




DeepSeek-VL2:高度なマルチモーダル理解のための専門家混合視覚言語モデル
AIの独占は変わりつつある。DeepSeek-VL2は、GPT-4-oレベルの視覚言語インテリジェンスをわずかなコストで提供する。オープンモデルは追いついているだけではないのだ。これは高価なクローズドAIの終焉を意味するのだろうか?
大規模視覚言語モデル(VLMs)は、人工知能における変革の力として登場した。VLMは、大規模言語モデル(LLM)の優れた能力を拡張し、視覚情報とテキスト情報をシームレスに処理する。VLMは、視覚的な質問への回答や文書分析などのタスクに取り組んでいる。しかし、VLMは高い計算コストという課題に直面している。また、VLMは高解像度の画像や様々なアスペクト比の画像に苦戦しており、その主な原因は、画像の解像度が上がるにつれて一般的に2次関数的に計算量がスケーリングされるためである。
DeepSeek-VL2は、大規模なMixture-of-Experts(MoE)ビジョン言語モデルの高度なシリーズで、これらの問題に対処します。動的な高解像度ビジョンエンコーディング戦略と最適化された言語モデルアーキテクチャを導入することで、視覚理解を強化し、学習と推論の効率を大幅に向上させます。もう一つの重要な進歩は、視覚言語データ構築パイプラインを改良したことで、全体的な性能を向上させ、正確な視覚的グラウンディングなどの新しい分野でモデルの能力を拡張している。
DeepSeek-VL2は、視覚的質問応答、光学的文字認識、文書/表/グラフの理解、視覚的グラウンディングを含むがこれらに限定されない様々なタスクにおいて優れた能力を発揮する。一般的に使用されているマルチモーダルベンチマークで評価、
DeepSeek-VL2は、より少ない起動パラメータで、最先端モデルと同等以上の性能を達成しました。特にOCRBenchでは834点を記録し、GPT-4oの736点を上回った。また、視覚的な質問応答タスクのDocVQAでは93.3%を達成した。定性的評価では、複数の画像にまたがって推論し、首尾一貫した視覚的物語を生成する能力が強調されている。
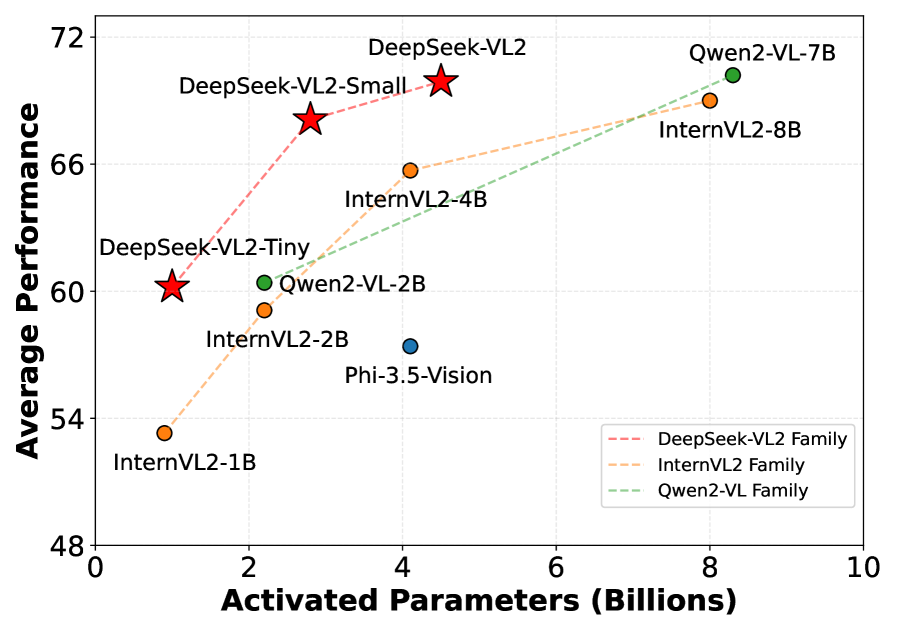
様々なオープンソースモデルの平均性能と活性化されたパラメータ|出典
このブログでは、ビジョンと言語におけるDeepSeek-VL2の技術的進歩について説明します。ベンチマークの結果と効率性の向上を詳細に分析し、高性能マルチモーダルAIの民主化における役割について説明します。
DeepSeek-VL2:コアモデルアーキテクチャ
DeepSeek-VL2の中核には、マルチモーダル理解を強化するために構築された構造化されたアーキテクチャがあります。MoE(Mixture-of-Experts)フレームワークと高度なVL(Vision-Language)処理パイプラインを組み合わせることで、DeepSeek-VL2は視覚情報とテキスト情報を効率的に統合します。
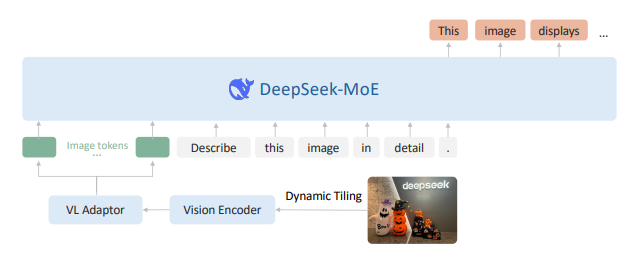
DeepSeek-VL2のアーキテクチャ概要|出典
以下は、DeepSeek-VL2 のコアモジュールの説明です:
1.### ビジョンエンコーダ
ビジョンエンコーダは、高解像度の視覚的特徴を効率的に抽出するように設計されています。DeepSeek-VL2 のビジョンエンコーダは、高解像度画像処理用に設計された動的タイリング戦略を使用しています。このアプローチは、アスペクト比の異なる高解像度画像を効率的に処理できるように、高解像度をタイルに分割するものです。
DeepSeek-VL2はSigLIP-SO400M-384ビジョンエンコーダを使用しています。このビジョンエンコーダは、384x384の基本解像度で動作します。様々なアスペクト比の高解像度画像に対応するため、画像はまずリサイズされ、384x384ピクセルのタイルに分割される。解像度の候補セットCRを定義する:
CR = {(m .384, n .384) | mN, n N, 1m,n,mn9}.
ここで、m:nはアスペクト比を表す。
各入力画像を各候補にリサイズするのに必要なパディングが計算され、最小のパディングを持つ候補が選択される。パディングを最小化することで、計算オーバーヘッドを削減し、より多くの画像コンテンツを確実に保持できるため、処理効率が向上します。リサイズされた画像は、384×384のミニローカルタイルと1つのグローバルサムネイルタイルに分割されます。SigLIP-SO400M-384ビジョンエンコーダは、すべての(1+ミニ)タイルを処理し、1タイルあたり1152次元の729ビジュアル埋め込みを生成します。
2.### ビジョン言語(VL)アダプター
視覚的特徴抽出の後、視覚言語アダプタは視覚表現とテキスト表現のギャップを埋めるためにトークンを再構築し圧縮する。このステップでは、空間関係をエンコードするための特別なトークンを導入することで、視覚データとテキストデータのシームレスな統合を可能にする。
まず、2×2ピクセルのシャッフル操作によって、各タイルのトークンの空間寸法が27×27から14×14=196トークンに縮小される。次にアダプタは、タイル間の空間的関係をエンコードするための特別なトークンを挿入する。
グローバルサムネイル:** グローバルサムネイルタイルでは、各行の末尾に14個の
<tile_newline>tokens` が追加され、14行×15トークン=210トークンの総数となる。** ローカルタイル:** グリッド状に配置された mn 個のローカルタイル (mi .14, ni .14) に対して、システムは mi .14 個の
<tile_newline>token を全てのローカルタイルの各行の終わりに追加する。Separator:**グローバルタイルとローカルタイルの間に
<view_separator>トークンが追加されます。
この構造化された出力は、モデルがタイル画像の空間レイアウトを理解することを保証します。最終的な視覚トークン列210+1+ mi・14 × (ni・14 +1)は、2層MLPを介してLLMの埋め込み空間に投影されます。

DeepSeek-VL2における動的タイリング戦略の説明図| 出典
3.### DeepSeekMoE 大規模言語モデル
DeepSeek-VL2 の言語バックボーンは、Multi-head Latent Attention (MLA)で補強された Mixture-of-Experts (MoE)モデルで構築されています。MLAは、Key-Valueキャッシュを潜在ベクトルに圧縮することで推論効率を高め、メモリオーバーヘッドを削減し、スループット能力を向上させます。これにより、DeepSeek-VL2は計算効率を維持しながら、長いコンテキストのシーケンスをより効果的に処理することができます。
MoEアーキテクチャは、推論時に上位6人のエキスパートだけが選択されるスパース計算によって、効率的な推論を可能にします。これにより、性能を維持しながら計算コストを大幅に削減できる。学習時には、各エキスパートにグローバルバイアス項を導入することで、負荷分散を改善し、学習効率を最適化する。
DeepSeek-VL2には3つのモデルバリエーションがあり、それぞれ活性化されるパラメータとエキスパートの数が異なります:
DeepSeek-VL2-Tiny**:1.0Bパラメータ、64エキスパート
DeepSeek-VL2-Small**:2.8Bパラメータ、64エキスパート
DeepSeek-VL2**:4.5Bパラメータ、72エキスパート
トレーニング方法
DeepSeek-VL2は、マルチモーダルな理解と計算効率のバランスをとるために、3段階のトレーニングパイプラインを使用しています。全体的なプロセスは3つのフェーズに分かれています:
1.視覚と言語のアライメント
2.ビジョンと言語の事前トレーニング
3.教師あり微調整

トレーニングパイプラインの高レベルフェーズ
トレーニングパイプラインについて説明する前に、異なるトレーニングフェーズで使用されるデータ構築とデータセットについて学びます。
データ構築
DeepSeek-VL2 のために、様々なソースからの包括的な Vision-Language データセットを構築した。このセクションでは、学習パイプラインのさまざまな段階で使用されるデータについて説明します。
視覚言語アライメントデータ
VLアライメントの段階では、視覚的特徴とテキスト埋め込みとの橋渡しに焦点が置かれる。この初期段階にはShareGPT4Vデータセットが使用される。このデータセットは約120万個のキャプションと会話サンプルから構成されている。
視覚言語事前学習データ
事前学習データは、視覚言語(VL)とテキストのみのデータを組み合わせ、VLの能力とテストのみの性能のバランスをとる。この段階では、データの約70%は視覚言語ソースから、残りの30%はLLM事前訓練コーパスから得たテキストのみのデータである。
使用されるVLデータのカテゴリをここで説明する:
WIT、WikiHow、OBELICSのサンプルのようなオープンソースのデータセットは、一般的な実世界の知識のための様々な画像とテキストのペアを提供する。
画像キャプションデータ:**オープンソースデータセットを使った最初の実験では、一貫性のない品質(テキストの不一致、幻覚など)が示された。包括的な画像キャプション作成パイプラインを使用し、OCRヒント、メタデータ、元のキャプションをプロンプトとして考慮し、社内モデルで画像にキャプションを付け直した。このキュレーションされたキャプションデータはトレーニングに使用された。
光学式文字認識(OCR)データ:** LaTeX OCRや12M RenderedTextのような公開データセットを、多様な文書タイプをカバーする広範な社内OCRデータと組み合わせた。
一般的な VQA(DeepSeek-VL)、文書理解(PubTabNet、FinTabNet、Docmatix)、Web-to-code/plot-to-Python 生成(Websight および Jupyter ノートブック、DeepSeek V2.5 で改良)、視覚的プロンプトによる QA(画像に矢印/ボックスなどのインジケータをオーバーレイして、焦点を絞った QA ペアを作成)。
- ビジュアル・グラウンディング・データ:**ビジュアル・グラウンディングのためのデータセットが構築された。各画像の物体検出の注釈について、特別なトークン<|ref|>、<|/ref|>、<|det|>、<|/det|>を用いて以下のようにデータを構成した:
プロンプト:** 与えられた画像から<|ref|>
<|/ref|>を探す。 レスポンス:** <ref|>
<|/ref|><|det|>[[x1, y1, x2, y2],...]<|/det|>.
*Grounded Conversation Data: プロンプトとレスポンスに、特定の画像領域とダイアログを関連付けるための特別な接地トークンが含まれる会話データセット。
教師あり微調整データ
SupervisedFine-Tuning段階は、モデルの指示追従と会話のパフォーマンスを改善する。対象となる側面は以下の通り:
一般的な視覚的質問応答:** 公開されている視覚的QAデータセットは、しばしば短い応答、不十分なOCR、幻覚に悩まされる。オリジナルの質問、画像、OCRデータを用いて回答を再生成することにより、新しいデータセットを生成した。
OCRと文書理解:** OCR品質の低いサンプルを除去することで、既存のOCRデータセットをクリーニングした。
表とグラフの理解:** 元の質問に基づいて回答を再生成することで、表ベースのQAデータを強化し、高品質のデータを作成。
推論、論理、数学:*** 明確さを向上させるため、公開推論データセットを詳細なプロセスと標準化された回答形式で強化。
教科書およびアカデミック問題:*** 複数の分野にわたるアカデミックな内容に焦点を当てた、大学レベルの内部教科書コレクション。
Web-to-codeおよびPlot-to-Python生成:***品質向上のため、回答生成後に社内データセットをオープンソースデータセットで拡張。
ビジュアルグラウンディング:** 物体検出の注釈を持つデータは、物体を正確に見つけ、記述するようモデルを導く。
グラウンディングされた会話:** 会話データセットには、インタラクションを向上させるために、対話と画像領域をリンクさせるためのグラウンディングトークンが組み込まれている。
テキストのみのデータセット:*** テキストのみの命令チューニングデータセットも、モデルの言語能力を維持するために使用されます。
トレーニングパイプライン
トレーニングを開始する前に、プロセスは定義された段階に分けられる。この構造により、アライメント、事前トレーニング、微調整の間のスムーズな移行が保証されます。最初に、視覚エンコーダと視覚言語適応MLPが学習され、言語モデルは固定されます。その後、すべてのモデルパラメータを凍結解除して広範な事前学習を行い、最後に教師ありデータを用いてモデルを微調整する。視覚的コンテキストの学習を優先させるため、各段階において損失はテキスト・トークンのみで計算される。
1.視覚-言語アライメント: VLアライメント段階は視覚的特徴とテキスト埋め込みを接続する。学習には、約120万の画像とテキストのペアからなるShareGPT4Vデータセットを使用する。このフェーズでは、言語モデルはフリーズしたままである。視覚とテキストの特徴を統合する軽量MLPコネクタを使用して、視覚エンコーダとアダプタのみがトレーニングされる。このフェーズでは、動的な高解像度入力を処理するために、固定解像度のエンコーダを調整する。
2)視覚-言語事前学習:* VL事前学習フェーズでは、最適化のためにすべてのパラメータが凍結解除される。視覚言語データが70%、テキストのみのデータが30%である。VLデータには、OCRや文書解析などのタスクをカバーするインターリーブされた画像とテキストのペアが含まれる。テキストのみのデータはLLM事前学習コーパスから得られる。訓練では、約8000億の画像-テキストトークンを使用して、視覚入力とテキスト入力の共同表現を構築する。
3.教師付き微調整:教師付き微調整では、モデルの指示追従能力と会話能力が改良される。この段階では、公開データセットと社内データから収集した質問と回答のペアを使用する。マルチモーダル対話データはDeepSeek-V2からのテキストのみの対話と組み合わされ、システム/ユーザープロンプトは、監視が回答と特別なトークンのみに適用されるようにマスクされます。
ハイパーパラメータとインフラストラクチャ
DeepSeek-VL2 のハイパーパラメータ構成の詳細は、以下の表に示します。学習中、異なるステージでは、個別の設定が使用されます。例えば、DeepSeek-VL2-Tiny のステージ 1 では、学習率は 5.4×10-⁴ に設定され、ステージ 3 では 3.0×10-⁵に低下する。ステップLRスケジューラは、全トレーニングステップの50%と75%で学習率を√10で分割する。0.1の固定乗数がビジョンエンコーダの学習率に適用される。コサイン学習率スケジューラは初期段階で使用され、最終段階では一定のスケジュールが使用される。その他の設定として、重みの減衰を0.1、勾配のクリッピングを1.0、AdamWオプティマイザをβ₁ = 0.9とβ₂ = 0.95に設定。

DeepSeek-VL2を学習するためのハイパーパラメータ| 出典
トレーニングは、大規模モデル用に設計された軽量システムであるHAI-LLMプラットフォーム上で行われる。このパイプラインは、ビジョンエンコーダにきめ細かいレイヤー分割を採用し、GPU間の負荷分散を確保することで、パイプラインバブルの発生を防ぎます。画像タイルの負荷分散もデータ並列ランク間で実行され、動的解像度戦略によってもたらされる変動に対応します。
さらに、効率を最大化するために、テンソル並列とエキスパート並列の技術が組み込まれています。綿密なハイパーパラメータのチューニングと組み合わせることで、DeepSeek-VL2は、堅牢なマルチモーダル性能を維持しながら、何十億ものトレーニングトークンを効率的に処理することができます。
DeepSeek-VL2は、8個のNVIDIA A100 GPUを搭載した16/33/42ノードのクラスタを使用して、7/10/14日でトレーニングされました。
評価
次に、標準的なベンチマークと定性的なテストを使用して、DeepSeek-VL2 のパフォーマンスを検証します。以下のセクションでは、評価結果の概要を示し、DeepSeek-VL2 を最先端のモデルと比較します。
ベンチマーク
DeepSeek-VL2 は、一般的に使用されているさまざまなベンチマークで評価されています。これには、DocVQA、ChartQA、InfoVQA、TextVQA、RealWorldQA、OCRBench、AI2D、MMMU、MMStar、MathVista、MME、MMBench(および MMBench-V1.1)、MMT-Bench が含まれます。さらに、RefCOCO、RefCOCO+、RefCOCOgベンチマークでモデルの接地能力をテストしています。これらのテストは、文書の理解や図表の解釈から実世界の問題解決に至るまで、さまざまなタスクに及んでおり、モデルの性能を総合的に測定することができます。
最新技術との比較
DeepSeek-VL2は、マルチモーダル理解ベンチマークにおいて、LLaVA-OV、InternVL2、DeepSeek-VL、Qwen2-VL、Phi-3.5-Vision、Molmo、Pixtral、MM1.5、Aria-MoEなど、いくつかの最先端の視覚言語モデルと比較されました。接地タスクでは、DeepSeek-VL2モデルは、Grounding DINO、UNINEXT、ONE-PEACE、mPLUG-2、Florence-2、InternVL2、Shikra、TextHawk2、Ferret-v2、MM1.5などの他のモデルを上回っています。
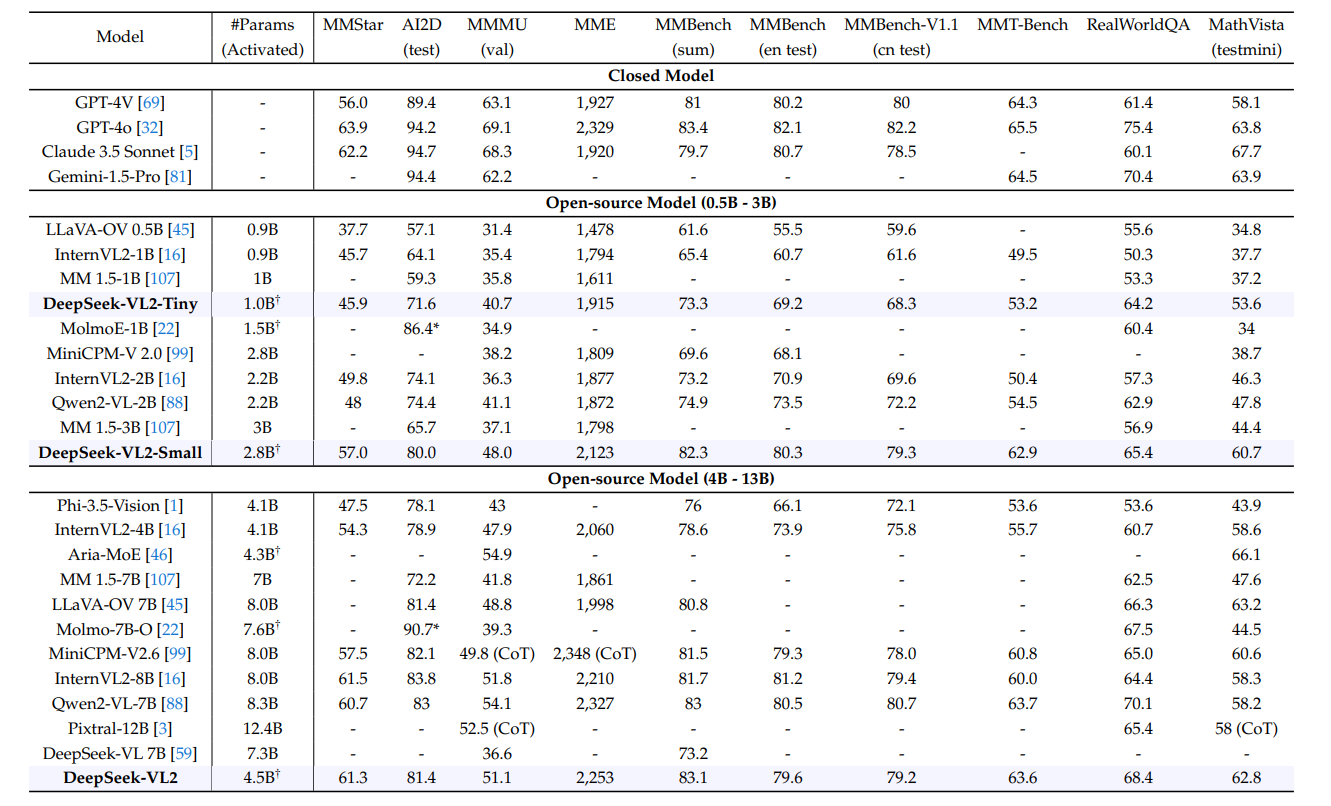
一般的なQAと数学関連のマルチモーダルベンチマークにおける最先端モデルとの比較|出典
DeepSeek-VL2は、より少ない起動パラメータで、同等以上のパフォーマンスを達成します。Qwen2-VL-7B(8.3B)やInternVL2-8B(8.0B)のような大規模なモデルと、MMBench(83.1 vs. 85.0)やMME(2,253 vs. 2,327)のようなタスクで同等かそれ以上の性能を発揮します。
活性化されたパラメータ数が少ないにもかかわらず、MMStar(61.3対63.9)ではGPT-4oの性能に近づき、AIDD(81.4)のようなOCRの負荷が高いタスクではほとんどのオープンソースモデルを上回っています。MoEアーキテクチャによって実現されたこのモデルの効率性は、能力と計算コストのバランスを効果的に保っています。
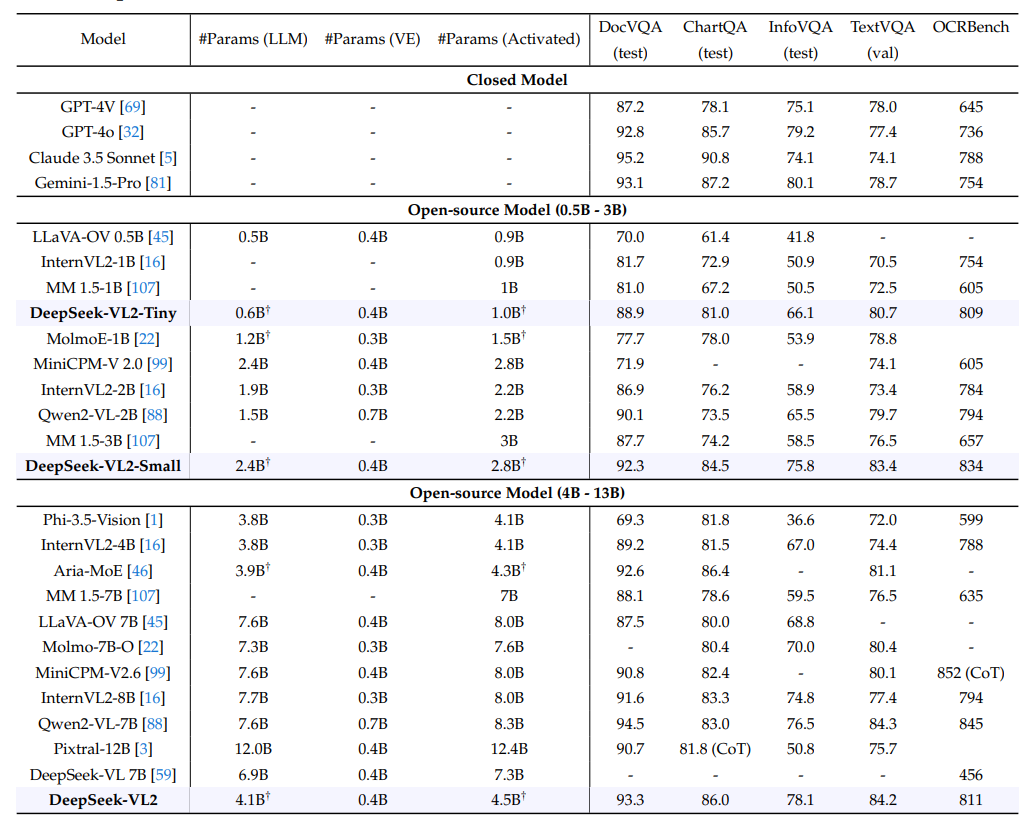
OCR関連マルチモーダルベンチマークにおける最先端モデルとの比較|出典
DeepSeek-VL2は、OCRタスクにおいて競争力のある性能を達成しており、TextVQAではQwen2-VL-7Bのような大規模モデルと同等かそれ以上であり(84.2対84.3)、DocVQAではGPT-4oを上回っています(93.3対92.8)。その ChartQA (86.0) と InfoVQA (78.1) のスコアは、ほとんどのオープンソースの同業他社を上回り、その効率性は Claude 3.5 Sonnet (OCRBench: 811 対 788) のようなクローズドモデルとのギャップを埋めています。これは、そのコンパクトなアーキテクチャにもかかわらず、堅牢なOCR能力を実証しています。
定性的調査
定性的調査では、さまざまなタスクにおける DeepSeek-VL2 の機能が実証されています。主な分野は以下のとおりです:
- 一般的な視覚的質問に対する回答:*** このモデルは、詳細な回答を提供し、高密度の画像コンテンツを正確に記述し、英語と中国語の両方でランドマークを認識します。ランドマークの認識、画像ベースの詩の構成、一般知識に関する質問への回答、グラフの理解、テキストの認識など、多面的な機能を備えています。
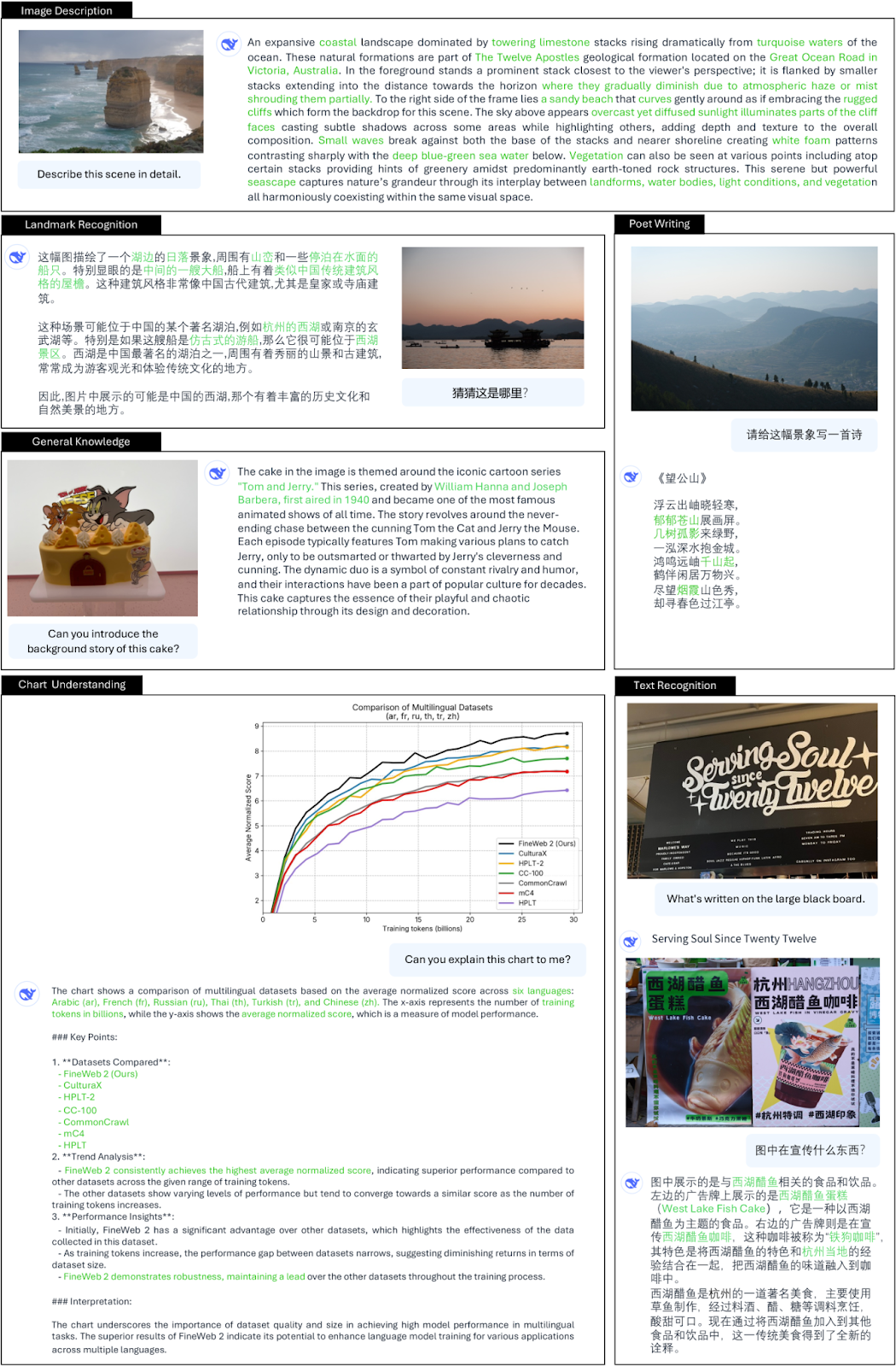
DeepSeek-VL2の一般的な質問応答機能| 出典
- 複数の画像の内容を統合することで、簡単な推論を可能にしながら、複数の画像の関連性や差異を効果的に分析する。例えば、ある食材の画像から料理の作り方を考えることができる。
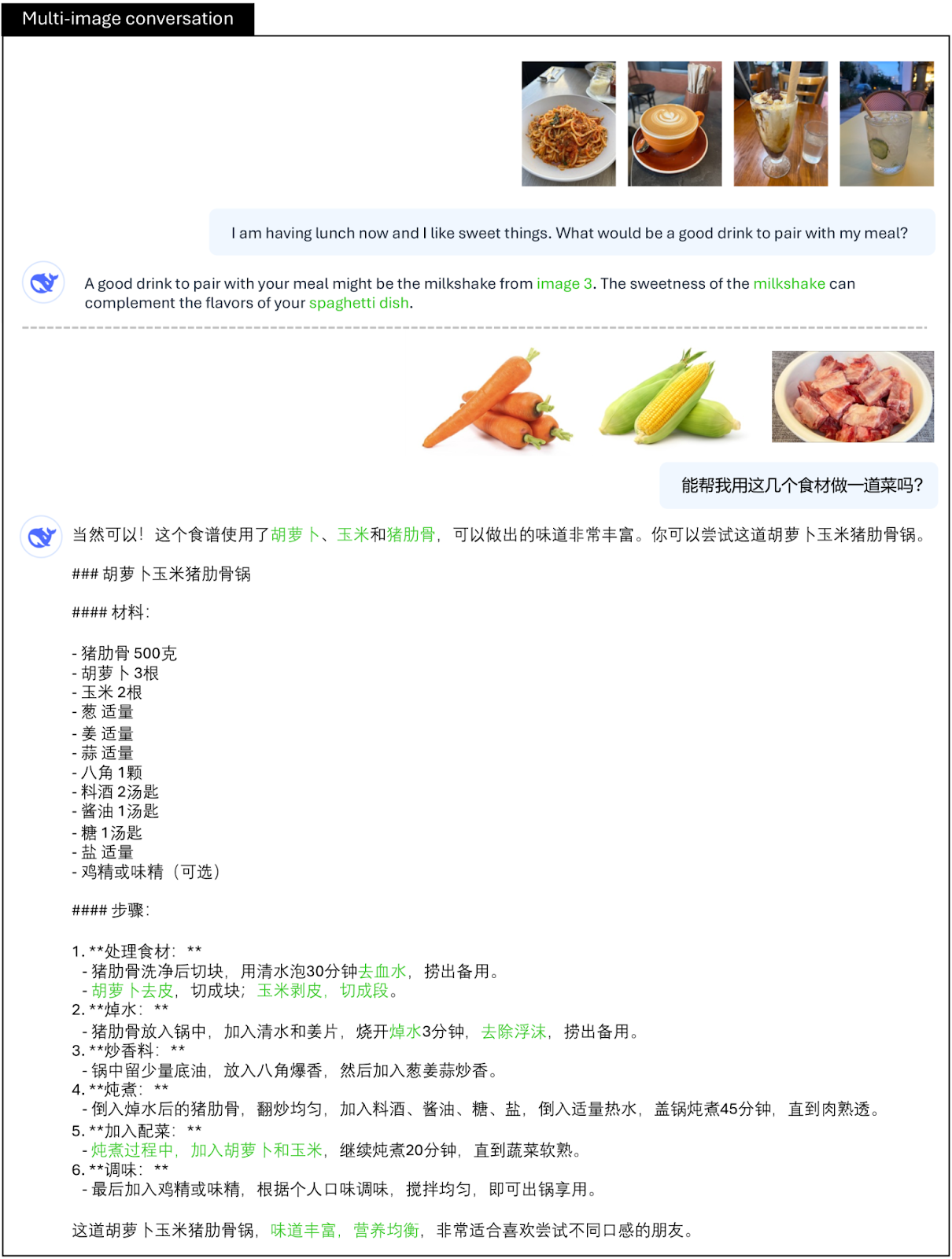
DeepSeek-VL2の複数画像会話機能|出典
- ビジュアルストーリーテリング:** DeepSeek-VL2は、文脈と一貫性を維持しながら、一連の画像に基づいて創造的な物語を生成できます。そのストーリーテリングは、時間的な進行とシーンの遷移の理解を反映し、生成されたナラティブに深みを与えます。

DeepSeek-VL2のビジュアルストーリーテリング機能|出典
- ビジュアル・グラウンディング:** このモデルは、自然なシーンからミームやアニメのような様々なシナリオまで、画像内のオブジェクトを一般化して識別し、位置を特定することに成功しています。物体が部分的に隠されていたり、困難な条件で提示された場合でも、頑健な性能を示す。
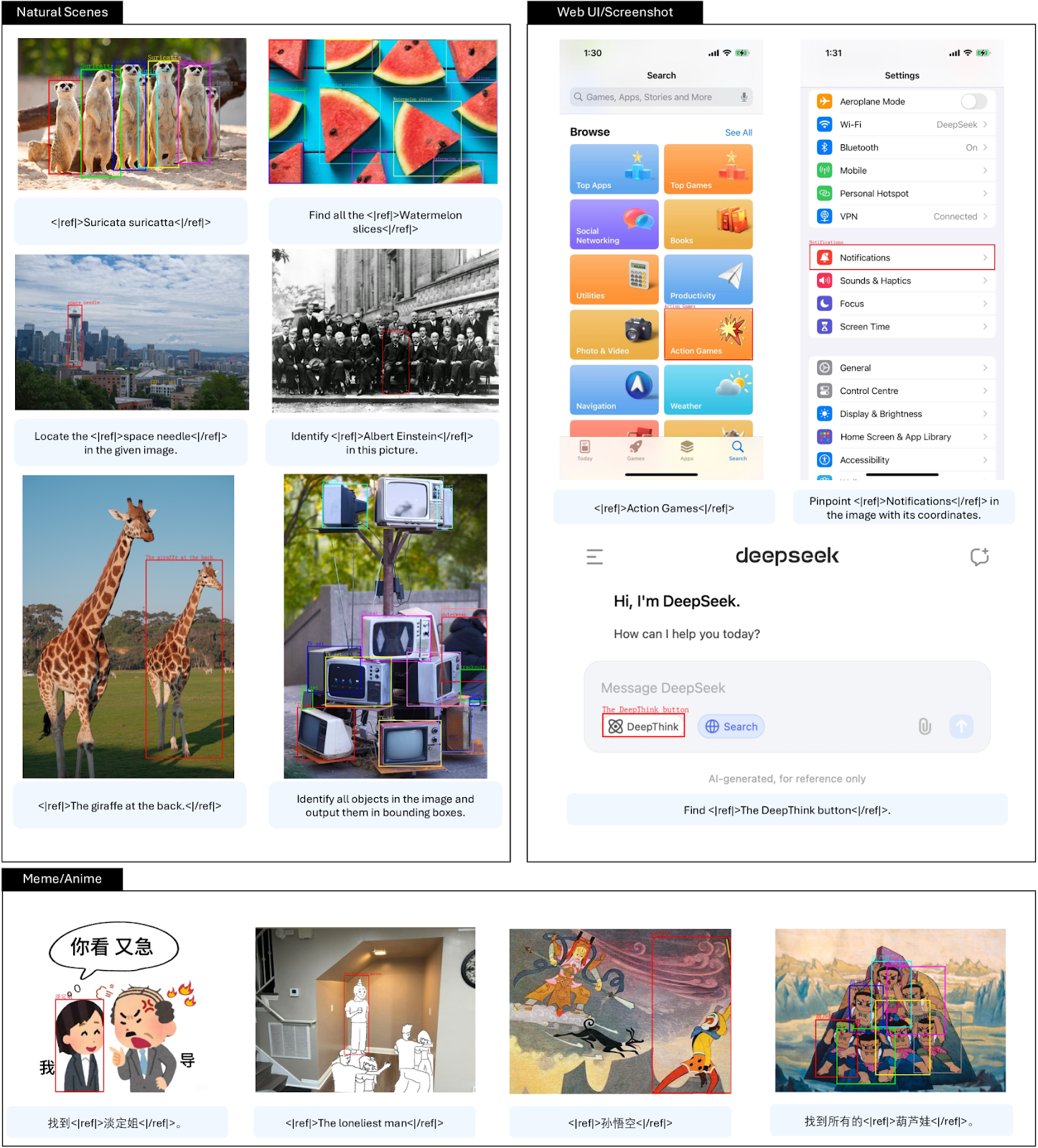
DeepSeek-VL2の視覚的接地能力| 出典
- グラウンディング会話:**特別なグラウンディングトークン<|grounding|>を使用することで、モデルは正確な位置の詳細で主要なオブジェクトを参照し、インタラクティブな能力を強化します。その接地された応答は、実世界の対話システムにおける実用的な応用を促進する。
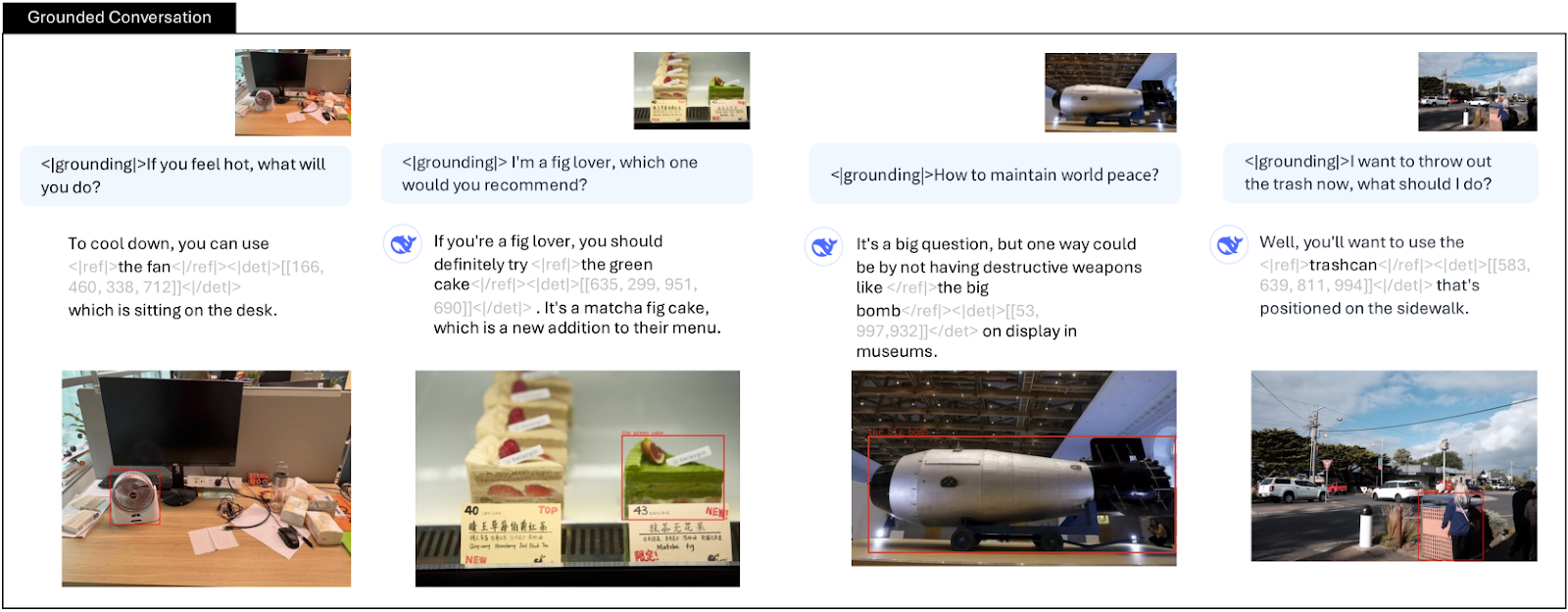
DeepSeek-VL2によるグラウンディング会話| 出典
主な発見
- 効率性とスケーラビリティ:** DeepSeek-VL2は、効率的なMoE設計とダイナミックタイリングアプローチにより、少ない起動パラメータで競争力のある結果を達成しています。性能とリソース使用量のこのバランスにより、計算能力が制限された環境での展開が可能になります。
- このモデルは、OCR、文書解析、および視覚的下地処理にまたがるタスクに優れています。視覚情報とテキスト情報を統合する能力により、多様なアプリケーションにおいて高い精度を実現します。
- このモデルは、教師ありの微調整により、首尾一貫した、文脈を意識した応答の生成において顕著な改善を示しています。この改良により、対話型および会話型の設定における性能が強化されました。
- 定量的ベンチマークと定性的研究の両方で観察された強力な性能は、DeepSeek-VL2が、自動文書処理、仮想アシスタント、具現化AIにおける対話システムなどの実用的なアプリケーションに適していることを示しています。
今後の研究の方向性
DeepSeek-VL2は、MoEベースの視覚言語モデルの拡張バージョンで、3つのサイズで利用可能です:3B、16B、27Bの全パラメータ、1.0B、2.8B、4.5Bのアクティブ化。このスマートな設計により、学習と推論の両方がより効率的になります。最小のモデルはわずか10GBのメモリで1つのGPUで実行できますが、大きなモデルは40GBと80GBのメモリを必要とします。
際立った特徴のひとつは、ダイナミック・タイリング戦略で、さまざまなアスペクト比の高解像度画像を巧みに処理する。DeepSeek-VL2は、コードと事前に訓練されたモデルを公開することで、視覚と言語のエキサイティングな交差点におけるさらなる研究と革新的なアプリケーションを刺激する。
DeepSeek-VL2には、改善すべき点がいくつかあります。
- コンテキスト・ウィンドウ:** 現在、このモデルはチャット・セッションごとに数枚の画像しかサポートしていません。将来のアップデートでは、コンテキスト・ウィンドウを拡張して、よりリッチな複数画像のインタラクションが可能になるかもしれません。
- 画像品質に対する信頼性:** このモデルは、時々、ぼやけた画像や見えないオブジェクトの問題に直面します。これらの問題に対処することで、多様なシナリオにおける信頼性を向上させることができる。
- 推論能力:** このモデルは視覚認識と認識において優れた性能を発揮するが、その推論能力を強化することができる。この点を強化することで、実世界での応用可能性が広がる可能性がある。
その他のリソース
大規模言語モデルとは](https://zilliz.com/glossary/large-language-models-(llms))
専門家の混合(MoE)とは](https://zilliz.com/learn/what-is-mixture-of-experts)
ディープラーニングでファインチューニングを極める](https://zilliz.com/glossary/fine-tuning)
視覚言語モデル(VLM)とは](https://zilliz.com/ai-faq/what-are-visionlanguage-models-vlms)
LLMにおけるトークン化とは](https://zilliz.com/ai-faq/what-is-tokenization-in-llms)

読み続けて

Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Notion solved vector search scaling in two years. The next bottleneck — offline context engineering, unified data, and the real-time/offline gap — is harder.

Migrating from S3 Vectors to Zilliz Cloud: Unlocking the Power of Tiered Storage
Learn how Zilliz Cloud bridges cost and performance with tiered storage and enterprise-grade features, and how to migrate data from AWS S3 Vectors to Zilliz Cloud.

Optimizing Embedding Model Selection with TDA Clustering: A Strategic Guide for Vector Databases
Discover how Topological Data Analysis (TDA) reveals hidden embedding model weaknesses and helps optimize vector database performance.