




AIの保護:PrivateGPTとMilvusによる高度なプライバシー戦略
#はじめに
組織が大規模言語モデル(LLM)やその他のAIツールを業務に統合するにつれ、データ・セキュリティに対する懸念が高まっている。例えば、金融、銀行、ヘルスケア、電子商取引などの主要部門では、コンテンツ作成やドキュメントの要約から、カスタマーサポートやプロンプトベースの質問応答まで、さまざまな機能を強化するためにAIを導入している。しかし、このようなAIの広範な導入は、潜在的なデータプライバシー侵害やコンプライアンス基準違反などの重大なリスクももたらす。
こうしたリスクを軽減するため、企業は機密データのセキュリティを損なうことなくAIの力を活用できるソリューションを模索している。Zilliz](https://zilliz.com/)が最近主催したウェビナーで、PrivateGPTとZylonの創設者であるDaniel Gallego Vicoは、企業環境におけるデータプライバシーを強化するために設計された様々なデータインフラに関する貴重な洞察を提供した。このブログポストでは、ダニエルのプレゼンテーションから重要なポイントを要約し、これらの開発についての我々の見解を提供します。詳細については、YouTubeの講演のリプレイをご覧ください。
AIツールがデータプライバシーを脅かす仕組み:リスクと影響図-AIの導入は止められない。.png](https://assets.zilliz.com/Figure_AI_adoption_is_unstoppable_6720aa71b6.png)
図-AIの導入は止められない:AIの導入は止められない。
ダニエルは、「2024 Work Trend Index」レポートからの印象的な統計に注目している:「世界の知識労働者の75%が現在、専門業務でAIを使用している」。このような広範な採用は、職場におけるAI統合の不可避性を強調するものだが、同時に個人データの保護という重大な課題も浮き彫りにしている:
モデルの出力におけるデータ漏洩:従業員がChatGPTのようなLLMを使用して会社のデータを分析する場合、これらのモデルは広範なデータセットで訓練されているため、出力に訓練データの断片が誤って含まれる可能性があります。これは意図しない機密情報の漏洩につながる可能性があり、セッション中に使用されたプロンプトやドキュメントの詳細を暴露する可能性があります。
**匿名化されたデータのリバースエンジニアリング: **名前、住所、クレジットカード番号などの個人を特定できる情報(PII)を暗号化または匿名化する努力にもかかわらず、これらの保護は完全ではありません。熟練したハッカーは、暗号化されたデータを解読するリバース・エンジニアリングの技術を成功させており、データ・プライバシーに対する重大な脅威となっています。
**モデル推論攻撃:この攻撃では、敵がAIモデルにさまざまな入力を送信し、その応答を分析して、特定のデータがトレーニングセットに含まれていたかどうかを推論します。例えば、この方法により、特定の患者の医療記録がヘルスケアAIシステムのトレーニングに使用されたかどうかが明らかになり、患者の機密性が損なわれる可能性がある。
図- AIはプライバシーを侵害する。.png](https://assets.zilliz.com/Figure_AI_breaks_privacy_dc78ed193d.png)
図:AIはプライバシーを侵害する。
これらの特定のリスク以外にも、データ・プライバシーの脅威は、データのスクレイピング、不十分なセキュリティ対策による侵害、AIモデルがトレーニング中に機密データを記憶する可能性などからも生じる。顧客や取引先のデータが流出すれば、規制基準を守れない企業にとっては深刻な法的問題に発展する可能性がある。
AIプライバシーのさまざまなレベル
チャットボットやretrieval augmented generation(RAG)のようなAIアプリケーションを開発するには、LLM、クラウドプロバイダー、embedding models、Milvusのようなvector databasesなど、様々なサードパーティーサービスを統合する必要があることが多い。これらすべてのサービスが、厳格なデータプライバシーとセキュリティの基準を満たしていることを保証することは、不可欠ではあるが、難しいことである。
このようなプライバシーの懸念に対処するために、様々なAIプライバシー・ソリューションが利用可能であり、それぞれがインフラストラクチャに基づいて異なるレベルのデータ・セキュリティを提供している。組織にとっては、それぞれの選択肢を十分に理解し、ニーズに最も合ったソリューションを選択することが極めて重要である。
ダニエルは、5つの異なるAIプライバシー戦略を共有した:準拠SaaS、データ匿名化、ローカル実行、社内開発、オンプレムインフラ不可知論である。以下のセクションでは、これらのソリューション、その利点、および制限について説明し、意思決定プロセスの参考とします。
準拠型SaaS
Compliant SaaSは、GDPRやHIPAAなどの規制基準を遵守する、データ・プライバシーの基礎となるレベルです。当初、データは企業のインフラ内に保存され、その後AI Software as a Service(SaaS)プロバイダーと共有される。このプロバイダーは、(Milvusのようなツールを使って)vector embeddingsを作成したり、(OpenAIのような)LLMを訓練したり、データの取り込みを管理したりするために、様々なサードパーティーベンダーとデータを共有することができる。
図-プライバシーレベル別AIソリューション-準拠SaaS .png](https://assets.zilliz.com/Figure_AI_Solutions_by_Privacy_Level_Compliant_Saa_S_1be93beb16.png)
図:プライバシーレベル別AIソリューション-コンプライアンス型SaaS_」。
しかし、この戦略には大きなリスクが伴う。サードパーティ・ベンダーで情報漏えいが発生すれば、組織のデータへの不正アクセスにつながる可能性がある。さらに、これらのサードパーティは、アップロードされたデータに完全にアクセスすることができ、独自のモデルを訓練するためにそれを使用する可能性があるため、データの悪用のリスクがさらに高まります。
データの匿名化
データの匿名化は、SaaSやクラウドベースのパイプラインでデータを保護するために設計された、プライバシーを強化するインフラソリューションです。SaaS プロバイダーとデータを共有する前に、追加の匿名化レイヤーが適用されます。このプロセスでは、個人を特定できる情報(PII)(名前、住所、クレジットカード番号など)が隠蔽されるか、暗号化で置き換えられます。この匿名化は、企業のセキュアなインフラ内でオンプレミスで行われるのが理想的です。
図-プライバシーレベル別AIソリューション-データの匿名化.png](https://assets.zilliz.com/Figure_AI_Solutions_by_Privacy_Level_Data_Anonymization_a4b3c6198e.png)
図:プライバシー・レベル別AIソリューション - データ匿名化_】(_png)
匿名化は、センシティブなデータが第三者によって再識別されたり、悪用されたりするリスクを大幅に低減できる一方で、欠点もある。匿名化されたデータでLLMをトレーニングすると、結果や推論の精度が低下する可能性がある。さらに、保護レイヤーが追加されたとはいえ、攻撃者は他のデータセットと相関させることで、部分的な情報を再識別できる可能性があります。
ローカル実行
ローカル実行は、パソコンやサーバーなど、隔離されたデバイス上でAIパイプライン全体を実行します。この方法は、データがシステム内に残り、LLMがオフラインで動作できるため、高いデータプライバシーを提供します。特に小規模なデータセットを扱う個人研究者に適しています。
図-プライバシーレベル別AIソリューション-ローカル実行.png](https://assets.zilliz.com/Figure_AI_Solutions_by_Privacy_Level_Local_Execution_f79e2bfbf4.png)
図:プライバシー・レベル別AIソリューション-ローカル実行_】(_png)
しかし、ローカル実行の実現可能性は、高いセットアップコストのために制限される可能性があります。完全にローカルシステム上で動作させるためには、高品質な結果を得るために高い計算能力を持つGPUや強力なデバイスが必要となる。さらに、ローカル実行は、データへのアクセスやリアルタイムのコラボレーションが制限されるため、複数の人々やチームによる共同プロジェクトには最適な選択肢ではないかもしれません。
社内開発
自社開発では、企業の安全なインフラ内で完全なエンドツーエンドのAIパイプラインを構築します。このアプローチにより、LLMのパフォーマンスが損なわれることはなく、データ漏洩のリスクも大幅に軽減されます。また、企業内のチーム間でのデータへのアクセスやコラボレーションも容易になります。
図-プライバシーレベル別AIソリューション-自社開発.png](https://assets.zilliz.com/Figure_AI_Solutions_by_Privacy_Level_In_House_Development_0cc3433794.png)
図:プライバシーレベル別AIソリューション - インハウス開発_」。
しかし、自社開発ソリューションの導入には、費用と時間の両面で多額の初期投資が必要であり、実現可能なのは主に大企業に限られる。企業は、ベクターデータベース、埋め込みモデル、GPU、フロントエンドなど、すべてをゼロからセットアップしなければならない。さらに、システムの構築と保守のために技術チームを雇い、訓練する必要があり、長期的なコストと運用上の要求が増える。
オンプレミス・インフラにとらわれない
ゼロから本格的なインフラを構築する余裕のない中小企業や新興企業にとって、ザイロンのようなオールインワンのAIワークスペースは実行可能なソリューションを提供する。このモデルでは、LLMを実行し、推論タスクをローカルで実行するために必要なコンポーネントをワークスペースが提供する一方で、データは企業のインフラ内に残ります。ザイロンには、PrivateGPTのようなプライバシー・ツールが組み込まれており、ユーザーは生成AIモデルを完全にローカル・ハードウェア上、または安全なインフラストラクチャ内で操作することができます。
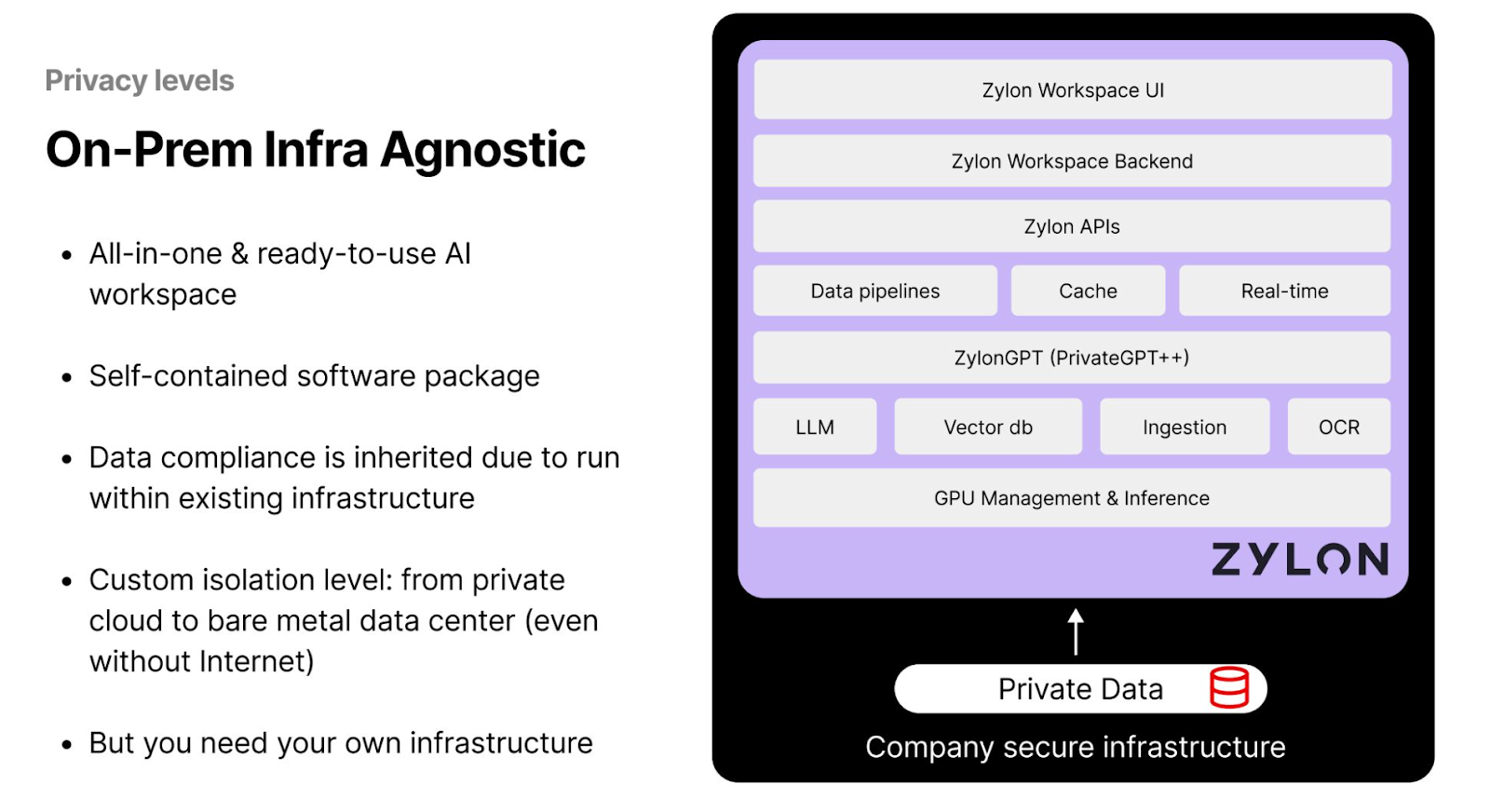 図-プライバシーレベル別AIソリューション-オンプレム・インフラ不可知論.png
図-プライバシーレベル別AIソリューション-オンプレム・インフラ不可知論.png
図:プライバシー・レベル別AIソリューション - オンプレミス・インフラ・アグノスティック
このアプローチでは、ザイロンは企業のデータにアクセスしないため、企業はプライバシーを損なうことなくAI機能を活用することができます。しかし、このソリューションの大きな限界は、企業がデータの管理を維持するためにデータセンターを設置する必要があり、コストがかかることです。この要件は、資本資源が限られている中小企業にとっては制約となる可能性がある。
PrivateGPTとは何か、どのようにAIのプライバシーを強化するのか?
PrivateGPTは、データプライバシー管理を強化したコンテキストアウェアなLLMを開発するために設計されたフレームワークである。PrivateGPTは、エンベッディングモデルを用いたエンベッディングの作成、Milvusのようなベクトルデータベースを用いた類似検索の実行、推論のための事前訓練されたLLMの利用など、様々なタスクのための一連のAIツールとAPIをユーザーに提供します。
下図は、PrivateGPTのパイプラインを示しています。このパイプラインには、通常、エンドユーザが問い合わせ可能なLLM、テキストや画像をベクトル埋め込みに変換する埋め込みモデル、およびこれらの埋め込みを格納するためのベクトルデータベースが含まれます。
図- PrivateGPTのアーキテクチャとコンポーネント.png](https://assets.zilliz.com/Figure_Private_GPT_Architecture_and_Components_16f50fb0cd.png)
図:PrivateGPTのアーキテクチャとコンポーネント
PrivateGPTは非常に柔軟性が高く、ユーザーは構成をカスタマイズしたり、ニーズに最適なAPIやモデルを選択することができます。例えば、ユーザーはLlamaやMistralのような様々なLLMから、要求されるアプリケーションの複雑さやスピードに応じて選択することができます。また、Milvusのような、ロバストで高速な検索が可能なベクトルデータベースを選択することも重要である。さらに、埋め込みモデルについては、Hugging Face社やNOMIC社など複数の選択肢が用意されており、さまざまなプロジェクト要件に対応し、システム全体のパフォーマンスを向上させるための幅広い選択肢を提供している。
PrivateGPTを使用してAIアプリケーションを構築するために、開発者はREST APIの2つの主要カテゴリにアクセスできます:プリミティブAPIとレシピAPIです。これらのAPIは、厳密なデータプライバシーを維持しながら、プライベートでコンテキストを意識したAIアプリケーションの作成を容易にするように設計されています。
プリミティブAPI
このAPIカテゴリは、チームが様々なレベルのカスタマイズを施したAIアプリケーションを開発することを可能にする:
ハイレベルAPI**:このAPIは、深いカスタマイズを必要としないシンプルなアプローチを好むユーザー向けに設計されており、すぐに使えるRAGパイプラインを提供する。チームはドキュメントをアップロードすることができ、APIは解析、分割、メタデータ埋め込み作成、保存など、多数のデータ処理タスクを処理する。また、プロンプトエンジニアリングにより、ユーザーのクエリに対してコンテキストベースの回答を提供することもできる。
低レベルAPI**:このAPIは、AIアプリケーションをよりコントロールしたいユーザーが、RAGパイプラインの個々のコンポーネントを作成し、カスタマイズすることを可能にします。ベクトル埋め込みロジックから文書取り込みの手順まで、ユーザーはデータ検索の最も効果的な戦略を発見するために実験することができます。
レシピAPI
最近導入された高度なAPIであるRecipes APIは、要約などの特定のAIタスクのための構造化されたワークフロー、つまり「レシピ」を構築することを可能にする。このAPIは、独自のビジネス要件に沿ったカスタマイズされたワークフローの開発を目指す企業にとって非常に貴重である。ローカルのデータベースやコンテンツ管理システムとシームレスに統合できるため、企業は外部サーバーにデータを送信することなく、内部プロセスを自動化・最適化できる。
ローカル実行のための## PrivateGPTセットアップ
PrivateGPTをローカル実行用に設定することで、100%のデータプライバシーを維持し、オフラインで運用することができます。Daniel氏はこのセットアップで推論タスクにOllamaを使用することを推奨しており、GPU構成をサポートし、様々なLLMモデルとシームレスに統合できます。この柔軟性は、さまざまなデータタイプ(テキスト、音声、画像など)や特定の計算タスクに適応するために極めて重要だ。一般的なLLMの選択肢としては、LlamaとMistral AIがあり、これらは多様なユースケースにおいて堅牢な性能を発揮することで知られています。
ベクトル・データベースについては、大規模な類似性検索機能で広く知られているMilvusベクトル・データベースの簡素化バージョンであるMilvus Liteを使用することをDanielは勧めている。リソース消費量が少ないため、Milvus Liteはリソースが限られた環境に最適です。迅速な類似検索とデータ検索が可能なため、大規模なインフラを必要としない小規模なアプリケーションに最適です。
さらにDaniel氏は、多様な言語をサポートする埋め込みモデルを選択することを勧めている。これにより、作成されたベクトル埋め込みは、さまざまな国際的な文脈や言語的ニーズに適用され、AIアプリケーションの全体的な実用性と到達度を高めることができます。
図-ローカル展開のための推奨PrivateGPTセットアップ.png](https://assets.zilliz.com/Figure_The_Recommended_Private_GPT_Setups_for_Local_Deployment_0f66be9f5e.png)
図:ローカル展開のための推奨PrivateGPTセットアップ_png
クラウド実行のためのPrivateGPTセットアップ
大規模なAIアプリケーションを開発する場合、PrivateGPTをクラウド実行用にセットアップし、ユーザーが世界中のどこからでもインスタンスにアクセスできるようにすることが推奨されます。このセットアップには、ローカル実行に比べてより複雑で厳しいインフラ要件が含まれます。Danielは、データプライバシーを保護しながら効率を最大化するクラウドアーキテクチャを確立するための効果的な戦略を概説しています。
まず始めに、ユーザーはAWSのようなサービスプロバイダーからクラウドインスタンスを調達する必要があります。Daniel氏は、このクラウドインスタンスにベクターデータベースとしてMilvus StandaloneをDockerを使ってインストールすることを推奨している。Milvus Standaloneはシングルノードのデプロイメントを提供し、そのシンプルさにもかかわらず、包括的なベクトル検索、インデックス作成、ストレージ機能を提供し、PrivateGPTアプリケーションに理想的である。
さらに、クラウドインスタンスにNodeJSサーバーをセットアップすることで、AIアプリケーションへのスムーズなアクセスとインタラクションが可能になる。このサーバーはPrivateGPTモデルへのリクエストとPrivateGPTモデルからのリクエストを処理する仲介役として機能し、ネットワーク全体でシームレスかつ効率的なオペレーションを実現します。
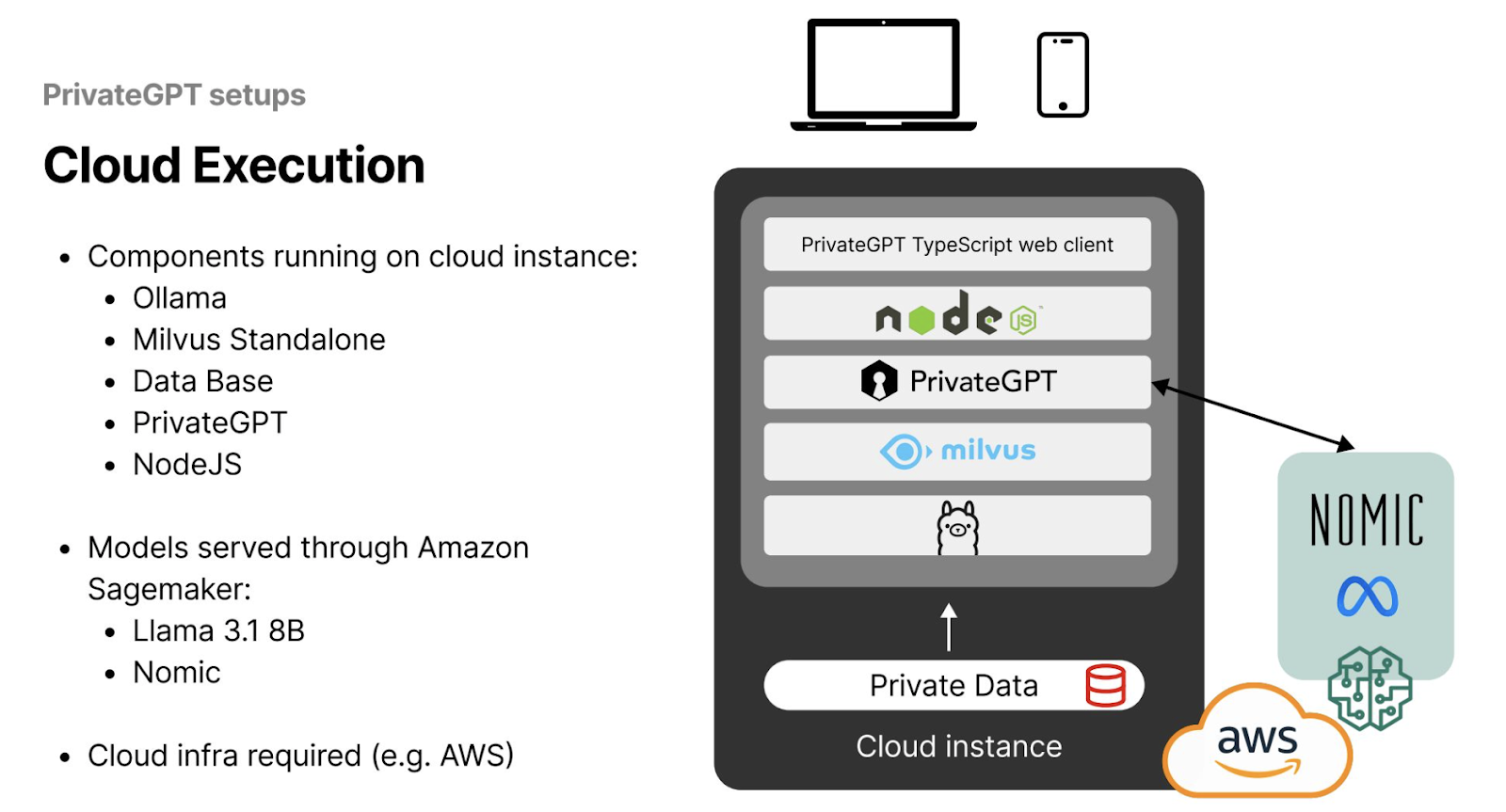 図- クラウド展開のための推奨PrivateGPTセットアップ.png
図- クラウド展開のための推奨PrivateGPTセットアップ.png
図:クラウド展開のための推奨PrivateGPTセットアップ__。
まとめ
この投稿では、AIアプリケーション開発におけるデータプライバシー、特に機密性の高い顧客情報を扱う場合について議論した。規制基準に従うだけでは、リバース・エンジニアリングやモデル推論のような高度な攻撃からデータを守ることはできないことを学んだ。
また、さまざまなデータ・プライバシー戦略を詳しく見て、それぞれに関連する投資とリスクを評価しました。ダニエルは、PrivateGPTのようなツールとMilvusのようなベクターデータベースを統合することで、LLM出力の精度を高め、プライバシーを保護する方法についての洞察を共有しました。また、ローカルおよびクラウドベースの展開におけるセキュアなアーキテクチャの設定に関する実践的なアドバイスも提供し、企業が厳格なデータ保護基準を守りながら、堅牢で効率的なAIシステムを構築できるようにしました。
その他のリソース
データの保護:ベクター・データベース・システムにおけるセキュリティとプライバシー ](https://zilliz.com/learn/safeguarding-data-security-and-privacy-in-vector-database-systems)
LangchainとZilliz CloudによるAI検索におけるデータ・プライバシーの確保 ](https://zilliz.com/blog/ensure-data-privacy-in-AI-search-with-langchain-and-zilliz-cloud)
プライベートLLMとは?大規模言語モデルをプライベートで実行する - PrivateGPTとその先へ](https://zilliz.com/learn/what-are-private-llms)
RAGとは何か ](https://zilliz.com/learn/Retrieval-Augmented-Generation)
GenAIエコシステムの風景:LLMとベクトルデータベースを超えて ](https://zilliz.com/blog/landscape-of-gen-ai-ecosystem-beyond-llms-and-vector-databases)
ジェネレーティブAIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)
MilvusでAIアプリを作る:チュートリアル&ノートブック](https://zilliz.com/learn/milvus-notebooks)
あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models)
 Fendy Feng
Fendy FengFendy Feng is the Technical Marketing Writer at Zilliz. She has extensive experience developing and enhancing the impact of open-source projects in various global markets by producing high-quality, tailored content. Before joining Zilliz, Fendy worked as a Content Strategist at PingCAP, a fast-growing E-Series startup renowned for its open-source distributed SQL database.
 ShriVarsheni R
ShriVarsheni R
読み続けて

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

Balancing Precision and Performance: How Zilliz Cloud's New Parameters Help You Optimize Vector Search
Optimize vector search with Zilliz Cloud’s level and recall features to tune accuracy, balance performance, and power AI applications.

What is the K-Nearest Neighbors (KNN) Algorithm in Machine Learning?
KNN is a supervised machine learning technique and algorithm for classification and regression. This post is the ultimate guide to KNN.