




DeepSeekはいつも忙しい? Milvusを使えば、わずか10分でローカルに展開できます!
DeepSeek-R1](https://zilliz.com/ai-faq/what-is-the-deepseekr1-model)を使ってみて、「サーバーがビジー状態です。Please try again later"(後で再試行してください)」というメッセージに遭遇したことがある方は、このメッセージがどれほど邪魔になるかをご存知でしょう。ビジー状態のサーバで待機していると、特に迅速な回答が必要な場合やタスクに集中している場合に、ワークフローが中断される可能性があります。
これを回避する実用的な方法は、DeepSeek-R1 を自分のマシンで直接実行することです。これにより、サーバの遅延を回避し、モデルの使用方法と使用時間をより詳細に制御できます。このガイドでは、一緒に動作するいくつかのツールを使用して、DeepSeek-R1をローカルにセットアップする手順を説明します。Ollama**を使用して、お使いのシステムにモデルをダウンロードして実行します。次に、AnythingLLM を使用して、簡単なインターフェイスで DeepSeek-R1 と簡単にやり取りできるようにします。最後に、ベクトルデータベースであるMilvusを統合して、モデルが質問に答えるときに、独自のドキュメントやカスタム情報などの外部データを参照できるようにします。
始めるのにトップクラスのハードウェアは必要ありません。DeepSeek-R1では、より一般的なセットアップで実行可能なモデルの小型バージョンを提供しています。DeepSeek-R1を仕事、研究、または個人的なプロジェクトで使用する場合でも、ローカルに設定することで、サーバの問題を回避し、モデルをニーズに合わせて調整することができます。まず、Ollama で DeepSeek-R1 をセットアップします。
OllamaによるDeepSeek-R1の展開: インストールとセットアップ
ローカルマシン上でAIモデルを実行するプロセスを簡素化するOllamaをインストールすることから始めます。まず、Ollama ダウンロードページ にアクセスし、オペレーティングシステムに対応するインストーラを選択します。
Ollama ダウンロードページ](https://assets.zilliz.com/Figure_Ollama_download_page_9053092c5d.png)
図:Ollamaダウンロードページ
ダウンロードが完了したら、実行し、画面の指示に従ってセットアップを終了してください。インストールが完了したら、Ollamaが正しくセットアップされていることをコマンドラインインターフェイスを開いて確認してください:
ollama --バージョン
すべてが正しくインストールされていれば、バージョン番号が表示されます。このチェックにより、AIモデルをローカルで管理する環境が整っていることが確認できます。
次に、DeepSeek-R1をダウンロードする。ほとんどのユーザーにとって、70億パラメータ(7B)バージョンは、パフォーマンスと必要なリソースの実用的なバランスを取っており、一般的に約18GBのVRAMを搭載したGPUが必要です。ハードウェアの性能が低い場合は、1.5Bモデル(約3.9GBのVRAM)が利用可能です。高度なセットアップの場合は、671Bフルモデルを検討することができますが、これははるかに高いリソースを要求します。ご希望のモデルサイズに応じて、以下のコマンドを調整してください:
ollama pull deepseek-r1:7b
上記のコマンドは、以下のように指定されたモデルをコンピューターにダウンロードします:

図:Ollamaを経由したdeepseek-r1:7bのコンピュータへのインストール_。
モデルのダウンロードが完了したら、DeepSeek-R1 を実行して起動します:
ollama run deepseek-r1:7b
7bを1.5b`に置き換えるか、別のモデルを選択した場合は別のバージョンに置き換える。モデルが起動したら、コマンドラインに直接プロンプトを入力することで、モデルとのやりとりを始めることができる。
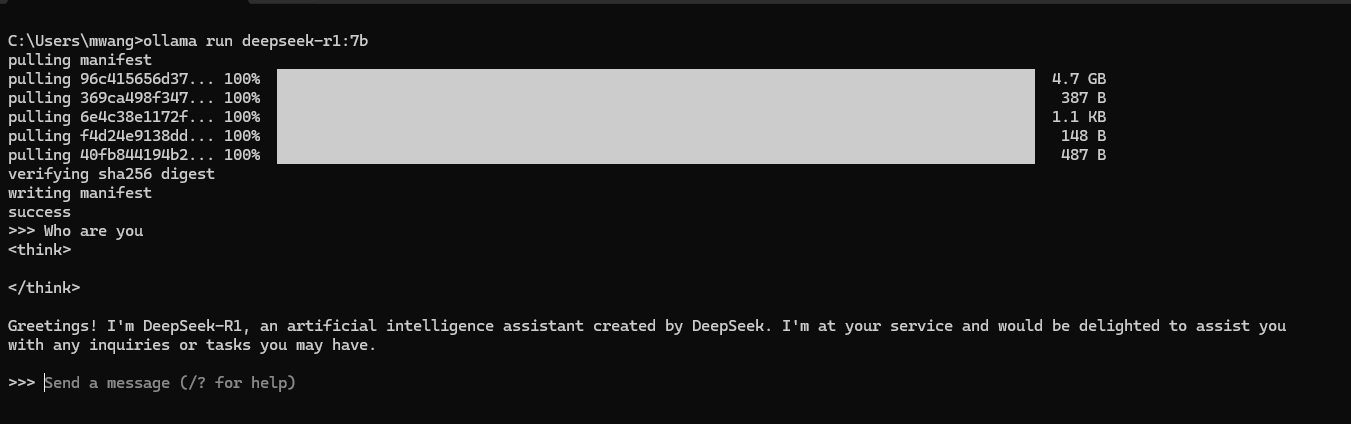
図:deepseek-r1:7bのサンプルセッションでは、ユーザーがクエリを尋ね、モデルが応答を返します。
上のスクリーンショットは、サンプル・セッションを示しています。「あなたは誰ですか?
##AnythingLLMのインストールと設定
コマンドラインでの対話は基本的なテストには有効ですが、継続的な使用には面倒な場合があります。AnythingLLMは、ローカルで実行されているモデルとの会話をより直感的にするチャットスタイルのインターフェースを提供します。また、複数の言語モデルバックエンドをサポートし、カスタムデータをアップロードする簡単な方法を提供し、Milvusのようなベクトルデータベースと統合することができます。以下はその機能の概要と、Ollamaへのインストールと接続方法です。
なぜAnythingLLMを使うのか?
機能の一部をご紹介します:
インタラクティブチャット:** AnythingLLM は、手動コマンドラインプロンプトをチャットウィンドウに置き換え、会話の流れを見たり、過去のクエリを参照することを容易にします。
モデルの一元管理:**異なる言語モデルを1つのインターフェイスで実行し、複数の端末を操作することなく切り替えることができます。
データ統合:** ベクターデータベース(Milvusのような)をサポートしているため、ドキュメント、リサーチファイル、その他のリソースをアップロードすることができます。
Easy Embeddings Configuration: ドキュメントやユーザークエリをベクトルに変換するために使用するエンベッディングモデルを選択することで、システムが関連情報をより正確に見つけることができます。
これらの機能は、基本的な端末でのやり取り以上のものを必要とする人に、よりスムーズなワークフローを提供します。AnythingLLMのインストールと設定方法を見てみましょう:
ステップ 1: AnythingLLM のダウンロードとインストール
AnythingLLM ウェブサイト](https://anythingllm.com/) にアクセスし、お使いのオペレーティングシステムに合ったインストーラを選択します。ファイルがダウンロードされたら、それを実行し、セットアップを完了するためにプロンプトに従ってください。インストールが完了したら、AnythingLLM を開き、アプリケーションが初期設定の準備ができていることを示す Get Started ページまたはウィザードが表示されます。
ステップ 2: 初期プロンプトのスキップ
AnythingLLM を最初に開くと、LLM Preference、Data Handling & Privacy、オプションの Survey のプロンプトが表示されます。アプリ内でこれらのオプションにアクセスし設定する方法を説明するため、各画面でスキップを選択してください。AnythingLLMを起動するたびにこれらのプロンプトが表示されるわけではありませんので、後でこれらのプロンプトが表示される場所を覚えておくと、必要に応じて設定を調整したり、設定を更新したりするのに役立ちます。
ステップ 3: 最初のワークスペースの作成
最初のプロンプトをスキップした後、最初のワークスペースを作成するように求められます。
ワークスペースの名前を選択し、右矢印をクリックして次に進みます。私たちは Milvus-DeepSeek-Local-Deploy と名付けました。このワークスペースは、会話を整理し、アップロードしたドキュメントを保存するための専用エリアです。作成されると、チャットのインターフェイスが表示されます:
モデルを接続した後、ここで DeepSeek-R1 と対話します。
ステップ 4: DeepSeek-R1 をワークスペースに接続します。
モデルを接続するには、ワークスペース名の横にある [Settings] ボタンをクリックします。開いたパネルで、[チャット設定] を選択します。ワークスペース** LLM プロバイダ を選択し、ワークスペース・チャット・モデル を設定するオプショ ンが表示されます。
ここでは Ollama を使用しているので、プロバイダのリストから Ollama を選択します。次に、Workspace Chat model をクリックして、Ollama からダウンロードしたモデルを選択します。これには、DeepSeek-R1 (たとえば、この例では deepseek-r1:7b) が含まれます。
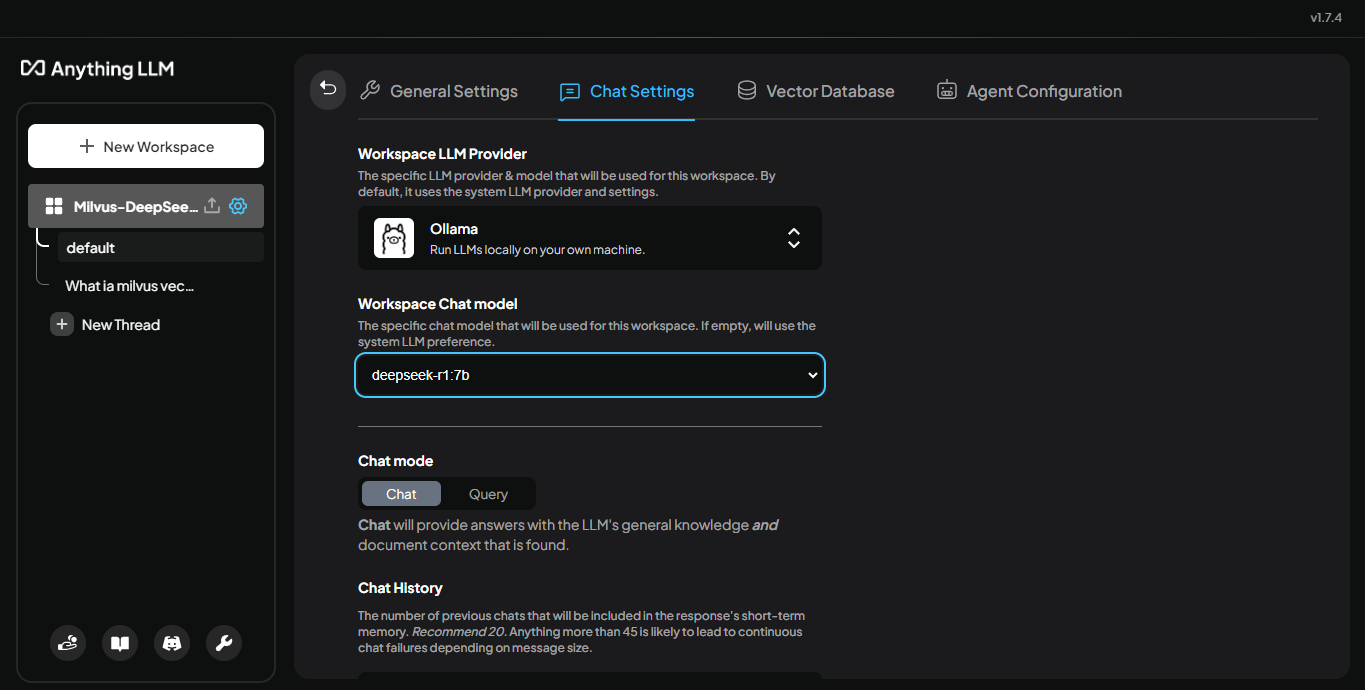
図:LLMプロバイダとしてOllamaを、選択されたモデルとして_ deepseek-r1:7bを表示するチャット設定パネル
モデルを選択したら、変更を保存します。これであなたのワークスペースは選択したモデルに接続され、チャットインターフェイスを通して直接対話できるようになります。チャットインターフェイスに戻ってチャットを始めてください。
ステップ5: クエリでモデルをテストする。
ワークスペースが DeepSeek-R1 に接続されたので、学習していない質問に対してどのように応答するかをテストできます。クリス・チュリロ(Chris Churilo)とは誰ですか?
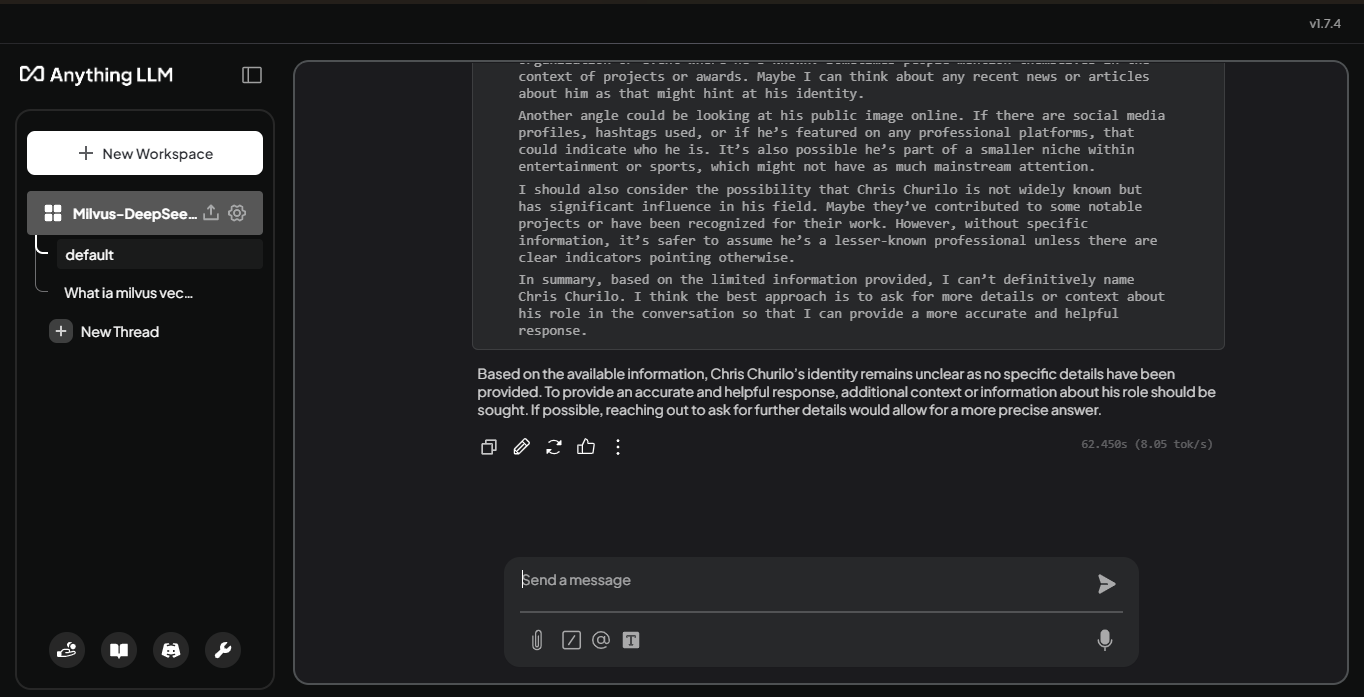
図:クリス・チュリロとは誰か」に対するLLMの回答_。
このモデルはクリス・チュリロに関する情報を欠いているため、詳細な回答を与えることができない。このギャップは、外部の知識ソースの必要性を示している。ベクトル・データベースであるMilvusは、クリス・チュリロに関するエンベッディングの形で関連データを保存することができ、LLMはそれらを参照することができます。
##MilvusのセットアップとAnythingLLMとの統合
ワークスペースと外部データをリンクする前に、カスタムデータからembeddings(連続したベクトル空間におけるデータ(単語や画像など)の数値表現で、その意味や特徴を捉え、類似したアイテムがより近くに配置されるようにする)を格納できるベクトルデータベースをデプロイする必要があります。Milvusをインストールし、AnythingLLMをベクトルデータベースとして使用するように設定する方法を見てみましょう。
Milvusのインストール
まず、お使いのマシンにDockerとDocker Composeがインストールされていることを確認します。次に、ターミナルを開き、MilvusのスタンドアロンDocker Composeファイルをダウンロードします:
wget https://github.com/milvus-io/milvus/releases/download/v2.5.4/milvus-standalone-docker-compose.yml -O docker-compose.yml
次に、ダウンロードした docker-compose.yml ファイルをテキストエディタで開く。そして、standalone サービスのコンフィギュレーション設定を確認し、COMMON_USER と COMMON_PASSWORD フィールドを任意の認証情報で更新する。
環境の設定を変更する:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
コモンユーザー: milvus
COMMON_PASSWORD:ミルバス
後でAnythingLLMをMilvusに接続するように設定する際に、これらの認証情報を使用します。変更を保存した後、ターミナルに戻り、以下のコマンドを実行してMilvusを起動します:
docker-compose up -d
このコマンドはバックグラウンドでMilvusを起動します。Milvusが起動しているかどうかは、Dockerコンテナを docker ps で確認するか、healthエンドポイントが設定されている場合はアクセスして確認することができる。
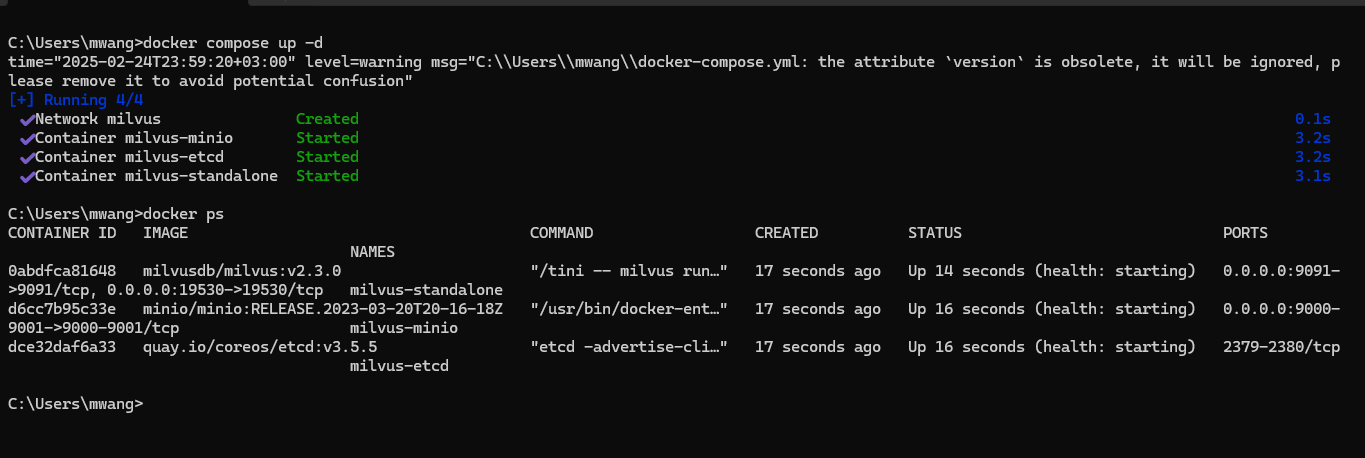
図:コマンドラインでdocker composeを使用してMilvusを起動する。
Milvusがインストールされたので、AnythingLLMと統合する準備ができました。
MilvusとAnythingLLMの統合
Milvusが実行されている今、カスタムデータの埋め込みを保存および取得するためにAnythingLLMを設定しましょう。以下のステップに従って、DeepSeek-R1モデルからより多くのコンテキスト駆動型レスポンスを有効にしてください。
1.設定を開く
AnythingLLM インターフェイスの左下にある Open Settings ボタンをクリックします。これにより、いくつかの設定カテゴリを持つパネルが表示されます。
図:設定を開く]ボタンが強調表示されたAnythingLLMのメインインターフェイス_。
2.ベクターデータベースを選択します
設定パネルで、AI Providers を展開し、Vector Database を選択します。Vector Database Providerで、Milvus**を選択します。Milvus Docker Composeファイルで設定したアドレスと認証情報のフィールドが表示されます:
Milvus DB Address:
http://localhost:19530Milvus Username: (設定したユーザ名).
ミルバスパスワード: (設定したパスワード)。
保存**をクリックして設定を確定します。
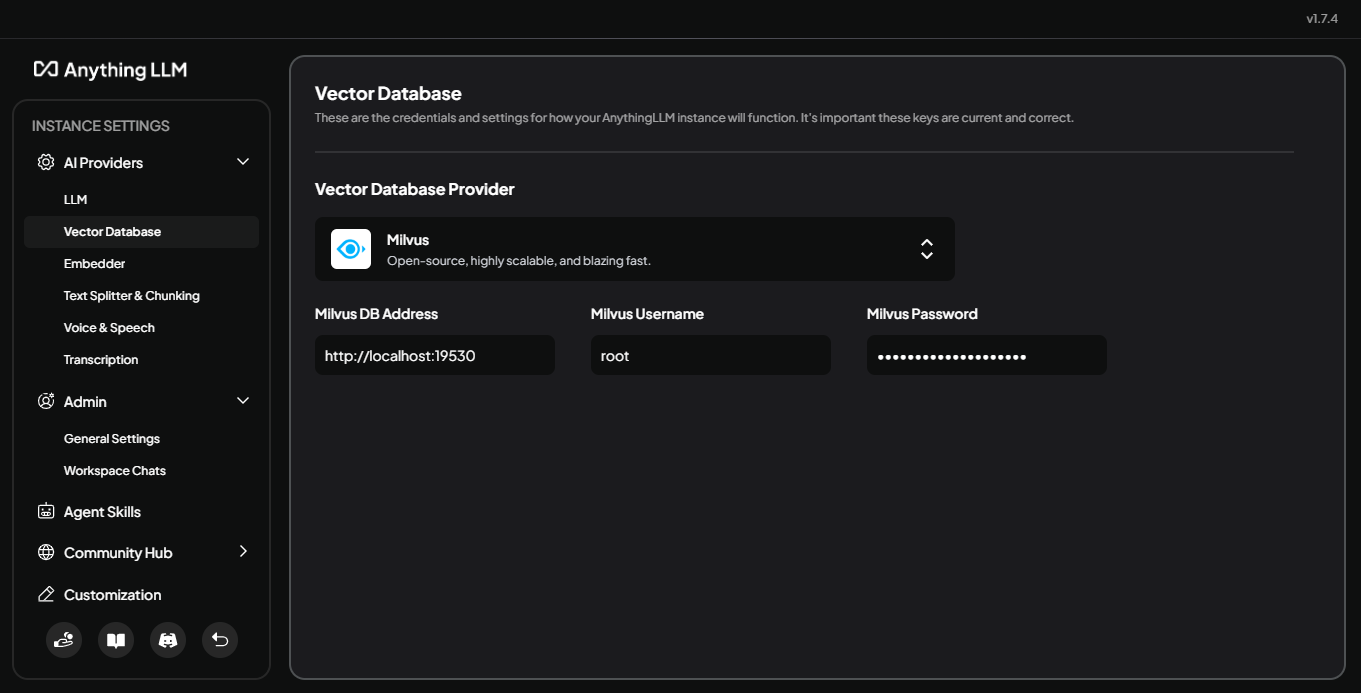
図:Milvusを選択した状態でのAnythingLLMでのベクターデータベースの設定_。
3.エンベッダーの選択(オプション)
まだAI Providersの下に、必要であれば、異なるエンベッディングモデルを選択することができます。何も選択しない場合、AnythingLLMはデフォルトのエンベッダーを使用します。このステップは、基本的な使用ではオプションですが、テキストがどのようにベクトル化されるかを最適化したい場合に便利です。この場合、デフォルトのオプションを使用します。
図:該当する場合、AnythingLLMにモデル選択を埋め込む_。
4.ドキュメントのアップロード
メインインターフェイスまたはワークスペースビューに戻ります。モデルに参照させたいドキュメントをドラッグ&ドロップするか、インターフェイスから選択してアップロードします。AnythingLLMがファイルを一覧表示し、埋め込む準備が整います。
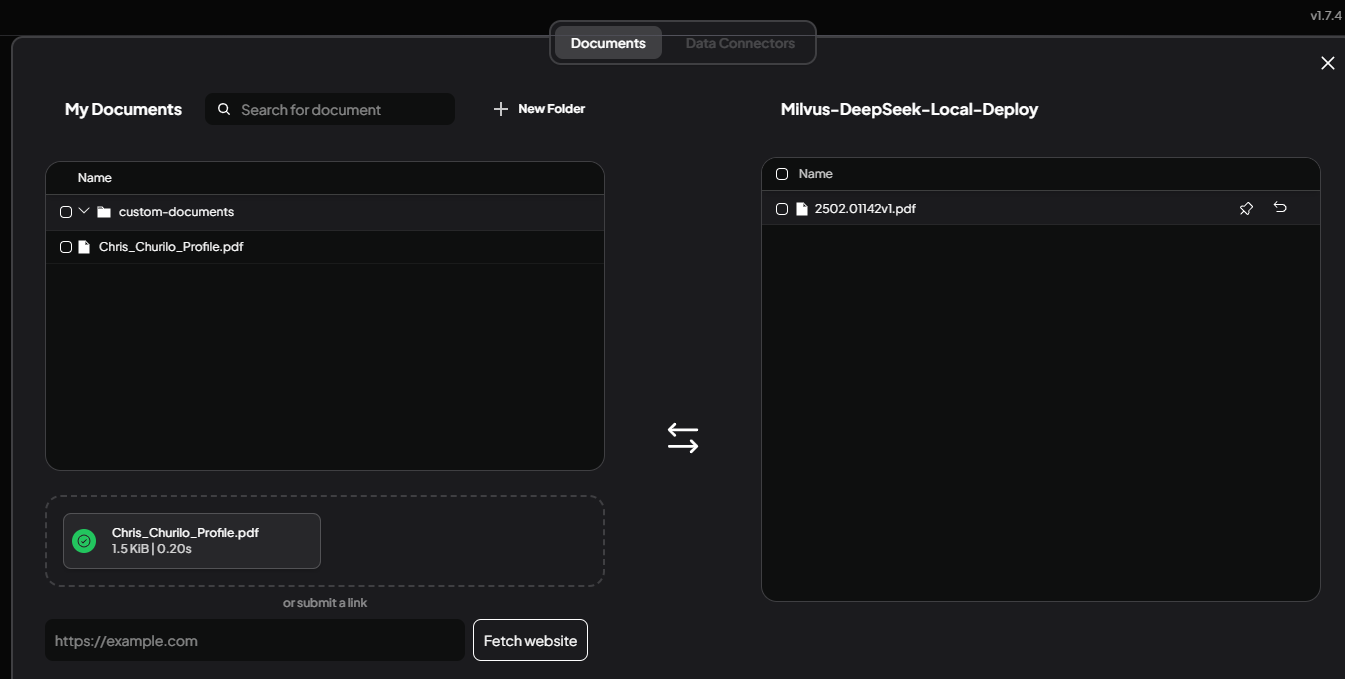
図:新しく追加されたファイルを表示するドキュメントのアップロードエリア
5.ドキュメントをワークスペースに移動する
ドキュメントが表示されたら、各ファイルを選択し、Move to Workspace を選択します。右側のパネルで、Save and Embed をクリックします。AnythingLLM は、ドキュメントをベクトル埋め込みに変換して Milvus に保存し、DeepSeek-R1 がコンテンツにアクセスできるようにします。
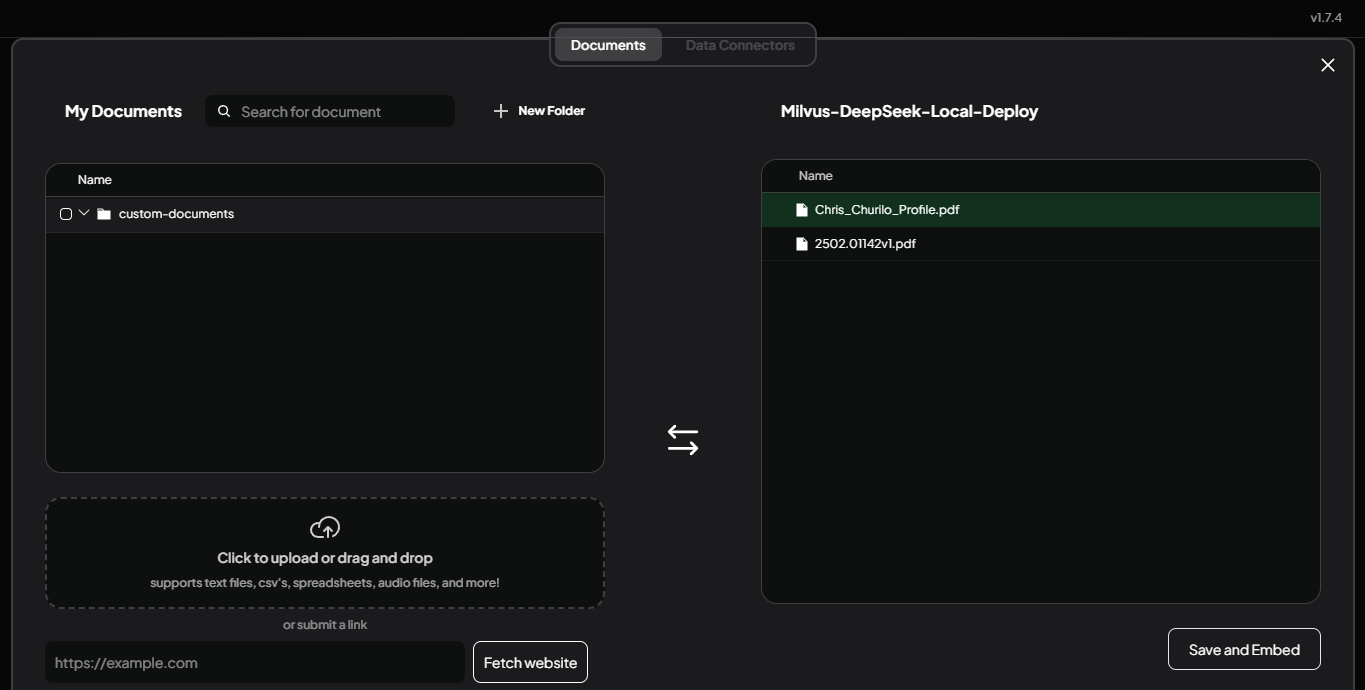
図:ドキュメントをワークスペースに移動し、埋め込む。
これらの手順を完了すると、DeepSeek-R1 モデルで埋め込みドキュメントを参照できるようになります。例えば、"Chris Churilo は誰ですか?と尋ねると、以下のように、モデルは彼女が誰であるかを認識します:
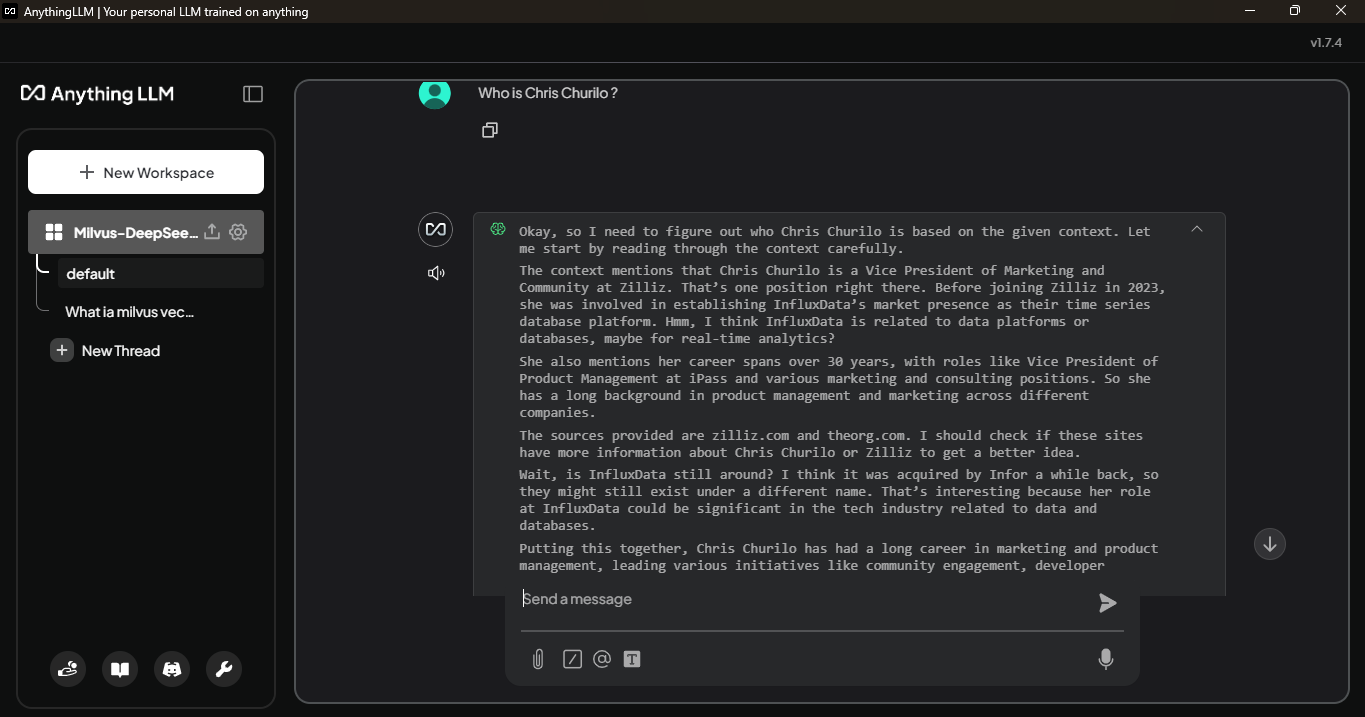
図:DeepseekR1がクエリに答える方法を考えているところ。
このモデルは、Milvusに格納されている関連情報を検索し、以前よりも詳細な回答を提供します。これがクエリに対する最終的な答えです。
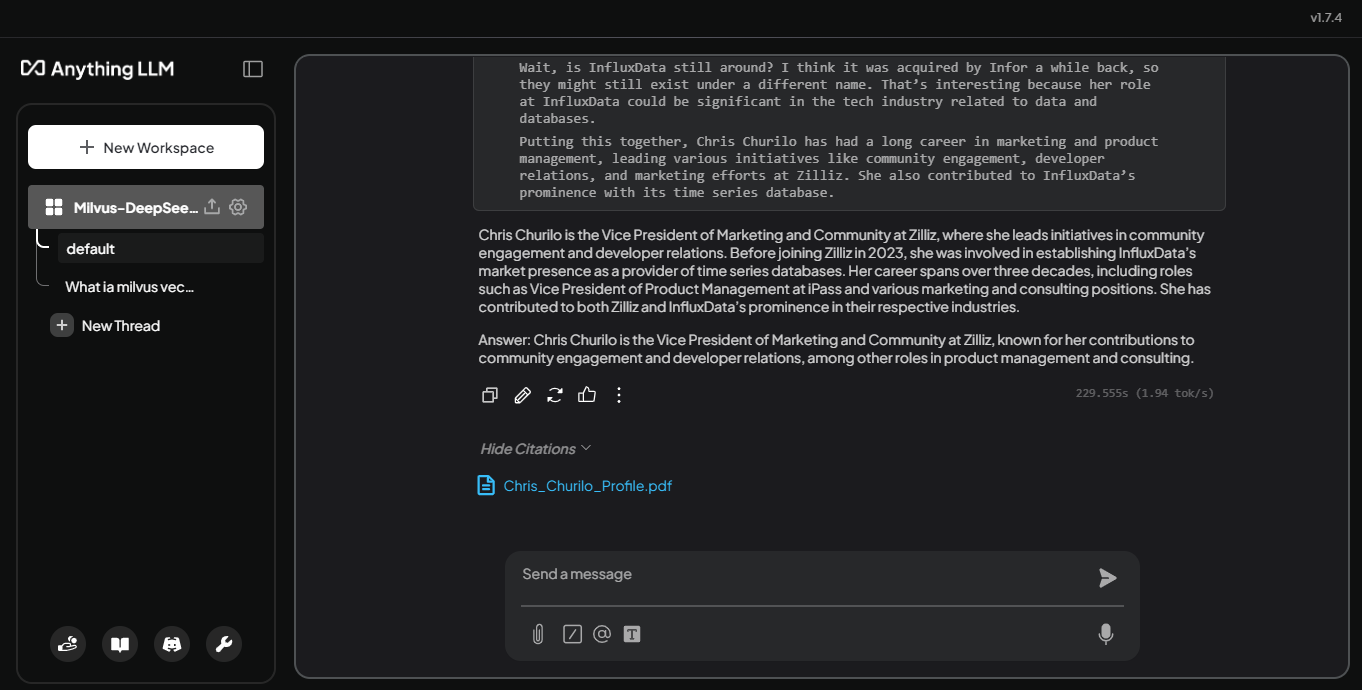
図:クエリに答えるDeepseekR1 _*_Chris Churiloは誰ですか?
このモデルは、アップロードされたドキュメントを引用した詳細な回答を返します。上のスクリーンショットでは、Milvusを統合する前には入手できなかったChris Churiloの役割、経歴、貢献について、モデルが関連する詳細を引き出していることがわかります。この強化されたレスポンスは、ローカルLLMデプロイメントとベクターデータベースを組み合わせることで、より情報に基づいたコンテキストを認識したAIエクスペリエンスを実現することの価値を示しています。
Milvusにおけるコレクションの検証
AnythingLLMを通してドキュメントを埋め込んだら、Milvusがそれらを正しく保存していることをコレクションをリストすることで確認できます。まだ pymilvus をインストールしていない場合は、以下のコマンドでインストールを開始します:
pip install pymilvus
そして、以下のPythonコードを実行して、Milvusに接続し、コレクションのリストを取得し、それらの名前を表示する:
from pymilvus import MilvusClient
# Milvus に接続する
client = MilvusClient(uri="http://localhost:19530") # URIが異なる場合は置き換えてください。
# 全てのコレクションをリストアップする
collections = client.list_collections()
# 結果を印刷する
print(f"{len(コレクション)}コレクションが見つかりました:")
for idx, collection in enumerate(collections, 1):
print(f"{idx}. {コレクション}")
# オプション:終了したら接続を閉じる
client.close()
Milvusをインストールしたばかりの場合、多くのコレクションは表示されません。しかし、AnythingLLMを使用してドキュメントを埋め込むと、使用したワークスペースの名前が付いた新しいコレクションが表示されます。以下の出力例では、関連するコレクションは 21.Anythingllm_milvus_deepseek_local_deploy です。
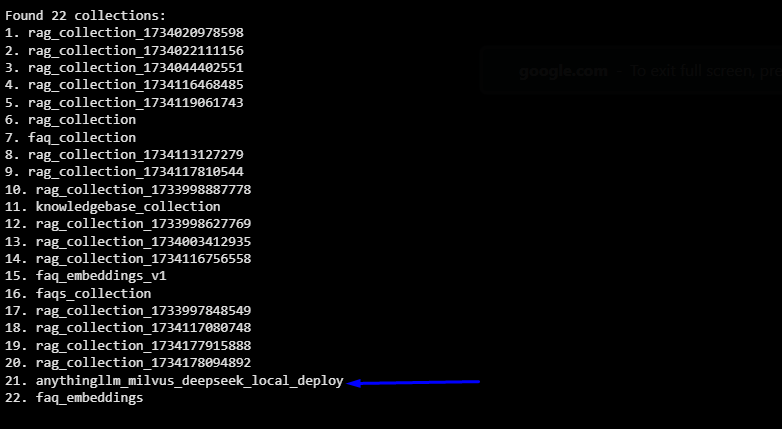
これにより、AnythingLLMがアップロードされたデータの埋め込みを保存するための専用コレクションをMilvusに正常に作成したことが確認できます。
ここまで、DeepSeek-R1をローカルにデプロイし、AnythingLLMをユーザーフレンドリーなインターフェースに設定し、Milvusをベクトルデータベースとして統合する手順を説明しました。このセットアップにより、モデルはカスタムデータにアクセスし、より効果的に質問に答えることができます。
結論
Ollama、AnythingLLM、Milvusの助けを借りてDeepSeek-R1をローカルにセットアップすると、AIワークフローをカスタマイズして強化するための新しい可能性が開けます。このアプローチでは、環境を完全に制御できるだけでなく、モデルが特定のデータソースにアクセスし、その関連性と精度を向上させることができます。このセットアップにより、サーバーの可用性や一般的なレスポンスに制限されることがなくなります。
その他のリソース
MilvusとDeepSeekによるRAGの構築|Milvusドキュメント](https://milvus.io/docs/build_RAG_with_milvus_and_deepseek.md)
わずか3分でDeepSeek-R1をローカルで無料実行 - DEVコミュニティ](https://dev.to/pavanbelagatti/run-deepseek-r1-locally-for-free-in-just-3-minutes-1e82)
deepseek-ai/DeepSeek-R1](https://github.com/deepseek-ai/DeepSeek-R1/tree/main)
読み続けて

Top 10 Context Engineering Techniques You Should Know for Production RAG
A practical guide to context engineering for production LLM systems, covering RAG, context processing, memory, agents, and multimodal context.

How to Build an Enterprise-Ready RAG Pipeline on AWS with Bedrock, Zilliz Cloud, and LangChain
Build production-ready enterprise RAG with AWS Bedrock, Nova models, Zilliz Cloud, and LangChain. Complete tutorial with deployable code.

Vector Databases vs. Key-Value Databases
Use a vector database for AI-powered similarity search; use a key-value database for high-throughput, low-latency simple data lookups.