




Crafting Superior RAG for Code-Intensive Texts with Zilliz Cloud Pipelines and Voyage AI
The embedding model is at the heart of Retrieval Augmented Generation (RAG), which primarily affects the retrieval capability and is crucial to the overall response quality. Trained with vast amounts of data corpora, embedding models can extract the numerical representations of meaning from any text, making them suitable for various information retrieval tasks. However, training an embedding model that excels at any task is still highly challenging. Various embedding models are available, each with unique strengths and weaknesses and varying properties.
Zilliz Cloud Pipelines integrates the best embedding models available as a one-stop solution for retrieval. Such flexible choices enable the developers to explore and choose the best models tailored to their specific use cases.
Today, we are thrilled to announce that embedding models from Voyage AI are available in Zilliz Cloud Pipelines. The freshly released voyage-2 and voyage-code-2 models have demonstrated outstanding quality on retrieval tasks related to source code, technical documentation, and general tasks. For example, voyage-code-2 is reportedly 14.52% better than OpenAI embedding on code-intensive datasets and 3.03% better for general purposes.

We also collaborated with Voyage AI to assess the effectiveness of a RAG system implemented with various embedding models for code-related tasks. The language model used is GPT4. We tested the system on a subset of the APPS and Codechef datasets, which contain questions about coding, and each question has exactly one correct answer from the corpus. We measure the retrieval quality by "recall@k," which is the probability of catching the proper result in the top-k retrieved documents. In addition, we also evaluate the end-to-end quality with Ragas, a popular evaluation framework for RAG pipelines. It has six metrics that describe various aspects of RAG, from the relevance and precision of the retrieved texts to the correctness and quality of the final answer. The harmonic mean of the six metrics, called "Ragas Score," measures the system's overall performance. You can learn more about each metric on the Milvus documentation page.
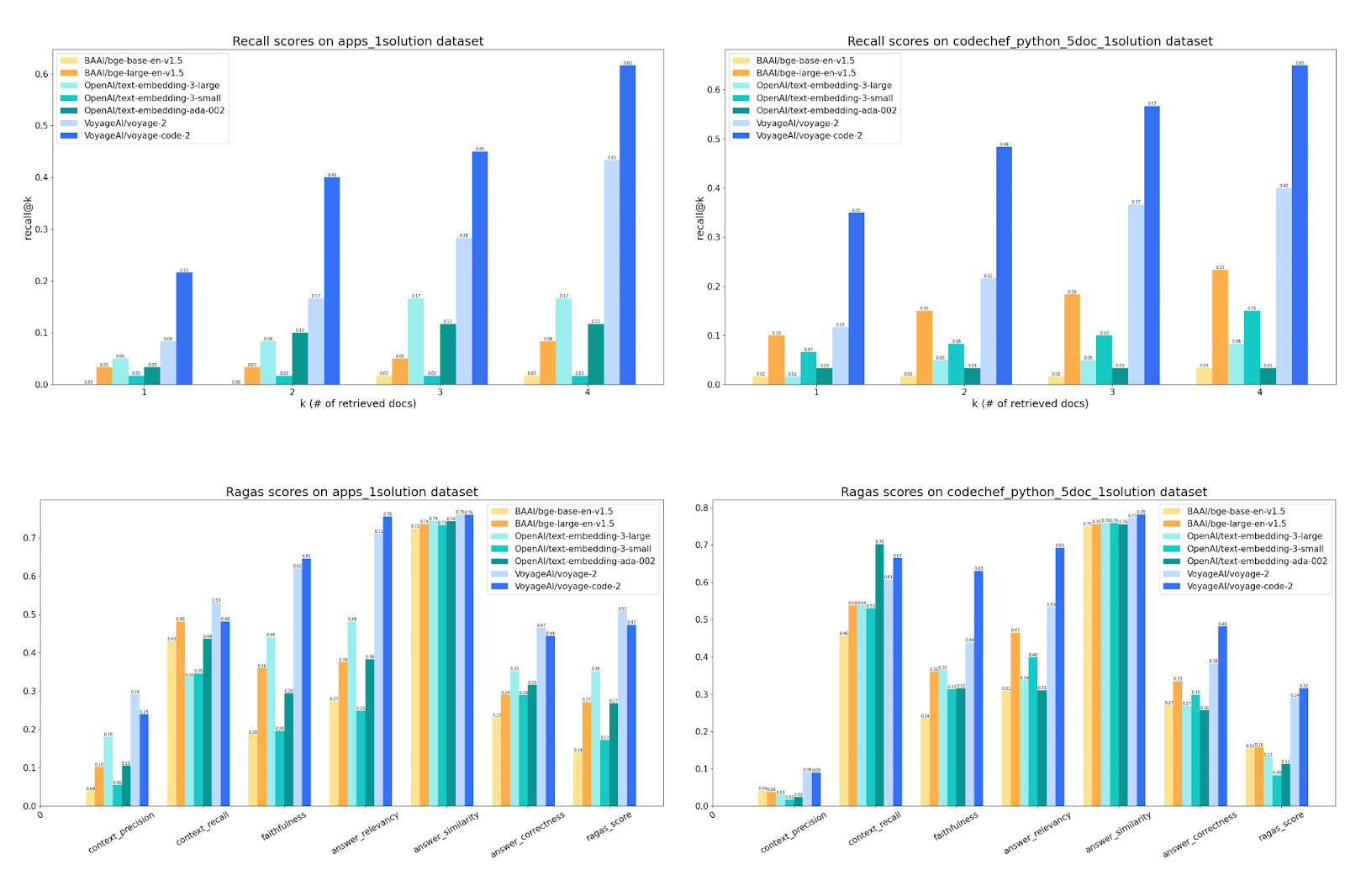
Comparing retrieval and overall scores across popular embedding models on code datasets.
The top two figures show that the voyages-2 and voyage-code-2 models have significantly better retrieval capability than the other models. The score “Recall@k” indicates that, when retrieving top-k results, there is a likelihood that the ground truth is included in the returned k results. For example, with the apps_1solution dataset, in 62% of the cases, voyage-code-2 gets the ground truth in the top-4 results, while bge-base-en-v1.5 only achieves that in 2% of the cases. These tests show that voyage-code-2 performs vastly better on code-related tasks than embedding models not optimized for it.
When it comes to the end-to-end RAG answers, the improvement in recall leads to a gain of over ten percentage points in Answer Correctness and Ragas Score, compared to the best-performing alternative. Specifically, Context Precision and Context Recall measure the effect of the retrieval phase. Voyage models significantly surpass the other options, especially in Context Precision. In Faithfulness and Answer Relevancy, which measure the quality of the generated answers, Voyage is ahead of different models by more than five percent points. The results show that better retrieval quality leads to better RAG pipeline generation. Answer Similarity and Answer Correctness pertain to assessing the semantic resemblance between the generated answer and the ground truth. In Answer Correctness, RAG based on Voyage again has apparent advantages, surpassing the others by more than five points.
RAG has become the predominant approach for question-answering bots on coding problems and software development. These applications can benefit even more from high-quality Voyage models that excel at code-related retrieval tasks. Improved retrieval quality translates to better locating relevant information from code or technical documentation, leading to more accurate answers and a better user experience.
In Zilliz Cloud Pipelines, you can now choose voyages-2 and voyage-code-2 as embedding models to achieve the highest retrieval quality on code-related tasks without worrying about DevOps or managing your ML infrastructure. The best part is that you can get started for free by signing up at https://cloud.zilliz.com/signup to build your RAG application with ease and precision!

Keep Reading

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

How to Use Anthropic MCP Server with Milvus
MCP + Milvus: Streamline AI agent development with standardized data access, eliminating integration hassles while enhancing context and flexibility.

Proactive Monitoring for Vector Database: Zilliz Cloud Integrates with Datadog
we're excited to announce Zilliz Cloud's integration with Datadog, enabling comprehensive monitoring and observability for your vectorDB deployments.