBAC、BYOC、監査ログ、ビジネスクリティカルプラン、そして新たにグローバルクラスターに対応。詳しくは当社の trust center をご覧ください。
グローバルな可用性 – AWS、GCP、Azure にまたがるデプロイにより、世界中で 100ms 未満のレイテンシを実現。
シームレスな移行 – Pinecone、Qdrant、Elasticsearch、PostgreSQL、OpenSearch、AWS S3 vectors、Weaviate、またはオンプレミス Milvus から移行するための組み込みツール。
自然言語クエリ – 複雑な API なしで直感的なクエリを実現する MCP server サポート。
これらの機能を総合すると、Zilliz Cloud は 単なるベクトルデータベース以上の存在 — 制限なく AI アプリケーションを構築・スケーリングするための、フルマネージドで本番環境対応のプラットフォームです。

読み続けて

Zilliz Cloud BYOC Now Available Across AWS, GCP, and Azure
Zilliz Cloud BYOC is now generally available on all three major clouds. Deploy fully managed vector search in your own AWS, GCP, or Azure account — your data never leaves your VPC.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.

Vector Databases vs. Document Databases
Use a vector database for similarity search and AI-powered applications; use a document database for flexible schema and JSON-like data storage.